
【導讀】
本文提出了一種使用搭載計算機視覺的智能無人機估算藍莓產量的方法。系統利用兩個YOLO模型:一個檢測灌木叢,另一個檢測漿果。它們協同工作,智能控制無人機位置和角度,安全獲取灌木近景圖,實現精準的漿果計數和產量估算。實驗展示了模型在裁剪圖像上的良好效果,并討論了部署時的采樣策略、小目標(藍莓)標注及模型評估的挑戰。
目錄
一、相關工作
二、處理流程
分層采樣
單株灌木檢測
灌木側視圖像采集
三、數據集
數據采集
漿果數據集
數據標注
四、YOLO目標檢測
訓練
驗證
DeepSORT追蹤
實驗結果
漿果模型
灌木模型
灌木裁剪漿果模型
五、討論
六、結論
人工智能與自主無人機相結合的精準農業技術,已被證明不僅能有效估算多種作物的產量,還能用于雜草和病害檢測管理。藍莓作為重要的經濟作物,其生長季早期的產量預測對農戶制定定價策略、安排充足采摘人員以及提前向分銷商通報供應量具有關鍵意義。

論文標題:
Accurate Crop Yield Estimation of Blueberries using Deep Learning and Smart Drones
論文鏈接:
https://arxiv.org/pdf/2501.02344
本研究提出基于YOLO(You Only Look Once)深度學習架構的目標檢測模型流程,通過編程控制智能無人機精準捕獲藍莓灌木圖像并檢測每株灌木的可采收漿果數量(圖1展示典型藍莓灌木示例),進而實現田間產量估算。創新點在于:不僅能檢測整株灌木上所有可見漿果,還通過灌木檢測確保無人機精準定位和圖像采集。這種智能任務模式與傳統自主任務的區別在于:后者需在任務前預設無人機飛行路徑(如沿灌木行保持固定距離飛行),且攝像頭以固定視角拍攝。但若因風力或GPS信號丟失導致位置偏移,無人機無法實時調整與灌木的距離或攝像頭視角進行補償。

而搭載灌木檢測模型的無人機能執行更智能的任務:在保持安全距離前提下,實時調整飛行位置緊貼灌木叢飛行,獲取漿果顯示尺寸最大化的最優灌木視角。這使系統無需預先獲取每株灌木的精確GPS坐標即可實施分層隨機采樣等策略——而這正是自主任務必需的前提條件。結合實時動態定位技術(RTK),流程還能實現藍莓田的精準測繪:先通過灌木模型對每株灌木進行地理標記,飛行后再用漿果模型統計單株漿果數量。配合第三節描述的田間數據,該方案能獲得比現有方法更精確的產量估算結果。
一、相關工作
涉及藍莓的具體研究有:采用YOLOv3-v4模型檢測手持設備拍攝藍莓的成熟度(后者針對野生藍莓);應用Mask R-CNN模型分割單顆藍莓以評估成熟階段;基于U-Net架構開發無人機圖像的行間分割模型;提出僅標注藍莓灌木主干的檢測模型。與之對比,灌木檢測模型要求識別完整灌木叢,這對產量精確估算至關重要。
現有研究中極少有通過人工采摘驗證單株果實數量的工作。為構建驗證數據集,人工采摘了15株藍莓灌木的全部果實獲取實際數量(稱為"采摘真值")。這類研究稀缺的主要原因是農業產量通常按重量而非果實數量記錄。相關驗證工作主要針對蘋果、芒果等大型果實,以及杏仁和葡萄,但均未如本文那樣詳細討論單株可見果實與實際果實的比例關系——這對理解遮擋程度具有重要意義。
二、處理流程
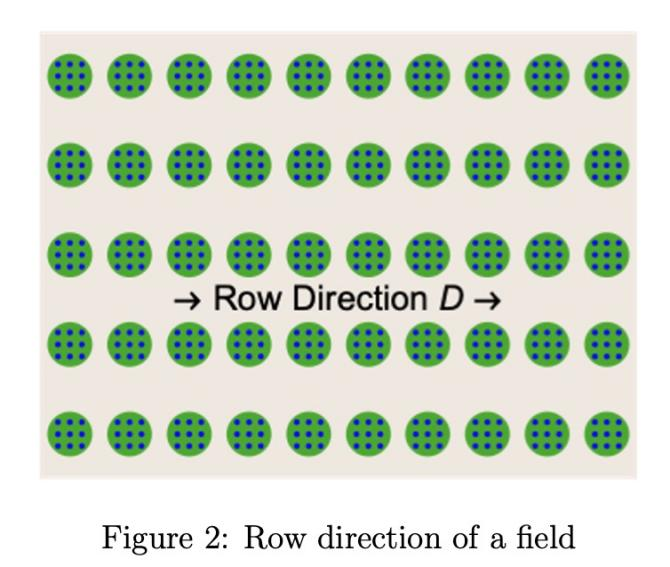
設F為二維矩形藍莓田,面積A(英畝),包含C株灌木。假設已知田塊角點GPS坐標及行向D(所有行方向一致,見圖2),Y表示單位面積產量(果實數/英畝)。產量估算流程可概括為:先通過分層采樣控制智能無人機飛越隨機點,利用灌木檢測模型捕獲圖像;再應用漿果檢測模型統計單株漿果數,最終通過公式1估算Y。具體步驟如下(根據采樣方法調整):
-
分層采樣
將F劃分為M×N非重疊方形網格{Cmn},提出兩種網格內灌木采樣策略:
-
點采樣:每個網格Cmn內選擇距離隨機點pmn最近的單株灌木
-
行采樣:在Cmn內沿垂直于D方向的邊緣選取隨機點pmn,采樣整行灌木(見圖3)
(a) 控制無人機飛抵各pmn點(預設高度h)
-
單株灌木檢測
(a)在pmn點俯拍視角內,使用灌木模型識別最近灌木bmn(即檢測框中心點,見圖3),并啟動DeepSort目標追蹤
(b) 控制無人機水平飛至bmn正上方(保持高度h)
-
灌木側視圖像采集
(a)沿垂直于D方向隨機選擇一側(考慮太陽角度等因素),水平飛離bmn點至距離d,同步調整攝像頭角度維持追蹤。可進一步協調無人機位置與攝像頭角度確保完整灌木入鏡(見圖5)

(b)?點采樣:拍攝bmn點灌木圖像,記錄灌木模型預測的檢測框坐標cmn
(c)?行采樣:沿D方向飛行,對視野中央灌木連續拍攝并記錄各株檢測框坐標cmn,直至穿越網格邊界。通過目標追蹤區分不同灌木并調整位置確保完整拍攝
漿果計數(任務后處理)
(a) 基于檢測框坐標cmn統計單側可見漿果數,提供兩種方案(第四節討論優劣):
i. 圖像裁剪:截取檢測框cmn區域圖像,應用漿果模型統計單株可見漿果
ii. 檢測框過濾:在全圖上運行漿果模型,僅統計落入cmn框內的檢測結果
(b) 計算所有采樣灌木的平均漿果數B,乘以2獲得整株平均漿果數
三、數據集
-
數據采集
數據包含兩種高叢藍莓(Vaccinium corymbosum)品種"Duke"和"Draper"的灌木圖像(靜態照片與視頻幀),采集自新澤西州南部多個露天藍莓農場。為增強數據多樣性,同時使用了手持設備(含手機)和無人機攝像頭進行拍攝。盡管原始采集圖像總數超過千幅,但由于標注工作耗時且資源有限(具體挑戰將在下文討論),實際用于模型訓練的僅為其中部分樣本。
-
漿果數據集
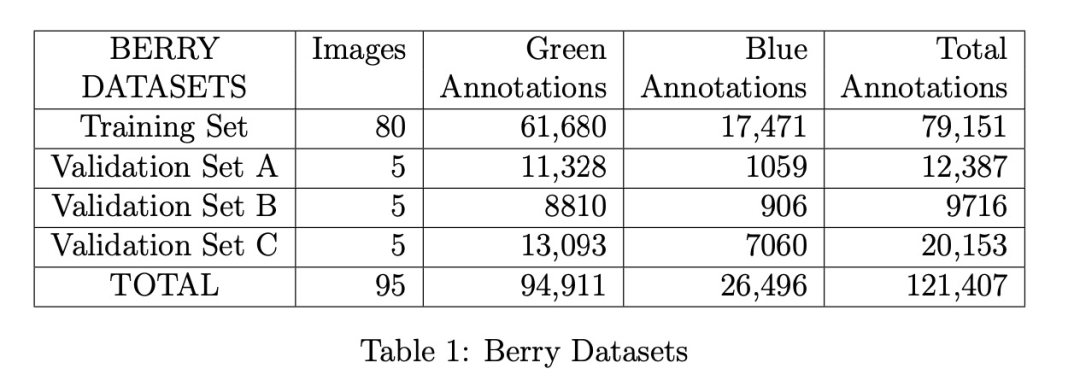
漿果數據集共包含95張標注圖像,來源分為兩類:
航拍圖像(無人機):35張
地面圖像(手持設備):60張
這95張圖像是當前已完成完整標注的全部樣本,雖然數量有限,但包含超過10萬枚漿果的標注。當前數據集規模已能支撐構建精度合理的模型,后續實驗結果將驗證這一點。
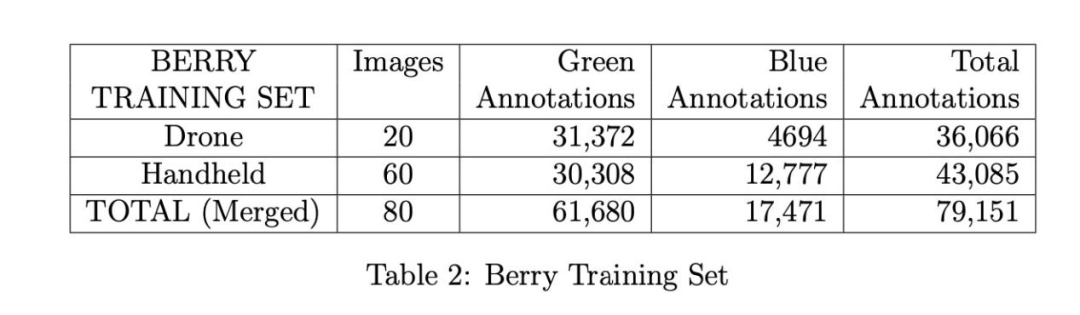
采用84/16的比例劃分訓練集與驗證集:訓練集含80張圖像,驗證集分為A/B/C三組各5張(見表1)。訓練集進一步細分為兩個子集(見表2):
-
無人機子集:20張圖像,由DJI Phantom 3和Autel Evo II Pro無人機拍攝
-
手持設備子集:60張圖像,來源包括iPhone、Android手機和佳能EOS Rebel單反
所有訓練集圖像均攝于2021與2022年夏季(示例見圖6a、6b、7a、7b)。


驗證集的構成差異如下:
驗證集A:5張DJI Phantom 3無人機2022年夏季航拍圖
驗證集B:與A集相同灌木群的另一側視角圖像
驗證集C:5張DJI Mini 3無人機2023年夏季航拍圖
-
灌木數據集
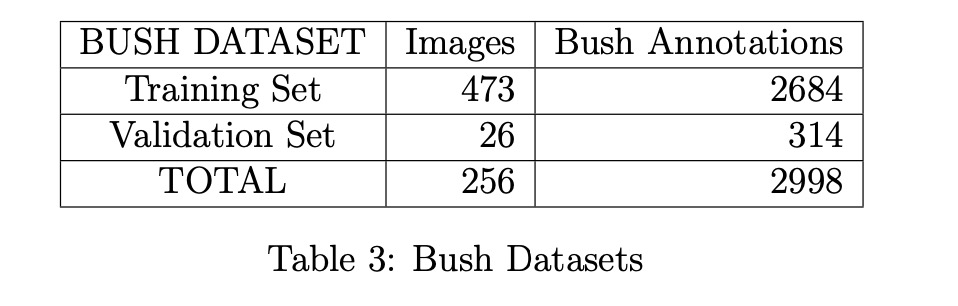
灌木數據集包含256張無人機拍攝的多角度圖像(不同高度與視角,示例見圖12、13),按90/10比例劃分為訓練集與驗證集(見表3)。


-
數據標注
漿果模型標注規范:
為每顆可見漿果繪制緊密包圍的矩形檢測框,按顏色分為兩類:青果(Green)與成熟果(Blue)(示例見圖8)

分類標準通過標注團隊共識確定(參考圖9、10),未采用客觀量化指標


考慮過增加顏色分類,但為提升標注效率(總標注量超12萬枚,目前該類型最大規模數據集)最終保留兩類
各數據集標注數量(青果、成熟果、總量)見表1。青果標注量顯著高于成熟果,驗證集A的青藍比最高(10.7),驗證集C最低(1.85),這與集C拍攝時間更接近首輪采收日有關
漿果計數模型:
-
將原圖分割為640×640像素的圖塊(因YOLO模型更適應小尺寸方形輸入)
-
從左上角開始切割,無法完整分割的殘余區域棄用(流程示意見圖14)
-
跨圖塊檢測框按中心點歸屬原則分配

四、YOLO目標檢測
基于以下原因,漿果與灌木模型均采用YOLOv5s(小型架構):
-
使用更大模型(如YOLOv5m中型或YOLOv5l大型)對訓練指標改善有限
-
灌木模型需依賴無人機機載計算機實時推理,小型模型方能滿足性能要求
-
在Jetson Nano平臺搭配Deepstream運行YOLOv5s時,灌木模型可實現6-9幀/秒的檢測速度
-
訓練
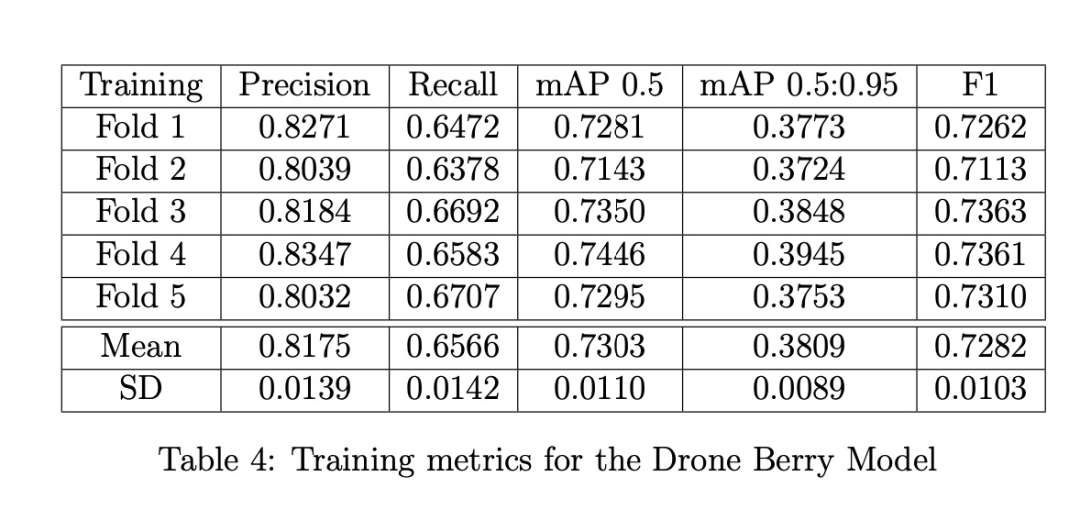
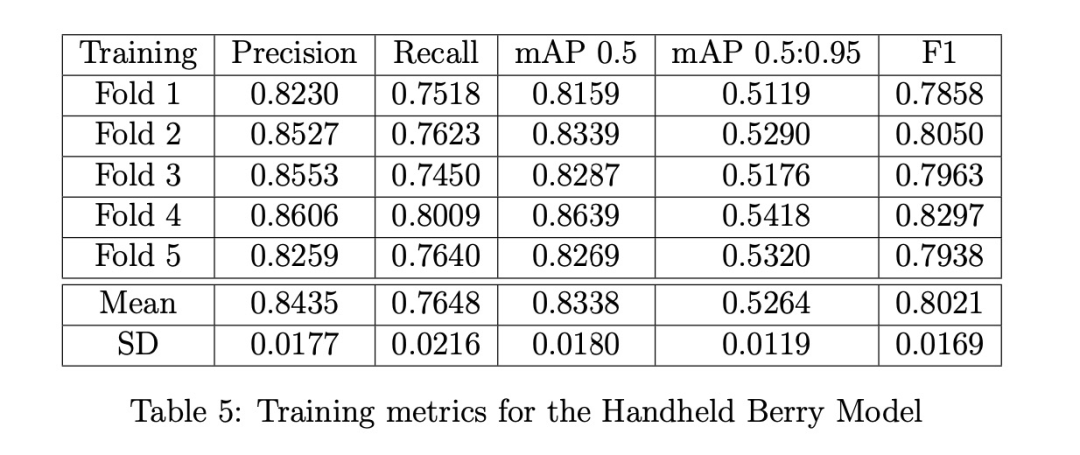
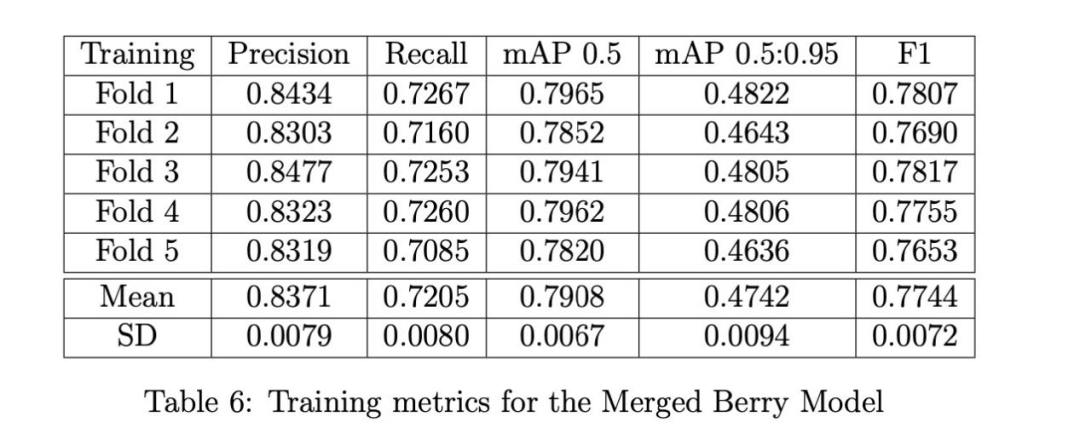
灌木和漿果模型分別基于灌木和漿果數據集,使用YOLOv5s的超參數配置文件"hyp.scratch-low.yaml"中的默認設置進行訓練。我們使用批量大小為32,灌木模型訓練最多400個epoch,漿果模型訓練最多300個epoch;當交叉驗證損失與訓練損失出現偏離時,使用默認的早停標準停止訓練。訓練指標通過Ultralytics YOLOv5的Python工具庫中的'metric.py'腳本計算。我們發現改變其他默認參數對準確度影響很小,認為優化這些參數不會改變本文的結論;我們相信更重要的是增加數據集規模并添加更多高分辨率圖像來顯著改進我們的模型。
-
驗證
使用五折交叉驗證中每折最佳模型(基于最高mAP:0.5)對表1和表3中的數據集進行驗證。對于漿果模型,每張圖像首先被分割為700×700的重疊圖塊,或盡可能接近這些尺寸,使它們在每個維度上重疊60像素;這樣可以避免如果使用不重疊的圖塊可能導致漿果被重復計數的情況。然后將每個圖塊通過漿果模型,并使用后處理去除出現在兩個重疊圖塊中的重復檢測框。為了計算每個類別的精確率和召回率,應用0.1的置信度閾值生成檢測結果,應用0.3的IOU閾值在與真實標注比較時計算真正例;如果有多個檢測結果在IOU閾值和類別上都匹配一個真實標注,則選擇置信度最高的檢測結果。使用較低的IOU閾值(相比YOLOv5默認的0.6閾值)是為了避免消除與真實標注重疊不足的正確預測。這是因為藍莓的檢測框尺寸較小;因此,這些框的位置檢測誤差即使只有幾個像素,也會顯著影響它們的IOU。
-
DeepSORT追蹤
為了測試我們的灌木模型在第3節流程中討論的追蹤灌木的準確性,我們使用DeepSORT計算多目標追蹤準確率(MOTA)。DeepSORT是一種計算機視覺追蹤算法,通過為每個檢測到的對象分配ID來追蹤視頻流中的對象[23]。它是簡單在線實時追蹤(SORT)的擴展,因為它整合了基于深度外觀描述符的外觀信息。我們將DeepSORT應用于兩個短視頻片段:一個是無人機執行點采樣的視頻,另一個是執行行采樣的視頻。
-
實驗結果
在本節中,我們展示漿果模型和灌木模型的訓練和驗證結果,包括單獨使用和組合使用進行灌木裁剪以獲得僅前景中心灌木的總漿果計數的情況。我們還展示了使用DeepSORT算法的灌木模型的追蹤結果(MOTA)。
-
漿果模型
使用五折交叉驗證訓練了三種不同的漿果模型:無人機模型、手持模型和融合模型。無人機和手持漿果模型分別在20張無人機圖像和60張手持圖像上訓練(見表2)。融合漿果模型(或簡稱漿果模型)在80張圖像(無人機和手持)的合并數據集上訓練;我們將這個合并數據集稱為漿果訓練集。
訓練結果:三種漿果模型(無人機、手持、融合)的訓練指標分別在表4-6中給出。手持模型在所有指標(精確率、召回率、mAP和F1)上都表現最佳,這在意料之中,因為手持圖像中的灌木拍攝距離更近,漿果比無人機圖像中的更大,因此檢測更容易。無人機模型在精確率方面幾乎與手持模型一樣好,但召回率明顯更差。當然,這兩個模型的好壞取決于它們訓練所用的數據,因此在下面展示驗證結果時,我們會看到它們的性能反轉,這支持了需要一個能適應多種不同類型圖像的融合模型。
驗證結果:表7、8和9分別展示了三種漿果模型(無人機、手持、融合)在驗證集A、B和C上的精確率和召回率。對于集A和B(表7、8),無人機漿果模型在所有模型中具有最高的總體精確率;然而,融合模型具有顯著更高的總體召回率和略好的藍色漿果精確率。另一方面,手持漿果模型在所有類別中表現最差。特別是綠色漿果的召回率極低,表明該模型未能檢測到許多綠色漿果,特別是在背景灌木上顯得更小的那些,這使得模型更難檢測它們。此外,藍色漿果類別的精確率也相當低,這表明手持漿果模型在正確檢測藍色漿果方面表現不佳。至于驗證集C(表9),性能發生反轉,融合模型現在具有最高的總體精確率,而總體召回率僅比無人機和手持模型略差。觀察到手持模型的總體召回率相比表7、8中的結果顯著提高。然而,所有三個模型在總體召回率上都表現不佳。對假陰性的檢查發現,它們是背景灌木上的漿果,雖然被標注但因尺寸太小或陰影太重而無法被任何模型檢測或識別為漿果。總體精確率的結果證明,與單獨使用無人機和手持圖像訓練相比,使用合并的無人機和手持圖像訓練有助于改進(融合)漿果模型,總體召回率僅略有下降(但綠色漿果召回率最佳)。
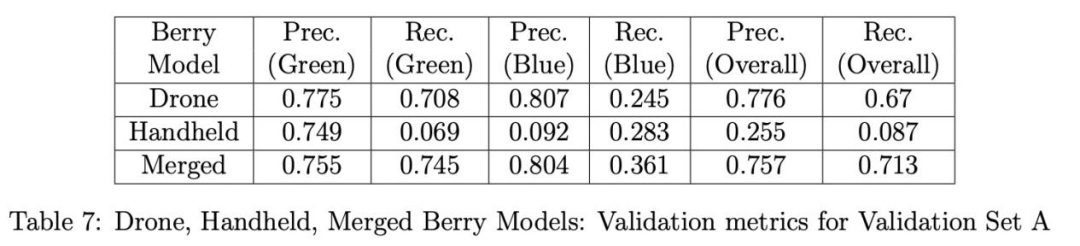
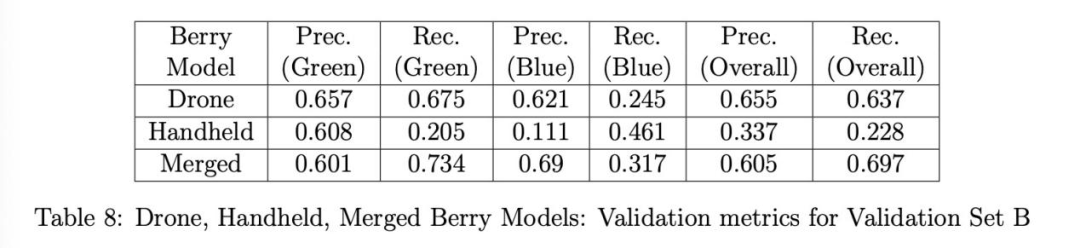
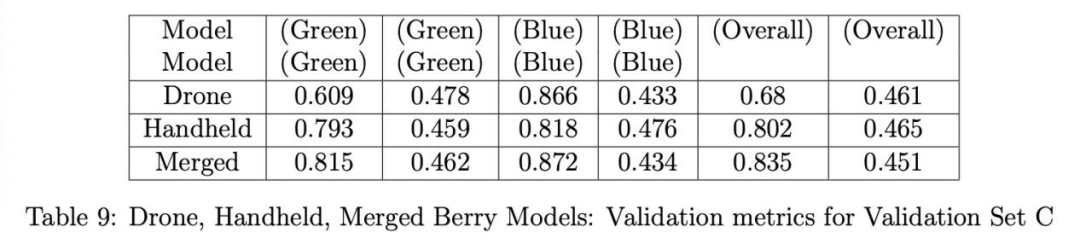
表10單獨展示了融合漿果模型在三個驗證集(A、B和C)上的精確率和召回率,以便更好地比較結果。集C的結果獲得了最高的總體精確率,但不幸的是也獲得了最低的總體召回率,我們之前將其歸因于背景灌木上的漿果像素分辨率太低,模型無法檢測。這一點在我們后續僅考慮檢測前景中心灌木上的漿果時得到的結果中得到了支持。相反,集B的結果具有最低的總體精確率,但最高的總體召回率。
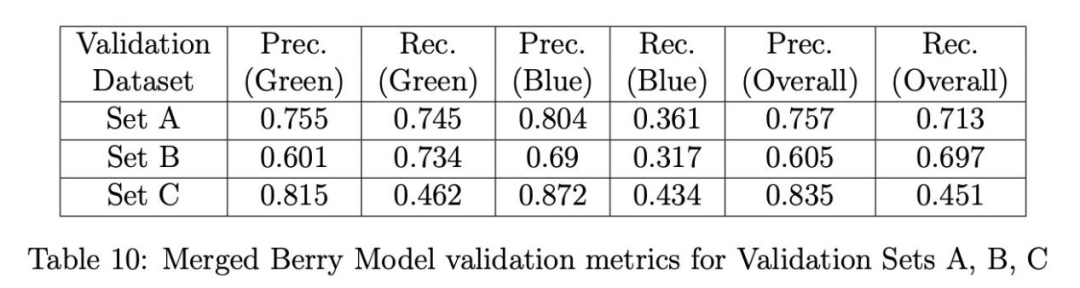
圖15、16和17展示了集B中的樣本圖像(B2),但繪制了不同類型的檢測框:真實標注(圖15)、預測結果(圖16)以及假陽性和假陰性(圖17)。仔細檢查假陽性可以發現,其中一些可能是漿果,但難以清晰辨別,這解釋了為什么它們沒有被標注。



-
灌木模型
訓練/驗證結果:表11給出了在灌木訓練集上訓練的灌木模型的訓練指標。表12給出了在灌木驗證集上驗證的灌木模型的驗證指標。兩個表都顯示了約90%的高精確率,以及從訓練的高70%到驗證的低80%的良好召回率。對真陰性(未檢測到的灌木)的檢查表明,灌木模型難以檢測圖像邊緣的那些灌木。幸運的是,這不是問題,因為灌木模型的目標是檢測和追蹤前景灌木。
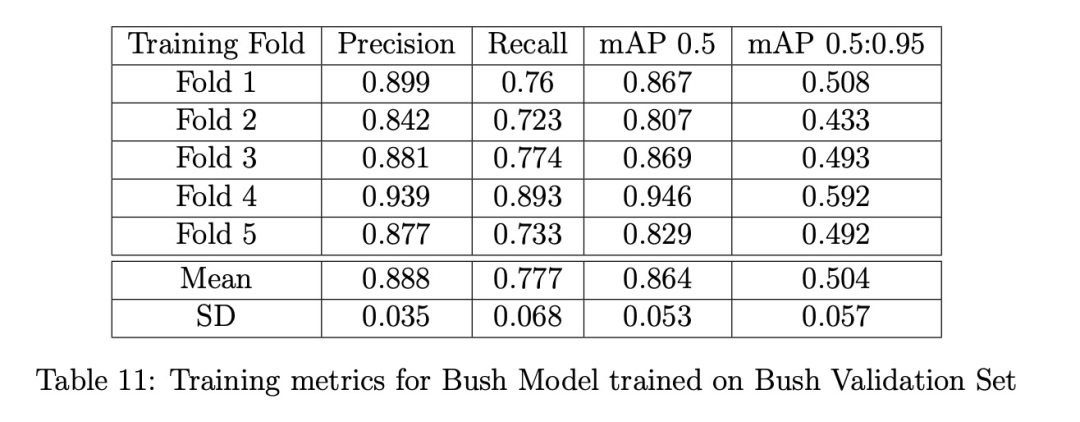

圖18和19分別展示了灌木模型在斜側視角和鳥瞰視角下的樣本預測結果,后者還包括一個假陽性和假陰性。灌木追蹤:我們計算了兩段視頻的多目標追蹤準確率(MOTA):灌木視頻1和灌木視頻2。灌木視頻1(24秒)是由DJI無人機從上方飛向灌木并同時調整其位置和攝像頭角度從鳥瞰到斜側視角拍攝的。灌木視頻2(5秒)是由DJI無人機沿藍莓灌木行橫向飛行拍攝的。表13給出了兩段視頻的MOTA結果。盡管MOTA低于我們的期望,但對檢測結果的檢查表明,灌木模型在追蹤前景中心灌木方面做得非常好,這是模型的主要目標,而在圖像邊緣的灌木上表現較差,這一點我們之前提到過。


-
灌木裁剪漿果模型
漿果和灌木模型可以組合成一個流程,僅檢測出現在單個灌木上的漿果。我們稱這個流程為灌木裁剪漿果模型。具體來說,我們首先將全尺寸圖像通過灌木模型,獲得檢測到的灌木及其對應檢測框的數組。從這些檢測框中,我們選擇一個稱為中心檢測框(對應前景中心灌木;見圖21a和21b),其中心在徑向距離上最接近圖像中心,然后使用OpenCV2圍繞中心檢測框裁剪圖像。裁剪后的圖像隨后通過漿果模型檢測漿果。檢測結果與中心檢測框內的真實標注進行比較。

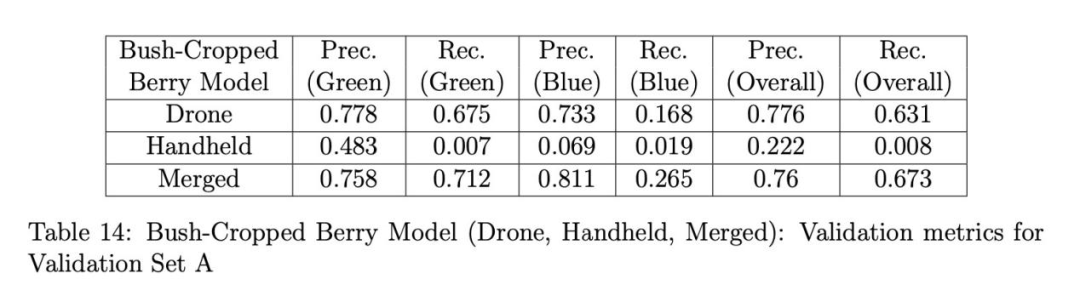
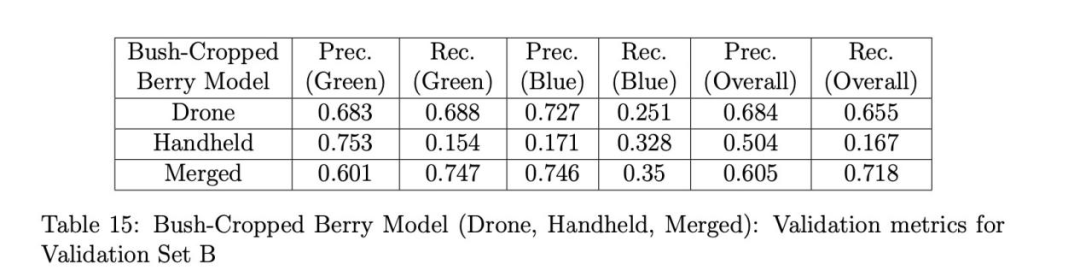
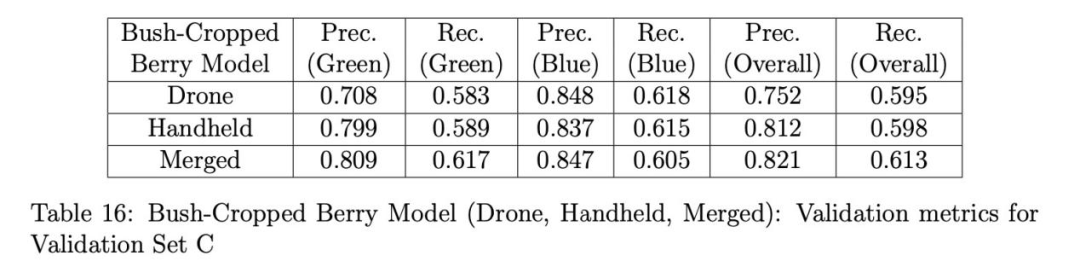
表14、15和16分別展示了使用灌木裁剪漿果模型(無人機、手持和融合)在驗證集A、B和C上的驗證結果。這次我們看到融合模型在所有驗證集上的總體召回率都優于無人機和手持模型。手持漿果模型在集A和B(表14和15)的總體精確率和召回率上都表現最差,正如在全圖像驗證時觀察到的那樣(見表10),但在集B(表15)的綠色漿果精確率上出人意料地表現良好。對于集C,融合模型獲得了最佳的總體精確率和召回率,手持模型的結果僅略差。這表明集C中的無人機圖像幾乎具有與手持圖像相同的空間分辨率。我們相信,融合模型在未來無人機拍攝的圖像上會表現最佳,這些無人機的攝像頭分辨率只會繼續提高。為了比較,表17單獨展示了使用相同的灌木裁剪融合漿果模型驗證集A、B和C的結果。這里的結果與在全圖像上驗證時的結果類似(見表10),但觀察到集C的召回率顯著提高,因為模型不再需要檢測背景灌木上的微小漿果,這在全圖像驗證時是困難的。
五、討論
我們的漿果模型結果突顯了標注漿果和訓練模型時的挑戰。由于尺寸小而難以辨別的漿果,特別是背景灌木上的那些,可能導致主觀標注,從而產生模糊的真實標注。許多假陽性檢測可以被認為是漿果的真實檢測,這取決于人的視力,但由于分辨率低而難以確定。此外,部分隱藏漿果的遮擋、綠葉對綠色漿果的偽裝以及陰影漿果,使得訓練一個準確的漿果模型相當具有挑戰性。
灌木模型的結果清楚地表明,檢測灌木不一定比檢測漿果更容易。顯然,灌木比漿果大得多;然而,灌木的復雜枝條結構,加上其枝條可能與鄰近灌木重疊,給訓練一個準確的灌木模型帶來了挑戰。
灌木裁剪漿果模型的結果表明,圍繞前景中心灌木裁剪以消除背景漿果的有效性,從而提高了模型的精確率和召回率,進而提供了更準確的作物產量估計。基于灌木裁剪漿果模型的采摘-視覺比α估計表明,它可以顯著變化,并取決于許多因素,如拍攝的灌木特定側面和藍莓品種,以及我們未考慮的其他因素:灌木大小、灌木葉密度、環境和土壤條件。
六、結論
在本文中,我們提出了一種基于深度學習的對象檢測模型流程,用于檢測藍莓灌木及其上的單個漿果。這些模型使搭載它們的智能無人機能夠執行智能任務,即精確定位灌木并捕捉其側視圖,從而獲得更準確的作物產量估計。我們已經開始使用定制構建的可編程無人機來捕獲數據以測試我們的流程,并希望在不久的將來報告我們的實驗結果。我們希望我們的工作能激發其他人解決本文提出的挑戰,并在我們的基準結果上改進。



性能)
















