掌握工具易,領悟其道難——本文帶你穿透API表面,直擊工業級機器學習實踐的核心邏輯。
作為一名長期耕耘在機器學習研究與工業應用一線的從業者,我見過太多因誤用?sklearn?而導致的模型失效案例。從數據泄露到評估失真,從特征處理失誤到超參調優陷阱。本文將結合真實項目經驗,系統闡述如何科學、嚴謹地使用這一強大工具庫。
一、數據預處理:模型效果的基石與常見陷阱
核心原則:?預處理必須在訓練集上擬合轉換器,在測試集/新數據上僅應用轉換。避免任何形式的數據泄露。
1.1 標準化/歸一化:不只是調用?StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler# 錯誤示范:在整個數據集上擬合轉換器
scaler = StandardScaler().fit(X) # 泄露測試集信息!
X_scaled = scaler.transform(X)# 正確方法:嚴格隔離訓練集與測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)scaler = StandardScaler().fit(X_train) # 僅在訓練集擬合
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test) # 測試集使用訓練集的參數轉換深入解析:?標準化器(如?StandardScaler)在?fit?時計算訓練集的均值(mean_)和標準差(scale_)。在測試集上使用這些參數轉換,模擬模型部署時遇到新數據的情景。若在整個數據集上擬合,測試集信息會“污染”轉換參數,導致評估過于樂觀,模型上線后性能驟降。
1.2 缺失值處理:選擇與模型兼容的策略
from sklearn.impute import SimpleImputer
from sklearn.ensemble import RandomForestRegressor# 數值型特征:中位數填充 (對異常值穩健)
num_imputer = SimpleImputer(strategy='median')# 分類特征:眾數填充
cat_imputer = SimpleImputer(strategy='most_frequent')# 高級技巧:模型驅動的填充 (如KNNImputer)
from sklearn.impute import KNNImputer
knn_imputer = KNNImputer(n_neighbors=5)經驗之談:?樹模型(如?RandomForest)本身能處理缺失值(sklearn?中需顯式設置),但多數模型(如?SVM, 線性模型)不能。KNN填充效果通常優于簡單統計量,但計算開銷大。關鍵點:?任何填充策略的擬合(如計算中位數/眾數/KNN模型)必須僅基于訓練集。
1.3 分類特征編碼:OneHotEncoder?vs?OrdinalEncoder
OneHotEncoder?(獨熱編碼):?適用于無內在順序的類別(如城市:北京、上海、深圳)。產生稀疏矩陣。OrdinalEncoder?(序數編碼):?適用于有內在順序的類別(如學歷:高中<本科<碩士<博士)。轉換為有序整數。
from sklearn.preprocessing import OneHotEncoder, OrdinalEncoder# 獨熱編碼 (注意handle_unknown='ignore'防止新類別報錯)
ohe = OneHotEncoder(handle_unknown='ignore', sparse_output=False).fit(X_train_cat)
X_train_ohe = ohe.transform(X_train_cat)# 序數編碼 (需指定categories順序)
education_order = [['高中', '本科', '碩士', '博士']]
ord_enc = OrdinalEncoder(categories=education_order).fit(X_train_edu)
X_train_ord = ord_enc.transform(X_train_edu)避坑指南:?獨熱編碼可能導致高維災難(維度爆炸)。對于高基數類別,考慮:
目標編碼 (
TargetEncoder):?用目標變量的統計量(如均值)編碼類別。極易導致目標泄露!?必須在交叉驗證循環內部謹慎使用或使用平滑技術。嵌入編碼 (Embedding):?深度學習常用,將類別映射到低維連續向量(需神經網絡模型配合)。
頻率編碼:?用類別出現頻率代替類別本身。
二、模型選擇:理解算法本質,匹配問題特性
2.1 沒有免費的午餐定理:算法選擇取決于數據
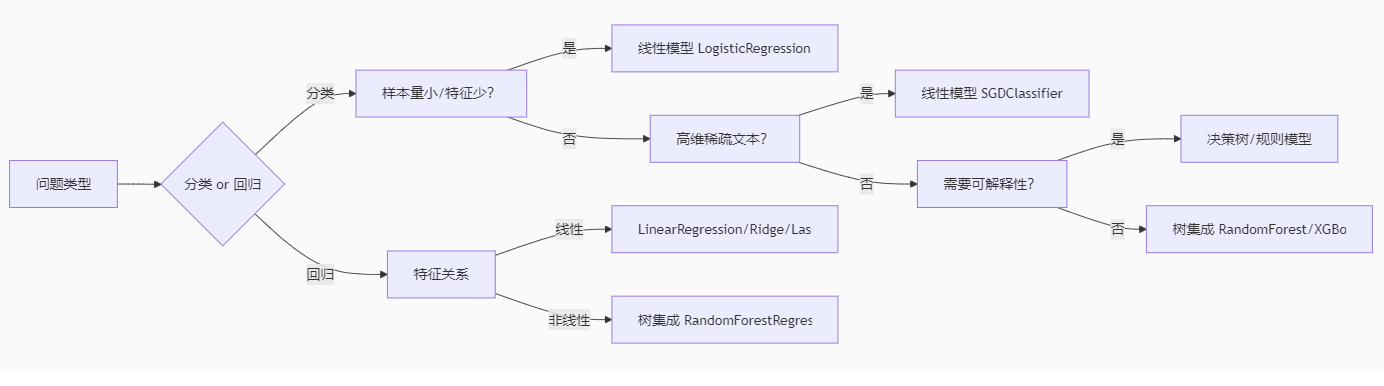
2.2 線性模型:正則化是防止過擬合的關鍵
Ridge?(L2正則化):所有系數收縮但不歸零,適用于特征間可能存在共線性的情況。Lasso?(L1正則化):傾向于將不重要特征的系數壓縮為零,實現特征選擇。ElasticNet:結合L1和L2正則化。
from sklearn.linear_model import Ridge, Lasso, ElasticNet# Ridge回歸:調整alpha控制正則化強度
ridge = Ridge(alpha=1.0).fit(X_train_scaled, y_train)# Lasso回歸:同樣調整alpha,特征選擇更明顯
lasso = Lasso(alpha=0.01, max_iter=10000).fit(X_train_scaled, y_train) # 常需增加max_iter# ElasticNet:平衡L1和L2,調整alpha和l1_ratio
en = ElasticNet(alpha=0.1, l1_ratio=0.5).fit(X_train_scaled, y_train)核心提示:?線性模型通常要求輸入特征進行標準化處理。?正則化強度?alpha?需要通過交叉驗證仔細調優。
2.3 支持向量機:核函數與參數?C?的選擇
線性核 (
kernel='linear'):?高效,適用于特征多、樣本多或樣本量遠大于特征數的情況。可解釋性較好。徑向基核 (
kernel='rbf'):?最常用,適用于非線性問題。關鍵參數?gamma?(控制單個樣本影響范圍) 和?C?(控制錯誤分類懲罰)。gamma?小:決策邊界平滑,模型簡單,可能欠擬合。gamma?大:決策邊界復雜,模型可能過擬合。C?小:允許更多誤分類,決策邊界平滑,模型簡單。C?大:嚴格懲罰誤分類,決策邊界復雜,模型可能過擬合。
代碼如下:
from sklearn.svm import SVC# 線性SVM
svm_linear = SVC(kernel='linear', C=0.1).fit(X_train_scaled, y_train)# RBF核SVM (通常需要特征縮放)
svm_rbf = SVC(kernel='rbf', C=1.0, gamma=0.1).fit(X_train_scaled, y_train)性能注意:?SVM 的訓練時間復雜度通常在 O(n2) 到 O(n3) 之間,不適合超大規模數據集。
2.4 樹與集成:RandomForest?和?Gradient Boosting?實踐
RandomForest?(隨機森林):并行訓練多棵決策樹,引入行采樣和列采樣增加多樣性。
關鍵參數:
n_estimators?(樹的數量,越大越好但計算開銷大),?max_depth?(樹的最大深度,控制復雜度),?max_features?(分裂時考慮的最大特征數,影響多樣性和強度)。優點:不易過擬合(相比單棵樹),對缺失值、異常值、不同量綱特征相對魯棒,提供特征重要性。通常作為優秀基線模型。
GradientBoosting?(梯度提升樹 - GBDT):串行訓練樹,每棵樹學習修正前一棵樹的殘差。
代表庫:
sklearn.ensemble.GradientBoostingClassifier/Regressor,?XGBoost,?LightGBM,?CatBoost。關鍵參數:
n_estimators?(樹的數量),?learning_rate?(學習率,控制每棵樹的貢獻,小學習率需更多樹),?max_depth?(通常較小,如3-6,構建弱學習器)。優點:精度通常高于隨機森林。
缺點:訓練更慢,參數調優更關鍵,對過擬合更敏感(需謹慎控制樹深和學習率)。
代碼如下:
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier# 隨機森林
rf = RandomForestClassifier(n_estimators=100, max_depth=5, max_features='sqrt',random_state=42, n_jobs=-1).fit(X_train, y_train)# 梯度提升樹 (sklearn實現)
gb = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1,max_depth=3, subsample=0.8, # 行采樣random_state=42).fit(X_train, y_train)工業級建議:?對于表格數據,LightGBM?或?XGBoost?通常是精度和效率的最佳平衡。CatBoost?在處理類別特征上有獨特優勢。
三、模型評估:超越簡單準確率,選擇正確的度量
核心原則:?評估指標必須與業務目標一致!盲目使用?accuracy?是常見錯誤。
3.1 分類任務:理解混淆矩陣及其衍生指標
from sklearn.metrics import confusion_matrix, classification_report, roc_auc_score# 預測測試集
y_pred = model.predict(X_test)
y_pred_proba = model.predict_proba(X_test)[:, 1] # 獲取正類的概率# 混淆矩陣
cm = confusion_matrix(y_test, y_pred)
print(cm)# 詳細報告 (Precision, Recall, F1, Support)
print(classification_report(y_test, y_pred))# AUC-ROC (評估模型排序能力,對不平衡數據敏感度較低)
auc = roc_auc_score(y_test, y_pred_proba)
print(f"AUC-ROC: {auc:.4f}")準確率 (
accuracy):?(TP + TN) / Total。僅在各類別樣本均衡時有效。精確率 (
precision):?TP / (TP + FP)。關注預測為正的樣本中有多少是真正的正例。“寧可放過,不可錯殺”。?例如:垃圾郵件檢測(不想把正常郵件誤判為垃圾)。召回率 (
recall?/?sensitivity):?TP / (TP + FN)。關注實際為正的樣本中有多少被正確找出。“寧可錯殺,不可放過”。?例如:疾病篩查(不想漏掉真正的病人)。F1分數 (
F1-score):?2 * (Precision * Recall) / (Precision + Recall)。精確率和召回率的調和平均,綜合兩者考量。AUC-ROC:?繪制真正例率?
TPR?(Recall) 隨假正例率?FPR?(FP / (FP + TN)) 變化的曲線下面積。衡量模型將正樣本排在負樣本前面的能力。值越接近1越好。對類別不平衡相對魯棒,常用于比較不同模型。
3.2 回歸任務:理解誤差的不同視角
均方誤差 (
mean_squared_error,?MSE):?Σ(y_true - y_pred)2 / n。平方項放大大誤差的影響。均方根誤差 (
root_mean_squared_error,?RMSE):?sqrt(MSE)。與目標變量單位相同,更易解釋。平均絕對誤差 (
mean_absolute_error,?MAE):?Σ|y_true - y_pred| / n。對異常值不如?MSE?敏感。決定系數 (
R2 score):?1 - (Σ(y_true - y_pred)2 / Σ(y_true - mean(y_true))2)。模型解釋的方差比例。值越接近1越好,可為負數(表示模型比簡單均值預測還差)。
代碼如下:
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_scoremse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)print(f"RMSE: {rmse:.2f}, MAE: {mae:.2f}, R2: {r2:.4f}")選擇依據:?如果大誤差的成本非常高(如金融預測),優先考慮?RMSE。如果所有誤差同等重要且數據可能有異常值,考慮?MAE。R2?用于衡量模型的整體解釋力。
四、泛化能力保障:交叉驗證與超參數調優
核心目標:?估計模型在未見數據上的性能,找到最優超參數組合,避免過擬合訓練數據。
4.1 交叉驗證:KFold?與?StratifiedKFold
KFold:?標準K折交叉驗證。將數據隨機分割成K個大小相似的互斥子集。依次用其中K-1個子集訓練,剩余1個子集驗證。重復K次,每次使用不同的驗證子集。最終性能取K次驗證的平均。StratifiedKFold:?分類問題強烈推薦!?在分層K折中,每個子集內各類別樣本的比例盡量保持與原始數據集一致。這尤其在類別不平衡時至關重要,確保每折都能代表整體分布。
代碼如下:
from sklearn.model_selection import KFold, StratifiedKFold, cross_val_score# 標準5折交叉驗證 (回歸或不平衡不嚴重的分類)
kf = KFold(n_splits=5, shuffle=True, random_state=42)
scores = cross_val_score(model, X, y, cv=kf, scoring='accuracy')
print(f"CV Accuracy: {scores.mean():.4f} ± {scores.std():.4f}")# 分層5折交叉驗證 (分類,尤其推薦用于不平衡數據)
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
scores = cross_val_score(model, X, y, cv=skf, scoring='f1_macro') # 使用F1宏平均
print(f"Stratified CV F1 Macro: {scores.mean():.4f} ± {scores.std():.4f}")重要提示:?交叉驗證的?fit?過程發生在訓練折疊上,整個交叉驗證循環結束后,通常會在整個訓練集上重新訓練一個最終模型。cross_val_score?主要用于評估模型性能,返回的是驗證折疊上的分數。
4.2 超參數調優:GridSearchCV?與?RandomizedSearchCV
GridSearchCV?(網格搜索):?窮舉指定的所有參數組合。計算開銷大,適用于參數組合空間較小的情況。RandomizedSearchCV?(隨機搜索):?從指定的參數分布中隨機采樣一定數量的組合進行嘗試。效率通常遠高于網格搜索,尤其在高維參數空間時,是更推薦的方法。
代碼如下:
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV
from scipy.stats import randint, uniform# 定義參數網格/分布
param_grid = {'n_estimators': [50, 100, 200],'max_depth': [3, 5, 7, None],'max_features': ['sqrt', 'log2', 0.8]
}
param_dist = {'n_estimators': randint(50, 300), # 均勻整數分布'max_depth': [3, 5, 7, 9, None],'learning_rate': uniform(0.01, 0.3), # 連續均勻分布 [0.01, 0.31)'subsample': [0.6, 0.7, 0.8, 0.9, 1.0]
}# GridSearchCV
grid_search = GridSearchCV(estimator=GradientBoostingClassifier(random_state=42),param_grid=param_grid,cv=5, # 內部交叉驗證折數scoring='neg_mean_squared_error', # 回歸常用n_jobs=-1,verbose=1
)
grid_search.fit(X_train, y_train)
print(f"Best Params (Grid): {grid_search.best_params_}")
print(f"Best MSE: {-grid_search.best_score_:.4f}") # 注意負號# RandomizedSearchCV (通常更高效)
random_search = RandomizedSearchCV(estimator=GradientBoostingClassifier(random_state=42),param_distributions=param_dist,n_iter=50, # 隨機嘗試的組合數cv=5,scoring='accuracy',n_jobs=-1,random_state=42,verbose=1
)
random_search.fit(X_train, y_train)
print(f"Best Params (Random): {random_search.best_params_}")
print(f"Best Accuracy: {random_search.best_score_:.4f}")# 使用找到的最佳參數重新訓練最終模型 (或在search對象中best_estimator_已使用全部訓練數據訓練)
best_model = random_search.best_estimator_關鍵點:
GridSearchCV/RandomizedSearchCV?內部已經包含了交叉驗證。傳入的?
X_train/y_train?會被進一步分割用于內部的訓練和驗證折。搜索結束后,
best_estimator_?是用整個傳入的?X_train/y_train?使用找到的最佳參數重新訓練好的模型,可以直接用于在測試集?X_test?上進行最終評估或部署。選擇?
scoring?指標至關重要,它決定了什么是“最佳”參數組合。使用?sklearn.metrics.SCORERS.keys()?查看所有可用評分指標。
五、構建健壯流程:Pipeline 與 ColumnTransformer
核心價值:?將預處理步驟和模型訓練步驟封裝成一個單一對象 (Pipeline),結合?ColumnTransformer?按列類型應用不同轉換,確保:
所有轉換僅基于訓練數據進行擬合。
避免測試集/新數據泄露。
代碼簡潔、可復用、不易出錯。
方便在交叉驗證/網格搜索中統一應用預處理。
5.1 構建復雜預處理流水線
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer# 定義數值型和分類型特征列名
numeric_features = ['age', 'income', 'credit_score']
categorical_features = ['gender', 'education', 'city']# 為數值型特征創建管道:填充中位數 -> 標準化
numeric_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='median')),('scaler', StandardScaler())
])# 為分類型特征創建管道:填充眾數 -> 獨熱編碼
categorical_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='most_frequent')),('onehot', OneHotEncoder(handle_unknown='ignore', sparse_output=False)) # sparse_output=False 返回數組
])# 使用ColumnTransformer組合不同的轉換器,按特征類型應用
preprocessor = ColumnTransformer(transformers=[('num', numeric_transformer, numeric_features),('cat', categorical_transformer, categorical_features)],remainder='passthrough' # 處理未被指定的列 (例如,保留ID列或手動處理的特征)# 或者 remainder='drop' 丟棄未指定的列
)# 創建包含預處理和最終模型的完整Pipeline
full_pipeline = Pipeline(steps=[('preprocessor', preprocessor),('classifier', RandomForestClassifier(n_estimators=100, random_state=42, n_jobs=-1))
])# 訓練整個流水線 (在preprocessor上自動調用fit_transform,在classifier上調用fit)
full_pipeline.fit(X_train, y_train)# 預測 (在preprocessor上自動調用transform,在classifier上調用predict)
y_pred = full_pipeline.predict(X_test)# 在GridSearchCV/RandomizedSearchCV中使用Pipeline
param_grid = {'classifier__n_estimators': [100, 200],'classifier__max_depth': [5, 10, None],'preprocessor__num__imputer__strategy': ['mean', 'median'], # 訪問嵌套參數# ... 其他參數
}
search = GridSearchCV(full_pipeline, param_grid, cv=5, scoring='accuracy')
search.fit(X_train, y_train)Pipeline 魔法:
使用?
fit?時,流水線依次對每個步驟調用?fit?或?fit_transform,并將輸出傳遞給下一步。使用?
predict?時,流水線依次對每個步驟(除了最后一步)調用?transform,最后一步調用?predict。在?
GridSearchCV/RandomizedSearchCV?中使用?Pipeline?是最佳實踐,能確保交叉驗證的每一折內部,預處理都只基于該折的訓練部分擬合,完全避免了數據泄露風險。
六、特征工程:提升模型性能的利器
雖然?sklearn?提供了強大的基礎轉換器,真正的特征工程往往需要結合領域知識和創造力。
6.1 交互特征與多項式特征
from sklearn.preprocessing import PolynomialFeatures# 創建多項式特征 (例如 degree=2: 1, a, b, a2, ab, b2)
# 通常只應用于數值特征
poly = PolynomialFeatures(degree=2, interaction_only=False, include_bias=False)
X_train_poly = poly.fit_transform(X_train_num)
X_test_poly = poly.transform(X_test_num) # 注意僅在訓練集擬合!# 在Pipeline中集成
numeric_transformer = Pipeline(steps=[('imputer', ...),('scaler', ...),('poly', PolynomialFeatures(degree=2))
])注意:?多項式特征會顯著增加維度,可能導致過擬合和計算負擔。通常結合正則化使用或進行特征選擇。
6.2 分箱 (KBinsDiscretizer) 與特征交叉
from sklearn.preprocessing import KBinsDiscretizer# 將連續年齡分箱成有序類別
age_binner = KBinsDiscretizer(n_bins=5, encode='ordinal', strategy='quantile').fit(X_train[['age']])
X_train['age_bin'] = age_binner.transform(X_train[['age']])
X_test['age_bin'] = age_binner.transform(X_test[['age']])# 特征交叉:結合年齡分箱和城市創建新類別特征
X_train['age_city'] = X_train['age_bin'].astype(str) + '_' + X_train['city']
# 測試集同樣操作 (注意處理訓練集未出現的新組合)6.3 特征選擇
基于模型的特征重要性:?使用?
RandomForest,?GradientBoosting, 或帶L1正則化的線性模型訓練后查看?feature_importances_?或?coef_。單變量統計檢驗:?
SelectKBest,?SelectPercentile?(例如?f_classif,?mutual_info_classif,?f_regression)。遞歸特征消除 (
RFE?/?RFECV):?遞歸地移除最不重要的特征。方差閾值 (
VarianceThreshold):?移除方差極低(幾乎恒定)的特征。
代碼如下:
from sklearn.feature_selection import SelectFromModel, RFECV# 使用RandomForest選擇特征
selector = SelectFromModel(estimator=RandomForestClassifier(n_estimators=100, random_state=42),threshold='median' # 選擇重要性大于中位數的特征
).fit(X_train, y_train)
X_train_selected = selector.transform(X_train)
X_test_selected = selector.transform(X_test)# 遞歸特征消除 (帶交叉驗證)
rfecv = RFECV(estimator=LogisticRegression(max_iter=1000, solver='liblinear'),step=1, # 每次迭代移除的特征數cv=5,scoring='accuracy'
).fit(X_train_scaled, y_train)
X_train_rfecv = rfecv.transform(X_train_scaled)
print(f"Optimal number of features: {rfecv.n_features_}")重要提示:?特征選擇必須作為?Pipeline?中的一個步驟,或者在交叉驗證循環內部進行(例如使用?RFECV),以避免使用測試集信息來選擇特征而導致評估偏差。
七、高級主題與最佳實踐總結
類別特征與樹模型:?現代高效的GBDT實現(如?
LightGBM,?CatBoost)可以直接處理類別特征(內部進行特殊編碼)。通常比手動做?OneHot?更好(避免維度爆炸,保留類別信息)。在?sklearn?的樹模型中,類別特征需要編碼(通常?OrdinalEncoder?或?OneHotEncoder)。類別不平衡處理:
數據層面:?過采樣 (
SMOTE?- 需?imbalanced-learn?庫), 欠采樣。算法層面:?使用帶類別權重 (
class_weight) 的模型(如?LogisticRegression,?SVC,?RandomForestClassifier?- 設置?class_weight='balanced')。評估層面:?使用?
precision,?recall,?F1,?AUC-ROC,?AUC-PR?等指標,而非?accuracy。
可重復性:?始終設置?
random_state!?無論是在數據分割 (train_test_split)、模型 (RandomForest,?SVC(probability=True))、交叉驗證 (KFold)、還是搜索 (GridSearchCV) 中。這是保證結果可復現的關鍵。增量學習:?對于無法一次性加載到內存的超大數據集,使用支持?
partial_fit?的模型(如?SGDClassifier,?SGDRegressor,?PassiveAggressiveClassifier,?MiniBatchKMeans)。模型持久化:?使用?
joblib(通常比?pickle?更高效)保存訓練好的模型(特別是?Pipeline)和必要的轉換器(如?Scaler,?Encoder)。
代碼如下:
import joblib# 保存整個訓練好的Pipeline
joblib.dump(full_pipeline, 'trained_model_pipeline.joblib')# 加載模型進行預測
loaded_pipeline = joblib.load('trained_model_pipeline.joblib')
new_prediction = loaded_pipeline.predict(new_data)理解計算成本:?不同模型和操作(如網格搜索、某些預處理)的計算開銷差異巨大。了解算法的時間/空間復雜度有助于在資源受限時做出選擇(例如,對于大數據集,線性模型或?
SGD?可能比?SVM?或?RandomForest?更可行;RandomizedSearchCV?比?GridSearchCV?更高效)。
結語:
Scikit-learn 的強大不僅在于其豐富的算法實現,更在于其一致的 API 設計 (fit,?transform,?predict) 和構建復雜、健壯機器學習流程的能力 (Pipeline,?ColumnTransformer)。遵循本文強調的原則——嚴防數據泄露、科學評估模型、善用交叉驗證與流水線、理解算法本質與適用場景、根據業務目標選擇評估指標——將使你能夠更專業、更有效地應用?sklearn?解決實際問題。
記住,熟練使用工具只是起點,深刻理解其背后的原理和最佳實踐,才是通往構建可靠、高性能機器學習模型的關鍵。持續實踐,結合領域知識進行特征工程,并始終保持對模型泛化能力的關注,你將在機器學習的應用之路上走得更遠。
 基礎知識點)


)
影響的系統性分析)



![R study notes[1]](http://pic.xiahunao.cn/R study notes[1])










