目錄
一、背景知識
為什么要在本地部署大模型?
在本地部署大模型需要做哪些準備工作?
(1)硬件配置
(2)軟件環境
有哪些部署工具可供選擇?
二、Ollma安裝
Ollama安裝完之后,還需要進行環境變量的配置
配置完環境變量后,就可以從Ollama上下載模型到本地了
接上一篇(非科班大模型工程師進階日記(〇)),這次我們來試試本地部署一個大模型。
開門見山,要想在本地部署自己的大模型,大致可以分以下幾步:
- 下載Ollama,通過Ollama將DeepSeek模型下載到本地運行;
- 下載RAGflow源代碼和Docker,通過Docker來本地部署RAGflow;
- 在RAGflow中構建個人知識庫并實現基于個人知識庫的對話問答。
But,光了解操作步驟是不夠的,下面我們先從背景知識開始進行一些簡單的介紹。
一、背景知識
注:不了解以下背景知識并不會對后續的安裝部署產生決定性影響,但是授人以魚不如授人以漁,大家各取所需就好。
為什么要在本地部署大模型?
本地部署的核心價值在于自主性與安全性,尤其適合對數據隱私、響應速度或定制化有高需求的場景:
-
數據主權保障
-
敏感數據(如企業文檔、個人隱私)無需上傳云端,避免第三方泄露風險。例如揚州環境監測中心部署DeepSeek-R1,就是因環境數據涉及國家安全,必須本地處理5。
-
-
性能與響應優化
-
本地推理消除網絡延遲,實現毫秒級響應(如實時數據分析、邊緣計算場景)16。
-
-
長期成本可控
-
云端模型按Token計費,高頻使用成本高昂;本地部署一次性投入硬件,后續近乎零成本67。
-
-
高度定制化能力
-
支持模型微調(如LoRA、P-Tuning)、知識庫集成(上傳私有文檔訓練),突破公版模型的功能限制18。
-
💡?典型場景:企業機密數據處理、離線環境應用(野外監測)、個性化AI助手開發。
在本地部署大模型需要做哪些準備工作?
(1)硬件配置
根據模型規模選擇硬件,顯存是關鍵瓶頸:
| 模型規模 | 最低配置 | 推薦配置 | 適用工具 |
|---|---|---|---|
| 7B參數 | 16GB內存 + RTX 3060 (6GB) | 32GB內存 + RTX 3070 (8GB) | Ollama, LM Studio |
| 13B參數 | 32GB內存 + RTX 3090 (24GB) | 64GB內存 + 雙RTX 4090 | vLLM, LLaMA.cpp |
| 70B參數 | 64GB內存 + 多A100顯卡 | 服務器級CPU+128GB內存+8×A100 GPU | vLLM(企業級)37 |
???注意:若無獨立顯卡,可用CPU+大內存運行量化模型(但速度顯著下降)。
(2)軟件環境
-
操作系統:Linux(最佳兼容性)、Windows/MacOS
-
基礎依賴:
-
Python 3.8+、CUDA工具包(NVIDIA顯卡必需)
-
深度學習框架:PyTorch或TensorFlow6
-
-
虛擬環境:建議用Conda隔離依賴(避免版本沖突)
有哪些部署工具可供選擇?
在進行大模型本地部署時,需要根據自己的技術背景和需求,選擇合適工具。
| 工具 | 特點 | 適用場景 | 安裝復雜度 |
|---|---|---|---|
| Ollama | 命令行操作,一鍵運行模型,支持多平臺 | 快速體驗、輕量測試 | ? |
| LM Studio | 圖形界面,可視化下載/運行模型(Hugging Face集成) | 非技術用戶、隱私敏感場景 | ?? |
| vLLM | 高性能推理框架,支持分布式部署、API服務化 | 企業級高并發需求 | ???? |
| LLaMA.cpp | CPU/GPU通用,資源占用低(C++編寫) | 老舊硬件或低顯存設備 | ??? |
| GPT4All | 開源輕量化,自動調用GPU加速 | 個人開發者、跨平臺應用 | ?? |
示例:Ollama部署DeepSeek-R1(適合新手,也是本次教程的選用方案)
# 安裝Ollama(Linux一鍵命令)
curl -fsSL https://ollama.com/install.sh | sh# 運行7B參數模型
ollama run deepseek-r1:7bOK,了解完以上知識,開展下面的工作就不會云里霧里,知其然而不知其所以然了。
二、Ollma安裝
Ollama是一個用于本地運行和管理大語言模型(LLM)的工具。
Ollama的安裝,直接上官網Download即可,不放心的可以看這篇教程:Ollama 安裝。
Ollama安裝完之后,還需要進行環境變量的配置:
(必選)OLLAMA_HOST - 0.0.0.0:11434
- 作用:默認條件下,Ollma只能通過本機訪問,但出于便捷性考慮,我們這次部署是通過Docker進行,配置這一環境變量就是為了讓虛擬機里的RAGFlow能夠訪問到本機上的 Ollama;(具體原理參見:配置Ollama環境變量,實現遠程訪問)
- 如果配置后虛擬機無法訪問,可能是你的本機防火墻攔截了端口11434;
- 不想直接暴露 11434 端口則可通過SSH 端口轉發來實現虛擬機訪問。
(可選)OLLAMA_MODELS - 自定義位置
- 作用:Ollama 默認會把模型下載到C盤,如果希望下載到其他盤需要進行這一配置。
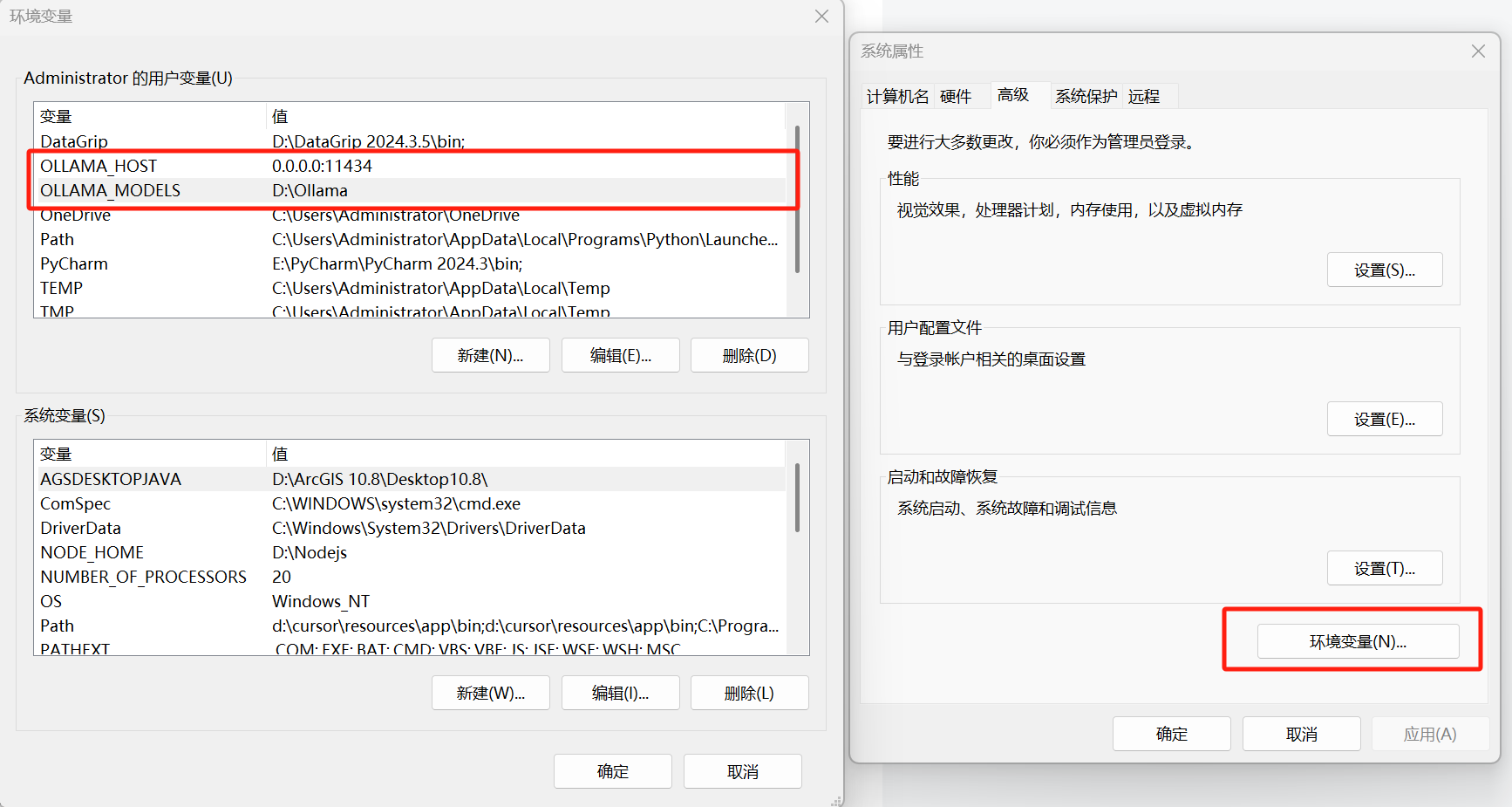
更新完兩個環境變量記得重啟,不然無法立即生效。
配置完環境變量后,就可以從Ollama上下載模型到本地了:
這次我們以Deepseek-R1:8b為例,需要注意的是,模型越大對本地機器配置要求越高,一般來說deepseek 32b就能達到不錯的效果,更高的不一定能跑的起來。
?配置及模型選擇可參考:個人用戶進行LLMs本地部署前如何自查和篩選
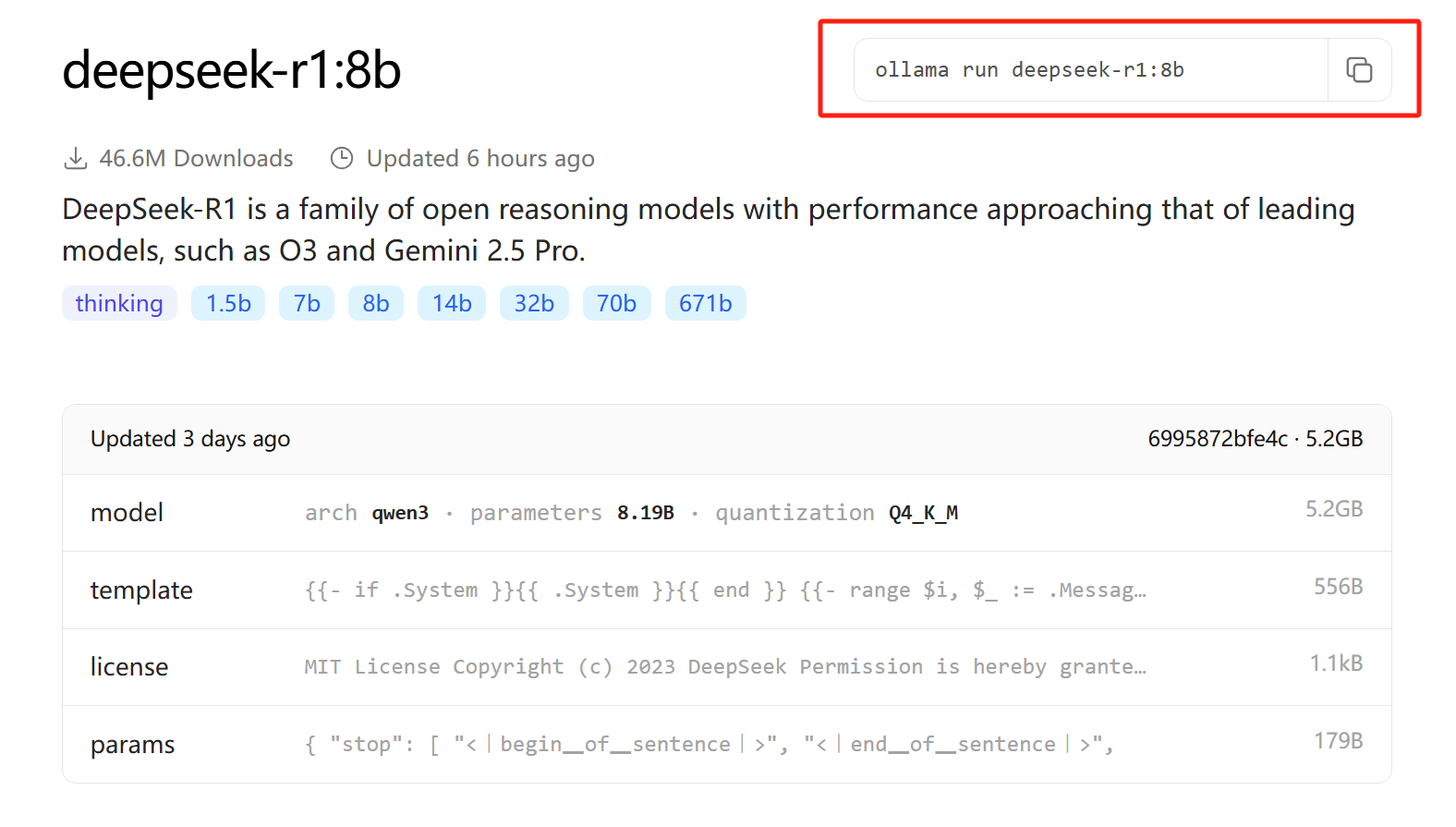
下載方式就是復制Ollama官網提供的相應指令,通過電腦命令行進行下載(Windows+R、cmd)
ollama run deepseek-r1:8b下載完成后,可以直接在命令行窗口進行問答,至此,你就成功完成了大模型的本地化部署!
Congrats!
本地化部署雖然是很簡單的一步,卻為未來打開了更多可能性。但是,做到這里還不算完全擁有了自己的大模型,下一篇我會講如何結合RAGFlow來構建自己的本地知識庫,從而讓DeepSeek更懂你的需求。
祝大家玩兒的開心!
See you next time!:)
















--- AOP、ThreadLocal)


