今天給大家分享下最近幾個典型的數字后端項目案例,希望對大家的學習和工作有所幫助。
數字IC后端培訓教程之數字后端項目典型項目案例解析
Q1:星主,有啥辦法可以看到refinePlace或者ecoPlace都動到了那些inst嗎,log里只會有mean和max move,是不是只能寫腳本抓全部inst,看看前后inst位置有沒有變化?
工具本身不支持報告所有被挪動的instance。但一般做timing eco階段我們要密切關注log中報告的instance挪動的數量。這個數量要盡量小,否則對于高性能設計很容易出現timing惡化的情況。
順帶分享下高性能設計在做Timing ECO或Function ECO時的一個策略——做之前先把原先的所有instance都fixed住,這樣可以確保后續refinePlace或ecoPlace過程不會動到其他不該動的instance。
set all_cells [get_cells -hier -filter "@is_hierarchical == false " -physical ]
set fixed_cells [filter_coll $all_cells "@is_fixed == true"]
set_attr $all_cells is_fixed true -q
source $timing_eco_script
place_eco_cells -eco_changed_cells -legalize_only -legalize_mode
Q2:老師好,我t28項目routeopt一直優化不下去,我重新做了三次,routeopt連續優化了五次,第一次優化需要4個小時,wns從-2.0ns多變成-0.6ns,之后再優化一直在在0.6左右,wns最好的一次在400多ps,您可以看看是什么原因嗎 ?
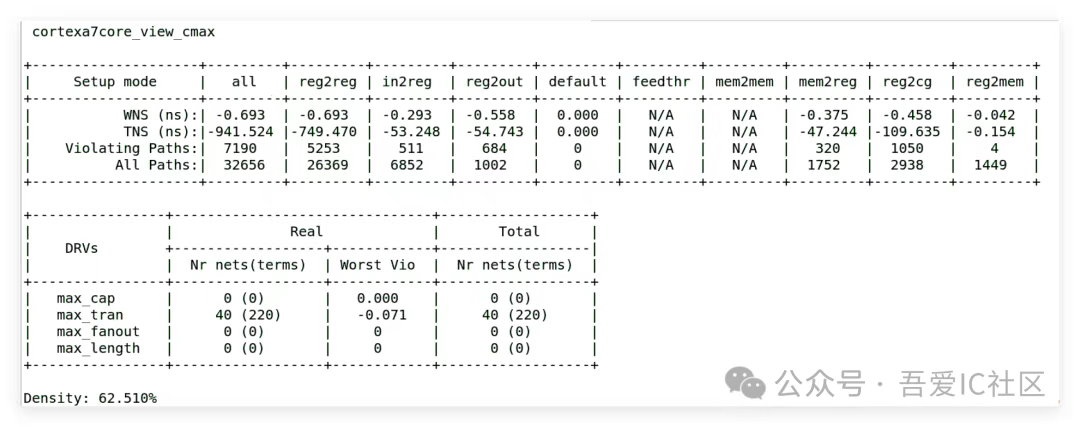
單純從上面的timing summary報告,我們發現WNS最大的是在reg2reg group path上,而且WNS高達-674ps!
而且我們看到當前設計的Density也才62.5%。這說明當前violation并非面積不夠導致的。
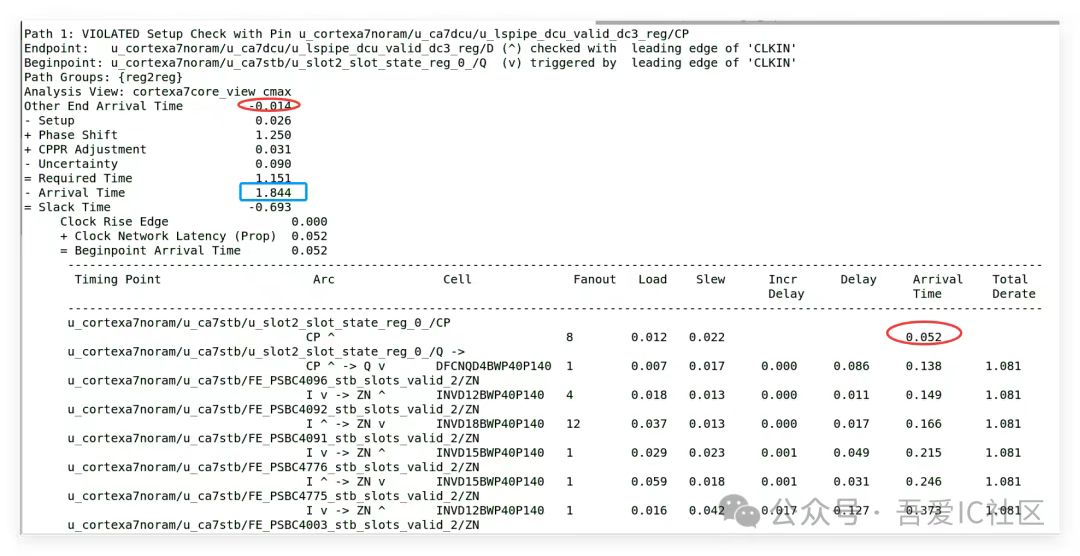
接下來我們具體來看看這條674ps timing violation的具體路徑以及layout上這條path是如何走的。
史上最全的數字IC后端設計實現培訓教程(整理版)
把這條timing path高亮在layout上后如下圖所示:

從這里很直觀看到繞線后存在比較嚴重的routing detour!
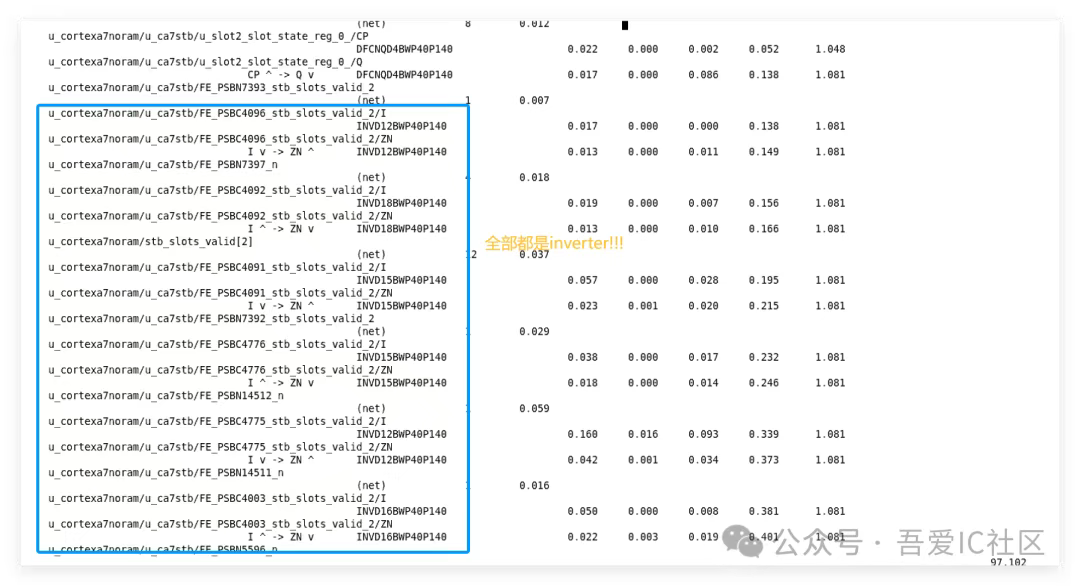
從上面那條timing path的具體路徑也可以看到存在一大堆的buffer和inverter。下圖所示框出來的部分全部都是普通inverter(從邏輯設計角度,這些inverter都是不需要的)!
這里也可以用咱們直播課講的快速獲取timing path邏輯深度和普通buffer,inverter的腳本來快速獲取到buffer和inverter的級數。

從上面獲取的結果得知,這條timing path上存在30顆buffer,inverter! 所以這條timing path是極度不合理的。
那為了定位哪個階段開始timing變成了,我們需要打開postCTS后的時序summary。
從下面這個postCTS的timing summary報告看到postCTS做完timing是一片大好!所以問題就出現在繞線階段。

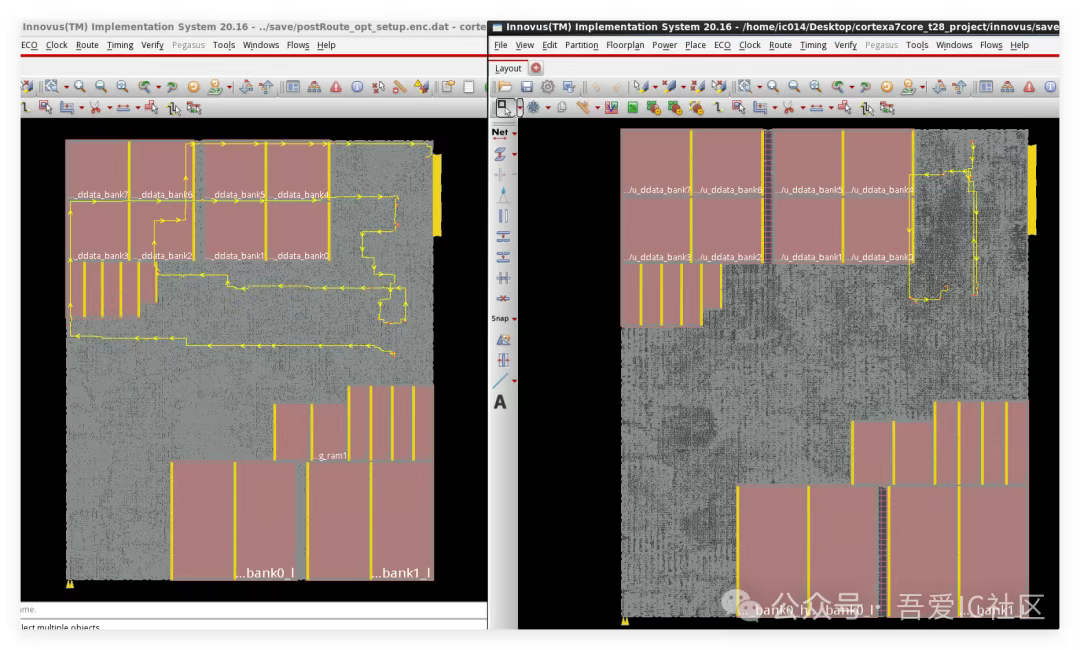
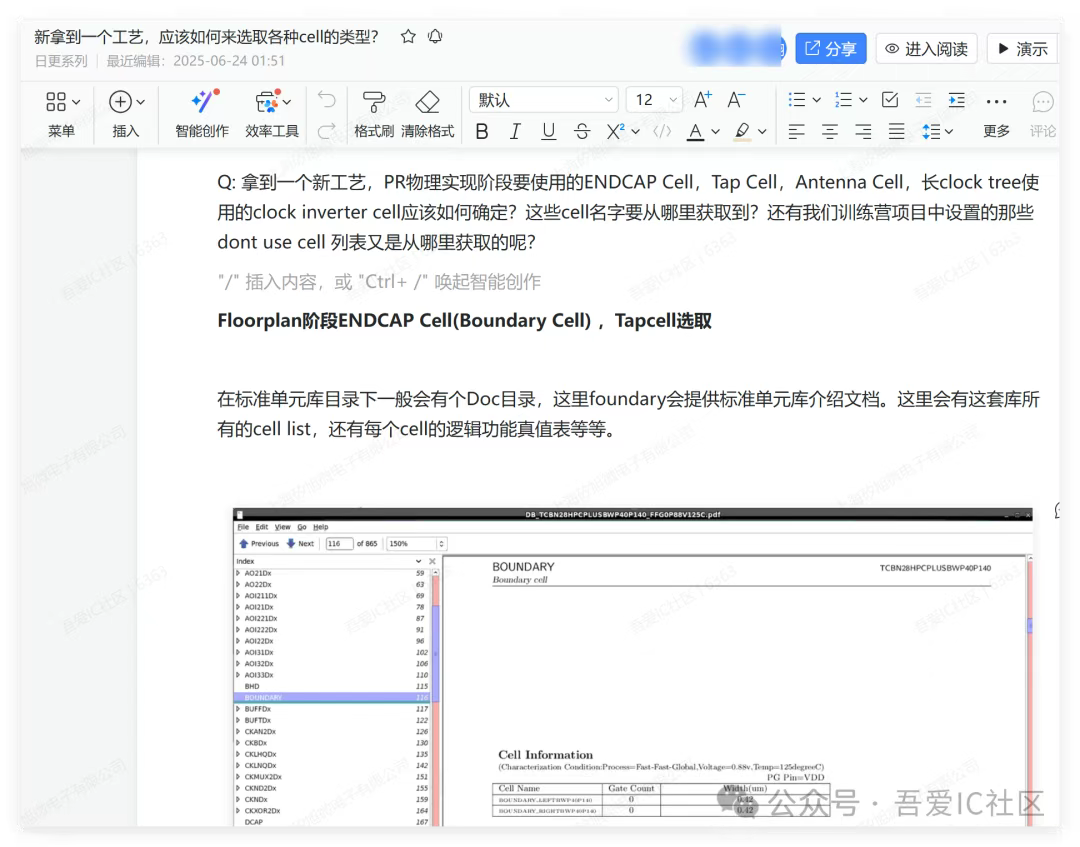
Q3:拿到一個新工藝,PR物理實現階段要使用的ENDCAP Cell,Tap Cell,Antenna Cell,長clock tree使用的clock inverter cell應該如何確定?這些cell名字要從哪里獲取到?還有我們訓練營項目中設置的那些dont use cell 列表又是從哪里獲取的呢?
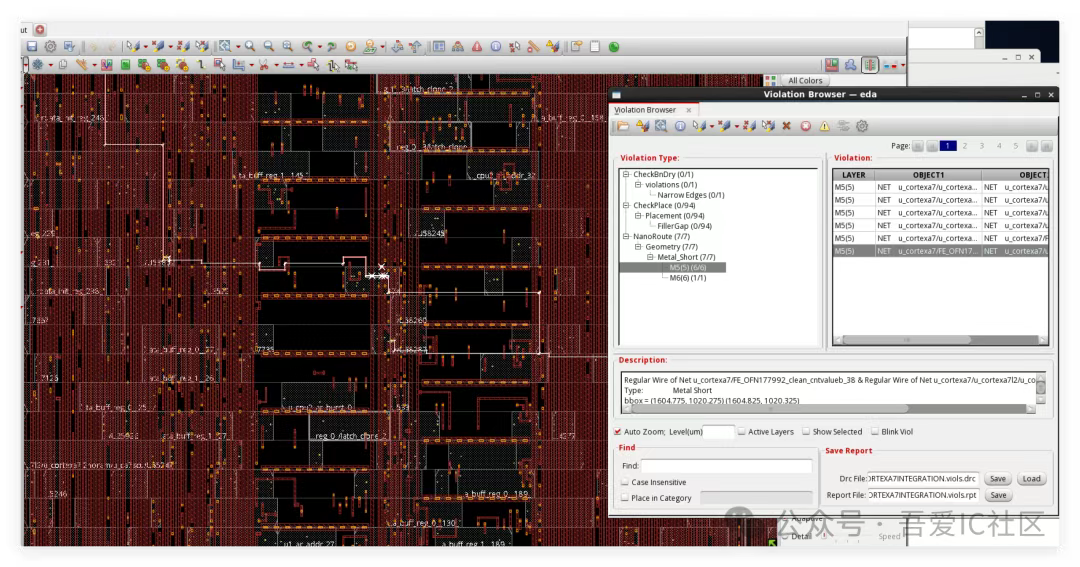
Q4:請問如下所示的Metal Short應該如何修復?
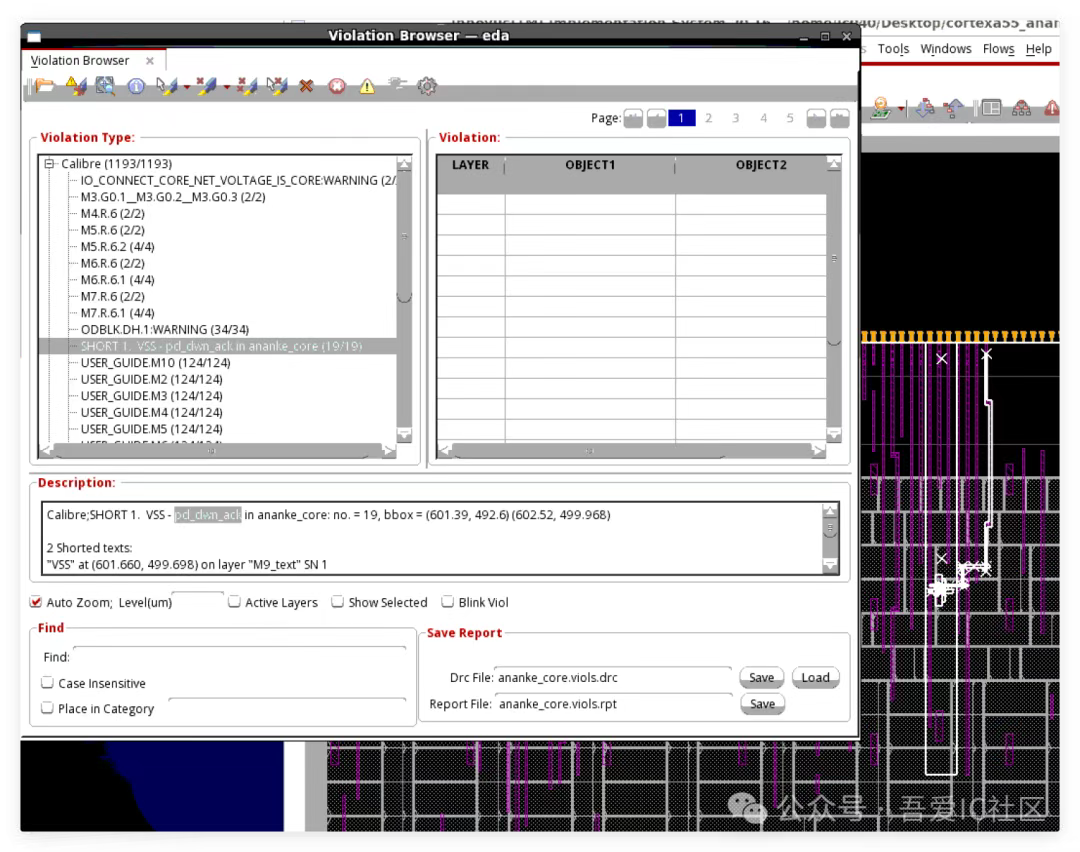
Q5: 在做T12nm A55 chipfinish后發現存在好幾個VDD_CORE的open問題,而且看起來是出現在power off domain中帶secondary pg pin的tap cell VPP pin上,請問應該如何修復?另外做Calibre LVS檢查也報告了有個io port和VSS short問題,高亮如下圖所示,請問這個是什么問題呢,應該如何進行修復?
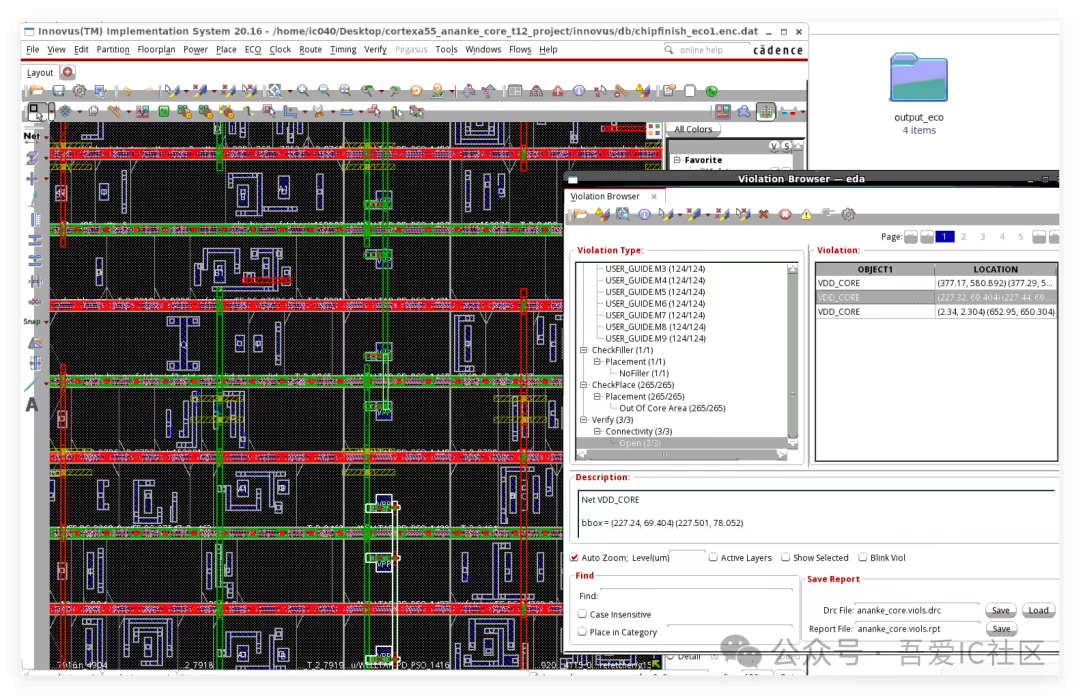
從高亮的圖形及位置很明顯是報在tap cell的VPP pin上。而且這個學員發現這個M1 VPP Pin已經通過via1,m2,via2和m3連通了,所以該學員認為這個不能算open。
我們說判斷一個pg pin(邏輯連接到VDD_CORE)是否open,核心是看它和最高層的VDD_CORE是否有實際的物理連接通路。所以,在咱們T12nm A55項目中這個M3還需要連接到M9的VDD_CORE!
下圖所示為其他tap cell VPP Pin連接正常的截圖。從這張圖可以看到連接Tap Cell VPP pin的M3會通過via3過渡到M4,然后在拉到power switch cell上的Global VDD_CORE mesh上(M1到M9的物理通路就建立起來了)。
關于pd_dwn_ack串鏈信號跟VSS Short問題,小編通過選中這個io port,發現它的邏輯net是VSS,這就說明這根信號目前是連接到1’b0!但對于需要連接到1’b0的信號,都必須通過Tie Low cell再到VSS。
這類串鏈信號如果設計中的確要用到,則需要連接到power switch cell上的Nsleep信號上。
所以這里大概率就是該學員在PR Flow中沒有做addTieHiLo這個步驟。而且對于設計中包含多個power domain的設計,還需要分別對每個power domain來添加tie cell。
setTieHiLoMode -prefix Tie -maxFanout 8 -maxDistance 20 -cell “TIEHBWP16P90CPD TIELBWP16P90CPD”
##addTieHiLo
addTieHiLo -powerDomain PD_PSO
addTieHiLo -powerDomain PD_AW_ON
Q6: 星主,用的是innovus請教個兩個問題①我的模塊是細長的模塊,模塊高度達到8000um,我想 極限做短時鐘latency 有沒有什么方案?②我看了cts skewgroup報告,比如skewgroup報告里 某個時鐘顯示的最大latency 700ps,但我打開cts timingreport 報告里面,從port端口到該時鐘 某個reg的latency達到了900ps,和skewgroup里不一致,這個是什么原因?
細長的模塊通常有DDR,顯示相關控制芯片。這種形狀通常會有明顯的timing和congestion問題。
想得到timing和drc上一個比較好的結果,我們就需要從以下幾方面入手:
1)clock tree長度做到最短。clock tree上主干時鐘的clock cell都需要手工引導工具做擺放。這種做法類似咱們社區復雜時鐘clock gen項目使用的manually place clock cell方法來做短clock tree長度。
2)設計中的各個module擺放也需要按照data flow人工干預,比如通過添加region等方式。
clock tree latency不一致主要有兩個原因:
skew group report里面的clock tree latency是不包含ocv derating的
PR flow中使用useful skew也會導致工具會調整clock tree長度來優化timing
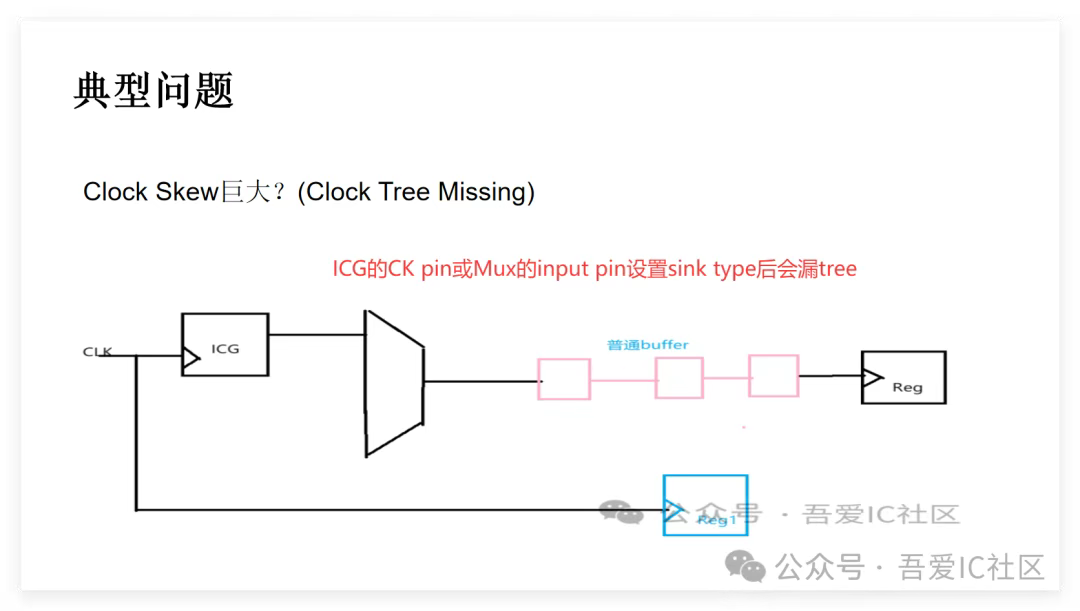
Q7: 匿名用戶 提問:星主,想請問通常會對icg 的enable close pin 設定負的insertion delay去減少icg 的setup time 問題,還是對于icg帶的sink 端設insertion delay 才是正確的?
對ICG的clock pin設置insertion delay,但需要注意這樣設置后,clock tree只能長到ICG 時鐘pin,從ICG輸出到后面寄存器Clock pin這段會漏clock tree。所以需要在ICG輸出定義時鐘,并把ICG和后面帶的寄存器擺放在一起。
Q8: 為何checkPlace結果會有5個cell orientation的錯誤?
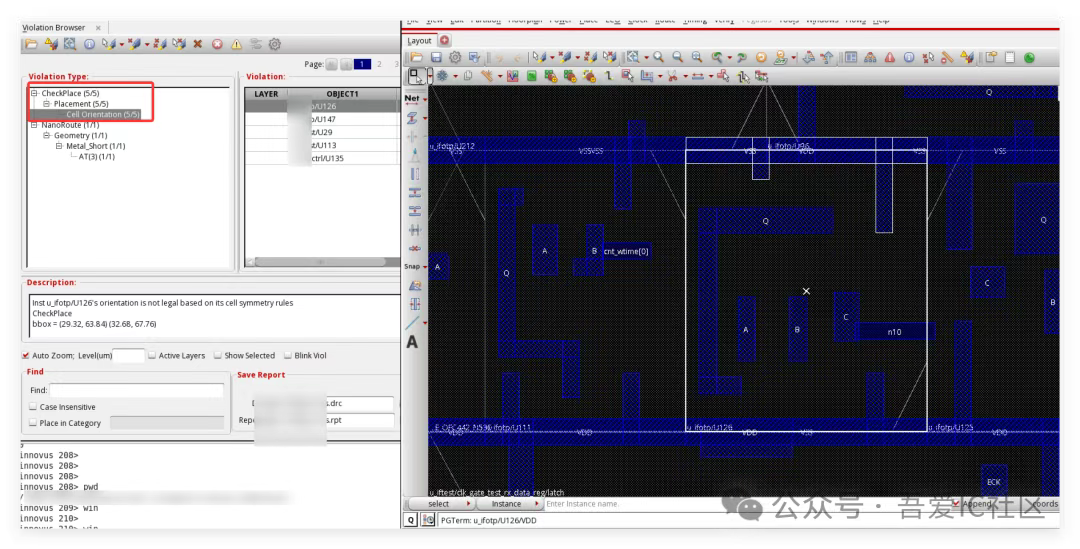
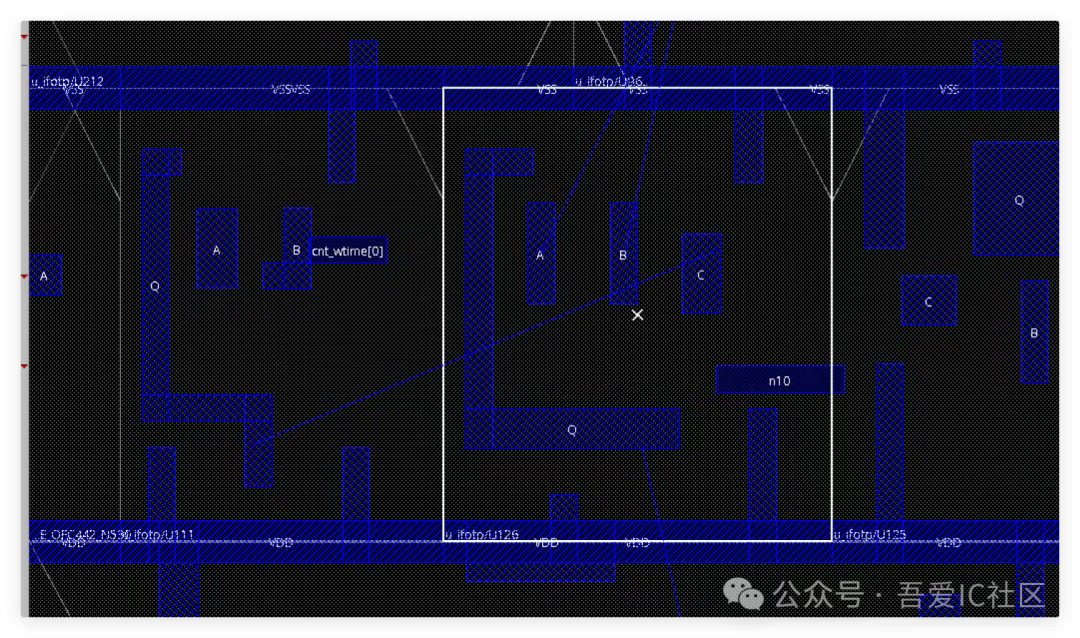
這個很明顯是這幾個cell的VSS PG Pin和VDD Power Rail重合了!需要把這幾個cell沿著X軸做一個鏡像!這個問題后續checkConnectivity和Calibre LVS也會報short錯誤。
)

AI編程的下一個范式革命——看Factory AI如何重構軟件工程?)




)










)
)