作者:來自 Elastic?Adel Wu
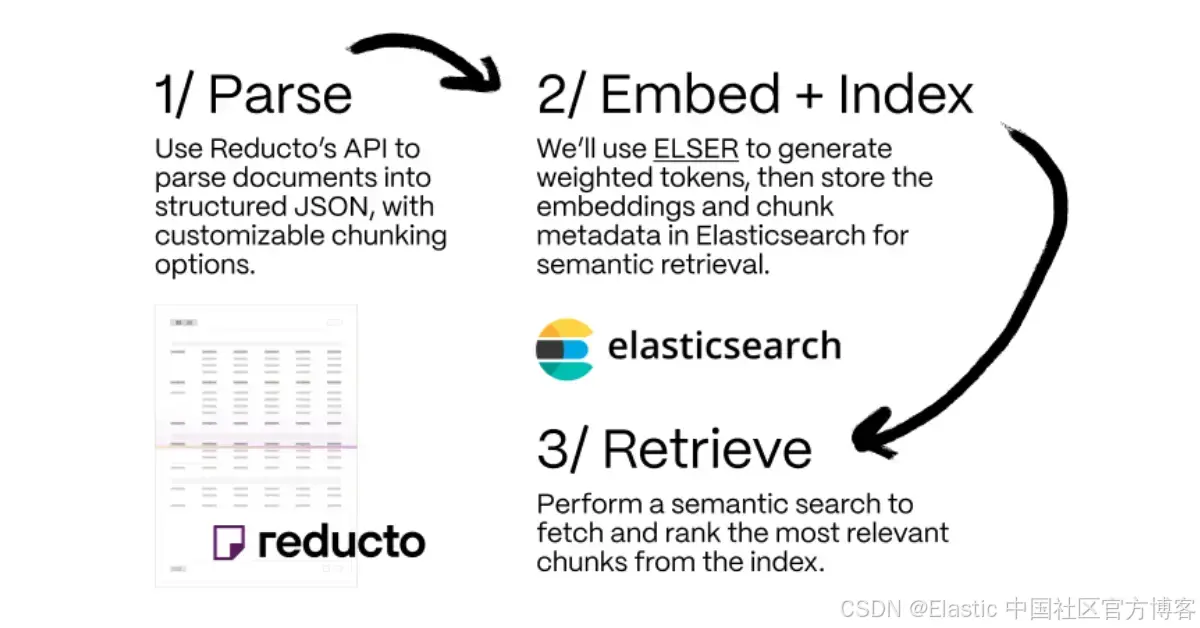
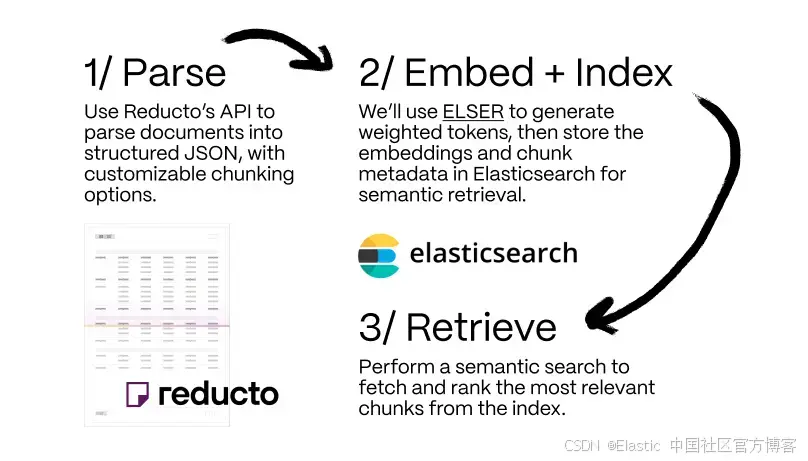
演示如何將 Reducto 的文檔處理與 Elasticsearch 集成以實現語義搜索。
Elasticsearch 與業界領先的生成式 AI 工具和提供商有原生集成。歡迎觀看我們的網絡研討會,了解如何超越 RAG 基礎,或使用 Elastic 向量數據庫構建可投入生產的應用。
為了為你的使用場景構建最佳搜索解決方案,現在就開始免費的云試用,或在本地機器上體驗 Elastic。
解析是大多數 RAG 流水線中的瓶頸。掃描版 PDF 和電子表格通常非常混亂,輸入質量差會導致檢索不完整、幻覺以及結果不穩定。企業知識中近 80%** 被困在這些格式中,而傳統 OCR 會破壞結構和語義。
解決這一挑戰需要先進的解析技術,結合傳統 OCR 和視覺語言模型(vision-language models -? VLMs )來理解文檔布局和內容,并生成結構化、適用于 LLM 的內容塊。本文將探討這種混合方法,并演示如何將 Reducto 的文檔解析 API 與 Elasticsearch 集成以實現語義搜索。
解析為何仍是巨大挑戰
傳統的 OCR 和基礎文本提取方法只能生成文檔的 “扁平” 視圖。這可能適用于復制粘貼,但對于搜索來說是災難性的。
想象一下把一份財務報告或復雜表單扁平化成一串純文本:
-
表格、標題、腳注和正文之間的關系被抹去
-
關于布局、重要性和層級的上下文線索丟失
-
基于向量或關鍵詞的檢索系統失去了有效的信號
Reducto 沒有沿用 “先 OCR 一切 → 再導入 Elastic” 的傳統流程,而是設計了一種新方法:保留現實文檔中的結構、上下文和語義。
Reducto 的 “視覺優先” 方法
Reducto 的 parsing?API 不再把文檔僅僅當作文本,而是作為具有上下文意義的視覺對象來處理。
我們的解析流程結合了:
-
傳統 OCR:字符級別的高精度文本提取
-
視覺語言模型(Vision-Language Models?- VLMs ):對視覺上下文的深度理解,例如表格、多欄布局、嵌入式表單等
Reducto 的混合方法在基準測試中相比傳統純文本解析器帶來了顯著提升(例如,在 RD-TableBench 這類開源表格解析基準數據集上,一些實現表現提升超過 20 個百分點)。
通過同時分析文檔的內容和視覺結構,Reducto 可生成:
-
精準的邊界框(頁面上某個元素的坐標,用于引用)
-
每個區塊的分段布局類型(標題、表格、文本、圖形等)
-
可自定義的 LLM 就緒內容塊
最終解析結果完整保留了原始文檔的豐富信息,適用于需要拆分與上下文嵌入的檢索流程。

引入 Agentic OCR:多輪自我糾錯
即使是最好的模型,也難免會出現解析錯誤。復雜的掃描件、手寫筆記或多層嵌套表格可能會讓一次性解析器失效。
為了解決這個問題,我們引入了 Agentic OCR ——一個多輪自我糾錯框架。
可以把它看作是一個 “人類參與” 的過程 —— 只是無需人工。該方法大幅提升了真實環境下的穩健性,確保即使是復雜、從未見過的文檔也能被清晰準確地解析。
示例:將 Reducto API 與 Elasticsearch 一起使用
解析不是最終目標,搜索才是。
Reducto 的客戶經常將解析后的輸出直接集成到 Elasticsearch 中,用于內部知識庫、智能文檔檢索或檢索增強生成(retrieval-augmented generation -? RAG )系統。
以下是一個高級概覽:
- 解析:使用 Reducto 的 API 將文檔解析為結構化的 JSON,可自定義分塊選項。
- 嵌入 + 索引:我們將在本例中使用 ELSER,這是一種內置于 Elasticsearch 的稀疏檢索模型,可以非常輕松地執行語義搜索,用于生成加權的 tokens。我們會將嵌入向量和分塊元數據存儲到 Elasticsearch 中以實現語義檢索。
- 檢索:給定一個查詢,從索引中獲取最相關的分塊。
如果你有興趣進一步了解稀疏向量以及為什么它們是語義搜索的優秀選擇,請閱讀這篇博客了解更多信息。
🧾 1. 使用 Reducto(通過 API)進行解析和分塊
要獲取 Reducto 的 API 密鑰,請前往 reducto.ai 并點擊 “Contact us”。我們會安排一次簡短的入職電話,了解你的使用場景,并為你設置一個試用密鑰。
安裝我們的 Python SDK —— 與我們 API 交互的最簡單方式。
pip install reductoai然后,調用我們的解析函數。這里有一些與分塊相關的配置需要注意:
- options.chunk_mode:選擇你希望如何配置分塊。例如,按頁、按塊、按變量(字符長度)等。
- options.chunk_size:你希望分塊的字符長度大約是多少。默認是 250-1500 個字符。
我們建議 RAG 用例保持 Reducto 默認的 “variable” 分塊模式,因為它在捕獲和分組最語義相關的數據方面最靈活。使用默認值時,調用中無需設置特定配置。
更多可配置項請參考 Reducto 的 API 文檔中 Parse 端點的說明。你也可以試用我們的 UI 體驗區,查看 “Configure Options” 下的所有選項。
from reducto import Reducto
from getpass import getpass# Parse documents using Reducto SDK
reducto_client = Reducto(api_key=getpass("REDUCTO_API_KEY"))
upload = reducto_client.upload(file=Path("sample_report.pdf"))
parsed = reducto_client.parse.run(
document_url=upload,
options={ # Optional configs would go here"chunking": {"chunk_mode": "variable","chunk_size": 1000,}}
)# Parsed output
print(f"Chunk count: {str(len(parsed.result.chunks))}")
print(parsed.result.chunks)使用我們提供的示例股票研究報告(鏈接在這里),解析后的輸出大致如下:
Chunk count: 32
ResultFullResultChunk(blocks=[ResultFullResultChunkBlock(bbox=BoundingBox(height=0.022095959595959596, left=0.08823529411764706, page=1, top=0.04671717171717172, width=0.22549019607843138, original_page=1), content='Goldman Stanley', type='Title', confidence='high', image_url=None), ...])📐 📦 2. 使用 ELSER 進行嵌入和索引
創建你的 Elastic Cloud Serverless 集群,或選擇你喜歡的部署方式。
安裝 Elasticsearch 的 Python 客戶端。
pip install elasticsearch初始化客戶端并連接到你的 Elasticsearch 實例。
from elasticsearch import Elasticsearch, exceptions# Create Elasticsearch Client
es_client = Elasticsearch(getpass("ELASTICSEARCH_ENDPOINT"),api_key=getpass("ELASTIC_API_KEY")
)print(es_client.info())創建用于生成嵌入向量的 ingest pipeline,使用 ELSER,并應用到我們的新索引中。
INDEX_NAME = "reducto_parsed_docs"# Drop index if exists
es_client.indices.delete(index=INDEX_NAME, ignore_unavailable=True)# Create the ingest pipeline with the inference processor
es_client.ingest.put_pipeline(id="ingest_elser",processors=[{"inference": {"model_id": ".elser-2-elasticsearch","input_output": {"input_field": "text","output_field": "text_semantic"}}}]
)print("Finished creating ingest pipeline")# Create mappings with sparse_vector for ELSER
es_client.indices.create(index=INDEX_NAME, body={"settings": {"index": {"default_pipeline": "ingest_elser"}},"mappings": {"properties": {"text": { "type": "text" },"text_semantic": { "type": "sparse_vector" }}}
})print("Finished creating index")將每個 Reducto 分塊索引到 Elasticsearch 中,Elastic Inference Service 會通過 ingest pipeline 生成嵌入向量。
# Index each chunk
for i, chunk in enumerate(parsed.result.chunks):doc = {"text": chunk.embed}es_client.index(index=INDEX_NAME, id=f"chunk-{i}", document=doc)🔍 3. 檢索
使用推理服務執行稀疏向量查詢,為查詢生成嵌入向量。該查詢由 ELSER 構建的稀疏向量組成。
# Use semantic text search
response = es_client.search(index=INDEX_NAME,query={"sparse_vector":{"field": "text_semantic","inference_id": ".elser-2-elasticsearch","query": "What was the client revenue last year?"}}
)# Print results
for hit in response["hits"]["hits"]:print(f"Score: {hit['_score']:.4f}")print(f"Text: {hit['_source']['text'][:300]}...\n")print(f"ELSER Embedding: {hit['_source']['text_semantic']}...\n")當查詢我們示例股票研究報告的分塊時,結果可能如下,包含余弦相似度分數和對應的分塊內容:
Score: 13.0095
Text: # Operations (cont.)Figure 2 - Jazz Historical and Projected Revenue Mix by Product...ELSER Embedding: {'studio': 0.5506277, 'copyright': 0.29489025, 'def': 1.0905615, ... }Score: 12.0828
Text: # Jazz Pharmaceuticals (JAZZ) (cont.)## Strong Q1 FY14 & Multiple Catalysts Ahead (cont.)...ELSER Embedding: {'##arm': 0.12544458, 'def': 1.4090042, '##e': 0.48080343, ... }
.
.
.
Elasticsearch 是領先的向量數據庫,為 AI 應用提供大規模性能。它在處理龐大嵌入數據集方面尤為強大,得益于其分布式架構和將向量相似度與關鍵詞相關性結合的混合搜索質量。Reducto 通過提供結構化、適合 LLM 的分塊,補充了 Elastic 的能力,確保 Elasticsearch 強大的索引和搜索檢索在最高質量的輸入上運行,從而帶來更優的 AI 代理性能和更準確的生成結果。
結論
企業多年來一直基于不完整或扁平化的文檔數據構建搜索系統——現在,新技術正出現以挖掘這些信息的更深層見解。Reducto 的 API 適合各行各業的公司,尤其是那些需要高準確性的領域,如金融、醫療和法律。
Reducto 的以視覺為先、由代理驅動的解析管道提供了前進的方向:
- 保持上下文、結構和意義
- 向像 Elasticsearch 這樣的向量存儲和檢索系統輸入更豐富、更準確的數據
- 實現更可靠、無幻覺的 RAG 和搜索體驗
你可以在 Reducto Playground 體驗 Reducto,或聯系了解完整集成方案。如果你想構建此應用并操作代碼,可以在這個 notebook 中找到說明。
有了 Reducto 和 Elasticsearch 向量數據庫,企業知識變得可搜索且易理解。
來源:Possibilities and limitations, of unstructured data - Research World
原文:Making sense of unstructured documents: Using Reducto parsing with Elasticsearch - Elasticsearch Labs



)




)










)