
在 AI 和大數據時代,企業通常需要構建各種數據同步管道。例如,實時數倉實現從數據庫到數據倉庫或者數據湖的實時復制,為業務部門和決策團隊分析提供數據結果和見解;再比如,NoSQL 游戲玩家數據,需要轉換為 SQL 數據庫以供運營團隊分析。那么,到底如何構造穩定而快速的數據 ETL 管道,并且可以進行數據合并或轉換?
📢限時插播:Amazon Q Developer 來幫你做應用啦1!
🌟10分鐘幫你構建智能番茄鐘應用,1小時搞定新功能拓展、測試優化、文檔注程和部署
?快快點擊進入《Agentic Al 幫你做應用 -- 從0到1打造自己的智能番茄鐘》實驗
免費體驗企業級 AI 開發工具的真實效果吧
構建無限,探索啟程!
Amazon 提供了幾種數據同步方法:
-
Amazon Zero-ETL
借助 Zero ETL ,數據庫本身集成 ETL 到數據倉庫的功能,減少了在不同服務間手動遷移或轉換數據的工作。目前 Zero ETL 支持的源和目標有如下幾種,都是托管的數據庫或者數據分析服務。
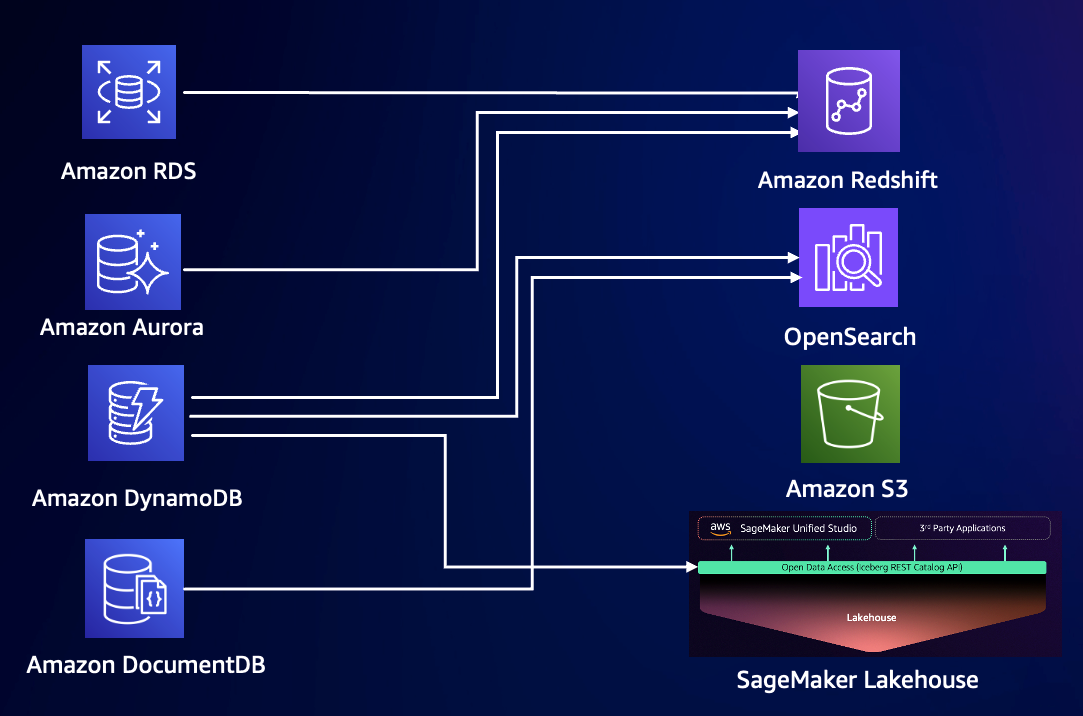
-
Amazon Database Migration Service(DMS)
DMS 可以遷移關系數據庫、數據倉庫、NoSQL 數據庫及其他類型的數據存儲,支持同構或者異構數據庫和數據倉庫的數據轉換。DMS 運行于單個節點,即使有高可用設計,仍然只有單節點實際工作。在高并發寫入的情況下,轉換效率受到影響。DMS 支持的源和目標仍然有限,一些開源數據庫或者上下游組件支持不足。
-
Apache Flink
Apache Flink 作為開源實時計算引擎,支持包括各種關系數據庫、NoSQL 數據庫和數據倉庫的多種數據源和下游連接。數據轉換流程也可以加入 Kafka 消息管道作為上下游解耦,滿足高性能和高可用數據同步復制需求。亞馬遜云科技提供 Amazon EMR Flink 組件和全托管 Amazon Managed Service for Apache Flink 兩種服務。EMR 更適合于包括 Flink 在內的開源生態的各種組件,而托管 Flink 只提供單個服務。
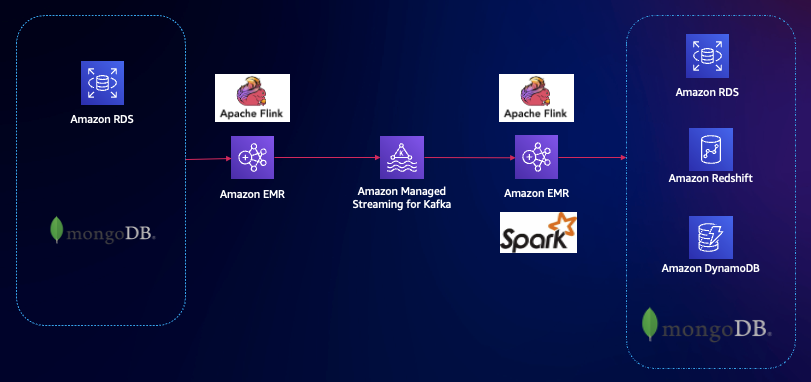
幾種方案的對比請參考:合縱連橫 – 以 Amazon Flink 和 Amazon MSK 構建 Amazon DocumentDB 之間的實時數據同步。
Flink 方案適用于以下場景:
-
各種數據庫到數據倉庫的實時 ETL
-
開源 NoSQL 到 DynamoDB 轉換
-
DynamoDB 表合并
-
S3 離線數據快速寫入 DynamoDB
-
中國和海外數據庫穩定數據復制

Flink 方案優勢在于:
-
托管服務,穩定運行。EMR 主節點可以設置高可用,計算節點以 resource manager 和 yarn 框架實現節點和任務的高可用管理以及任務調度。Flink Checkpoint 機制定期創建檢查點,恢復失敗任務。
-
高性能。EMR 可以設置多個計算節點,以及并行度,充分利用多節點計算能力,并發處理。實際測試復制寫入速度可達幾 GB/s,適合需要短時間內遷移數據。
-
一致性,避免數據重復寫入。
-
開發靈活,可以根據需求進行表合并或者字段轉換。
-
批流一體,支持全量和增量復制,幾乎適用于任何數據復制場景。
-
開源生態豐富,支持多種數據源和目標。
以下對于細分場景單獨以示例說明。
場景 1:實時數據聚合計算
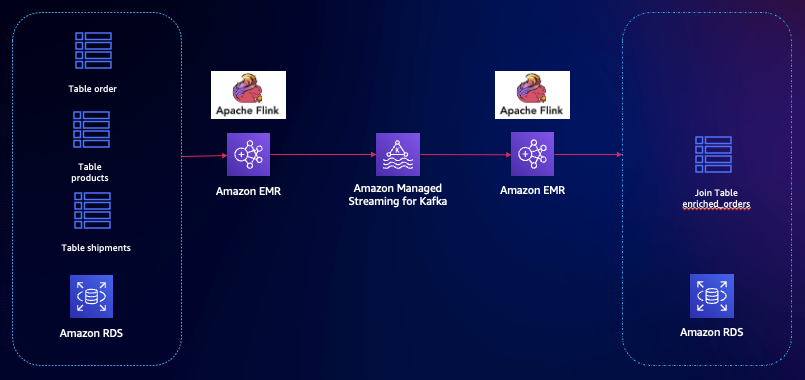
多個業務表需要實時 Join 查詢,把結果寫入目標表。例如電商業務,對訂單數據進行統計分析,進行關聯形成訂單的大寬表,業務方使用業務表查詢。
源端 Flink 創建 Mysql CDC 多表實時 Join,打入 Kafka。目標端 Flink 消費 Kafka 實時數據,同步到目標數據庫。
環境設置
-
源數據庫:RDS Mysql 8.0
創建數據庫 mydb 以及表 products,并寫入數據。
表數據參考 Building a Streaming ETL with Flink CDC | Apache Flink CDC。
-
目標數據庫:RDS Postgresql 14,創建與 MySQL 相同結構的表,可參考上述鏈接。
-
MSK Kafka,禁用密碼驗證。
-
EMR 6.10.0:Flink 1.16.0、ZooKeeper 3.5.10,1 個 primary 節點 + 3 個 core 節點,通過 SSH 登錄主節點。
下載與 Flink1.16 兼容的相關 Flink jar 軟件包,包括 Flink CDC、Kafka、JDBC Connector,目標 PostgreSQL 還需要 JDBC 驅動:
https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-mysql-cdc/2.3.0/flink-sql-connector-mysql-cdc-2.3.0.jar
https://repo1.maven.org/maven2/org/apache/flink/flink-sql-connector-kafka/1.16.1/flink-sql-connector-kafka-1.16.1.jar
https://repo1.maven.org/maven2/org/apache/flink/flink-connector-jdbc/1.16.1/flink-connector-jdbc-1.16.1.jar
https://jdbc.postgresql.org/download/postgresql-42.7.5.jar
把下載的 jar 包復制到 Flink lib 目錄,并修改權限,例如:
sudo cp /home/hadoop/flink-sql-connector-mysql-cdc-2.3.0.jar /usr/lib/flink/lib/
sudo chown flink:flink flink-sql-connector-mysql-cdc-2.3.0.jar
sudo chmod 755 flink-sql-connector-mysql-cdc-2.3.0.jar重啟 Flink 服務使 jar 包加載成功:
cd /usr/lib/flink/bin
./stop-cluster.sh
./start-cluster.sh創建 Kafka topic,修改 –bootstrap-server 為創建的 MSK 地址:
kafka-topics.sh --create --bootstrap-server b-3.pingaws.jsi6j6.c6.kafka.us-east-1.amazonaws.com:9092,b-1.pingaws.jsi6j6.c6.kafka.us-east-1.amazonaws.com:9092,b-2.pingaws.jsi6j6.c6.kafka.us-east-1.amazonaws.com:9092 --replication-factor 3 --partitions 1 --topic flink-cdc-kafka以 yarn 啟動 Flink 應用:
./yarn-session.sh -d -s 1 -jm 1024 -tm 2048 -nm flink-cdc-kafka查看 Flink 啟動應用:
yarn application -listTotal number of applications (application-types: [], states: [SUBMITTED, ACCEPTED, RUNNING] and tags: []):1Application-Id Application-Name Application-Type User Queue State Final-State Progress Tracking-URL
application_1687084195703_0001 flink-cdc-kafka Apache Flink hadoop default RUNNING UNDEFINED 100% http://172.31.88.126:46397此時也可以通過 SSH Tunnel,查看 Flink Web UI 界面,顯示任務運行狀況:
Option 1: Set up an SSH tunnel to the Amazon EMR primary node using local port forwarding - Amazon EMR
下面開始 Flink 流程。啟動 Flink SQL 客戶端:
$ ./sql-client.sh embedded -s flink-cdc-kafka1、設置 Flink checkpoint,間隔 3 秒
SET execution.checkpointing.interval = 3s;2、創建 Flink 表,連接 Mysql 源數據
表結構和 Mysql 相同,使用 mysql-cdc connector 作為連接 Mysql 和 Flink 的組件,獲取數據變化。
CREATE TABLE products (id INT,name STRING,description STRING,PRIMARY KEY (id) NOT ENFORCED) WITH ('connector' = 'mysql-cdc','hostname' = 'Source RDS endpoint','port' = '3306','username' = 'user','password' = 'password','database-name' = 'mydb','table-name' = 'products');3、創建 Kafka 表
根據最終需求而設計的業務表,包含各個表和字段 Join 查詢后的結果。指定 Kafka connector,格式為’debezium-json’,記錄前后變化。
CREATE TABLE enriched_orders (order_id INT,order_date TIMESTAMP(0),customer_name STRING,price DECIMAL(10, 5),product_id INT,order_status BOOLEAN,product_name STRING,product_description STRING,shipment_id INT,origin STRING,destination STRING,is_arrived BOOLEAN,PRIMARY KEY (order_id) NOT ENFORCED) WITH ('connector' = 'kafka','topic' = 'flink-cdc-kafka','properties.bootstrap.servers' = ‘xxxx:9092','properties.group.id' = 'flink-cdc-kafka-group','scan.startup.mode' = 'earliest-offset','format' = 'debezium-json');4、源 Mysql 數據寫入 Kafka 表
多表 Join 結果寫入大寬表,進入 Kafka 消息隊列。
INSERT INTO enriched_ordersSELECT o.*, p.name, p.description, s.shipment_id, s.origin, s.destination, s.is_arrivedFROM orders AS oLEFT JOIN products AS p ON o.product_id = p.idLEFT JOIN shipments AS s ON o.order_id = s.order_id;查看 Kafka 消費程序,可以看到類似以下信息。Mysql 的數據以 debzium json 方式寫入 Kafka,以 before & after 記錄數據前后變化狀況。以下是 INSERT 信息:
kafka-console-consumer.sh --bootstrap-server xxt:9092 --topic multi-table-join --from-beginning
{"before":null,"after":{"order_id":10001,"order_date":"2020-07-30 10:08:22","customer_name":"Jark","price":50.5,"product_id":102,"order_status":false,"product_name":"car battery","product_description":"12V car battery","shipment_id":10001,"origin":"Beijing","destination":"Shanghai","is_arrived":false},"op":"c"}5、消費 Kafka 實時數據,寫入最終目標端業務數據庫
創建目標表:
CREATE TABLE enriched_orders_output(order_id INT,order_date TIMESTAMP(0),customer_name STRING,price DECIMAL(10, 5),product_id INT,order_status BOOLEAN,product_name STRING,product_description STRING,shipment_id INT,origin STRING,destination STRING,is_arrived BOOLEAN,PRIMARY KEY (order_id) NOT ENFORCED
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://<Target RDS endpoint>:3306/mydb','table-name' = 'kafka_orders_output', 'username' = ‘user', 'password' = ‘password'
);6、讀取 Kafka 數據,寫入目標數據庫
INSERT INTO enriched_orders_output SELECT * FROM enriched_orders;7、在源數據庫 Insert/Update/Delete,檢查 Kafka 和目標數據庫,變化幾乎實時同步到目標數據庫
源 Mysql:
mysql> INSERT INTO orders-> VALUES (default, '2020-07-30 15:22:00', 'Jark', 29.71, 104, false);
mysql> INSERT INTO shipments-> VALUES (default,10004,'Shanghai','Beijing',false);
mysql> UPDATE orders SET order_status = true WHERE order_id = 10004;
mysql> UPDATE shipments SET is_arrived = true WHERE shipment_id = 1004;至此,實時查詢的需求已經實現。但生產環境需要可靠的方案,高可用和性能也是重要的考慮因素。因此接下來進行測試。
高可用測試:
EMR 可以實現主節點和計算節點高可用,出現節點故障時可以自動替換,并重新調度任務。模擬節點故障,重啟 core node。Flink checkpoint 機制生成周期性數據快照用于恢復。
啟用 Flink checkpoint:
SET execution.checkpointing.interval = 3s; Checkpoint 有重試機制,直到超過最大重試次數。
如果禁用 Flink checkpoint ,任務失敗不重啟,導致中斷。但是,默認情況下,即使設置 checkpoint,無論位于本地還是 S3,重啟 core 節點也會導致任務中斷。
解決辦法:EMR Configuration 加入 Flink 高可用配置 zookeeper
[{"Classification": "yarn-site","Properties": {"yarn.resourcemanager.am.max-attempts": "10"}},{"Classification": "flink-conf","Properties": {"high-availability": "zookeeper","high-availability.storageDir": "hdfs:///user/flink/recovery","high-availability.zookeeper.path.root": "/flink","high-availability.zookeeper.quorum": "%{hiera('hadoop::zk')}","yarn.application-attempts": "10"}}
]結論:EMR 配置 Flink 高可用,即使出現節點故障,仍然可以保持任務繼續運行,適合長期運行 CDC 任務的場景。
性能測試
運行 EMR Flink CDC 和 MSK 實時數據同步源 Mysql 到目標 PostgreSQL。運行測試程序,源 Mysql 持續快速批量插入數據,同時 4 個測試進程同時運行 20 分鐘,Mysql 寫入數據,打入 Kafka 并消費寫入目標 PostgreSQL。性能指標顯示:
RDS Mysql:CPU 26%, 寫 IOPS 1400/s, 寫入速度 23000/s
RDS PostgreSQL:DML(Insert) 23000/s
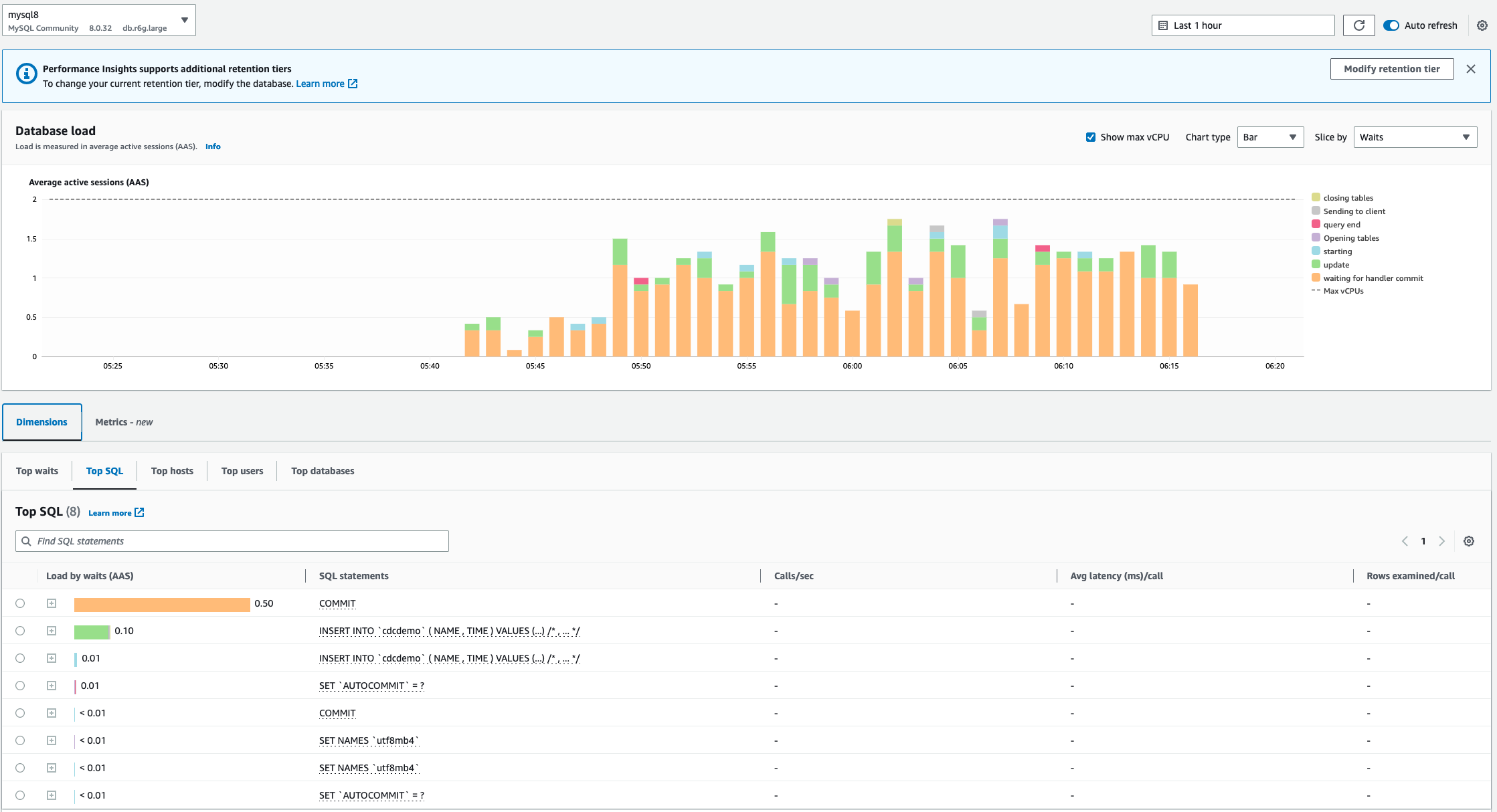
觀察測試結果,以及源和目標數據對比,源 Mysql 經過 EMR Flink + MSK 到目標 PostgreSQL,即使寫壓力高的情況下,復制延遲保持在秒級。
此數據流轉過程中加入了 MSK Kafka 解耦上下游數據,即使在目標端處理能力不足,或者網絡延遲較大時,仍然可以保證整個數據管道正常運行。
場景 2:實時同步數據庫到數據倉庫
Flink 作為數據庫到數據湖/倉庫的 ETL 管道,實現在線和離線數據的統一處理。
以下示例說明從 Spark Streaming 從 Kafka 中消費 Flink CDC 數據,多庫多表實時同步到 Redshift 數據倉庫。

詳情參考:多庫多表場景下使用 Amazon EMR CDC 實時入湖最佳實踐
場景 3:SQL 數據庫(Mysql、PostgreSQL)在線遷移到 NoSQL(DocumentDB、DynamoDB)
傳統 SQL 關系型數據庫在現代化應用的高并發場景下不一定完全適用。由于索引多層效率問題,在數據庫表特別大的時候,加上大量并發讀寫,可能導致數據庫性能下降。分庫分表可以解決擴展問題,但是也帶來中間件 proxy 管理問題和性能損失,更難以解決的是,sharding key 以外的查詢需要從所有分片獲取數據,效率極低。
NoSQL 數據庫是解決大表大并發的很好方法。簡單的 Key Value 或者文檔存儲,不需要復雜的 Join 查詢,可以利用 NoSQL 數據庫的海量存儲和遠高于 SQL 數據庫的高并發和低延遲。Amazon DynamoDB Key Value 數據庫,更可以無需擴容升級運維等升級工作,支持幾乎無上限的的數據容量,輕松擴展到百萬 QPS。
要實現從 SQL 到 NoSQL 的轉換,從應用程序到數據庫都需要改造。在遷移數據庫時,為盡量降低對業務的影響,在線遷移成為大多數客戶的選擇。Amazon DMS 工具是一個選擇,但是對于源和目標,會有些限制。例如,DMS 對于 DynamoDB 復合主鍵支持不足,不允許更新主鍵。源和目標對于一些數據庫并不支持,合并或者轉換數據比較困難。
而 Flink 開發靈活,廣泛的 connector 支持多種數據庫,可以解決這些問題。
以下是方案示例:
此方案中,源數據為 RDS Mysql,通過 Flink CDC Connector,數據以 EMR Flink 處理,打入到 Kafka 消息隊列,再以 Flink 消費數據,最終寫入下游的目標數據庫,包括 DynamoDB、DocumentDB 等。
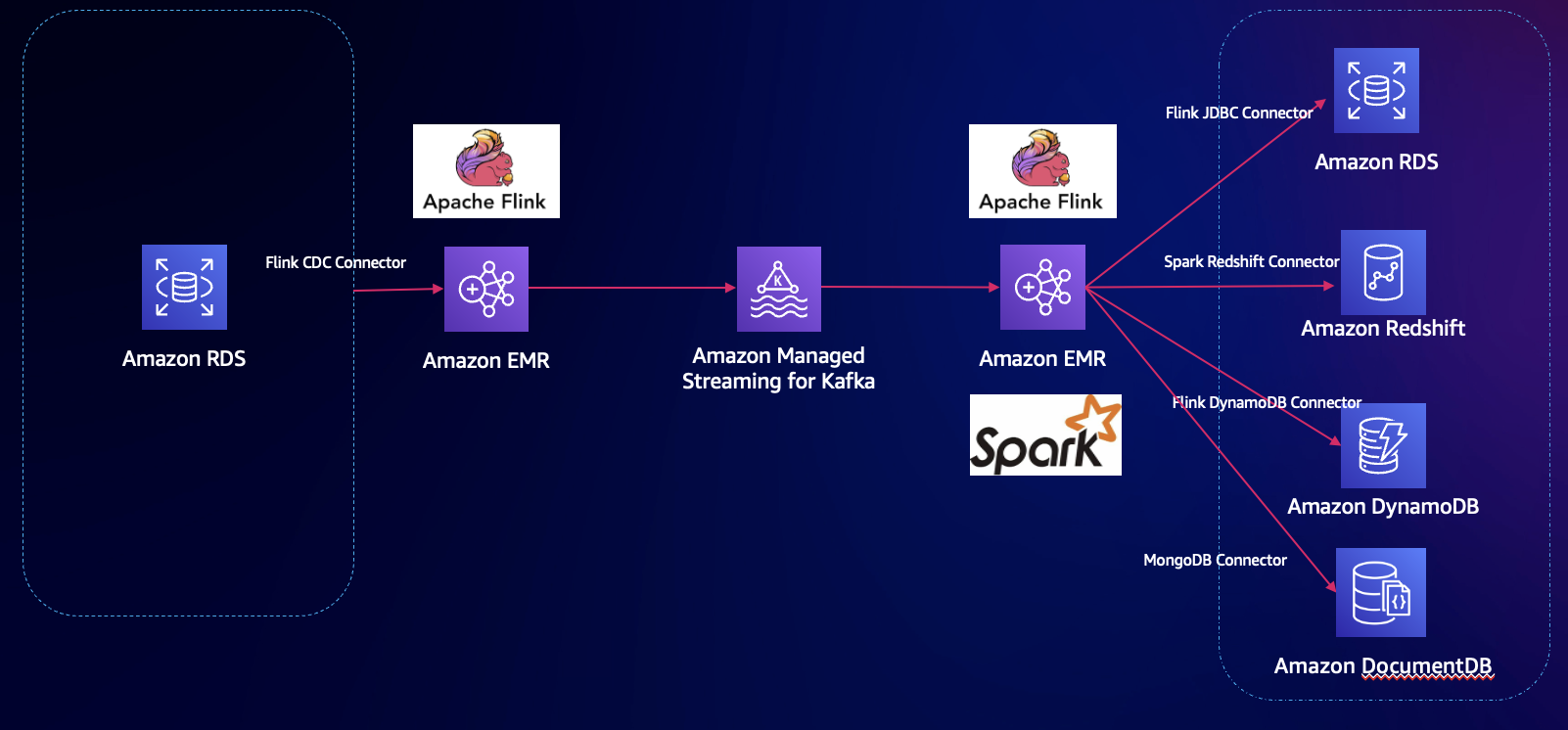
環境:
-
源數據庫 RDS Mysql 8.0
-
目標數據庫:DynamoDB
-
MSK Kafka 2.8.1
-
EMR 6.10.0: Flink 1.16.0, Flink SQL Connector MySQL CDC 2.3.0
下載相應 jar 包到 Flink lib目錄 /usr/lib/flink,修改相關文件的權限和所有者:
flink-connector-jdbc-1.16.2.jar
flink-sql-connector-kafka-1.16.1.jar
flink-sql-connector-mysql-cdc-2.3.0.jar
flink-sql-connector-dynamodb-4.1.0-1.16.ja
cd /usr/lib/flink/lib
sudo chown flink:flink flink-sql-connector-dynamodb-4.1.0-1.16.jar
sudo chmod 755 flink-sql-connector-dynamodb-4.1.0-1.16.jar重啟 Flink 以讓 jar 成功加載:
/usr/lib/flink/bin
sudo ./stop-cluster.sh
sudo ./start-cluster.sh創建 Flink 應用:
./yarn-session.sh -d -s 1 -jm 1024 -tm 2048 -nm flink-cdc-ddb查看 Flink 應用情況:
yarn application -listApplication-Id Application-Name Application-Type User Queue State Final-State Progress Tracking-URL
application_1739533554641_0006 flink-cdc-ddb Apache Flink hadoop default RUNNING UNDEFINED 100% http://172.31.86.244:45475打開 Flink SQL 客戶端:
./sql-client.sh embedded -s flink-cdc-ddb啟用 checkpoint:
SET execution.checkpointing.interval = 3s;創建 Flink 表,關聯 Mysql 表:
CREATE TABLE product_view_source (
`id` int,
`user_id` int,
`product_id` int,
`server_id` int,
`duration` int,
`times` string,
`time` timestamp,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = ‘xxxx',
'port' = '3306',
'username' = ‘user',
'password' = ‘password',
'database-name' = 'test',
'table-name' = 'product_view'
);創建 Flink Kafka 表,并把 Mysql 數據寫入 Kafka。掃描數據從最早開始,’scan.startup.mode’ = ‘earliest-offset’
CREATE TABLE product_view_kafka_sink(
`id` int,
`user_id` int,
`product_id` int,
`server_id` int,
`duration` int,
`times` string,
`time` timestamp,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH ('connector' = 'kafka','topic' = 'flink-cdc-kafka','properties.bootstrap.servers' = ‘xxxx:9092','properties.group.id' = 'flink-cdc-kafka-group','scan.startup.mode' = 'earliest-offset','format' = 'debezium-json’
);insert into product_view_kafka_sink select * from product_view_source;創建 Flink DynamoDB 表,并把 Kafka 隊列里的數據寫入 DynamoDB。Flink DynamoDB Connector 需要設置 PARTITIONED BY ( ),以和 DynamoDB 主鍵一致。
CREATE TABLE kafka_output(
`id` int,
`user_id` int,
`product_id` int,
`server_id` int,
`duration` int,
`times` string,
`time` timestamp
) PARTITIONED BY ( id )
WITH ('connector' = 'dynamodb','table-name' = 'kafka_ddb','aws.region' = 'us-east-1’
);INSERT INTO kafka_output SELECT * FROM product_view_kafka_sink;最終可以看到,源端 Mysql 全量和增量變化數據,都寫入到目標端 DynamoDB。
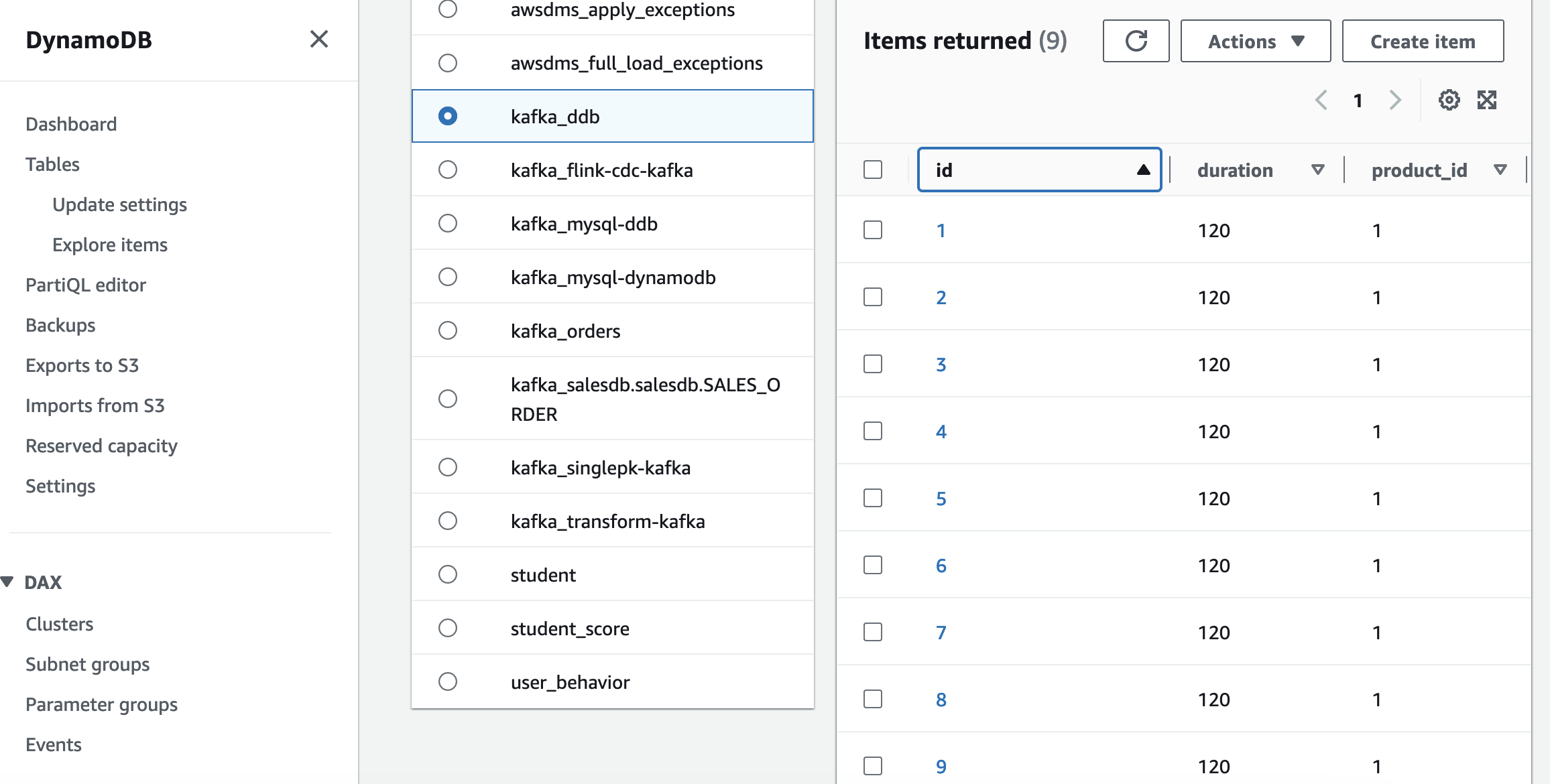
以下是 Kafka Debezium JSON 格式,包含數據前后變化:
{"before":null,"after":{"id":1,"user_id":1,"product_id":1,"server_id":1,"duration":120,"times":"120","time":"1587734040000"},"op":"c"}
{"before":null,"after":{"id":2,"user_id":1,"product_id":1,"server_id":1,"duration":120,"times":"120","time":"1587734040000"},"op":"c"}
…
{"before":{"id":10,"user_id":8,"product_id":1,"server_id":2,"duration":120,"times":"120","time":"1589375640000"},"after":null,"op":"d"}
{"before":null,"after":{"id":10,"user_id":8,"product_id":10,"server_id":2,"duration":120,"times":"120","time":"1589375640000"},"op":"c"}
{"before":{"id":10,"user_id":8,"product_id":10,"server_id":2,"duration":120,"times":"120","time":"1589375640000"},"after":null,"op":"d"}
{"before":null,"after":{"id":10,"user_id":8,"product_id":1,"server_id":2,"duration":120,"times":"120","time":"1589375640000"},"op":"c"}除了數據庫之外,應用程序也需要從訪問 Mysql 改為 DynamoDB,相應的數據庫接口和讀寫語句也完全不一樣。對于那些 DynamoDB 不是非常熟悉的開發者,如何更絲滑轉換現有代碼呢?Amazon Q Developer CLI AI 助手可以幫助我們大大降低轉換代碼的工作量。通過提示詞,描述現有的項目情況,指定轉換目標,實現業務需求。Amazon Q Developer CLI 會分析現有代碼,根據需求和自己的理解,生成與原來業務實現一樣的代碼。整個過程無需過多干預,即使遇到錯誤,Amazon Q Developer CLI 也會自己排查然后解決,最終生成新的項目。
下面演示從 Mysql 到 DynamoDB 數據庫代碼改造的過程。項目使用 Python,Mysql 數據庫作為聊天消息存儲。
打開 Amazon Q Developer CLI,輸入提示詞:
Design Dynamodb as RDS Mysql table for chat message. Refer to SQL:
CREATE TABLE message (msgid STRING PRIMARY KEY,sessionid STRING NOT NULL,sender_id STRING NOT NULL,receiver_id STRING NOT NULL,message_type VARCHAR(20),content VARCHAR(1000),status VARCHAR(10),created_at DATETIME DEFAULT CURRENT_TIMESTAMP,updated_at DATETIME
);
ID should be unique but incremental, considering snowflake algorithm. Each chat session(sessionid) may contain several messages with "msgid". Need query:
1. Chat sessions to get messages in time range.
2. Recent messages for sender and receiver.
Insert 10000 rows data.
RDS: <Your RDS Mysql endpoint>, user: admin, password: xxxx提示定義了 Mysql 聊天消息表結構,按照 snowflake 算法生成 id,查詢實現兩種業務,某個時間段的聊天會話,以及發送者或者接受者最近消息。在此基礎上繼續轉換代碼為 DynamoDB。
Amazon Q Developer CLI 進行以下工作:
1、構建 Mysql 代碼,創建表,寫入數據,并構造聊天消息的業務查詢。
## MySQL Table Design
I've created a MySQL table with the following schema:
sql
CREATE TABLE message (msgid VARCHAR(255) PRIMARY KEY,sessionid VARCHAR(255) NOT NULL,sender_id VARCHAR(255) NOT NULL,receiver_id VARCHAR(255) NOT NULL,message_type VARCHAR(20),content VARCHAR(1000),status VARCHAR(10),created_at DATETIME DEFAULT CURRENT_TIMESTAMP,updated_at DATETIME
);With indexes for common query patterns:
sql
CREATE INDEX idx_sessionid ON message(sessionid);
CREATE INDEX idx_sender_id ON message(sender_id);
CREATE INDEX idx_receiver_id ON message(receiver_id);
CREATE INDEX idx_created_at ON message(created_at);2、創建 DynamoDB 表,按照 Mysql 業務邏輯構建,并創建相應索引。
## DynamoDB Design? **Primary Key**:? Partition Key: PK (String) - Composite key with different prefixes? Sort Key: SK (String) - Composite key for sorting and querying? **Global Secondary Indexes**:? GSI1: For session-based queries? GSI2: For sender-based queriesThis design efficiently supports your required query patterns:
1. Get messages in a session within a time range
2. Get recent messages for a sender or receiver## ID GenerationI've implemented a Snowflake-like ID generation algorithm in snowflake_id.py that creates:
? Time-sortable IDs (41 bits for timestamp)
? Unique across distributed systems (10 bits for machine ID)
? High throughput (12 bits for sequence number)3、寫入測試數據,并從 Mysql 遷移數據到 DynamoDB,然后運行業務查詢測試。
1. create_mysql_table.sql: SQL script to create the MySQL table
2. snowflake_id.py: ID generation utility
3. create_dynamodb_table.py: Script to create the DynamoDB table
4. generate_sample_data.py: Script to generate 10,000 sample messages in MySQL
5. migrate_to_dynamodb.py: Script to migrate data from MySQL to DynamoDB
6. query_examples.py: Examples of common query patterns
7. requirements.txt: Required Python packages
8. run.sh: Shell script to run the entire migration processAmazon Q Developer CLI 還總結了此方案的特點,包括:
-
高效 DynamoDB 查詢
-
消息按照 DynamoDB 時間戳排序
-
使用 snowflake 雪花算法生成按時間排序的唯一消息 id
-
高擴展性
查看項目,Mysql 查詢代碼,改造為 DynamoDB:

DynamoDB 數據示例:
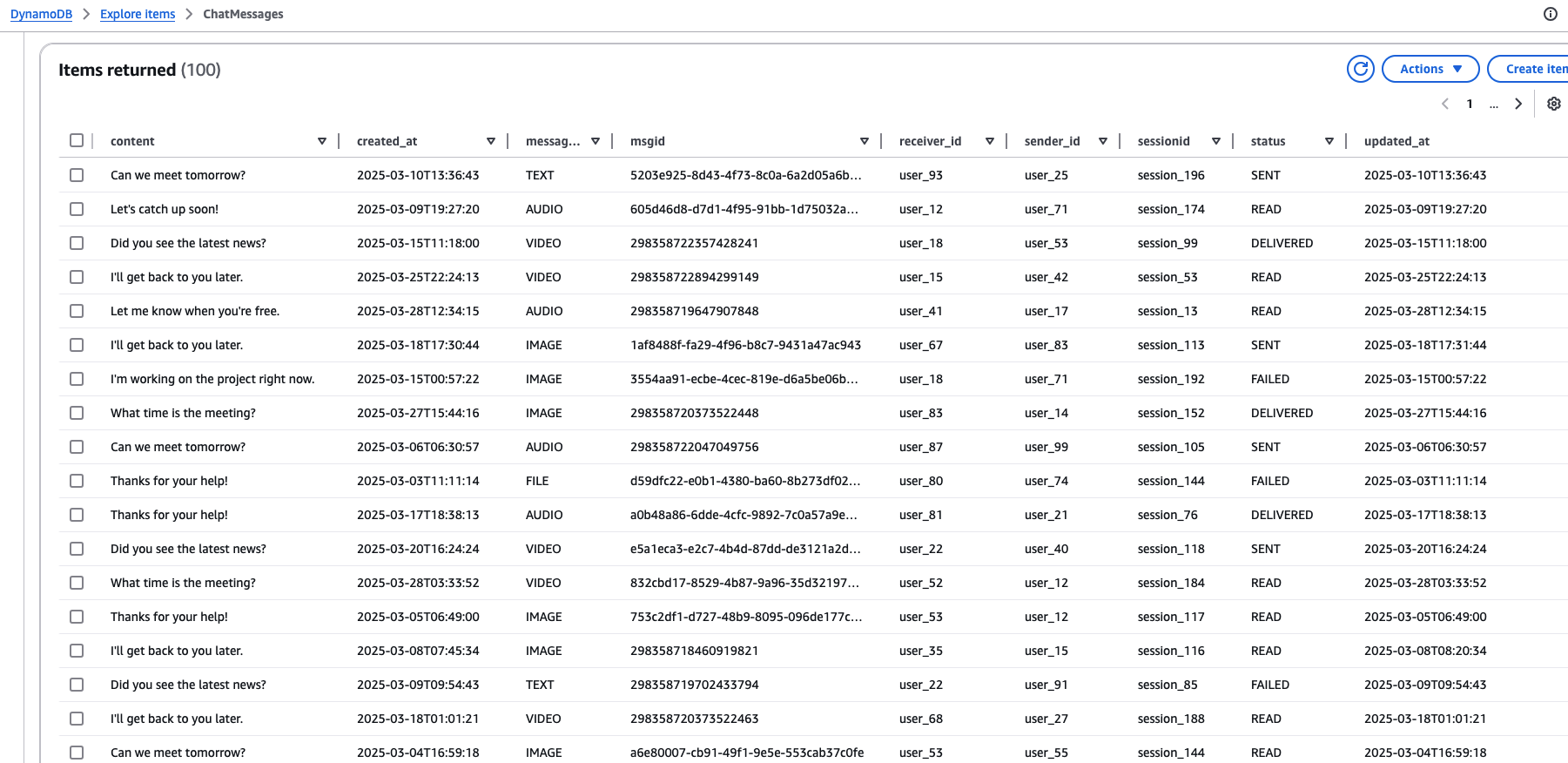
下面查看 Mysql 與 DynamoDB 的代碼對比。
Mysql:實現按照時間查詢會話,以及按照發送者查詢消息。
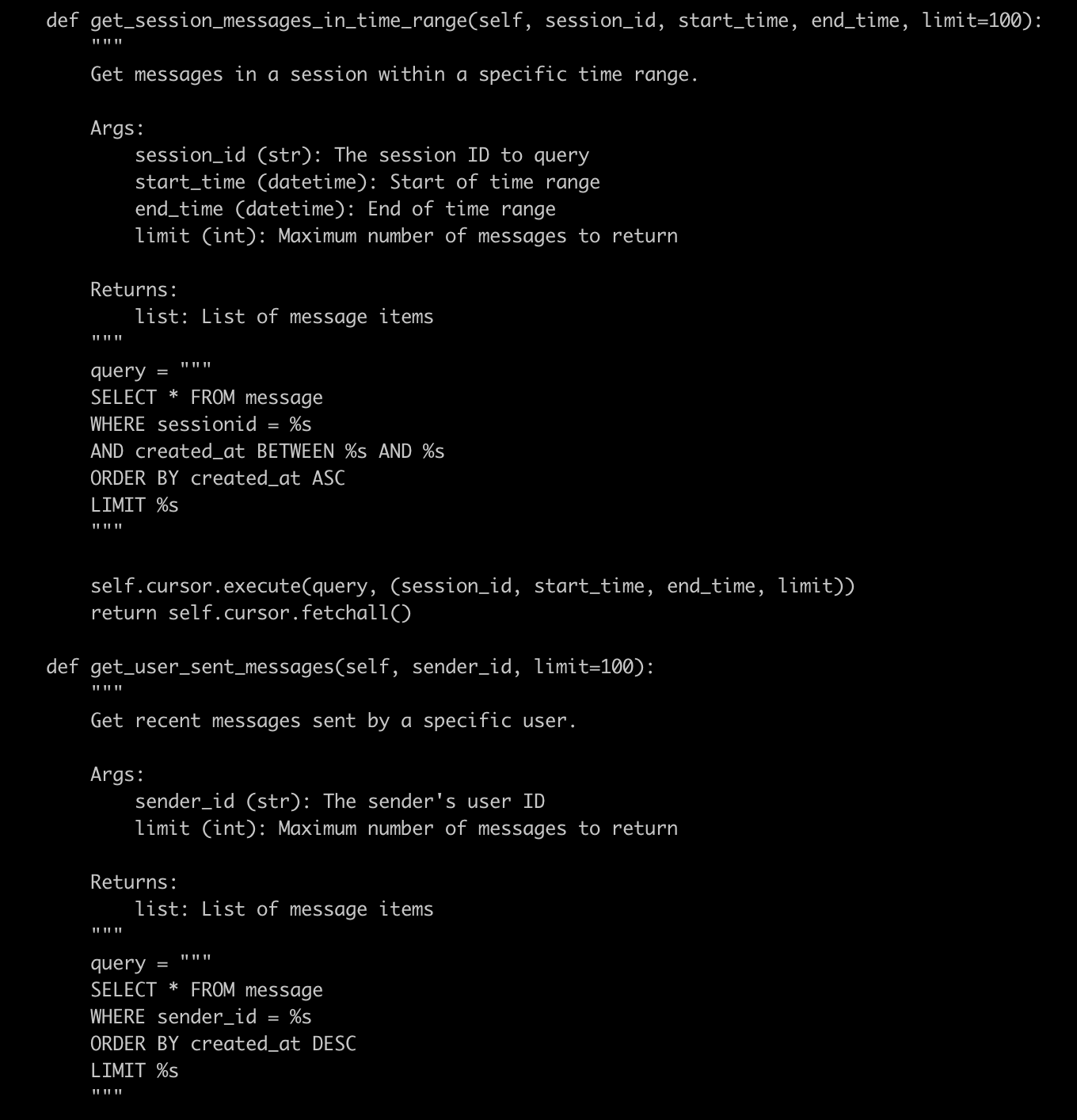
同樣的業務邏輯,在 DynamoDB 實現時,原 Mysql SQL 語句為:
SELECT * FROM messageWHERE sessionid = %sAND created_at BETWEEN %s AND %sORDER BY created_at ASCLIMIT %s修改為 DynamoDB 查詢后:
response = self.table.query(IndexName='SessionTimeIndex',KeyConditionExpression=Key('sessionid').eq(session_id) &Key('created_at').between(start_timestamp, end_timestamp),Limit=limit,ScanIndexForward=True # True for ascending (oldest first))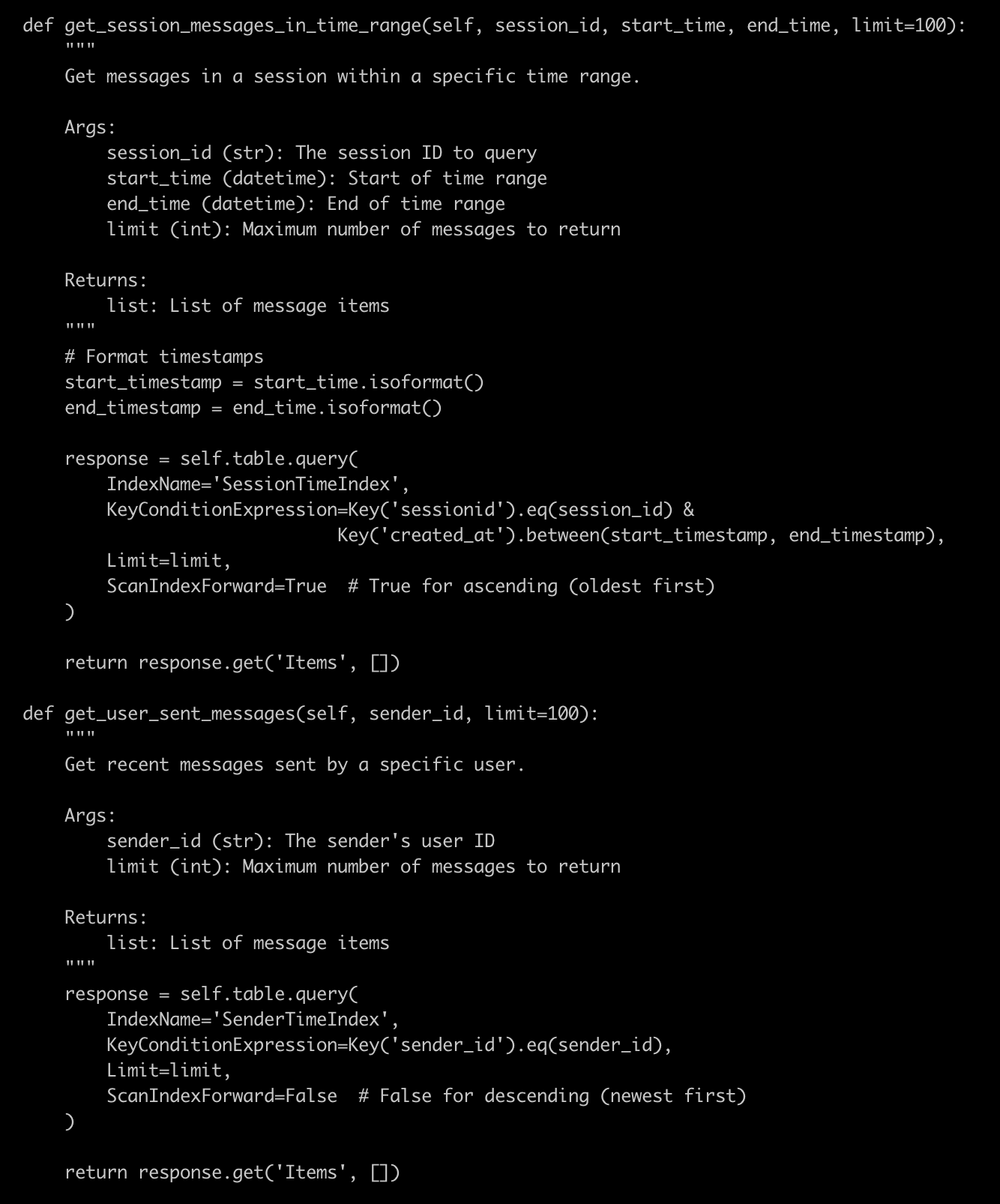
從以上示例可以看出,Amazon Q Developer CLI 可以加速 SQL 到更高效 NoSQL 的數據庫代碼改造。當然,我們可以給出更精確的要求,例如列出現有需求、合并或者轉換數據等,都可以讓 Amazon Q Developer CLI 幫助生成和轉換代碼。
Amazon Q Developer CLI 還生成了輸出對比效果,轉換前后結果一致。此過程中,無需編寫任何一行代碼,即可實現數據庫代碼的轉換,業務功能沒有變化,使用更為靈活的 NoSQL 數據庫提高性能和擴展性。如果需要發揮 DynamoDB 更多性能優勢,可以在提示詞讓 Amazon Q Developer CLI 遵循最佳實踐來設計數據庫,也可以按照業務需求做表合并等修改。
參考:GitHub - milan9527/mysql2nosql
場景 4:開源 NoSQL 數據庫在線遷移到 Amazon SQL/NoSQL
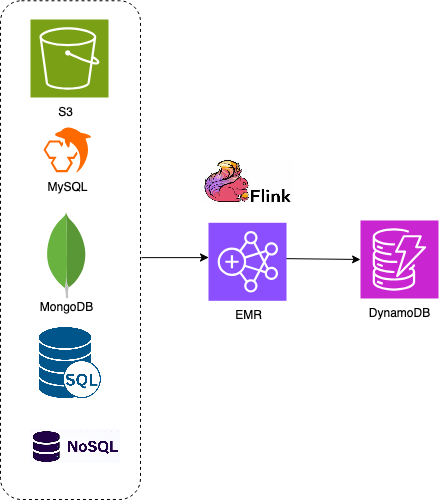
NoSQL 數據庫已經在很多行業廣泛使用。例如,游戲中使用 MongoDB 作為戰斗服玩家數據更新,Cassandra/CouchDB/Couchbase 等開源數據庫也有應用。如果想要更多云原生 NoSQL 數據庫的優勢,無需自己維護分片和升級,或者更高彈性滿足業務,Amazon DynamoDB/DocumentDB 更為適合。但是,不同數據庫訪問接口不一樣,如何從開源 NoSQL 數據庫平滑遷移到 DynamoDB?對于沒有接觸過 DynamoDB 的客戶,需要一定的學習,而遷移工具也是影響落地的重要因素。Flink 支持多種開源 NoSQL Connector,也支持定制開發,在遷移過程中合并或者轉換數據。
方案架構:
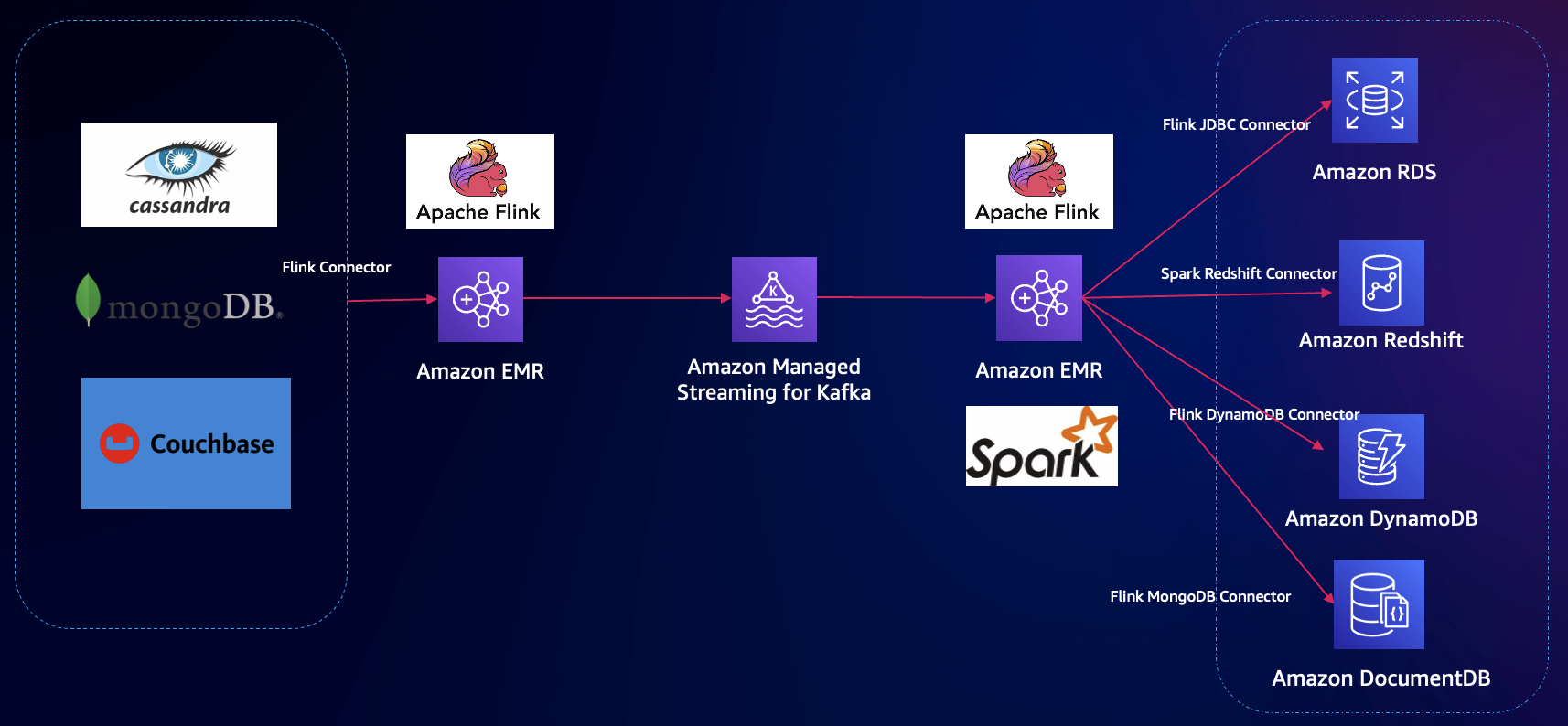
與場景 3 類似,只是源數據庫從 SQL 變成 NoSQL 數據庫,目標端可以是 NoSQL 或者 SQL 數據庫,源數據庫和 Flink 使用相應的 Connector 即可。
以下示例用 Amazon Q Developer CLI 生成 Flink 項目,從 Couchbase 遷移數據到 DynamoDB。此簡易示例中沒有使用 Kafka,而是直接以 Flink 連接源和目標,實現全量和增量數據復制。當然,Kafka 也支持一些 Connector,以此接入消息隊列。
步驟:
安裝 Couchbase,生成測試數據。
Amazon Q Developer CLI 提示詞:
Need migrate database from Couchbase to Dynamodb. Create data pipeline by Flink. I have local Couchbase 7.6.6, Flink 1.6.2. Create project which can run in intellij idea IDEAmazon Q Developer CLI 生成 Flink Java 代碼,運行出錯:
org.apache.flink.api.common.eventtime.WatermarkStrategy;自動排錯:
Let me fix those import errors. The issue is that some of the dependencies might not be correctly specified in the pom.xml file. Let‘s update the pom.xml to include the correct dependencies:Flink batch 模式錯誤,繼續修復:
Exception in thread "main" java.lang.IllegalStateException: Detected an UNBOUNDED source with the 'execution.runtime-mode' set to 'BATCH'.
This error occurs because the Flink job is configured to run in BATCH mode, but your CouchbaseSource is being treated as an unbounded source (which is not allowed in BATCH mode).
Let me fix this issue by modifying the CouchbaseSource class to implement the SourceFunction interface correctly for batch processing:出現查詢表錯誤,源表不存在,繼續修復:
Caused by: com.couchbase.client.core.error.IndexFailureException: com.couchbase.client.core.error.IndexFailureException: The server reported an issue with the underlying index
I see the error. The issue is that the Couchbase query is trying to access a bucket named "default" but your configuration is set to use"gamesim-sample" as the bucket. Let me fix this mismatch至此,已經成功把數據從 Couchbase 通過 Flink 寫入 DynamoDB。
下面繼續優化,使用高可用設置,提高性能。自動修改代碼,加入 Flink checkpoint 和重試機制,使用 batch 批量寫入 DynamoDB,調整 Flink 并行度。
最后在項目中生成 Readme 文件,總結架構、使用方法、配置文件。
整個過程中無需手動編寫代碼,即可絲滑生成遷移項目。對于不熟悉 Flink 的開發者,也能實現遷移功能,建議 review 生成的代碼功能,先在測試環境驗證。
生成項目如下:simple-flink-migration/simple-flink-migration at main · milan9527/simple-flink-migration · GitHub
場景 5:DynamoDB 多表合并
游戲場景中經常有合服操作,多個游戲服務合成一個,相應的組件也需要合并。這里演示 DynamoDB 多表合并,此過程中還需要把數據結構稍微調整,并要求合并過程在線完成,不影響線上業務。
可以考慮的方案:
-
S3 export/import:DynamoDB 支持 S3 導入導出,但是需要異步進行,在數據量大時時間過久,并且不支持增量復制,要求目標表為新表。這些限制使得快速在線遷移難以實現。
-
DMS:DMS 源不支持 DynamoDB,復合主鍵有限制,此方案技術上不可行。
-
Hive + DynamoDB Stream:Hive 支持 DynamoDB,以外表方式操作 DynamoDB 表,結合 DynamoDB Stream 可以自己編寫 Lambda 處理增量變化數據。但是此方案對 map 字段支持有限,也排除考慮。
-
Glue + DynamoDB Stream:Glue 以 Spark 程序訪問 DynamoDB,也需要一些 Spark 開發經驗,Glue 性能以 DPU 來控制,需要對此服務有所了解。
-
Flink:流批一體,支持全量+增量復制,可以在線遷移。靈活的數據接口和開發支持合并和轉換操作。Flink 方案最合適。
具體實現方式上,Flink SQL 雖然簡單,以 SQL 方式操作數據表,但是只支持 DynamoDB Sink 不支持 Source。Flink DataStream API 可以支持 DynamoDB 作為源和目標,需要開發代碼。并非所有開發人員都熟悉 Flink,但是 Amazon Q Developer CLI 可以幫助實現整個數據流程、編寫代碼、構建 jar 包,并提交任務到 EMR Flink 應用。原來即使熟悉 Flink,整個開發過程也需要幾天時間,而現在可以讓 Flink 幫助我們幾個小時完成測試。
整個方案架構如下。創建 EMR Flink,編寫 Flink 程序,使用 Datastream API 訪問多個 DynamoDB 表,合并轉換數據,寫入目標 DynamoDB 表。此過程還需要獲取 DynamoDB 變化并寫入目標表,開啟 DynamoDB Stream。
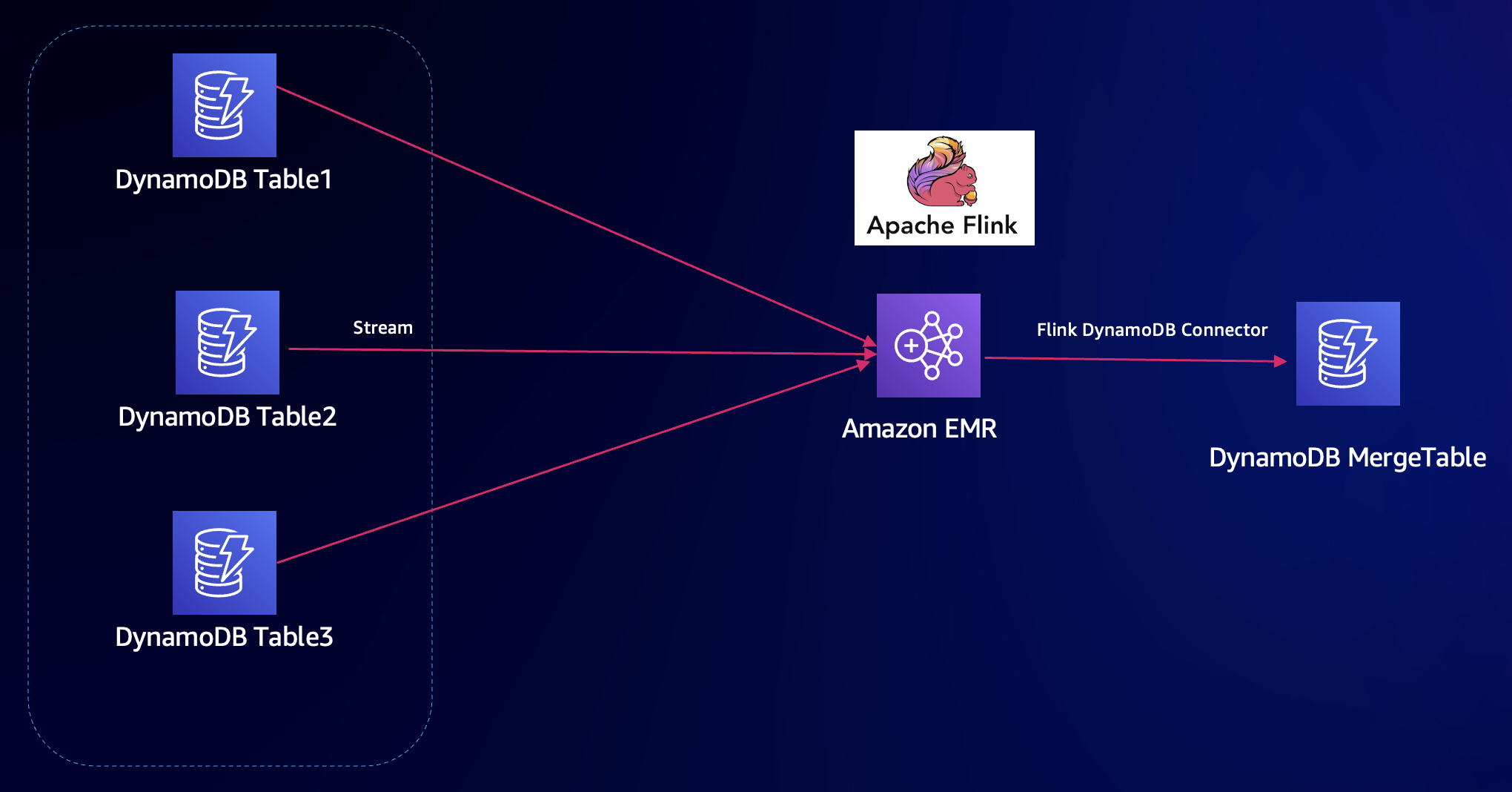
以下演示Amazon Q Developer CLI 構建過程:
提示詞:{JSON}部分是 DynamoDB 數據結構,提供合并轉換前后的數據樣例。
Use EMR flink to merge and sync Dynamodb tables.
In us-east-1 region, 3 Dynamodb tables already exist(GameMailbox1, GameMailbox2, GameMailbox3) with the same schema for gaming mail box. Sample data:
{JSON}
Field "reward" data type is map.
Each table has almost 10000 items.
Combine the 3 tables into one merged table(GameMailboxMerged) with data format like:
(JSON}
The target merged table has the same gameId. Partition key is built as "gameId#mailId".
Data is processed via Flink includeing full load and cdc without interruption. Source table stream should be enabled. You can use existing EMR cluster "mvdemo" with flink 1.16. Make sure Flink keeps running for cdc. Use Flink datastream connector with Java for cdc. Also Java for full load.整個過程幾乎無需過多干預,Amazon Q Developer CLI 自動調試運行,最終生成 Flink Java項目,并提交 EMR Flink 任務。
Flink UI 界面可以看到,全量 Full load 和增量 CDC 任務正常運行:
項目結構如下:GitHub - milan9527/dynamodbmerge
以下為合并處理邏輯,包含了處理刪除操作,處理 Map 類型,寫入 DynamoDB 數據:
public void invoke(GameMailboxMergedItem value, Context context) {try {// Check if this is a delete operationif (value.isDeleteOperation()) {// Delete the item from the target tabledeleteItem(value);} else {// Convert the item to a DynamoDB item and write itMap<String, AttributeValue> item = convertToAttributeValues(value);// Write to DynamoDBPutItemRequest putItemRequest = PutItemRequest.builder().tableName(tableName).item(item).build();dynamoDbClient.putItem(putItemRequest);LOG.info("Successfully wrote item with PK: {} to table: {}", value.getPK(), tableName);}最終,我們實現了業務需求,全量數據迅速加載,增量數據以 KCL 讀取 DynamoDB Stream,增刪改都可以快速復制,源表數據轉換后按照預定格式復制到目標表。而且,Amazon Q Developer CLI 還提高了 Flink 運行效率和可靠性,以 checkpoint 實現 Exactly-once 只寫一次,多表并行處理。
需要注意的是,Amazon Q Developer CLI 生成的代碼仍然需要 review。測試中,Amazon Q Developer CLI 自由發揮,最開始的 stream pulling 時間稍長,在增量 CDC 部分使用 DynamoDB scan 到內存對比,雖然功能可以實現,但是效率低,成本高,后來改成更優的 DynamoDB Stream + KCL(Kinesis Client Library)方式。
場景 6:S3 離線數據快速寫入數據庫
對于應用程序收集的打點數據,離線數據會存儲在 S3 以降低成本,每隔一段時間寫入 S3。業務上需要在數據庫快速訪問這些數據,如何快速把這些離線數據寫入數據庫,是個很大的挑戰。
通常此類數據量很大,并且并發訪問很高,可以考慮 DynamoDB 這類高性能 NoSQL 數據庫。批量寫入可以使用 Flink,源端支持 S3 文件系統方式接口,目標端支持 DynamoDB。Flink SQL 支持簡單的查詢插入。
讓我們看看以下需求:
S3 離線數據存儲在 6 個目錄,壓縮 1.8 TB,一共 130 億行。每隔一段時間批量寫入 DynamoDB,要求盡快寫完,最好 1 小時內。此需求的挑戰在于,時間很短,整個方案要求寫入處理速度很高。
考慮方案:
-
Dynamodb import from S3:導入為異步運行,導入時間過長,并且目標表必須為空。
-
DMS:單實例處理性能不足,不支持 DynamoDB 復合主鍵。
-
Hive MR/Tez:Hive 適合離線數據倉庫,并非為高性能設計。MapReduce 引擎性能較低,即使使用 Tez,性能仍然成為瓶頸。
-
Flink:高性能,多節點并發處理,DynamoDB 支持每秒幾百萬的寫入,成為解決問題的關鍵。
Flink 方案架構如下:
測試環境:
-
DynamoDB:WCU 10M,RCU 1.5M,需要提前預熱,表讀寫容量可以根據需求調整。
-
EMR 6.10.0:Flink 1.16.0,1 個 primary 節點 + 32 個 core 節點,r8g.2xlarge,Flink 并行度 Parallelism=128,節點和并行度也可以調整。
Flink 運行過程參考之前場景 3。
創建 Flink S3 表:
CREATE TABLE s3_duf_3d(oneid string, duf_3d_feas_map string,
PRIMARY KEY (oneid) NOT ENFORCED
) WITH ('connector' = 'filesystem','path' = 's3://pingawsdemo/duf_1_3d_by_region/','format' = 'csv','csv.field-delimiter'='\t'
);創建 Flink DynamoDB 表:
CREATE TABLE ddb_fea (oneid string, type string, feas string
)
WITH ('connector' = 'dynamodb','table-name' = 'mydemo','aws.region' = 'us-east-1'
);S3 數據寫入 DynamoDB:
INSERT INTO ddb_fea
SELECT oneid, 'duf_3d' AS type, duf_3d_feas_map AS feas FROM s3_duf_3d;
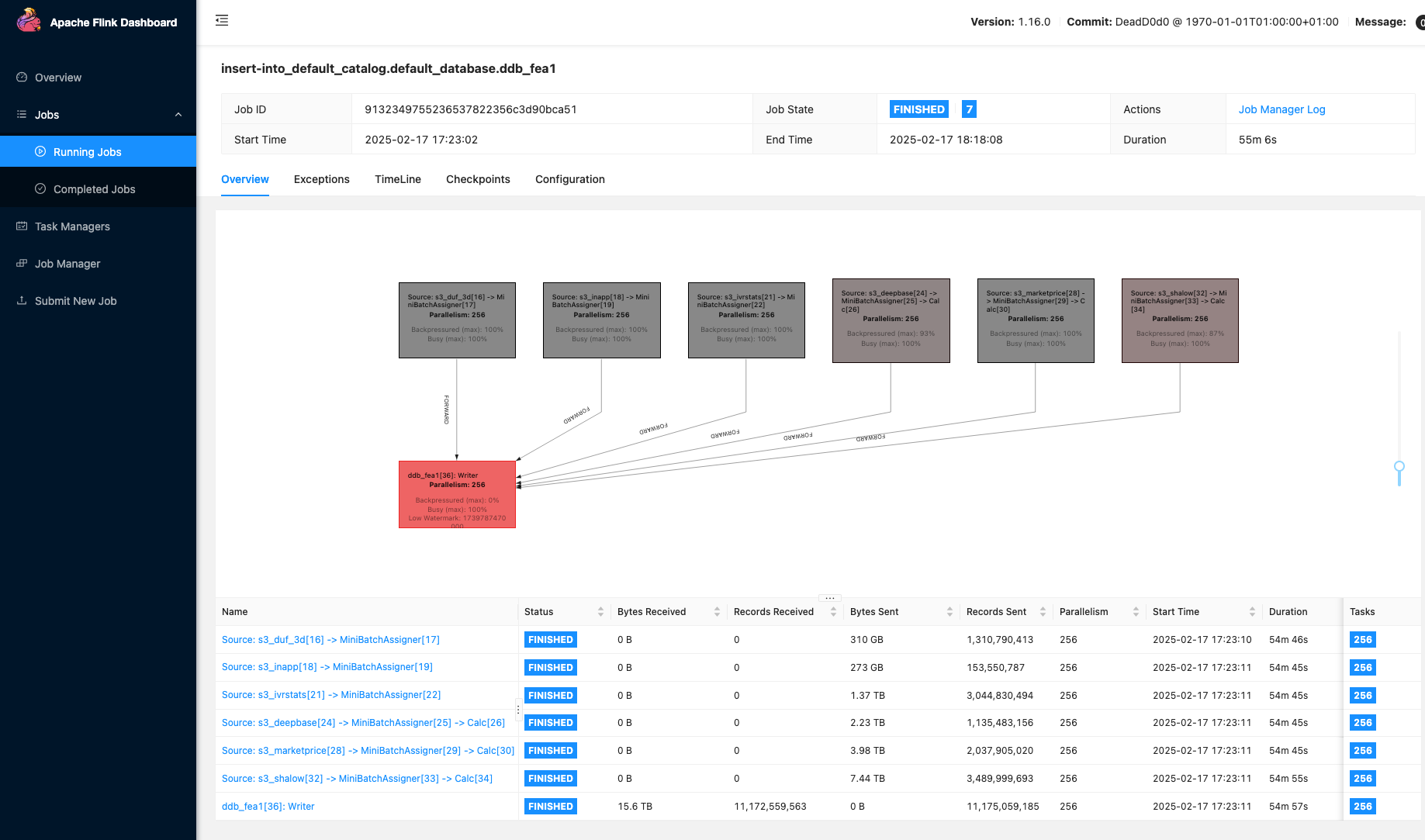
從 EMR Flink UI 可以看到,6 個任務同時運行:
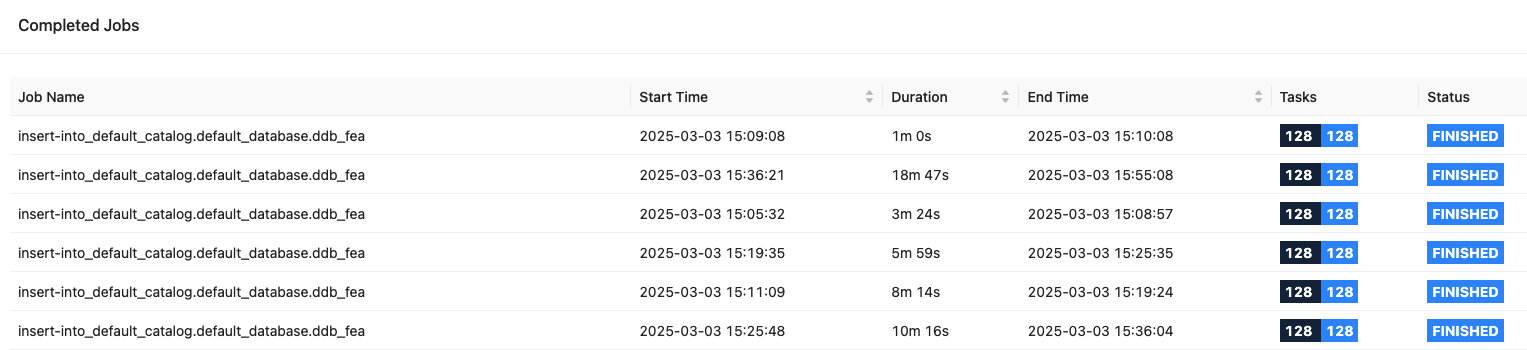
DynamoDB 指標:WCU 10M,相當于每秒寫入 1 千萬條 1KB 數據,寫延遲 6ms,性能相當優異。
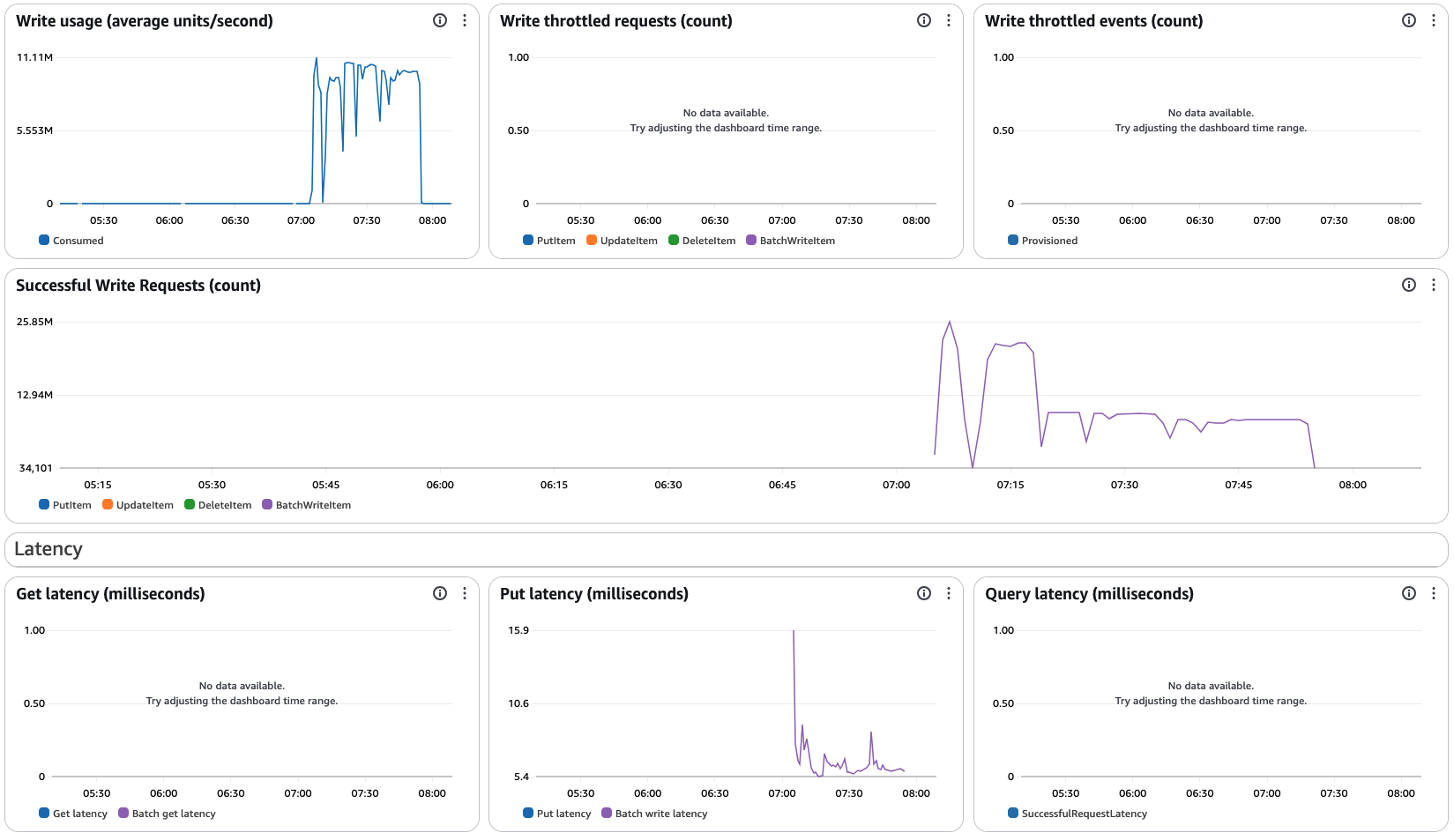
任務運行結果:
-
S3 文件解壓后 20TB,總處理寫入時間 47 分鐘,平均 7GB/s。
-
這是 32 個 EMR 節點以及 Flink 并行度 128 的表現,可以適當調整 EMR 節點和并行度,以及 DynamoDB WCU。
-
Flink SQL 即可完成,無需編寫代碼。
此過程也可以用 Flink DataStream 開發,可考慮 Amazon Q Developer CLI AI 助手加速生成代碼。
場景 7:中國和海外數據庫數據復制
中國和海外區域隔離,服務不能互通,原生的跨區域數據復制功能不支持。對于需要國內外數據復制的場景,需要自行搭建復制工具。
參考:《合縱連橫 – 以 Amazon Flink 和 Amazon MSK 構建 Amazon DocumentDB 之間的實時數據同步》。
Flink 作為 Zero ETL/DMS 的補充方案,在更多場景下可以發揮作用,也存在一些落地難度問題。Flink 提供多種使用方式,Flink SQL 更簡單,用 SQL 即可完成表創建和上下游寫入,但是部分源和目標可能不支持,并且合并轉換不能用 SQL 完全實現。
相對而言,代碼方式更加靈活。但是,并非所有運維人員都了解 Flink 開發,即使是開發人員,也不一定懂 Flink。Amazon Q Developer CLI AI 助手實現方案落地。我們只需要提需求,所有 Flink 開發工作交給大模型處理,包括下載 mvn 依賴,項目打包,創建 Flink 應用并提交任務,極大降低了 Flink 使用難度。
結論
Flink 可以構建靈活的數據庫和數據倉庫的數據管道,實現:
-
實時數據聚合計算
-
實時同步數據庫到數據倉庫
-
SQL 數據庫在線遷移到 NoSQL
-
開源 NoSQL 到 Amazon DynamoDB 轉換
-
DynamoDB 表合并
-
S3 離線數據快速寫入 DynamoDB
-
中國和海外數據庫穩定數據復制
使用 Amazon Q Developer CLI 快速搭建 Flink 管道,只需要描述需求,即可構建代碼和服務組件,進行部署和測試,完成整個部署流程,大量節省時間,即使不熟悉 Flink 開發也可以使用。
*前述特定亞馬遜云科技生成式人工智能相關的服務僅在亞馬遜云科技海外區域可用,亞馬遜云科技中國僅為幫助您了解行業前沿技術和發展海外業務選擇推介該服務。
本篇作者

本期最新實驗為《Agentic AI 幫你做應用 —— 從0到1打造自己的智能番茄鐘》
? 自然語言玩轉命令行,10分鐘幫你構建應用,1小時搞定新功能拓展、測試優化、文檔注釋和部署
💪 免費體驗企業級 AI 開發工具,質量+安全全掌控
??[點擊進入實驗] 即刻開啟 AI 開發之旅
構建無限, 探索啟程!


![[特殊字符] FFmpeg 學習筆記](http://pic.xiahunao.cn/[特殊字符] FFmpeg 學習筆記)







高級應用和使用示例)

)

:完善解析邏輯/文檔撰寫模式全新升級)


![[深度學習]搭建開發平臺及Tensor基礎](http://pic.xiahunao.cn/[深度學習]搭建開發平臺及Tensor基礎)

