????????ConvMixer 是一個簡潔的視覺模型,僅使用標準的卷積層,達到與基于自注意力機制的視覺 Transformer(ViT)相似的性能,由此證明純卷積架構依然很強大。
核心原理:極簡的卷積設計:
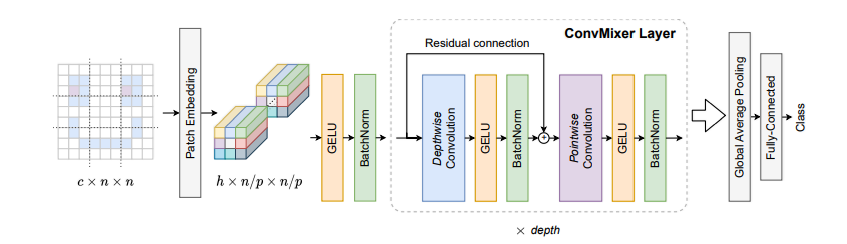
????????它摒棄了復雜的自注意力模塊,只依賴于兩種基礎的卷積操作:深度卷積(Depthwise Convolution) 和逐點卷積(Pointwise Convolution)。
? ? ? ?制作一杯混合果汁。我們不會把整個水果直接扔進攪拌機,而是先切成小塊(分塊)。然后,攪拌機有兩個關鍵動作:第一,刀片高速旋轉,讓每種水果塊自己先碎掉(空間混合);第二,整個杯子里的碎塊因為攪動而互相融合在一起(通道混合)。
????????ConvMixer 的設計與此相似。它認為,復雜的圖像特征提取,可以被分解為這兩個最基本、最核心的“攪拌”動作,而不需要像 Vision Transformer 那樣引入復雜的自注意力機制。
我們來一步步看這個模型是如何工作的。
1. 分塊嵌入 (Patch Embedding):
傳統卷積的起點:
????????傳統的卷積網絡(如 VGG)通常在開頭使用小的卷積核(比如 3x3),步長為1或2。這意味著網絡一開始的視野非常小,它是在逐個像素地、非常局部地觀察圖像。它需要堆疊很多層,才能慢慢地將局部信息組合起來,形成對一個更大區域的理解。
ConvMixer 的革新:
ConvMixer 借鑒了 Vision Transformer (ViT) 的一個核心思想:不要一開始就糾結于像素細節,而是直接把圖像切成一塊塊(Patches),把每一塊作為一個基本處理單元。
它如何用卷積實現這一點呢?請看代碼:
nn.Conv2d(in_channels=3, out_channels=dim, kernel_size=7, stride=7)
#當卷積核的大小和移動步長相同時,效果就是卷積核在圖像上進行不重疊的滑動。
#每滑動一次,這個 7x7 的卷積核就完整地覆蓋了一個 7x7 的圖像塊(Patch)。
#它將這個塊內的所有像素信息(3個通道的 7x7=49 個像素)進行一次計算,然后“壓縮”成 dim 個通道的 一個 像素點。這一步的意義:
降維與提煉:瞬間將高分辨率的圖像(如 224x224x3)轉換成一個低分辨率的特征圖(如 32x32x768)。這大大減少了后續計算量。
視角轉變:強迫模型從一開始就從一個“區域”(Patch)的層面去理解圖像,而不是從單個像素。這與人類的視覺習慣更相似,我們看一張圖也是先看整體布局和各個區域,再看細節。
信息嵌入:
out_channels=dim這個參數(例如dim=768)意味著每個圖像塊被轉換成了一個包含 768 個特征的向量。這個過程被稱為“嵌入”(Embedding),它將原始的像素信息轉化成了更利于模型處理的、高維的抽象特征
2. ConvMixer 層:
????????這是模型的核心,它由 深度卷積 (Depthwise Convolution) 和 逐點卷積 (Pointwise Convolution) 構成。這種組合也被稱為 深度可分離卷積 (Depthwise Separable Convolution),是 MobileNet 等輕量級網絡的基石。
深度卷積 (Depthwise Conv):空間混合
????????經過分塊嵌入后,我們得到了一個 dim 通道(比如 768 個通道)的特征圖。每個通道都可以看作是圖像在某個特定方面的特征表達(比如某個通道可能對輪廓敏感,另一個對紋理敏感)。一個 9x9 的普通卷積核,在計算輸出特征圖的一個點時,會同時查看輸入特征圖上 9x9 區域內的 所有 768 個通道的信息,然后把它們加權求和。這是“空間混合”和“通道混合”同時進行的,計算開銷巨大。
深度卷積卻將這兩個過程分離開。深度卷積只負責空間混合。
具體過程:
一個通道,一個專屬卷積核:如果輸入有 C 個通道,深度卷積就會使用 C 個扁平的(2D)卷積核(例如 3x3x1)。
獨立工作:第1個卷積核只負責在第1個輸入通道上滑動,第2個卷積核只負責第2個通道……以此類推。
保持通道數:處理完成后,輸出的通道數仍然是 C。它只在每個通道內部進行了空間特征提取,但通道之間還是完全隔離的。
核心目的:用極低的計算成本,在每個特征通道內部有效地捕捉空間模式。
逐點卷積 (Pointwise Convolution):通道混合:
????????深度卷積完成了空間特征整理,但留下了致命問題:通道之間完全沒有信息交流。這就像一個公司里,銷售、技術、市場三個部門都各自完成了自己的KPI,但他們之間從不開會,公司無法形成合力。逐點卷積就是來主持這場“跨部門會議”的。它只專注于第二步:通道混合。它的工作方式非常簡單,就是一次 1x1 的卷積。
????????
具體過程:
微型卷積核:它的卷積核大小是 1x1。這意味著它在空間上看的范圍只有一個像素點,所以它完全不做空間混合。
貫穿所有通道:這個 1x1 的卷積核是立體的(例如 1x1xC,C是深度卷積的輸出通道數,;比如768個通道)。在特征圖的每一個像素點上,它都會同時考慮所有 768個通道的值,然后進行加權求和,輸出一個新值。
重組特征:通過使用 N 個這樣的 1x1xC 卷積核,它就可以將輸入的 C 個通道的信息,重新組合成 N 個全新的、更有意義的特征通道。
核心目的:在不同通道之間建立聯系,讓模型學習如何將從不同通道提取出的空間特征(比如“有筆直的輪廓”、“有紅色的紋理”)組合成更高級的概念(比如“這是一支筆”)。
當 深度卷積 和 逐點卷積 按順序組合在一起時,就構成了大名鼎鼎的 深度可分離卷積。
流程:輸入 -> 深度卷積 (空間混合) -> 逐點卷積 (通道混合) -> 輸出
這個結構可以成功的原因來自于它背后的假設:空間相關性(一個區域內的像素關系)和通道相關性(不同特征之間的關系)是可以被分開處理的,事實證明,這種解耦思想很成功。
3. 數據參數對比:
假設我們有如下任務:
輸入特征圖: 16x16x256 (高 x 寬 x 通道數)
輸出特征圖: 16x16x512
卷積核大小: 3x3
方案一:標準卷積
需要
512個3x3x256的立體卷積核。總參數量 = 3×3×256×512=1,179,648
方案二:深度可分離卷積
深度卷積 (空間混合):
需要
256個3x3x1的扁平卷積核。參數量 = 3×3×256=2,304
得到一個
16x16x256的中間特征圖。
逐點卷積 (通道混合):
需要
512個1x1x256的卷積核,將256通道變為512通道。參數量 = 1×1×256×512=131,072
總參數量 = 2,304+131,072=133,376
結果對比: 標準卷積需要約 118 萬 參數,而深度可分離卷積只需要約 13 萬 參數,參數量減少到了原來的 11% 左右!
這就是為什么深度可分離卷積成為了 MobileNet、Xception、ConvMixer 等高效模型的基石。它用極低的成本,實現了與標準卷積非常接近的特征提取能力。
4. Pytorch代碼逐行講解實現:
我們回顧一下結構:
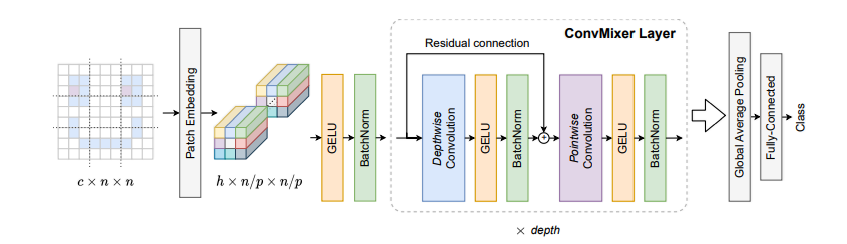
1. 核心組件:ConvMixerLayer
我們先構建模型最小、也是最核心的重復單元——ConvMixerLayer。它包含了我們詳細討論過的 深度卷積、逐點卷積 和 殘差連接。
????????
import torch
import torch.nn as nnclass ConvMixerLayer(nn.Module):"""ConvMixer 的核心重復層。包含一個深度卷積和一個逐點卷積,并通過殘差連接。"""def __init__(self, dim, kernel_size=9):# 初始化 PyTorch 模塊super().__init__()# --- 定義層的各個組件 ---# 1. 深度卷積 (Depthwise Convolution)# 負責在每個通道內部進行空間信息混合。self.depthwise_conv = nn.Conv2d(dim, # 輸入通道數。dim, # 輸出通道數與輸入相同。kernel_size=kernel_size, # 使用一個較大的卷積核(如9x9)來獲取大感受野。groups=dim, # 分組數=通道數,這是實現“深度卷積”的關鍵技巧。padding="same" # 'same' 填充可以確保卷積后特征圖的高和寬不變。)# 2. 激活函數 (Activation)# 為模型引入非線性,GELU 是 Transformer 中常用激活函數。self.activation = nn.GELU()# 3. 批歸一化 (Batch Normalization)# 在網絡層之間穩定和加速訓練。self.norm = nn.BatchNorm2d(dim)# 4. 逐點卷積 (Pointwise Convolution)# 負責在通道之間混合信息,它本質上就是一個 1x1 的標準卷積。self.pointwise_conv = nn.Conv2d(dim, # 輸入通道數。dim, # 輸出通道數。kernel_size=1 # **核大小為1x1,是實現“逐點卷積”的關鍵**。)def forward(self, x):# 定義數據如何“流過”這個層 (前向傳播)# 輸入 x 的維度: [批次大小, 通道數, 高, 寬]# 1. 保存原始輸入,用于最后的殘差連接residual = x# 2. 應用第一個處理塊:深度卷積 -> 激活 -> 歸一化x = self.depthwise_conv(x)x = self.activation(x)x = self.norm(x)# 3. 應用第二個處理塊:逐點卷積 -> 激活 -> 歸一化x = self.pointwise_conv(x)x = self.activation(x)x = self.norm(x)# 4. 完成殘差連接return x + residual2. 整體架構:ConvMixer 模型
現在,我們把 ConvMixerLayer 堆疊起來,并加上開頭的“分塊嵌入”和結尾的“分類頭”,構成完整的 ConvMixer 模型。
class ConvMixer(nn.Module):"""完整的 ConvMixer 模型架構。"""def __init__(self, dim, depth, kernel_size=9, patch_size=7, num_classes=1000):super().__init__()# --- 1. 分塊嵌入 (Patch Embedding) ---# 使用一個卷積層同時實現圖像分塊和特征嵌入。self.patch_embedding = nn.Sequential(nn.Conv2d(3, # 輸入是RGB圖像,所以有3個通道。dim, # 輸出通道數,即我們想要的嵌入維度。kernel_size=patch_size, # 卷積核大小等于塊大小。stride=patch_size # 步長等于核大小,確保分塊不重疊。),nn.GELU(), # 同樣使用 GELU 激活函數。nn.BatchNorm2d(dim) # 批歸一化。)# --- 2. 堆疊 ConvMixer 層 ---self.mixer_layers = nn.Sequential(*[ConvMixerLayer(dim=dim, kernel_size=kernel_size) for _ in range(depth)])# --- 3. 分類頭 (Classification Head) ---# a. 全局平均池化# 將每個通道的 HxW 特征圖壓縮成一個 1x1 的值。self.global_avg_pool = nn.AdaptiveAvgPool2d((1, 1))# b. 全連接層 (分類器)# 將池化后的向量映射到最終的類別數量上。self.classifier = nn.Linear(dim, num_classes)def forward(self, x):# 定義數據在整個模型中的流動路徑# 初始輸入 x 維度: [批次大小, 3, 224, 224] (以ImageNet為例)# 1. 應用分塊嵌入# x 維度變為 -> [批次大小, dim, 32, 32] (224 / 7 = 32)x = self.patch_embedding(x)# 2. 通過所有 ConvMixer 層# 維度保持不變 -> [批次大小, dim, 32, 32]x = self.mixer_layers(x)# 3. 應用全局平均池化# x 維度變為 -> [批次大小, dim, 1, 1]x = self.global_avg_pool(x)# 4. 展平張量以適應全連接層# `torch.flatten(x, 1)` 會將從第1個維度(通道維)開始的所有維度拍平。# x 維度變為 -> [批次大小, dim]x = torch.flatten(x, 1)# 5. 通過分類器得到最終輸出# x 維度變為 -> [批次大小, num_classes]return self.classifier(x)3. 實例化與測試?
最后,讓我們創建模型的一個實例,并用一個假的圖像數據來測試它,看看整個流程是否能跑通。
# --- 實例化一個 ConvMixer-1536/20 模型 ---
# 這是論文中提出的一個高性能版本配置
# dim=1536, depth=20, kernel_size=9, patch_size=7
model = ConvMixer(dim=1536,depth=20,kernel_size=9,patch_size=7,num_classes=1000 # ImageNet 數據集的類別數
)# 打印模型結構,可以清晰地看到我們定義的每一層
# print(model)# --- 創建一個假的輸入圖像張量進行測試 ---
# 模擬一個批次包含4張 224x224 的3通道彩色圖像
dummy_images = torch.randn(4, 3, 224, 224)# 將假圖像輸入模型,得到輸出
output = model(dummy_images)# 打印輸出張量的形狀
# 預期輸出: torch.Size([4, 1000]),代表每張圖片都得到了1000個類別的得分
print(f"輸入張量形狀: {dummy_images.shape}")
print(f"輸出張量形狀: {output.shape}")OK,結束,希望可以幫助大家學會這個輕量化模型。


![[spring6: @EnableWebSocket]-源碼解析](http://pic.xiahunao.cn/[spring6: @EnableWebSocket]-源碼解析)







)






)

