文章目錄
- 引言
- 正文
- 結束語
引言
陪女朋友出門,我大概有兩個小時左右的空閑時間,遂帶上電腦,翻了下論文列表,選擇了這篇文章做一個簡讀。
因為這一年負責時序系統的存儲引擎和計算引擎演進,而Compaction又是串聯讀寫的核心組件,其Trade off就成了對于性能來講非常重要的事情,所以sigmod2025的這篇文章我一直很期待。
吐槽下知乎只有文章,想法(字數限制50)這兩種內容輸出的形式,我其實希望發一篇總結,但沒有文章那么正式,又比想法更加復雜,公司內部的知識平臺有筆記這種內容輸出形式,就很符合我的需求。
問了下LLM,得到的答案是這樣的:
- 知乎的核心價值:作為中文互聯網高質量問答社區,其內容需具備公共討論價值和長期復用性。問題(結構化問答)、文章(深度解析)、想法(輕量觀點)均服務于這一目標。
- 筆記的潛在沖突:筆記通常偏向個人化、碎片化、非結構化內容(如摘抄、待辦清單),與知乎“公共知識庫”的定位不符,易稀釋內容質量。
仔細思考后發現我想輸出的內容仍舊屬于文章范疇,且具備公共討論價值和長期復用性,不單單是碎片化的個人內容,遂完成了這篇簡讀文章,但是沒有加入到從一到無窮大的專欄中,而是另起爐灶,重新創建一個專欄,收錄后續的非正式文章。
這半年其實算下來也有十幾篇有意思的論文我都寫了筆記,但是夠不上從一到無窮大的文章思考水平,遂全部在草稿箱吃灰,后續都可以放在問津集中來。
正文
Compaction is the key operation of the LSM-tree. Compacting aggressively leads to higher write amplification while reducing read amplification. Compacting lazily reduces write amplification but can hurt query performance.
文章的一個觀點很有意思,以前的工作主要集中在寫放大和讀放大之間的權衡上,假設更高的WA會導致較低的寫入性能。但是,LSM 樹應用程序通常會經歷穩定且適度的寫入流,并且它只優先考慮頂級刷新,以避免由于寫入停止而導致數據丟失。
例如,Meta已經證明,在實際工作負載中,最高寫入速度約為45 MB/s。鑒于現代 NVMe SSD 提供超過 2 GB/s 的寫入帶寬。論文的實驗表明,Compaction和查詢之間剩余 CPU 和 I/O 資源的分布不會影響 LSM 樹的寫入性能。因此Compaction策略的目標是優化查詢性能。
論文的實驗主要關注Compaction和查詢處于同機,所以需要聯合優化,因為Compaction和讀取作會爭奪來自同一剩余池的 CPU 和 I/O 資源。
所以,論文的實際建模為:給定穩定的 LSM 樹寫入流(以恒定的刷新速度),如何設計壓縮策略以最大化平均查詢吞吐量?
Compaction的本質是投入計算和 I/O 來減少sort run的數量,從而使未來的查詢能夠探測更少的sort run。但是,這種效果是暫時的,因為會不斷生成新的sort run。Compacion的未來收益取決于其對瞬時查詢吞吐量的影響以及該影響的持續時間。
論文還觀察到 Compaction的時機對于確定其影響的持續時間至關重要,在下一次Global Compaction(我們叫Full Compaction)之前執行Compaction越早,平均查詢吞吐量的后續收益就越大。這是因為較早的Compaction可以在較長的時間內減少查詢開銷,從而大大增加后續從Compaction中受益的查詢數量。
因此,理想的設計應該在不同時間采用不同的Compaction策略。這意味著同一level 的 sort run 應該具有不同的大小,因為它們是在不同的時間創建的,所以level的概念變得模糊,因為 LSM 樹不再具有相同大小的sort run。
自然積極的Compaction策略可以最大化查詢性能,但是其會占用資源,進而影響查詢。
這就是文章的核心思路:從投資的視角設計Compaction
We view compaction as a form of investment.
Compaction’s write amplification is the cost of the investment
and the increased instantaneous query throughput is the immediate return.
Maximizing average query performance means maximizing the accumulated return from each investment.
A compaction’s accumulated return might be less than the opportunity cost.
文章提出了EcoTune Algorithm:該策略在給定客戶端確定的恒定寫入速度的情況下,在Compaction中優化平均查詢吞吐量。
平均查詢性能通過Compaction的成本和累積回報來建模。Compaction的成本可以根據涉及的數據量輕模,并且每次壓縮的成本是獨立的。累積回報的建模比較復雜,因為需要考慮其查詢速度的即時改進以及這種改進將持續多長時間。
從立即回報到累積回報。最佳Compaction策略旨在最大化其累積收益,同時最大限度地降低其成本。文章分析了Compaction對查詢速度的直接影響與其成本之間的關系。在Compaction中,LSM 樹的數據布局和查詢吞吐量是動態變化的,因此壓縮的影響會隨著時間的推移而逐漸減弱。要分析Compaction的累積回報,還必須考慮其影響會持續多久。
文章的一個觀點是:越早進行Compaction,累積的未來回報就越大。當 LSM 樹遠離Full Compaction時,將多個sort run壓縮為一個可以提高較長時間的查詢速度。當 LSM 樹接近Full compaction時,Compaction 產生的好處越小,因為新創建的sort run不會被長時間查詢。由于時間的影響,具有相同成本的兩個Compaction可能具有非常不同的累積收益。因此,在Compaction開始時,應該更積極地合并sort run。隨著接近 full Compaction,compacion 策略應該變得更加懶惰。
其策略設計的核心稱為Three-Level Generalization.
最佳壓縮策略的積極性應該隨著時間的推移而改變。換句話說,每個sort run的大小取決于其創建時間,而不是限制為 L 允許的大小。因此,沒有大小相等的sort run。由于level的概念來自 L 允許的大小,因此不再有level的定義。而是將 LSM 樹視為一組sort run,類似于RocksDB universal compaction。
因為合并小的sort run和之前一樣,因此我們根據sort run對查詢速度的影響將sort run重新劃分為三個邏輯級別:
- top level:多個相同大小的sort run
- main level:多個不同大小的sort run
- last level:一個sort run
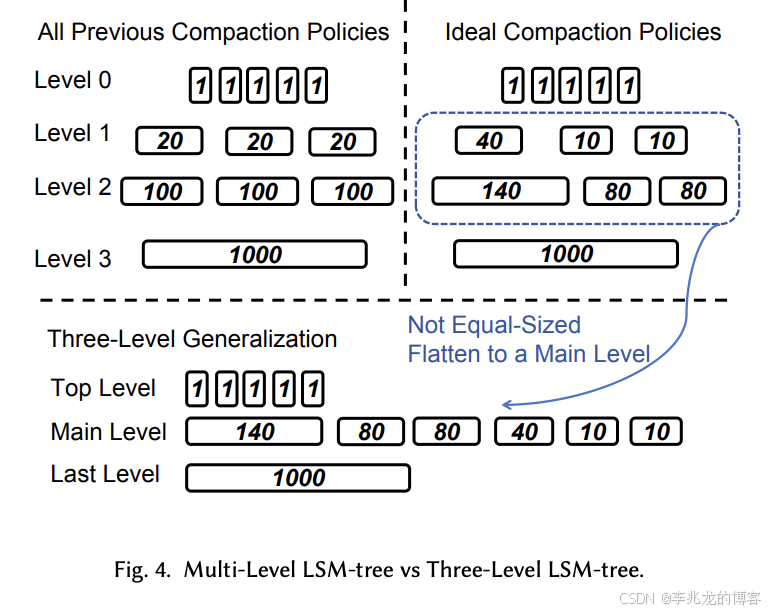
對于Three-Level Generalization,有三種后臺任務:
- flush from memory to the top level
- compaction from the top level to the main level (TMC)
- compaction within the main level (MLC).
EcoTune Algorithm就是在main level的壓縮策略,其對于最佳的定義是:兩次full compactions之間查詢的平均吞吐量最高。
算法的具體實現有興趣的讀者可以參考原論文的4.3節,這篇文章的目的是搞清楚問題和建模方法,具體的解決方法對于泛讀論文來講反而不太重要。
結束語
這篇論文對于Compaction其實不需要在意寫放大的觀察非常具有洞察力,在云環境下我們將Compaction,Ingester和查詢引擎完全分離的做法導致Compaction策略的思考與單機的Compaction完全不同。
而且當介質變成對象存儲時,寫放大很多時候也不是考慮的重點,因為讀寫帶寬是分離的,當存在帶寬風險時一般都會分桶,此時Compaction就更不應該將寫放大作為首要思考因素了,當然我們面對的問題和論文中的完全不一樣,但是其對問題建模的方式非常值得學習。
Investment View,只學計算機可沒法說出這樣的話,跨界的知識儲備對個人還是非常重要的,很多時候可以提供更為創新的視角。

|SVM-幾何距離)
![[每日隨題11] 貪心 - 數學 - 區間DP](http://pic.xiahunao.cn/[每日隨題11] 貪心 - 數學 - 區間DP)
)






)





)


