往篇內容:
?C++學習筆記(一)
????????一、C++編譯階段※????????二、入門案例解析?
????????三、命名空間詳解
????????四、C++程序結構
C++學習筆記(二)
????????五、函數基礎
??????? 六、標識符
????????七、數據類型
????????補充:二進制相關的概念
? ? ? ? ? ? ? ? ? sizeof 運算符簡介
????????補充:原碼、反碼和補碼
C++學習筆記(三)
????????補充:ASCII碼表
????????八、內存構成
?????????補充:變量
????????九、指針基礎?
?????? ?十、const關鍵字
????????十一、枚舉類型?
C++學習筆記(四)
????????十二、 類型轉換
????????十三、define指令?
???? ? ?十四、typedef關鍵字
???? ? ?十五、運算符
????????十六、 流程控制
C++學習筆記(六)
? ? ? ? 十七、數組
C++學習筆記(七)
? ? ? ? 十八、指針
目錄
?十九、函數進階
1、內聯函數
2、函數重載?
3、缺省函數
4、遞歸調用
?經典案例1:計算階乘!
案例2:斐波那契數列(Fibonacci Sequence)
案例3:漢諾塔(Tower of Hanoi)
補充:尾遞歸
案例1:尾遞歸階乘
案例2:尾遞歸斐波那契
二十、變量進階
1、作用域
1.1 局部變量
1.2?全局變量?
?2、存儲類型
🧩 2.1?auto
🧩 2.2?register
🧩 2.3?static
①局部靜態變量
?②全局靜態變量
3、鏈接屬性
4、內部函數
?
?十九、函數進階
1、內聯函數
????????在 C++ 中,內聯函數(inline function) 是一種優化機制,用來減少函數調用的開銷。通常情況下,函數調用會有一些運行時開銷:比如參數壓棧、跳轉到函數地址等。
????????為了提高效率,對于一些短小精悍、頻繁調用的函數,我們可以將其聲明為inline ,這樣編譯器就會嘗試將該函數的代碼直接插入到調用處,而不是進行常規的函數調用。
定義格式:
inline 返回類型 函數名(參數列表) {
// 函數體
}
作用與優點:
| 特性 | 描述 |
|---|---|
| ?提升性能 | 避免了函數調用的開銷(如棧操作、跳轉等),適合頻繁調用的小函數 |
| 🔍增強可讀性 | 把常用邏輯封裝成函數,又不會帶來性能損失 |
| 📦代碼復用 | 和普通函數一樣,可以多次調用 |
?與宏函數的區別(#define)
| 對比項 | 宏函數(#define) | 內聯函數(inline) |
|---|---|---|
| 類型檢查 | 無 | 有 |
| 調試支持 | 無(預處理階段替換) | 有(保留函數信息) |
| 運算符優先級問題 | 易出錯 | 安全 |
| 編譯器優化 | 不參與 | 參與 |
| 作用域 | 無 | 有(遵循 C++ 作用域規則) |
結論:在 C++ 中,應盡量避免使用宏函數,改用 inline 函數來替代!?
注意事項:
- 聲明和定義必須在一起,通常在頭文件中定義并實現
- 內聯函數的建議性的,不是強制性的,編譯時函數嵌入
- 內聯函數一般功能簡單,頻繁調用,代碼量5行以內
- 如果函數太復雜(例如包含循環、遞歸、靜態變量等),編譯器可能不會將其內聯
- 如果修改了內聯函數體里面內容,則必須要重新編譯鏈接才可以起作用
應用場景:
- 函數非常簡單(如取絕對值、加減乘除)
- 函數被頻繁調用(如類的 getter/setter 方法)
- 性能敏感區域(如游戲引擎、圖形庫)
2、函數重載?
????????C++中函數重載(Function Overloading) 是指在同一作用域中可以有多個同名函數,但它們的參數列表不同(參數個數或類型不同)。編譯器會根據調用時傳遞的參數來決定調用哪一個函數。
基本語法:
返回類型 函數名(參數列表1) { ... }返回類型 函數名(參數列表2) { ... }...
案例:
#include <iostream>
using namespace std;// 函數重載示例
int add(int a, int b) {return a + b;
}double add(double a, double b) {return a + b;
}int add(int a, int b, int c) {return a + b + c;
}int main() {cout << "add(3, 4) = " << add(3, 4) << endl; // 調用第一個add函數cout << "add(3.5, 4.2) = " << add(3.5, 4.2) << endl; // 調用第二個add函數cout << "add(1, 2, 3) = " << add(1, 2, 3) << endl; // 調用第三個add函數return 0;
} 編譯器判斷函數是否構成重載的因素?
| 判斷標準 | 是否影響重載 |
|---|---|
| 函數名相同 | ? 必須相同 |
| 參數數量不同 | ? 可以重載 |
| 參數類型不同 | ? 可以重載 |
| 參數順序不同 | ? 可以重載(如?void foo(int, double)?vs?void foo(double, int)?) |
| 返回值類型不同 | ? 不可重載 |
返回值類型不同就不可重載嗎?
? ? ? ? 答:是的,僅返回值類型不同不能構成函數重載。函數重載的核心是參數列表必須不同(參數數量、類型或順序不同),而返回值類型不參與重載的判斷。
為什么?
????????因為 C++ 編譯器根據調用時提供的參數來決定調用哪個重載函數,而不是根據返回值類型。例如:
add(3, 4); // 編譯器如何知道該調用 int 還是 double 版本?此時編譯器無法通過返回值類型區分,因此會報錯。
總結
情況 示例 是否重載? 參數列表相同,僅返回值不同 int add(int, int)
double add(int, int)? 不構成重載(編譯錯誤) 參數列表不同,返回值可相同或不同 int add(int, int)
double add(double, double)? 構成重載
?底層機制
函數重載是靜態多態的一種形式,也稱為編譯時多態(后續會討論)。它是由編譯器在編譯階段完成的:
- 編譯器根據函數名和參數列表生成不同的內部符號(name mangling)
- 在鏈接階段,鏈接器會找到正確的函數地址
例如,兩個重載函數:
int add(int a, int b);
double add(double a, double b);
可能被編譯為類似
_add_int_int
_add_double_double
應用場景:
- 功能相似但參數類型或數量不同
- 提供更靈活的接口(如構造函數)
- 類型安全的替代宏函數
- 實現類的多種初始化方式
3、缺省函數
基本語法:?
返回類型 函數名(參數類型 參數名 = 默認值, ...) {
// 函數體
}
案例:
#include<iostream>
using namespace std;void greet(string name="Guest")
{cout<<"Hello,"<<name<<"!"<<endl;
}int main()
{greet();//使用默認參數greet("Alice");//傳遞參數return 0;
}//輸出:Hello,Guest Hello,Alice- 缺省參數必須放在參數列表的最后面
- 也就是說:一旦某個參數有默認值,它后面的所有參數也必須有默認值
//正確寫法
void func(int a, int b = 10, int c = 20);
//錯誤寫法
void func(int a = 5, int b, int c); // 錯誤:a 之后的參數沒有默認值
缺省參數作用域與可見性:
-
缺省參數通常在函數聲明中給出(頭文件中)
-
函數定義中不再重復指定缺省值
-
如果在定義中給缺省值,在聲明中就不應該再給(否則會沖突)
?注意:當函數即作為重載函數,又有默認參數時,注意不要產生二義性。
?錯誤案例:
#include <iostream>
using namespace std;// 函數1:帶缺省參數的版本
void display(int a, int b = 10) {cout << "display(" << a << ", " << b << ")" << endl;
}// 函數2:單參數版本(與函數1沖突)
void display(int a) {cout << "display(" << a << ")" << endl;
}int main() {display(5); // 編譯錯誤:二義性調用return 0;
} - 參數有合理默認值(如緩沖區大小、超時時間等)
- 提高接口可讀性和易用性
- 避免過多函數重載
4、遞歸調用
- 遞歸函數:一個函數在其函數體內調用了自己
- 遞歸終止條件(Base Case):必須存在一個或多個不進行遞歸調用的條件,否則會導致無限遞歸和棧溢出
- 遞歸步驟(Recursive Step):將大問題分解為更小的子問題,并通過遞歸調用來解決這些子問題
基本結構:
返回類型 函數名(參數列表)
{
????????if (滿足終止條件) {
????????????????return 某個值; // 終止遞歸
????????} else {
????????????????// 遞歸調用
????????????????函數名(縮小后的參數);
????????}
}
?經典案例1:計算階乘!
#include <iostream>
using namespace std;
int factorial(int n) {if (n == 0 || n == 1) { // 遞歸終止條件return 1;}return n * factorial(n - 1); // 遞歸調用
}
int main() {int num;cout << "請輸入一個整數:";cin >> num;cout << num << "! = " << factorial(num) << endl;return 0;
}案例2:斐波那契數列(Fibonacci Sequence)
#include <iostream>
using namespace std;int fibonacci(int n) {if (n == 0) return 0;if (n == 1) return 1;return fibonacci(n - 1) + fibonacci(n - 2);
}int main() {int n;cout << "請輸入斐波那契數列的項數:";cin >> n;for (int i = 0; i < n; ++i)cout << fibonacci(i) << " ";cout << endl;return 0;
}案例3:漢諾塔(Tower of Hanoi)
#include <iostream>
using namespace std;/*** 漢諾塔問題解決方案* 將n個盤子從source柱子,借助auxiliary柱子,移動到target柱子* @param n 盤子數量* @param source 源柱子* @param auxiliary 輔助柱子* @param target 目標柱子*/
void hanoi(int n, char source, char auxiliary, char target) {if (n == 1) {cout << "Move disk 1 from " << source << " to " << target << endl;return;}// 步驟1:將n-1個盤子從源柱子移動到輔助柱子hanoi(n - 1, source, target, auxiliary);// 步驟2:將最大的盤子從源柱子移動到目標柱子cout << "Move disk " << n << " from " << source << " to " << target << endl;// 步驟3:將n-1個盤子從輔助柱子移動到目標柱子hanoi(n - 1, auxiliary, source, target);
}int main() {int n;cout << "請輸入漢諾塔的盤子數量:";cin >> n;hanoi(n, 'A', 'B', 'C');return 0;
} 遞歸優缺點
? 優點:
- 代碼簡潔清晰;
- 更符合某些問題的自然邏輯;
- 易于實現復雜的數據結構操作(如樹、圖等);
遞歸優缺點
? 優點:
- 代碼簡潔清晰;
- 更符合某些問題的自然邏輯;
- 易于實現復雜的數據結構操作(如樹、圖等);
補充:尾遞歸
????????如果一個函數的最后一步只是調用自身,而沒有其他需要執行的操作(例如return f(x) 而不是 return x + f(x) ),則稱為 尾遞歸(TailRecursion)。
尾遞歸優勢
- 可以被編譯器優化為循環,避免棧溢出
- 減少內存占用
- 提高性能
案例1:尾遞歸階乘
int factorial(int n, int result = 1) {????????if (n == 0 || n == 1)????????????????return result;????????return factorial(n - 1, n * result); // 尾遞歸????????// f(5) == f(5,1) = f(4,5*1) = f(3,5*4)????????// = f(2,5*4*3) = f(1,5*4*3*2) == 5*4*3*2}
案例2:尾遞歸斐波那契
int fib(int n, int a = 0, int b = 1) {
????????if (n == 0) return a;
????????if (n == 1) return b;
????????return fib(n - 1, b, a + b); // 尾遞歸
}
?2種遞歸對比:
| 特性 | 普通遞歸 | 尾遞歸 |
|---|---|---|
| 是否有未完成的計算 | 是 | 否 |
| 是否可以優化 | 否 | 是 |
| 棧幀是否增長 | 是 | 否 |
| 實現難度 | 簡單 | 稍微復雜 |
| 性能 | 差 | 好 |
?
注意:
- 并非所有遞歸都可以寫成尾遞歸
- 不同編譯器對尾遞歸優化的支持程度不同
- 使用 -O2 或 -O3 編譯選項可以啟用尾遞歸優化
二十、變量進階
1、作用域
- 文件作用域
也稱為全局作用域,在任何函數、類或命名空間之外聲明的變量具有文件作用域
- 塊作用域
變量聲明在一對花括號 {} 內,其作用范圍從定義點開始直到包含它的最內層的塊結束 - 函數原型作用域
指的是函數原型中的參數名的作用域
?void func(int param); // param 在這里是函數原型作用域
- 函數作用域
goto 標簽是唯一具有函數作用域的實體,意味著標簽名稱在整個函數體內都是有效的,
void func() {
????????goto label;
????????label: //標簽可以放置在函數內的任何位置,但必須在函數范圍內使用
????????cout << "Jumped to label" << endl;
}
- 類作用域(Class Scope)
成員變量和函數屬于其類的作用域,后續類和對象再討論!- 命名空間作用域(Namespace Scope)
命名空間內的名字具有命名空間作用域,例如:namespace MySpace {? ? int var = 10;}int main() {? ? cout << MySpace::var << endl; // 使用命名空間限定符訪問變量}
- 命名空間作用域(Namespace Scope)
?
1.1 局部變量
????????在一個函數內部定義的變量是內部變量,它只在本函數范圍內有效。也就是說只有在本函數內才能使用它們,在此函數以外是不能使用這些變量的。
????????同樣,在復合語句中定義的變量只在本復合語句范圍內有效。
上面兩種都稱為局部變量 (local variable)。具體可見下圖:

?注意:函數聲明和函數定義中的形式參數,相互獨立!

1.2?全局變量?
????????在函數內定義的變量是局部變量,而在函數之外定義的變量是外部變量,稱為 全局變量 (global variable,也稱全程變量)。全局變量的有效范圍為從定義變量的位置開始到本源文件結束。

?2、存儲類型
????????在 C++ 中,存儲類型(Storage Class)決定了變量的生命周期、可見性(作用域)以及是否可以被初始化等特性。C++ 中主要有4種存儲類型: auto 、register 、 static 和 extern 。每種存儲類型都有其特定的應用場景和特點。
?存儲類型:存儲變量值的內存類型
?決定了變量的創建時間、銷毀時間、值的生命周期
?普通內存、運行時堆棧、硬件寄存器?存儲類型:
靜態變量:代碼塊之外或則代碼塊內部并用?
static?修飾自動變量:代碼塊內部并且不使用?
static寄存器變量:使用?
register?修飾的自動變量?生命周期并不等同于存儲類型
?初始化
靜態變量有默認初始化值?
0自動變量沒有默認初始化
🧩 2.1?auto
- 默認存儲類型:對于局部變量,默認即為 auto 類型。
- 作用域與生命周期:具有塊作用域(Block Scope),從聲明點開始直到包含它的最內層代碼塊結束;生命周期從進入作用域時開始,離開作用域時結束。
- 使用情況:自 C++11 起, auto 關鍵字更多地用于自動類型推導,而不是傳統的存儲類型指定。
void autoExample() {
auto x = 5; // 自動類型推導,x 是 int 類型
}
🧩 2.2?register
- 意圖優化:建議編譯器將變量存儲在寄存器中以提高訪問速度,但現代編譯器通常會自動進行這種優化,因此很少顯式使用 register
- 寄存器變量:為提高執行效率, C++允許將局部變量的值放在CPU中的寄存器中,需要用時直接從寄存器取出參加運算,不必再到內存中去存取。
- 限制:不能取地址(如 &var ),因為它們可能不在內存中
- 生命周期:與 auto 相同,具有塊作用域
void registerExample() {
????????register int i;
????????// int *p = &i; // 錯誤,不能取地址
}
注意:C++17 已經棄用了 register 關鍵字作為存儲類說明符
?
🧩 2.3?static
①局部靜態變量
在函數內使用 static 修飾變量時,其存儲類型會由棧空間修改為數據區(初始化或未初始化)。它只會在第一次執行到它的初始化語句時初始化一次,并且它的值會保留直到程序結束,即使函數多次被調用也不會重新初始化。
#include <iostream>
using namespace std;int f(int a) {auto b = 0;// 只初始化一次,存儲在初始化數據區,函數幀銷毀,c 不會銷毀static int c = 3; b = b + 1; // 每次調用 b 重新從 0 加 1c = c + 1; // c 靜態變量,值持續累加,依次為 4、5、6 return a + b + c;
}int main() {int a = 2;// 調用 3 次 f 函數for (int i = 0; i < 3; i++) {// 第一次:2 + 1 + 4 = 7// 第二次:2 + 1 + 5 = 8// 第三次:2 + 1 + 6 = 9 cout << f(a) << " "; }cout << endl;return 0;
}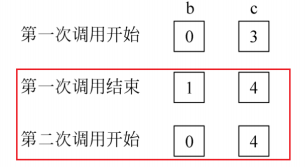
靜態局部變量在靜態存儲區內分配存儲單元,在程序整個運行期間都不釋放;
????????為靜態局部變量賦初值是在編譯時進行值的,即只賦初值一次,在程序運行時它已有初值。以后每次調用函數時不再重新賦初值而只是保留上次函數調用結束時的值;
????????如果靜態局部變量沒有初始化,則編譯時自動賦初值 0(對數值型變量 )或空字符 (對字符型變量);
注意:雖然static修飾局部變量會改變其存儲類型,變量生命周期也發生改變(由所在代碼塊結束就銷毀,變成進程結束才銷毀),但其作用域并不會發生改變!
?②全局靜態變量
????????在程序設計中希望某些外部變量只限于被本文件引用,而不能被其他文件 引用。這時可以在定義外部變量時加一個 static聲明。

總結:

3、鏈接屬性
- 標識符的鏈接屬性(linkage)用于決定如何處理在不同文件中出現的標識符,主要有?
external、internal、none?三種 。
三種鏈接屬性具體說明
-
None(無鏈接屬性):帶有這種鏈接屬性的標識符,總是被當作單獨的個體,各聲明相互獨立,不關聯其他位置的同名標識符 。
-
Internal(內部鏈接屬性):在同一個源文件內,所有對該標識符的聲明都指向同一個實體;但在不同源文件中,同名標識符的聲明會被視為不同實體,相互獨立 。
-
External(外部鏈接屬性):無論標識符被聲明多少次、分布在幾個源文件中,都表示同一個實體,可跨源文件關聯使用 。
- 鏈接屬性:聲明一個變量或函數,告訴編譯器該標識符是在其他地方定義的
- 用途:主要用于多文件編程中,允許在一個文件中引用另一個文件中定義的全局變量或函數
// file1.cpp
int globalVar = 10;// file2.cppextern int globalVar; // 聲明 globalVar 存在于其他文件中
- 函數聲明:通常省略 extern ,因為它是函數聲明的默認存儲類型?
4、內部函數
如果一個函數只能被本文件中其他函數所調用,它稱為內部函數,在定義函數時用 static 修飾。
格式: static 返回值類型 函數名(形參列表); 如: static int fun(int a, int b); 內部函數也稱為靜態(static)函數。
如果在不同的文件中有同名的內部函數,互不干擾。
static關鍵字總結
?static 用于函數定義或則用于代碼塊之外的變量聲明時,static 關鍵字用于修改標識符的鏈接屬性,從 external 修改為 internal。修改標識符的存儲類型和作用域。
static 用于代碼塊內部的變量聲明時,static 用于修改變量的存儲類型,從自動變量修改為靜態變量。變量的鏈接屬性和作用域不受影響。



)

)
![[極客大挑戰 2019]FinalSQL--布爾盲注](http://pic.xiahunao.cn/[極客大挑戰 2019]FinalSQL--布爾盲注)
)

)
)



7.27)


)

