一、問題描述
原來的日志系統使用的是ES作為底層存儲,后來因為數據量大了之后,出現了寫入存在阻塞和查詢效率變低的問題。后來決定切換到Doris數據庫。
Doris的優勢根據公開資料來看,它在寫入性能、查詢效率和存儲成本上,都優于ES。比如下面這個對比圖:
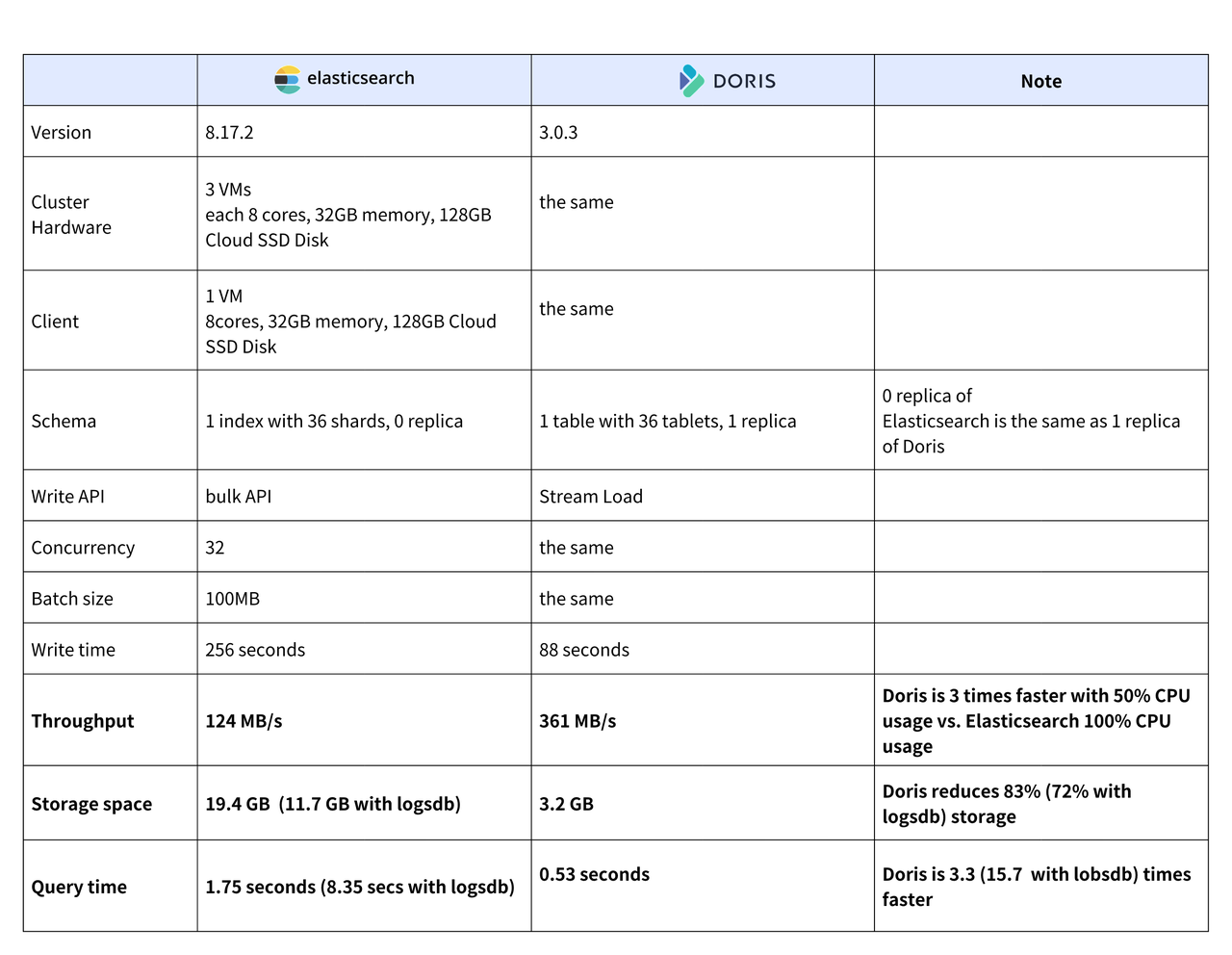
但是真正上了生產環境之后才發現,各有各的坑。
首先我們遇到的問題就是默認情況下對中文日志的檢索效果遠遠不如ES。具體比如說,搜索“預訂下單接口”,搜索結果出來還出現了同時包含“預訂”“下單”“接口”的日志信息,也就是說這一句話被分詞后進行了分別匹配。比如說:
 這個結果也被搜索了出來,這顯然不是我們期望看到的結果。但是在ES上進行同樣搜索的時候就不存在這個問題。
這個結果也被搜索了出來,這顯然不是我們期望看到的結果。但是在ES上進行同樣搜索的時候就不存在這個問題。
二、解決探索
從理論上分析導致這個搜索結果有兩個原因:
- 是入庫階段對文本進行分詞操作的時候,按照較細粒度的中文詞拆分后入的庫;
- 是在檢索的時候是簡單的按照是否包含詞來判斷匹配情況,而沒有按照短語進行匹配。
針對第一個原因的探究,我們首先來看看Doris是如何分詞入庫的。
1.查看Doris官方文檔我們得知,在表創建時,可以通過指定索引的倒排索引屬性值,來對索引的分詞和短語支持進行設置的,官方文檔:倒排索引 - Apache Doris
其中最關鍵的就是parser、support_phrase、parser_mode三個參數。
2.查看我們現有的表結構可以獲知目前我們的表是這么設置這些參數的:
CREATE TABLE `logs` (`alllogs` text NULL COMMENT '日志',INDEX idx_alllogs (`alllogs`) USING INVERTED PROPERTIES("support_phrase" = "false", "char_filter_pattern" = ".,", "parser" = "unicode", "lower_case" = "true", "char_filter_replacement" = " ", "char_filter_type" = "char_replace") COMMENT 'idx_alllogs'
) ENGINE=OLAP ......parser:在這里的用處就是指定索引的分詞器,這里我們原來設置的是unicode。
support_phrase:使用了false,也就是關閉了短語支持。同時parser_mode就沒有必要設置了。
3.我們來看看parser的三個分詞器english、chinese、unicode效果上有什么差異:
SELECT TOKENIZE('預訂下單接口報錯 at com.test.com.CheckOneTwo.doCheck', '"parser"="english"');
--運行結果:["at", "com", "test", "com", "checkonetwo", "docheck"]SELECT TOKENIZE('預訂下單接口報錯 at com.test.com.CheckOneTwo.doCheck', '"parser"="chinese"');
--運行結果:["預訂", "下單", "接口", "報錯", "com", "test", "com", "CheckOneTwo", "doCheck"]SELECT TOKENIZE('預訂下單接口報錯 at com.test.com.CheckOneTwo.doCheck', '"parser"="unicode"');
--運行結果:["預", "訂", "下", "單", "接", "口", "報", "錯", "com.test.com.checkonetwo.docheck"]可以看到三種結果都各有各的問題:english直接忽略了中文,chinese雖然按中文詞的粒度進行拆分但是又把包名進行了單次拆分,而unicode雖然把包名當成了整體但是卻把中文拆成了單個字。
而如果我們在ES中使用IK分詞器它的分詞結果會是:
"預訂","訂下","訂","下單","接口","報錯","com.test.com.checkonetwo.docheck","com","test","com","checkonetwo","docheck"顯然從分詞效果來看IK分詞是最好的,但是遺憾的是Doris目前的版本并不支持IK分詞(Doris官方計劃2025年年內支持)。
僅僅基于目前的條件,parser設置為chinese或者unicode都可以。而對效果影響最大的應該是短語搜索的支持。
4.support_phrase設置為true之后,就支持短語搜索了,具體的修改過程如下:
SHOW INDEX FROM logs;
--查看表大小
SHOW DATA FROM logs;
--查看索引任務
show BUILD INDEX WHERE TableName="logs";--刪除索引
ALTER TABLE logs DROP INDEX idx_alllogs;--嘗試1:改為support_phrase=true, parser=chinese。
ALTER TABLE logs ADD INDEX idx_alllogs(`alllogs`) USING INVERTED PROPERTIES("support_phrase" = "true", "parser" = "chinese", "lower_case" = "true") COMMENT 'idx_alllogs';--嘗試2:改為support_phrase=true, parser=unicode。
ALTER TABLE logs ADD INDEX idx_alllogs(`alllogs`) USING INVERTED PROPERTIES("support_phrase" = "true", "parser" = "unicode", "lower_case" = "true") COMMENT 'idx_alllogs';--重建索引
BUILD INDEX idx_alltext ON logs_message_crs;這里我測試了support_phrase設置為true之后,分別設置chinese和unicode兩個分詞器的索引,觀察了下存儲代價。
logs表在support_phrase設置為false時,表大小3.9G。
改為support_phrase=true、 parser=chinese,表大小變為了8.9G。
改為support_phrase=true 、parser=unicode,表大小變為了8.0G。
可見短語支持讓表空間幾乎大了一倍。根據我們生產環境同樣數據與ES的橫向對比得出一個結論:要Doris實現與ES同樣的中文搜索效果,可能在存儲空間大小上Doris并無優勢。
接下來我們針對上面的第二個原因進行探究,也就是查詢需要使用短語查詢。
查詢的時候有四種查法。
1. LIKE:跟MySQL差不多,如果使用LIKE "%keyword%"進行匹配,大部分時候是用不到索引的,會進行全表掃描,查詢效率極低,所以不推薦。
2.MATCH_ANY:"keyword1 keyword2",多個搜索關鍵字時,只要包含其中任意一個就會命中。值得注意的是如果keyword是多個中文短語,那么會被拆成詞語后進行匹配。比如說“預定信息? 錯誤異常”,會把只包含“預定”的記錄也會匹配出來。也就是這里并沒有用上短語匹配。
3.MATCH_ALL:"keyword1 keyword2",多個搜索關鍵字時,包含全部關鍵字才會命中。同樣值得注意的是是如果keyword是多個中文短語,那么會被拆成詞語后進行匹配。比如說“預定信息? 錯誤異常”,它會把同時包含“預定” “信息” “錯誤” “異常”的匹配出來,是拆分后進行匹配的。同樣也沒有用上短語匹配。
4.MATCH_PHRASE:這個才是我們需要用到的短語匹配的能力。當我們需要MATCH_PHRASE "預定訂單錯誤"時,他會把"預定訂單錯誤"當成一個短語整體進行匹配,而不是拆分成單個詞進行匹配。但是這里又有一個新的問題需要注意,就是多個關鍵詞匹配的問題,如果我們需要搜索同時包含“預定信息? 錯誤異常”的日志,那么使用MATCH_PHRASE "預定信息? 錯誤異常"將無法得到我們想要的結果,因為它會把"預定信息? 錯誤異常"當成一個整體,而不是以空格為切分。那多個關鍵字如何匹配呢,其中一個簡單的辦法就是使用多個MATCH_PHRASE進行匹配,比如說:MATCH_PHRASE "預定信息" AND?MATCH_PHRASE "錯誤異常",這樣就能達到預期的效果。
三、結論
好了,以上就是整個調優和分析的過程,總結一下如何解決Doris的中文檢索效果,有如下幾個關鍵點:
1.打開support_phrase=true,使其索引支持短語檢索。但是要注意這里將會帶來額外的存儲開銷。
2.parser設置為chinese或者unicode,使其支持中文分詞。
3.使用MATCH_PHRASE進行短語匹配。
希望上面的內容對你有所幫助,如果你還遇到其他問題,歡飲留言區討論。
參考材料:為什么 Apache Doris 是比 Elasticsearch 更好的實時分析替代方案?-騰訊云開發者社區-騰訊云
Doris如何做到將查詢性能提升100倍 - 墨天輪
Doris 超全索引實戰教程 - 墨天輪
深入剖析 Doris 倒排索引(上):原理與應用全解析?_doris 分詞器-CSDN博客
倒排索引 - Apache Doris


:擴展與生態系統集成)






之Express)









