1. 主從復制架構
核心概念
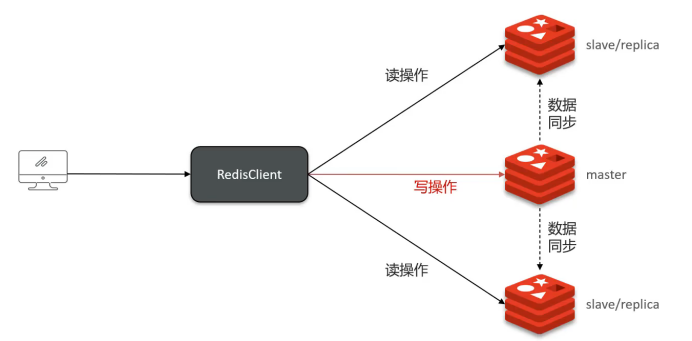
Redis單節點并發能力有限,通過主從集群實現讀寫分離提升性能:
- Master節點:負責寫操作
- Slave節點:負責讀操作,從主節點同步數據
主從同步流程
全量同步(首次同步)
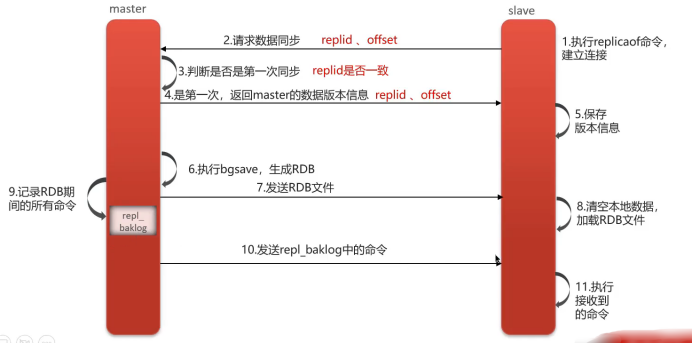
- 建立連接:從節點向主節點發送同步請求(攜帶replicationid、offset)
- 版本校驗:主節點判斷是首次請求,與從節點同步版本信息
- 生成快照:主節點執行bgsave生成RDB文件
- 數據傳輸:將RDB文件發送給從節點加載
- 增量補償:同步期間新寫入的命令記錄到緩沖區(replication buffer),隨后發送給從節點
增量同步(后續同步)
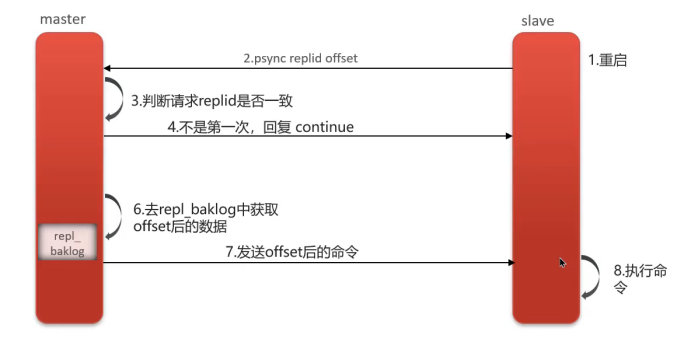
- 斷線重連:從節點重啟或網絡恢復后請求同步
- 偏移量對比:主節點獲取從節點的offset值
- 差異同步:從命令日志(replication backlog)中獲取offset之后的數據發送給從節點
關鍵參數:
replicationid:標識數據集版本offset:復制偏移量,標識同步進度
2. 哨兵機制(Sentinel)
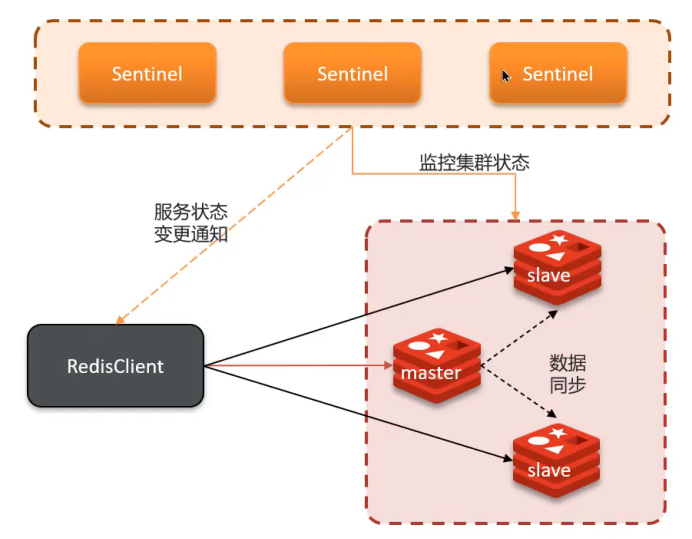
解決問題
主從架構無法自動故障轉移,引入哨兵實現高可用。
工作原理
健康監測
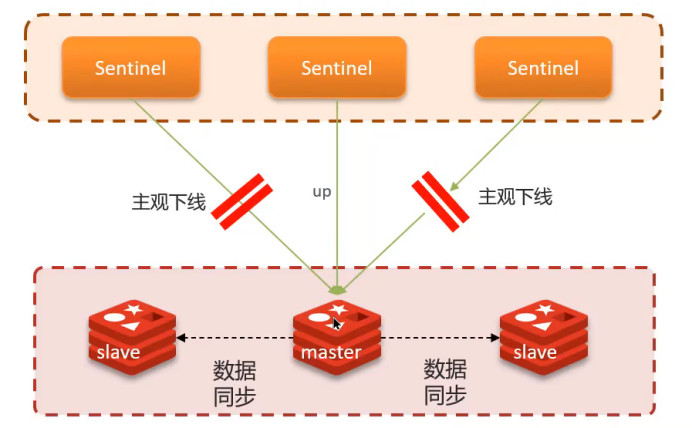
- 心跳檢測:每隔1秒向集群實例發送PING命令
- 主觀下線:單個哨兵認為實例無響應
- 客觀下線:超過quorum數量的哨兵都認為實例下線(quorum > 哨兵數/2)
故障轉移
自動選舉新的主節點,選主規則按優先級:
- 網絡連接:排除與主節點斷開時間過長的從節點
- slave-priority:優先級配置,數值越小優先級越高
- 復制偏移量:offset越大(數據越新)優先級越高
- 運行ID:ID越小優先級越高
3. 腦裂問題
問題描述
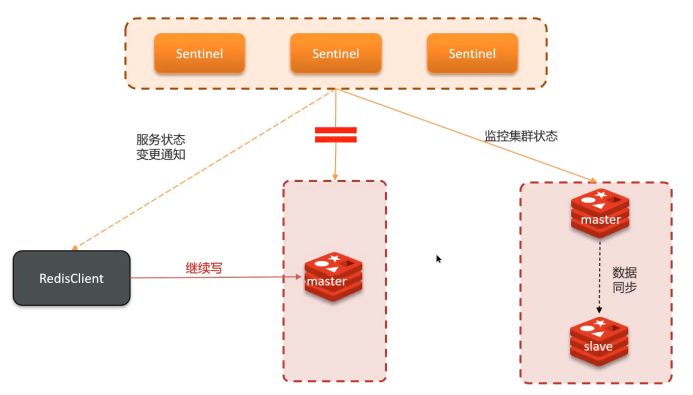
網絡分區導致集群出現兩個Master節點,類似"大腦分裂"。
產生原因
主節點與哨兵、從節點網絡隔離,哨兵誤判主節點下線并選舉新主節點。
危害
- 客戶端向舊主節點寫入數據
- 新主節點無法同步這些數據
- 網絡恢復后數據丟失
解決方案
配置參數限制寫入條件:
min-replicas-to-write 1 # 至少1個從節點在線
min-replicas-max-lag 5 # 主從同步延遲不超過5秒
4. 分片集群(Cluster)
解決問題
主從+哨兵仍存在兩個核心問題:
- 海量數據存儲:單主節點內存限制
- 高并發寫入:單主節點寫入瓶頸
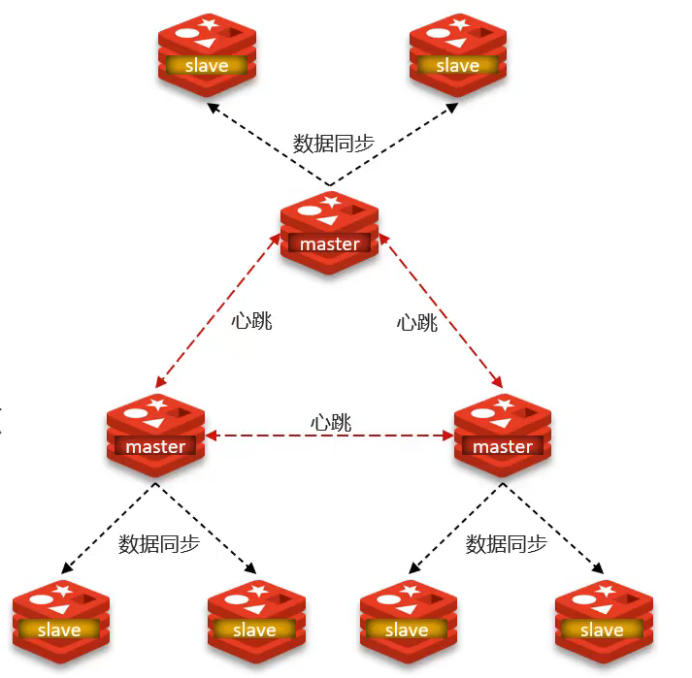
集群特征
- 多個Master節點,每個存儲不同數據
- 每個Master可配置多個Slave節點
- Master間通過PING監測健康狀態
- 客戶端可訪問任意節點,自動路由到正確節點
數據分片機制
哈希槽(Hash Slot)
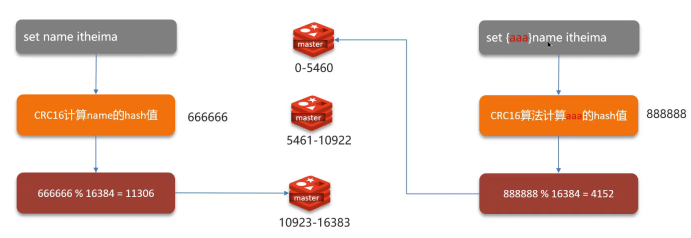
- 槽位總數:16384個哈希槽
- 分配算法:CRC16(key) % 16384
- 槽位分配:每個Master節點負責一部分槽位
數據路由流程
- 客戶端對key進行CRC16校驗
- 對16384取模確定槽位
- 根據槽位映射找到對應節點
- 如果訪問錯誤節點,返回MOVED重定向
面試要點總結
架構演進路徑
單機 → 主從復制 → 哨兵集群 → 分片集群
各架構解決的問題
- 主從復制:讀寫分離,提升并發讀能力
- 哨兵機制:自動故障轉移,實現高可用
- 分片集群:水平擴展,解決存儲和寫入瓶頸
核心技術點
- 數據同步:全量同步 + 增量同步
- 故障檢測:心跳機制 + 主客觀下線
- 數據分片:一致性哈希槽算法
- 腦裂預防:最小從節點數 + 同步延遲限制






:一款從編輯器腳本發展起來的編程語言)












