ARM匯編一般無法在PC上直接運行,因為ARM和x86架構是不一樣的。但是很多時候用ARM開發板是很不方便的,所以能不能直接在PC上仿真運行ARM匯編來練習呢?當然可以,那就是:使用QEMU來仿真。
這篇文章我們就來演示下如何在Ubuntu上安裝QEMU并仿真ARM匯編程序(其實windows下也可以,只是比較麻煩,需要的話自行百度即可,這里就不記錄了)
QEMU是啥
QEMU 是一款開源的硬件虛擬化工具,全稱為 "Quick Emulator",它能模擬多種硬件架構的處理器、內存、外設等,讓你在一種硬件平臺上運行為另一種硬件平臺編譯的操作系統或程序。
簡單來說,QEMU 的核心功能是模擬不同的計算機硬件環境,主要用途包括:
跨架構運行程序 比如在 x86 架構的 PC 上,通過 QEMU 模擬 ARM、MIPS 等架構的處理器,直接運行為這些架構編譯的程序(如前面提到的在 x86 Ubuntu 上運行 ARM 匯編程序)。
完整系統仿真 模擬整個計算機系統(包括 CPU、內存、硬盤、網卡等),可以在其中安裝和運行不同的操作系統。例如:
在 Windows 上通過 QEMU 運行 Linux 系統
在 x86 Linux 上模擬 ARM 架構的 Ubuntu 服務器
調試與開發 開發者常用 QEMU 調試底層代碼(如內核、驅動、匯編程序),因為它可以模擬各種硬件場景,且支持調試接口(如 GDB 遠程調試),無需依賴真實硬件。
虛擬化加速 配合 KVM(Linux 內核虛擬化技術)等模塊時,QEMU 可以實現接近原生性能的虛擬化(此時更像傳統虛擬機,而非純軟件模擬)。
QEMU 支持的架構非常廣泛,包括 x86、ARM、RISC-V、PowerPC 等,是嵌入式開發、操作系統研究、跨平臺測試的常用工具。它本身是命令行工具,但可以通過圖形界面前端(如 Virt-Manager)簡化操作。
QEMU是不是就是虛擬機?
QEMU 不完全等同于傳統意義上的 “虛擬機”,但它包含虛擬機的功能,且功能范圍更廣泛。可以說,虛擬機是 QEMU 的一種使用場景,但 QEMU 不止是虛擬機。
具體區別和聯系如下:
QEMU 的兩種核心模式
QEMU 有兩種主要工作模式,其中一種是虛擬機模式,另一種則超越了傳統虛擬機的范疇:
全系統仿真(System Emulation) 這是最接近 “虛擬機” 的模式:QEMU 會模擬一整套硬件系統(CPU、內存、硬盤、網卡、顯卡等),你可以在其中安裝完整的操作系統(如 Linux、Windows),就像使用 VMware、VirtualBox 等虛擬機軟件一樣。 例如,在 x86 電腦上用 QEMU 模擬一臺 ARM 架構的 “虛擬電腦”,并在里面運行 ARM 版的 Ubuntu。
用戶模式仿真(User Mode Emulation) 這種模式不模擬完整系統,只模擬目標架構的 CPU 指令集,讓單個程序在當前系統中直接運行(無需安裝完整 OS)。 例如,在 x86 架構的 Ubuntu 上,通過
qemu-arm命令直接運行一個 ARM 架構的二進制程序(就像前面運行 ARM 匯編程序的例子)。 這是 QEMU 獨有的輕量功能,傳統虛擬機(如 VMware)無法做到。與傳統虛擬機的核心差異
對比維度 QEMU(全系統仿真) 傳統虛擬機(如 VMware、VirtualBox) 核心依賴 純軟件模擬(可配合 KVM 加速) 依賴硬件虛擬化技術(如 Intel VT、AMD-V) 性能 純模擬時性能較低;配合 KVM 后接近原生 接近原生性能 支持架構 極其廣泛(x86、ARM、RISC-V、MIPS 等) 主要支持 x86/x86_64,部分支持 ARM 適用場景 跨架構開發、底層調試、小眾系統 日常多系統運行、服務器虛擬化 總結
QEMU 包含虛擬機功能:在 “全系統仿真” 模式下,它就是一款虛擬機工具,能模擬完整的計算機系統。
QEMU 不止是虛擬機:它的 “用戶模式仿真” 可以輕量地跨架構運行單個程序,且支持更多小眾硬件架構,是開發者調試底層代碼的重要工具。
簡單說,傳統虛擬機更像 “一臺虛擬電腦”,而 QEMU 更像 “一個萬能的硬件模擬器”,虛擬機功能只是它的一部分。
Ubuntu下安裝QEMU
我們直接使用apt來安裝,步驟如下:
首先更新系統軟件包列表,打開終端輸入命令:
sudo apt update。若只需要安裝 QEMU 基本功能,可執行命令:
sudo apt install qemu-system。若希望獲得更完整的虛擬化體驗,例如使用圖形界面管理虛擬機等,則執行命令:
sudo apt install qemu qemu-kvm libvirt-daemon libvirt-clients bridge-utils virt-manager。安裝完成后,可通過運行
qemu-system-x86_64 --version來驗證 QEMU 是否正確安裝,并查看其版本信息。
模擬ARM架構執行ARM匯編?
在 Ubuntu 下使用 QEMU 用戶模式模擬 32 位 ARM 架構執行 ARM 匯編代碼,是一種輕量高效的方案,無需配置完整的系統鏡像。以下是詳細步驟:
一、安裝工具鏈
首先安裝 32 位 ARM 交叉編譯工具和 QEMU 用戶模式模擬器:
# 安裝32位ARM交叉編譯工具鏈(支持ARMv7及以下架構) sudo apt install gcc-arm-linux-gnueabihf binutils-arm-linux-gnueabihf# 安裝QEMU用戶模式模擬器(用于運行32位ARM程序) sudo apt install qemu-user二、編寫 32 位 ARM 匯編代碼
創建一個示例程序(
arm32_demo.s),使用 ARMv7 指令集和 Linux 系統調用:.datamsg: .asciz "Hello, 32-bit ARM Assembly (QEMU User Mode)!\n"len = . - msg @字符串長度.text.global _start _start:@系統調用:write(1, msg, len)mov r0, #1 @r0 = 標準輸出文件描述符(stdout)ldr r1, =msg @r1 = 字符串地址ldr r2, =len @r2 = 字符串長度mov r7, #4 @r7 = write系統調用號(32位ARM Linux約定)swi #0 @觸發軟中斷執行系統調用@系統調用:exit(0)mov r0, #0 @r0 = 退出狀態碼(0表示成功)mov r7, #1 @r7 = exit系統調用號swi #0 @退出程序三、編譯為 32 位 ARM 可執行文件
使用交叉工具鏈將匯編代碼編譯為 32 位 ARM 二進制程序:
# 匯編:將.s文件轉為目標文件(指定ARM架構為armv7) arm-linux-gnueabihf-as -mcpu=armv7-a -o arm32_demo.o arm32_demo.s# 鏈接:生成可執行文件 arm-linux-gnueabihf-ld -o arm32_demo arm32_demo.oarm-linux-gnueabihf-as -mcpu=armv7-a -o arm32_demo.o arm32_demo.s
這一步遇到問題:

Assembler messages:
Error: unknown cpu `armv7-a'
Error: unrecognized option -mcpu=armv7-a
查看下匯編器的版本:
arm-linux-gnueabihf-as --version

查看
arm-linux-gnueabihf-as匯編器支持的架構,可以使用它的幫助選項來列出所有支持的 CPU 和架構:arm-linux-gnueabihf-as --target-help
在輸出結果中,你會看到類似以下的內容(不同版本可能略有差異):
... -mcpu=name select CPU variant (arm1020e, arm1020t, arm1022e, ..., armv7-a, armv7-m, armv7-r, ...) ...其中列出的所有以
armv開頭的選項(如armv7-a、armv8-a等)都是該匯編器支持的 ARM 架構版本。但是我執行后沒有列出來
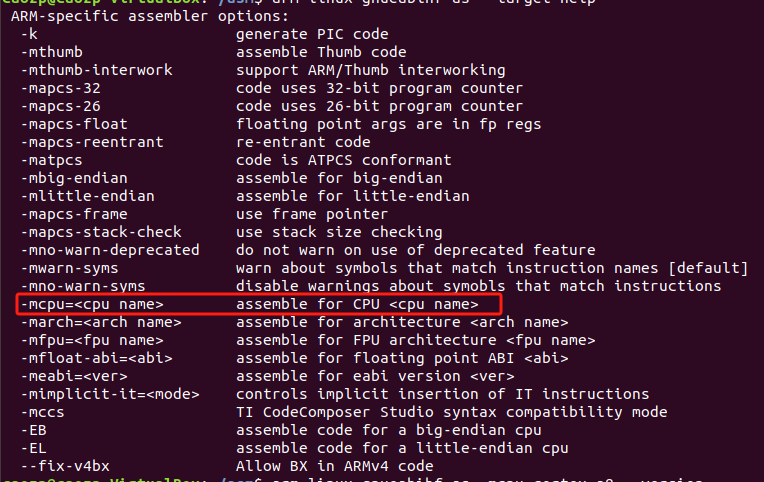
下面有個-march選項,這個才是架構吧,-mcpu需要指定的是CPU型號?
然后試著改下,用-march來指定armv7-a架構
arm-linux-gnueabihf-as -march=armv7-a -o arm32_demo.o arm32_demo.s或者用-mcpu來指定具體的CPU型號比如cortex-a8
arm-linux-gnueabihf-as -mcpu=cortex-a8 -o arm32_demo.o arm32_demo.s在執行之前,我們先測試下看看
arm-linux-gnueabihf-as -march=armv7-a --versionarm-linux-gnueabihf-as -mcpu=cortex-a8 --version如果不報錯的話應該就是對的
在 ARM 工具鏈中,
-mcpu和-march是兩個相關但含義不同的選項,它們的使用場景有明確區別:
-march=<architecture>:指定目標處理器架構(如armv7-a),僅關注指令集架構版本,不涉及具體 CPU 實現細節(如緩存大小、流水線等)。 例如:-march=armv7-a明確指定使用 ARMv7-A 架構的指令集。
-mcpu=<cpu-name>:指定具體的 CPU 型號(如cortex-a9),不僅包含該 CPU 所屬的架構版本,還會啟用該型號特有的硬件特性優化。 例如:-mcpu=cortex-a9會自動隱含-march=armv7-a,同時針對 Cortex-A9 的硬件特性進行優化。關鍵點:
ARM 工具鏈中,
-march確實是指定架構(如armv7-a)的更直接方式,而-mcpu更多用于指定具體 CPU 型號。當使用
-mcpu指定某個屬于armv7-a架構的 CPU 時(如cortex-a8、cortex-a9),工具鏈會自動推斷出對應的-march=armv7-a,無需重復指定。如果你只需要確保代碼兼容
armv7-a架構(不針對特定 CPU 優化),直接使用-march=armv7-a更合適:arm-linux-gnueabihf-as -march=armv7-a -o arm32_demo.o arm32_demo.s如果之前用
-mcpu=armv7-a報錯,可能是因為工具鏈對-mcpu的參數要求更嚴格(必須是具體 CPU 型號),而-march=armv7-a是更標準的架構指定方式,通常能解決這類識別問題。
四、用 QEMU 用戶模式運行
直接通過
qemu-arm模擬 32 位 ARM 環境并執行程序:qemu-arm ./arm32_demo執行后會輸出:
Hello, 32-bit ARM Assembly (QEMU User Mode)!五、擴展:調試 32 位 ARM 程序
若需調試匯編代碼,可結合
gdb-multiarch進行單步調試:# 1. 啟動QEMU并等待GDB連接(監聽1234端口) qemu-arm -g 1234 ./arm32_demo &# 2. 另開終端,啟動多架構GDB gdb-multiarch ./arm32_demo# 3. 在GDB中連接調試端口 (gdb) target remote localhost:1234# 4. 設置斷點(如在_start處) (gdb) b _start# 5. 運行程序 (gdb) c# 6. 單步執行(匯編級) (gdb) si # 執行下一條匯編指令關鍵說明
用戶模式的特點:
QEMU 用戶模式(qemu-arm)僅模擬 32 位 ARM 指令集和系統調用轉換,直接復用宿主 Ubuntu 的文件系統、標準輸入輸出等資源,無需配置內核或根文件系統,啟動速度極快。系統調用兼容性:
32 位 ARM Linux 的系統調用通過r7寄存器傳遞調用號(如write=4、exit=1),QEMU 會自動將這些調用轉換為 x86 Ubuntu 的系統調用,因此程序可直接與宿主系統交互。指令集兼容性:
若需模擬更低版本的 ARM 架構(如 ARMv5),可在編譯時指定-mcpu=arm926ej-s,QEMU 會自動適配對應的指令集模擬。通過以上步驟,可在 x86 架構的 Ubuntu 中快速驗證 32 位 ARM 匯編代碼,適合學習 ARMv7 指令集或開發調試簡單程序。
補充:匯編轉成可執行文件
在上面我們看到,匯編程序轉成可執行程序,用了兩步,即匯編和鏈接,我們知道,C語言可以直接用GCC來一步生成可執行程序,為啥匯編要分成兩步?
匯編程序需要先匯編再鏈接,而 C 語言可以通過
gcc一步生成可執行文件,這是由兩種語言的特性、編譯流程和工具鏈設計決定的,核心原因在于語言抽象層次不同和工具鏈的自動化封裝:匯編語言:直接映射機器碼,與硬件強綁定
匯編指令是機器碼的 “人類可讀形式”,一條匯編指令通常對應一條機器碼(或少數幾條),直接操作寄存器、內存地址和硬件接口。
- 匯編器(如
as)的工作是將匯編指令翻譯成機器碼(生成目標文件.o),但不處理跨文件符號引用(如調用其他文件的函數)、內存地址分配等復雜邏輯。- 例如,匯編中調用外部函數
func時,只能生成一個 “待填充” 的跳轉地址,具體地址需要鏈接器在整合所有目標文件后確定。C 語言:高級抽象,依賴復雜的編譯流程
C 語言通過變量、函數、控制結構等抽象屏蔽了硬件細節,編譯器需要完成:
這些步驟被
gcc等工具鏈自動化封裝,用戶只需執行gcc main.c -o main,工具鏈會自動完成上述所有流程。
- 預處理(展開宏、頭文件)
- 編譯(將 C 代碼翻譯成匯編代碼)
- 匯編(將匯編代碼翻譯成機器碼,生成目標文件)
- 鏈接(整合所有目標文件和庫,處理符號引用,分配最終內存地址)
gcc等 C 語言編譯器并非 “直接編譯” 生成可執行文件,而是自動串聯了預處理、編譯、匯編、鏈接四個步驟。例如:gcc main.c -o main實際執行的流程是:
cpp main.c > main.i(預處理,生成.i 文件)cc1 main.i -o main.s(編譯,生成匯編代碼.s 文件)as main.s -o main.o(匯編,生成目標文件.o)ld main.o -lc -o main(鏈接,整合目標文件和 C 標準庫,生成可執行文件)用戶看不到中間步驟,是因為工具鏈將其封裝為 “一步命令”,而匯編程序通常需要手動執行 “匯編→鏈接” 以更靈活地控制過程(如指定鏈接腳本、庫路徑等)。
簡言之,匯編語言更貼近硬件,流程拆分更細以保留靈活性;C 語言通過工具鏈自動化隱藏了復雜步驟,降低了使用門檻,但本質上仍遵循 “編譯→匯編→鏈接” 的底層邏輯。

)




機器學習(2)-day29)



 配置指南)







![[spring6: @EnableWebSocket]-源碼解析](http://pic.xiahunao.cn/[spring6: @EnableWebSocket]-源碼解析)
