性能是個宏大而駁雜話題,從代碼,到網絡,到實施,方方面面都會涉及到性能問題,網上對性能講解的文章多如牛毛,從原理到方法再到工具都有詳細的介紹,本文雖不能免俗,但期望能從另外一個角度來觀察性能:站在硬件的角度看待軟件性能。
要探討高性能,首先要明確一下,什么是高性能? 是每秒過億的QPS?還是每秒數G的數據傳輸?這些當然都是高性能的量化指標,但我想再更本質得明確一下高性能的含義,其核心訴求點在于:將硬件資源利用到核心的業務邏輯上,展開來講:
- 資源利用率:程序能充分的利用硬件資源,到達得性能上限應該是硬件上限而非軟件上限。
- 資源能效:完成相同的工作使用更少的資源,硬件資源使用在核心業務邏輯上。
那么如何實現高性能?
軟件行業常有一個傳言:過早的性能優化是萬惡之源。但我想應該額外再補充一句:早期的性能考慮是高效之基。應該在編寫第一行代碼之前就想好怎么樣的設計是高性能,而非等到功能完善之后再回頭進行優化。心中時刻謹記高性能,在每個細節處都精益求精,才能真正的實現高性能。前期不管不顧,后期再性能優化面臨幾個問題:
- 有些程序結構不合理導致的性能問題變更起來牽連甚廣,修改成本太高,不優化又不行
- 沒有集中的性能問題,各處邏輯時間消耗不長也不短,最終性能不低也不高,卻無處著手
這里分別從不同的硬件出發,來探討如何壓榨硬件資源,追求極致性能,本篇文章是第一篇,CPU篇。
CPU構造
現代CPU架構是一個高度復雜且多層次優化的系統,其設計核心目標是 最大化計算效率 和 資源利用率 。可以簡單的概括其幾個特性:
- 多核設計:現代CPU通常包含多個物理核心,每個核心可以獨立的執行指令。單個物理核心通過虛擬化技術模擬多個邏輯核心,共享核心的運算單元和緩存,實現超線程。
- 指令流水線:將指令執行拆分為多個階段(取指,解碼。執行,訪存,寫回), 各個階段可以并行工作,以提升吞吐量,數據依賴或分支預測失敗會導致流水線停滯
- 多級緩存:L1緩存分指令緩存(L1i)和數據緩存(L1d),每個核心獨享,延遲1-3周期。L2緩存:核心獨享或共享,延遲約10周期。L3緩存:多核心共享,延遲約30-50周期。多層緩存逐級擴大。通過標記緩存行的狀態,確保多核間數據一致性,避免臟讀。
這是一個簡單的多級緩存多核CPU架構圖

有了這些簡單的CPU知識,我們就可以進一步討論如何充分得利用CPU的這些特性以實現高性能。
有效利用多核性能
大家知道現代操作系統調度CPU時間片的單位是線程,所以想充分利用多核特性,就要開啟多個線程。
每個線程在Linux系統中都被封裝為一個task,每個task包含了自己的堆棧,cpu執行寄存器的上下文(這是線程能夠被搶占切換調度的關鍵),以及一些其他信息。從原理上講,應該使用和CPU核心數量相當的線程數量,但由于應用程序和CPU之間并非直接的使用關系,中間還有一層調度層,即操作系統。操作系統內核也會有自己的執行進程。所以早期Windows核心編程書中推薦使用cpu核心數*2的線程配置。但不論怎么設置線程數量,都不宜過多或者過少。操作系統需要保證公平且高效的調度讓所有線程都有機會在CPU上得到執行,但線程有CPU密集的計算邏輯,也有和外部設備進行數據通信的IO邏輯,如何給不同的線程分配CPU呢?這又是一套很復雜的算法,簡單來歸納:CPU密集的線程被調度的次數少,但是執行的時間片長,IO密集型的線程被調度的次數多,但是執行的時間片短。開的線程越多,那么操作系統執行算法需要調度的對象就越多。開的線程太少,則無法有效利用多核特性,自不待言。
操作系統是如何測量線程到底是IO密集還是CPU密集的呢?答案是:操作系統并不能明確的知道。因為IO密集和CPU密集并不是絕對屬性,CPU計算的過程中可能會發生IO, 而IO的過程中也會有CPU計算,操作系統只能根據一些操作統計來推斷線程行為。這導致一個問題,當一個線程阻塞在一個IO操作上,比如阻塞的向一個socket發送數據,我們知道這個調用send的過程可能很短,只是把用戶態的內存拷貝進內核態的緩存中,也可能很長,需要等待內核協議棧將內核緩存的數據發送,留出足夠的空閑以容納新發送的數據。站在應用程序的角度看,就是send發送阻塞了線程的執行。這個阻塞的過程,操作系統是知道的,其會將線程標記為block狀態之后讓出CPU,問題是操作系統什么時候知道了send已經完成,需要將這個線程切回到CPU上繼續執行呢?這需要硬件觸發中斷來再次觸發操作系統的調度邏輯,如果只是簡單的調用阻塞的IO接口,那么什么時候切換回CPU執行只能依賴于操作系統的調度策略,時間可長可斷,但并不會是一個高效的時機。如果要充分提升CPU的使用率,就要避免使用阻塞式的系統調用,現代操作系統一般都提供了異步響應式的編程接口,將在到另外一篇文章中討論。
總的來說,開多少個線程合適并不是一個簡單的問題,要結合自己的硬件水平,執行邏輯等多方面因素,因地制宜的綜合決策。
有效利用緩存
CPU和主存之間每次交換數據需要近百的CPU時間,如果每次數據交互都需要直接訪問主存,CPU大多數時間都將消耗在數據等待上。CPU提供的三層緩存機制:第一級最接近CPU核心,訪問速度最快,之后每級速度遞減,一二級緩存通常單個核心獨享,三級緩存多個核心共享,其內部也有自己的數據一致性算法。感興趣的讀者可以自行搜索,本文不再討論。
每個線程在CPU看來,無非是一堆數據以及對應的計算指令,想要提升緩存的利用率,其實和常規的編程過程是一樣的:提升緩存命中率,降低緩存miss。不同的點在于平常的內存操作是顯式的,我們明確的知道哪里訪問了緩存,哪里發生了miss,CPU的緩存命中與否,并沒有那么直觀。CPU每次進行緩存交換的單位,稱為cache line,每個cache line通常為64字節。從編程的角度出發,可以通過以下措施提升緩存的命中率:
- 避免頻繁的線程切換。每個線程都有自己的運行上下文,對CPU來講就是不同的數據和指令,所以每次在CPU上切換線程,之前緩存的其他線程數據大概率會失效,進而導致需要重新從低訪問速度的緩存或者內存中加載數據。現代操作系統都提供了API來實現線程和CPU核心的綁定,支持一個線程一直都被調度到一個CPU核心上,從而提升一二級緩存的命中率。
- 盡量訪問內存相鄰的數據,以提高cache line的數據使用率,減少緩存數據交換次數。比如我們有個二維數據:
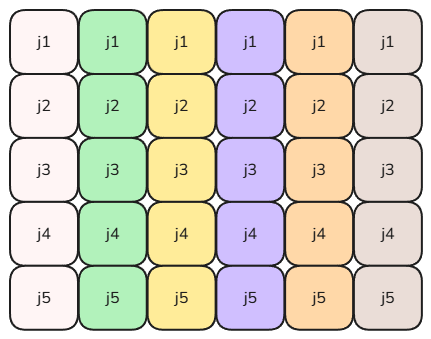
縱向的不同顏色的列表示內存連續的第二維數組,很常見的數據結構。遍歷這個二維數組,當橫向遍歷時,每次訪問的都是不連續的內存,當 j 的序列超過一個cache line的時候,意味著每次訪問都需要加載一個新的cache line才能讀取到新的數據。當縱向的遍歷時,每次訪問的內存位置是連續的,所以一個cache line上大部分數據都會被利用到。雖然在代碼層面來看無論怎么遍歷結果都是相同的,但對CPU來講,縱向的遍歷能顯著的減少cache line的交換次數,可以大幅提升CPU的吞吐量。
- 避免局部數據的多線程訪問。我們都知道多個線程讀寫相同的變量會導致內存競爭問題,需要進行加鎖。那我們在不同線程訪問相鄰的變量時會發生什么?
struct Data { int32_t param_a_;int32_t param_b_;
};當兩個線程分別讀寫這個結構體的param_a_,param_b_,由于cache line是64字節,而CPU更新緩存的單位只有cache line。所以當A線程訪問param_a_時,可能會將param_b_也一并加載,線程B訪問param_b_也是相同的道理,當CPU的某個核心修改了cache line的數據,而這個cache line又被其他核心訪問,為了防止數據不一致的情況,CPU會將這個cache line失效,以加載最新的數據,這會導致大量的cache line交換。為了避免這種情況的發生,我們需要用一些編程技巧來進行CPU的數據訪問隔離。可以使用內存對齊,將不同線程訪問的變量按照64字節對齊。或者使用thread local store來降低線程間的數據競爭,當然這會比中心式的數據維護要復雜很多。
提升分支預測準確度
結構化編程最常見的編程結構便是分支控制,我們的代碼中充斥的大量的if else,平時編程的時候多一個少一個,怎么排布順序對程序功能來說無傷大雅。但站在CPU的角度上看,由于分支預測失效會導致數十乃至數百CPU時鐘的停頓,提升分支預測的準確性就可以有效的提升CPU的指令執行效率。
好在我們依然可以使用一些簡單的編程策略來提升分支準確度:
- 減少代碼的判斷分支,合并條件判斷。這是最直觀的降低分支預測的失敗的方法。
- 優化分支模式,使分支判斷具有局部性。比如遍歷一個整數數組,偶數執行A操作,奇數執行B操作,如果數據按照先偶數再奇數的方式排列,就可以有效提升分支預測準確度
- 優先處理高頻路徑,將最可能執行的分支判斷放到最上方
- 避免使用復雜的分支判斷,將大量的if else通過查找表實現。
性能優化是個博大精深的問題,本文從CPU的角度出發,介紹了一些性能優化的知識,但知距離全面詳實還差的很遠。本篇也作為性能問題的一個開篇,之后計劃再介紹一下IO的性能優化手段。
Finally, 期望本文能對大家有所啟發,你還知道什么特別的CPU利用率的優化知識,也歡迎交流討論。
![[SC]SystemC在CPU/GPU驗證中的應用(三)](http://pic.xiahunao.cn/[SC]SystemC在CPU/GPU驗證中的應用(三))

-14)
Unity 物理系統之范圍檢測)










 變換圖像與形態學操作)




