文章目錄
- Makefile 的通用模板
- 1. Makefile 的推導原則
- 2. 設計 Makefile 的通用模板
- 3. 通用模板代碼(可以直接拿來用)
- Linux 第一個系統程序-進度條(7-3.00.00)
- 1. 補充回車與換行
- 2. 行緩沖區
- 3. 倒計時小程序
Makefile 的通用模板
1. Makefile 的推導原則
以程序的翻譯作為例子來引出
Makefile的推導原則。在Makefile中可以用警號(#)去注釋
code:code.o gcc code.o -o code
code.o:code.s gcc -c code.s -o code.o
code.s:code.i gcc -S code.i -o code.s
code.i:code.c gcc -E code.c -o code.i .PHONY:clean
clean: rm -rf *.o *.i *.s code

- 在
make時,code是依賴code.o的,可code.o文件在當前路徑下存在嗎?不存在,就向下去推導。 code.o是依賴code.s的,可code.s文件在當前路徑也不存在,又向下推導,最終來到了code.c,發現在當前路徑下存在該文件。- 就依次形成了
code.i,code.s,code.o,code。所以make會進行依賴關系的推導,直到依賴文件是存在的 - 這就類似于將依賴方法不斷入棧,推導完畢,出棧執行方法,這就是
makefile的推導原則

2. 設計 Makefile 的通用模板
通用做法:先將該路徑下的所有.c文件全部編譯成.o文件,再與動靜態庫進行鏈接,最終形成可執行程序,并不是直接將所有.c文件一股腦的形成可執行程序

1. 第一代版本,并不具備通用性,只適用于code.c這一個源文件
1 code:code.o
2 gcc code.o -o code
3 code.o:code.c
4 gcc -c code.c -o code.o
5
6 .PHONY:clean
7 clean:
8 rm -rf *.o code #下面的圖片寫錯了

2. 第二代版本,用變量的形式去進行替換,但也不是很通用,只適用于編譯一個文件
1 BIN=code #可執行程序2 SRC=code.c #源文件3 OBJ=code.o4 CC=gcc #編譯器5 RM=rm -rf #刪除命令6 7 # $(變量)->內容,比如:$(BIN)->code 8 # 照著下面改即可9 $(BIN):$(OBJ)10 $(CC) $(OBJ) -o $(BIN)11 $(OBJ):$(SRC)12 $(CC) -c $(SRC) -o $(OBJ)13 14 .PHONY:clean15 clean:16 $(RM) $(BIN) $(OBJ)17 18 #code:code.o19 # gcc code.o -o code 20 #code.o:code.c 21 # gcc -c code.c -o code.o22 # 23 #.PHONY:clean 24 #clean: 25 # rm -rf *.o code

3. 第三代版本,如果在當前目錄下有一百個或一千個源文件呢?怎么保證你的代碼寫的更加通用呢?
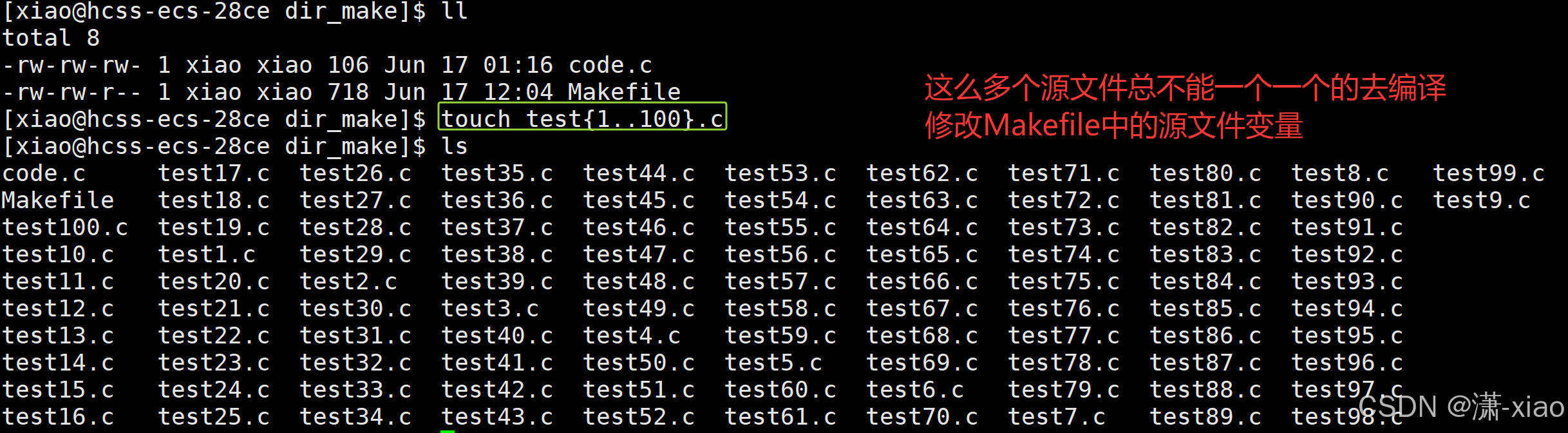
- 既然源文件從一個變成了100個,那賦值給變量也需要進行相應的修改。
SRC=code.c→$(shell ls *.c),把所有羅列出來的.c文件全部放到SRC里面 - 如何驗證變量
SRC里面放置了100個源文件列表呢?用依賴方法:echo $(SRC),打印到顯示器上 - 命令前面帶上
@符號,可以不用回顯命令執行的過程,只顯示命令執行的結果

- 想將100個源文件放置到變量
SRC也可以:SRC→$(wildcard *.c)。這里的wildcard就相當于一個函數,兩種用法是等價的 - 源文件的變量(
SRC)發生改變,則對應的OBJ也要發生變化。OBJ=code.o→OBJ=$(SRC:.c=.o),這是Makefile自己的語法,要求將SRC所有的源文件的.c換成.o,再賦值給OBJ,這個對于SRC和源文件是沒有影響的

- 接著就是依賴關系(
$(BIN):$(OBJ))+ 依賴方法(gcc $(OBJ) -o $(BIN))。這里的依賴方法還有另外一種寫法:gcc $^ -o $@,$^→$(OBJ),$@→$(BIN)

- 根據
Makefile的推導原則,當前路徑下并沒有.o文件,會向下推導。因此要形成.o文件,依賴關系(%.o:%.c)+ 依賴方法($(CC) -c $<) - 這里的
%符號就是Makefile中的通配符,%.o與%.c分別匹配所有的.o與.c文件。$<就是把%.c中的文件一個一個的拿出來交給對應的命令,再被gcc一個一個的編譯成同名.o文件

- 一個依賴關系后面是可以跟多個依賴方法的

3. 通用模板代碼(可以直接拿來用)
BIN=code #可執行程序
SRC=$(wildcard *.c)
#SRC=$(shell ls *.c) #源文件列表放到變量SRC中
OBJ=$(SRC:.c=.o)
CC=gcc #編譯器
RM=rm -rf #刪除命令 $(BIN):$(OBJ) @#gcc $(OBJ) -o $(BIN) 雖然加了警號,但不帶@,也會進行命令回顯 @$(CC) $^ -o $@ #加上@符號不讓命令回顯 @echo "鏈接 $^ 成 $@"
%.o:%.c @$(CC) -c $< @echo "編譯... $< 成 $@" .PHONY:clean
clean: @$(RM) $(BIN) $(OBJ) .PHONY:test
test: @echo $(BIN) @echo $(SRC) #不會讓命令進行回顯 @echo $(QBJ)
Linux 第一個系統程序-進度條(7-3.00.00)
1. 補充回車與換行

回車和換行是兩個動作,回車:先回到開頭,換行:新啟一行
2. 行緩沖區
通過有沒有帶
\n的變化來引出行緩沖區的存在
#include<stdio.h>
#include<unistd.h> int main()
{ printf("hello world"); sleep(2); return 0;
}
- 發現了一個現象:當字符串沒帶
\n時,hello world不會立即顯示出來。當帶了\n則會立即顯示出來hello world - 程序執行永遠是從上至下依次執行,那肯定是先打印(
printf)hello world,再去sleep,可結果好像是sleep了再打印? - 其實
printf這條語句已經執行完了,字符串是被存儲到了緩沖區(在內存處)中,而printf打印是將字符串打印到顯示器上 - 只不過顯示器的刷新策略是:行刷新(帶上
\n,就會將緩沖區的字符串刷新到顯示器上)。不帶\n,要么程序結束時進行刷新,要么手動強制進行刷新 - 手動強制進行刷新,可以用到函數
fflush,它的參數類型是FILE*。FILE* stdin(鍵盤),FILE* stdout(顯示器),傳入參數fflush(stdout)可立即刷新

#include<stdio.h>
#include<unistd.h> int main()
{ printf("hello world\n"); sleep(2); fflush(stdout); return 0;
}
3. 倒計時小程序
- 光標控制,當向光標所在位置寫入一個字符后,光標會自動地向后移動。那就可以先往光標處打印9,再讓光標回車到開頭顯示8,將這個過程循環往復,直至光標處顯示0

- 為了解決上面的問題,可以用到回車符(
\r),因為顯示器的刷新策略,還得進行手動強制刷新:fflush(stdout)

- 但是當程序從兩位數開始倒計時(
cnt = 10),就會依次打印10,90,80,...。這是因為顯示器它只認字符,比如當你往顯示器打印1234時,并不是打印整數1234,而是一個字符一個字符的打印1,2,3,4 - 這也是為啥顯示器叫字符設備的緣故,
printf("%d\n", 1234),printf打印要對這個整數進行格式化,格式化是將這個整數轉成字符再進行輸出 - 所以從兩位數倒計時,
cnt必須占兩個字符(printf("%2d\r", cnt),只不過格式化輸出定長控制的時候,不足對應的位置默認是右對齊的(空格在左邊),所以2前面得加個負號,就能居左對齊
int main()
{int cnt = 15;while(cnt >= 0){printf("%-2d\r", cnt);fflush(stdout);cnt--;sleep(1);}printf("\n");return 0;
}



















