一、認識AI
1.人工智能發展
AI,人工智能(Artificial Intelligence),使機器能夠像人類一樣思考、學習和解決問題的技術。
AI發展至今大概可以分為三個階段:

其中,深度學習領域的自然語言處理(Natural Language Processing, NLP)有一個關鍵技術叫做Transformer,這是一種由多層感知機組成的神經網絡模型,是現如今AI高速發展的最主要原因。
我們所熟知的大模型(Large Language Models, LLM),例如GPT、DeepSeek底層都是采用Transformer神經網絡模型。
以GPT模型為例,其三個字母的縮寫分別是Generative、Pre-trained、Transformer:

那么問題來, Transformer神經網絡有什么神奇的地方,可以實現如此強大的能力呢?
2.大模型原理
其實,最早Transformer是由Google在2017年提出的一種神經網絡模型,一開始的作用是把它作為機器翻譯的核心:
Transformer中提出的注意力機制使得神經網絡在處理信息時可以根據上下內容調整對數據的理解,變得更加智能化。這不僅僅是說人類的文字,包括圖片、音頻數據都可以交給Transformer來處理。于是,越來越多的模型開始基于Transformer實現了各種神奇的功能。
例如,有的模型可以根據音頻生成文本,或者根據文本生成音頻:
還有的模型則可以根據文字生成圖片,比如Dall-E、MidJourney:
不過,我們要聊的大語言模型(Large Language Models, 以下簡稱LLM)是對Transformer的另一種用法:推理預測。
LLM在訓練Transformer時會嘗試輸入一些文本、音頻、圖片等信息,然后讓Transformer推理接下來跟著的應該是什么內容。推理的結果會以概率分布的形式出現:
可能大家會有疑問:
僅僅是推測接下來的內容,怎么能讓ChatGPT在對話中生成大段的有關聯的文字內容呢?
其實LLM采用的就是笨辦法,答案就是:持續生成
根據前文推測出接下來的一個詞語后,把這個詞語加入前文,再次交給大模型處理,推測下一個字,然后不斷重復前面的過程,就可以生成大段的內容了:
這就是為什么我們跟AI聊天的時候,它生成的內容總是一個字一個字的輸出的原因了。
以上就是LLM的核心技術,Transformer的原理了~
二、大模型應用開發
相信大家肯定會有疑問:
- 什么是大模型應用開發呢?
- 跟傳統的Java應用開發又有什么區別呢?
- 我們該如何去開發大模型應用呢?
別著急,本章我們就一起來分析一下。
1.模型部署
首先要明確一點:大模型應用開發并不是在瀏覽器中跟AI聊天。而是通過訪問模型對外暴露的API接口,實現與大模型的交互。
因此,企業首先需要有一個可訪問的大模型,通常有三種選擇:
- 使用開放的大模型API
- 在云平臺部署私有大模型
- 在本地服務器部署私有大模型
使用開放大模型API的優缺點如下:
- 優點:
- 沒有部署和維護成本,按調用收費
- 缺點:
- 依賴平臺方,穩定性差
- 長期使用成本較高
- 數據存儲在第三方,有隱私和安全問題
云平臺部署私有模型:
- 優點:
- 前期投入成本低
- 部署和維護方便
- 網絡延遲較低
- 缺點:
- 數據存儲在第三方,有隱私和安全問題
- 長期使用成本高
本地部署私有模型:
- 優點:
- 數據完全自主掌控,安全性高
- 不依賴外部環境
- 雖然短期投入大,但長期來看成本會更低
- 缺點:
- 初期部署成本高
- 維護困難
注意:
這里說的本地部署并不是說在你自己電腦上部署,而是公司自己的服務器部署。
由于大模型所需要的算力非常多,自己電腦部署的模型往往都是閹割蒸餾版本,性能和推理能力都比較差。
再加上現在各種模型都有很多免費的服務可以訪問,性能還是滿血版本,推理能力拉滿。
所以完全不建議大家在自己電腦上部署,除非你想自己做模型微調或測試。
接下來,我們給大家演示下兩種部署方式:
- 開發大模型服務
- 本地部署(在本機演示,將來在服務器也是類似的)
1.1 開放大模型服務
通常發布大模型的官方、大多數的云平臺都會提供開放的、公共的大模型服務。大模型官方前面講過,我們不再贅述,這里我們看一些國內提供大模型服務的云平臺:
| 云平臺 | 公司 | 地址 |
|---|---|---|
| 阿里百煉 | 阿里巴巴 | https://bailian.console.aliyun.com |
| 騰訊TI平臺 | 騰訊 | https://cloud.tencent.com/product/ti |
| 千帆平臺 | 百度 | https://console.bce.baidu.com/qianfan/overview |
| SiliconCloud | 硅基流動 | https://siliconflow.cn/zh-cn/siliconcloud |
| 火山方舟-火山引擎 | 字節跳動 | https://www.volcengine.com/product/ark |
這些開放平臺并不是免費,而是按照調用時消耗的token來付費,每百萬token通常在幾毛~幾元錢,而且平臺通常都會贈送新用戶百萬token的免費使用權。(token可以簡單理解成你與大模型交互時發送和響應的文字,通常一個漢字2個token左右)
我們以阿里云百煉平臺為例。
1.1.1 注冊賬號
首先,我們需要注冊一個阿里云賬號:
https://account.aliyun.com/
然后訪問百煉平臺,開通服務:
https://www.aliyun.com/product/bailian?spm=5176.29677750.nav-v2-dropdown-menu-1.d_main_0_6.6b44154amuN66a&scm=20140722.M_sfm.P_197.ID_sfm-OR_rec-V_1-MO_3480-ST_12892
首次開通應該會贈送百萬token的使用權,包括DeepSeek-R1模型、qwen模型。
1.1.2 申請API_KEY
注冊賬號以后還需要申請一個API_KEY才能訪問百煉平臺的大模型。
在阿里云百煉平臺的右上角,鼠標懸停在用戶圖標上,可以看到下拉菜單:

選擇API-KEY,進入API-KEY管理頁面:

選擇創建我的API-KEY,會彈出表單:

填寫完畢,點擊確定,即可生成一個新的API-KEY:

后續開發中就需要用到這個API-KEY了,一定要記牢。而且要保密,不能告訴別人。
1.1.3 體驗模型
訪問百煉平臺,可以看到如下內容:

點擊模型調用 ->立即調用 就能進入模型廣場:

選擇一個自己喜歡的模型,然后點擊API調用示例,即可進入API文檔頁:

點擊立即體驗,就可以進入API調用大模型的試驗臺:

在這里就可以模擬調用大模型接口了。
1.2 本地部署
很多云平臺都提供了一鍵部署大模型的功能,這里不再贅述。我們重點講講如何手動部署大模型。
手動部署最簡單的方式就是使用Ollama,這是一個幫助你部署和運行大模型的工具。官網如下:
https://ollama.com/
1.2.1 下載安裝ollama
首先,我們需要下載一個Ollama的客戶端,在官網提供了各種不同版本的Ollama,大家可以根據自己的需要下載。

下載后雙擊即可安裝,這里不再贅述。
注意:
Ollama默認安裝目錄是C盤的用戶目錄,如果不希望安裝在C盤的話(其實C盤如果足夠大放C盤也沒事),就不能直接雙擊安裝了。需要通過命令行安裝。
命令行安裝方式如下:
在OllamaSetup.exe所在目錄打開cmd命令行,然后命令如下:
OllamaSetup.exe /DIR=你要安裝的目錄位置
OK,安裝完成后,還需要配置一個環境變量,更改Ollama下載和部署模型的位置。環境變量如下:
OLLAMA_MODELS=你想要保存模型的目錄
環境變量配置方式相信學過Java的都知道,這里不再贅述,配置完成如圖:

1.2.2 搜索模型
ollama是一個模型管理工具和平臺,它提供了很多國內外常見的模型,我們可以在其官網上搜索自己需要的模型:
https://ollama.com/search
如圖,目前熱度排第一的就是deepseek-r1:

點擊進入deepseek-r1頁面,會發現deepseek-r1也有很多版本:

這些就是模型的參數大小,越大推理能力就越強,需要的算力也越高。671b版本就是最強的滿血版deepseek-r1了。需要注意的是,Ollama提供的DeepSeek是量化壓縮版本,對比官網的蒸餾版會更小,對顯卡要求更低。對比如下:
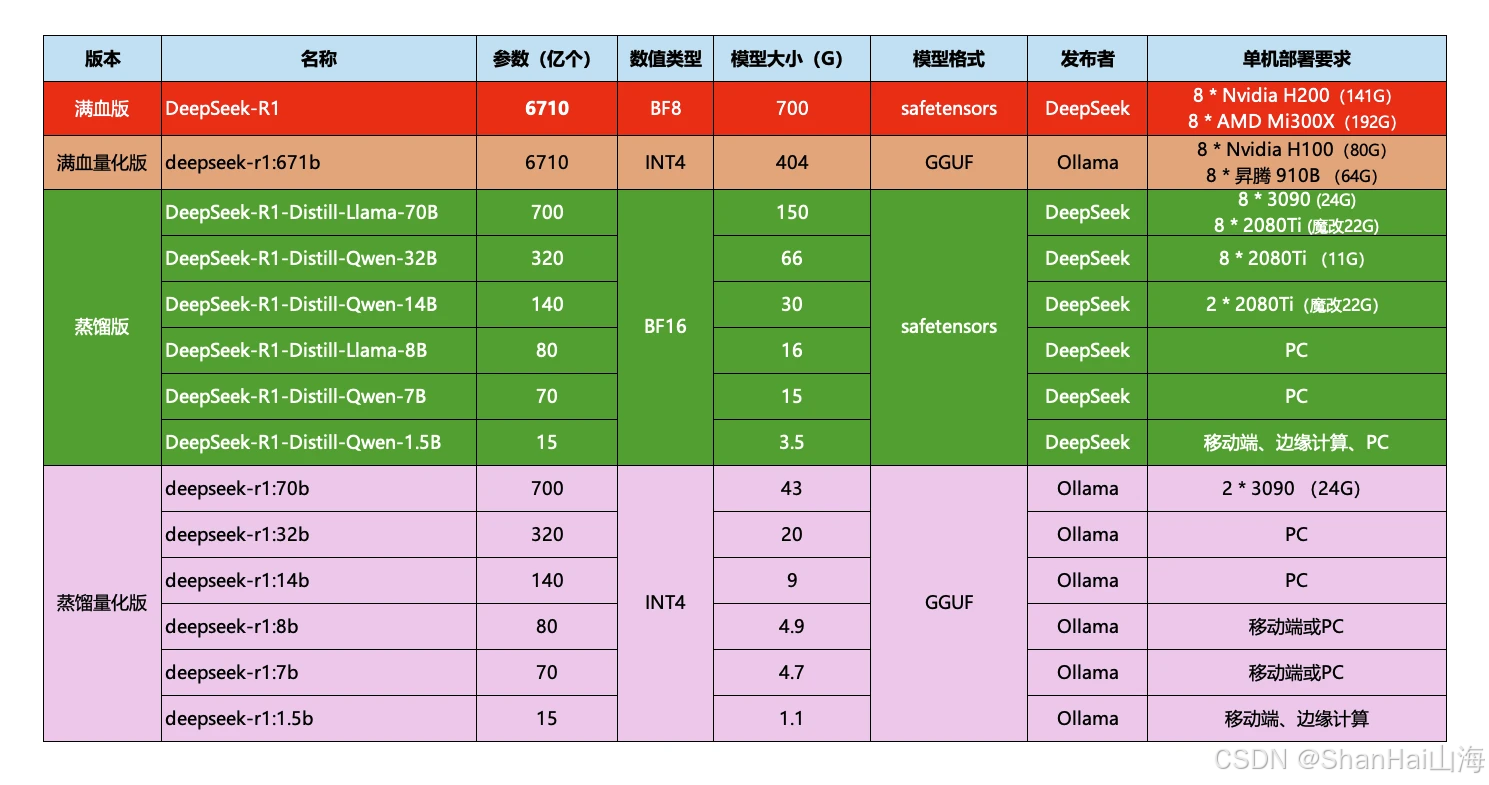
比如,我的電腦內存32G,顯存是6G,我選擇部署的是7b的模型,當然8b也是可以的,差別不大,都是可以流暢運行的。
1.2.3 運行模型
選擇自己合適的模型后,ollama會給出運行模型的命令:

復制這個命令,然后打開一個cmd命令行,運行命令即可,然后你就可以跟本地模型聊天了:
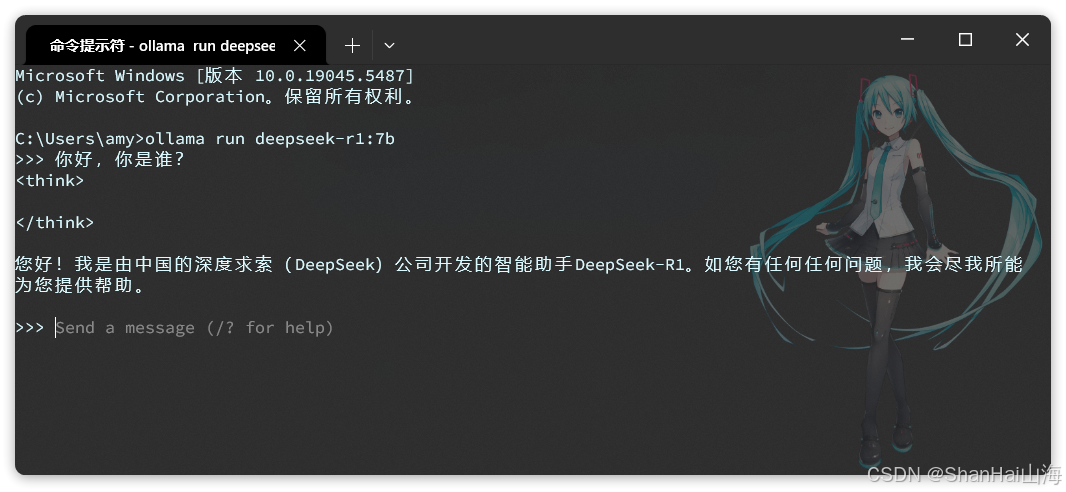
注意:
- 首次運行命令需要下載模型,根據模型大小不同下載時長在5分鐘~1小時不等,請耐心等待下載完成。
- ollama控制臺是一個封裝好的AI對話產品,與ChatGPT類似,具備會話記憶功能。
Ollama是一個模型管理工具,有點像Docker,而且命令也很像,比如:
ollama serve # Start ollamaollama create # Create a model from a Modelfileollama show # Show information for a modelollama run # Run a modelollama stop # Stop a running modelollama pull # Pull a model from a registryollama push # Push a model to a registryollama list # List modelsollama ps # List running modelsollama cp # Copy a modelollama rm # Remove a modelollama help # Help about any command
2.調用大模型
前面說過,大模型開發并不是在瀏覽器中跟AI聊天。而是通過訪問模型對外暴露的API接口,實現與大模型的交互。
所以要學習大模型應用開發,就必須掌握模型的API接口規范。
目前大多數大模型都遵循OpenAI的接口規范,是基于Http協議的接口。因此請求路徑、參數、返回值信息都是類似的,可能會有一些小的差別。具體需要查看大模型的官方API文檔。
2.1 大模型接口規范
我們以DeepSeek官方給出的文檔為例:
# Please install OpenAI SDK first: `pip3 install openai`from openai import OpenAI# 1.初始化OpenAI客戶端,要指定兩個參數:api_key、base_url
client = OpenAI(api_key="<DeepSeek API Key>", base_url="https://api.deepseek.com")# 2.發送http請求到大模型,參數比較多
response = client.chat.completions.create(model="deepseek-chat", # 2.1.選擇要訪問的模型messages=[ # 2.2.發送給大模型的消息{"role": "system", "content": "You are a helpful assistant"},{"role": "user", "content": "Hello"},],stream=False # 2.3.是否以流式返回結果
)print(response.choices[0].message.content)
2.1.1 接口說明
- 請求方式:通常是POST,因為要傳遞JSON風格的參數
- 請求路徑:與平臺有關
- DeepSeek官方平臺:https://api.deepseek.com
- 阿里云百煉平臺:https://dashscope.aliyuncs.com/compatible-mode/v1
- 本地ollama部署的模型:http://localhost:11434
- 安全校驗:開放平臺都需要提供API_KEY來校驗權限,本地ollama則不需要
- 請求參數:參數很多,比較常見的有:
- model:要訪問的模型名稱
- messages:發送給大模型的消息,是一個數組
- stream:true,代表響應結果流式返回;false,代表響應結果一次性返回,但需要等待
- temperature:取值范圍[0:2),代表大模型生成結果的隨機性,越小隨機性越低。DeepSeek-R1不支持
注意,這里請求參數中的messages是一個消息數組,而且其中的消息要包含兩個屬性:
- role:消息對應的角色
- content:消息內容
其中消息的內容,也被稱為提示詞(Prompt),也就是發送給大模型的指令。
2.1.2 提示詞角色
通常消息的角色有三種:
| 角色 | 描述 | 示例 |
|---|---|---|
| system | 優先于user指令之前的指令,也就是給大模型設定角色和任務背景的系統指令 | 你是一個樂于助人的編程助手,你以小團團的風格來回答用戶的問題。 |
| user | 終端用戶輸入的指令(類似于你在ChatGPT聊天框輸入的內容) | 寫一首關于Java編程的詩 |
| assistant | 由大模型生成的消息,可能是上一輪對話生成的結果 | 注意,用戶可能與模型產生多輪對話,每輪對話模型都會生成不同結果。 |
其中System類型的消息非常重要!影響了后續AI會話的行為模式。
比如,我們會發現,當我們詢問這些AI對話產品“你是誰”這個問題的時候,每一個AI的回答都不一樣,這是怎么回事呢?
這其實是因為AI對話產品并不是直接把用戶的提問發送給LLM,通常都會在user提問的前面通過System消息給模型設定好背景:
所以,當你問問題時,AI就會遵循System的設定來回答了。因此,不同的大模型由于System設定不同,回答的答案也不一樣。
示例:
## Role
System: 你是智能客服,你的名字叫小黑。請以友好、熱情的方式回答用戶問題。
## Example
User: 你好
Assisant: 你好,我是小黑,很高興認識你!無論什么問題,我都會盡力幫你解答哦!
2.1.3 會話記憶問題
這里還有一個問題:
我們為什么要把歷史消息都放入Messages中,形成一個數組呢?
這是因為大模型是沒有記憶的,因此我們調用API接口與大模型對話時,每一次對話信息都不會保留,多次對話之間都是獨立的,沒有關聯的。
但是大家可能發現了,我們使用的AI對話產品卻能夠記住每一輪對話信息,根據這些信息進一步回答,這是怎么回事呢?
答案就是Messages數組。
我們只需要每一次發送請求時,都把歷史對話中每一輪的User消息、Assistant消息都封裝到Messages數組中,一起發送給大模型,這樣大模型就會根據這些歷史對話信息進一步回答,就像是擁有了記憶一樣。
示例:
System: 你是智能客服,你的名字叫小黑。請以友好、熱情的方式回答用戶問題。User: 你好,我是小明
Assisant: 你好小明,我是小黑,很高興認識你!無論什么問題,我都會盡力幫你解答哦!User: 幫我寫一個跟我名字有關的詩
Assisant: 好的,下面是以你的名字寫的詩:
小明啊小明,名字真明亮,
如晨曦初現,驅散了黑暗。
心中有火焰,智慧放光芒,
在求知路上,你是那最亮的星。像清澈溪流,繞過知識山崗,
帶著勇氣和希望,不斷向前方。
你的每一步,都閃耀著堅強,
未來的大門,正為你而敞開。無論走到哪,世界因你更晴朗,
小明啊小明,愿你永遠這樣,
保持那份純真,還有對夢想的向往,
人生的旅途上,成為自己的太陽。
2.2 調用大模型
部分平臺提供了圖形化的試驗臺,可以方便測試模型接口。比如阿里云百煉平臺:

當然,我們也可以用普通的http客戶端來發起請求大模型,我們以Ollama為例:
Ollama在本地部署時,會自動提供模型對應的Http接口,訪問地址是:http://localhost:11434/api/chat

3.大模型應用
大模型應用是基于大模型的推理、分析、生成能力,結合傳統編程能力,開發出的各種應用。
為什么要把傳統應用與大模型結合呢?
別著急,我們先來看看傳統應用、大模型各自擅長什么,不擅長什么
3.1 傳統應用
作為Java程序員,大家應該對傳統Java程序的能力邊界很清楚。
核心特點
基于明確規則的邏輯設計,確定性執行,可預測結果。
擅長領域
- 結構化計算
- 例:銀行轉賬系統(精確的數值計算、賬戶余額增減)。
- 例:Excel公式(按固定規則處理表格數據)。
- 確定性任務
- 例:排序算法(快速排序、冒泡排序),輸入與輸出關系完全可預測。
- 高性能低延遲場景
- 例:操作系統內核調度、數據庫索引查詢,需要毫秒級響應。
- 規則明確的流程控制
- 例:紅綠燈信號切換系統(基于時間規則和傳感器輸入)。
不擅長領域
- 非結構化數據處理
- 例:無法直接理解用戶自然語言提問(如"幫我寫一首關于秋天的詩")。
- 模糊推理與模式識別
- 例:判斷一張圖片是"貓"還是"狗",傳統代碼需手動編寫特征提取規則,效果差。
- 動態適應性
- 例:若用戶需求頻繁變化(如電商促銷規則每天調整),需不斷修改代碼。
3.2 AI大模型
傳統程序的弱項,恰恰就是AI大模型的強項:
核心特點
基于數據驅動的概率推理,擅長處理模糊性和不確定性。
擅長領域
- 自然語言處理
- 例:ChatGPT生成文章、翻譯語言,或客服機器人理解用戶意圖。
- 非結構化數據分析
- 例:醫學影像識別(X光片中的腫瘤檢測),或語音轉文本。
- 創造性內容生成
- 例:Stable Diffusion生成符合描述的圖像,或AI作曲工具創作音樂。
- 復雜模式預測
- 例:股票市場趨勢預測(基于歷史數據關聯性,但需注意可靠性限制)。
不擅長領域
- 精確計算
- 例:AI可能錯誤計算"12345 × 6789"的結果(需依賴計算器類傳統程序)。
- 確定性邏輯驗證
- 例:驗證身份證號碼是否符合規則(AI可能生成看似合理但非法的號碼)。
- 低資源消耗場景
- 例:嵌入式設備(如微波爐控制程序)無法承受大模型的算力需求。
- 因果推理
- 例:AI可能誤判"公雞打鳴導致日出"的因果關系。
3.3 強強聯合
傳統應用開發和大模型有著各自擅長的領域:
- 傳統編程:確定性、規則化、高性能,適合數學計算、流程控制等場景。
- AI大模型:概率性、非結構化、泛化性,適合語言、圖像、創造性任務。
兩者之間恰好是互補的關系,兩者結合則能解決以前難以實現的一些問題:
- 混合系統(Hybrid AI)
- 用傳統程序處理結構化邏輯(如支付校驗),AI處理非結構化任務(如用戶意圖識別)。
- 示例:智能客服中,AI理解用戶問題,傳統代碼調用數據庫返回結果。
- 增強可解釋性
- 結合規則引擎約束AI輸出(如法律文檔生成時強制符合條款格式)。
- 低代碼/無代碼平臺
- 通過AI自動生成部分代碼(如GitHub Copilot),降低傳統開發門檻。
在傳統應用開發中介入AI大模型,充分利用兩者的優勢,既能利用AI實現更加便捷的人機交互,更好的理解用戶意圖,又能利用傳統編程保證安全性和準確性,強強聯合,這就是大模型應用開發的真諦!
綜上所述,大模型應用就是整合傳統程序和大模型的能力和優勢來開發的一種應用。
3.4大模型與大模型應用
我們熟知的大模型比如GPT、DeepSeek都是生成式模型,顧名思義,根據前文不斷生成后文。
不過,模型本身只具備生成后文的能力、基本推理能力。我們平常使用的AI對話產品除了生成和推理,還有會話記憶功能、聯網功能等等。這些都是大模型不具備的。
要想讓大模型產生記憶,聯網等功能,是需要通過額外的程序來實現的,也就是基于大模型開發應用。
所以,我們現在接觸的AI對話產品其實都是基于大模型開發的應用,并不是大模型本身,這一點大家千萬要區分清楚。
下面我把常見的一些大模型對話產品及其模型的關系給大家羅列一下:
| 大模型 | 對話產品 | 公司 | 地址 |
|---|---|---|---|
| GPT-3.5、GPT-4o | ChatGPT | OpenAI | https://chatgpt.com/ |
| Claude 3.5 | Claude AI | Anthropic | https://claude.ai/chats |
| DeepSeek-R1 | DeepSeek | 深度求索 | https://www.deepseek.com/ |
| 文心大模型3.5 | 文心一言 | 百度 | https://yiyan.baidu.com/ |
| 星火3.5 | 訊飛星火 | 科大訊飛 | https://xinghuo.xfyun.cn/desk |
| Qwen-Max | 通義千問 | 阿里巴巴 | https://tongyi.aliyun.com/qianwen/ |
| Moonshoot | Kimi | 月之暗面 | https://kimi.moonshot.cn/ |
| Yi-Large | 零一萬物 | 零一萬物 | https://platform.lingyiwanwu.com/ |
當然,除了AI對話應用之外,大模型還可以開發很多其它的AI應用,常見的領域包括:

那么問題來了,如何進行大模型應用開發呢?
4.大模型應用開發技術架構
基于大模型開發應用有多種方式,接下來我們就來了解下常見的大模型開發技術架構。
4.1 技術架構
目前,大模型應用開發的技術架構主要有四種:

4.1.1 純Prompt模式
不同的提示詞能夠讓大模型給出差異巨大的答案。
不斷雕琢提示詞,使大模型能給出最理想的答案,這個過程就叫做提示詞工程(Prompt Engineering)。
很多簡單的AI應用,僅僅靠一段足夠好的提示詞就能實現了,這就是純Prompt模式。
其流程如圖:

4.1.2 FunctionCalling
大模型雖然可以理解自然語言,更清晰弄懂用戶意圖,但是確無法直接操作數據庫、執行嚴格的業務規則。這個時候我們就可以整合傳統應用于大模型的能力了。
簡單來說,可以分為以下步驟:
- 我們可以把傳統應用中的部分功能封裝成一個個函數(Function)。
- 然后在提示詞中描述用戶的需求,并且描述清楚每個函數的作用,要求AI理解用戶意圖,判斷什么時候需要調用哪個函數,并且將任務拆解為多個步驟(Agent)。
- 當AI執行到某一步,需要調用某個函數時,會返回要調用的函數名稱、函數需要的參數信息。
- 傳統應用接收到這些數據以后,就可以調用本地函數。再把函數執行結果封裝為提示詞,再次發送給AI。
- 以此類推,逐步執行,直到達成最終結果。
流程如圖:

注意:
并不是所有大模型都支持Function Calling,比如DeepSeek-R1模型就不支持。
4.1.3 RAG
RAG(Retrieval**-Augmented Generation)叫做檢索增強生成。簡單來說就是把信息檢索技術和大模型**結合的方案。
大模型從知識角度存在很多限制:
- 時效性差:大模型訓練比較耗時,其訓練數據都是舊數據,無法實時更新
- 缺少專業領域知識:大模型訓練數據都是采集的通用數據,缺少專業數據
可能有同學會說, 簡單啊,我把最新的數據或者專業文檔都拼接到提示詞,一起發給大模型,不就可以了。
同學,你想的太簡單了,現在的大模型都是基于Transformer神經網絡,Transformer的強項就是所謂的注意力機制。它可以根據上下文來分析文本含義,所以理解人類意圖更加準確。
但是,這里上下文的大小是有限制的,GPT3剛剛出來的時候,僅支持2000個token的上下文。現在領先一點的模型支持的上下文數量也不超過 200K token,所以海量知識庫數據是無法直接寫入提示詞的。
怎么辦呢?
RAG技術正是來解決這一問題的。
RAG就是利用信息檢索技術來拓展大模型的知識庫,解決大模型的知識限制。整體來說RAG分為兩個模塊:
- 檢索模塊(Retrieval):負責存儲和檢索拓展的知識庫
- 文本拆分:將文本按照某種規則拆分為很多片段
- 文本嵌入(Embedding):根據文本片段內容,將文本片段歸類存儲
- 文本檢索:根據用戶提問的問題,找出最相關的文本片段
- 生成模塊(Generation):
- 組合提示詞:將檢索到的片段與用戶提問組織成提示詞,形成更豐富的上下文信息
- 生成結果:調用生成式模型(例如DeepSeek)根據提示詞,生成更準確的回答
由于每次都是從向量庫中找出與用戶問題相關的數據,而不是整個知識庫,所以上下文就不會超過大模型的限制,同時又保證了大模型回答問題是基于知識庫中的內容,完美!
流程如圖:

4.1.4 Fine-tuning
Fine-tuning就是模型微調,就是在預訓練大模型(比如DeepSeek、Qwen)的基礎上,通過企業自己的數據做進一步的訓練,使大模型的回答更符合自己企業的業務需求。這個過程通常需要在模型的參數上進行細微的修改,以達到最佳的性能表現。
在進行微調時,通常會保留模型的大部分結構和參數,只對其中的一小部分進行調整。這樣做的好處是可以利用預訓練模型已經學習到的知識,同時減少了訓練時間和計算資源的消耗。微調的過程包括以下幾個關鍵步驟:
- 選擇合適的預訓練模型:根據任務的需求,選擇一個已經在大量數據上進行過預訓練的模型,如Qwen-2.5。
- 準備特定領域的數據集:收集和準備與任務相關的數據集,這些數據將用于微調模型。
- 設置超參數:調整學習率、批次大小、訓練輪次等超參數,以確保模型能夠有效學習新任務的特征。
- 訓練和優化:使用特定任務的數據對模型進行訓練,通過前向傳播、損失計算、反向傳播和權重更新等步驟,不斷優化模型的性能。
模型微調雖然更加靈活、強大,但是也存在一些問題:
- 需要大量的計算資源
- 調參復雜性高
- 過擬合風險
總之,Fine-tuning成本較高,難度較大,并不適合大多數企業。而且前面三種技術方案已經能夠解決常見問題了。
那么,問題來了,我們該如何選擇技術架構呢?
4.2技術選型
從開發成本由低到高來看,四種方案排序如下:
Prompt < Function Calling < RAG < Fine-tuning
所以我們在選擇技術時通常也應該遵循"在達成目標效果的前提下,盡量降低開發成本"這一首要原則。然后可以參考以下流程來思考:












)







