系列文章目錄
文章目錄
- 系列文章目錄
- 前言
- 一、torchvision.datasets
- 1. 數據下載
- 2. 數據分批次傳入
- 二、網絡
- 1. 網絡搭建
- 2. 訓練
- 3.測試
- 完整代碼
- 三、保存模型與推理(inference)
- 模型保存
- 推理
- 鳴謝
前言
??手寫數字識別,就是要根據手寫的數字0~9,然后我們搭建網絡,進行智能識別。說句實話,中草藥識別啊,等等。都可以用在本科的畢業設計論文中,妥妥的加分項,而且還不難。最離譜的是我有一個研究生的哥們兒,也用這個當做畢業設計論文,準確率高達99%。笑死我了,哈哈哈,我只能說,水深啊
?? 在實戰一中,我們已經詳細講解了 torch 完成一個神經網絡搭建的過程,在以后我將直接給出代碼,講解額外的庫函數。
一、torchvision.datasets
1. 數據下載
??本文使用的手寫數字的識別就在 torchvision.datasets 中,我們可以直接調用。在手寫數據中,有 6 w張訓練集和 1 w 張測試集。
dowload = True, 只能運行一次,之后改成False, transform.Tensor ,就是把數據轉化成我們可以使用的 Tensor 數據類型。
代碼加載數據:
# data
train_data = datasets.MNIST(root='./datasets',train = True,transform = transforms.ToTensor(),download=True)
但是這個下載可能有點慢?這里給出一個百度鏈接:
https://pan.baidu.com/s/1ia3vFA73hEtWK9qU-O-4iQ?pwd=mnis
2. 數據分批次傳入
??在第一個章節中,我們把數據一次加載到訓練集和測試集中,但是深度學習的照片可能很大,我們這里要用一種新的方法:
# batchSize
train_loader = data_util.DataLoader(dataset=train_data,batch_size=64,shuffle=True)test_loader = data_util.DataLoader(dataset=test_data,batch_size=64,shuffle=True)
dataset = train_data 這個參數是傳入要分割的數據集,batch_size 分塊的批次,shuffle 數據是否需要打亂,那必須的啊。所以把這個當做模版來,用的時候就 CV。
二、網絡
1. 網絡搭建
??在實戰一中,我們是直接定義算子,然后組合在一起。在實戰二中,我們玩點不一樣的,使用序列定義算子。
class CNN(torch.nn.Module):def __init__(self):super(CNN, self).__init__()# 定義第一個卷積操作self.conv = torch.nn.Sequential(# 參數的具體含義我們在卷積神經網絡中介紹torch.nn.Conv2d(1, 32, kernel_size=(5,5),padding = 2),# 第一個參數是灰度,第二個參數是輸出通道,第三個參數是卷積核torch.nn.BatchNorm2d(32),torch.nn.ReLU(),torch.nn.MaxPool2d(2))self.fc = torch.nn.Linear(14*14*32,10) # 第一個是特征圖整體的數量,第二個是Y的種類def forward(self, x):out = self.conv(x) # 第一個卷積out = out.view(out.size()[0],-1) # 拉成一個一維的向量out = self.fc(out) # 線性運算return out # 返回最后的輸出
cnn = CNN()
??class 用于構建我們的網絡,第一個函數除了繼承父類的初始化操作,還要定義我們的算子。卷積操作,用一個序列torch.nn.Sequential,在里面定義了一個 2d 卷積、BatchNorm等等,這些參數的配置我們在卷積神經網絡會細講。此處我們需要了解編程的結構。網絡中定義了一個前向傳播算子,經過卷積,拉直,輸出的線性化。
2. 訓練
cnn = cnn.cuda()
# loss
loss_fn = torch.nn.CrossEntropyLoss() # 交叉熵的損失函數# optimizer
optimizer = torch.optim.Adam(cnn.parameters(),lr=0.01)# 采用Adam 對學習率不是特別敏感
# training
for epoch in range(10):# 這里我們把整個數據集過 10 遍for i, (images, labels) in enumerate(train_loader):images = images.cuda() # 圖片放到cuda上面labels = labels.cuda()# 定義輸出結構outputs = cnn(images)loss = loss_fn(outputs,labels) # loss 傳入輸出的結果optimizer.zero_grad() # 梯度優化loss.backward() # 反向傳播optimizer.step()print("Epoch is:{} item is :{}/{} Loss is :{}".format(epoch+1,i,len(train_data)//64,loss.item()))
把網絡加載到cuda上面,使用顯卡跑數據。損失函數采用交叉熵,優化函數采用Adam,這可以減小學習率的影響。然后訓練10個輪次,每個輪次還有64個區塊,我們都要訓練完全。訓練過程每個batch:
- 把數據加載到 cuda 上面
- 網絡上跑一邊獲得第一個輸出,輸出在net中已經處理了。
- 計算損失函數
- 梯度優化器
- 損失函數反向傳播
- 優化器保存參數
圖片:
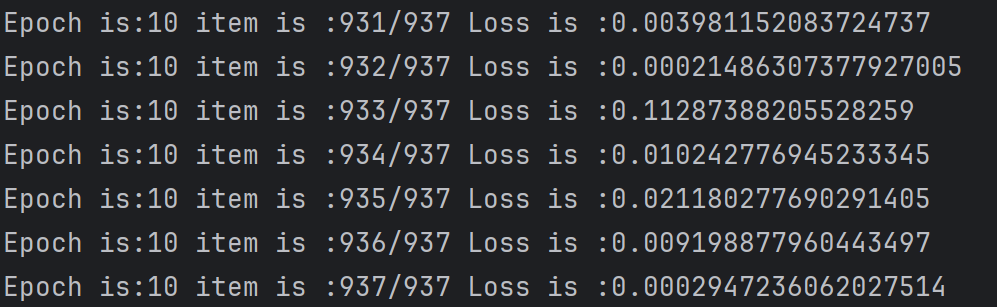
3.測試
??測試我們在每個epoch測試一次(每輪測試),注意代碼的位置。用測試集來跑模型,然后計算出準確率。
# testloss_test = 0accuracy = 0for i, (images, labels) in enumerate(test_loader):images = images.cuda() # 圖片放到cuda上面labels = labels.cuda()# 定義輸出結構outputs = cnn(images)# 我們使用交叉熵計算,label 的維度是[batchsize],每個樣本的標簽樣本是一個值# outputs = batches * cls_num cls_num 概率分布也就是種類10 個loss_test += loss_fn(outputs, labels) # loss 傳入輸出的結果,對text_loss 進行一個累加,最后求平均值_, predicted = outputs.max(dim=1) # 獲得最大的概率作為我們的預測值accuracy += (predicted ==labels).sum().item() # 我們通過相同的樣本進行統計求和,通過item獲取這個值accuracy = accuracy/len(test_data)loss_test=loss_test/(len(test_data)//64) # 除以batch的個數print("測試:\nEpoch is:{} accuracy is :{} loss_test is :{}".format(epoch+1,accuracy,loss_test.item()))
??測試我們定義在每輪測試一次。先定義損失函數的值和準確率為零,我們把他們的每個batch求和,然后求得平均值,這是我們測試經常做的。注意預測, _, predicted = outputs.max(dim=1) 我們取得最大的預測結果,_ 表示忽略索引,只保留預測的標簽。accuracy += (predicted ==labels).sum().item() 把預測值和真實值進行比較,再求和,再取得數據,加到 accuracy (每個batch的輪次)。.item() 將單元素張量轉換為Python標量,有利于計算。最后計算求平均值,準確率除以整個測試集,而loss_test 除以batch的數量,因為損失函數這一個batch只有一個,準確率統計了這個batch的所有正確樣本。
圖片:
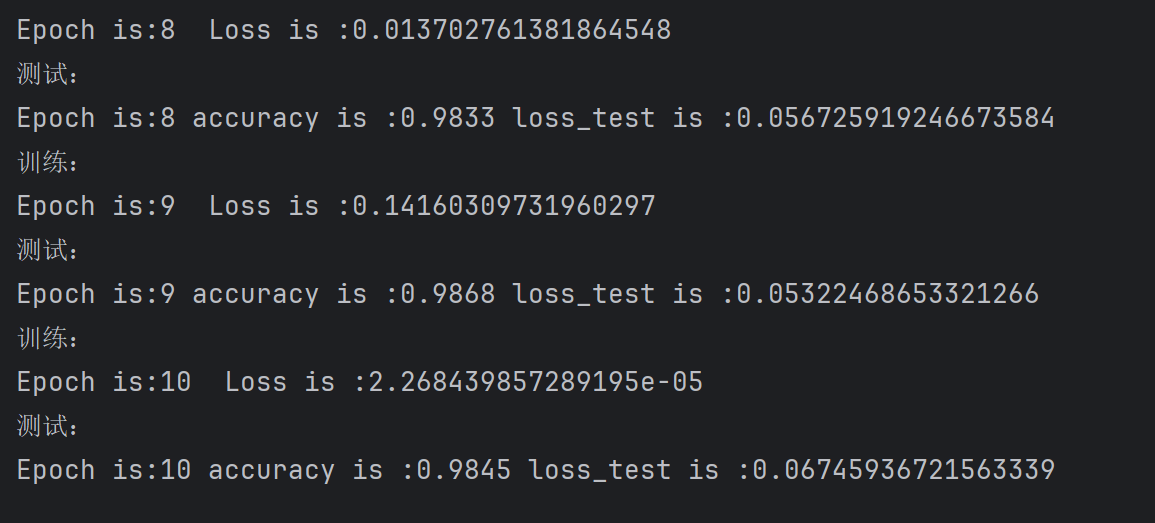
??從數據來看,準確率 98%,loss 也在0.06 左右,基本是個好模型了。
完整代碼
記得修改數據集的路徑:
import torch
import torchvision.datasets as datasets
import torchvision.transforms as transforms
import torch.utils.data as data_util
# data
train_data = datasets.MNIST(root='datasets',train = True,transform = transforms.ToTensor(),download=True)
test_data = datasets.MNIST(root='datasets',train = False,transform = transforms.ToTensor(),download=False)# batchSize
train_loader = data_util.DataLoader(dataset=train_data,batch_size=64,shuffle=True)test_loader = data_util.DataLoader(dataset=test_data,batch_size=64,shuffle=True)
# net
class CNN(torch.nn.Module):def __init__(self):super(CNN, self).__init__()# 定義第一個卷積操作self.conv = torch.nn.Sequential(# 參數的具體含義我們在卷積神經網絡中介紹torch.nn.Conv2d(1, 32, kernel_size=(5,5),padding=2),# 第一個參數是灰度,第二個參數是輸出通道,第三個參數是卷積核torch.nn.BatchNorm2d(32),torch.nn.ReLU(),torch.nn.MaxPool2d(2))self.fc = torch.nn.Linear(14*14*32,10) # 第一個是特征圖整體的數量,第二個是Y的種類def forward(self, x):out = self.conv(x) # 第一個卷積out = out.view(out.size()[0],-1) # 拉成一個一維的向量out = self.fc(out) # 線性運算return out # 返回最后的輸出
cnn = CNN()
cnn = cnn.cuda()
# loss
loss_fn = torch.nn.CrossEntropyLoss() # 交叉熵的損失函數# optimizer
optimizer = torch.optim.Adam(cnn.parameters(),lr=0.01)# 采用Adam 對學習率不是特別敏感
# training
for epoch in range(10):# 這里我們把整個數據集過 10 遍for i, (images, labels) in enumerate(train_loader):images = images.cuda() # 圖片放到cuda上面labels = labels.cuda()# 定義輸出結構outputs = cnn(images)loss = loss_fn(outputs,labels) # loss 傳入輸出的結果optimizer.zero_grad() # 梯度優化loss.backward() # 反向傳播optimizer.step()# print("訓練:\nEpoch is:{} Loss is :{}".format(epoch+1,loss.item()))
# testloss_test = 0accuracy = 0for i, (images, labels) in enumerate(test_loader):images = images.cuda() # 圖片放到cuda上面labels = labels.cuda()# 定義輸出結構outputs = cnn(images)# 我們使用交叉熵計算,label 的維度是[batchsize],每個樣本的標簽樣本是一個值# outputs = batches * cls_num cls_num 概率分布也就是種類10 個loss_test += loss_fn(outputs, labels) # loss 傳入輸出的結果,對text_loss 進行一個累加,最后求平均值_, predicted = outputs.max(dim=1) # 獲得最大的概率作為我們的預測值accuracy += (predicted ==labels).sum().item() # 我們通過相同的樣本進行統計求和,通過item獲取這個值accuracy = accuracy/len(test_data)loss_test=loss_test/(len(test_data)//64) # 除以batch的個數# .item() 將單元素張量轉換為Python標量# print("測試:\nEpoch is:{} accuracy is :{} loss_test is :{}".format(epoch+1,accuracy,loss_test.item()))# 保存模型
torch.save(cnn,"model/cnn.pkl")三、保存模型與推理(inference)
模型保存
# 保存模型
torch.save(cnn,"model/cnn.pkl")
推理
import torch
import torchvision.datasets as datasets
import torchvision.transforms as transforms
import torch.utils.data as data_util# net
class CNN(torch.nn.Module):def __init__(self):super(CNN, self).__init__()# 定義第一個卷積操作self.conv = torch.nn.Sequential(# 參數的具體含義我們在卷積神經網絡中介紹torch.nn.Conv2d(1, 32, kernel_size=(5,5),padding=2),# 第一個參數是灰度,第二個參數是輸出通道,第三個參數是卷積核torch.nn.BatchNorm2d(32),torch.nn.ReLU(),torch.nn.MaxPool2d(2))self.fc = torch.nn.Linear(14*14*32,10) # 第一個是特征圖整體的數量,第二個是Y的種類def forward(self, x):out = self.conv(x) # 第一個卷積out = out.view(out.size()[0],-1) # 拉成一個一維的向量out = self.fc(out) # 線性運算return out # 返回最后的輸出test_data = datasets.MNIST(root='../datasets',train = False,transform = transforms.ToTensor(),download=False)# batchSize
test_loader = data_util.DataLoader(dataset=test_data,batch_size=64,shuffle=True)
cnn = torch.load("cnn.pkl")
cnn = cnn.cuda()
# loss
loss_fn = torch.nn.CrossEntropyLoss() # 交叉熵的損失函數# optimizer
optimizer = torch.optim.Adam(cnn.parameters(),lr=0.01)# 采用Adam 對學習率不是特別敏感
# training
for epoch in range(10):# 這里我們把整個數據集過 10 遍
# testloss_test = 0accuracy = 0for i, (images, labels) in enumerate(test_loader):images = images.cuda() # 圖片放到cuda上面labels = labels.cuda()# 定義輸出結構outputs = cnn(images)# 我們使用交叉熵計算,label 的維度是[batchsize],每個樣本的標簽樣本是一個值# outputs = batches * cls_num cls_num 概率分布也就是種類10 個loss_test += loss_fn(outputs, labels) # loss 傳入輸出的結果,對text_loss 進行一個累加,最后求平均值_, predicted = outputs.max(dim=1) # 獲得最大的概率作為我們的預測值accuracy += (predicted ==labels).sum().item() # 我們通過相同的樣本進行統計求和,通過item獲取這個值accuracy = accuracy/len(test_data)loss_test=loss_test/(len(test_data)//64) # 除以batch的個數# .item() 將單元素張量轉換為Python標量# print("測試:\nEpoch is:{} accuracy is :{} loss_test is :{}".format(epoch+1,accuracy,loss_test.item()))
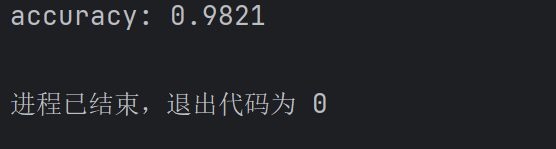
print("accuracy:",accuracy)??模型推理的數據集一定要找準確,模型調用的路徑也要準確。我們可以直接復制代碼到新建的推理 python 文件中:
- 刪除所有與訓練有關的數據
- 刪除模型的保存部分
3.模型初始化改成調用:cnn = torch.load("cnn.pkl")
4.修改打印參數
運行結果:
鳴謝
??為了感謝我弟對我的照顧,我也沒有什么可以報答的,如果這篇文章有助于大家搭建一個神經網絡,有助于大家的pytorch編程,還請大家來我弟的小店逛一逛,增加一點訪問量,小店才開也不容易,點擊一下這里 ,謝謝大家~。
![[Godot] C#讀取CSV表格創建雙層字典實現本地化](http://pic.xiahunao.cn/[Godot] C#讀取CSV表格創建雙層字典實現本地化)


(附詳細解題思路))





:-W1、-L、-rpath和-rpath-link)

)







