
【作者主頁】Francek Chen
【專欄介紹】???智能大數據分析??? 智能大數據分析是指利用先進的技術和算法對大規模數據進行深入分析和挖掘,以提取有價值的信息和洞察。它結合了大數據技術、人工智能(AI)、機器學習(ML)和數據挖掘等多種方法,旨在通過自動化的方式分析復雜數據集,發現潛在的價值和關聯性,實現數據的自動化處理和分析,從而支持決策和優化業務流程。與傳統的人工分析相比,智能大數據分析具有自動化、深度挖掘、實時性和可視化等特點。智能大數據分析廣泛應用于各個領域,包括金融服務、醫療健康、零售、市場營銷等,幫助企業做出更為精準的決策,提升競爭力。
【GitCode】專欄資源保存在我的GitCode倉庫:https://gitcode.com/Morse_Chen/Intelligent_bigdata_analysis。
文章目錄
- 一、實驗目的
- 二、實驗要求
- 三、實驗原理
- (一)Spark 簡介
- (二)Spark 適用場景
- 四、實驗環境
- 五、實驗內容和步驟
- (一)部署 HDFS
- (二)配置 Spark 集群
- (三)配置 HDFS
- (四)提交 Spark 任務
- 六、實驗結果
- 七、實驗心得
一、實驗目的
能夠理解 Spark 存在的原因,了解 Spark 的生態圈,理解 Spark 體系架構并理解 Spark 計算模型。學會部署 Spark 集群并啟動 Spark 集群,能夠配置 Spark 集群使用 HDFS。
二、實驗要求
要求實驗結束時,每位學生均已構建出以 Spark 集群:master 上部署主服務 Master;slave1、2 上部署從服務 Worker;待集群搭建好后,還需在 master 上進行下述操作:提交并運行 Spark 示例代碼 WordCount,將 master 上某文件上傳至 HDFS 里剛才新建的目錄。
三、實驗原理
(一)Spark 簡介
Spark 是一個高速的通用型集群計算框架,其內部內嵌了一個用于執行 DAG(有向無環圖)的工作流引擎,能夠將 DAG 類型的 Spark- App 拆分成 Task 序列并在底層框架上運行。在程序接口層,Spark 為當前主流語言都提供了編程接口,如用戶可以使用 Scala、Java、Python、R 等高級語言直接編寫 Spark-App。此外,在核心層之上,Spark 還提供了諸如 SQL、Mllib、GraphX、Streaming 等專用組件,這些組件內置了大量專用算法,充分利用這些組件,能夠大大加快 Spark-App 開發進度。
一般稱 Spark Core 為 Spark,Spark Core 處于存儲層和高層組建層之間,定位為計算引擎,核心功能是并行化執行用戶提交的 DAG 型 Spark-App。目前,Spark 生態圈主要包括 Spark Core 和基于 Spark Core 的獨立組件(SQL、Streaming、Mllib 和 Graphx)。
(二)Spark 適用場景
(1)Spark 是基于內存的迭代計算框架,適用于需要多次操作特定數據集的應用場合。
(2)由于 RDD 的特性,Spark 不適用那種異步細粒度更新狀態的應用,例如 web 服務的存儲或者是增量的 web 爬蟲和索引。
(3)數據量不是特別大,但是要求實時統計分析需求。
四、實驗環境
- 云創大數據實驗平臺:

- Java 版本:jdk1.7.0_79
- Hadoop 版本:hadoop-2.7.1
- Spark 版本:spark-1.6.0
五、實驗內容和步驟
(一)部署 HDFS
1、配置各節點之間的免密登錄,具體步驟參考:【大數據技術基礎 | 實驗一】配置SSH免密登錄
2、因為下面實驗涉及 Spark 集群使用 HDFS,所以按照之前的實驗預先部署好 HDFS。具體部署 HDFS 的步驟參考:【大數據技術基礎 | 實驗三】HDFS實驗:部署HDFS
3、驗證HDFS啟動成功:分別在 master、slave1~2 三臺機器上執行如下命令,查看 HDFS 服務是否已啟動。
jps
若啟動成功,在master上會看到類似的如下信息:

而在slave1、slave2上會看到類似的如下信息:


(二)配置 Spark 集群
1、在 master 機上操作:確定存在 spark。
ls /usr/cstor

2、在 master 機上操作:進入/usr/cstor目錄中。進入配置文件目錄/usr/cstor/spark/conf, 先拷貝并修改slave.templae為slaves。
cd /usr/cstor/spark/conf
cp slaves.template slaves

然后用 vim 命令編輯器編輯slaves文件
vim slaves
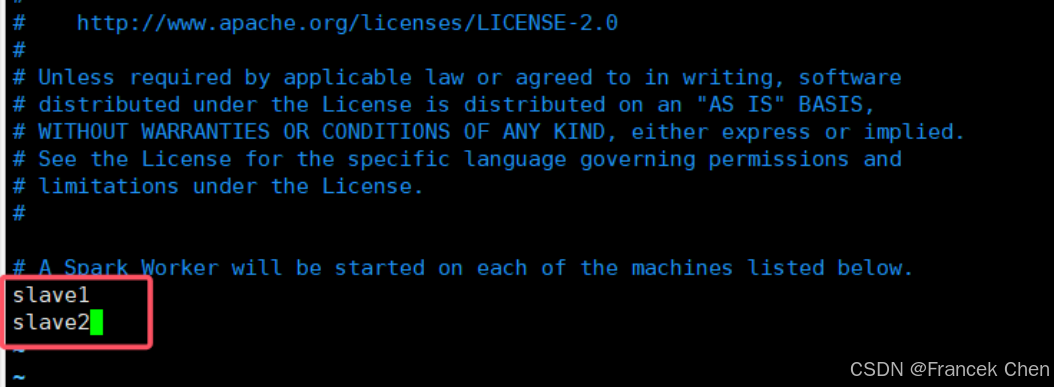
上述內容表示當前的 Spark 集群共有兩臺 slave 機,這兩臺機器的機器名稱分別是 slave1~2。
3、在spark-config.sh中加入JAVA_HOME。

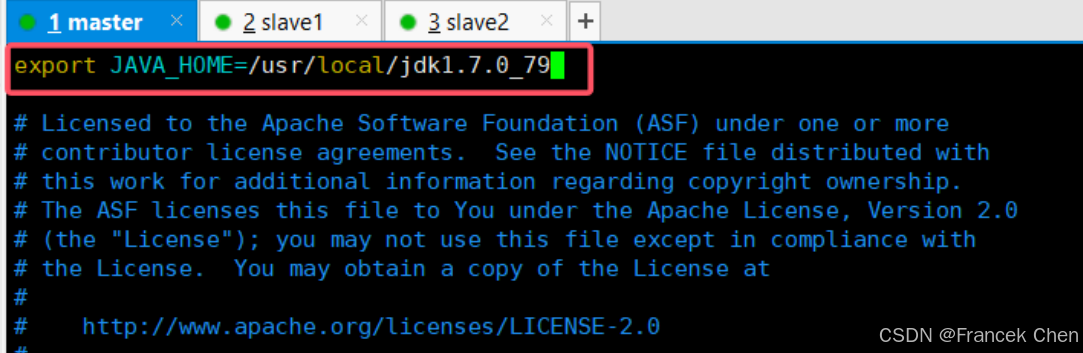
vim /usr/cstor/spark/sbin/spark-config.sh
加入以下內容:export JAVA_HOME=/usr/local/servers/jdk1.7.0_79
4、將配置好的 Spark 拷貝至 slave1~2。使用 for 循環語句完成多機拷貝。
cd /root/data/2
cat machines
for x in `cat /root/data/2/machines` ; do echo $x ; scp -r /usr/cstor/spark/ $x:/usr/cstor/; done;
5、在 master 機上操作:啟動 Spark 集群。
/usr/cstor/spark/sbin/start-all.sh

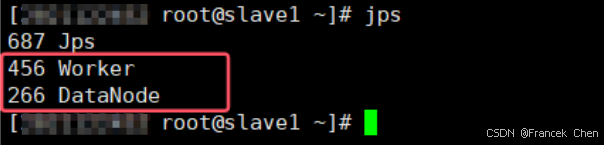
在 slave1~2 上查看進程:
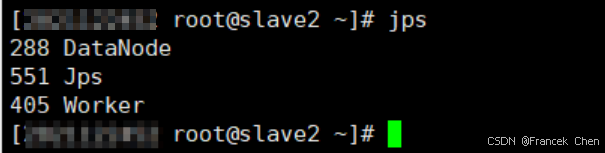
(三)配置 HDFS
1、配置 Spark 集群使用 HDFS,首先關閉集群(在 master 上執行)。
/usr/cstor/spark/sbin/stop-all.sh
2、將 Spark 環境變量模板復制成環境變量文件。修改 Spark 環境變量配置文件spark-env.sh。
cd /usr/cstor/spark/conf
cp spark-env.sh.template spark-env.sh

在sprak-env.sh配置文件中添加下列內容:export HADOOP_CONF_DIR=/usr/cstor/hadoop/etc/hadoop
vim spark-env.sh
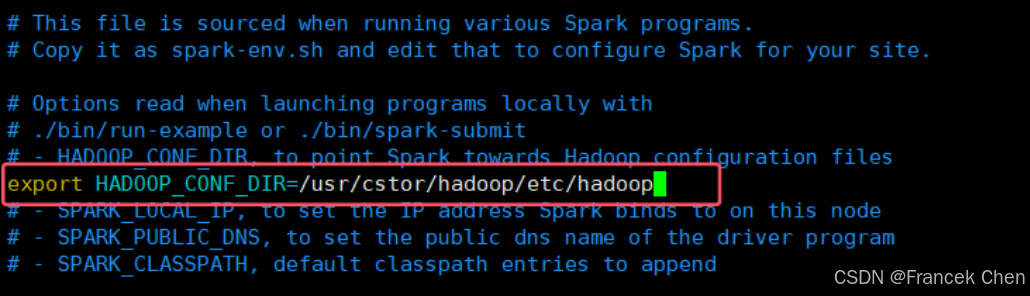
3、重新啟動 Spark。
/usr/cstor/spark/sbin/start-all.sh
(四)提交 Spark 任務
在 master 機上操作:使用 Shell 命令向 Spark 集群提交 Spark-App
1、上傳in.txt文件到 HDFS。
hadoop fs -mkdir -p /user/spark/in/
hadoop fs -put /root/data/13/in.txt /user/spark/in/

2、提交 wordcount 示例代碼。進入/usr/cstor/spark目錄,執行如下命令:
bin/spark-submit --master spark://master:7077 \
> --class org.apache.spark.examples.JavaWordCount \
> lib/spark-examples-1.6.0-hadoop2.6.0.jar hdfs://master:8020/user/spark/in/in.txt
六、實驗結果
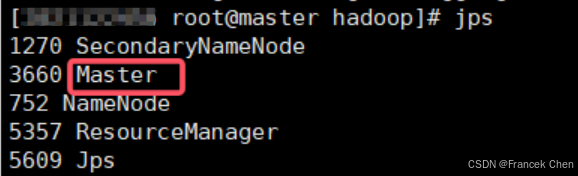
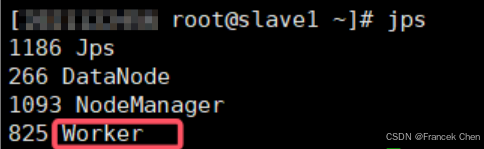
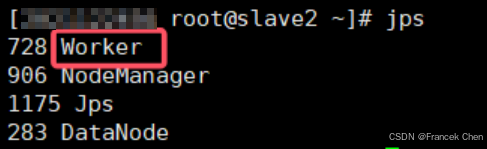
1、進程查看
在 master 和 slave1-2 上分別執行 jps 命令查看對應進程。master 中進程為 Master,slave 機進程為 Worker。
2、驗證 WebUI
在本地瀏覽器中輸入 master 的 IP 和端口號 8080,即可看到 Spark 的 WebUI。此頁面包含了 Spark 集群主節點、從節點等各類統計信息。

3、SparkWordcount 程序執行
輸入:in.txt:

輸出:

WebUI 中 Application 的詳細信息:

七、實驗心得
??首先,環境搭建是關鍵。在部署 Spark 集群之前,我花了不少時間配置 Hadoop 和 Spark 的環境,包括安裝 Java、Hadoop 和 Spark 等。通過參考官方文檔和社區資源,我逐步克服了各種依賴問題。值得注意的是,確保各個節點的時間同步非常重要,這可以避免因時間差異引發的一些錯誤。
??其次,集群管理與監控至關重要。在部署完成后,我學習了如何使用 Spark 的 Web UI 進行任務監控。這讓我對作業的執行過程有了更直觀的了解,比如任務的運行時間、資源使用情況等。此外,結合 Hadoop 的 YARN 資源管理器,可以更加有效地分配資源,提高集群的整體性能。
??在實驗中,我體驗到了分布式計算的優勢。通過將數據分片分配到不同的工作節點上,Spark 能夠并行處理大量數據,大幅提高了計算效率。我實現了一些基本的數據處理任務,比如數據過濾、聚合等,觀察到處理速度相較于單機模式有了顯著提升。
??總結來說,這次 Spark 集群部署實驗讓我對大數據處理技術有了更深入的理解。從環境搭建到任務執行,再到性能優化,每一步都讓我感受到分布式計算的魅力。未來,我期待將這些知識應用于實際項目中,進一步探索大數據的無限可能。
附:以上文中的數據文件及相關資源下載地址:
鏈接:https://pan.quark.cn/s/43cf46ec0d4d
提取碼:SwUU

 配置指南)







![[spring6: @EnableWebSocket]-源碼解析](http://pic.xiahunao.cn/[spring6: @EnableWebSocket]-源碼解析)







)

