簡歷書寫
熟悉C++的封裝、繼承、多態,STL常用容器,熟悉C++11的Lambda表達式、智能指針等,熟悉C++20協程語法,具有良好的編碼習慣與文檔能力。
回答思路
這里是基本上就是要全會,考察的問題也很固定,stl這塊可以定制自己的特色,C++(XX)特性、語法可以根據自己項目里用到的技術去補充。也可不寫
封裝繼承多態問題有很多不一一解釋
這里就寫幾個代表性問題,,基本上大家都會,根本就不需要看攻略。。。
封裝
將具體的實現過程和數據封裝成一個函數,通過接口進行訪問,降低耦合性。
繼承
繼承是什么
繼承其實就是在保持原有類特性的基礎上進行擴展,增加功能。這樣產生的新類叫派生類,而被繼承的類稱基類。其實繼承主要就是類層次上的一個復用。
比如創建了一個動物的類,具有一些屬性,但是呢具體到某類動物又有特有的屬性,比如熊貓冬天愛睡覺,此時我們可以再創建一個熊貓 的類,繼承動物類,復用它的屬于,并且也增加了自己所特有的屬性。
繼承的三種方式
構造函數和析構函數的執行順序
初始化列表概念,為什么用成員初始化列表會快一些
- 注意:對于const成員變量,必須通過初始化列表進行初始化
多重繼承的問題,如何避免?
- 這里面包含菱形繼承問題
多態
多態是什么
多態就是不同繼承類的對象,對同一消息做出不同的響應,基類的指針指向或綁定到派生類的對象,使得基類指針呈現不同的表現方式。在基類函數的前加上virtual關鍵字,在派生類中重寫該函數,運行時將會根據對象的實際類型來調用相應的函數。如果對象類型是派生類,就調用派生類的函數;如果對象類型是基類,就調用基類的函數。
多態的實現方式
虛函數實現(虛函數表,虛函數表指針)
基類的指針是怎么綁定派生類的
其實,如果類包含了虛函數,那么在該類的對象內存中還會額外增加類型的信息,即type_info對象。
然后編輯器會在該虛函數表的開頭插入一個指針,指向當前類對應的type_info對象。
當程序在運行階段獲取類型信息時,可以通過對象指針p找到虛函數表指針vfptr,再通過vfptr指針找到type_info對象的指針,進行得到類型信息。(多態指針類型的轉換)
為什么構造函數不能是虛函數
為什么要把析構函數聲明成虛函數
防止內存泄露
為什么不能把虛函數聲明成inline(內聯)
inline是在編譯器將函數類替換到函數調用處,是靜態編譯的。而虛函數是動態調用的,在編輯器并不知道需要調用的是父類還是子類的虛函數,所以不能夠inline聲明展開,所以編輯器會忽略
為什么(靜態)static成員函數不能為virtual
static成員不屬于任何類對象或類實例,沒有this指針
純虛類概念,以及為什么要有純虛類 (重點)
它沒有實現體(即沒有函數體),只有聲明,被聲明為純虛函數的類被稱為抽象類,不能直接實例化。抽象類中的純虛函數需要在非抽象類中被實現,否則非抽象類也是抽象類。
如果在抽象類的派生類中沒有重新說明純虛函數,則該函數在派生類中仍然為純虛類,而這個派生類仍然是一個抽象類
由于抽象類中至少包含有一個沒有定義功能的純虛函數,因此抽象類只能用作其他類的基類,不能建立抽象類對象
抽象類不能用作參數類型、函數返回類型或 顯示轉換的類型。但可以聲明指向抽象類的指針變量,此指針可以指向它的派生類,進而實現多態
構造函數和析構函數中調用虛函數
其實就是,從語法上講,調用完全沒有問題;但是從效果上看,往往不能 達到需要的目的
比如,一個基類base構造函數和析構函數里調用Function虛函數,另一個繼承這個基類的子類A的構造函數和析構函數里也調用這Function虛函數
然后在主程序中聲明這個基類base指針,然后指向派生類A。這是會顯示Base 類的構造函數中調用 Base 版本的虛函數,A
類的構造函數中調用 A 版本的虛函數;A 類的析構函數中調用 A 版本的虛函數,Base 類的析構函數中調用 Base 版本的虛函數
與預期不符,和普通函數一樣
重載(overload )和重寫(override)的區別還有隱藏是什么
函數重載原理(為什么C語言里面沒有重載)
介紹下STL
回答這種比較大的問題,還是那個套路。能多答就多答,因為你答答的肯定是你會的。如果你簡單說下名字就不說了,那人家面試官就自己問了,假如問道一個自己不會的就掛了。并且面試時間是固定的,你答的越多,問其他問題時間就少。
STL萬能回答模板(先發制人版)
STL知道的挺多的,那我就來簡單從前往后說下
- 首先說說array吧,這最基本的
我們一般用array容器來替代普通數組,因為array模板類中有好多已經寫好的方法很方便編程
- 那接下來就是vector,動態擴容的數組么
vector是動態空間,隨元素加入內部有一個機制會自動擴充空間——具體的他會變成兩倍,當然這個是連續的內存空間放在堆里
那他的這個擴容方法就是:首先重新配置空間,元素移動,釋放舊的內存空間。這里面一旦空間重新配置了則指向原來vector的所有迭代器都失效了,因為vector的地址改變了。所以迭代器是否失效就是看你地址從哪開始改變(比如說:在vector容器中間根據指定迭代器刪除元素,也就是調用erase函數,此時因為當前位置會被后面的元素覆蓋,所以該指定迭代器會失效)
所以這個他的特點就是刪除等于覆蓋,所以復制元素的機制就有點復雜,比如說你如果要是在提前沒有 reserve 足夠的空間,那么vector就會自動重新分配內存,他會將現有元素搬移到新的內存位置std::move (C++11新特性,右值引用,建議了解,在此不專門闡述)使用正確,它應該調用移動構造函數,但如果在某些實現中(例如容器大小調整時),編譯器沒有完全優化,也可能會進行拷貝構造。比如,如果容器在分配新內存后沒有直接采用新內存而是繼續使用舊內存,可能會觸發一些額外的拷貝操作這樣的。
然后說說函數使用方面(那肯定是最常用的訪問、+、-):我們在操作vector的時候不確定的情況下還是用at而不是operator[];因為實際上你at函數就是調用的operator[]函數,只是多了一個檢查是否越界的動作,而operator[]函數是直接跳轉位置訪問元素,所以速度是很快的,從時間復雜度看,是O(1)。還有放元素的時候push_back()會創建這個元素,然后再將這個元素拷貝或者移動到容器中(如果是拷貝的話,事后會自動銷毀先前創建的這個元素);emplace_back()在實現時,則是直接在容器尾部創建這個元素,省去了拷貝或移動元素的過程。clear()和erase(),實際上只是減少了size(),清除了數據,并不會減少capacity,所以內存空間沒有減少。釋放內存空間呢,正確的做法是swap()操作,其實就是讓一個空vector與當前的交換,而這個空vector因為是一個臨時變量,它在這行代碼結束以后,會自動調用vector的析構函數進行釋放,這樣就相當于釋放掉了
內存分配這里常遇到的一個問題是,你vector一個數據量特別大的元素就需要特別的注意:
1.使用 reserve() 預分配內存,避免頻繁擴展。
2.按需加載數據(懶加載)。
3.使用指針或智能指針存儲大對象,避免拷貝。
4.使用內存池、內存映射文件或分塊存儲來管理內存。
5.如果數據存儲在外部文件中,可以考慮壓縮存儲或內存映射文件來提高效率。
#include <sys/mman.h>
#include <fcntl.h>
#include <unistd.h>int main() {int fd = open("large_data.dat", O_RDONLY);size_t fileSize = /* 獲取文件大小 */;void* map = mmap(NULL, fileSize, PROT_READ, MAP_PRIVATE, fd, 0);// 通過 map 訪問文件內容munmap(map, fileSize);close(fd);
}
- 然后說下deque(雙端隊列),這個和數組聯系挺大的就是——用數組管理map[*真正用來存儲數據的各個連續空間]
為啥這么說呢?
1.deque 容器也擅長在序列尾部添加或刪除元素(時間復雜度為O(1)),而不擅長在序列中間添加或刪除元素。
2.deque 容器也可以根據需要修改自身的容量和大小。
但他肯定還是和vector不同,
deque 容器存儲數據的空間是由一段一段等長的連續空間構成,各段空間之間并不一定是連續的,可以位于在內存的不同區域。
deque 容器用數組(數組名假設為 map)存儲著各個連續空間的首地址。所以通過建立 map 數組,deque 容器申請的這些分段的連續空間就能實現“整體連續”的效果。
所以可知不同的是,
1.deque 還擅長在序列頭部添加或刪除元素,所耗費的時間復雜度也為常數階O(1)。
2.并且更重要的一點是,deque 容器中存儲元素并不能保證所有元素都存儲到連續的內存空間中。
如果 map 數組滿了怎么辦?
很簡單,再申請一塊更大的連續空間供 map 數組使用,將原有數據(很多指針)拷貝到新的 map 數組中,然后釋放舊的空間。
迭代器
迭代器內部包含四個指針:cur:指向當前正在遍歷的元素;first:指向當前連續空間的首地址;last:指向當前連續空間的末尾地址;node:它是一個二級指針,用于指向map數組中存儲的指向當前連續空間的指針
- 然后自然就想到了相反的list(又稱雙向鏈表容器)
STL list 容器,即該容器的底層是以雙向鏈表的形式實現的。
這意味著,list 容器中的元素可以分散存儲在內存空間里,而不是必須存儲在一整塊連續的內存空間中
- 之后自然可以延伸出stack因為他一般用list或者deque實現(不用vector的原因是該容量大小有限制,擴容耗時)
用隊列實現棧的方法(來回倒騰)
使用兩個隊列實現棧:模擬入棧用一個隊列1,模擬出棧的時候隊列2用做備份,把隊列1中除隊列中的最后一個元素外的所有元素都備份到隊列2中,然后彈出隊列1的最后的元素,再把元素1從隊列2導回隊列1。
使用一個隊列實現棧(彈出=插入+彈出)
模擬棧彈出元素的時候只要將隊列頭部的元素(除了最后一個元素 )重新添加到隊列尾部,此時再彈出元素的順序就是棧的順序
- 還有Queue(隊列)底層一般用list或deque實現封閉頭部即可,和上面的同理
queue也可以使用list作為底層容器,不具有遍歷功能,沒有迭代器
用棧實現隊列(雙棧法輸入棧+輸出棧)
用兩個棧實現,一個是輸入棧,另一個是輸出棧。添加數據的時候,只要將數據放進輸入棧即可。彈出數據的時候,如果輸出棧為空,則把進棧數據全部導入輸出棧,如果輸出棧不為空,則直接從輸出棧中彈出數據即可
- 最后就是set,map等
- set(集合,沒有鍵值對,只有值)
底層紅黑樹,數值有序,不可重復,值不可修改
查詢效率O(logn),增刪效率O(logn)
- multiset
底層紅黑樹,數值有序,可重復,值不可修改,
查詢效率O(logn),增刪效率O(logn)
- unordered_set
底層哈希表,數值無序,不可重復,值不可修改,
查詢效率O(1),增刪效率O(1)
- map(有鍵值對)
底層紅黑樹,key有序,key不可重復,key不可修改(但是如果插入一個已經存在的鍵,它的值會被更新。不會出錯),值可以重復
查詢效率O(logn),增刪效率O(logn)
當實現“向 map 容器中添加新鍵值對元素”的操作時,insert() 成員方法的執行效率更高;而在實現“更新 map
容器指定鍵值對的值”的操作時,operator[ ] 的效率更高
- multimap
底層紅黑樹,key是有序的,key可重復,key不可修改,值可以重復
查詢效率O(logn),增刪效率O(logn)
- unordered_map
底層哈希表,key是無序的,key不可重復,key不可修改,值可以重復
查詢效率O(1),增刪效率O(1)
用“鏈地址法”(又稱“開鏈法”)(桶中存放一個鏈表)解決數據存儲位置發生沖突的
- 哈希表
每個元素都有一個鍵(key),通過哈希函數將這個鍵映射為一個整數值(哈希值)。
這個哈希值通常是一個數組的索引,數組中的每個位置稱為桶(bucket)。
哈希表中的元素按其鍵值存儲在不同的桶中。
因為哈希值直接定位到桶的位置,所以查找、插入、刪除的時間復雜度平均為 O(1)。
哈希表的一個重要問題是哈希沖突,即不同的鍵通過哈希函數計算得到相同的哈希值。在這種情況下,兩個元素會被存儲到同一個桶中。
鏈地址法(開鏈法)解決了哈希沖突的這個問題。
鏈地址法的核心思想是:當兩個鍵的哈希值相同,直接將它們存儲在同一個桶中,而不是覆蓋前一個鍵值對。
也就是說每個桶中并不是存放一個單獨的元素,而是存放一個鏈表,這個鏈表存儲所有哈希值相同的鍵值對。哈希表的每個桶都是一個鏈表的頭指針。
- unordered_map和哈希
假設有一個 unordered_map 存儲鍵值對:
std::unordered_map<int, std::string> map;
創建桶:unordered_map 初始化時會創建一個數組,這個數組的大小是預先設定的,通常是一個質數。每個數組位置(即桶)是一個指向鏈表的指針。
//插入過程舉例
map[2] = "apple"
hash(2) = 2
2 % 5 = 2
(2, "apple")
map[7] = "banana"
hash(7) = 7
7 % 5 = 2
[(2, "apple"), (7, "banana")]
map[12] = "cherry"
hash(12) = 12
% 5 = 2
[(2, "apple"), (7, "banana"), (12, "cherry")]
- unordered_map和哈希總結
哈希表:unordered_map 底層是一個哈希表,用哈希函數計算鍵的哈希值,并將元素存儲到相應的桶中。
鏈地址法:當不同的鍵通過哈希函數映射到相同的桶時,使用鏈表來存儲這些元素,解決哈希沖突問題。
桶和鏈表:每個桶是一個鏈表的頭指針,所有哈希值相同的鍵值對存儲在同一個桶對應的鏈表中。
效率:由于哈希函數可以直接定位到桶的位置,平均情況下查詢、插入和刪除操作的時間復雜度是 O(1),但最壞情況下,如果所有元素都落在同一個桶中,時間復雜度會退化為 O(n)。
通過這種方法,unordered_map 可以提供高效的查找、插入和刪除操作。
算法
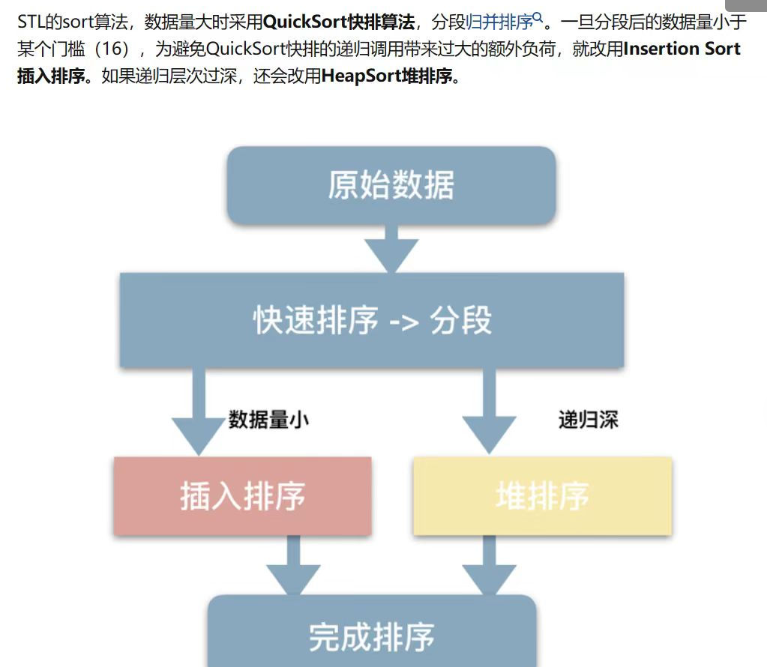
以下截圖均為博主手搓精華版,可能晦澀難懂,需要有一定基礎
四種強制轉換

reinterpret_cast
const_cast
static_cast
dynamic_cast
C++11新特性
智能指針

lambda表達式

下面這些東西了解下即可
在實際工作中,下面的就function用的多一些。
如果非要說
這個時候說下,move,完美轉發,function即可。
右值

移動語義

完美轉發

function

無鎖操作

模板

內存相關
內存分布
全局數據區?
堆區?
自由分配區?
內存泄露概念
沒釋放
常見的內存泄露
new 沒 delete
局部分配未釋放
delete void*
基類析構未定義為虛函數
內存泄漏工具的實現
hook(劫持)malloc 和 free 的底層函數,在里面插入東西
_libc_malloc 和 _libc_free 是底層的內存分配與釋放函數,我們直接調用這兩個函數來實現分配,
__builtin_return_address 函數,你可以獲取調用 malloc 或 free 的位置(代碼段地址),我們把他寫到一個文件里
為每個分配的內存塊創建一個文件,文件名使用內存地址作為文件名,文件內容可以記錄內存分配時的代碼段地址(調用堆棧地址,用 __builtin_return_address )
每次調用 malloc 時,創建一個新的文件;每次調用 free 時,刪除對應的文件。
有文件存在,則表示該內存塊未被釋放,可能存在內存泄漏。我們查看里面的內容就知道是哪個了
可能的問題——printf,malloc死循環
- 由于 printf 本身會使用 malloc 來分配內存,如果你直接在 malloc 中使用 printf,會導致死循環,因為
printf 可能會再次調用 malloc,從而再次進入 malloc 的實現,形成遞歸調用。 - 所以在 malloc 函數中添加一個標識位,控制是否在內存分配時使用 printf。通過標識位來確保在 malloc 中調用 printf
時不會引發遞歸調用。
示例代碼框架
#include <iostream>
#include <cstdio>
#include <cstdlib>
#include <cstring>// 標志位,防止 printf 導致死循環
bool malloc_in_progress = false;void* my_malloc(size_t size) {if (!malloc_in_progress) {malloc_in_progress = true; // 標記 malloc 進行中,防止 printf 進入死循環void* ptr = _libc_malloc(size); // 使用 libc 的底層 malloc 進行內存分配malloc_in_progress = false; // 標記 malloc 完成if (ptr) {// 獲取調用 my_malloc 的函數地址(即調用棧信息)void* return_address = __builtin_return_address(0);// 打開一個以內存地址為文件名的文件FILE* f = fopen(reinterpret_cast<const char*>(&ptr), "w");if (f) {// 在文件中記錄分配內存的信息,包括內存地址和調用的代碼段地址fprintf(f, "Memory allocated at address %p, called from %p\n", ptr, return_address);fclose(f);}}return ptr;}return nullptr; // 防止 printf 內部遞歸
}void my_free(void* ptr) {if (ptr) {// 刪除記錄的文件,表示內存已被釋放remove(reinterpret_cast<const char*>(&ptr)); // 刪除內存地址對應的文件}// 使用 libc 的 _free 進行內存釋放_libc_free(ptr);
}int main() {// 測試內存分配和釋放int* p = (int*)my_malloc(sizeof(int) * 10); // 分配內存if (p) {my_free(p); // 釋放內存}return 0;
}
hook技術
技術介紹
hook技術又叫作鉤子技術,它就是在程序運行的過程中,對其中的某個方法進行重寫;在原有的方法前后加入我們自定義的代碼。相當于在系統沒有調用該函數之前,鉤子程序就先捕獲該消息,可以先得到控制權,這時鉤子函數便可以加工處理(改變)該函數的執行行為。
基于修改sys_call_table的系統調用掛鉤
Linux內核中所有的系統調用都是放在一個叫做sys_call_table的數組中,數組的值就表示這個系統調用服務程序的入口地址
將這個數組中存儲的系統調用的地址改成我們自己的程序地址,就可以實現系統調用劫持(但是這個sys_call_table的內存頁是只讀屬性)
- 步驟
獲得sys_call_table的內存地址
grep sys_call_table /boot/ -r
關閉寫保護
控制頁表只讀屬性是由CR0寄存器的WP位控制的,只要將這個位清零就可以對只讀頁表進行修改
查找虛擬地址所在頁表地址(lookup_address)
設置只讀頁表屬性
- 修改sys_call_table
找到要修改的系統調用的調用號(sys_call_table數組的下標)(cat /usr/include/asm/unistd_64.h )
指針替換就好
- 向linux內核中添加編譯的內核模塊(Linux內核是Linux 5.3.0-40)
Linux內核開發所必需的頭文件(3個init、module、kernel)
模塊的許可證,module_license(查看完整列表)
編寫init(加載)和exit(卸載),定義為靜態的
調用 module_init 和 module_exit 函數告訴內核哪些函數是內核模塊的加載和卸載函數
編寫makefile,make
使用insmd將編譯的才模塊加載進內核進行測試
動態鏈接庫的方法:
主要就是通過動態庫的全局符號介入功能,用自定義的接口來替換掉同名的系統調用接口。由于系統調用接口基本上是由C標準函數庫libc提供的,所以這里要做的事情就是用自定義的動態庫來覆蓋掉libc中的同名符號
- 外掛式
通過優先加自定義載動態庫來實現對后加載的動態庫進行hook,這種hook方式不需要重新編譯代碼
gcc編譯生成可執行文件時會默認鏈接libc庫,所以不需要顯式指定鏈接參數(使用ldd命令查看可執行程序的依賴的共享庫) - 步驟:
在不重新編譯代碼的情況下,用自定義的動態庫來替換可執行程序的系統調用
建立一個c文件,里面設計的函數簽名和libc提供的庫函數一樣(參數返回值之類的),可以用syscall的方式調用對應編號的系統調用,然后再添加幾種內容
將這個.c文件編譯成動態庫(gcc -fPIC -shared hook.c -o libhook.so)
通過設置 LD_PRELOAD環境變量,將libhoook.so設置成優先加載,從面覆蓋掉libc中的庫函數(# LD_PRELOAD=“./libhook.so” ./a.out)
LD_PRELOAD環境變量,在指明在可執行程序運行之前,系統會優先把咱們自定義的動態庫加載到程序的進程空間,使得在可執行程序之前,其全局符號表中就已經有了一個系統調用符號,這樣在后序加載libc共享庫時,由于全局符號介入機制,libc中的write符號不會再被加入全局符號表,所以全局符號表中的系統調用就變成 我們自己實現
- 侵入式
需要改造代碼或是重新編譯一次以指定動態庫加載順序
把改造的系統調用直接放在執行程序中
編譯時,全局符號表里先出現的必然是可執行程序中的
如果不改造代碼,那么可以重新編譯一次,通過編譯參數將自定義的動態庫放在libc之前進行鏈接(gcc main.c -L. -lhook -Wl,-rpath=.)(由于默認情況下gcc總會鏈接一次libc,并且libc的位置也總在命令行所有參數后面,所以只需要像下面這樣操作就可以了)
- 對于全局符號介入機制覆蓋的系統調用接口,如何找回的方法
因為程序運行時,依賴的動態庫無論是先加載還是后加載,最終都會被加載到程序的進程空間中,也就是說,那些因為加載順序靠后而被覆蓋的符號,它們只是被“雪藏”了而已,實際還是存在于程序的進程空間中的,通過一定的辦法,可以把它們再找回來
可以使用Linux中的dslym方法找回被覆蓋的符合
c++中怎么對內存泄露情況檢查?怎么避免內存
gcc asan
hook
valgrind
RALL思想
一般公司有自己獨特的工具
內存泄露造成的不利影響
中止運行
new和malloc的實現原理和區別
brk、mmap、munmap?在哪實現?數據結構?尋找方式?
new的過程(1、2、3)是什么?可被free?
段錯誤(coredump)
是什么?實際發生的情況有哪些?注意事項?
動態庫靜態庫
結尾?
制作流程?
區別?

C++20無棧協程(以下是關于一個企業項目的技術)
線程和協程的區別??
線程是輕量級的進程,是資源調度的最小單位,雖然已經大幅度提高了并發能力,但是線程的切換仍然 有內核態切換的開銷,當線程數量非常多的時候,有可能會適得其反
- 協程是輕量級用戶態的線程,切換不需要經過內核態,由開發者控制切換時機,沒有時間和資源開銷
- 協程可以以同步變成的思維方式,來開發異步編程,降低了異步編程的難度
- 簡單的異步編程我們可以直接在協程中處理,復雜的異步我們可以通過協程調用線程池處理
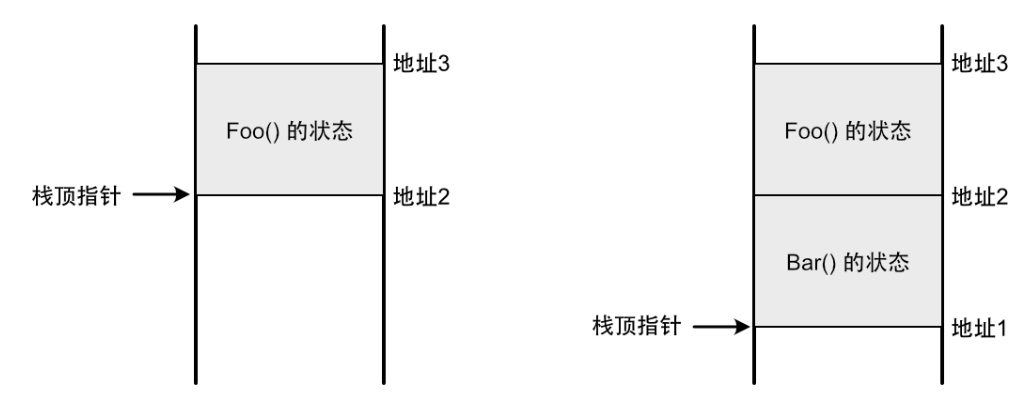
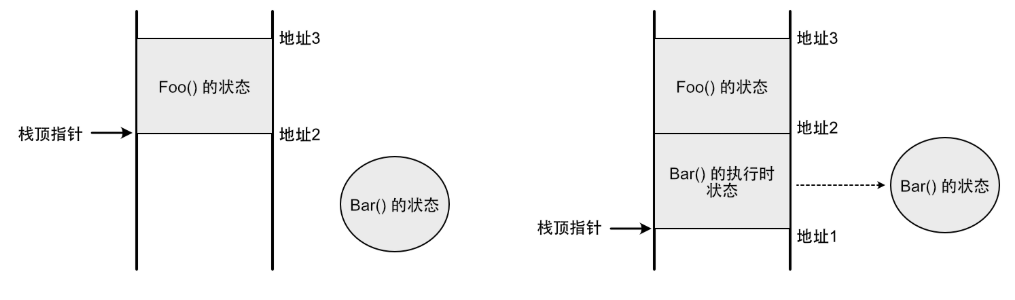
無棧協程是什么?
無棧協程 并非完全不需要棧,而是不需要獨立的調用棧
普通的函數如果等待回調會在棧內維持一個上下文信息,如果回調地獄就會一直占用棧,無棧協程不是,他在堆上維護所有信息,調用的時候從堆里拿出來再去棧運行,必須運行函數肯定是要占用棧空間的,但是一旦不運行就徹底不占,只是有一個指向堆的指針,相當于掛起。
沒有協程的時代
在沒有協程的時代,為了應對 IO 操作,主要有三種模型
- 同步編程:
應用程序等待IO結果(比如等待打開一個大的文件,或者等待遠端服務器的響應),阻
塞當前線程;
優點:符合常規思維,易于理解,邏輯簡單;
缺點:成本高昂,效率太低,其他與IO無關的業務也要等待IO的響應;
- 異步多線程/進程:
將IO操作頻繁的邏輯、或者單純的IO操作獨立到一/多個線程中,業務線程與IO
線程間靠通信/全局變量來共享數據;
優點:充分利用CPU資源,防止阻塞資源
缺點:線程切換代價相對較高,異步邏輯代碼復雜
- 異步消息+回調函數:
設計一個消息循環處理器,接收外部消息(包括系統通知和網絡報文等),
收到消息時調用注冊的回調函數;
優點:充分利用CPU資源,防止阻塞資源
缺點:代碼邏輯復雜
協程出現,解決回調地獄問題
協程是一個函數,它可以暫停以及恢復執行。按照我們對普通函數的理解,函數暫停意味著線程停止運行了(就像命中了斷點一樣),那協程的不同之處在哪里呢?區別在于,普通函數是線程相關的,函數的狀態跟線程緊密關聯;而協程是線程無關的,它的狀態與任何線程都沒有關系。
協程不用維護自己的調用棧,所有的狀態信息存儲在堆中,切換協程只需要保存當前上下文,恢復下一 個協程的上下文即可完成切換
有棧協程的切換需要維護自己的調用棧,支持復雜的調用,偏向于線程。
無棧協程更加的輕量,適合快 速的上下文切換。
- 只要是代碼中出現了三個關鍵字,編譯器自動把這段代碼認為是協程,那就設計到兩個技巧
1.調用到函數,這個函數的內部實現 有協程,結果就是這個函數被直接分離出去,程序繼續往下執行
2.程序繼續往下執行的時候,co_await協程返回的結果,這個函數的所有立即變成協程,等著(這叫嵌套)
協程的喚醒和銷毀有兩種方法,一種是用任務結構體里面的句柄,一種是Awaitable內執行 await_suspend() 后喚醒和直接調用co_return,他標志著會自動銷毀。
c++20協程基礎語法?
在C++中,只要在函數體內出現了 co_await 、co_return 和 co_yield 這三個操作符中的其中一個,這個函數就成為了協程。我們先來關注一下 co_await 操作符。
co_await 和 Awaitable
- co_await
的作用是讓協程暫停下來,等待某個操作完成之后再恢復執行。在上面的協程示例中,我們對 IntReader 調用了 co_await 操作符,目前這是不可行的,因為 IntReader 是我們自定義的類型,編譯器不理解它,不知道它什么時候操作完成,不知道如何獲取操作結果。為了讓編譯器理解我們的類型,C++定義了一個協議規范,只要我們的類型按照這個規范實現好,就可以在 co_await 使用了。
這個規范稱作
- Awaitable
它定義了若干個函數,傳給 co_await 操作符的對象必須實現這些函數。這些函數包括:
- await_ready()
,返回類型是 bool。協程在執行 co_await 的時候,會先調用 await_ready() 來詢問“操作是否已完成”,如果函數返回了 true ,協程就不會暫停,而是繼續往下執行。實現這個函數的原因是,異步調用的時序是不確定的,如果在執行 co_await 之前就已經啟動了異步操作,那么在執行 co_await 的時候異步操作有可能已經完成了,在這種情況下就不需要暫停,通過await_ready()就可以到達到這個目的。
- await_suspend()
,有一個類型為 std::coroutine_handle<> 的參數,返回類型可以是 void 或者 bool 。如果 await_ready() 返回了 false ,意味著協程要暫停,那么緊接著會調用這個函數。該函數的目的是用來接收協程句柄(也就是std::coroutine_handle<> 參數),并在異步操作完成的時候通過這個句柄讓協程恢復執行。協程句柄類似于函數指針,它表示一個協程實例,調用句柄上的對應函數,可以讓這個協程恢復執行。
- await_suspend()
的返回類型一般為 void,但也可以是 bool ,這時候的返回值用來控制協程是否真的要暫停,這里是第二次可以阻止協程暫停的機會。如果該函數返回了 false ,協程就不會暫停(注意返回值的含義跟 await_ready() 是相反的)。
- await_resume()
,返回類型可以是 void ,也可以是其它類型,它的返回值就是 co_await 操作符的返回值。當協程恢復執行,或者不需要暫停的時候,會調用這個函數。
預定義的Awaitable
C++預定義了兩個符合 Awaitable 規范的類型: std::suspend_never 和 std::suspend_always 。顧名思義,這兩個類型分別表示“不暫停”和“要暫停”,實際上它們的區別僅在于 await_ready() 函數的返回值, std::suspend_never 會返回 true,而 std::suspend_always 會返回 false。除此之外,這兩個類型的 await_supsend() 和 await_resume() 函數實現都是空的。
這兩個類型是工具類,用來作為 promise_type 部分函數的返回類型,以控制協程在某些時機是否要暫停。
協程的返回類型和 promise_type
現在我們把關注點聚焦在協程的返回類型上。C++對協程的返回類型只有一個要求:包含名為 promise_type 的內嵌類型。跟上文介紹的 Awaitable 一樣, promise_type 需要符合C++規定的協議規范,也就是要定義幾個特定的函數。 promise_type 是協程的一部分,當協程被調用,在堆上為其狀態分配空間的時候,同時也會在其中創建一個對應的 promise_type 對象。通過在它上面定義的函數,我們可以與協程進行數據交互,以及控制協程的行為。
promise_type 要實現的第一個函數是 get_return_object() ,用來創建協程的返回值。在協程內,我們不需要顯式地創建返回值,這是由編譯器隱式調用 get_return_object() 來創建并返回的。這個關系看起來比較怪異, promise_type 是返回類型的內嵌類型,但編譯器不會直接創建返回值,而是先創建一個 promise_type 對象,再通過這個對象來創建返回值。
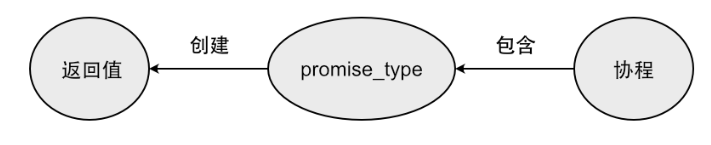
那么協程的返回值有什么用呢?這取決于協程的設計者的意圖,取決于他想要以什么樣的方式來使用協程。例如,某示例中,PrintInt() 這個協程只是輸出一個整數,不需要與調用者有交互,所以它的返回值只是一個空殼。 假如我們想實現一個 GetInt() 協程,它會返回一個整數給調用者,由調用者來輸出結果,那么就需要對協程的返回類型做一些修改了。
c++20怎么實現協程?
總覽
我在項目中實現一個協程,主要分為三個部分
c++20提供三個關鍵字,co_await、co_return、co_yield co_await作用于一個Awaitable對象,用于掛起當前協程。不阻塞當前線程的執行
co_return 提供協程返回的功能,可以返回空或者協程異步執行的結果
co_yield 提供在不結束協程的情況下,多次返回結果
promise_type(協程管理者)
作用:管理協程的生命周期、保存協程的返回值、處理協程內部的異常、確保協程正確結束、控制協程的掛起和恢復
需要定義的函數:
- get_return_object()
返回一個可以操作協程的對象,通常是協程的句柄。
協程執行的結果通過這個對象返回。 - initial_suspend()
定義協程第一次掛起時的行為。這個函數在協程開始時執行
在協程的起始時會暫停,直到被 co_await 等操作喚醒才開始干。 - final_suspend()
定義協程完成時的行為。當協程執行完畢,掛起或銷毀時會調用此函數。
此函數通常確保協程完成時能夠清理資源,或者決定協程是否需要進行最后一次掛起。 - return_value()
用于存儲協程的返回值。
co_return 會將值傳遞到此函數。
他會直接結束協程 - yield_value()
用于存儲協程的返回值。
co_return 會將值傳遞到此函數。
它會使協程暫停,并允許外部控制協程的恢復。 - unhandled_exception()
當協程內部拋出異常時,處理異常的函數。
它負責捕捉協程中的異常并做適當的處理,如中止程序或記錄日志。
co_await(關鍵字,執行到此,協程先被掛起,而不是直接執行)
他比較奇怪的一點就是一般寫什么代碼運行到這里肯定是要進入這個代碼運行的
但是他不是,走到他這里他先被掛起等別人喚醒才能運行
那他等誰呢,等的是可等待(Awaitable) 對象完成
所以他必須有一個可等待(Awaitable) 對象,而這個對象里就和一個結構體一樣必須要定義一些函數
- await_ready()
返回true表示不用掛起,false需要掛起 - await_suspend()
函數內部主要實現需要異步執行的操作,執行完畢后,通過句柄喚醒協程 - await_resume()
協程恢復執行時的操作。
promise_type、co_await 和 Awaitable 之間的關系
promise_type:每個協程都必須有一個 promise_type,它負責管理協程的狀態,包括返回值、異常和掛起操作。promise_type 提供了協程的生命周期管理方法,如 get_return_object()、return_value() 等。
co_await:協程在執行時,可以使用 co_await 等待某個 Awaitable 對象。co_await 會暫停協程并等待該對象的完成,只有該對象完成后,協程才能繼續執行。
Awaitable:這是支持被 co_await 掛起和等待的類型。任何一個類型,只要提供了 await_suspend() 和 await_resume() 方法,就可以作為 Awaitable 類型被 co_await 使用。通常用于處理異步任務,如 I/O 操作。
- 一個例子
#include <iostream>
#include <coroutine>
#include <thread>
#include <chrono>// Awaitable 類型:模擬一個異步操作
struct my_awaitable {bool await_ready() const noexcept {return false; // 返回 false 代表需要掛起}void await_suspend(std::coroutine_handle<> h) noexcept {// 模擬異步操作,2秒后恢復協程std::thread([h]() {std::this_thread::sleep_for(std::chrono::seconds(2));std::cout << "Async operation completed, resuming coroutine...\n";h.resume(); // 恢復協程}).detach();}void await_resume() const noexcept {std::cout << "Resumed from async operation!\n";}
};// 協程的 Promise 類型:管理協程生命周期
struct my_coroutine_promise {int value;my_coroutine_promise() : value(0) {}// 協程啟動時掛起std::suspend_always initial_suspend() {std::cout << "Initial suspend\n";return {}; // 表示協程在開始時掛起}// 協程結束時不再掛起std::suspend_never final_suspend() noexcept {std::cout << "Final suspend\n";return {}; // 協程結束后不再掛起}// 返回值函數:當協程通過 co_return 返回值時調用void return_value(int v) {value = v;std::cout << "Returning value: " << value << std::endl;}// 異常處理函數void unhandled_exception() {std::cout << "Exception occurred in coroutine\n";std::terminate();}// 獲取協程對象:協程的外部代碼可以通過它來控制協程my_coroutine_promise* get_return_object() {return this;}
};// 協程函數:帶有 co_await 的協程
std::coroutine_handle<> my_coroutine() {std::cout << "Coroutine started\n"; // 同步操作co_await my_awaitable(); // 掛起協程,等待異步操作完成std::cout << "Coroutine resumed\n"; // 同步操作co_return 42; // 返回值并結束協程
}int main() {std::cout << "Main thread starts\n";auto handle = my_coroutine(); // 創建協程std::cout << "Coroutine created\n";handle.resume(); // 啟動協程,協程開始執行std::this_thread::sleep_for(std::chrono::seconds(3)); // 等待協程完成std::cout << "Main thread ends\n";return 0;
}
//主程序第一句話的打印
Main thread starts
//到這發現my_coroutine()里面有關鍵字,直接自動創建協程,還有管理他的哪個任務結構體
Coroutine created
//創建了之后第一件事情就是進入到這個結構體的Initial suspend函數,發現是總是掛起,所以不執行任何的操作接著往下走
Initial suspend
//此刻走到了handle.resume(); 通過句柄喚醒了協程,真正進入my_coroutine()函數開始執行,此刻執行的所有代碼都是協程干的,稱其為,異步操作開始之前協程干的事兒
Coroutine started
//執行完異步操作開始之前協程干的事兒,碰到了co_await,于是進入awaitable結構體,執行異步操作
Async operation completed, resuming coroutine...
//執行完,喚醒了協程,協程從co_await后面接著執行,稱之為異步操作開始之后協程干的事兒
Coroutine resumed
// 碰到了 co_return,直接調用管理協程的任務結構體的return_value函數,表示此時協程得到的結果,然后還知道了協程得到這個結果就要被掛掉了,(co_yield是繼續等)
Returning value: 42
//掛掉了進入任務結構體的Final suspend函數,表示掛掉該干的事兒
Final suspend
//主程序最后一句
Main thread ends







和 發布-訂閱模式(Publisher-Subscriber Pattern))




基礎篇(概念與評估))
配合使用的接口)

)


)
