目錄
一.網絡爬蟲的介紹
1.網絡爬蟲庫
2.robot.txt規則
二.requests庫
1.requests庫的安裝
2.get()函數
3.Response對象
Response的屬性
?設置編碼
返回網頁內容
text()
content()
三.提交信息到網頁
post()函數
四.會話與代理服務器
一.網絡爬蟲的介紹
1.網絡爬蟲庫
①urllib庫:Python自帶的標準庫,代碼編寫略微復雜
②requests庫:第三方庫,在urllib庫的基礎上建立的,但使用起來更簡潔方便
③scrapy庫:第三方庫,是一個專業應用程序開發的網絡爬蟲庫
④selenium庫:第三方庫,可用于驅動計算機中的瀏覽器執行相關命令,而無需用戶手動操作
2.robot.txt規則
注意不是 網站中的所有信息都允許被爬取,也不是所有的網站都允許被爬取,在大部分網站的根目錄存在一個robot.txt文件用于聲明此網站中禁止訪問的url和可以訪問的url
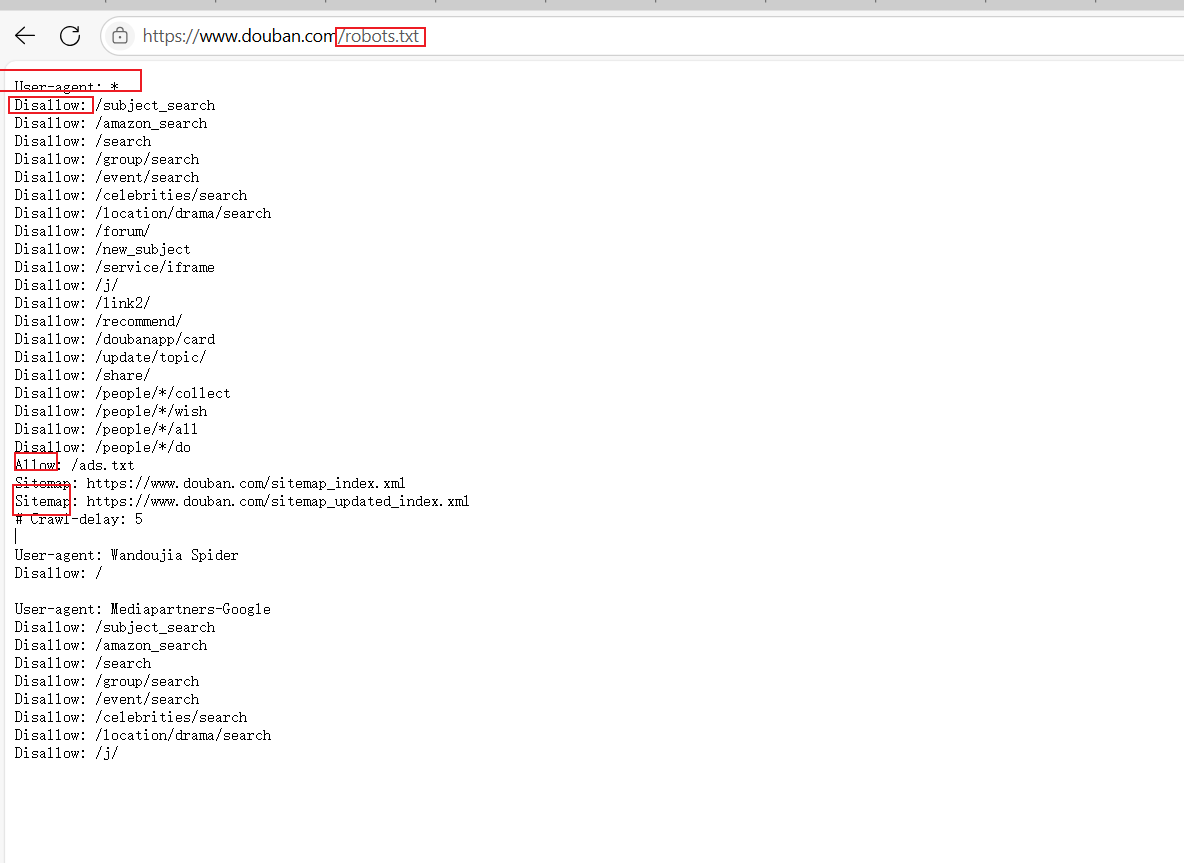
User-agent表示訪問網站的引擎,第一個值為*表示所有搜索引擎都需要遵守2-21行的規則
? ? ? ? ? ? ? ? ? 第二個值為Wandoujia Spider 表示Wandoujia Spider搜索引擎需要遵守的規則
Disallow表示該搜索引擎不允許訪問的url,值為/則表示不允許訪問任何內容
Allow表示該搜索引擎允許訪問的url
Sitemap網站地圖,用于提供網站中所有可以爬取的url
二.requests庫
1.requests庫的安裝
pip install requests -i 鏡像源地址2.get()函數
在requests庫中獲取html網頁內容的方法就是get()函數
get(url,params=None,**kwargs)url:需要獲取的網址
params:可選參數,以字典的形式發送信息,當需要想向網頁中提交查詢信息時使用
**kwargs:請求采用的可選參數
注意:此時get()函數爬取的網頁源代碼僅包含原始文本數據(如城市名稱),不包含渲染后的資源(如圖片、視頻)。r是返回的Response對象
import requests
r = requests.get('https://www.ptpress.com.cn/')
部分數據(如搜索關鍵詞)可通過字典參數動態添加到 URL 后(如 ?keyword=excel),適配不同網站的查詢格式。search表示搜索
import requests
r = requests.get('https://www.ptpress.com.cn/search?keyword=人工智能')
我們也可以用param參數來添加搜索信息,需要提前將param定義為字典
import requests
info ={'keyword':'人工智能
'}
r = requests.get('https://www.ptpress.com.cn/',params=info)系統會自動在url后面添加字典信息形式為
https://www.ptpress.com.cn/search?keyword=人工智能'
3.Response對象
Response的屬性
關鍵屬性包括:
status_code:服務器返回的狀態碼(如200表示成功,301表示永久重定向)。
url:實際爬取的網頁地址。
encoding、cookies:網頁編碼和 Cookie 信息。
狀態碼用于判斷請求是否成功(如200為允許爬取,其他代碼可能表示拒絕或錯誤)。
?設置編碼
爬取內容出現亂碼時,需將響應對象的編碼(encoding)與網頁實際編碼(apparent_encoding)對齊。通過response對象.encoding = response對象.apparent_encoding自動匹配編碼(如UTF-8),解決亂碼問題。如果設置自動匹配編碼后依然出現亂碼,需要我們自行設置encoding編碼方式
未設置編碼時,輸出內容可能因默認編碼(如ISO-8859-1)與網頁編碼不匹配而顯示亂碼。
返回網頁內容
Response對象返回網頁對象有兩種方法text()和content()
text()
以字符串形式返回網頁內容
content()
以二進制形式返回網頁內容常用于保存網頁中的媒體文件,例如
import requests
r = requests.get('https://fileinfo.com/img/ss/xl/jpg_44-2.jpg')
f = open("1.jpg",'wb')
f.write(r.content)
f.close()三.提交信息到網頁
我們用post請求將表單中的數據提交給瀏覽器
post()函數
post(url,data=None,json=None,**kwarge)- url:目標網站地址。
data:需要發送的以字典/元組形式提交的信息(如密碼修改表單)。json:需要發送的JSON類型的數據-
**kwargs:請求采用的可選參數
返回值也是一個Response對象
四.會話與代理服務器
會話維持:HTTP無記憶性需通過cookie或session保持連續操作(如翻頁爬取)
代理服務器:
作用:避免IP被封禁,通過中間服務器轉發請求(如爬取淘寶數據)。
擴展應用:VPN原理類似,通過代理訪問受限網站(如Facebook、ChatGPT)。
獲取方式:免費代理IP不穩定,推薦付費服務(如香港/新加坡服務器)。



(下))
)








)
)
)



)