
互聯網時代,關系型數據庫為王。相應的,我們的檢索方式也是精確匹配查詢為主——查找特定的用戶ID、商品編號或訂單狀態。
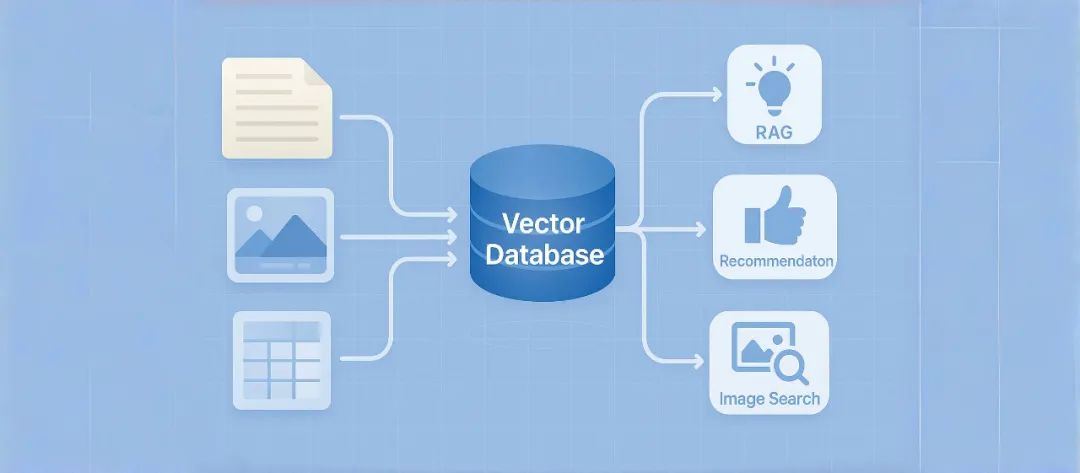
但AI時代,語義檢索成為常態,向量數據庫成為搜索推薦系統,大模型RAG落地,自動駕駛數據篩選等場景的關鍵基礎設施。
但一個問題是,不同場景,對向量數據庫的需求不同:
-?RAG(檢索增強生成):需要在海量文檔中找到與用戶問題語義相關的內容。對召回質量要求高,可靈活添加元信息,支持多租戶,存儲成本低。
-?推薦系統:基于用戶行為向量找到相似用戶或商品。要求高 QPS、低延遲、高可用性,支持數據離線導入和彈性擴縮容。
-?圖像搜索:通過圖像特征向量實現以圖搜圖。要求低延遲,高可擴展性,以應對數據急速增長。
-?代碼搜索:基于代碼語義而非關鍵字匹配。要求高召回,高 QPS,低延遲,數據規模相對可控。
但是從Elasticsearch 到Milvus 到PG vector,再到Qdrant ,甚至就在昨天,AWS也推出了自己的S3 Vctor。
那么,面對市場上多的讓人眼花繚亂的向量數據庫產品,如何選擇最適合自己業務場景的那一個?
本文將從功能、性能、生態三個核心維度,給出系統的決策框架和最佳實踐建議(不涉及任何帶貨與傾向性引導):
01?如何做業務與VDB的功能匹配
在選擇向量數據庫時,功能是最基礎和關鍵的考慮因素。以下是評估功能時需要重點關注的幾個方面:
完善的向量數據類型
豐富的向量索引算法
全面的向量檢索能力
企業級的可擴展架構
1.1 完善的向量數據類型
為什么要把完善的向量數據類型放在最開始?
原因很簡單,文本、圖像、音頻分別對應不同向量類型;一個業務也往往對應多個向量字段,沒有完善的向量數據類型支持,功能構建就無從談起。
以電商平臺的商品搜索為例,一個搜索動作,通常會涉及至少三種向量類型:
商品圖片經過圖像模型處理后生成的稠密向量,可以用于以圖搜圖和視覺相似性匹配。
商品描述文本經過分詞后生成的稀疏向量,可以用于關鍵詞匹配和全文檢索。
商品的用戶行為特征(如點擊、收藏、購買等)會編碼為二值向量,用于快速用戶興趣匹配。

1.2 豐富的向量索引算法與精細化參數設置
不同場景對向量檢索的要求,通常可以概括為三方面:高召回率、高性能和低成本,但這三個目標之間往往又會構成一個不可能三角。
但通常來說,三者取其二,就能滿足99%以上的需求。那么究竟選哪兩者,需要不同的高效索引算法來支持。以下是不同索引算法,對應的不同場景總結:
基于內存索引算法:
Flat索引適合追求極致召回率的場景
IVF索引適合大規模數據的快速檢索
HNSW索引則在召回率和性能之間取得良好平衡
基于磁盤的索引方案,可以突破內存容量限制,實現PB級大規模數據的經濟存儲和高效檢索
基于GPU等硬件加速的GPU 索引,滿足對延遲極其敏感的在線推理場景
提供細粒度的參數調優能力,支持用戶根據業務特點精確控制索引行為
而基于多樣化的索引選擇,向量數據庫還應具備精細的參數配置,讓用戶在有限的資源投入下實現最優的性能產出。
1.3 全面的向量檢索能力
Top-K相似性檢索是最常見的向量檢索需求,但除此之外過濾檢索、閾值檢索、分組檢索和混合檢索,也是一個企業級向量數據庫的必備功能。
還是以電商平臺的智能商品推薦為例,場景設置為用戶要買一條裙子。那么一個推薦動作,其實可以被拆解為以下幾個服務的結合:
Top-K相似性檢索
基于當前商品的圖片和文本描述向量,檢索視覺和語義相似的商品
智能過濾
通過價格區間篩選(標量過濾)、庫存狀態過濾(布爾過濾)和相似度閾值控制(設定最低相似度分數為0.8)進行智能篩選
多樣性優化
按商品品類分組(連衣裙、半身裙、套裝等)并對每個品類精選Top-3展示(分組檢索)
個性化推薦
通過融合用戶畫像向量、結合歷史購買行為,實現多模態混合檢索(商品文本稀疏向量 + 圖片稠密向量)
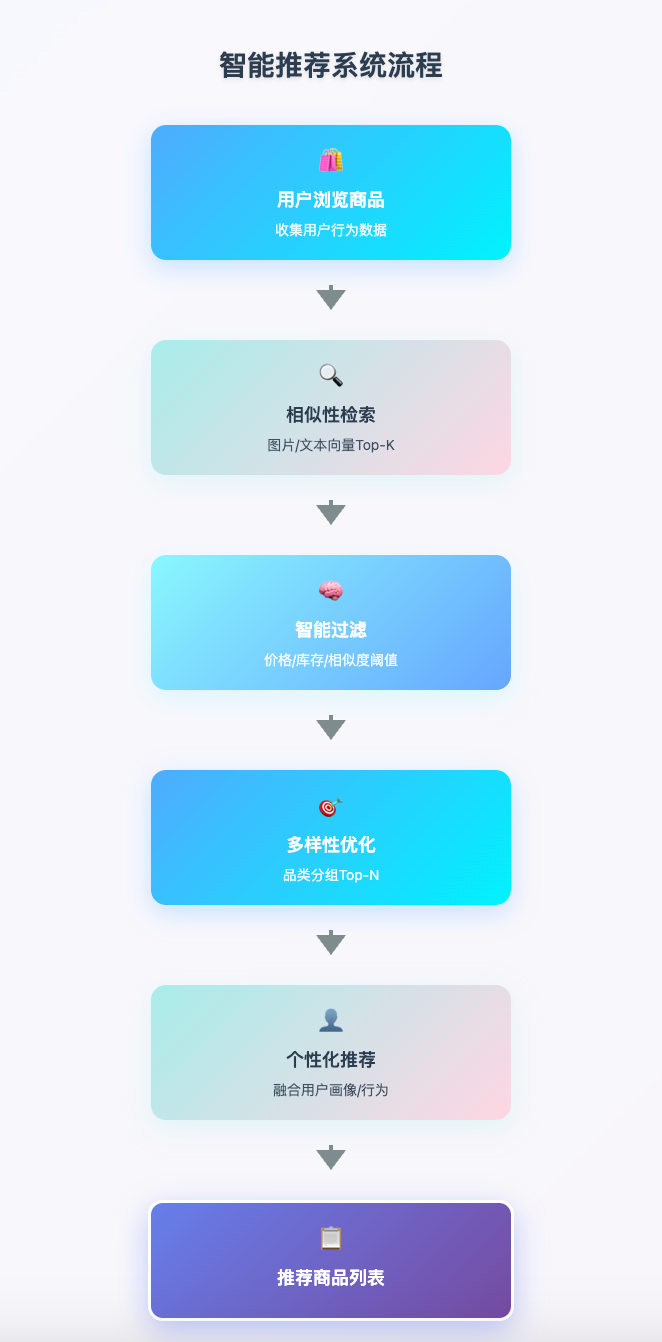
看似簡單的相關商品推薦背后,實際需要向量數據庫提供一整套完備的檢索能力。
1.4 企業級的可擴展架構
相比傳統結構化數據,非結構化數據最大的特點就是數據量足夠大。IDC數據顯示,到2027年,全球非結構化數據將占到數據總量的86.8%,達到246.9ZB。
這些數據通過各類AI模型處理后會產生海量的向量數據。
相應的,一個好的的向量數據庫必須采用高度靈活和可擴展的云原生架構,以應對這種指數級的數據增長。同時,系統需要具備完善的高可用機制,包括多副本容災、自動故障切換等特性,確保服務的連續性。
02?如何做VDB的性能評估
建立在完整的功能需求之上,性能是我們最關注的特性。
通常來說,性能評估,可以從以下幾個維度系統性進行考察:
查詢延遲:包括P50、P95、P99等分位點,反映大部分和極端情況下的響應速度。
吞吐量(QPS):單位時間內可處理的查詢數量,體現系統并發能力。
準確率(Recall@K):近似檢索場景下,結果的準確性同樣重要。
數據規模適應性:在百萬、千萬、億級數據量下的性能表現,是否能平滑擴展。
過濾查詢性能:在不同過濾比例(如1%、10%、50%、90%、99%)下的向量檢索性能表現,體現系統處理復雜查詢的能力。
流式處理性能:在持續寫入和實時查詢的場景下,系統的寫入延遲、查詢延遲波動情況,以及數據一致性保證。
資源消耗:CPU、內存、磁盤IO等資源占用,決定了系統的性價比和可持續性。
知道需要評估的指標以后,選擇一個好的評測工具也很重要。在算法層面,ANN-Benchmark是一個廣受認可的近似最近鄰算法評測平臺,但它主要面向底層算法庫的性能對比,忽略了動態場景、數據集維度也有些過時、用例相對簡單,不適用生產環境。
而關于生產環境的向量數據庫評測,我們更推薦同樣開源的VDBBench。其特性可以參考我們的歷史文章:
https://mp.weixin.qq.com/s/LK2aC2AkPeBGRn41Bd6l-A
使用 VDBBench 的典型測試流程:
確定使用場景:選擇合適的數據集(如SIFT1M、GIST1M等)和業務場景(如TopK檢索、過濾檢索、邊寫入邊檢索等)。
配置數據庫和VDBBench參數:保證測試環境公平、可復現。
在Web界面上配置并啟動測試,自動收集各項性能指標,對其進行對比后,做綜合選型決策。
03?不要忽略VDB的生態
生態系統的完善程度會直接決定VDB的可用性、可推廣性和長期生命力。
我們的考量維度可以從以下幾個方面來展開
大模型生態的適配
一個優秀的向量數據庫應當能夠無縫對接主流大模型(如OpenAI、Claude、Qwen等)和Embedding服務,支持多種主流向量生成方式。同時,還可以和LangChain、LlamaIndex、Dify等AI開發框架深度集成,方便開發者快速構建RAG、智能問答、推薦系統等應用。
工具體系的適配
一個高效簡潔的交互與監測系統,會直接決定用戶的數據庫使用體驗,常見的配套工具體系主要有以下幾個:
可視化管理工具:支持數據管理、性能監控、權限配置等一站式操作
備份與恢復工具:支持全量/增量備份、數據恢復,保障數據安全
容量規劃工具:幫助用戶科學評估資源需求,合理規劃集群規模
診斷與調優工具:支持日志分析、性能瓶頸定位、故障排查等
監控與告警體系:如Prometheus/Grafana集成,便于實時監控系統健康狀態
是否開源與中立
向量數據庫是個尚在進化中的進行時產品,開源意味著可以聽到更多用戶聲音,率先完成進化。同時,借助活躍的開源社區,也能夠降低用戶的使用與認知門檻。
但只有開源是不夠的,大型開源項目的迭代維護是需要很高的人力投入,單靠個人開發者幾乎無法支撐,業界知名的數據服務相關的開源項目,比如Spark、MongoDB、Kafka,背后都是有成熟的商業化公司在運營。
在此基礎上,VDB的商業化方案,則應該保持云中立,在保證彈性、低運維投入的基礎上,能滿足不同業務、不同地區產品,以及不同階段企業的多樣化需求。
是否有足夠的成功落地案例
一個成功的落地案例抵得上一萬句解釋與論證。在選型一款向量數據庫之前,不妨先看看這個產品的官網和公眾號上是否有涵蓋各種行業(互聯網、金融、制造、醫療、法律等),各種應用場景(搜索、推薦、風控、智能客服、質量檢測等)的落地案例。
一個產品能服務好同行,自然能更好的服務自己。
如果還有擔心,那么實踐是檢驗真理的唯一標準,先做個POC測試驗證一下肯定沒錯。
尾聲
寫這篇文章的起因,是最近很多朋友問到我關于向量數據庫選型的問題。
但數據庫選型是一個復雜的決策過程,選完之后可能會用三五年甚至更久,甚至決定一批開發者的職業生涯,給出建議必須慎之又慎。
所以我將自己的一些經驗寫成文章系統的分享出來,如果大家關于VDB選型或者應用、發展趨勢的更多問題,歡迎掃描文末二維碼,隨時和我們交流!
作者介紹

李成龍
Zilliz 資深開源布道師
推薦閱讀
開源|VDBBench 1.0正式官宣,完全復刻業務場景,支持用戶自定義數據集
實戰|TRAE+Milvus MCP,現在用自然語言就能搞定向量數據庫部署了!
Milvus Week | ?Kafka 很好, Pulsar也不錯,但WoodPecker才是未來
Milvus Week | 1bit極度量化+高召回,RaBitQ才是最好的向量量化算法











)


)
)


|SVM-幾何距離)
![[每日隨題11] 貪心 - 數學 - 區間DP](http://pic.xiahunao.cn/[每日隨題11] 貪心 - 數學 - 區間DP)
)
