Linux 適用于多種體系結構,需用體系結構無關方式描述內存。本章介紹影響 VM 行為的內存簇、頁面和標志位結構。
- 非一致內存訪問(NUMA):在 VM 中,大型機器內存分簇,依簇與處理器距離,訪問代價不同。可將內存簇指派給處理器或設備。每個簇是一個節點,Linux 中
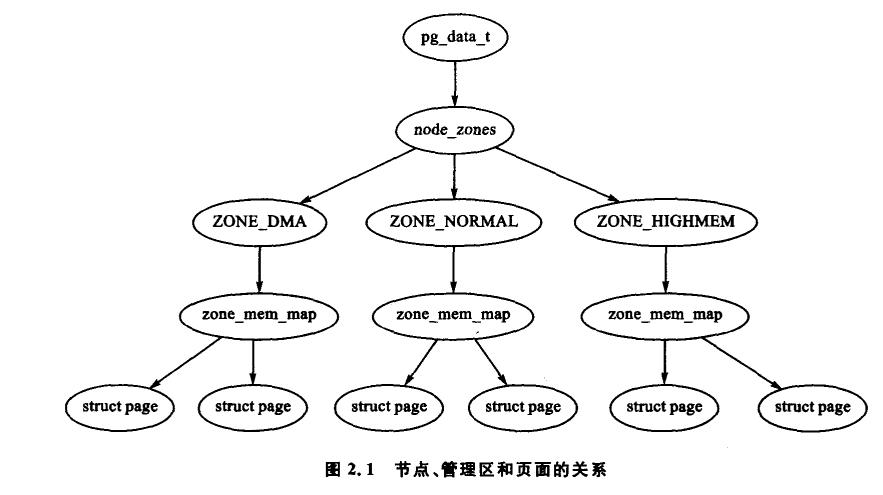
struct pg_data_t體現此概念,用于一致內存訪問(UMA)體系結構,系統節點鏈接成pgdat_list鏈表,節點通過pg_data_tnode_next字段連接。像 PC 采用 UMA 結構的機器,使用contig_page_data的靜態pg_data_t結構。 - 管理區(zone)
-
- 內存中節點分成管理區,由
struct zone_struct描述,類型為zone_t,包括ZONE_DMA、ZONE_NORMAL、ZONE_HIGHMEM。不同管理區適用于不同用途。 ZONE_DMA指低端物理內存,供某些 ISA 設備使用,x86 機器中存放前 16MB 內存。ZONE_NORMAL是內核直接映射到線性地址空間的較高部分,x86 機器范圍是 16MB - 896MB ,許多內核操作依賴此區,對系統性能影響重大。ZONE_HIGHMEM是系統預留的可用內存空間,不被內核直接映射,x86 機器從 896MB 到末尾 。
- 內存中節點分成管理區,由
- 頁面幀:系統內存劃分成頁面幀,由
struct page描述,結構存儲在全局mem_map數組,通常在ZONE_NORMAL首部或小內存系統預留區域。后續章節將討論其細節及內存結構間基本關系。
2.2 管理區
在Linux系統中,每個管理區由struct zone_t描述,zone_structs用于跟蹤頁面使用情況統計數、空閑區域信息和鎖信息等 ,在<linux/mmzone.h>中聲明如下:
typedef struct zone_struct {spinlock_t lock;unsigned long free_pages;unsigned long pages_min, pages_low, pages_high;int need_balance;free_area_t free_area[MAX_ORDER];wait_queue_head_t * wait_table;unsigned long wait_table_size;unsigned long wait_table_shift;struct pglist_data *zone_pgdat;struct page *zone_mem_map;unsigned long zone_start_paddr;unsigned long zone_start_mapnr;char *name;unsigned long size;
} zone_t;- lock:并行訪問時保護該管理區的自旋鎖。
- free_pages:管理區中空閑頁面的總數。
- pages_min, pages_low, pages_high:管理區極值,用于跟蹤管理區壓力情況 。
- need_balance:標志位,通知頁面換出kswapd平衡管理區,當可用頁面數量達到管理區極值某值時,需平衡管理區。
- free_area:空閑區域位圖,由伙伴分配器使用。
- wait_table:等待隊列的哈希表,由等待頁面釋放的進程組成,對
wait_on_page()和unlock_page()重要 。 - wait_table_size:哈希表大小,是2的冪。
- wait_table_shift:定義為一個
long型對應的位數減去該表大小的二進制對數。 - zone_pgdat:指向父
pg_data_t。 - zone_mem_map:涉及的管理區在全局
mem_map中的第一頁。 - zone_start_paddr:同
node_start_paddr。 - zone_start_mapnr:同
node_start_mapnr。 - name:管理區字符串名字,如“DMA”“Normal”或“HighMem” 。
- size:管理區大小,以頁面數計算。
以下是關于Linux內核mmzone.h頭文件的內存管理架構解析(整理為中文):
一、Linux內存管理與mmzone.h概述
Linux內核將物理內存劃分為節點(Node,適用于NUMA系統)和區域(Zone,基于內存類型)。
mmzone.h定義了管理這些內存區域的核心數據結構和常量,尤其是分區伙伴分配器(zoned buddy allocator)——內核用于分配物理內存頁的主要機制。
核心架構概念:
- 內存節點(Memory Nodes)
在NUMA系統中,物理內存按節點劃分,每個節點與一個或一組處理器關聯,通過pg_data_t結構管理。 - 內存區域(Memory Zones)
每個節點內的內存進一步按用途劃分為區域(如DMA、Normal、Highmem),用于處理硬件限制(如DMA設備的地址范圍限制)或性能特性。 - 伙伴分配器(Buddy Allocator)
內核通過伙伴系統管理每個區域的空閑頁,將頁按2的冪次塊(Order)分組,減少內存碎片。 - NUMA感知(NUMA Awareness)
內核優化內存分配,優先使用本地節點內存以提升性能。 - 頁面回收(Page Reclamation)
區域跟蹤活躍(Active)和非活躍(Inactive)頁,用于內存不足時的回收(如交換或釋放頁)。
mmzone.h是這些機制的核心,定義了內存的組織、分配和回收邏輯。
二、mmzone.h中的關鍵數據結構
a. struct free_area
struct free_area {struct list_head free_list; // 同大小空閑塊鏈表(按Order分組)unsigned long nr_free; // 該大小的空閑塊數量
};- 作用:表示伙伴分配器中特定大小(Order)的空閑內存塊列表。
- 架構角色:每個區域維護一個
free_area數組(每個Order對應一項),伙伴系統通過分裂/合并塊來管理內存,減少外部碎片。 - 面試要點:解釋伙伴系統如何通過分裂(如將4頁塊拆分為2個2頁塊)和合并塊滿足分配請求。
b. struct per_cpu_pages
struct per_cpu_pages {int count; // 緩存中的頁數int low, high; // 觸發緩存填充/清空的水位線int batch; // 單次操作添加/移除的頁數struct list_head list; // 頁鏈表
};- 作用:管理 per-CPU 頁緩存,減少分配時對全局區域鎖的競爭。
- 架構角色:CPU可直接從本地緩存分配/釋放頁,避免鎖競爭。熱緩存(Hot)和冷緩存(Cold)區分近期使用頁,優化緩存局部性。
- 面試要點:討論per-CPU緩存如何提升SMP系統性能,以及緩存空間與鎖競爭的權衡。
c. struct per_cpu_pageset
struct per_cpu_pageset {struct per_cpu_pages pcp[2]; // 0: 熱頁,1: 冷頁
#ifdef CONFIG_NUMAunsigned long numa_hit; // 在目標節點分配成功數unsigned long numa_miss; // 在非目標節點分配數// 其他NUMA統計字段
#endif
} ____cacheline_aligned_in_smp;- 作用:擴展per-CPU頁緩存,增加NUMA統計和熱/冷頁分離。
- 架構角色:通過NUMA統計(如
numa_hit)優化節點分配策略,緩存行對齊(____cacheline_aligned_in_smp)減少SMP系統中的偽共享(False Sharing)。 - 面試要點:解釋NUMA對內存分配的影響,內核如何優先本地節點分配以降低延遲。
d. struct zone
struct zone {unsigned long free_pages; // 區域空閑頁數struct free_area free_area[]; // 伙伴分配器的空閑塊數組spinlock_t lock; // 保護伙伴分配器的自旋鎖struct per_cpu_pageset pageset[]; // per-CPU頁緩存struct list_head active_list, inactive_list; // LRU鏈表// 其他字段(回收統計、水位線、節點關聯等)
} ____cacheline_maxaligned_in_smp;- 作用:表示節點內的一個內存區域(如DMA、Normal、Highmem)。
- 核心功能:
-
- 分配:通過
free_area和lock管理伙伴系統。 - 回收:通過LRU鏈表(
active_list/inactive_list)和kswapd線程實現頁面回收。 - 元數據:
zone_start_pfn(區域起始頁幀號)、lowmem_reserve(保留低內存防止耗盡)。
- 分配:通過
- 架構角色:區域是節點內存管理的核心,平衡分配效率與硬件約束(如DMA的地址限制)。
- 面試要點:說明區域如何處理硬件限制(如Highmem在32位系統的作用),以及
lowmem_reserve如何保障關鍵區域內存。
e. struct zonelist
struct zonelist {struct zone *zones[MAX_NUMNODES * MAX_NR_ZONES + 1]; // 按優先級排序的區域列表(NULL結尾)
};- 作用:定義內存分配時的區域優先級列表(如優先本地節點,再 fallback 其他節點)。
- 架構角色:結合GFP標志(如
__GFP_DMA)實現NUMA感知分配和故障轉移策略。 - 面試要點:解釋
zonelist如何支持NUMA分配,以及不同分配標志(如DMA/Highmem)如何影響區域選擇。
f. struct pglist_data (pg_data_t)
typedef struct pglist_data {struct zone node_zones[]; // 節點內的所有區域(如DMA、Normal)struct zonelist node_zonelists[]; // 分配時的區域優先級列表struct page *node_mem_map; // 節點頁結構數組struct task_struct *kswapd; // 節點的頁面回收線程// 其他字段(節點ID、內存范圍、啟動內存數據等)
} pg_data_t;- 作用:表示NUMA系統中的一個內存節點,封裝節點內的所有內存管理邏輯。
- 架構角色:鏈接區域(
node_zones)和分配策略(node_zonelists),通過kswapd線程實現節點級內存回收。 - 面試要點:說明
pg_data_t如何支持NUMA,以及節點鏈表(pgdat_next)如何遍歷所有節點。
三、關鍵常量與宏
MAX_ORDER
-
- 定義伙伴分配器的最大塊大小(默認11,即2^11頁,約8MB/4KB頁),可通過
CONFIG_FORCE_MAX_ZONEORDER配置。 - 面試要點:討論增大
MAX_ORDER的權衡(支持大分配 vs. 增加碎片風險)。
- 定義伙伴分配器的最大塊大小(默認11,即2^11頁,約8MB/4KB頁),可通過
- 區域類型(ZONE_DMA, ZONE_NORMAL, ZONE_HIGHMEM)
-
- DMA:適用于ISA設備(<16MB,x86系統)。
- Normal:內核直接映射的內存(16MB~896MB,x86 32位)。
- Highmem:內核無法永久映射的高端內存(>896MB,僅32位系統需要)。
- 面試要點:解釋Highmem存在的原因(32位內核地址空間限制)及管理方式(動態映射如
kmap)。
GFP_ZONEMASK與GFP_ZONETYPES
-
GFP_ZONEMASK:分配標志中指定目標區域的位掩碼(如0x03)。GFP_ZONETYPES:計算所需zonelist數量,優化內存使用。- 面試要點:說明GFP標志如何影響區域選擇(如
__GFP_HIGHMEM允許從Highmem分配)。
四、架構設計原則
- 模塊化與抽象
-
- 通過
zone和pg_data_t抽象節點和區域,支持跨架構(NUMA/UMA、32/64位)移植。 zonelist解耦分配邏輯與硬件細節。
- 通過
- 性能優化
-
- Per-CPU緩存:減少鎖競爭,提升SMP系統吞吐量。
- 緩存行對齊:通過
____cacheline_aligned_in_smp避免偽共享。 - NUMA感知:優先本地節點分配,降低內存訪問延遲。
- 可擴展性
-
- 伙伴分配器的對數復雜度(與
MAX_ORDER相關)支持大內存系統。 - NUMA支持擴展至多節點架構(
MAX_NODES_SHIFT)。
- 伙伴分配器的對數復雜度(與
- 可靠性
-
lowmem_reserve保障關鍵區域(如DMA)內存,避免饑餓。- LRU鏈表和
kswapd線程防止OOM(內存不足)。
- 靈活性
-
- 通過宏(如
CONFIG_DISCONTIGMEM、CONFIG_NUMA)適配不同內存架構。 wait_table支持進程等待頁可用,緩解分配競爭。
- 通過宏(如
五、面試常見問題與解答
- 區域(Zone)在內存管理中的作用?
-
- 答:區域按硬件約束劃分內存(如DMA的地址限制、Highmem的內核映射限制),每個區域獨立管理分配(伙伴系統)和回收(LRU鏈表),提升硬件兼容性和分配效率。
- 伙伴分配器如何工作?
MAX_ORDER的意義?
-
- 答:伙伴系統將空閑頁按2的冪次塊分組(Order 0~MAX_ORDER-1),分配時分裂大塊,釋放時合并相鄰塊以減少碎片。
MAX_ORDER決定最大塊大小,平衡大分配支持與碎片風險。
- 答:伙伴系統將空閑頁按2的冪次塊分組(Order 0~MAX_ORDER-1),分配時分裂大塊,釋放時合并相鄰塊以減少碎片。
- Linux如何處理NUMA系統的內存分配?
-
- 答:通過
pg_data_t管理節點,zonelist優先本地節點區域分配,利用numa_hit/numa_miss統計優化策略,kswapd線程按節點獨立回收內存,降低跨節點訪問延遲。
- 答:通過
lowmem_reserve的作用?
-
- 答:在低內存區域(如DMA、Normal)預留內存,防止高內存區域(如Highmem)的分配耗盡關鍵區域內存,保障硬件設備(如DMA設備)的正常運行。
- 內核如何減少內存分配的鎖競爭?
-
- 答:使用per-CPU頁緩存(
per_cpu_pageset)避免全局鎖,緩存行對齊減少偽共享,自旋鎖(如lock、lru_lock)保護共享結構,縮小鎖持有時長。
- 答:使用per-CPU頁緩存(
六、深入理解要點
- 緩存行對齊:
____cacheline_maxaligned_in_smp確保關鍵結構(如自旋鎖)獨占緩存行,避免多CPU訪問不同變量時的緩存一致性開銷。 - Highmem挑戰:32位系統中,Highmem頁需動態映射(如
kmap),增加管理復雜度,而64位系統因地址空間充足可直接映射。 - 回收策略:LRU鏈表通過
prev_priority調整掃描優先級,內存壓力大時加強回收,避免OOM。
七、面試準備建議
- 閱讀關聯代碼:結合
mm/page_alloc.c(分配邏輯)和mm/vmscan.c(回收邏輯)理解mmzone.h結構的實際應用。 - 掌握GFP標志:理解
__GFP_DMA、__GFP_HIGHMEM等標志如何與區域和zonelist交互。 - 圖示輔助解釋:用示意圖描述節點-區域-
zonelist的層級關系,或伙伴系統的塊分裂過程。 - 硬件約束分析:明確DMA、Highmem等區域存在的硬件背景(如ISA設備限制、32位地址空間限制)。
八、總結
mmzone.h是Linux內存管理的核心,通過節點、區域、伙伴系統和NUMA感知設計,實現了跨架構的內存分配與回收。面試中需重點掌握:
- 數據結構角色:
zone、pg_data_t、zonelist的職責。 - 性能優化機制:per-CPU緩存、伙伴系統、NUMA感知分配。
- 硬件與架構適配:區域如何處理DMA/Highmem等限制,32位與64位系統的差異。
思考:linux 內核如何感知硬件是否是 NUMA 架構?
思考:mmzone.h 中和伙伴系統相關的數據結構和函數是什么?
思考: per_cpu_pages 是什么意思?有什么用?為什么需要 per_cpu_pages?
以下是對你的三個問題的詳細解答,結合 mmzone.h 頭文件,從 Linux 內核內存管理的架構視角進行分析,旨在幫助你深入理解并為面試做好準備。答案將使用中文,并盡量清晰、簡潔,同時涵蓋技術細節。
問題 1:Linux 內核如何感知硬件是否是 NUMA 架構?
Linux 內核通過以下機制感知硬件是否是 NUMA(Non-Uniform Memory Access)架構:
- 硬件初始化階段的探測:
-
- ACPI(高級配置與電源接口):現代系統通常通過 ACPI 表(如 SRAT 和 SLIT)獲取 NUMA 拓撲信息。SRAT(System Resource Affinity Table)描述了內存和處理器的親和性,列出每個 NUMA 節點的內存范圍和 CPU 關聯;SLIT(System Locality Information Table)提供節點間訪問延遲信息。
- BIOS 或固件:在系統啟動時,BIOS 或 UEFI 固件會通過 ACPI 或其他機制向內核傳遞硬件拓撲信息。內核通過解析這些表來識別 NUMA 節點及其內存分布。
- 設備樹(Device Tree):在嵌入式系統或非 ACPI 系統(如某些 ARM 架構)上,設備樹描述硬件拓撲,包括 NUMA 節點的內存和 CPU 分布。
- 內核初始化代碼:
-
- 內核在啟動過程中會調用與 NUMA 相關的初始化函數(如
mm/numa.c中的numa_init),根據 ACPI 或設備樹信息構建pglist_data結構(對應每個 NUMA 節點)。 - 如果系統檢測到多個 NUMA 節點(
MAX_NUMNODES > 1),內核會啟用 NUMA 支持,初始化每個節點的pg_data_t結構,并填充node_zones和node_zonelists。 - 如果只有一個節點(UMA 系統),內核會退化為單一節點模式,
pglist_data只包含一個實例(如contig_page_data)。
- 內核在啟動過程中會調用與 NUMA 相關的初始化函數(如
- 宏和配置選項:
-
CONFIG_NUMA:內核編譯時通過配置選項啟用 NUMA 支持。如果未啟用,內核假設 UMA(Uniform Memory Access)架構。numa_node_id():返回當前 CPU 所屬的 NUMA 節點 ID,基于硬件探測結果(如cpu_to_node映射)。MAX_NUMNODES和MAX_NODES_SHIFT:定義支持的最大節點數,限制 NUMA 系統的規模(32 位系統最多 64 節點,64 位系統最多 1024 節點)。
- 運行時驗證:
-
- 內核通過
node_present_pages(nid)和node_spanned_pages(nid)檢查每個節點的內存是否存在和大小,確認 NUMA 拓撲。 - 運行時統計(如
numa_hit和numa_miss)幫助內核監控 NUMA 分配效率,進一步驗證拓撲的有效性。
- 內核通過
總結:
Linux 內核通過 ACPI 表、設備樹或固件信息在啟動時探測 NUMA 拓撲,初始化 pglist_data 結構來管理每個節點。如果只有一個節點或未啟用 CONFIG_NUMA,內核按 UMA 模式運行。面試時,可以強調 ACPI 的 SRAT/SLIT 表和 numa_init 函數的角色,以及 NUMA 對性能優化的重要性。
🌍 思考:mmzone.h 中和伙伴系統相關的數據結構和函數是什么?
伙伴系統(Buddy Allocator)是 Linux 內核用于管理物理內存頁的主要分配器,mmzone.h 定義了與其相關的核心數據結構和少量函數。
相關數據結構
struct free_area:
struct free_area {struct list_head free_list;unsigned long nr_free;
};- 作用:表示特定大小(order)的空閑頁面塊列表,用于伙伴系統的內存管理。
- 字段:
-
free_list:一個雙向鏈表,存儲同一 order(2^order 頁)的空閑頁面塊。nr_free:記錄該 order 下空閑塊的數量。
- 在伙伴系統中的角色:
-
- 每個
zone包含一個free_area數組(free_area[MAX_ORDER]),從 order 0(1 頁)到 orderMAX_ORDER-1(默認 2^10 頁,即 4MB)。 - 伙伴系統通過
free_area管理空閑頁面,分配時從合適 order 的free_list獲取,釋放時合并相鄰塊(伙伴)到更高 order。
- 每個
struct zone(部分字段):
struct zone {unsigned long free_pages;spinlock_t lock;struct free_area free_area[MAX_ORDER];...
};- 相關字段:
-
free_pages:跟蹤區域內總的空閑頁面數。lock:自旋鎖,保護free_area和free_pages的并發訪問。free_area:伙伴系統的核心,存儲不同 order 的空閑頁面列表。
- 在伙伴系統中的角色:
-
zone是伙伴系統的工作單元,每個區域獨立管理自己的空閑頁面。- 分配請求通過
zone的free_area查找合適大小的塊,必要時分裂大塊。 lock確保多核系統下的線程安全。
struct per_cpu_pages(間接相關):
struct per_cpu_pages {int count;int low;int high;int batch;struct list_head list;
};- 作用:雖然主要是 per-CPU 緩存,伙伴系統通過它快速分配/釋放頁面。
- 在伙伴系統中的角色:
-
- 當 per-CPU 緩存不足(
count < low),從free_area批量獲取頁面(batch控制批量大小)。 - 當緩存過滿(
count > high),將頁面批量歸還到free_area。(這段代碼在哪里?)
- 當 per-CPU 緩存不足(
相關函數
mmzone.h 本身主要是數據結構定義,伙伴系統的核心邏輯在 mm/page_alloc.c 中實現,但 mmzone.h 中定義了以下與伙伴系統相關的函數:
- zone_watermark_ok:
int zone_watermark_ok(struct zone *z, int order, unsigned long mark,int alloc_type, int can_try_harder, int gfp_high);-
- 作用:檢查區域是否滿足分配請求的內存水位要求。
- 參數:
-
-
z:目標區域。order:請求的頁面塊大小(2^order 頁)。mark:水位標記(如pages_low、pages_high)。alloc_type:分配類型(如 GFP 標志)。can_try_harder:是否允許更激進的分配嘗試。gfp_high:是否為高優先級分配。
-
-
- 在伙伴系統中的角色:
-
-
- 在分配頁面之前,檢查區域是否有足夠的空閑頁面(
free_pages)和滿足水位條件,防止過度分配導致內存耗盡。 - 如果水位不足,可能觸發
kswapd回收頁面。
- 在分配頁面之前,檢查區域是否有足夠的空閑頁面(
-
- wakeup_kswapd:
void wakeup_kswapd(struct zone *zone, int order);-
- 作用:喚醒
kswapd線程以回收頁面,增加區域的空閑頁面。 - 在伙伴系統中的角色:
- 作用:喚醒
-
-
- 當伙伴系統無法滿足分配請求(例如,
free_area[order]為空),觸發kswapd回收頁面,補充free_area的空閑塊。
- 當伙伴系統無法滿足分配請求(例如,
-
數據結構:free_area 是伙伴系統的核心,管理空閑頁面塊;zone 提供分配環境;per_cpu_pages 優化分配性能。
函數:zone_watermark_ok 確保分配安全,wakeup_kswapd 支持內存回收以補充空閑頁面。
面試建議:準備解釋伙伴系統的分裂與合并機制,如何通過 free_area 查找頁面,以及水位檢查如何防止內存耗盡。
🌍 思考:per_cpu_pages 是什么意思?有什么用?為什么需要 per_cpu_pages?
per_cpu_pages 是什么?
per_cpu_pages 是一個數據結構,定義在 mmzone.h 中,用于實現每個 CPU 的頁面緩存:
struct per_cpu_pages {int count; /* 緩存中的頁面數量 */int low; /* 低水位,觸發補充 */int high; /* 高水位,觸發歸還 */int batch; /* 批量補充/歸還的頁面數量 */struct list_head list; /* 緩存的頁面鏈表 */
};結構說明:
- 每個 CPU 核有一個
per_cpu_pages實例,嵌入在per_cpu_pageset中(pcp[0]為熱頁面,pcp[1]為冷頁面)。 list存儲緩存的頁面,count跟蹤數量。low和high是水位標記,控制緩存的填充和清空。batch決定從伙伴系統批量獲取或歸還的頁面數。
per_cpu_pages 的主要作用是:
提高分配效率:
- 通過為每個 CPU 維護一個本地頁面緩存,內核可以在不獲取全局
zone->lock的情況下快速分配/釋放頁面。 - 熱頁面(
pcp[0])優先分配以優化緩存局部性(cache locality),提高性能。
減少鎖競爭:
- 在多核(SMP)系統中,多個 CPU 同時訪問
zone->lock會導致嚴重的鎖競爭,降低分配性能。 per_cpu_pages允許 CPU 在本地緩存中操作,減少對全局鎖的依賴。
NUMA 優化:
- 在 NUMA 系統下,
per_cpu_pages與per_cpu_pageset的 NUMA 統計字段(如numa_hit)結合,優先從本地節點分配頁面,降低跨節點訪問的延遲。
批量操作:
- 通過
batch參數,內核可以批量從伙伴系統獲取或歸還頁面,減少頻繁的鎖操作和伙伴系統交互。
為什么需要 per_cpu_pages?
多核系統中的鎖競爭:
-
- 在 SMP 系統中,多個 CPU 可能同時請求頁面,頻繁獲取
zone->lock會導致性能瓶頸。 per_cpu_pages提供本地緩存,CPU 大多數時候可以直接從緩存分配頁面,避免鎖競爭。
- 在 SMP 系統中,多個 CPU 可能同時請求頁面,頻繁獲取
性能優化:
-
- 內存分配是內核的熱點路徑(hot path),尤其在高負載場景(如服務器或虛擬化)。
- 本地緩存減少了訪問全局數據結構的開銷,熱頁面優先分配利用 CPU 緩存,提高效率。
NUMA 局部性:
-
- NUMA 系統要求盡量從本地節點分配內存以降低延遲。
per_cpu_pages配合per_cpu_pageset的 NUMA 統計,確保分配優先考慮本地頁面。
- NUMA 系統要求盡量從本地節點分配內存以降低延遲。
動態內存管理:
-
- 水位機制(
low和high)動態調整緩存大小,避免緩存過多占用內存或過少導致頻繁訪問伙伴系統。 - 批量操作(
batch)平衡了分配效率和內存使用率。
- 水位機制(
分配流程:
當 CPU 需要分配頁面時,先檢查 per_cpu_pages 的 list。如果緩存中有頁面(count > 0),直接從 list 分配。
如果緩存不足(count < low),從 zone->free_area 批量獲取 batch 個頁面,需獲取 zone->lock。
釋放流程:
-
- 釋放頁面時,優先放入
per_cpu_pages的list。 - 如果緩存過滿(
count > high),批量歸還頁面到zone->free_area,可能觸發伙伴合并。
- 釋放頁面時,優先放入
NUMA 支持:
per_cpu_pageset中的 NUMA 統計字段(如numa_hit、numa_miss)跟蹤分配是否來自目標節點,幫助優化 NUMA 策略。
🌍 思考:struct page 和 Zone 是如何聯系到一起的?
mm/page_alloc.c 文件
這段代碼是 Linux 內核內存管理子系統中與頁面分配和回收相關的核心實現,位于 mm/page_alloc.c 文件中,結合 mmzone.h 頭文件,實現了 zoned buddy allocator(分區伙伴分配器),這是 Linux 內核管理物理內存頁的主要機制。以下從頂層設計、設計思想、頁面分配與回收的流程以及相關函數的角度,詳細解答你的問題,力求清晰、全面,并幫助你為面試準備。
1. 頂層設計
Linux 內核的內存管理基于 節點(Node) 和 分區(Zone) 的分層架構,使用 伙伴系統(Buddy Allocator) 進行頁面分配和回收,結合 per-CPU 頁面緩存 和 NUMA 優化 來提升性能。以下是頂層設計的要點:
- 內存分層:
-
- 節點(Node):在 NUMA 架構中,物理內存被劃分為節點(
struct pglist_data),每個節點對應一個 CPU 或 CPU 組及其本地內存。 - 分區(Zone):每個節點內進一步劃分為分區(如 ZONE_DMA、ZONE_NORMAL、ZONE_HIGHMEM),以適應不同的硬件約束(如 DMA 的 <16MB 限制)。
- 頁面(Page):內存的最小分配單位是頁面(通常 4KB),通過
struct page表示。
- 節點(Node):在 NUMA 架構中,物理內存被劃分為節點(
- 伙伴系統:
-
- 伙伴系統是核心分配機制,將內存組織為 2order 大小的塊(order 從 0 到
MAX_ORDER-1,默認最大 210 頁,即 4MB)。 - 每個分區(
struct zone)維護一個free_area數組,存儲不同 order 的空閑頁面塊鏈表。
- 伙伴系統是核心分配機制,將內存組織為 2order 大小的塊(order 從 0 到
- Per-CPU 緩存:
-
- 每個 CPU 維護一個
per_cpu_pageset結構,包含熱(hot)和冷(cold)頁面緩存,用于快速分配和釋放頁面,減少對全局zone->lock的競爭。
- 每個 CPU 維護一個
- NUMA 優化:
-
- 使用
zonelist優先從本地節點分配內存,fallback 到其他節點,優化 NUMA 系統中的內存訪問延遲。 - 統計字段(如
numa_hit、numa_miss)跟蹤分配效率。
- 使用
- 頁面回收:
-
- 當內存不足時,
kswapd線程或直接回收機制(try_to_free_pages)通過 LRU(Least Recently Used)列表回收頁面,補充空閑頁面。 - 水位線(
pages_min、pages_low、pages_high)控制分配和回收的觸發。
- 當內存不足時,
- 初始化:
-
- 內核啟動時通過
free_area_init和build_all_zonelists初始化節點、分區和 zonelist,確保內存管理子系統就緒。
- 內核啟動時通過
頂層設計圖示:
[Node 0 (pg_data_t)]├── Zone DMA: free_area[0..MAX_ORDER-1], pageset[CPU0..CPUn], LRU lists├── Zone Normal: free_area[0..MAX_ORDER-1], pageset[CPU0..CPUn], LRU lists├── Zone Highmem: free_area[0..MAX_ORDER-1], pageset[CPU0..CPUn], LRU lists└── Zonelist: [Zone Normal (Node 0), Zone DMA (Node 0), Zone Normal (Node 1), ...]
[Node 1 (pg_data_t)]└── ...2. 設計思想
Linux 內核頁面分配與回收的設計思想圍繞 性能、可擴展性、可靠性 和 靈活性 展開:
- 性能優化:
-
- Per-CPU 緩存:通過
per_cpu_pages減少鎖競爭,快速分配/釋放頁面。 - NUMA 局部性:優先分配本地節點內存,降低跨節點訪問延遲。
- Cacheline 對齊:
zone和per_cpu_pageset使用 cacheline 對齊,減少 SMP 系統中的偽共享。 - 批量操作:批量分配/釋放頁面(如
rmqueue_bulk、free_pages_bulk)減少鎖操作。
- Per-CPU 緩存:通過
- 可擴展性:
-
- 分層架構:節點和分區設計支持 NUMA 和 UMA 系統,適應不同硬件規模。
- 伙伴系統:通過 power-of-2 塊管理內存,適合大內存系統,復雜度為 O(log n)。
- 模塊化宏:通過
CONFIG_NUMA和CONFIG_DISCONTIGMEM等宏支持不同架構。
- 可靠性:
-
- 水位線管理:
pages_min、pages_low、pages_high確保內存分配不會耗盡關鍵區域(如 ZONE_DMA)。 - 低內存保護:
lowmem_reserve防止低端內存被高階分配耗盡。 - 錯誤檢查:
bad_page和bad_range檢測頁面狀態異常,增強健壯性。
- 水位線管理:
- 靈活性:
-
- GFP 標志:通過
gfp_mask(如__GFP_DMA、__GFP_HIGHMEM)支持不同分配需求。 - 可配置參數:
sysctl_lowmem_reserve_ratio和min_free_kbytes允許動態調整內存策略。 - 支持大頁面:通過
CONFIG_HUGETLB_PAGE支持復合頁面(compound pages)。
- GFP 標志:通過
- 內存回收:
-
- 使用 LRU 列表(
active_list、inactive_list)和kswapd線程動態回收頁面,平衡內存壓力。 - 優先級機制(
prev_priority、temp_priority)根據內存壓力調整回收強度。
- 使用 LRU 列表(
3. 頁面分配的流程和函數
頁面分配的核心函數是 __alloc_pages,它協調伙伴系統、per-CPU 緩存和 zonelist 來滿足分配請求。以下是流程和關鍵函數:
分配流程
- 入口:
__alloc_pages(gfp_mask, order, zonelist):
-
- 根據
gfp_mask(分配標志,如__GFP_DMA)和order(請求的頁面塊大小,2^order 頁)選擇合適的 zonelist。 - 遍歷 zonelist 中的分區,檢查水位線(
zone_watermark_ok)以確保有足夠空閑頁面。
- 根據
- 嘗試分配:
-
- 調用
buffered_rmqueue(zone, order, gfp_mask)從目標分區分配頁面:
- 調用
-
-
- order == 0:優先從 per-CPU 緩存(
per_cpu_pages)分配單頁。 - order > 0:直接從
zone->free_area的伙伴系統分配。
- order == 0:優先從 per-CPU 緩存(
-
-
- 如果 per-CPU 緩存不足,調用
rmqueue_bulk從伙伴系統補充頁面。
- 如果 per-CPU 緩存不足,調用
- 水位檢查:
-
zone_watermark_ok檢查分區空閑頁面是否滿足pages_low或pages_min(根據gfp_mask和can_try_harder調整)。- 如果水位不足,喚醒
kswapd(wakeup_kswapd)回收頁面。
- 回收和重試:
-
- 如果分配失敗,調用
try_to_free_pages進行同步回收,釋放頁面到free_area。 - 如果仍失敗,可能觸發 OOM(Out of Memory)殺進程(
out_of_memory)或返回 NULL。
- 如果分配失敗,調用
- 頁面準備:
-
- 分配成功后,調用
prep_new_page初始化頁面(清除標志、設置引用計數)。 - 如果需要(
__GFP_ZERO或__GFP_COMP),調用prep_zero_page清零頁面或prep_compound_page設置復合頁面。
- 分配成功后,調用
關鍵分配函數
__alloc_pages(gfp_mask, order, zonelist):
-
- 核心分配函數,遍歷 zonelist,調用
buffered_rmqueue分配頁面,處理水位檢查、回收和 NUMA 統計。
- 核心分配函數,遍歷 zonelist,調用
buffered_rmqueue(zone, order, gfp_mask):
-
- 從 per-CPU 緩存(order == 0)或伙伴系統(order > 0)分配頁面,處理頁面初始化。
__rmqueue(zone, order):
-
- 從伙伴系統的
free_area分配頁面,必要時分裂大塊(通過expand)。
- 從伙伴系統的
rmqueue_bulk(zone, order, count, list):
-
- 批量分配頁面到指定鏈表,用于補充 per-CPU 緩存。
prep_new_page(page, order):
-
- 初始化新分配的頁面,清除標志,設置引用計數。
prep_compound_page(page, order):
-
- 為大頁面(compound pages)設置標志和元數據(如
PG_compound)。
- 為大頁面(compound pages)設置標志和元數據(如
zone_watermark_ok(z, order, mark, classzone_idx, can_try_harder, gfp_high):
-
- 檢查分區是否滿足分配的水位要求,調整空閑頁面計算。
4. 頁面回收的流程和函數
頁面回收通過釋放頁面回伙伴系統或 per-CPU 緩存完成,涉及以下流程和函數:
回收流程
- 入口:
__free_pages(page, order):
-
- 檢查頁面是否可釋放(
put_page_testzero),如果是 order == 0,調用free_hot_page;否則調用__free_pages_ok.
- 檢查頁面是否可釋放(
- 釋放到 per-CPU 緩存:
-
- 對于單頁(order == 0),
free_hot_cold_page(page, cold)將頁面加入 per-CPU 緩存(per_cpu_pages的 hot 或 cold 鏈表)。 - 如果緩存超過
high水位,調用free_pages_bulk批量歸還頁面到伙伴系統。
- 對于單頁(order == 0),
- 釋放到伙伴系統:
-
__free_pages_bulk(page, zone, order)將頁面歸還到zone->free_area[order].free_list,嘗試與伙伴合并到更高 order。- 如果伙伴也是空閑的,遞歸合并(通過
__page_find_buddy和__find_combined_index)。
- 狀態檢查:
-
free_pages_check檢查頁面狀態(映射、引用計數、標志等),防止釋放非法頁面。
- 特殊場景:
-
- 在電源管理(
CONFIG_PM)或 CPU 熱插拔(CONFIG_HOTPLUG_CPU)時,drain_local_pages和__drain_pages清空 per-CPU 緩存,歸還頁面到伙伴系統。
- 在電源管理(
關鍵回收函數
__free_pages(page, order):
-
- 頁面釋放的入口,決定調用
free_hot_page或__free_pages_ok。
- 頁面釋放的入口,決定調用
free_hot_cold_page(page, cold):
-
- 將單頁釋放到 per-CPU 緩存,區分熱/冷頁面。
__free_pages_ok(page, order):
-
- 處理多頁釋放,檢查頁面狀態后調用
free_pages_bulk。
- 處理多頁釋放,檢查頁面狀態后調用
free_pages_bulk(zone, count, list, order):
-
- 批量釋放頁面到伙伴系統,更新
free_area和free_pages。
- 批量釋放頁面到伙伴系統,更新
__free_pages_bulk(page, zone, order):
-
- 單頁面塊的釋放邏輯,執行伙伴合并,更新
free_area。
- 單頁面塊的釋放邏輯,執行伙伴合并,更新
page_is_buddy(page, order):
-
- 檢查頁面是否是空閑伙伴,可用于合并。
__page_find_buddy(page, page_idx, order):
-
- 查找頁面的伙伴頁面,用于合并。
destroy_compound_page(page, order):
-
- 釋放復合頁面,清除
PG_compound標志。
- 釋放復合頁面,清除
5. 關鍵函數總結
以下是頁面分配與回收的核心函數及其作用:
| 函數 | 作用 | 場景 |
|
| 核心分配函數,協調 zonelist 和水位檢查 | 分配任意 order 的頁面 |
|
| 從 per-CPU 緩存或伙伴系統分配頁面 | 單頁或多頁分配 |
|
| 從伙伴系統分配頁面,執行分裂 | 多頁分配 |
|
| 批量分配頁面到鏈表 | 補充 per-CPU 緩存 |
|
| 初始化新分配頁面 | 分配后準備 |
|
| 設置復合頁面元數據 | 大頁面分配 |
|
| 檢查分區水位是否滿足分配 | 分配前檢查 |
|
| 頁面釋放入口 | 釋放任意 order 頁面 |
|
| 釋放單頁到 per-CPU 緩存 | 單頁釋放 |
|
| 釋放多頁到伙伴系統 | 多頁釋放 |
|
| 批量釋放頁面到伙伴系統 | 批量回收 |
|
| 單頁面塊釋放,執行伙伴合并 | 伙伴系統回收 |
|
| 清空 per-CPU 緩存 | 電源管理/CPU 熱插拔 |
6. 頁面分配與回收的詳細流程
分配流程示例
假設請求分配 2 頁(order=1),GFP 標志為 GFP_KERNEL:
- 調用
__alloc_pages(GFP_KERNEL, 1, zonelist)。 - 遍歷
zonelist->zones,檢查每個分區(優先 ZONE_NORMAL)。 zone_watermark_ok確認分區有足夠空閑頁面(free_pages>pages_low)。- 調用
buffered_rmqueue(zone, 1, GFP_KERNEL):
-
- 因 order > 0,直接調用
__rmqueue(zone, 1)。 __rmqueue從free_area[1]獲取 2 頁塊,若為空,從更高 order 分裂(expand)。
- 因 order > 0,直接調用
- 初始化頁面(
prep_new_page),設置復合頁面(prep_compound_page如果需要)。 - 更新 NUMA 統計(
zone_statistics),返回頁面。
回收流程示例
釋放 2 頁(order=1):
調用 __free_pages(page, 1),檢查引用計數(put_page_testzero)。
調用 __free_pages_ok(page, 1):
-
free_pages_check驗證頁面狀態。- 調用
free_pages_bulk(zone, 1, list, 1)。
free_pages_bulk 調用 __free_pages_bulk(page, zone, 1):
-
- 將頁面加入
free_area[1].free_list。 - 檢查伙伴頁面(
__page_find_buddy),若空閑,合并到free_area[2],遞歸直到無法合并。
- 將頁面加入
更新 zone->free_pages 和 free_area[order].nr_free。
7. 面試準備建議
- 核心概念:
-
- 理解伙伴系統的分裂與合并(
expand和__free_pages_bulk)。 - 掌握 per-CPU 緩存的作用(
buffered_rmqueue和free_hot_cold_page)。 - 熟悉 NUMA 優化的 zonelist 和統計機制(
zone_statistics)。
- 理解伙伴系統的分裂與合并(
- 常見問題:
-
- 如何處理內存不足? 答:通過
wakeup_kswapd和try_to_free_pages回收頁面,必要時觸發 OOM。 - GFP 標志的作用? 答:控制分配的分區(
__GFP_DMA、__GFP_HIGHMEM)和行為(__GFP_ZERO、__GFP_NOFAIL)。 - 伙伴系統如何減少碎片? 答:通過 power-of-2 塊和合并機制,減少外部碎片。
- 如何處理內存不足? 答:通過
- 代碼分析:
-
- 熟悉
__alloc_pages和__free_pages的邏輯,結合mmzone.h的數據結構(如free_area、per_cpu_pages)。 - 理解水位線(
zone_watermark_ok)和低內存保護(lowmem_reserve)的實現。
- 熟悉
- 實踐建議:
-
- 閱讀
mm/page_alloc.c和mm/vmscan.c的相關代碼。 - 用圖示解釋分配流程(如 zonelist -> zone -> free_area)。
- 準備討論 NUMA 和 SMP 場景下的優化。
- 閱讀
總結
mm/page_alloc.c 實現了 Linux 內核的頁面分配與回收,基于伙伴系統、per-CPU 緩存和 NUMA 優化的分層架構。核心函數包括 __alloc_pages(分配)、__free_pages(回收)、buffered_rmqueue(緩存分配)、free_hot_cold_page(緩存回收)等。設計思想強調性能(緩存、NUMA 局部性)、可擴展性(節點/分區)、可靠性(水位線、錯誤檢查)和靈活性(GFP 標志)。通過理解這些機制和函數,你可以深入掌握 Linux 內存管理的架構,并在面試中自信應對相關問題。
2.2.1 管理區極值
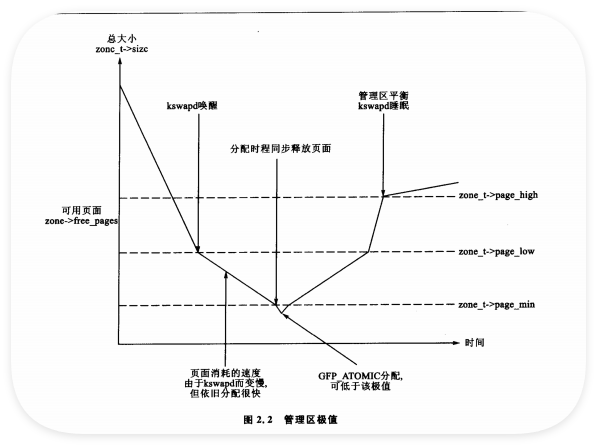
系統可用內存少時,守護程序kswapd被喚醒釋放頁面。內存壓力大時,進程會同步釋放內存(direct - reclaim路徑)。影響頁面換出行為的參數與FreeBSD、Solaris、MM01中所用參數類似。
每個管理區有三個極值pages_low、pages_min和pages_high :
- pages_low:空閑頁面數達到該值時,伙伴分配器喚醒kswapd釋放頁面,默認值是
pages_min的兩倍 。 - pages_min:達到該值時,分配器同步啟動kswapd ,在Solaris中無等效參數。
- pages_high:kswapd被喚醒并開始釋放頁面后,在釋放
pages_high個頁面以前,不認為管理區“平衡”,達到該極值后,kswapd再次睡眠,默認值是pages_min的三倍 。 這些極值用于決定頁面換出守護程序或頁面換出進程釋放頁面的頻繁程度。
2.2.2 計算管理區大小
- 計算位置與流程
管理區大小在setup_memory()函數中計算。圖2.3展示了setup_memory的調用關系,其調用鏈包含find_max_pfn、find_max_low_pfn、init_bootmem、register_bootmem_low_pages、find_smp_config等多個函數,各函數在內存初始化等環節發揮作用。 - 關鍵變量及含義
-
- PFN(物理頁幀號):用于物理內存映射,以頁面計算偏移量。系統中第一個可用的PFN(
min_low_pfn)分配在被導入的內核映象末尾_end后的第一個頁面位置,存儲在mm/bootmem.c文件中,與引導內存分配器配合使用。 max_low_pfn:在x86情況下,通過find_max_pfn()函數計算出ZONE_NORMAL管理區的結束位置值。此管理區是內核可直接訪問的物理內存,通過PAGE_OFFSET標記內核/用戶空間劃分,該值存儲在mm/bootmem.c文件。max_pfn:表示系統中最后一個頁面幀的編號。在內存少的機器上,max_pfn值等于max_low_pfn。
- PFN(物理頁幀號):用于物理內存映射,以頁面計算偏移量。系統中第一個可用的PFN(
- 計算用途
通過min_low_pfn、max_low_pfn和max_pfn這三個變量,可確定高端內存起始和結束位置(相關變量highstart_pfn和highend_pfn存儲在arch/i286/mm/init.c中 ),這些值被物理頁面分配器用于初始化高端內存頁面。
?
2.2.3 管理區等待隊列表
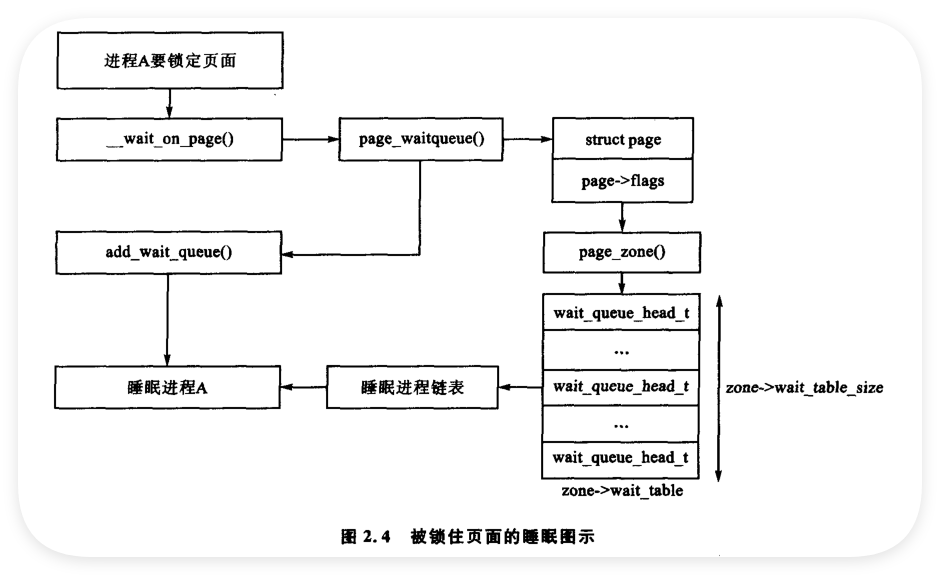
- 等待隊列機制原理
當頁面進行I/O操作(如頁面換入/換出 )時,為防止訪問不一致數據,使用頁面的進程需在I/O訪問前通過wait_on_page()添加到等待隊列,I/O完成后頁面經UnlockPage()解鎖,等待隊列上進程被喚醒。理論上每個頁面都應有等待隊列,但這會耗費大量內存,Linux將等待隊列存儲在zone_t中。 - 解決驚群效應
若管理區只有一個等待隊列,頁面解鎖時所有等待進程都會被喚醒,產生驚群效應。Linux的解決辦法是將等待隊列的哈希表存儲在zone_t->wait_table中,雖哈希沖突時仍可能有無故喚醒進程,但沖突頻率降低。 - 哈希表相關計算
-
wait_table_size計算:在free_area_init_core()時初始化,通過wait_table_size()計算 ,存儲在zone_t->wait_table_size。等待隊列表最多4096個,其大小取NoPages/PAGE_PER_WAITQUEUE個隊列數和2的冪次方的最小值,計算公式為:
[ wait_table_size = \log_2\left(\frac{NoPages \times 2}{PAGE_PER_WAITQUEUE} - 1\right) ]
其中NoPages是管理區頁面數 ,PAGE_PER_WAITQUEUE定義為256。zone_t->wait_table_shift計算:通過頁面地址的比特數右移得到其在表中的索引 。page_waitqueue()函數:用于返回某管理區中一個頁面對應的等待隊列,一般采用基于已被哈希的struct page虛擬地址的乘積哈希算法,通常需用GOLDEN_RATIO_PRIME乘以該地址,并將結果右移得到在哈希表中的索引,GOLDEN_RATIO_PRIME [Lev00]是系統中最接近所能表達的最大整數的golden ratio[Knu68]的最大素數。
2.3 管理區初始化
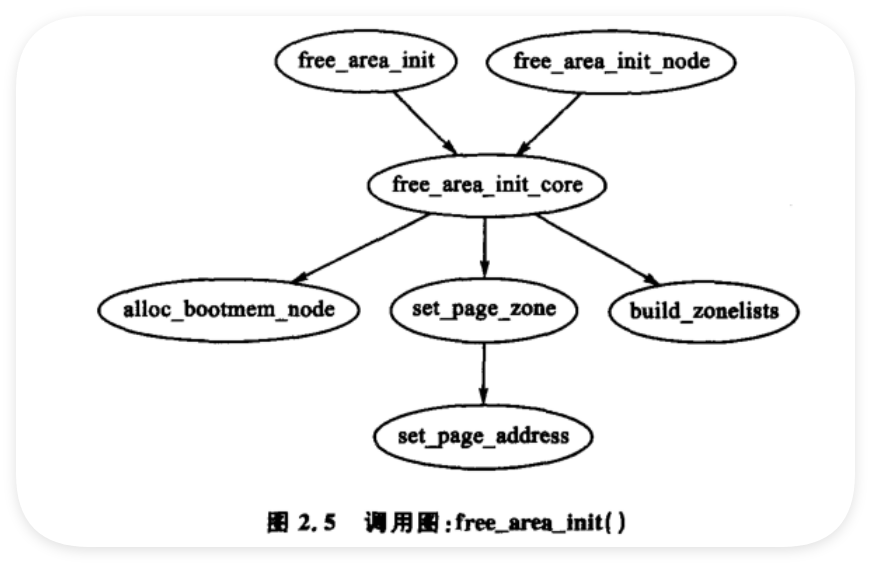
- 初始化時機
管理區的初始化在內核頁表通過paging_init()完全建立起來后進行 ,頁表初始化在3.6節涉及。不同系統執行此任務方式有別,但目標一致,即向UMA結構中的free_area_init()或NUMA結構中的free_area_init_node()傳遞合適參數。 - 所需參數
-
nid:被初始化管理區中節點的邏輯標識符(NodeID )。pgdat:指向pg_data_t,在UMA結構里為contig_page_data。pmap:被free_area_init_core()函數用于設置指向分配給節點的局部lmem_map數組的指針 。在UMA結構中常被忽略,因NUMA將mem_map處理為起始于PAGE_OFFSET的虛擬數組,而UMA中該指針指向全局mem_map變量,目前相關mem_map都在UMA中被初始化。zones_sizes:包含每個管理區大小的數組,管理區大小以頁面為單位計算。zone_start_paddr:每個管理區的起始物理地址。zone_holes:包含管理區中所有空閑洞大小的數組。
- 核心函數作用
核心函數free_area_init_core()用于向每個zone_t填充相關信息,并為節點分配mem_map數組 。此時不考慮釋放管理區中哪些頁面的信息,該信息在引導內存分配器用完之后才可知,將在第5章討論。
2.4 初始化mem_map
- 初始化方式
-
- NUMA系統:全局
mem_map被視為起始于PAGE_OFFSET的虛擬數組。free_area_init_node()函數由每個活動節點調用,在節點初始化時分配數組的一部分 。 - UMA系統:
free_area_init()使用contig_page_data作為節點,將全局mem_map當作該節點的局部mem_map。
- NUMA系統:全局
- 核心函數及內存分配
核心函數free_area_init_core()為已初始化的節點分配局部lmem_map,其內存通過引導內存分配器中的alloc_bootmem_node()分配(第5章介紹 )。在UMA結構中,新分配內存成為全局mem_map,與NUMA結構存在差異。 - NUMA與UMA的差異
-
- NUMA:分配給
lmem_map的內存位于各自內存節點。全局mem_map未明確分配,被處理成虛擬數組。局部映射地址存儲在pg_data_t->node_mem_map和虛擬mem_map中。對節點內每個管理區,虛擬mem_map中管理區地址存儲在zone_t->zone_mem_map,其余節點將mem_map視為真實數組,僅有效管理區被節點使用。
- NUMA:分配給
2.5 頁面
在Linux系統中,每個物理頁面都由struct page關聯記錄狀態,在內核2.2版本中,該結構在<linux/mm.h>中聲明如下:
typedef struct page {struct list_head lru;struct list_head list;struct address_space *mapping;unsigned long index;struct page *next_hash;atomic_t count;unsigned long flags;struct list_head lru;struct page *pprev_hash;struct buffer_head *buffers;# if defined(CONFIG_HIGHMEM) || defined(WANT_PAGE_VIRTUAL)void *virtual;# endif /* CONFIG_HIGHMEM || WANT_PAGE_VIRTUAL */mem_map_t;
}各字段介紹:
list:頁面可屬于多個列表,此字段用作列表首部。在slab分配器中,存儲指向管理頁面的slab和高速緩存結構指針 ,用于鏈接空閑頁面塊。mapping:若文件或設備映射到內存,其索引節點有相關address_space。若頁面屬于該文件,此字段指向該address_space;匿名頁面且設置了mapping,則address_space是交換地址空間的swapper_space。index:有兩個用途,若是文件映射部分,是頁面在文件中的偏移;若是交換高速緩存部分,是在交換地址空間中swapper_space的偏移量。若包含頁面的塊被釋放,釋放塊的順序(被釋放頁面2的冪 )存于其中,在free_pages_ok()中設置。next_hash:屬于文件映射并散列到索引節點及偏移中的頁面,將共享相同哈希桶的頁面鏈接一起。count:頁面被引用數目,減到0時釋放,被多個進程使用或內核用到時增大。flags:描述頁面狀態標志位,在<linux/mm.h>聲明,部分在表2.1列出 ,許多已定義宏用于測試、清空和設置,最有用的是SetPageUptodate(),若設置位前已定義,會調用體系結構相關函數arch_set_page_uptodate()。lru:根據頁面替換策略,可能被交換出內存的頁面存于page_alloc.c聲明的active_list或inactive_list中,是最近最少使用(LRU )鏈表的鏈表首部。pprev_hash:是next_hash的補充,使哈希鏈表可雙向鏈表工作。buffers:若頁面有相關塊設備緩沖區,此字段跟蹤buffer_head。匿名頁面有后援交換文件時,進程映射的該匿名頁面也有相關buffer_head,緩沖區必不可少,因頁面須與后援存儲器中的文件系統塊同步。virtual:通常情況下,只有來自ZONE_NORMAL的頁面才由內核直接映射。為定位ZONE_HIGHMEM中的頁面,kmap()用于為內核映射頁面(第9章討論 ),只有一定數量頁面會被映射,頁面被映射時,這是其虛擬地址。mem_map_t:是對struct page的類型定義,在mem_map數組中方便使用。
表2.1 描述頁面狀態的標志位
| 位名 | 描述 |
|
| 位于LRU |
|
| 直接從代碼中引用,是體系結構相關的頁面狀態位,一般代碼保證第一次進入頁面高速緩存時清除,使體系結構可延遲到頁面被進程映射后才進行D - Cache刷盤 |
|
| 僅由Ext2文件系統使用 |
|
| 顯示頁面是否需刷新到磁盤上,磁盤上對應頁面進行寫操作后設置,保證臟頁面寫出前不會被釋放 |
|
| 在磁盤I/O發生錯誤時設置 |
|
| 被文件系統保留,目前只有NFS用它表示一個頁面是否和遠程服務器同步 |
|
| 高端內存的頁面標記,高端內存頁面在 |
|
| 只對頁面替換策略重要,VM要換出頁面時設置,并調用 |
|
| 頁面在磁盤I/O所在內存時設置,I/O啟動時設置,I/O完成時釋放 |
|
| 當頁面存在于 |
|
| 頁面被映射且被映射的索引哈希表引用時設置,在LRU鏈表上移動頁面做頁面替換時使用 |
|
| 禁止換出的頁面,系統初始化時由引導內存分配器設置,標志頁面或不存在 |
|
| 被slab分配器使用的頁面 |
|
| 某些Space體系結構用于跳過部分地址空間,現在不再使用 |
|
| 表示沒有被使用 |
|
| 當一個頁面從磁盤無錯誤讀出時設置 |
表2.2 用于測試、設置和清除page->flags的宏
| 位名 | 設置 | 測試 | 清除 |
|
|
|
|
|
|
| None | None | None |
|
|
|
| None |
|
|
|
|
|
|
|
|
|
|
|
| None |
| None |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| None | None | None |
|
|
|
|
|
|
| None | None | None |
|
|
|
|
|
2.6 頁面映射到管理區
- 頁面管理區映射方式演變
在內核2.4.18版本,struct page曾存儲指向對應管理區的指針page->zone,但因大量struct page存在時該指針消耗內存多,在更新內核版本中被刪除,改用page->flags的最高ZONE_SHIFT位(x86下是8位 )記錄頁面所屬管理區。 - 管理區相關數據結構及函數
-
zone_table:在linux/page_alloc.c中聲明,用于建立管理區 ,定義如下:
zone_t * zone_table[MAX_NR_ZONES * MAX_NR_NODES];
EXPORT_SYMBOL(zone_table);其中MAX_NR_ZONES是一個節點中能容納管理區的最大數(如3個 ),MAX_NR_NODES是可存在節點的最大數。EXPORT_SYMBOL()函數使zone_table能被載入模塊訪問,該表類似多維數組。
- free_area_init_core()函數:在該函數中,一個節點中的所有頁面會被初始化。設置zone_table值的方式為:
zone_table[nid * MAX_NR_ZONES + j] = zone;這里nid是節點ID,j是管理區索引號,zone是zone_t結構。
- set_page_zone()函數:用于為每個頁面設置所屬管理區,調用方式為:
set_page_zone(page, nid * MAX_NR_ZONES + j);其中page是要設置管理區的頁面 ,通過這種方式,zone_table中的索引被顯式存儲在頁面中。
2.7 高端內存
- 引入原因:內核
ZONE_NORMAL中可用地址空間有限,所以Linux內核支持高端內存概念。 - 32位x86系統閾值及相關限制
-
- 4 GB閾值:與32位物理地址定位的內存容量有關。為訪問1 GB - 4 GB之間內存,內核通過
kmap()將高端內存頁面臨時映射成ZONE_NORMAL,第9章深入討論。 - 64 GB閾值:與物理地址擴展(PAE )有關,PAE是Intel發明用于允許32位系統使用RAM的技術,通過附加4位定位內存地址,實現2??字節(64 GB)內存定位 。
- 4 GB閾值:與32位物理地址定位的內存容量有關。為訪問1 GB - 4 GB之間內存,內核通過
- 理論與實際情況差異
理論上PAE允許處理器尋址到64 GB,但Linux中進程虛擬地址空間仍是4 GB,試圖用malloc()分配所有RAM的用戶會失望。 - 地址擴展空間(PAE)的影響
PAE不允許內核自身擁有大量可用RAM。描述頁面的struct page需44字節,占用ZONE_NORMAL內核虛擬地址空間 。描述1 GB內存需約11 MB內核內存,描述16 GB內存需176 MB,給ZONE_NORMAL帶來巨大壓力。像頁面表項(PTE )這類小數據結構最壞情況下也需約16 MB。所以在x86機器上Linux可用物理內存被限制為16 GB,若需訪問更多內存,建議使用64位機器。
1


 --- Linux 鏈表結構)












)



