25年5月來自北大、理想汽車和 UC Berkeley 的論文“GeoDrive: 3D Geometry-Informed Driving World Model with Precise Action Control”。
世界模型的最新進展徹底改變動態環境模擬,使系統能夠預見未來狀態并評估潛在行動。在自動駕駛中,這些功能可幫助車輛預測其他道路使用者的行為、執行風險意識規劃、加速模擬訓練并適應新場景,從而提高安全性和可靠性。當前的方法在保持強大的 3D 幾何一致性或在遮擋處理期間累積偽影方面表現出不足,這兩者對于自動導航任務中的可靠安全評估都至關重要。為了解決這個問題,GeoDrive 將強大的 3D 幾何條件明確地集成到駕駛世界模型中,以增強空間理解和動作可控性。具體而言,首先從輸入幀中提取 3D 表示,然后根據用戶指定的自車軌跡獲取其 2D 渲染。為了實現動態建模,提出一個訓練期間的動態編輯模塊,通過編輯車輛的位置來增強渲染。大量實驗表明,該方法在動作精度和 3D 空間-覺察方面均顯著優于現有模型,從而能夠構建更逼真、適應性更強、更可靠的場景建模,從而實現更安全的自動駕駛。此外,該模型可以泛化到新軌跡,并提供交互式場景編輯功能,例如目標編輯和目標軌跡控制。
GeoDrive 如圖所示:

給定初始參考圖像 I_0 和自車軌跡 {C_t},框架合成遵循輸入軌跡的真實未來幀。利用參考圖像中的 3D 幾何信息來指導世界建模。首先,重建 3D 表示,然后沿著用戶指定的軌跡渲染視頻序列,并進行動態物體處理。渲染后的視頻為生成遵循輸入軌跡的時空一致視頻提供幾何指導。其訓練流水線如圖所示:
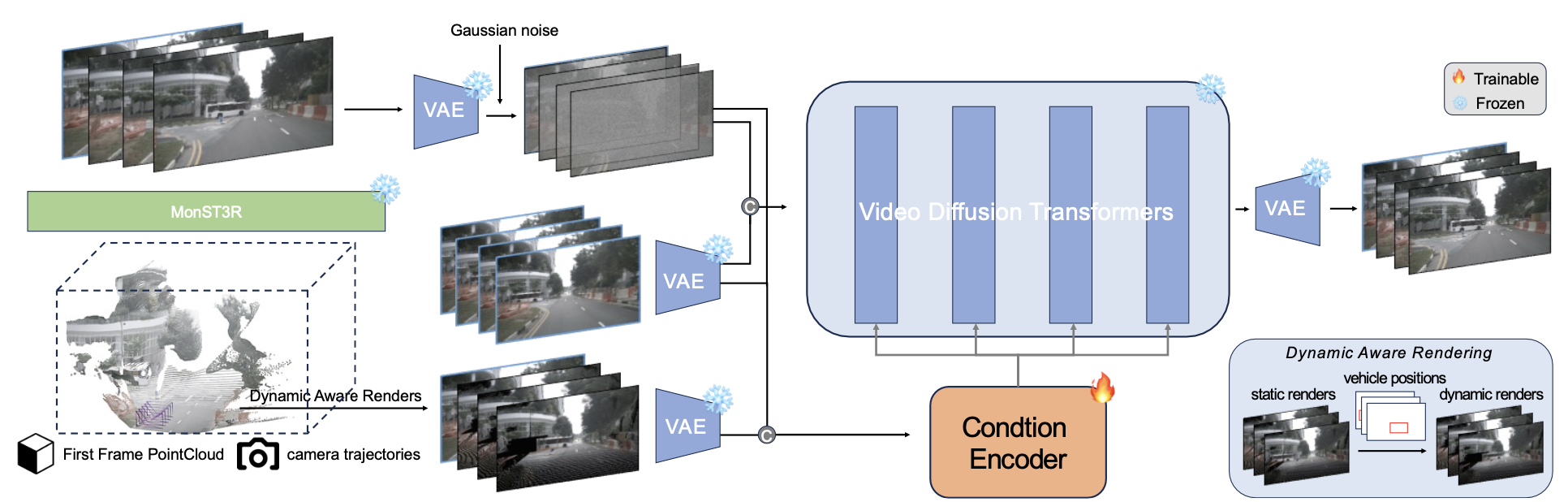
從參考圖像中提取 3D 表示
為了利用 3D 信息進行 3D 一致性生成,首先從單幅輸入圖像 I_0 構建 3D 表示。采用 MonST3R [81],這是一個現成的密集立體視覺模型,可以同時預測 3D 幾何形狀和相機姿態,這與訓練范式一致。在推理過程中,復制參考圖像以滿足 MonST3R 的跨視圖匹配要求。
給定 RGB 幀 {I_t},MonST3R 通過跨幀跨視圖特征匹配來預測每像素 3D 坐標 {O_t} 和置信度得分 {D_t}。
將 D_0 設置為 τ(通常 τ = 0.65),第 t 個參考幀的彩色點云結果如下:
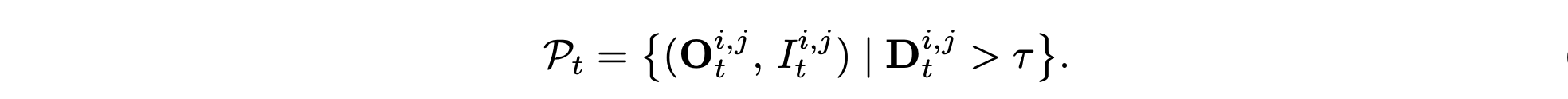
為了抵消序列中有效匹配和無效匹配之間的不平衡,用焦點損失來訓練置信度圖 D_0。此外,為了將靜態場景幾何與運動目標分離,MonST3R 采用基于 Transformer 的解耦器。該模塊處理參考幀的初始特征(跨視圖上下文進行豐富),并將其分離為靜態和動態部分。解耦器使用可學習的提示 token 來劃分注意圖:靜態 token 關注較大的平面,動態 token 關注緊湊且運動豐富的區域。通過排除動態對應關系,獲得穩健的相機姿態估計:
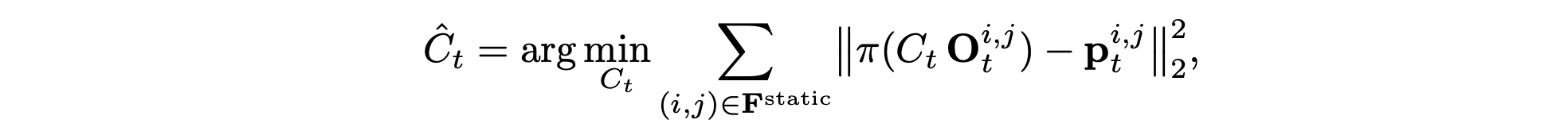
利用動態編輯渲染 3D 視頻
為了實現精確的輸入軌跡跟蹤,模型會渲染一段視頻,作為生成過程的視覺引導。用標準射影幾何技術,通過用戶提供的每個相機配置 C_t = (R_t, T_t, f_t) 將參考點云 P_0 投影。每個 3D 點 Pw_i ∈ P_0 經過剛性變換到相機坐標系 Pc_i = R_tPw_i +T_t,然后使用相機的內參矩陣 K_t 進行透視投影,得到圖像坐標 p_i。僅考慮 P_ic_z ∈ [0.1, 100.0 m] 深度范圍內的有效投影,并使用 z-緩沖處理遮擋,最終為每個相機位置生成渲染視圖 I ?_t。
靜態渲染的局限性。由于僅使用第一幀點云,渲染場景在整個序列中保持靜態。這與現實世界的自動駕駛環境存在顯著差異,因為在現實世界中,車輛和其他動態物體處于持續運動狀態。渲染的靜態特性未能捕捉到區分自動駕駛數據集和傳統靜態場景的動態本質。
動態編輯。為了解決這一局限性,提出動態編輯來生成具有靜態背景和移動車輛的渲染圖 R。具體而言,當用戶為場景中的移動車輛提供一系列二維邊框信息時,會動態調整它們的位置,從而在渲染圖中營造出運動的視覺效果。這種方法不僅可以在生成過程中引導自身車輛的軌跡,還可以引導場景中其他車輛的移動。如圖展示此過程。這種設計顯著縮小靜態渲染與動態現實世界場景之間的差異,同時實現對其他車輛的靈活控制——這是 Vista [13] 和 GAIA [23] 等現有方法無法實現的功能。

雙-分支控制實現時空一致性
雖然基于點云的渲染能夠準確地保留視圖之間的幾何關系,但它存在一些視覺質量問題。渲染后的視圖通常包含大量遮擋、由于傳感器覆蓋范圍有限而導致的區域缺失,并且與真實相機圖像相比視覺保真度較低。為了提升質量,調整潛在視頻擴散模型 [5],以優化投影視圖,同時通過專門的調節來保持 3D 結構保真度。
在此基礎上,進一步改進將上下文特征集成到預訓練擴散Transformer (DiT) 中的方案,這借鑒 VideoPainter [2] 提出的方法。然而,根據自身特定需求引入關鍵的區別。采用動態渲染來捕捉時間和上下文的細微差別,從而為生成過程提供更具自適應性的表示。令 δ_φ(z_t, t, C) 表示修改后的 DiT 主干網絡 δ_φ 第 i 層的特征輸出,其中 z_R 表示通過 VAE 編碼器 E 的動態渲染潛特征,z_t 是時間步長 t 的噪聲潛特征。
這些渲染圖通過輕量級條件編碼器進行處理,該編碼器提取必要的背景線索,而無需復制主干架構的大量部分。將條件編碼器的特征集成到凍結的 DiT 中,其公式如下:
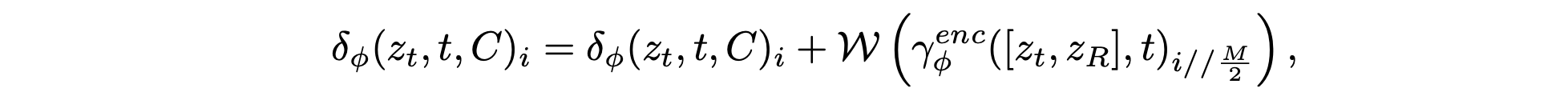
其中 γenc_φ 表示處理噪聲潛變量 z_t 的連接輸入和渲染潛變量 z_R 的條件編碼器,M 表示 DiT 主干網中的總層數。W 是一個可學習的線性變換,初始化為零,以防止早期訓練中的噪聲崩潰。提取的特征以結構化的方式選擇性地融合到凍結的 DiT 中,確保只有相關的上下文信息引導生成過程。最終的視頻序列通過凍結的 VAE 解碼器 D 解碼為 I?_t = D(z(0)_t)。
通過將訓練限制在條件編碼器 g_φ(占總參數的 6%),保持預訓練模型的照片級真實感,并獲得精確的相機控制。時間相干性自然地源于視頻 Transformer 的動態建模以及跨幀 {I ?_t} 特征的幾何一致性,從而實現忠實軌跡的視頻合成。
訓練配置。僅在 nuScenes [7] 上進行訓練,通過 MonST3R 處理每個片段,以獲得公制尺度的 3D 重建和攝像機軌跡。初始幀 P_0 的 3D 重建通過可微分光柵化器沿估計的軌跡進行投影渲染,其中動態編輯利用 2D 邊框注釋來編輯車輛位置。整理 25,109 個視頻-條件對用于訓練。凍結基礎擴散模型 (CogVideo-5B-I2V [22]),同時以 1 × 10?5 的學習率對條件編碼器進行 28,000 步訓練,持續 4 天。
基準和基線方法。將 GeoDrive 與兩個最相關的基線模型(Vista[13]、Terra[1])以及其他幾個駕駛世界模型進行了比較,這幾個基線模型以單幅圖像和自我動作為條件。遵循 Vista 的協議,從跨越 25 幀剪輯的傳感器和標定數據中計算軌跡,作為它們的條件輸入。通過在 GT 視頻上運行 MonST3R 來估計條件相機姿勢。雖然以不同的模態為條件,但所有方法的軌跡都是從同一個真值視頻剪輯中提取的,以確保動作條件一致。在 NuScenes 驗證集上評估所有方法。為了評估軌跡控制精度,從 1087 個具有平衡駕駛軌跡的視頻子集進行采樣。視覺質量通過 PSNR、SSIM[63]、LPIPS[29]、FID[20]和 FVD[57]進行量化。而軌跡保真度指標采用平均位移誤差(ADE)和最終位移誤差(FDE)。
將 GeoDrive 與場景重建方法 StreetGaussians [73] 進行比較。在 Waymo 驗證集上進行評估,并篩選出 5 個場景進行測試。新軌跡是通過水平移動前置攝像頭的原始軌跡生成的。由于新軌跡沒有真實值,用 FID 和 FVD 來評估生成質量。









 大數據概述)




![[特殊字符] FFmpeg 學習筆記](http://pic.xiahunao.cn/[特殊字符] FFmpeg 學習筆記)




