隨著AI技術的演進,模型的計算復雜度和參數量呈現幾何級數增長,這使得傳統單機單卡部署在算力供給與顯存容量方面顯得力不從心,從而直接推動了分布式訓練/推理技術的快速發展。今年年初爆火的DeepSeek在訓練及推理Prefill階段采用了分級流水AlltoAll算法,具體實現為:首先在Server間執行Token傳輸,當Token到達目標Server后,再在目標Server內執行Bcast操作,Server內和Server間的操作以Token為粒度進行流水掩蓋。
HCCL支持細粒度的分級流水算法,基于Atlas A2 訓練系列產品,可大幅提升DeepSeek集群訓練中Allgather、ReduceScatter、AlltoAll等集合通信算子的執行效率。
1、簡單分級算法存在的問題
為降低網絡流量沖突,AI計算集群中常常采用Server內Server間分級網絡架構,即Server內通過直連電纜互聯,Server間同號卡通過交換機互聯。
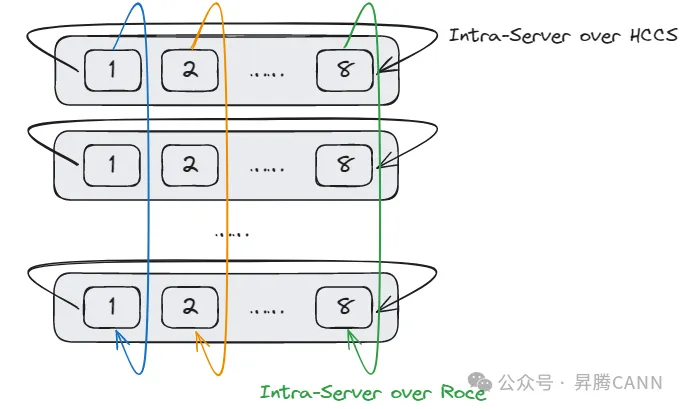
然而,在Server內Server間分級網絡對應的全局通信域中執行集合通信算子,將面臨以下兩個挑戰:
1)Server內鏈路和Server間鏈路帶寬不同,一般情況下Server內帶寬大于Server間帶寬,如果使用全局Ring或RHD(Recursive Halving Doubling)算法會存在慢鏈路的問題。
2)不同Server的不同號卡之間無直連鏈路,算法設計時,需要考慮連通性問題。
為了解決上述問題,在Server內Server間分級網絡中,通常使用分級算法,將全局通信操作分解為多層次的局部操作,利用分階段、分層遞進的方式優化通信效率。例如Allgather操作,Server間先執行一次同號卡間的Allgather(下圖紅色箭頭),再在Server內執行一次Allgather(下圖藍色箭頭)。
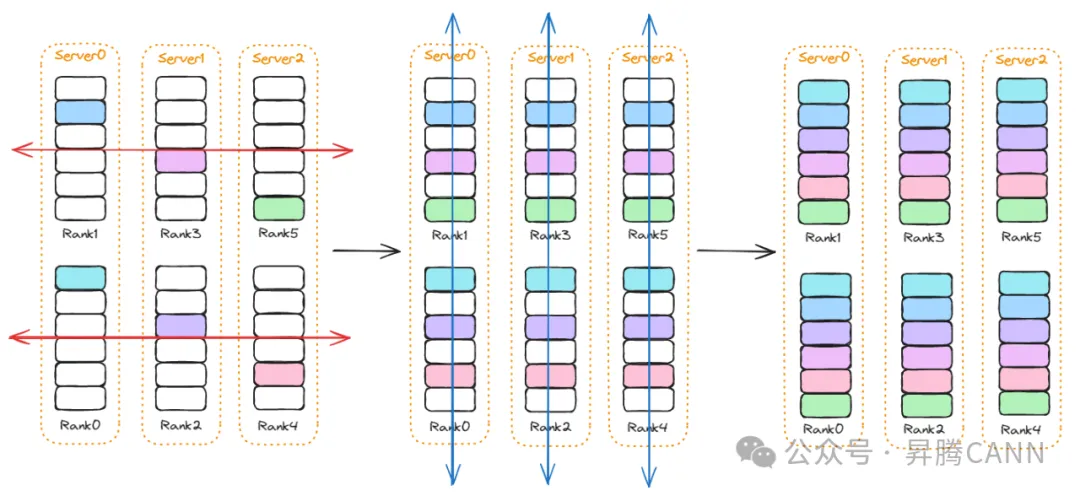
該分級算法仍然存在一些問題:
1)帶寬浪費:上圖中Server間數據傳輸時,Server內的鏈路處于空閑狀態,無法實現帶寬利用率的最大化。
2)存在離散數據:以Rank0為例,Server間完成數據傳輸后,持有Rank0、Rank2、Rank4的數據,這三塊數據在Server內數據傳輸過程中需要發送到Rank1上,但是這三塊數據在Rank1上并不是連續分布的,如果將這三塊數據分別發送到Rank1上,會引入每次發送的頭開銷;如果將這三塊數據合并發送,又需要引入數據重排的開銷。
2、細粒度分級流水算法技術解讀
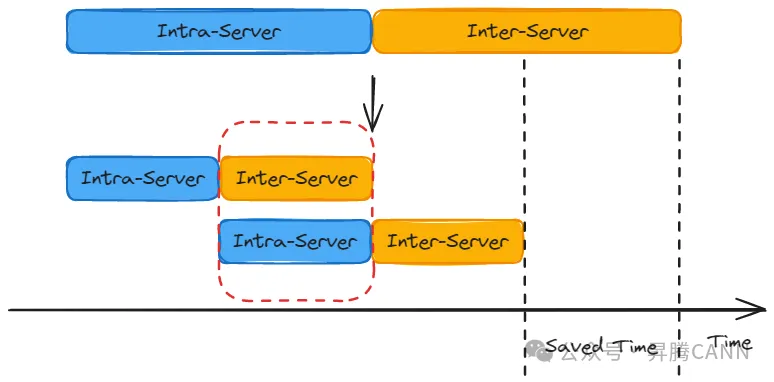
帶寬浪費的問題,通常采用流水的方式解決。如下圖所示,通過切分數據塊,使得完成一部分Server內的數據傳輸后,就可以開始Server間的數據傳輸,同時啟動第二部分的Server內數據傳輸。這樣,Server內和Server間的數據傳輸可以并行進行(如紅框所示),從而提高總的帶寬利用率。
雖然這種方法可以解決帶寬利用率不足的問題,但是通過切分數據塊的方式進行流水掩蓋,會導致單次數據傳輸的數據量變小,頭開銷占比過大,通信效率降低,而且無法解決離散數據的問題。
因此,采用細粒度分級流水算法,一方面挖掘通信算法本身的數據依賴,另一方面結合流水并行的方式,解決帶寬利用率不足與離散數據的問題。以Allgather為例,Server間的通信選擇Ring算法,Server內的通信選擇Full Mesh算法。讓我們先回顧一下Ring算法的步驟:假設共有n個Server,那么Ring算法會執行n-1步操作,在第i步時,本Rank將獲得前i個Rank上的數據。
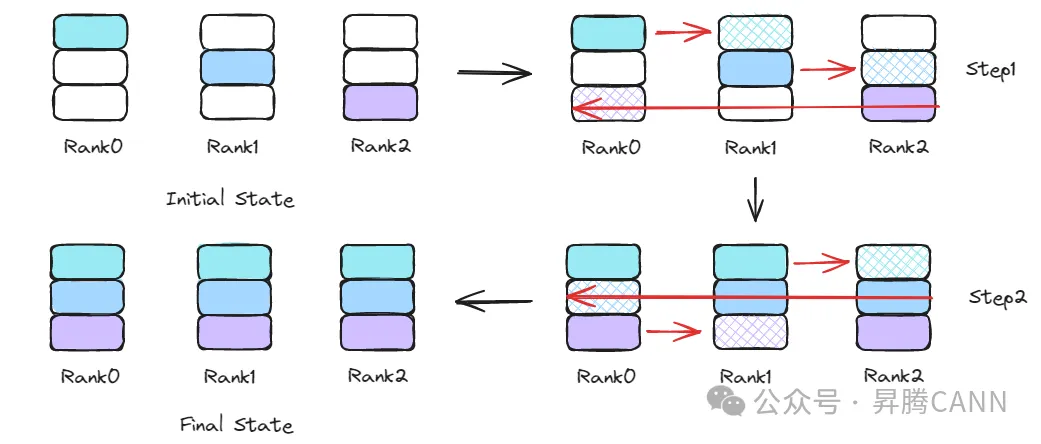
在簡單分級算法中,執行完全部n-1步操作后才會進行Server內的數據傳輸。然而,觀察Rank上每個步驟的數據狀態可以發現:每完成一步數據傳輸,都會有新的數據塊被傳輸到Rank上,該數據塊在下一步數據傳輸時,可以同時完成Server間的數據傳輸和Server內的數據傳輸。如下中圖所示,綠色數據塊從Rank5被發送到Rank1上(僅陳述部分Rank的行為,其它Rank對稱處理),在接下來的步驟中,Rank1繼續向Rank3發送綠色數據塊(Ring算法標準步驟),同時Rank1也可以向同Server中的Rank0發送綠色數據塊。

繼續執行Ring算法,每一步在進行Server間數據傳輸的同時,還會向Server內其它Rank傳輸上一步接收到的數據塊,Ring算法的最后一個步驟結束后,僅需要在Server內再進行一次數據塊的傳輸即可完成全部算法步驟(Rank初始數據塊的Server內傳輸操作,可以隱藏在Ring算法的第一步中進行),Rank0上的全部傳輸任務編排如下圖所示,LocalCpy操作僅在輸入輸出內存不同場景中執行,用于將數據塊從輸入內存移動到輸出內存,在輸入輸出內存相同場景中,則無需執行該操作。
該算法利用Ring算法的數據依賴關系,實現了Server內/Server間的并發執行,以提高帶寬利用率。同時,由于該算法的切分方式是對傳輸數據塊進行重排,每次數據傳輸所操作的數據塊僅包含一個Rank的初始數據,因此在跨卡傳輸時,數據可以直接傳輸到最終位置,從而避免了離散數據的問題。
3、性能收益評估
讓我們對該算法進行簡單的收益分析,假設n個Server,每個Server中有m張卡,Server內采用Full Mesh通信算法,每條鏈路的帶寬為bw_a,Server間Clos連接,帶寬為bw_e;假設輸入數據量s足夠大,僅考慮帶寬時延,并且bw_a > bw_e。
采用簡單分級算法,算子耗時為:
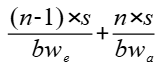
?采用細粒度分級流水算法,算子耗時為:
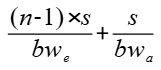
可以看到,當bw_e和bw_a接近時,n越大,算法性能提升越大,最大提升接近1倍。
4、更多學習資源
HCCL集合通信庫,通過高性能集合通信算法、計算通信統一硬化調度、計算通信高性能并發等創新技術,可充分利用硬件資源,顯著提升大模型通信效率。歡迎昇騰社區HCCL學習專區,獲取海量學習資源。

昇騰社區HCCL信息專區


)









)


?)
)


