在復雜的系統中,每個業務實體都需要使用ID做唯一標識,以方便進行數據操作。例如,每個用戶都有唯一的用戶ID,每條內容都有唯一的內容ID,甚至每條內容下的每條評論都有唯一的評論ID。
4.1.1 全局唯一與UUID
在互聯網還未普及的年代,由于用戶量少、網絡交互形式單調,互聯網產品后臺數據庫使用單體架構就可以滿足日常服務的需求。當時每個業務實體都對應數據庫中的一個數據表,每條數據都簡單地使用數據庫的自增主鍵作為唯一ID。
近年來,隨著互聯網用戶的爆發式增長,數據庫從單體架構演進到分庫分表的分布式架構,同一個業務實體的數據被分散到多個數據庫中。由于數據表之間相互獨立,在插入數據時會生成相同的自增主鍵。此時,如果還使用自增主鍵作為唯一ID,就會導致大量數據的標識相同,造成嚴重事故。我們應該保證無論一個業務實體的數據被分散到多少個數據庫中,每條數據的唯一ID都是全局的,這個全局唯一ID就是分布式唯一ID。
RFC 4122 規范中定義了通用唯一識別碼(Universally Unique Identifier, UUID),它是計算機體系中用于識別信息的一個128位標識符。UUID按照標準方法生成時,在實際應用中具有唯一性,UUID重復的概率可以忽略不計。JDK 1.5在語言層面實現了 UUID,可以輕松生成全球唯一ID:
import java.util.UUID;public class idgenerator {public static void main(String[] args) {String uuid = UUID.randomUUID().toString();System.out.printin(uuid);}
}
UUID的標準格式由32個十六進制數字組成,并通過連字符-分隔成8-4-4-4-12共 36 個字符的形式。例如,6a0d3e6f-allc-4b7d-bb35-c4c530a456b0、123e4567-e89b-12d3- a456-426655440000。這種唯一ID的生成方式足夠簡單,利用本地計算即可生成全球唯一ID。不過,UUID具有一些缺點:
- UUID字符串需要占用36字節的存儲空間,如果每條數據都攜帶UUID,那么在海量數據場景下存儲空間消耗較大。
- 此外,UUID是無數據規律的長字符串,如果將其用作數據庫主鍵,則會導致數據在磁盤中的位置頻繁變動,嚴重影響數據庫的寫操作性能。
4.1.2 唯一ID生成器的特點
UUID僅適合數據量不大的場景,比如一個存儲集群使用UUID標識每個數據分區。真正可用于海量數據場景的唯一ID生成器,除保證ID不可重復外,還應該具有如下特點。
- 空間占用小:作為每條數據都攜帶的字段,唯一ID不應該占用過多的存儲空間。
- 高并發與高可用性:唯一ID生成器是大部分業務服務的重要依賴方,唯一ID的生成操作需要做到高并發無壓力,維持長期高可用性。
- 唯一ID可用作數據庫主鍵:為了不對數據庫的寫操作造成負面影響,需要保證唯一ID對數據庫主鍵友好。
前兩點很好理解,最后一點,什么樣的唯一ID才對數據庫主鍵友好呢?我們以MySQL數據庫的InnoDB引擎為例。InnoDB使用基于磁盤的B+樹表示數據表,并以主鍵作為索引,即B+樹按照主鍵從小到大的順序排列數據。
如圖4-1所示,B+樹的節點使用默認為16KB大小的數據頁(Page)表示,其中:
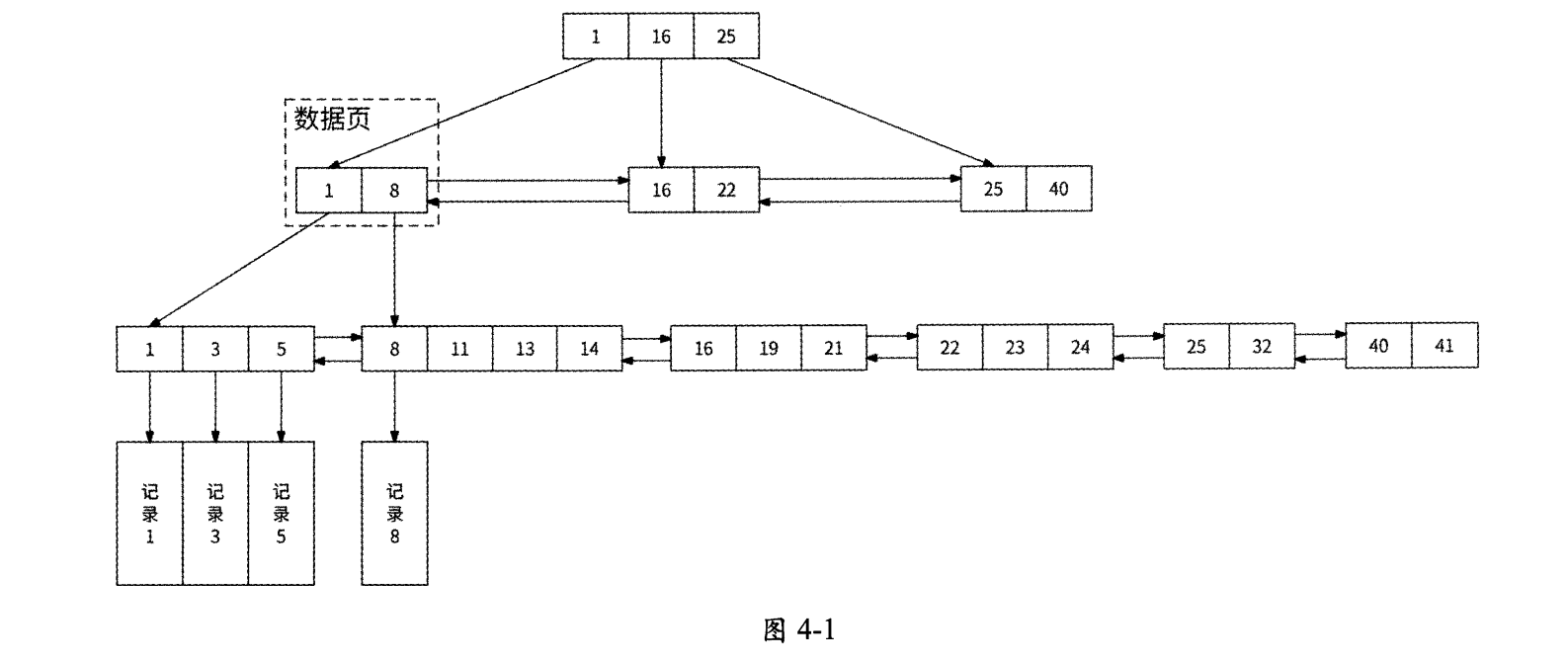
- 節點分為葉節點和非葉節點,底層是葉節點。
- 同層數據頁之間相互組成雙向鏈表。
- 非葉節點僅保存N個主鍵作為指向下一層N個數據頁的索引,主鍵從小到大排列。
- 葉節點保存實際的數據,葉節點組成的雙向鏈表上的所有數據按照主鍵從小到大的順序排列。
使用自增性質的字段作為InnoDB數據表的主鍵是一個很好的選擇,每次寫入新數據時,數據都被順序添加到對應數據頁的尾部;一個數據頁寫滿后,B+樹自動開辟一個新的數據頁。
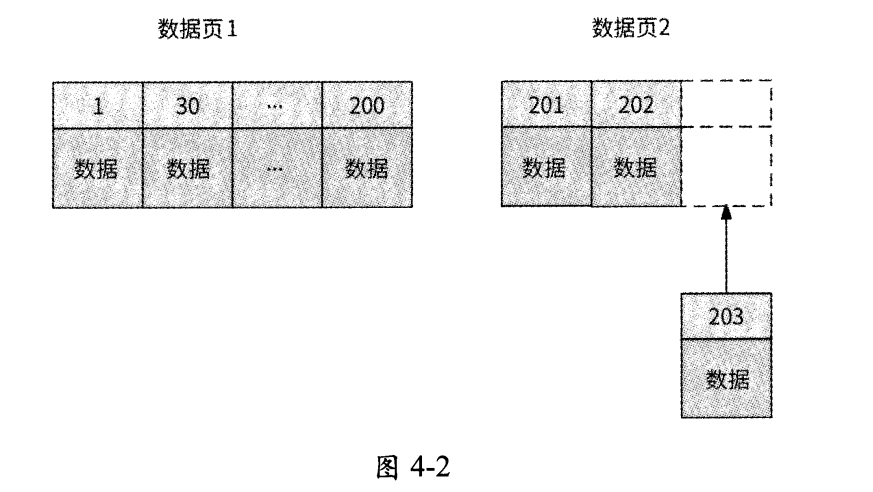
如圖4.2所示,主鍵值為203的新數據被插入數據頁2的尾部,這樣一來,B+樹將會形成一個較為緊湊的索引結構,空間利用率較高;而且,每次插入數據時也不需要移動已有的數據,時間開銷很小。
而如果使用非自增性質的字段(比如身份證號碼、電話號碼)作為主鍵,由于主鍵值較為隨機,新數據可能要被插入數據頁中間的某個位置。如圖4-3所示,主鍵值為15的新數據只能被插入數據1和數據30之間,數據30、50、90都需要向后移動。
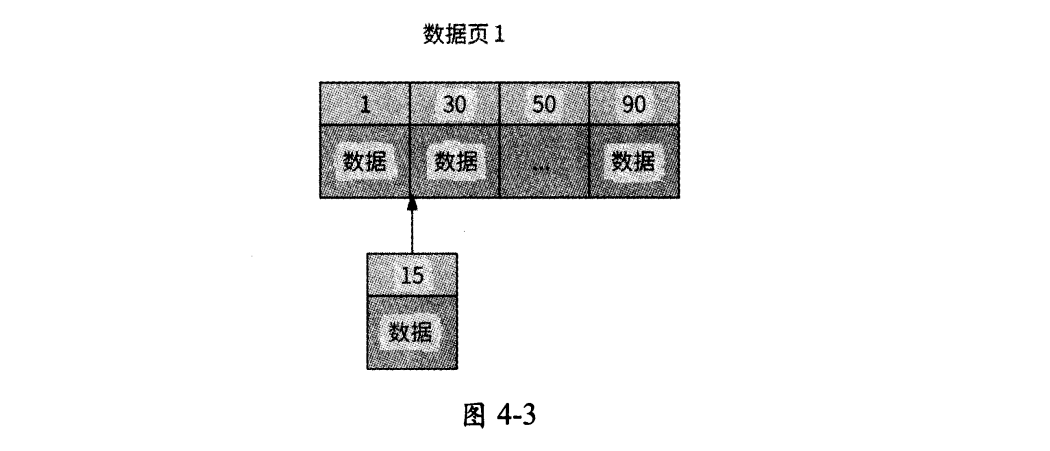
為了給新數據騰出位置,B+樹不得不將已有的數據向后移動——如果數據頁已滿,則會進行多次分頁操作。頻繁的數據移動和分頁操作使得B+樹在磁盤上產生大量的碎片,且時間開銷很大。因此,官方建議盡量使用自增性質的字段作為InnoDB數據表的主鍵。
為了成為自增性質的主鍵,唯一ID生成器生成的唯一ID在數值上應該是遞增的,這樣的唯一ID對數據庫主鍵就是友好的。
占用8字節(64位)的long類型整數適合用作唯一ID,因為:
- long類型雖然占 用的空間較小,但是可表示的ID范圍卻非常大
- long類型整數很容易實現遞增的效果。
至此,本章的議題已經明確:設計一個可以生成遞增的long類型唯一ID的生成器。
4.1.3 單調遞增與趨勢遞增
在正式開始設計唯一ID生成器之前,我們還需要解釋一下遞增。遞增可以分為單調遞增和趨勢遞增,從技術實現的角度來看,它們的差異較大。
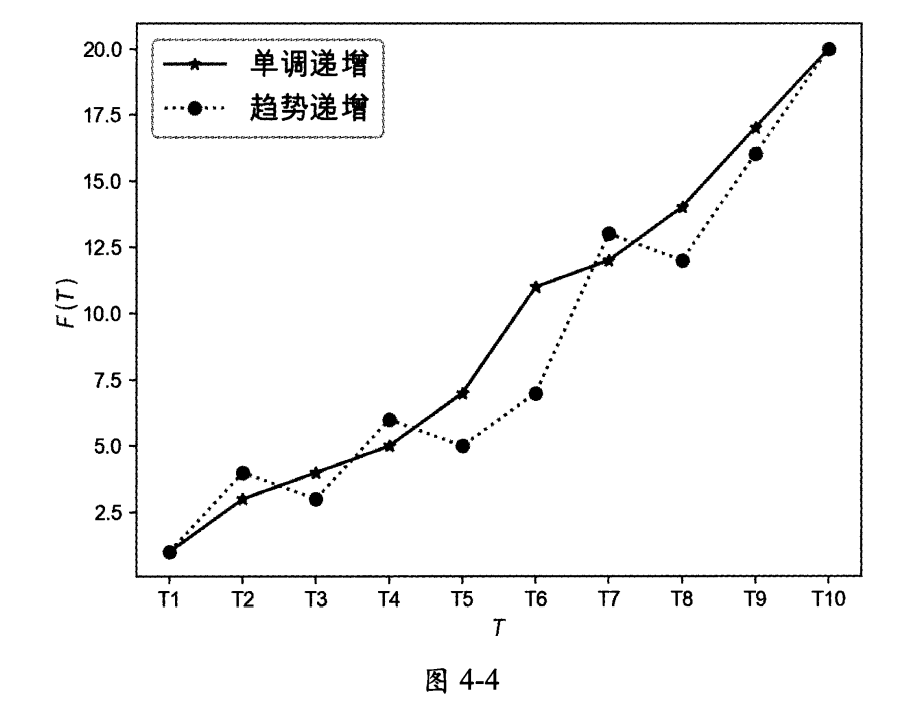
- 單調遞增:T表示絕對時間點,如果Tn+1>TnT_{n+1} > T_nTn+1?>Tn?,則一定有F(Tn+1)>F(Tn)F(T_{n+1}) > F(T_n)F(Tn+1?)>F(Tn?)。如果唯一ID生成器生成的ID單調遞增,則說明下一次獲取到的ID一定大于上一次獲取到的ID。
- 趨勢遞增:T表示絕對時間點,如果Tn+1>TnT_{n+1} > T_nTn+1?>Tn?,則大概率有F(Tn+1)>F(Tn)F(T_{n+1}) > F(T_n)F(Tn+1?)>F(Tn?)。雖然在一小段時間內數據有亂序的情況,但是從整體趨勢上看,數據是遞增的。
單調遞增和趨勢遞增的數據特點如圖4-4所示。
雖然我們在4.1.2節中已經討論了唯一ID應該是遞增的,但無奈受限于全局時鐘、延遲等分布式系統問題,單調遞增的唯一ID生成器的設計方案往往會有較大的局限性,與此相比,趨勢遞增的唯一 ID生成器更受業界歡迎。接下來具體介紹這兩種遞增類型的唯一ID生成器設計方案的差別。
總結
在分布式架構中,如果還使用自增主鍵作為唯一ID,會發生什么問題呢?
數據庫從單體架構演進到分庫分表的分布式架構,同一個業務實體的數據被分散到多個數據庫中。由于數據表之間相互獨立,在插入數據時會生成相同的自增主鍵。此時,如果還使用自增主鍵作為唯一ID,就會導致大量數據的標識相同,造成嚴重事故。
什么是UUID呢?
UUID的標準格式由32個十六進制數字組成,并通過連字符-分隔成8-4-4-4-12共 36 個字符的形式。例如,6a0d3e6f-allc-4b7d-bb35-c4c530a456b0、123e4567-e89b-12d3- a456-426655440000。
UUID的缺點?
-
UUID字符串需要占用36字節的存儲空間,如果每條數據都攜帶UUID,那么在海量數據場景下存儲空間消耗較大。
-
UUID是無數據規律的長字符串,如果將其用作數據庫主鍵,則會導致數據在磁盤中的位置頻繁變動,嚴重影響數據庫的寫操作性能。
唯一ID生成器的特點?
- 空間占用小:作為每條數據都攜帶的字段,唯一ID不應該占用過多的存儲空間。
- 高并發與高可用性:唯一ID生成器是大部分業務服務的重要依賴方,唯一ID的生成操作需要做到高并發無壓力,維持長期高可用性。
- 唯一ID可用作數據庫主鍵:為了不對數據庫的寫操作造成負面影響,需要保證唯一ID對數據庫主鍵友好。
為什么使用自增性質的字段作為InnoDB數據表的主鍵是一個很好的選擇?
- 使用自增性質的字段,每次寫入新數據時,數據都被順序添加到對應數據頁的尾部;一個數據頁寫滿后,B+樹自動開辟一個新的數據頁。
- 使用非自增性質的字段(比如身份證號碼、電話號碼)作為主鍵,由于主鍵值較為隨機,新數據可能要被插入數據頁中間的某個位置。為了給新數據騰出位置,B+樹不得不將已有的數據向后移動——如果數據頁已滿,則會進行多次分頁操作。頻繁的數據移動和分頁操作使得B+樹在磁盤上產生大量的碎片,且時間開銷很大。
為什么占用8字節(64位)的long類型整數適合用作唯一ID呢?
- long類型雖然占用的空間較小,但是可表示的ID范圍卻非常大
- long類型整數很容易實現遞增的效果。
什么是單調遞增和趨勢遞增?
- 單調遞增:T表示絕對時間點,如果Tn+1>TnT_{n+1} > T_nTn+1?>Tn?,則一定有F(Tn+1)>F(Tn)F(T_{n+1}) > F(T_n)F(Tn+1?)>F(Tn?)。如果唯一ID生成器生成的ID單調遞增,則說明下一次獲取到的ID一定大于上一次獲取到的ID。
- 趨勢遞增:T表示絕對時間點,如果Tn+1>TnT_{n+1} > T_nTn+1?>Tn?,則大概率有F(Tn+1)>F(Tn)F(T_{n+1}) > F(T_n)F(Tn+1?)>F(Tn?)。雖然在一小段時間內數據有亂序的情況,但是從整體趨勢上看,數據是遞增的。


















![[ComfyUI] -入門1-ComfyUI 是什么?比 Stable Diffusion WebUI 強在哪?](http://pic.xiahunao.cn/[ComfyUI] -入門1-ComfyUI 是什么?比 Stable Diffusion WebUI 強在哪?)
![[python][flask]flask接受get或者post參數](http://pic.xiahunao.cn/[python][flask]flask接受get或者post參數)