Hive 技術及應用介紹
參考資料
- Hive 技術原理
- Hive 架構及應用介紹
- Hive - 小海哥哥 de - 博客園
- https://cwiki.apache.org/confluence/display/Hive/Home(官方文檔)
Apache Hive 是基于 Hadoop 構建的數據倉庫工具,它為海量結構化數據提供類 SQL 的查詢能力,并將查詢翻譯為 MapReduce、Tez 或 Spark 作業執行。Hive 簡化了大數據批量分析的使用門檻,讓熟悉 SQL 的開發者能夠在 Hadoop 生態上輕松進行 ETL、OLAP 和 BI 分析。
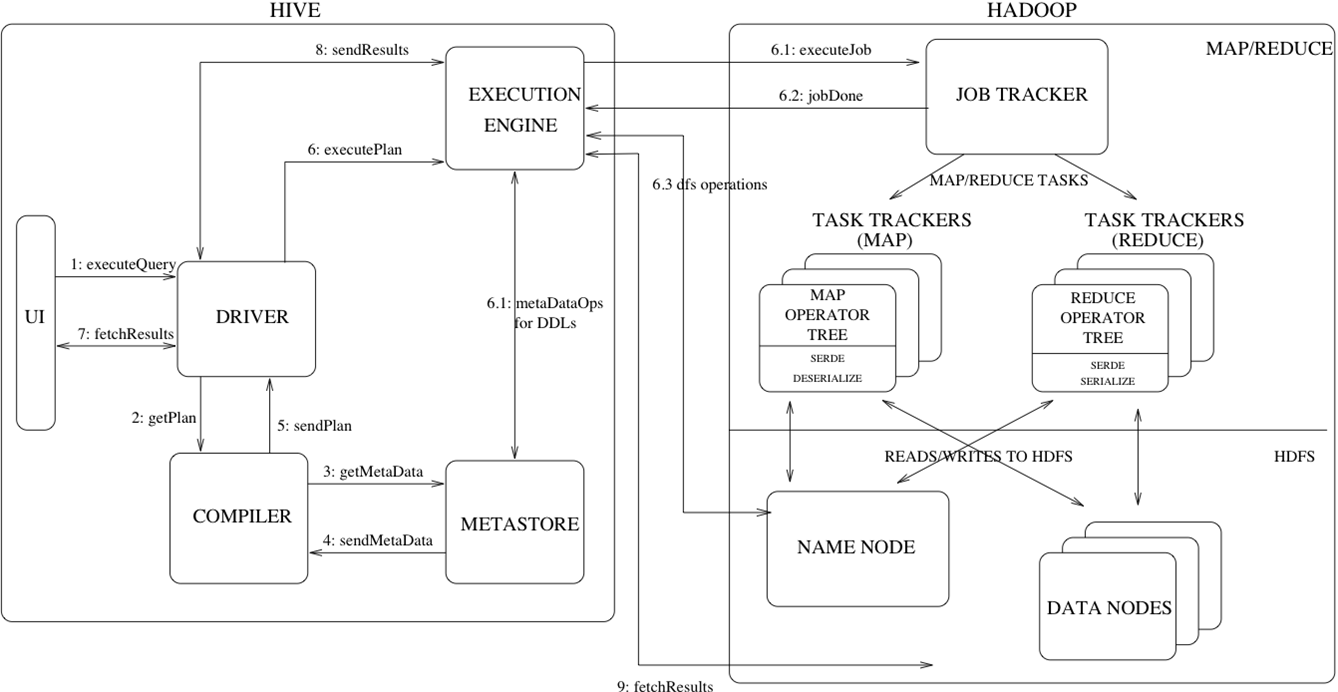
Hive 的執行流程
Hive 的背景與定位
- 背景:隨著大數據時代到來,Hadoop 分布式文件系統(HDFS)與 MapReduce 為存儲與計算提供了高吞吐的能力,但原生 MapReduce 編程復雜、開發成本高。
- 定位:Hive 通過 HiveQL(類似 SQL 的查詢語言)屏蔽 MapReduce/Tez/Spark 的底層細節,將查詢語句編譯為執行計劃并自動運行,適合批量離線分析,主要面向 ETL、數據聚合與多維分析。
Hive 在 Hadoop 生態系統中的位置

Hive 的運行深度依賴于 Hadoop 的核心生態,包括其分布式文件系統 HDFS、計算框架 MapReduce 以及資源調度器 YARN,因此可以將 Hive 理解為一種構建在 Hadoop 之上的 “SQL on Hadoop” 應用。其核心工作機制是將用戶輸入的類 SQL 查詢語句轉換為底層的 MapReduce 任務來執行,也正是因為多了這一步從 SQL 到 MapReduce 的轉化開銷,所以在同等條件下,Hive 查詢的執行效率通常會低于直接編寫原生 MapReduce 程序。
Hive 體系結構
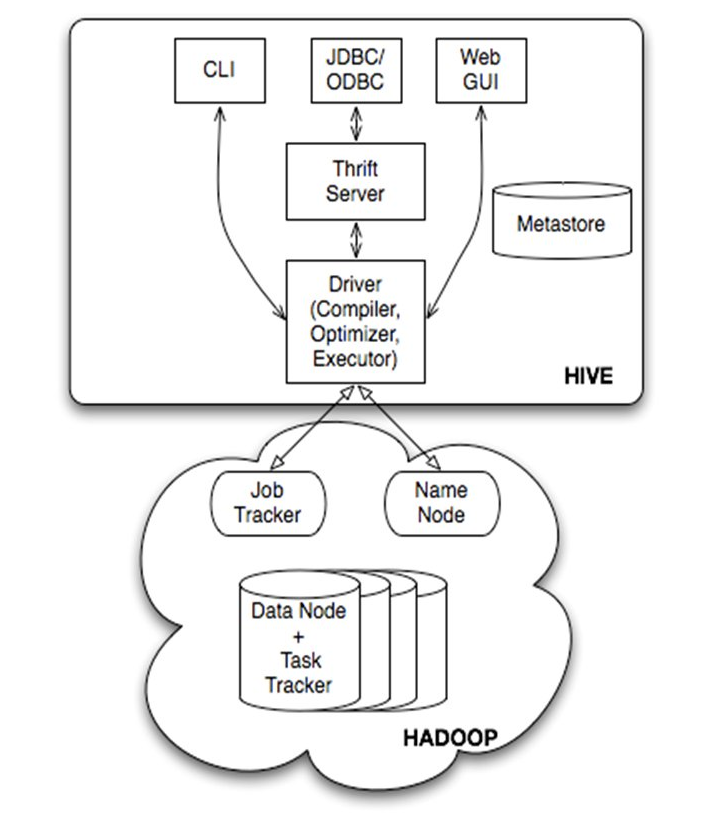
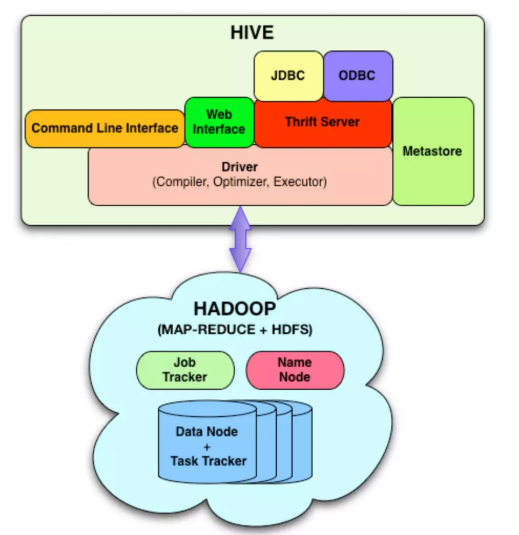
Hive 的核心組件包括:
-
Hive 客戶端(CLI、Beeline、JDBC/ODBC)
- 支持交互式提交 HiveQL,或通過 JDBC/ODBC 接入 BI 工具(如 Tableau、Power BI)。
-
Driver
- 接收并解析 HiveQL,生成抽象語法樹(AST),再進行優化和編譯,生成執行計劃(Execution Plan)。
-
Compiler / Optimizer
- 將 AST 轉為邏輯計劃,應用謂詞下推、列裁剪等優化,再生成物理計劃,拆分為一個或多個 MapReduce/Tez/Spark 任務。
-
Execution Engine
- 將物理計劃提交給底層執行框架(MapReduce、Tez 或 Spark),監控任務狀態并返回結果。
-
Metastore
- 存儲表結構、分區信息、列類型、SerDe、統計信息等元數據,通常使用 MySQL、PostgreSQL 或 Derby。
數據模型與存儲格式
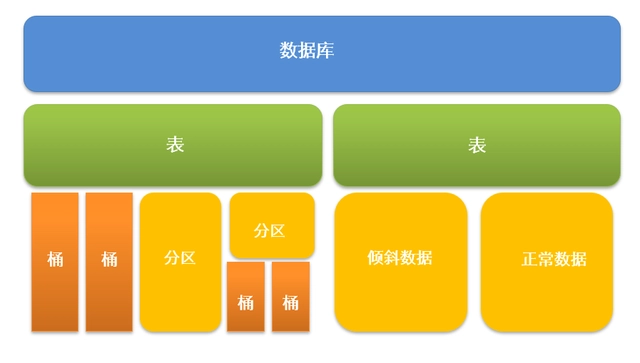
- 表與分區
- Hive 將 HDFS 文件組織為表(Table)、分區(Partition)和桶(Bucket)。分區通常按日期、地域等字段維度存儲,減少查詢掃描量。
數據庫:創建表時如果不指定數據庫,則默認為 default 數據庫。
表:物理概念,實際對應 HDFS 上的一個目錄。
分區:對應所在表所在目錄下的一個子目錄。
桶:對應表或分區所在路徑的一個文件
- 文件格式
- 支持文本(Text)、SequenceFile、ORC、Parquet、Avro 等列式與行式格式。列式格式(ORC、Parquet)通過壓縮和列裁剪大幅提升查詢性能。
-- 創建按日期分區的 ORC 表
CREATE EXTERNAL TABLE logs (user_id BIGINT,action STRING,ts TIMESTAMP
)
PARTITIONED BY (dt STRING)
STORED AS ORC
LOCATION '/data/logs/';
- SerDe(序列化/反序列化)
- 通過自定義 SerDe,Hive 能解析任意復雜格式(JSON、CSV、XML 等)。
HiveQL 基本用法
- www.slideshare.net
數據操作
創建表
CREATE TABLE IF NOT EXISTS example.employee(
Id INT COMMENT 'employeeid',
Company STRING COMMENT 'your company',
Money FLOAT COMMENT 'work money',)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
可以發現就是對應的 SQL 語句
查詢
SELECT id, name FROM employee WHERE salary >= 10000;
SELECT department, avg(salary) FROM employee GROUP BY department;
SELECT id, salary, date FROM employee_a UNION ALL
SELECT id, salary, date FROM employee_b;
-- 加載數據到表(分區)
ALTER TABLE logs ADD PARTITION (dt='2025-06-01');
LOAD DATA INPATH '/raw/logs/2025-06-01/*.log'
INTO TABLE logs PARTITION (dt='2025-06-01');
-- 簡單查詢
SELECT user_id, COUNT(*) AS cnt
FROM logs
WHERE dt='2025-06-01'
GROUP BY user_id
ORDER BY cnt DESC
LIMIT 10;
窗口函數與高級特性
-- 統計每個用戶每天的前 3 次操作
SELECT dt, user_id, action, ts,ROW_NUMBER() OVER (PARTITION BY dt, user_id ORDER BY ts) AS rn
FROM logs
WHERE dt >= '2025-06-01' AND dt <= '2025-06-07'
AND rn <= 3;
與 Spark 集成
在 Hive on Spark 模式下,HiveQL 會被提交到 Spark 引擎執行,兼享 Spark 的低延遲與豐富算子。
-- 啟動 Hive 使用 Spark 執行引擎
set hive.execution.engine=spark;
典型應用場景
-
ETL 批量處理
- 定時從日志系統、關系庫導入數據,清洗、聚合后寫入 Hive 數據倉庫,用于下游 BI 報表。
-
多維 OLAP 分析
- 基于 Hive 的 HiveCube 或第三方 OLAP 引擎(如 Apache Kylin)實現大規模多維分析。
-
數據探索與報表
- 數據分析師通過 Beeline 或 BI 工具(Tableau、Power BI)直接查詢 Hive 表。
-
機器學習特征工程
- 使用 HiveQL 快速統計用戶行為特征,然后將結果導出到 HDFS,再由 Spark/MLlib 訓練模型。
性能優化要點
-
合理分區
- 按查詢高頻過濾字段分區(如按日期、地域),減少文件掃描。
-
使用列式存儲
- ORC/Parquet 格式支持列裁剪、矢量化讀取和壓縮。
-
開啟成本模型優化
SET hive.cbo.enable=true;
-
利用 Tez/Spark
- 將執行引擎換為 Tez 或 Spark,降低 MapReduce 的啟動開銷與 I/O 序列化成本。
-
小文件合并
- 小文件過多會導致任務過多,建議合并或使用 HDFS 合并工具。
示例:用戶次日留存率統計
-- 1. 計算用戶首次活躍日期
CREATE TABLE user_first (user_id BIGINT,first_dt STRING
)
STORED AS ORC
AS
SELECT user_id, MIN(dt) AS first_dt
FROM logs
GROUP BY user_id;
-- 2. 次日留存:join 當天活躍用戶與第一天活躍日期后一天
SELECT f.first_dt AS reg_dt,l.dt AS act_dt,COUNT(DISTINCT f.user_id) AS reg_users,COUNT(DISTINCT l.user_id) AS retained_users,ROUND(COUNT(DISTINCT l.user_id) / COUNT(DISTINCT f.user_id), 4) AS retention_rate
FROM user_first f
JOIN logs lON f.user_id = l.user_idAND l.dt = date_add(f.first_dt, 1)
GROUP BY f.first_dt, l.dt
ORDER BY f.first_dt;
優缺點
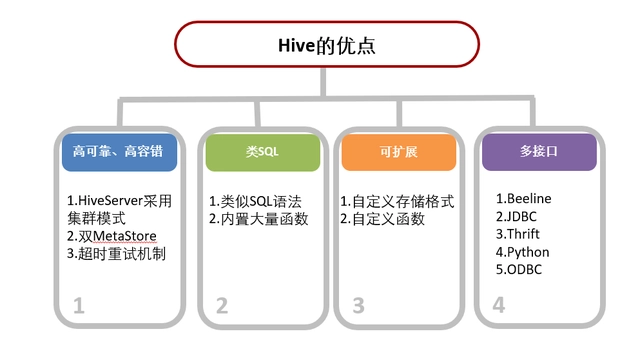
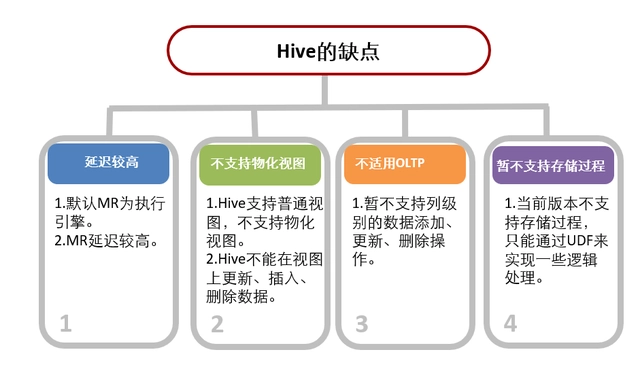
總結
- Hive 以 SQL 友好的方式在 Hadoop 集群上實現批量離線分析,適用于 ETL、OLAP、報表和特征工程。
- 通過 Metastore 管理元數據,通過多種文件格式和執行引擎(MapReduce/Tez/Spark)兼顧兼容性與性能。
- 合理分區、列式存儲和成本模型優化可顯著提升查詢性能。
- Hive 與 Spark、Flink、Presto 等工具生態配合,為大數據平臺提供靈活多樣的計算選擇。
Scrapy-Redis分布式爬蟲架構實戰:IP代理池深度集成與跨地域數據采集)

--單片機控制ESP8266實現TCP地址通信)


課71:查看指定 query_id 的 SQL 語句的執行各個階段的耗時情況 show profile for query query_id;)
)




 --- Linux 鏈表結構)







