專欄:大模型垂直應用技術?? ?????
個人主頁:云端筑夢獅
大模型應用落地亟需解決的核心問題有一個是:如何與私域數據交互。私域數據主要的問題是:需要有效地將企業數據整合進大語言模型中。由于大模型的上下文處理能力有限,一次性把太多的數據給到大模型是不現實的,所以必須精準的選擇出哪些數據在當前對話上下文中是有效的。
一.傳統RAG
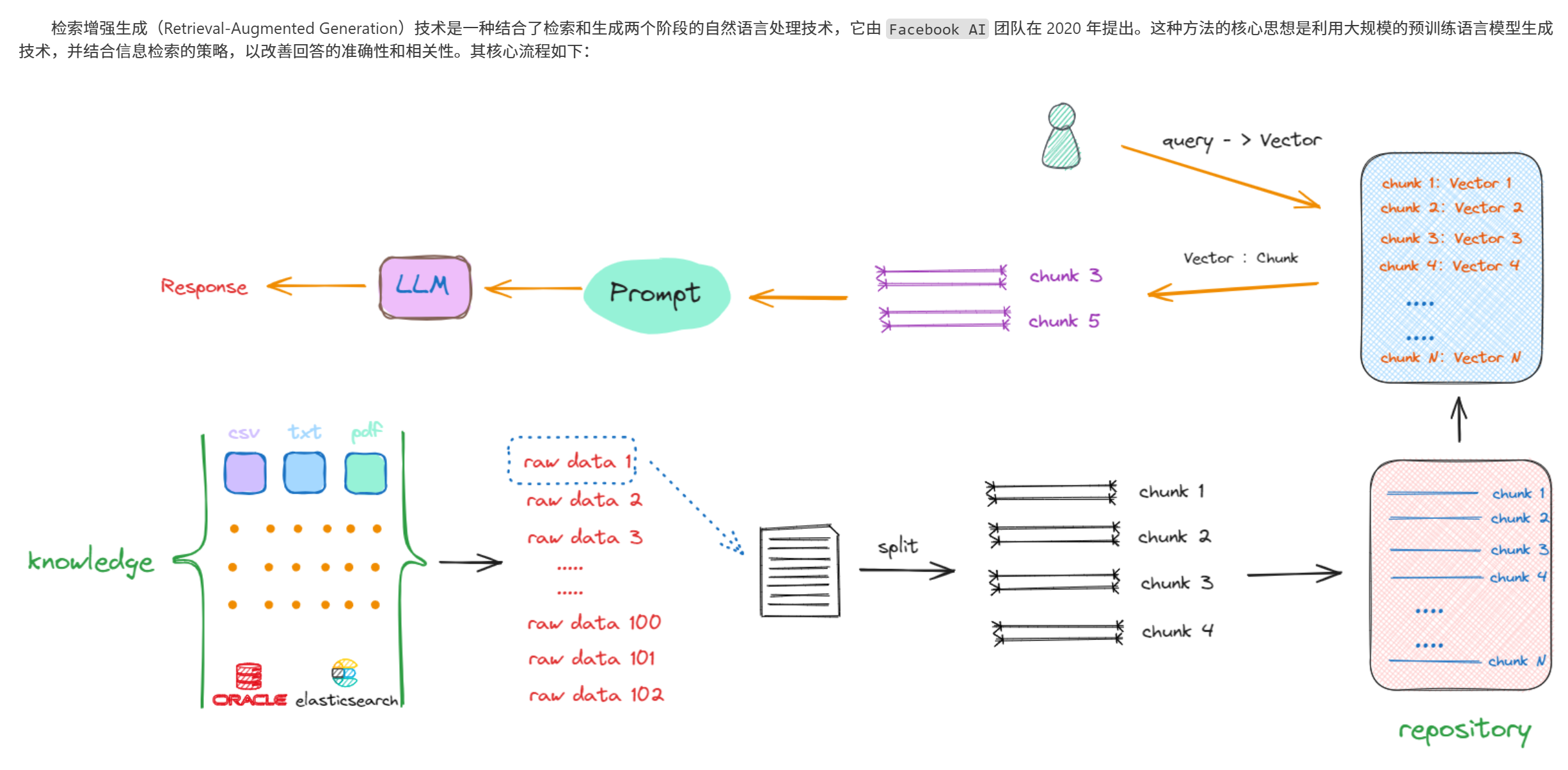
RAG`的實現是包括兩個階段的:檢索階段和生成階段。在檢索階段,從知識庫中找出與問題最相關的知識,為后續的答案生成提供素材。在生成階段,`RAG`會將檢索到的知識內容作為輸入,與問題一起輸入到語言模型中進行生成。這樣,生成的答案不僅考慮了問題的語義信息,還考慮了相關私有數據的內容。

傳統的RAG技術很難去搜索到全局信息,若問題散落在不同的語言塊中,基于傳統RAG就很難檢索到全局信息。
圖結構Graph的優勢在于:在圖譜中建立實體關系,從而檢索到全局的信息

GraphRAG可以向大模型提供結構化實體信息,文本與屬性的關系相結合,借助GraphRAG可以豐富上下文表示,但是GraphRAG的成本極高!
二. Microsoft GraphRAG(僅僅為GraphRAG的一種實現模式)

GraphRAG 整個 Indexing 過程可以通過以下簡單的方式來理解:
- 類似于 Baseline RAG,將源文檔分塊為較小的子文檔;
- 執行兩個并行提取:實體提取用于識別人名、地名、組織名等實體,關系提取:查找不同數據塊中實體之間的關系,比如朋友、同事,員工等;
- 創建知識圖譜,其中節點表示實體,邊表示它們之間的關系,比如張三是李四的朋友, 張三是王五的同事;
- 通過識別密切相關的實體來構建社區;
- 生成不同社區級別的分層摘要;
- 使用 reduce - map 方法通過逐步組合塊來創建摘要,直到實現整體概覽;
這個過程非常復雜,因此是需要一些配置文件來控制整個流程的。Microsoft GraphRAG 實現的是完整的索引構建流程邏輯,但具體到每個環節的一些關鍵參數,比如:文本分塊的大小,實體提取、關系提取的粒度,選擇使用的大模型,Embedding 模型等,都是需要通過配置文件來控制的。
1. 文檔加載器的輸入輸出格式---過程補
2.創建文本單元
準備好數據以后,才正式進入`Microsoft GraphRAG`實現的索引構建流程。其中,第一階段要做的事情是:將傳入的文檔內容進行分塊,然后生成`TextUnit`。`TextUnit`是用于圖提取技術的文本塊,同時會被提取的知識項用作源引用,以便能夠溯源到最原始的文本。

3.圖元素的提取?
在對文檔進行分塊成`TextUnit`以后,接下來就要對每個`TextUnit`中的內容進行圖元素的提取。 元素主要包括:實體、關系。

4.社區檢測

現在有了可用的實體和關系圖,但是這些實體和關系都是孤立的,沒有形成一個完整的圖譜。因此需要做的就是將這些實體和關系進行聚合,形成一個完整的圖譜。所以接下來的任務就是要將識別出來的實體和關系分組成相關關聯的子集。
社區檢索是圖論中的一個重要任務,旨在識別圖中節點的聚集結構。其中社區是指在圖中,節點之間的連接比與其他節點的連接更為密切的子集。通過識別社區,我們就可以理解數據的內在結構,發現潛在的模式和關系。其中萊頓算法(Leiden Algorithm)是一種用于社區檢測的高效算法,旨在優化社區結構的識別過程。它是基于 Louvain 算法的改進,具有更好的性能和準確性。
微軟實現的就是分層的萊頓算法(Hierarchical Leiden Algorithm),它將圖中的節點分成多個層次的社區,從而形成一個層次化的社區結構。
5. 生成社區報告
要做的就是對每個社區中的節點、關系和摘要的定義進行總結。這樣做的目的是為了方便查詢,當查詢時需要根據問題匹配知識庫中的實體信息和關系信息時,只需要根據總結后的實體描述和關系描述就可以進行匹配了。不然遍歷所有的`Description`進行匹配,效率會非常低下。

二.自定義接入圖數據庫與知識圖譜
Neo4j 是一個開源的 NoSQL 圖數據庫,它使用圖來表示和存儲數據。在 DB - Engines 排名中根據數據庫管理系統的受歡迎程度對其進行排名中,Graph DBMS 榜單中 Neo4j 排名第一。

)






)


)





)
實驗詳解,結尾有詳細腳本)
 SparseViT: 用于圖像篡改檢測的Spare-Coding Transformer)