一、爬蟲
1.1 爬蟲解釋
爬蟲簡單的說就是模擬人的瀏覽器行為,簡單的爬蟲是request請求網頁信息,然后對html數據進行解析得到自己需要的數據信息保存在本地。
1.2 爬蟲的思路
# 1.發送請求
# 2.獲取數據
# 3.解析數據
# 4.保存數據
1.3 爬蟲工具
DrissionPage的個人空間-DrissionPage個人主頁-嗶哩嗶哩視頻
DrissionPage??是一個基于 Python 的網頁自動化工具。
既能控制瀏覽器,也能收發數據包,還能把兩者合而為一。
可兼顧瀏覽器自動化的便利性和 requests 的高效率。
功能強大,語法簡潔優雅,代碼量少,對新手友好。
可以參考官網視頻學習基本概念。
二、爬蟲實戰
2.1 爬蟲需求
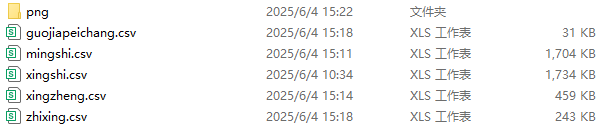
對首頁 - 人民法院案例庫的4884條法律案件信息進行csv保存。
2.2 爬蟲效果
爬蟲后的效果圖:

2.3 爬蟲實現過程
2.3.1 環境配置
最好先再本地安裝好anaconda,然后創建虛擬環境和安裝這個包。如何安裝anaconda可以參考我之前的博客手把手教你使用云服務器和部署相關環境!!!-CSDN博客
conda create -n pachong python=3.10.16 -y
conda activate pachong
pip install?DrissionPage==4.1.0.18
DrissionPage ? ? ? 4.1.0.18
python? 3.10.16
2.3.2 學習DrissionPage的基本操作
設置好DrissionPage的默認瀏覽器啟動路徑,找到自己的chrome瀏覽器或者edge瀏覽器,得到路徑,注意是需要.exe的執行文件路徑,運行下面的代碼就設置好了瀏覽器的啟動環境。
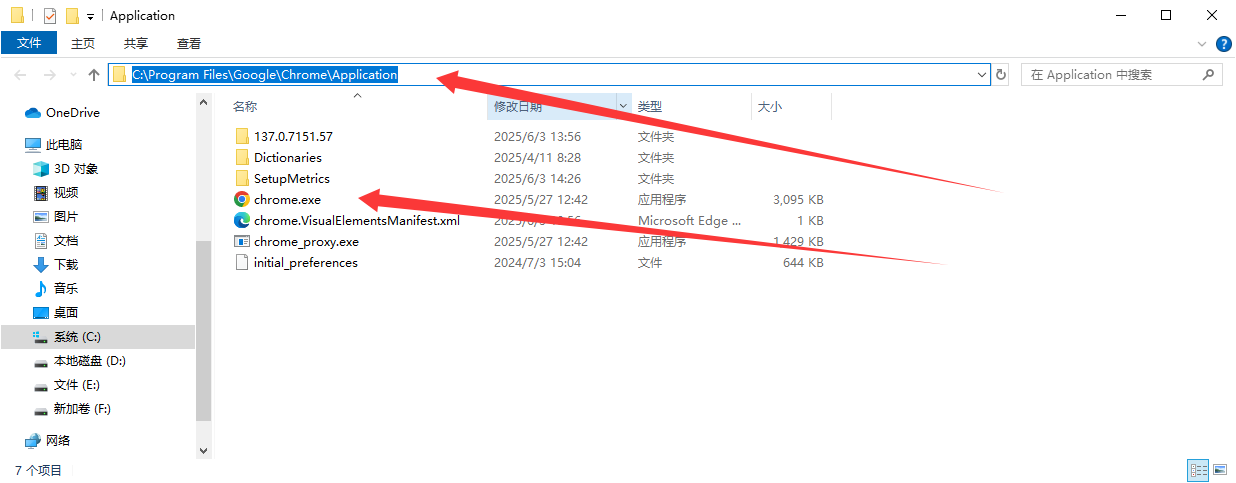
from DrissionPage import ChromiumOptions
path = r'C:\Program Files\Google\Chrome\Application\Chrome.exe' ?# 請改為你電腦內Chrome可執行文件路徑
ChromiumOptions().set_browser_path(path).save()
?實例化瀏覽器對象和關閉瀏覽器對象操作
# 瀏覽器對象,標簽頁對象,頁面元素對象
from DrissionPage import Chromium
# 鏈接瀏覽器
browser = Chromium()
browser.set.retry_interval(5)# 設置重試間隔
tab = browser.latest_tab
# 關閉瀏覽器
browser.quit()
?標簽頁的相關函數
# 瀏覽器對象,標簽頁對象,頁面元素對象
from DrissionPage import Chromium
# 鏈接瀏覽器
browser = Chromium()
browser.set.retry_interval(5)# 設置重試間隔
tab = browser.latest_tab
tab.get('http://DrissionPage.cn') # 使用標簽頁訪問url函數
tab2 = browser.new_tab("http://www.baidu.com") # 新建標簽頁函數
tab3 = browser.get_tab(title="DrissionPage") # 訪問標簽頁函數
# 關閉標簽頁對象
tab.close()
# 標簽頁的后退前進與刷新
tab.back(2) # 后退2次
tab.forward(1) # 前進
tab.refresh() # 刷新
# 關閉瀏覽器
browser.quit()
?html元素對象的相關函數,元素可以使用Xpath語法進行定位
from DrissionPage import Chromium
# 鏈接瀏覽器
browser = Chromium()
browser.set.retry_interval(5)# 設置重試間隔
tab = browser.latest_tab
tab.get('http://DrissionPage.cn')
# 獲取頁面元素
# tab對象中直接查找
ele = tab.ele('使用文檔') # 獲取文本中包含“使用文檔”的元素
ele.check() # 點擊元素
# 相對位置查找
ele2 = ele.next() # 獲取ele的下一個兄弟元素
ele2.click() # 點擊元素
# 關閉瀏覽器
# browser.quit()
?一個實例
from DrissionPage import Chromium
# 鏈接瀏覽器
browser = Chromium()
browser.set.retry_interval(5)# 設置重試間隔
tab2 = browser.new_tab("http://www.baidu.com")
# 定位一個元素,輸入按鈕 , x表示xpath語法
input_btn = tab2.ele('x://*[@id="kw"]')
print(input_btn.html)
# 輸入搜索內容
input_btn.input("python")
# 定位一個搜索按鈕
search_btn = tab2.ele('x://*[@id="su"]')
search_btn.click()
2.3.3 獲取目標網頁的數據
2.3.3.1 抓包分析得到數據,需要先監聽標識符
按F12進入開發者模式,刷新頁面,再network中可以搜索相關的數據包
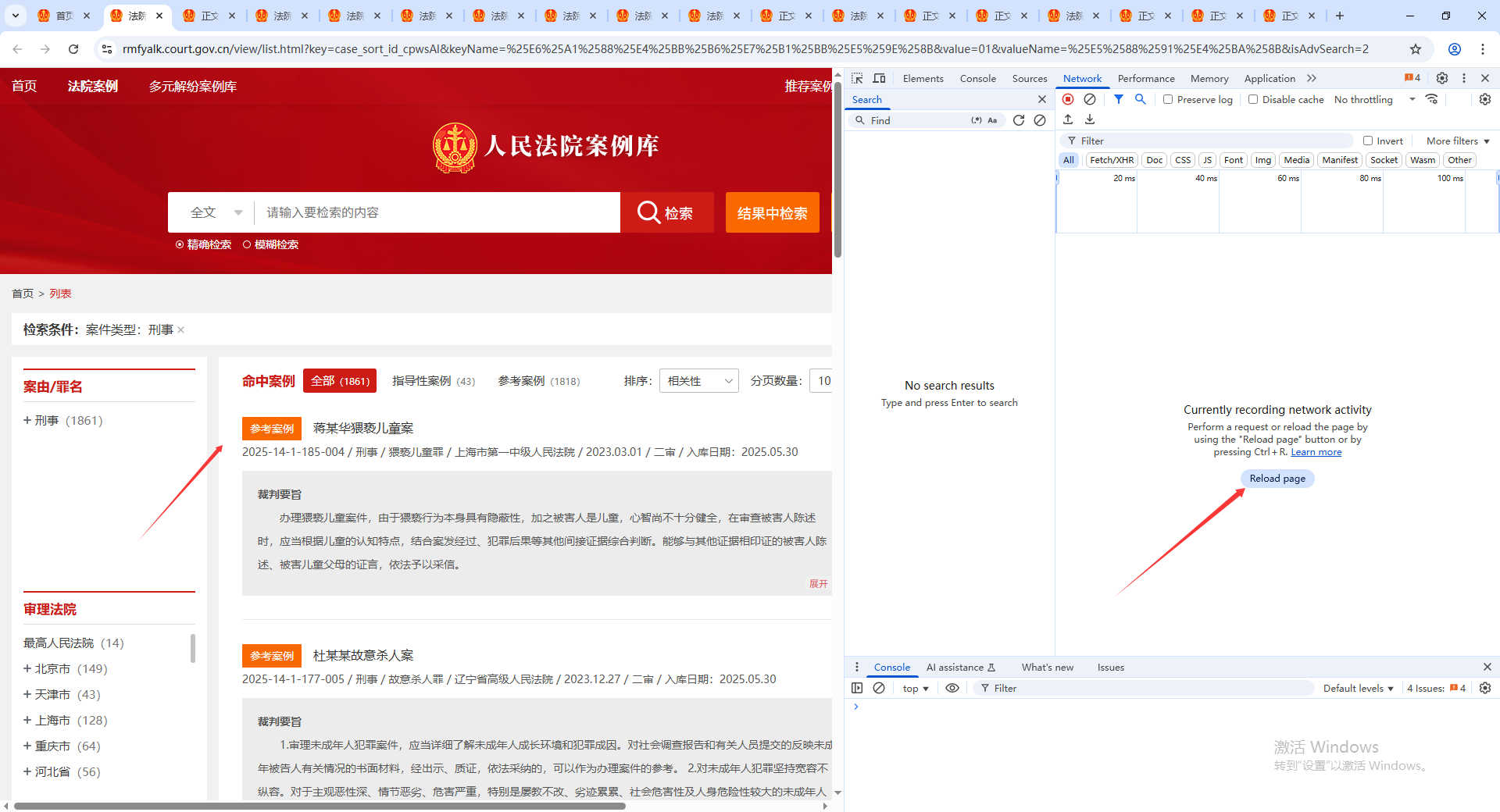
比如我們搜索,蔣某華猥褻兒童案。只有一個搜索結果,headers是前端請求后端的信息,preview是請求結果的預覽信息,response是請求結果的詳細信息。我們對數據抓包主要是看這三部分信息。
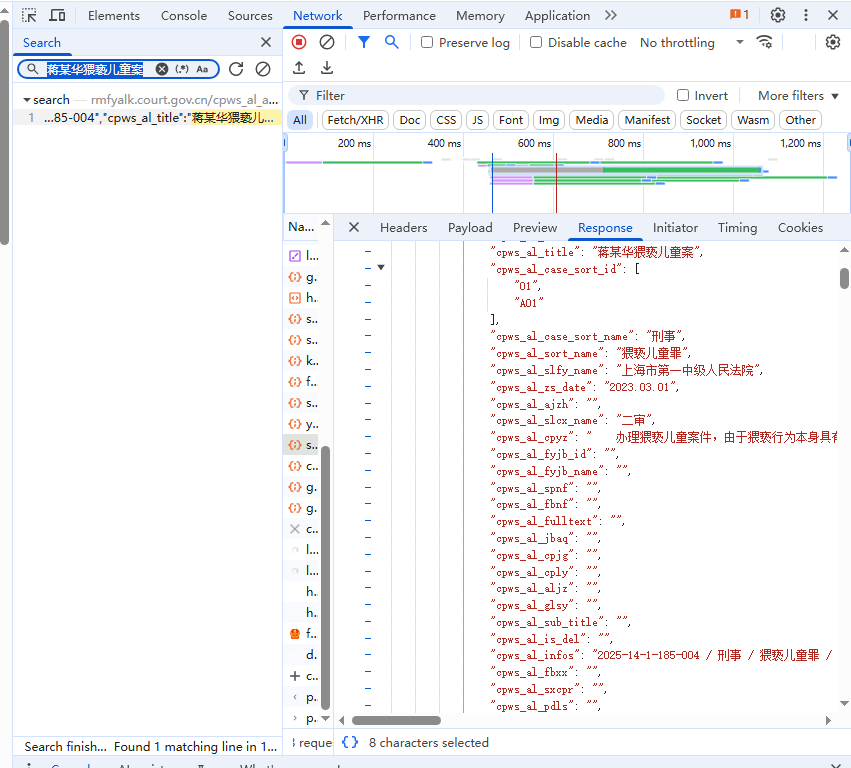 ?我們再preview中可以看到數據包中的['data']['datas']剛好有這頁的10個案件信息,我們對這個信息中抽取我們需要的信息再保存再本地就行。
?我們再preview中可以看到數據包中的['data']['datas']剛好有這頁的10個案件信息,我們對這個信息中抽取我們需要的信息再保存再本地就行。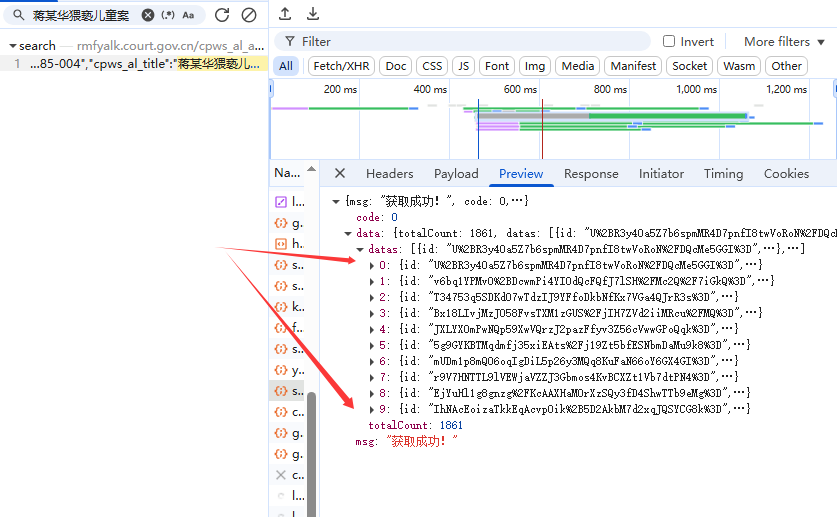
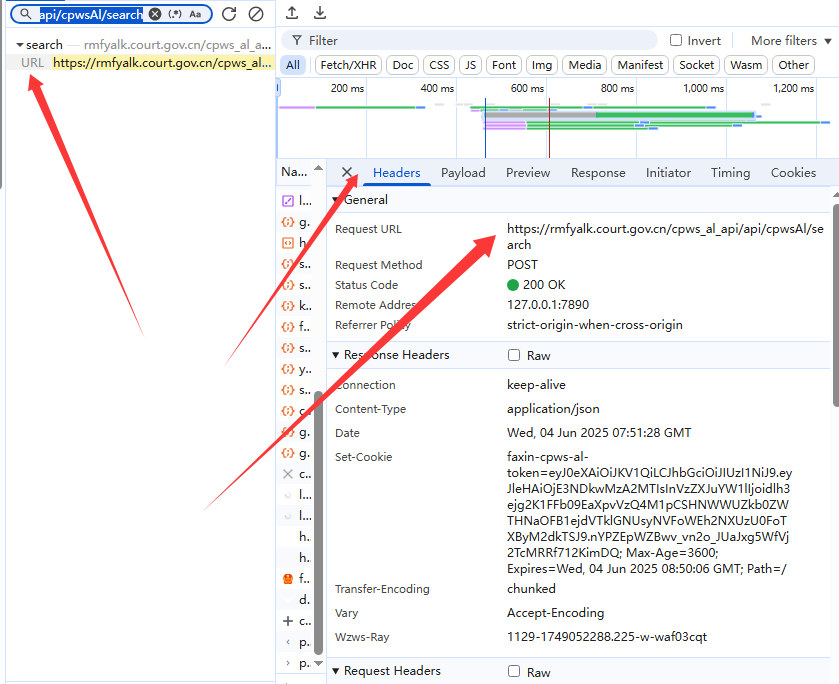
?我們此時監聽的是:蔣某華猥褻兒童案,雖然也可以用,但是我們一般選擇監聽請求頭的信息,一般是“?”前面的https(如果有的話),復制一下,檢索一下看一下是不是唯一值。
2.3.3.2 html元素定位xpath得到html元素,得到數據
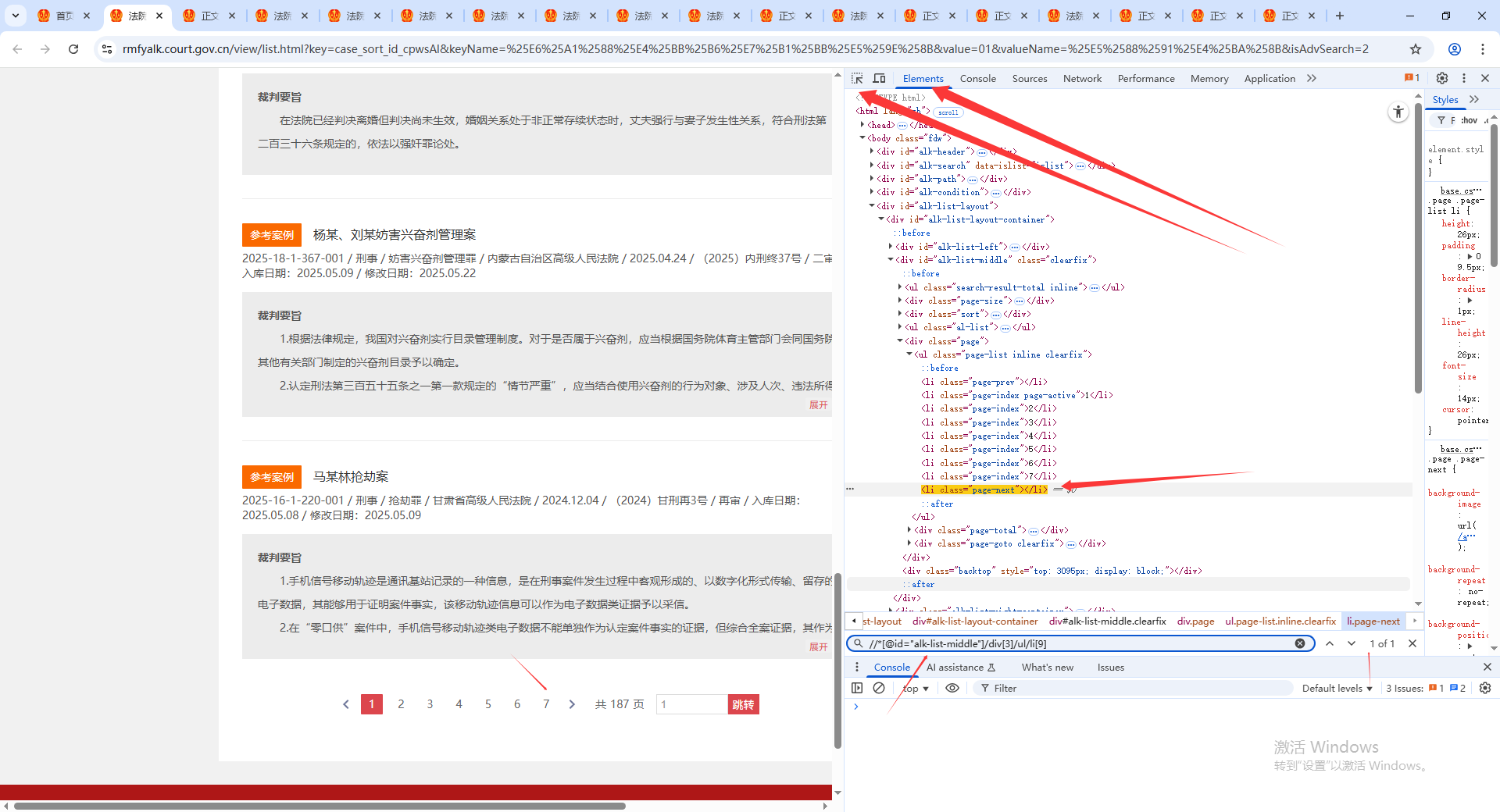
DrissionPage非常好的功能是通過xpath語法定位到html元素,就可以使用元素.text 、元素.html等獲得相關數據,定位元素過程,F12打開開發者工具,最左邊的定位標識符選擇你想定位的網頁元素,比如我定位的是下一頁的按鈕元素,得到位置后,右鍵選擇copy,XPath,然后按ctrl+f進行搜索模式,就可以看到你的這個XPath語法定位的元素再當前標簽頁中有幾個了。
2..3.4 爬取全部信息
我們平時怎么操作瀏覽器,就怎么寫代碼。
思路: 打開瀏覽器,新建標簽頁,搜索目標url,通過監聽唯一的標識符:“https://rmfyalk.court.gov.cn/cpws_al_api/api/cpwsAl/search”得到當前頁面的10個案件的數據包,對數據包列表的每個數據進行抽取我們需要的信息,再保存到csv表格中。下滑,點擊下一頁,重復上述操作。
from DrissionPage import Chromium
from pprint import pprint
import csv
# 打來瀏覽器
tab = Chromium().latest_tab
# 監聽數據包
tab.listen.start("https://rmfyalk.court.gov.cn/cpws_al_api/api/cpwsAl/search")
# 訪問頁面
url = "https://rmfyalk.court.gov.cn/view/list.html?key=case_sort_id_cpwsAl&keyName=%25E6%25A1%2588%25E4%25BB%25B6%25E7%25B1%25BB%25E5%259E%258B&value=05&valueName=%25E6%2589%25A7%25E8%25A1%258C&isAdvSearch=2"
tab.get(url)
f = open(r'E:\gdzd_hb\pachoong\zhixing.csv', 'w', encoding='utf-8', newline='')
# 字典寫入方法
csv_writer = csv.DictWriter(f, fieldnames=['案件名稱', '案件標簽', '裁判要旨'])
# 寫入表頭
csv_writer.writeheader()
for page in range(1, 208):
? ? print(f'正在爬取第{page}頁')
? ? # 等待數據包加載
? ? resp = tab.listen.wait()
? ? # 獲取響應數據-->json
? ? json_data = resp.response.body
? ? # # 打印數據
? ? # print(json_data)
? ? # print(type(json_data))
? ? # 遍歷jobInfo列表
? ? jobList = json_data['data']['datas']
? ? for job in jobList:
? ? ? ? pprint(job) # 打印字典格式
? ? ? ? break # 打印一個結束
? ? # 抽取需要的數據
? ? for job in jobList:
? ? ? ? dit = {
? ? ? ? ? ? '案件名稱': job['cpws_al_title'],
? ? ? ? ? ? '案件標簽': job['cpws_al_infos'],
? ? ? ? ? ? '裁判要旨': job['cpws_al_cpyz']
? ? ? ? }
? ? ? ? pprint(dit)
? ? ? ? # 字典寫入數據
? ? ? ? csv_writer.writerow(dit)
? ? # 下滑到最底部
? ? tab.scroll.to_bottom()
? ? # 點擊下一頁
? ? tab.ele('css:.page-next').click()
三、問題和小結?
進階需求:爬取每個案件的對應的詳細PDF信息。
方法一:通過點擊每個案件,進去后再點擊下載PDF的案件到指定文件夾中實現。
存在問題:網站做了限制,每個賬號下載了20個左右的PDF,就會顯示下面的報錯,就算是人工手動下載PDF文件也是一樣的。

方法二:通過獲取每個案件的詳情url地址,使用元素來獲取相關信息,用字典保存,再保存到csv文件中。
存在的問題:網站做了限制,我們一個賬號連續訪問40個左右的案件詳情網頁后,就會顯示空的網頁,從而無法獲得html元素。
?這兩個問題我暫時沒有解決辦法,因為DrissionPage已經是模擬人的行為進行抓包了,但是網站對每個賬號進行了限制。











 大數據概述)




![[特殊字符] FFmpeg 學習筆記](http://pic.xiahunao.cn/[特殊字符] FFmpeg 學習筆記)


