文章目錄
- 一、機器學習數據導入
- 1、 Pandas:機器學習數據導入的最佳選擇
- 2、與其他方法的差異
- 二、機器學習數據理解的系統化方法論
- 1、數據審查方法論:六維數據畫像技術
- 維度1:數據結構審查
- 維度2:數據質量檢查
- 維度3:目標變量分析
- 維度4:特征關聯分析
- 維度5:數據分布特征
- 維度6:數據完整性
- 2、從數據觀察到算法選擇的邏輯鏈條
- 1、數據特征→算法匹配
- 2、決策示例
- 三、數據可視化驅動的機器學習決策
- 1、五維可視化分析
- 維度1:直方圖:分布形態分析 - "數據長什么樣?
- 維度2:箱線圖:分布細節分析 - "異常值在哪里?"
- 維度3:密度圖:連續性分析 - "數據如何變化?"
- 維度4:熱力圖:關聯強度分析 - "特征間如何影響?"
- 維度5:關系模式分析 - "特征間如何交互?"
- 2、"觀察-提問-決策"閉環系統
- 1、示例說明
- 2、可視化驅動的工作流
一、機器學習數據導入
1、 Pandas:機器學習數據導入的最佳選擇
Pandas DataFrame的數據結構優勢
Pandas之所以成為機器學習數據導入的首選,核心在于其DataFrame數據結構。DataFrame不僅是一個二維表格,更是一個為數據科學量身定制的數據容器:
- 列式存儲:每列可以是不同數據類型,完美適配機器學習特征的多樣性
- 索引系統:內置行列索引,支持快速數據定位和切片
- 內存優化:自動類型推斷和內存管理,避免不必要的內存浪費
?
2、與其他方法的差異
讓我們通過實際代碼來對比三種方法的差異:
方法1:Python標準庫 - 手動處理每個細節
from csv import reader
import numpy as npfilename = 'pima_data.csv'
with open(filename, 'rt') as raw_data:readers = reader(raw_data, delimiter=',')x = list(readers)data = np.array(x).astype('float') # 手動類型轉換print(data.shape)
方法2:NumPy - 適合純數值數據
from numpy import loadtxtfilename = 'pima_data.csv'
with open(filename, 'rt') as raw_data:data = loadtxt(raw_data, delimiter=',')print(data.shape)
方法3:Pandas - 一行代碼完成復雜任務
from pandas import read_csvfilename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)
print(data.shape)
?
核心差異分析:
Pandas的優勢不僅在于語法簡潔,更重要的是它在背后自動處理了復雜邏輯:
- 自動類型推斷:無需手動指定數據類型,智能識別數字、文本、日期
- 缺失值處理:自動將空值轉換為NaN,統一處理邏輯
- 列名管理:支持自定義列名,便于后續數據操作
- 內存優化:大文件時采用懶加載策略,避免內存溢出
而標準庫和NumPy都需要手動處理這些細節,導致代碼復雜度呈指數級增長。
?
選擇推薦
| 場景 | 推薦方案 | 原因 |
|---|---|---|
| 機器學習項目 | Pandas | 生態完整,與scikit-learn無縫集成 |
| 大規模數值計算 | NumPy + Pandas | 結合NumPy的計算性能和Pandas的易用性 |
| 簡單數據處理 | 標準庫 | 無外部依賴,適合輕量級場景 |
?
二、機器學習數據理解的系統化方法論
數據理解的本質不是簡單的數據瀏覽,而是通過系統化的觀察和分析,發現數據中隱藏的模式、問題和機會,從而指導后續的特征工程和算法選擇。
一個經典的失敗案例:某團隊花費3個月訓練復雜的深度學習模型,準確率始終無法提升。最后發現問題出在數據上—目標變量分布極不均衡(99%為負例),而他們從未做過類別分布分析。
?
1、數據審查方法論:六維數據畫像技術
一個完整的數據畫像需要從六個維度進行審查:
維度1:數據結構審查
from pandas import read_csvfilename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)# 查看數據規模和結構
print(data.shape)
print(data.dtypes)
關鍵問題:數據規模是否足夠?特征類型是否合理?
?
維度2:數據質量檢查
# 查看前10行,發現數據模式
print(data.head(10))# 描述性統計,發現異常值
print(data.describe())
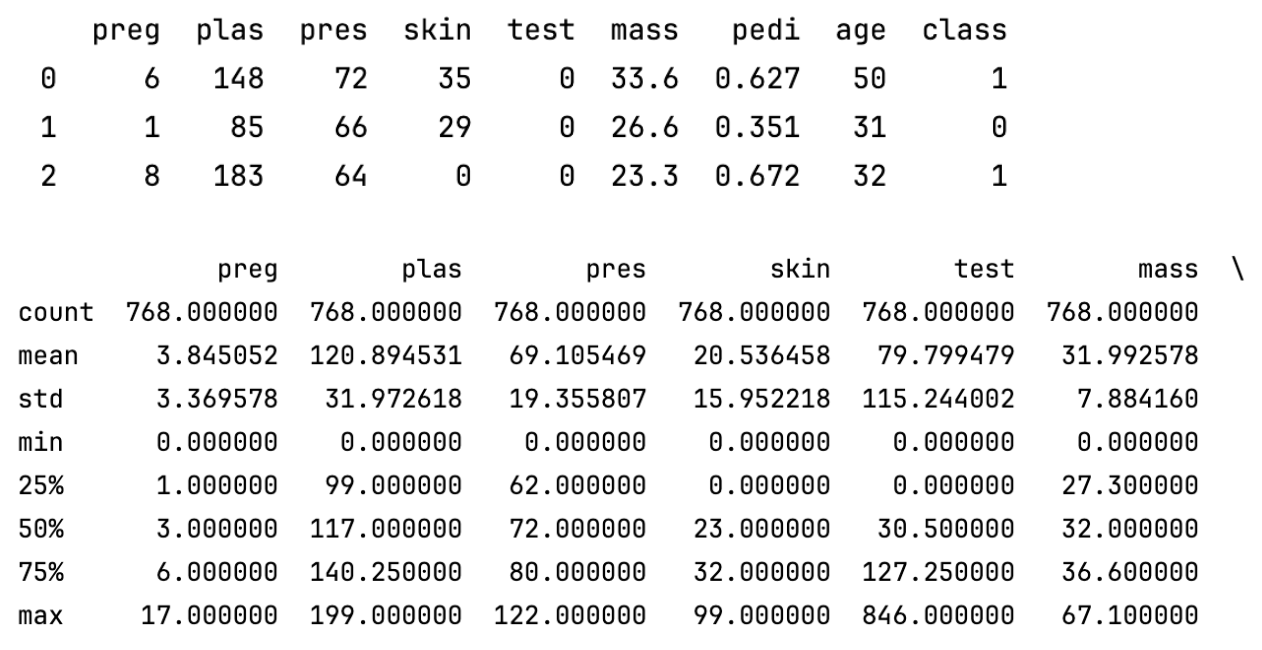
說明了數據集中各數值型特征的分布情況,包括均值、極值、分布范圍等。通過這些統計量,可以初步發現數據中的異常值(比如最大值或最小值遠離均值,或者四分位數間距很大等)。
關鍵問題:是否存在缺失值?數值范圍是否合理?
?
維度3:目標變量分析
# 類別分布分析
print(data.groupby('class').size())
- 分析數據集中class這一列的類別分布情況,即每個類別有多少條數據。
- 常用于分類問題的數據探索階段,幫助了解各類別樣本是否均衡。
關鍵問題:類別是否均衡?是否需要重采樣?
?
維度4:特征關聯分析
from pandas import set_optionset_option('display.width', 100)
set_option('display.precision', 2)
print(data.corr(method='pearson'))
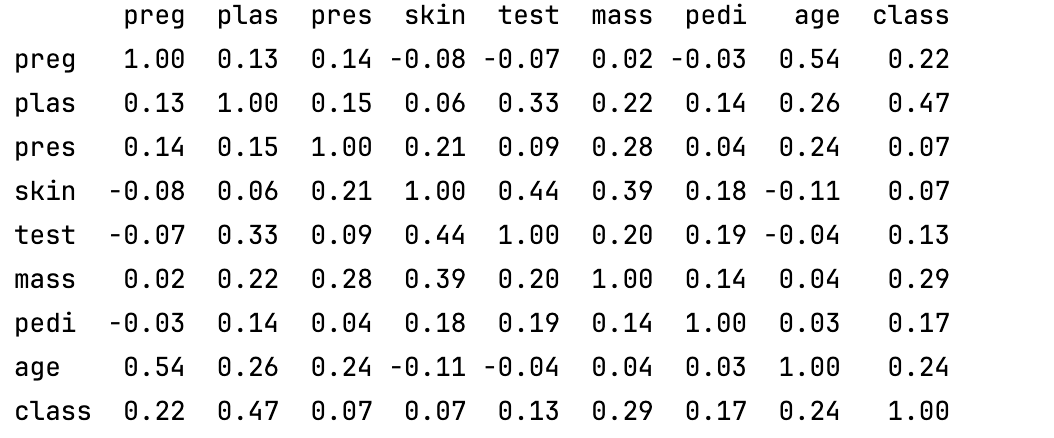
- 計算了皮爾遜相關系數矩陣。皮爾遜相關系數反映了兩個變量之間的線性相關程度,取值范圍為 [-1, 1],1 表示完全正相關,-1 表示完全負相關,0 表示無線性相關。
- 即數據集中各數值型特征之間的相關性矩陣,方便你分析變量之間的關系。
關鍵問題:哪些特征與目標變量強相關?是否存在多重(ing)共線性?
?
維度5:數據分布特征
# 計算偏態系數
print(data.skew())
偏態系數衡量的是數據分布的對稱性。
偏態系數 = 0,表示分布完全對稱(如正態分布)。
偏態系數 >0,表示分布右偏(長尾在右邊,數據集中在左邊)。
偏態系數 < 0,表示分布左偏(長尾在左邊,數據集中在右邊)。
?
通過查看偏態系數,可以判斷數據是否偏離正態分布。偏態較大的特征,可能需要做對數變換、Box-Cox變換等預處理,以便更好地建模。
關鍵問題:數據分布是否符合算法假設?是否需要變換?
?
維度6:數據完整性
# 檢查缺失值
print(data.isnull().sum())
?
這六個維度的檢查順序遵循了從宏觀到微觀,從結構到內容的認知規律:
- 結構審查建立整體的數據認知
- 質量檢查發現數據可靠性問題
- 目標分析明確建模難度和策略
- 關聯分析揭示特征工程方向
- 分布分析指導算法選擇
- 完整性檢查確定數據清洗優先級
?
2、從數據觀察到算法選擇的邏輯鏈條
1、數據特征→算法匹配
通過系統化的數據理解,我們可以建立數據特征到算法選擇的映射關系:
| 數據特征 | 算法選擇 | 原因 |
|---|---|---|
| 數值型+線性關系 | 線性回歸、嶺回歸 | 符合線性假設,計算效率高 |
| 高維稀疏數據 | 邏輯回歸、SVM | 處理高維特征能力強 |
| 類別不均衡 | 隨機森林+重采樣 | 對不均衡數據魯棒性好 |
| 非線性關系復雜 | 梯度提升樹、神經網絡 | 強大的非線性擬合能力 |
?
2、決策示例
假設通過數據理解發現:
目標變量類別比例為7:3(輕度不均衡)、特征間存在中等程度相關性(0.3-0.6)、部分特征呈現右偏分布。
決策邏輯:
- 類別不均衡程度中等 → 可以使用類別權重平衡,無需重采樣
- 特征相關性適中 → 可以保留所有特征,無需降維
- 數據右偏 → 建議使用基于樹的算法(對分布不敏感)
推薦算法:隨機森林 + 類別權重調整
?
三、數據可視化驅動的機器學習決策
可視化的核心價值:它能夠揭示統計數字背后的數據結構、異常模式和潛在關系,讓我們在建模之前就能洞察數據的本質特征。
一個典型的例子:某數據科學家通過describe()發現某特征均值為50,看似正常。但通過箱線圖可視化后發現,數據呈現雙峰分布,實際上是兩個不同群體的混合,這直接影響了后續的特征工程策略。
1、五維可視化分析
下面將從分布、異常、連續性、關聯、交互五個維度進行系統化分析
維度1:直方圖:分布形態分析 - "數據長什么樣?
from pandas import read_csv
import matplotlib.pyplot as pltfilename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)# 直方圖 - 揭示頻率分布
data.hist()
plt.show()
代碼為數據集中的每個數值型特征繪制直方圖,直觀展示其取值分布和頻率,幫助你了解數據的整體分布特征。
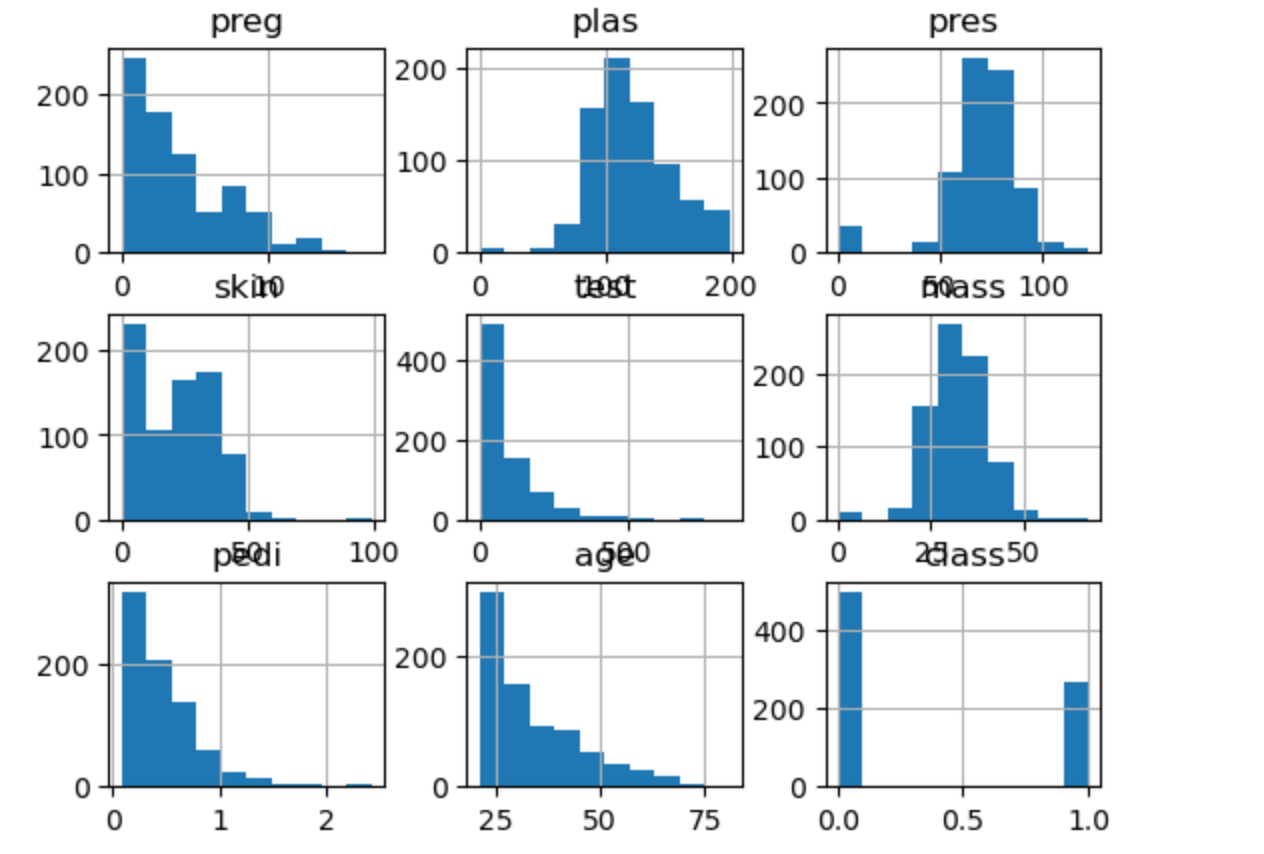
核心洞察:直方圖能夠識別數據的分布類型(正態、偏態、雙峰),這直接影響算法選擇。
?
維度2:箱線圖:分布細節分析 - “異常值在哪里?”
# 箱線圖 - 識別異常值和四分位數
data.plot(kind='box', subplots=True, layout=(3,3), sharex=False)
plt.show()
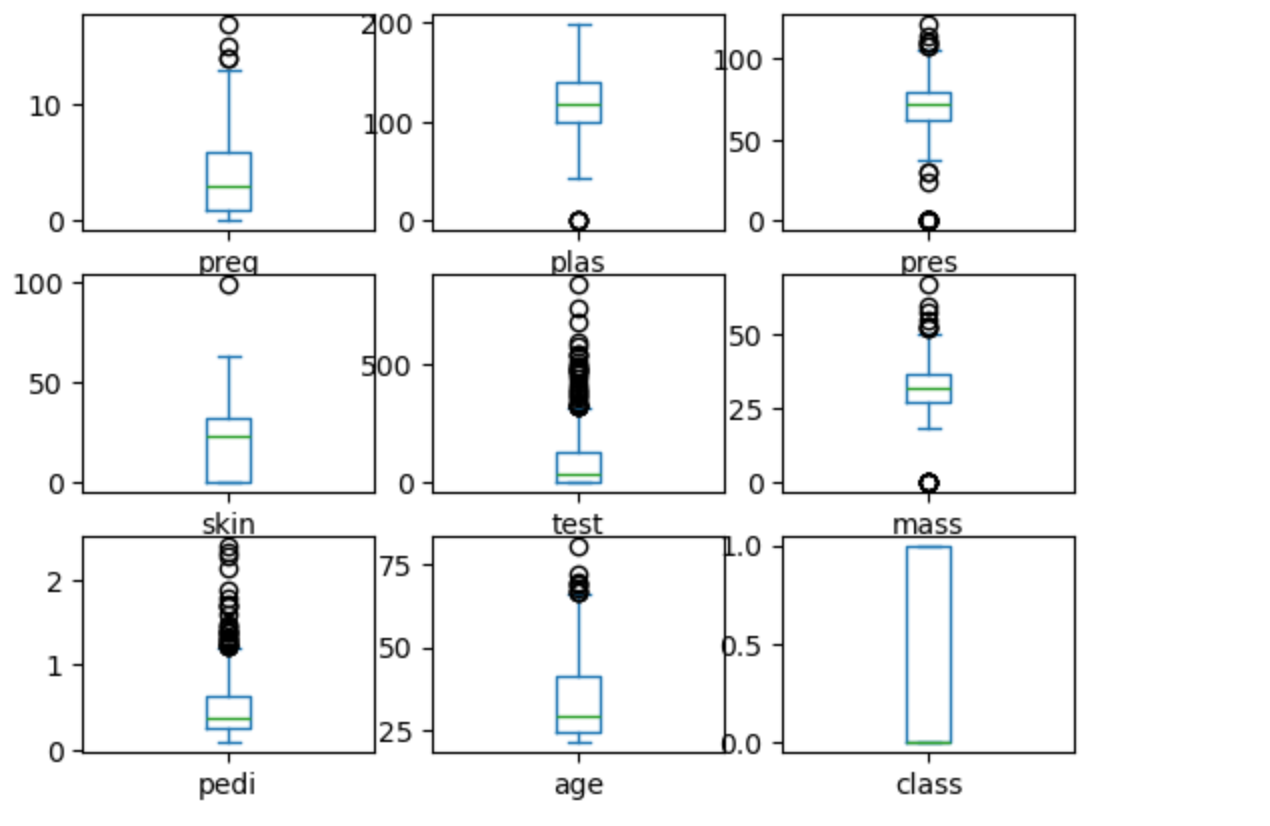
箱線圖(Boxplot)是一種常用的統計圖表,用于展示數據的分布特征、中心位置、離散程度以及異常值。
?
箱線圖的結構
- 箱體(Box):表示數據的中間50%(從第1四分位數Q1到第3四分位數Q3)。
- 中位線(Median):箱體中間的綠線,表示數據的中位數(第2四分位數Q2)。
- “胡須”(Whiskers):從箱體延伸出去的線,通常延伸到1.5倍四分位距(IQR)以內的數據。(IQR=Q3-Q1,四分位距 ing)。
- 異常值(Outliers):超出“胡須”范圍的點,單獨以小圓點等方式標出。
具體分析
一、preg, plas, pres, skin, test, mass, pedi, age 字段數據
- 這些特征的箱線圖都顯示了不同程度的異常值(上方或下方的圓點),說明這些特征中有一些數據點遠離主流分布,可能是極端值或錄入錯誤。
- 箱體高度:箱體越高,說明該特征的中間50%數據分布越分散;越矮則越集中。 中位線位置:如果中位線偏向箱體上方或下方,說明數據分布有偏態。
?二、class 字段數據
這個特征的箱線圖顯示為0和1的分布(因為是分類變量),沒有異常值,箱體覆蓋了0和1兩個取值。
?
三、結論
- 異常值:如test、skin、pedi等特征有較多異常值(上方或下方的圓點)。
- 分布偏態:如preg、pedi等特征的中位線偏下,說明數據右偏。
- 數據分布:大部分特征的箱體都比較靠近下方,說明數據集中在較小的取值區間,少數點取值很大。
通過這些箱線圖,你可以快速發現哪些特征有異常值、分布是否偏態、數據是否集中等,為后續的數據清洗和建模提供依據。
?
維度3:密度圖:連續性分析 - “數據如何變化?”
# 密度圖 - 顯示連續分布特征
data.plot(kind='density', subplots=True, layout=(3,3), sharex=False)
plt.show()
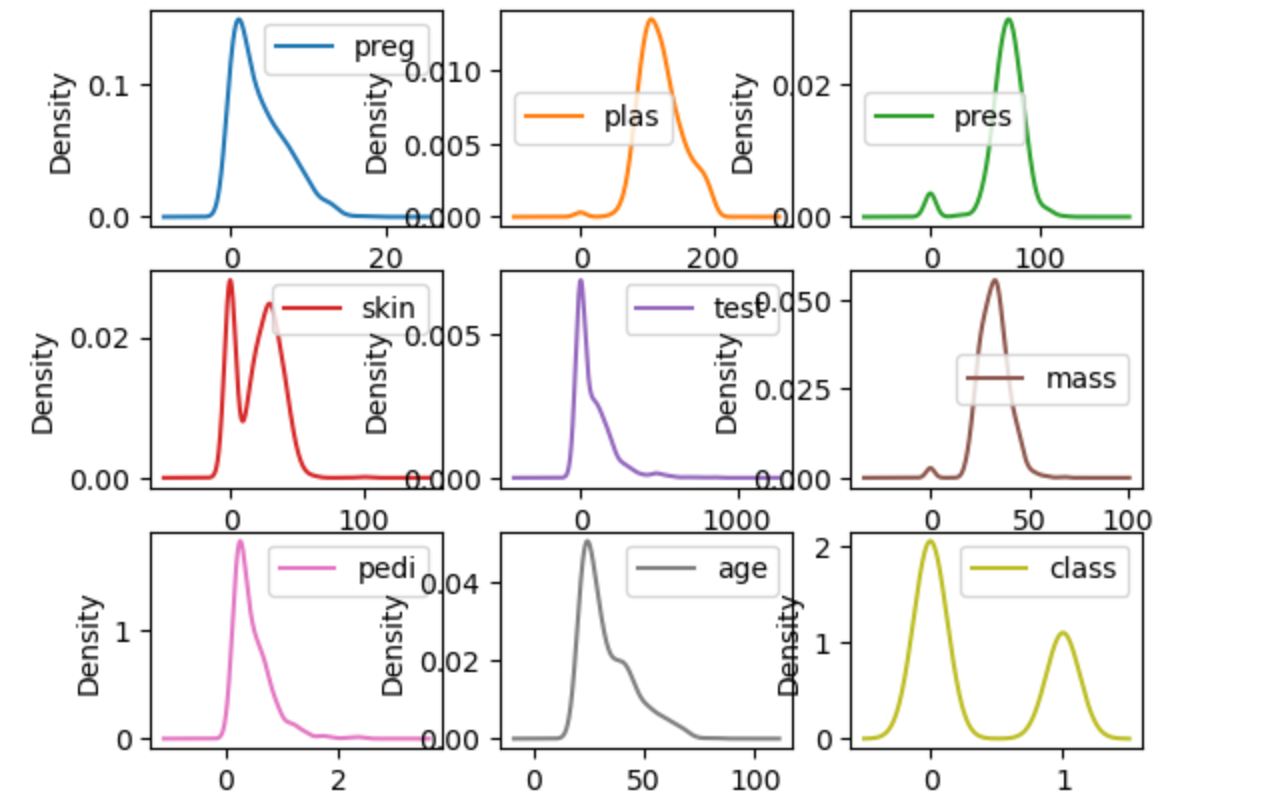
密度圖能說明什么?
- 數據的分布形態:可以直觀地看到數據是單峰(一個高峰)、多峰(多個高峰)、偏態(左偏/右偏)還是近似正態分布。 比直方圖更平滑,能更好地反映數據的真實分布趨勢。
- 數據的集中趨勢和離散程度:峰值高且窄,說明數據集中在某個區間。 峰值低且寬,說明數據分布較分散。
- 是否有異常分布或多重分布:如果密度圖有多個峰,說明數據可能由多個不同的子群體組成(多模態分布)。 可以輔助發現異常值(極端的孤立小峰)。
- 數據的偏態情況:峰值偏左,右側尾巴長,說明右偏(正偏態)。 峰值偏右,左側尾巴長,說明左偏(負偏態)。
核心洞察:密度圖能夠發現數據的平滑分布模式,識別潛在的數據生成機制。
?
維度4:熱力圖:關聯強度分析 - “特征間如何影響?”
import numpy as np# 相關性熱力圖 - 顯示特征間關聯強度
correlations = data.corr()
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(correlations, vmin=-1, vmax=1)
fig.colorbar(cax)
ticks = np.arange(0, 9, 1)
ax.set_xticks(ticks)
ax.set_yticks(ticks)
ax.set_xticklabels(names)
ax.set_yticklabels(names)
plt.show()
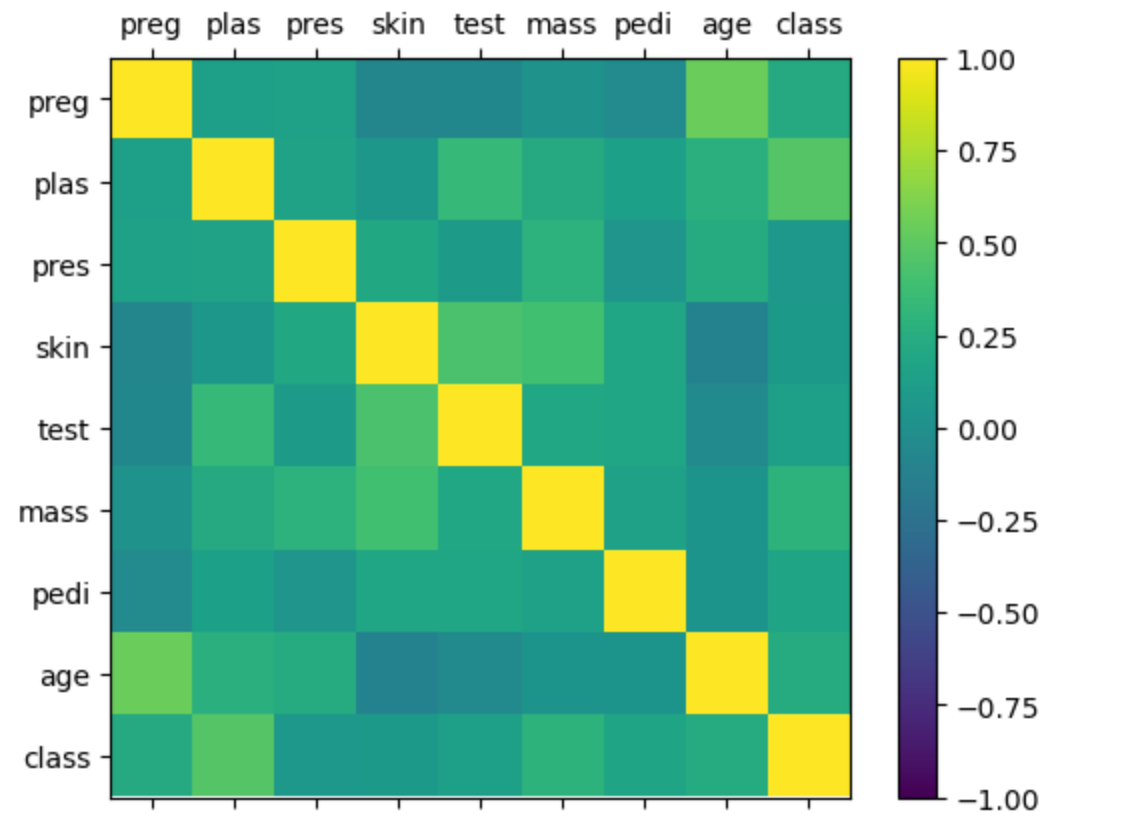
熱力圖是一種用顏色深淺來表示數值大小的可視化方式。在相關性熱力圖中,每個格子代表兩個特征之間的相關系數(correlation coefficient),顏色越接近黃色,相關性越強(正相關);顏色越接近深藍色,相關性越弱或為負相關。
熱力圖的作用
- 發現強相關特征:如果兩個特征高度相關,可能存在冗余,可以考慮去除其中一個,避免多重共線性。
- 發現無關特征:相關系數接近0的特征對彼此影響小,適合獨立建模。
- 輔助特征工程:根據相關性調整特征選擇、降維等策略。
圖中的對角線都是黃色(相關系數為1)。其他格子的顏色大多為綠色或青色,說明大部分特征之間的線性相關性不強。如果有某兩個特征之間的格子顏色明顯偏黃或偏藍,說明它們之間有較強的正相關或負相關關系。
?
維度5:關系模式分析 - “特征間如何交互?”
from pandas.plotting import scatter_matrix# 散點圖矩陣 - 顯示特征間非線性關系
scatter_matrix(data)
plt.show()
- 什么是散點矩陣圖?
散點矩陣圖會將數據集中的每一對數值型特征都畫成一個散點圖,排列成一個矩陣。 對角線上的圖通常是每個特征的直方圖(顯示該特征的分布)。 非對角線上的每個小圖,表示兩個特征之間的散點分布關系。- 散點矩陣圖能看出什么?
- 特征之間的關系:可以直觀地看到任意兩列特征之間的關系(線性、非線性、無關等)。
a. 如果兩個特征之間的點分布成一條直線,說明它們高度線性相關。
b. 如果點分布成某種曲線,說明它們有非線性關系。
c. 如果點分布很分散,沒有明顯形狀,說明它們之間沒有明顯關系。- 異常值: 可以發現某些特征組合下的極端點(離群點)。
- 分布特征:對角線上的直方圖顯示每個特征的分布形態(如正態分布、偏態、多峰等)。
- 多重共線性:如果某兩列的散點圖呈現出很強的線性關系,說明這兩個特征可能存在多重共線性。
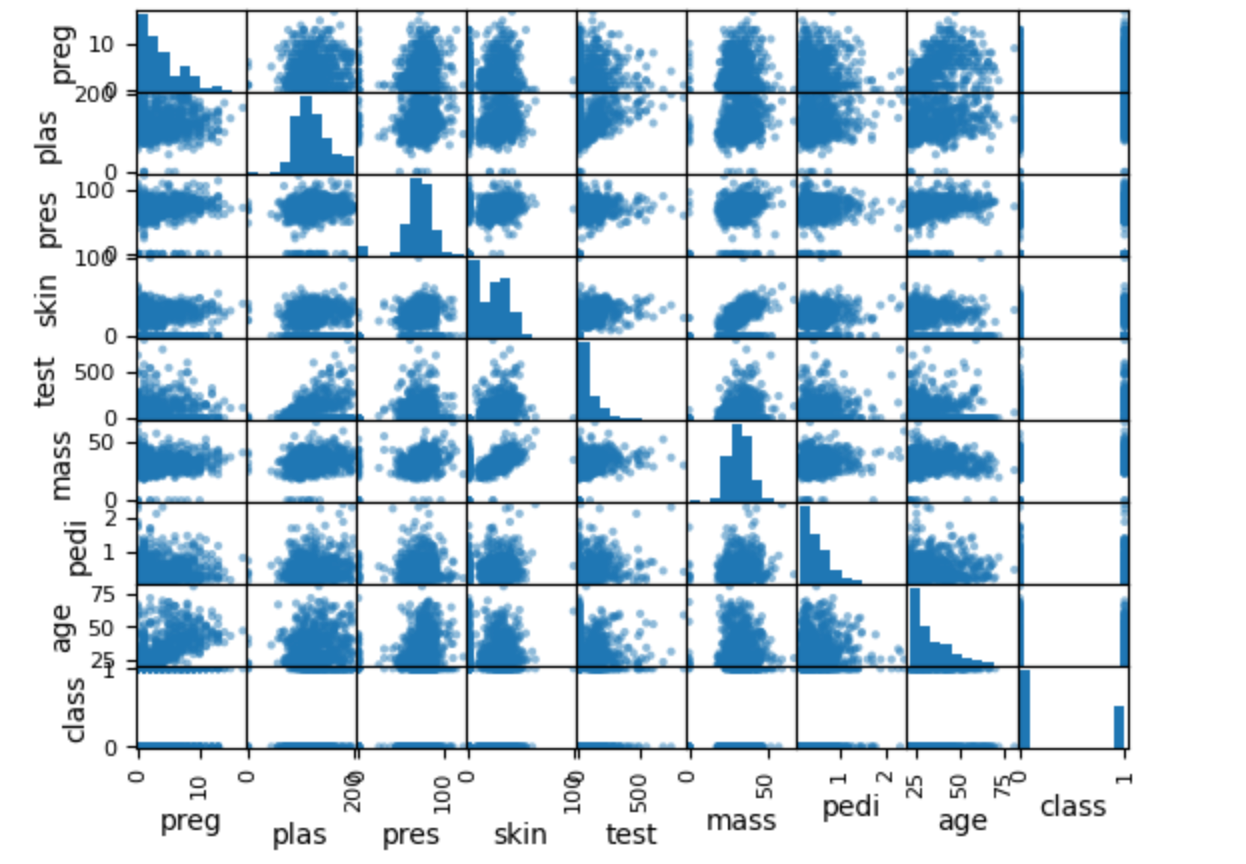
散點圖矩陣能夠全面、直觀地展示數據集中各特征之間的兩兩關系和各自分布。
幫助你發現特征間的相關性、異常值、分布形態等,為后續的數據預處理和特征工程提供依據。
?
2、"觀察-提問-決策"閉環系統
可視化分析的核心不是看圖,而是建立從觀察到決策的邏輯鏈條:
第一步:結構化觀察
- 分布形態:是否符合正態分布?
- 異常值:異常值比例和位置?
- 關聯性:哪些特征強相關?
第二步:關鍵問題提煉
- 數據質量:異常值是噪聲還是有價值的信號?
- 特征工程:是否需要變換或組合特征?
- 算法選擇:數據特征適合哪類算法?
第三步:決策規則制定
| 觀察結果 | 提問 | 決策行動 |
|---|---|---|
| 數據嚴重偏態 | 是否需要變換? | 應用對數變換或Box-Cox變換 |
| 存在強相關特征 | 是否存在冗余? | 考慮降維或特征選擇 |
| 發現異常值聚集 | 是否為特殊群體? | 分層建模或異常檢測 |
| 非線性關系明顯 | 線性模型是否適用? | 選擇基于樹或核方法的算法 |
?
1、示例說明
假設通過五維可視化發現:
- 直方圖顯示:目標變量呈現雙峰分布;
- 箱線圖顯示:某特征存在大量異常值;
- 相關性圖顯示:兩個特征高度相關(r>0.8);
- 散點圖顯示:特征與目標存在明顯非線性關系。
決策邏輯:
- 雙峰分布 → 可能存在隱含的數據子群 → 考慮聚類或分層建模
- 大量異常值 → 需要異常值處理策略 → 使用魯棒性強的算法
- 高度相關特征 → 存在多重共線性 → 進行特征選擇或正則化
- 非線性關系 → 線性模型不適用 → 選擇隨機森林或XGBoost
最終決策:使用隨機森林算法 + 特征選擇 + 異常值處理的組合策略
?
2、可視化驅動的工作流
?





的技術面試題)

)

AI編程的下一個范式革命——看Factory AI如何重構軟件工程?)




)




