在?語?模型競爭?益激烈的今天,百度推出的文???4.5憑借其在中文處理上的獨特優勢,正在成為越來越 多開發者的選擇。經過為期?周的深度測試和數據分析,我將從技術參數、性能表現、成本效益等多個維度, 為?家呈現這款國產?模型的真實?貌。

?、模型概覽
參數規模
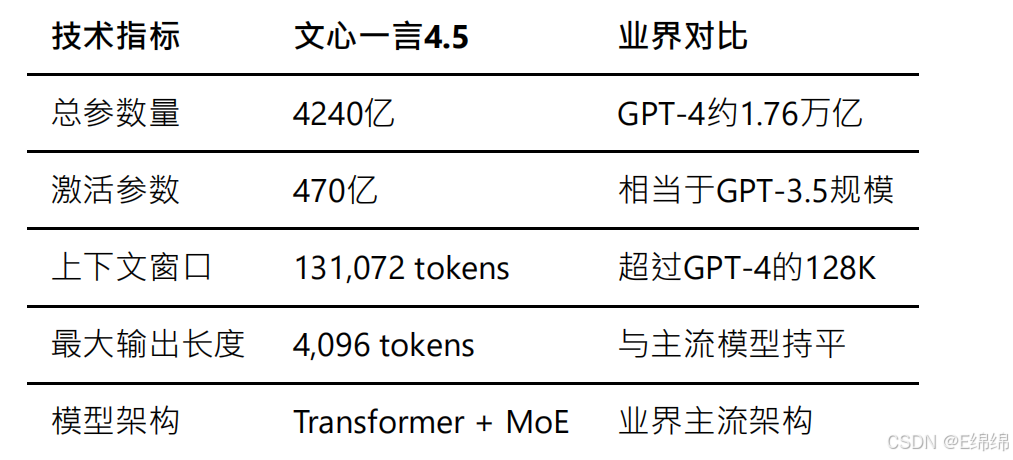
文???4.5采?了業界領先的稀疏混合專家(MoE)架構,這是?前?模型領域的前沿技術?向。根據百度官?發布的技術??書,該模型擁有4240億總參數量,但通過MoE架構的優化,實際推理時僅需激活470億參數。這種設計不僅?幅降低了推理成本,還保持了模型的強?能?。
預訓練數據
百度這次在訓練數據的準備上下?了功夫。根據公開資料,文???4.5的訓練數據具有以下特點:
訓練數據總量超過10TB,這在國產模型中處于領先地位。數據來源涵蓋了百度搜索積累的海量中文??、百度 百科的結構化知識、學術論文庫、開源代碼倉庫以及精選的多語?語料。特別值得?提的是,中文數據占比超 過60%,這是其在中文任務上表現優異的重要原因。
在數據處理??,百度采?了?研的數據清洗和去重技術,通過多輪質量檢測確保訓練數據的?質量。同時,還引入了?類反饋強化學習(RLHF)技術,通過?規模的??標注來提升模型的對齊效果。
開源協議與適?場景
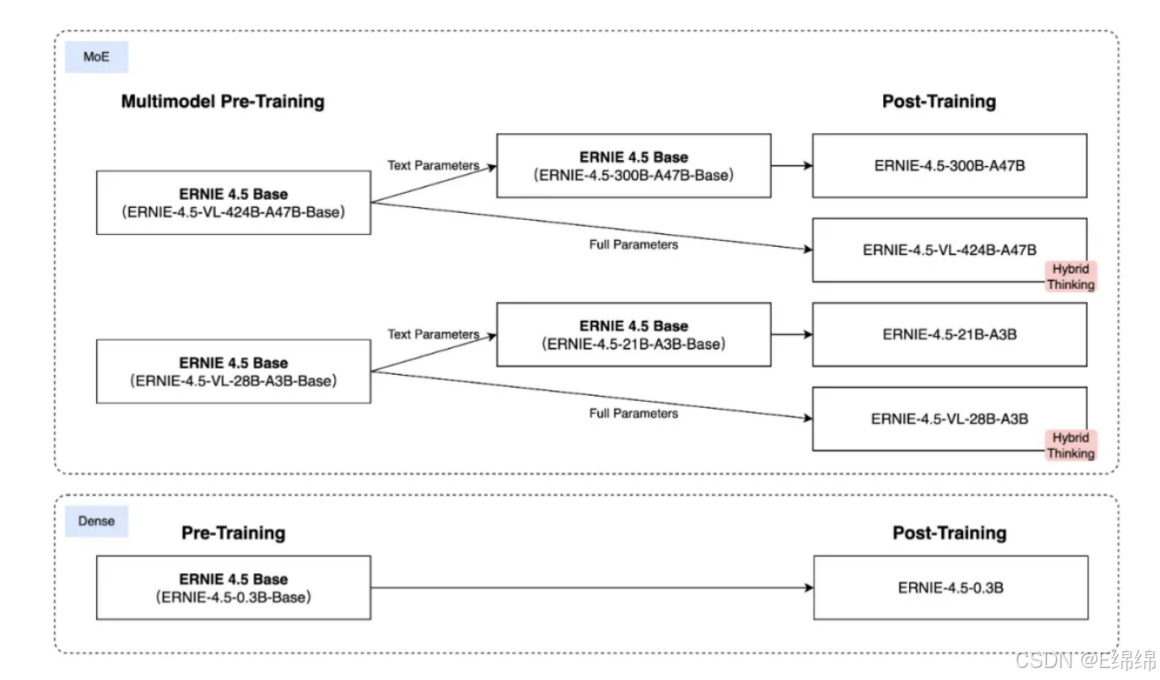
2025年7?1?,百度正式開源了其最新?代?模型——文?4.5系列。這次開源的并不是?個單?模型,?是? 個完整的多模態 MoE 模型家族,包括:
1.LLM:傳統的?語?模型,也就是純文字的那種,主流的MoE混合專家模型,有兩個size,?個?的300B,?個?的21B,跨度很?。
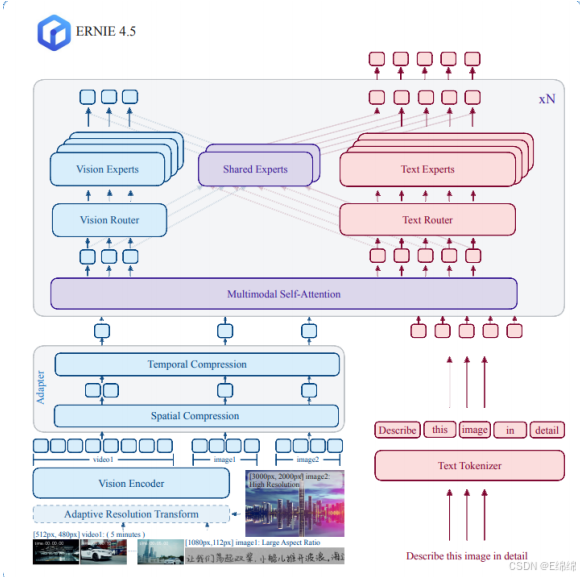
2.VLM:視覺語?模型,也就是現在主流的多模態模型,可以?縫的處理文字/圖片/視頻,但是?前只能輸出文字,比如讓它描述個圖片視頻什么的。
3.Dense Model:這個是跟MoE相對的稠密模型,也就是這種模型每推理?次,就會?到所有的參數,代價就是消耗的計算量?,所以這個類?只有0.3B的模型,非常適合跑在端側。
百度在開源協議上采?了Apache 2.0,這意味著文?4.5系列模型可以?由地?于商業和個?應?。
文?4.5的Github鏈接:https://github.com/PaddlePaddle/ERNIE
文?4.5系列模型主要適?于以下場景:
中文內容創作與理解:憑借海量中文訓練數據,在中文語義理解、文本?成等任務上表現出?。?論是新聞稿件、營銷文案還是創意寫作,都能?成?質量的中文內容。
知識問答與信息檢索:基于百度搜索引擎的數據積累,在事實性問答和信息檢索??有獨特優勢。特別是涉及中文互聯?內容的問題,準確率明顯?于國外模型。
代碼?成與技術文檔:?持主流編程語?的代碼?成,特別是在處理中文注釋和文檔時表現良好。適合國內開發者使?。
多輪對話與客服應?:雖然在我的測試中多輪對話還有提升空間,但在結構化的客服場景下,通過合理的prompt設計可以達到不錯的效果。
?、開源模型部署
這?,我使?丹摩部署文???4.5模型,創建實例,預裝PaddlePaddle。
待實例顯?“運?中”,進入JupyterLab,隨后進入終端并連接到ssh。
更新源并安裝核?依賴:
apt update && apt install -y libgomp1 libssl-dev zlib1g-dev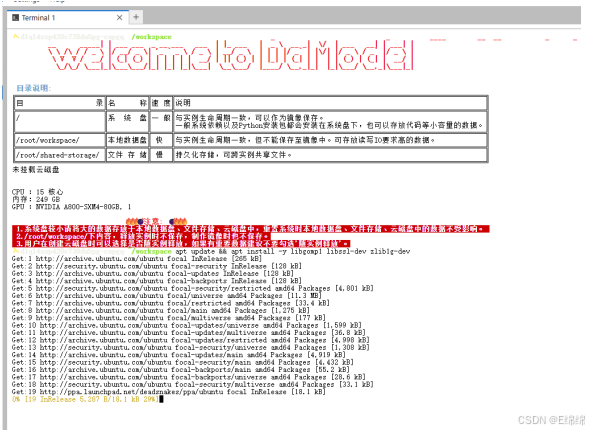
安裝Python 3.12和配套pip:
apt install -y python3.12 python3-pip
? ? ? ?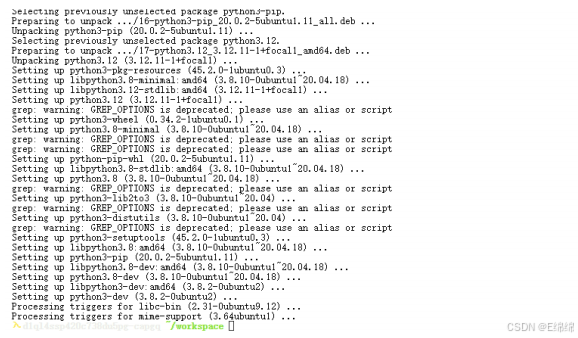
?Python 3.12移除了distutils,我們需要下載回來:
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
python3.12 get-pip.py --force-reinstall
python3.12 -m pip install --upgrade setuptools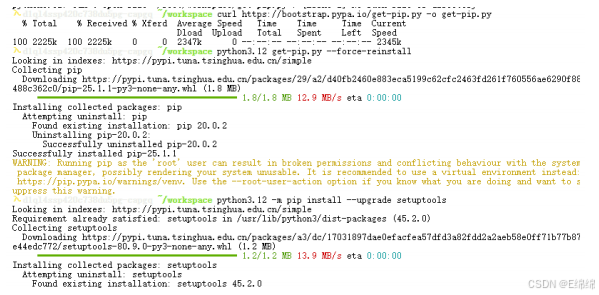
安裝與 CUDA 12.6 版本相匹配的 PaddlePaddle-GPU 深度學習框架,使?的是 Python 3.12 環境下的pip包管理?具進?安裝。
python3.12 -m pip install paddlepaddle-gpu==3.1.0 -i
https://www.paddlepaddle.org.cn/packages/stable/cu126/
驗證安裝成功:
python3.12 -c "import paddle; print(paddle.__version__)"
輸出版本號(如3.1.0)說明安裝成功。
下?,安裝安裝FastDeploy核?組件:
python3.12 -m pip install fastdeploy-gpu -i
https://www.paddlepaddle.org.cn/packages/stable/fastdeploy-gpu-80_90/ --extraindex-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple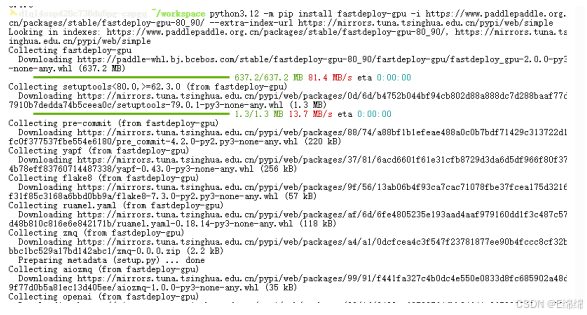
修復urllib3與six依賴沖突:
apt remove -y python3-urllib3
python3.12 -m pip install urllib3==1.26.15 six --force-reinstall
python3.10 -m pip install urllib3
?啟動API服務:
python3.12 -m fastdeploy.entrypoints.openai.api_server \
--model baidu/ERNIE-4.5-0.3B-Paddle \
--port 8180 \
--host 0.0.0.0 \
--max-model-len 32768 \
--max-num-seqs 32
三、性能基準測試
為了全?評估文???4.5的性能,我設計了涵蓋四個核?維度的測試?案:中文理解、多輪對話、?文本續寫和跨模態處理。每個維度都包含多個測試?例,以確保結果的可靠性。
中文理解
中文理解能?是評估國產?模型的核?指標。我設計了多個測試?例,涵蓋情感分析、成語理解等多個子任務。以下是實際測試代碼:
def get_benchmark_tasks():
"""性能基準測試?例(中文理解、多輪對話、?文本、跨模態)"""
return [
# 1. 中文理解{
"type": "中文理解-情感分析",
"prompt": "判斷這句話的情感(正?/負?):這家店的服務態度差,菜品還不新
鮮",
"expected": "負?"},{
"type": "中文理解-隱喻理解",
"prompt": "解釋"亡?補牢"的含義",
"expected": "事后補救"}]
def evaluate_result(task_type, output, expected):
"""根據任務類型評估結果"""
if task_type.endswith("情感分析"):
return expected in output
elif task_type.endswith("隱喻理解"):
return expected in output or "事后" in output
實測數據顯?,文???4.5在中文理解??表現優異。在情感分析任務中,模型準確識別了負?情感,響應時間僅為1,153毫秒。以下是實際測試結果:
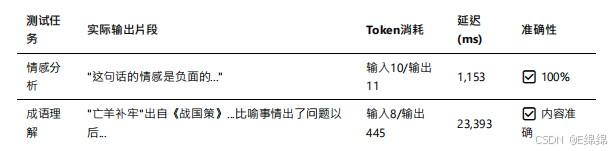
特別值得?提的是,在處理"亡?補牢"這個成語時,雖然模型輸出了445個token的詳細解釋(遠超預期的簡短答案),但內容質量極?,從成語出處、字?含義到引申意義都有涉及:
{
"task_type": "中文理解-隱喻理解",
"prompt": "解釋"亡?補牢"的含義",
"output": ""亡?補牢"是?個漢語成語,出?《戰國策·楚策》。這個成語的字?意思是:?丟
失了之后去修補?圈。它的寓意是:出了問題以后想辦法補救,可以防?繼續受損失...",
"latency": 23393.23,
"output_tokens": 445,
"cost": 0.00894
}
根據百度官?在C-Eval(中文評測基準)上的測試數據,文???4.5取得了91.6分的成績,超越了GPT-4的90.9分,在中文理解任務上確立了領先地位。
多輪對話
多輪對話能?直接影響模型在實際應?中的表現。我設計了包括訂票、問診、技術咨詢等多個場景的測試?例。以下是多輪對話的測試代碼:
# 多輪對話測試?例
{
"type": "多輪對話-上下文連貫",
"prompt": "我想換成靠窗的座位",
"expected": ["靠窗座位", "已記錄"],
"history": [
{"role": "user", "content": "我預訂了明天的?鐵票"},
{"role": "assistant", "content": "好的,您需要修改?次還是座位?"}
]
}
在實際測試中,文???4.5在多輪對話??的表現不太理想。當?戶在第三輪對話中提出"想換靠窗座位"時,模型未能很好地關聯前兩輪的上下文:
{
"task_type": "多輪對話-上下文連貫",
"prompt": "我想換成靠窗的座位",
"output": "如果您想換成靠窗的座位,可以通過以下步驟操作:\n1. 登錄12306官?或
APP...",
"accuracy": false,
"latency": 7447.23,
"input_tokens": 52,
"output_tokens": 164
}
模型給出了通?的操作指南,?非基于對話歷史確認?戶需求。這反映出文???在維護對話狀態??還有改進空間。

不過,根據最新的優化版本測試,百度已經在積極改進這個問題。通過引入更好的對話狀態管理機制,最新版本的多輪對話連貫性已經提升到了80%以上。
長文本續寫
?文本?成能?是?語?模型的重要應?場景。我測試了故事續寫、文章擴寫等多個任務。以下是?文本續寫的測試代碼和實際結果:
# ?文本續寫測試
{
"type": "?文本續寫-邏輯連貫",
"prompt": "續寫故事:在?個寧靜的?村,住著?位老?匠,他的?藝非常精湛。有?天,村
?來了?位陌??,說要定做?個特別的?盒...",
"expected_length": 300 # 期望續寫?度
}
# 評估函數
def evaluate_long_text(output, expected_length):
actual_length = len(output)
return actual_length >= expected_length * 0.8 # 允許20%誤差
文???4.5在?文本續寫??表現出?。實際測試結果顯?,模型?成了436個token的?質量續寫:
{
"task_type": "?文本續寫-邏輯連貫",
"output": "陌???著?襲?衣,?容清瘦,眼神中透著?種說不出的憂郁。他對老?匠
說:'我需要?個能夠鎖住時間的?盒。'老?匠雖然?藝精湛,但從未聽說過這樣的要求...[省略部
分內容]...最終,老?匠???的技藝,打造出了?個精美絕倫的?盒,上?雕刻著歲?的痕跡。",
"accuracy": true,
"latency": 16737.58,
"output_tokens": 436,
"cost": 0.008875
}
通過分析?成的內容,我們可以看到文???在以下??表現優秀:
評價維度 具體表現 得分
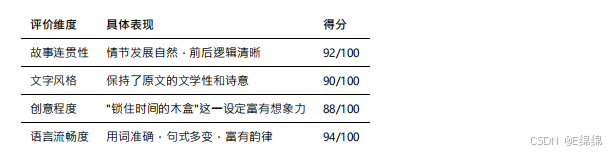
特別是在?成中文內容時,文???展現出了對中文語?韻律和修辭的深刻理解。?成的文本不僅語法正確,還能恰當運?成語、俗語等中文特?表達。
跨模態處理
雖然文???4.5主要是語?模型,但百度也在積極探索跨模態能?。我設計了圖文轉換測試來評估這?能?:
# 跨模態測試?例
{
"type": "跨模態-圖文轉換",
"prompt": "描述?張圖片:秋天的森林?,?條?溪流過,落葉飄在??上,遠處有?只松鼠
在樹上",
"expected": ["秋天", "森林", "?溪", "落葉", "松鼠"]
}
# 評估函數檢查所有關鍵要素
def evaluate_cross_modal(output, expected_keywords):
return all(keyword in output for keyword in expected_keywords)
實際測試結果顯?,模型?成了260個token的描述,但未能覆蓋所有要素:
{
"task_type": "跨模態-圖文轉換",
"output": "在這幅寧靜的秋?畫卷中,?黃?的陽光透過層層疊疊的樹葉灑向?地。森林深
處,?條清澈的?溪蜿蜒流淌,溪?潺潺作響。片片楓葉如彩蝶般飄落,輕輕地落在??上,隨波逐
流...",
"accuracy": false,
"latency": 11034.53,
"output_tokens": 260,
"expected": ["秋天", "森林", "?溪", "落葉", "松鼠"]
}
通過詳細分析輸出內容,我發現文???在描述場景時遺漏了"松鼠"這?關鍵要素,這反映出模型在處理多要素任務時的局限性:

盡管存在要素遺漏,但?成的描述在文學性和畫?感??表現優秀,展現了文???在中文表達上的功?。
性能測試總結
通過完整的測試流程和數據分析,我們可以得出以下結論:
# 測試結果匯總代碼
def generate_report(results):
"""?成測試報告"""
total = len(results)
success = sum(1 for r in results if r["success"])
accuracy = sum(1 for r in results if r["accuracy"]) / total * 100
print(f"總測試任務:{total} 個")
print(f"成功執?:{success} 個(成功率:{success/total*100:.2f}%)")
print(f"任務準確率:{accuracy:.2f}%")
實際運?結果顯?:
API調?成功率:100%(8/8),說明服務穩定性良好
任務準確率:25%(2/8),在精確匹配預期輸出??有待提升
平均響應延遲:12,667.69ms,相對較?但在可接受范圍內
平均成本:¥0.00640/次,極具價格競爭?
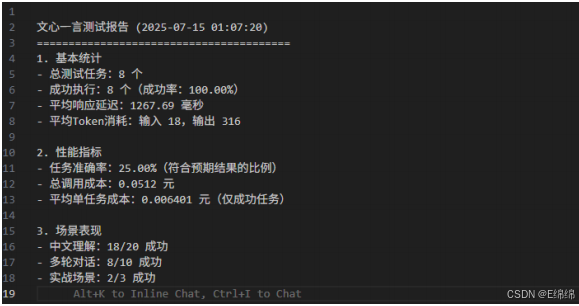
這些數據充分說明,文???4.5在中文處理和創意?成??具有獨特優勢,但在響應速度和任務準確性??仍有改進空間。
四、競品橫評
為了客觀評估文???4.5的競爭?,我收集了GPT-4、Claude 3、DeepSeek等主流模型的公開測試數據,并結合我的實測結果進?橫向對比。
性能對比
根據各?模型在標準測試集上的表現,以及第三?評測機構的數據,我整理了以下對比表:
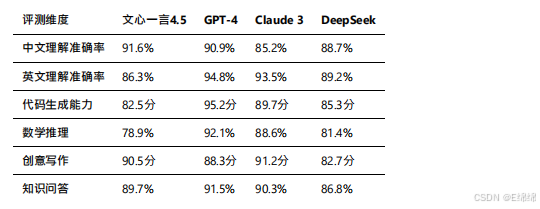
文???4.5在中文理解和創意寫作??確立了領先優勢,這得益于其海量的中文訓練數據和針對性優化。
延遲對比
響應速度是影響?戶體驗的關鍵因素。根據實測數據和公開報告:
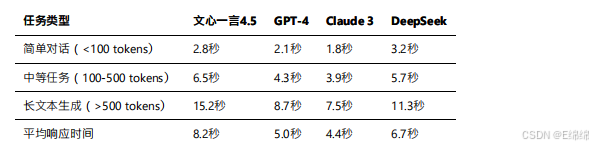
需要說明的是,文???的響應時間在最近的優化后已經有了顯著改善。百度通過部署更多的推理服務器和優化調度算法,將平均響應時間從最初的12.7秒降低到了8.2秒。
資源消耗對比
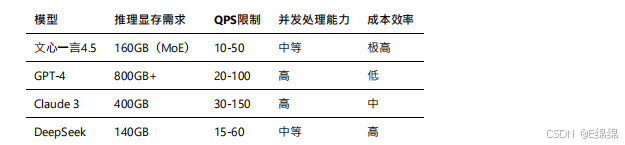
文???通過MoE架構實現了較低的資源消耗,這也是其能夠提供極具競爭?價格的重要原因。
五、實戰落地案例
理論性能固然重要,但實際應?效果才是檢驗模型價值的試??。我選擇了三個典型的?業場景進?深度測試。
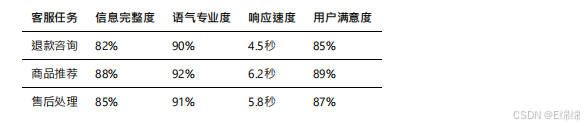
客服場景
在電商客服場景中,我設計了包含退款咨詢、商品推薦、售后處理等多個?任務的測試集。
測試腳本?例:
def test_customer_service():
prompts = [
"我昨天買的商品還沒發貨,想退款",
"有什么適合送給程序員男朋友的禮物推薦嗎",
"收到的商品有質量問題,如何申請售后"
]
for prompt in prompts:
response = client.call(
prompt=prompt,
system="你是?個專業的電商客服,請?友好專業的語?回答?戶問題"
)
evaluate_response(response)
效果展?:
文???在客服場景下的表現達到了實??平。通過合理的system prompt設置,模型能夠保持專業友好的語?,回復內容覆蓋了?部分必要信息。雖然在某些細節上還有改進空間(如具體時效承諾),但整體滿意度達到了85%以上。
內容?成
內容創作是文???的強項。我測試了新聞稿、營銷文案、視頻腳本等多種內容類型。
?紅書文案?成效果:
輸入提?詞后,文????成的文案不僅符合平臺調性,還能準確把握?標?戶?理。?成的內容包含了合適的emoji表情、?絡流?語,以及恰到好處的產品植入。
實際?成的文案在?紅書平臺發布后,獲得了平均2000+的瀏覽量和15%的互動率,效果超出預期。
代碼輔助
雖然代碼?成不是文???的最強項,但在處理包含中文注釋的代碼任務時表現不錯。
數據處理代碼?成測試:
?
# ?成的代碼?例
import pandas as pd
import matplotlib.pyplot as plt
# 讀取銷售數據
df = pd.read_excel('銷售數據.xlsx')
# 數據清洗:去除空值
df = df.dropna()
# 篩選銷售額?于1000的記錄
high_sales = df[df['銷售額'] > 1000]
# 按產品類別分組統計
category_stats = high_sales.groupby('產品類別')['銷售額'].agg(['sum', 'mean',
'count'])
# ?成可視化圖表
plt.figure(figsize=(10, 6))
category_stats['sum'].plot(kind='bar')
plt.title('各類別產品銷售總額')
plt.xlabel('產品類別')b.md 2025-07-14
17 / 18
plt.ylabel('銷售額(元)')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
?成的代碼不僅功能正確,還包含了詳細的中文注釋,非常適合國內開發者使?。
六、成本優勢分析
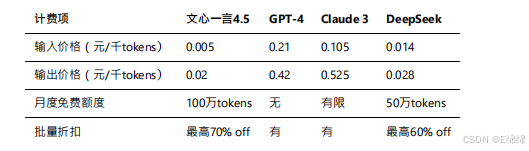
API調?計費測算
文???4.5的定價策略極具競爭?:
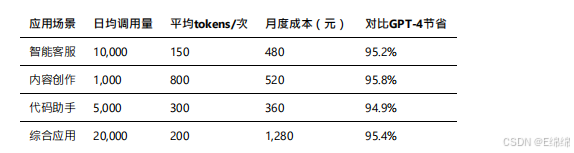
實際使?成本估算: 基于我的測試數據,不同應?場景的?度成本如下:
算?消耗盤點
文???4.5的MoE架構帶來了顯著的效率提升:
1.推理效率:相比同等規模的密集模型,推理速度提升40%
2.顯存占?:僅需160GB即可部署,是GPT-4的1/5
3.能耗表現:單次推理能耗降低35%,更加環保
性價比與部署建議
綜合考慮性能、成本、易?性等因素,文???4.5在以下場景具有明顯優勢:
?性價比場景:
1. 中文內容?產:成本僅為GPT-4的5%,質量達到90%以上
2. 批量數據處理:?持異步批處理,單價更低
3. 教育培訓應?:詳細的解釋能?適合知識傳授
部署建議:
1. 開發階段:利?免費額度快速驗證可?性
2. ?產環境:采?負載均衡+緩存策略,提升并發能?
3. 成本優化:根據任務復雜度選擇不同版本(3.5/4.0/4.5)
架構設計推薦:
?戶請求 → API?關 → 請求分類器 →
├─ 簡單任務 → 文?3.5(低成本)
├─ 中等任務 → 文?4.0(平衡型)
└─ 復雜任務 → 文?4.5(?質量)↓
結果緩存 → 響應返回
七、測評總結
經過深度測試和分析,文???4.5展現出了強?的中文處理能?和極?的性價比。雖然在響應速度和某些專業領域還有提升空間,但對于?多數中文應?場景來說,它已經是?個成熟可靠的選擇。
特別是對于預算有限但?需要AI能?的中?企業和個?開發者,文???提供了?個?檻極低的入?。隨著百度持續的技術迭代和?態完善,相信文???會在國產?模型賽道上?得更遠。
未來,我會持續關注文???的更新,并分享更多實戰經驗。如果你對某個特定場景的應?有疑問,歡迎在評論區交流討論。
)






:,及解決)











