一、docker與k8s
一、Docker 核心解析
1.?Docker 定義與架構
本質:
- 容器化平臺(構建容器化應用)、進程管理軟件(守護進程管理容器生命周期)。
- 客戶端(
docker cli)與服務端(docker server)通過 Unix 套接字通信,本機客戶端可直接管理容器。核心功能:
- 應用打包:鏡像(Image)包含應用 + 依賴,解決?環境一致性(“一次構建,處處運行”)。
- 進程隔離:通過 Namespace(網絡、PID 等)和 Cgroups(資源限制)實現容器級隔離,確保進程(容器)間互不干擾。
- Swarm 集群:
- 多節點部署(
swarm init/join)、服務伸縮(docker service scale)、負載均衡(Ingress 網絡)。- 配置與密鑰管理(
configs/secrets),支持集群化部署與安全管控。技術邊界:
- 單進程原則:容器內?僅運行一個主進程(如 Web 服務),復雜場景需 Sidecar 容器(如日志代理)輔助。
- 非 GUI 環境:不支持容器內運行帶 GUI 的開發環境(如 IDE),專注于運行時(Runtime)管理。
2.?Docker Swarm 與 K8s 的對比(為何需要 K8s)
?
特性 Docker Swarm K8s(Kubernetes) 生態兼容性 僅支持 Docker 容器(原生生態) 兼容所有 CRI 運行時(如 containerd、CRI-O) 復雜度與規模 輕量,適合小規模集群 復雜,支持大規模高可用場景(多租戶、跨云) 資源類型 少(無 CSI 存儲擴展) 豐富(CRD 擴展,支持 GPU、存儲類等) 配置管理 手動維護部署指令(無自動同步) 聲明式配置(YAML + etcd 自動同步狀態) 多租戶支持 弱(無命名空間隔離) 強(命名空間 + 資源配額精細管控) 擴展性 擴展能力有限(依賴 Docker 生態) 高度可擴展(CRD、Operator 模式,自定義資源) 總結:
?
- Swarm 適合?Docker 生態內的簡單集群(如小規模微服務),但缺乏標準化擴展(如 CSI 存儲)。
- K8s 通過?CRI/CSI 標準化?和?CRD 擴展性,成為?云原生時代的主流編排平臺(支持復雜多集群、混合云場景)。
二、K8s(Kubernetes)核心解析(基于圖片內容)
1.?定義與架構
本質:
分布式容器編排與服務管理平臺,不負責容器化(依賴 Docker 等 CRI 運行時),專注?容器生命周期管理(部署、伸縮、故障恢復)。核心組件:
- Master 節點:
- 調度器(Scheduler):分配 Pod 到 Worker 節點。
- API Server:集群控制入口(接收 REST 請求,管理資源狀態)。
- etcd:分布式鍵值存儲,持久化集群狀態(如 Pod 期望副本數)。
- Worker 節點:
- Kubelet:管理節點上的容器(與 API Server 交互,確保 Pod 狀態)。
- Kube-proxy:網絡代理(實現 Service 負載均衡,維護 Pod 網絡連接)。
核心功能:
- 彈性部署:
- 無狀態服務(Deployment,滾動更新)、有狀態服務(StatefulSet,有序部署)。
- HPA(水平自動伸縮):根據 CPU / 內存使用率動態調整 Pod 副本數。
- 服務治理:
- Service:將 Pod 暴露為網絡服務(ClusterIP 內部訪問,NodePort 外部訪問)。
- Ingress:七層負載均衡(HTTP 流量路由,支持 TLS 終止、路徑匹配)。
- 故障與資源管理:
- 自愈能力:Pod 崩潰自動重啟,節點故障時 Pod 遷移到其他節點。
- 資源配額(ResourceQuota):限制命名空間內的 CPU / 內存使用,避免資源爭搶。
- Sidecar 模式:
Pod 內多容器協同(如主應用 + 日志采集器),實現?非侵入式擴展(無需修改主應用代碼)。技術邊界:
- 無鏡像構建:僅管理已構建的鏡像,需 CI/CD 工具(如 Jenkins)配合生成鏡像。
- 非應用級隔離:不支持應用程序級別的內部服務隔離(如 MySQL 與 Kafka 中間件的資源隔離需通過 Namespace 或標簽)。
2.?K8s 重要概念
Pod:
最小調度單元,包含?共享網絡(同一 Pod 內容器可通過?localhost?通信)和存儲?的容器組。每個 Pod 含一個?Pause 容器(維持網絡命名空間)和業務容器(如 Web 服務 + Sidecar 代理)。控制器(Controller):
- Deployment:管理無狀態服務(滾動更新、回滾),確保 Pod 副本數符合期望(
replicas: 3)。- StatefulSet:管理有狀態服務(如數據庫),保證 Pod 唯一標識(
pod-name-0, pod-name-1)和有序部署。- DaemonSet:每個節點運行一個 Pod(如監控 Agent、日志收集器)。
Label 與 Selector:
- Label:鍵值對(如?
app=web, env=prod),用于分組資源(Pod、Node)。- Selector:通過 Label 篩選資源(如?
kubectl get pods -l app=web?篩選 Web 服務 Pod),實現靈活的服務發現與調度。3.?K8s 擴展場景
網絡擴展(CNI):
如 Calico(基于 BGP 的網絡策略,支持 Pod 間訪問控制)、Flannel(Overlay 網絡,跨節點通信),通過?CNI 插件?實現自定義網絡拓撲。存儲擴展(CSI):
如 NFS(共享存儲)、Ceph(分布式存儲),通過?CSI 插件?提供持久化存儲,支持?StorageClass?動態分配卷(如?volumeClaimTemplates?定義 PVC)。API 擴展(CRD/API Server):
- CRD(自定義資源定義):擴展 K8s API(如定義?
CustomApp?資源),適合內部工具(字段少、無需外部存儲)。- API Server 擴展:資源需存儲在外部(非 etcd)或需獨立 API 服務時,通過自定義 API Server 實現(如集成第三方服務管理)。
三、Docker 與 K8s 的協同關系(總結)
Docker 角色:
負責?容器化(鏡像構建、運行時隔離),是 K8s 的?運行時基礎(通過 CRI 接口與 K8s 集成,提供容器運行能力)。K8s 角色:
負責?集群級編排(部署、伸縮、治理),構建?云原生應用的運行時平臺,通過聲明式配置(YAML)和自動化控制器(如 Deployment),實現?彈性、高可用、可擴展?的應用部署。典型流水線:
開發(Dockerfile 構建鏡像) → 測試(Docker Compose 本地編排) → 部署(K8s 集群,通過 Helm 管理應用) → 運維(K8s 控制器自動修復故障,HPA 伸縮服務)。四、技術邊界與實踐建議
Docker 實踐:
- 本地開發用?Docker Compose?定義多容器依賴(如 Web + 數據庫),簡化環境搭建。
- 生產環境通過?Docker Swarm?或?K8s?實現集群化,根據規模選擇(小規模用 Swarm,大規模用 K8s)。
K8s 實踐:
- 基礎部署:掌握?Pod、Service、Deployment?定義,通過?
kubectl?管理資源。- 進階擴展:學習?CRD、Operator 模式,實現自定義資源管理(如數據庫備份自動化)。
- 生態集成:結合?Prometheus(監控)、Jaeger(鏈路追蹤)、ArgoCD(持續部署),構建完整云原生棧。
?二、docker網絡
1.?素材準備
1. dockerfile 定義
From alpine:3.18run apk add ethtoolrun apk add ipvsadmrun apk add iptables2. 鏡像構建
docker build -t myalpine .2.?網絡解決什么問題
1. 容器與外界通信
2. 容器間通訊,跨主機容器間通訊
3. 網絡隔離(容器網絡命名空間、子網隔離)
4. 提供網絡自定義能力
5. 提供容器間發現功能
6. 提供負載均衡能力
3. docker網絡命令
一、Docker 網絡核心命令
命令格式 描述說明 docker network connect將容器連接到指定網絡 docker network create創建新的 Docker 網絡 docker network disconnect將容器從網絡中斷開 docker network inspect查看網絡的詳細配置信息 docker network ls列出所有已創建的網絡 docker network prune移除所有未被使用的閑置網絡 docker network rm移除指定的一個或多個網絡 二、端口發布與映射操作
1. 端口發布語法
# 基礎格式:-p [主機地址:][主機端口]:容器端口[協議]# 案例1:將容器TCP端口80映射到主機8080端口 -p 8080:80# 案例2:將容器TCP端口80映射到指定IP的8080端口 -p 192.168.239.154:8080:80# 案例3:將容器UDP端口80映射到主機8080端口 -p 8080:80/udp# 案例4:同時映射TCP和UDP端口 -p 8080:80/tcp -p 8080:80/udp2. 實戰案例:發布 Nginx 服務端口
# 運行Nginx容器并映射8080端口 docker run -d --rm --name mynginx -p 8080:80 nginx:1.23.4# 驗證訪問(本地或遠程主機) curl http://localhost:8080 # 輸出:Nginx默認歡迎頁面內容三、容器 Hostname 修改配置
1. --hostname 選項修改容器主機名
# 運行容器時指定hostname(影響容器內/etc/hosts) docker run -d --rm --name mynginx1 -p 8081:80 --hostname mynginx1.0voice.com nginx:1.23.4# 驗證訪問 curl http://localhost:8081# 查看容器內hostname docker exec mynginx1 hostname # 輸出:mynginx1.0voice.com2. 查看容器 hosts 文件配置
# 查看容器內/etc/hosts映射 docker exec mynginx1 cat /etc/hosts # 輸出示例: # 127.0.0.1 localhost # ... # 172.17.0.2 mynginx1.0voice.com mynginx13. 容器內交互驗證 hostname
# 進入容器交互環境 docker exec -it mynginx1 bash# 在容器內驗證hostname hostname # 輸出:mynginx1.0voice.com# 退出容器 exit
?4. 網絡驅動
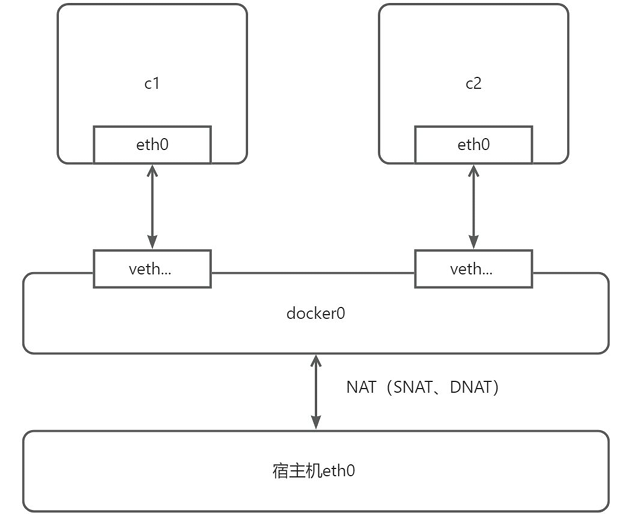
一、網橋(Bridge)基礎概念
網橋(Bridge)是 Docker 默認的網絡驅動程序。當未顯式指定網絡驅動時,所有新創建的網絡均為網橋類型。其核心作用是在同一臺主機的容器之間建立通信鏈路,同時隔離不同網橋網絡的容器。
1. 網橋的本質
- 鏈路層設備:網橋工作在 OSI 模型的鏈路層(二層),基于 MAC 地址轉發流量,實現網段間的通信。
- 軟件網橋:Docker 中的網橋是運行在宿主機內核的軟件設備(如默認的?
docker0?網橋),負責管理容器間的網絡連接與隔離。2. Docker 網橋的核心特性
- 容器通信:同一網橋下的容器可直接通信(無需顯式端口映射);不同網橋的容器無法直接通信。
- 默認網橋:安裝 Docker 后,會自動創建名為?
docker0?的默認網橋,新啟動的容器默認連接至此網絡(除非顯式指定其他網絡)。3. 虛擬網卡對(veth pair)
每個容器啟動時,Docker 會為其創建一對虛擬網卡(veth pair):
- 一端(如?
veth-xxxx)連接到虛擬網橋?docker0;- 另一端(如?
eth0)作為容器的 “內網網卡”,分配容器的 IP 地址(默認子網為?172.17.0.0/16,可通過?docker network inspect bridge?查看)。4. 容器 IP 與子網
默認網橋?
bridge(對應虛擬網橋?docker0)會為容器分配一個私有 IP(如?172.17.0.2、172.17.0.3?等),所有容器共享同一子網(如?172.17.0.0/16),形成一個局域網。
二、用戶自定義網橋 vs 默認網橋
Docker 支持兩種網橋類型:默認網橋(
docker0)和用戶自定義網橋(通過?docker network create?創建)。二者的核心區別如下:
特性 默認網橋(docker0) 用戶自定義網橋 DNS 解析 僅支持 IP 地址訪問,不支持容器名 / 別名 自動支持容器名 / 別名的 DNS 解析(通過 Docker 內置 DNS) 網絡隔離 所有未指定網絡的容器默認連接至此,隔離性差 需顯式指定容器加入,隔離性更可控 配置靈活性 配置(如子網、IP 范圍)需手動修改 Docker 配置文件,且需重啟 Docker 可通過? docker network create?命令靈活配置(子網、網關、IP 范圍等)容器間連接(ICC) 默認啟用(容器間可直接通信) 可通過選項? com.docker.network.bridge.enable_icc?控制是否啟用IP 偽裝(NAT) 默認啟用(容器可訪問外網) 可通過選項? com.docker.network.bridge.enable_ip_masquerade?控制是否啟用
三、網橋驅動的配置選項
使用?
?docker network create --driver bridge?創建網橋時,可通過?--opt?參數傳遞以下特定選項,精細控制網橋行為:
選項名稱 默認值 描述 com.docker.network.bridge.namedocker0(默認網橋)自定義網橋的 Linux 接口名稱(如? alpine-net1)。com.docker.network.bridge.enable_ip_masqueradetrue是否啟用 IP 偽裝(NAT):若啟用,容器可通過宿主機 IP 訪問外網;禁用則容器無法訪問外網。 com.docker.network.bridge.enable_icctrue是否啟用容器間連接(ICC):啟用時同一網橋的容器可直接通信;禁用則容器間無法通信(但仍可通過端口映射訪問)。 com.docker.network.bridge.host_binding_ipv40.0.0.0容器端口映射時的默認綁定 IP(如? 192.168.1.10)。com.docker.network.driver.mtu0(無限制)容器網絡的最大傳輸單元(MTU),默認與宿主機網絡 MTU 一致。 com.docker.network.container_iface_prefixeth容器內網絡接口的名稱前綴(如設置為? ethnick,則容器接口為?ethnick0)。
四、默認網橋網絡詳情
1. 默認網絡列表
安裝 Docker 后,默認創建三個網絡(可通過?
docker network ls?查看):、、docker network ls輸出示例
NETWORK ID NAME DRIVER SCOPE a1b2c3d4 bridge bridge local # 默認網橋(docker0) e5f6g7h8 host host local # 主機網絡(直接使用宿主機網絡) i9j0k1l2 none null local # 無網絡(容器隔離)2. 默認網橋(docker0)的關鍵參數
- 子網:默認子網為?
172.17.0.0/16(可通過?docker network inspect bridge?查看)。- 網橋名稱:Linux 接口名為?
docker0(通過?ip addr?或?brctl show?查看)。3. 宿主機網絡關聯
內核路由表:宿主機路由表中會添加一條規則,將?
172.17.0.0/16?網段的流量轉發到?docker0?網橋:route -n輸出示例(關鍵行):
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0iptables 規則:Docker 會自動配置 iptables 規則管理網絡流量,關鍵鏈如下:
FORWARD?鏈:默認策略為?DROP(丟棄所有轉發流量),僅允許 Docker 網橋相關的流量通過。DOCKER?鏈:處理容器的 NAT 規則(如端口映射)。DOCKER-USER?鏈:用戶自定義規則(可在此添加流量過濾策略)。DOCKER-ISOLATION-STAGE?鏈:實現容器網絡隔離(如不同網橋間的流量隔離)。4. 查看 iptables NAT 規則
通過以下命令查看 NAT 表的詳細規則
iptables -t nat -vnL關鍵規則解讀:
Chain POSTROUTING (policy ACCEPT 0 packets, 0 bytes)pkts bytes target prot opt in out source destination 0 0 MASQUERADE all -- * !docker0 172.17.0.0/16 0.0.0.0/0含義:對于源 IP 屬于?
172.17.0.0/16?網段、且不通過?docker0?接口輸出的流量,執行?MASQUERADE(動態 NAT),將源 IP 替換為宿主機公網 IP,實現容器訪問外網。
五、網橋網絡使用案例
案例 1:使用默認網橋網絡
目標:驗證默認網橋的容器通信與限制(僅支持 IP 訪問,無 DNS 解析)。
步驟 1:啟動容器
# 啟動兩個容器(默認連接到 docker0 網橋) docker run -dit --rm --name alpine1 myalpine ash docker run -dit --rm --name alpine2 myalpine ash步驟 2:查看網橋網絡詳情
docker network inspect bridge輸出關鍵信息(子網、容器 IP 等)
{"Name": "bridge","Subnets": [{"IPRange": "172.17.0.0/16","Gateway": "172.17.0.1"}],"Containers": {"alpine1": { "IPv4Address": "172.17.0.2/16" },"alpine2": { "IPv4Address": "172.17.0.3/16" }} }步驟 3:驗證容器通信
通過 IP 訪問(成功):
# 進入 alpine1 容器,ping alpine2 的 IP(172.17.0.3) docker exec alpine1 ping -c 3 172.17.0.3通過容器名訪問(失敗):
# 進入 alpine1 容器,ping alpine2(無 DNS 解析) docker exec alpine1 ping -c 3 alpine2 # 輸出:ping: bad address 'alpine2'案例 2:自定義網橋網絡
目標:創建自定義網橋,驗證容器間 DNS 解析與靈活隔離。
步驟 1:創建自定義網橋
docker network create --driver bridge alpine-net步驟 2:啟動容器并指定網絡
# 啟動兩個容器,連接到 alpine-net 網橋 docker run -dit --rm --name alpine3 --network alpine-net myalpine ash docker run -dit --rm --name alpine4 --network alpine-net myalpine ash步驟 3:驗證 DNS 解析
# 進入 alpine3 容器,ping alpine4(通過容器名訪問) docker exec alpine3 ping -c 3 alpine4 # 輸出:64 bytes from alpine4 (172.18.0.3): icmp_seq=1 ttl=64 time=0.078 ms步驟 4:將已有容器加入自定義網絡
# 將 alpine1、alpine2 加入 alpine-net 網橋 docker network connect alpine-net alpine1 docker network disconnect alpine-net alpine2 # 可選:斷開容器與網絡的連接步驟 5:移除自定義網絡(需先斷開所有容器)
# 斷開所有容器與 alpine-net 的連接 docker network disconnect alpine-net alpine1 docker network disconnect alpine-net alpine3 docker network disconnect alpine-net alpine4# 移除網絡 docker network rm alpine-net案例 3:自定義網橋網絡(高級配置)
目標:通過參數定制網橋的子網、網關、接口名稱,并禁用 IP 偽裝和容器間連接(ICC)。
步驟 1:創建高級自定義網橋
docker network create \--driver=bridge \--subnet=172.28.0.0/16 \ # 自定義子網--ip-range=172.28.5.0/24 \ # 容器 IP 分配范圍(僅 172.28.5.0-172.28.5.255)--gateway=172.28.5.254 \ # 網橋網關 IP--opt com.docker.network.bridge.name=alpine-net1 \ # 網橋接口名--opt com.docker.network.bridge.enable_ip_masquerade=false \ # 禁用 IP 偽裝(容器無法訪問外網)--opt com.docker.network.bridge.enable_icc=false \ # 禁用容器間連接(ICC)--opt com.docker.network.container_iface_prefix=ethnick \ # 容器接口前綴alpine-net1步驟 2:啟動容器并驗證配置
# 啟動兩個容器,連接到 alpine-net1 網橋 docker run -dit --rm --name alpine6 --network alpine-net1 myalpine ash docker run -dit --rm --name alpine7 --network alpine-net1 myalpine ash步驟 3:驗證容器間通信(ICC 禁用)
# 進入 alpine6 容器,ping alpine7(容器間無法通信) docker exec alpine6 ping -c 3 alpine7 # 輸出:From 172.28.5.254 icmp_seq=1 Destination Host Unreachable步驟 4:驗證外網訪問(IP 偽裝禁用)
# 進入 alpine6 容器,ping 外網(如 www.0voice.com) docker exec alpine6 ping -c 3 www.0voice.com # 輸出:From 172.28.5.254 icmp_seq=1 Destination Host Unreachable步驟 5:查看容器接口名稱(前綴為 ethnick)
# 進入 alpine6 容器,查看網絡接口 docker exec alpine6 ip addr # 輸出示例:ethnick0: <BROADCAST,MULTICAST,UP,LOWER_UP> ...
5. overlay
????????Docker 的?Overlay 網絡是一種跨主機的網絡驅動,主要用于解決不同宿主機上容器的通信問題。它通過將底層物理網絡 “抽象” 成一個邏輯上的虛擬網絡,讓分布在多臺宿主機上的容器能夠像在同一局域網中一樣通信,無需手動配置復雜的路由規則。
一、Overlay 網絡的核心作用
Overlay 網絡的核心是跨主機容器通信,主要解決以下問題:
- 分布式應用(如微服務)需要跨多臺宿主機部署容器(例如:A 主機的?
web?容器需要調用 B 主機的?db?容器);- 容器需要透明訪問其他主機的服務,無需關心底層物理網絡拓撲;
- 容器需要支持動態擴縮容(如 Docker Swarm 或 Kubernetes 的服務發現)。
二、Overlay 網絡的工作原理
Overlay 網絡基于?VXLAN(Virtual Extensible LAN)?技術實現,通過 “封裝 - 解封裝” 網絡流量,將容器間的通信流量 “包裹” 在宿主機的物理網絡中傳輸。其核心組件和流程如下:
1. VXLAN 封裝
VXLAN 是一種隧道協議,將容器的原始網絡包(如 TCP/UDP)封裝到一個新的 UDP 報文中,外層 UDP 報文的源 / 目的地址是宿主機的物理 IP。這樣,容器間的跨主機流量可以通過宿主機的物理網絡傳輸。
2. 控制平面(Control Plane)
Overlay 網絡需要一個控制平面來管理網絡元數據(如容器 IP、宿主機對應關系、VXLAN 隧道信息)。Docker 默認使用?Gossip 協議(適用于 Swarm 集群)或集成?Consul/Etcd(需手動配置)來同步這些信息。控制平面的作用是:
?
- 記錄每臺宿主機的物理 IP 和對應的 VXLAN 隧道端點(VTEP);
- 同步容器的 IP 地址和所屬宿主機信息;
- 確保所有節點對網絡狀態達成一致(如新增容器、容器銷毀)。
3. 數據平面(Data Plane)
數據平面負責實際的流量傳輸。當容器 A(宿主機 H1)需要訪問容器 B(宿主機 H2)時:
- 容器 A 發送原始數據包(源 IP: 容器 A 的 IP,目的 IP: 容器 B 的 IP);
- 宿主機 H1 的 Docker 守護進程通過控制平面獲取容器 B 所在的宿主機 H2 的物理 IP;
- H1 將原始數據包封裝為 VXLAN 報文(外層 UDP 源 IP: H1 物理 IP,目的 IP: H2 物理 IP);
- 物理網絡將 VXLAN 報文傳輸到 H2;
- H2 解封裝 VXLAN 報文,將原始數據包轉發給容器 B。
三、Overlay 網絡的典型場景
Overlay 網絡最常見于?Docker Swarm 集群或?Kubernetes 集群(通過 CNI 插件如 Flannel 實現類似功能),適用于以下場景:
?
- 跨主機的微服務通信(如?
web?服務調用?redis?服務);- 容器化應用的高可用部署(多副本分布在不同宿主機);
- 服務發現與負載均衡(Swarm 或 Kubernetes 自動管理容器的網絡入口)。
四、Overlay 網絡的使用案例(以 Docker Swarm 為例)
以下通過一個具體案例演示 Overlay 網絡的創建和使用,需準備?2 臺或更多 Linux 宿主機(假設 IP 分別為?
192.168.1.10?和?192.168.1.11)。前提條件
- 所有宿主機安裝 Docker(版本 ≥ 19.03);
- 所有宿主機時間同步(避免 Gossip 協議同步異常);
- 防火墻開放以下端口:
2377/tcp:Swarm 集群管理;7946/tcp/udp:節點間通信(Gossip 協議);4789/udp:VXLAN 流量(Overlay 網絡核心端口)。步驟 1:初始化 Swarm 集群
在主節點(如?
192.168.1.10)執行以下命令,初始化 Swarm 集群:# 主節點初始化 Swarm(生成加入令牌) docker swarm init --advertise-addr 192.168.1.10輸出會包含從節點加入集群的命令(類似?
docker swarm join --token ... 192.168.1.10:2377)。步驟 2:從節點加入集群
在從節點(如?
192.168.1.11)執行主節點生成的加入命令,將節點加入 Swarm 集群# 從節點加入集群(替換為實際令牌和主節點 IP) docker swarm join --token SWMTKN-1-... 192.168.1.10:2377步驟 3:創建 Overlay 網絡
在主節點創建一個 Overlay 網絡(名稱為?
my-overlay)docker network create -d overlay my-overlay步驟 4:部署跨主機服務
在 Swarm 集群中部署兩個服務(
?web?和?db),分別運行在不同宿主機,并連接到?my-overlay?網絡。部署?
db?服務(MySQL):docker service create \--name db \--network my-overlay \--replicas 1 \-e MYSQL_ROOT_PASSWORD=123456 \mysql:5.7部署?
?web?服務(Nginx,模擬調用?db):docker service create \--name web \--network my-overlay \--replicas 2 \ # 部署 2 個副本,分布在不同節點 -p 8080:80 \ # 映射宿主機 8080 端口到容器 80 端口 nginx:alpine步驟 5:驗證跨主機通信
查看服務分布:
docker service ps web # 輸出會顯示兩個副本分別在主節點和從節點運行進入其中一個?
web?容器(假設在從節點?192.168.1.11),嘗試訪問?db?服務:# 找到 web 容器的 ID(假設為 abc123) docker exec -it abc123 sh# 在容器內 ping db 服務(Swarm 自動解析服務名為 IP) ping db # 應成功響應(說明跨主機通信正常)宿主機訪問?
web?服務:
無論訪問主節點還是從節點的?192.168.1.10:8080?或?192.168.1.11:8080,都會路由到可用的?web?容器(Swarm 自動負載均衡)。
6. host網絡模式
一、Host 網絡模式(主機網絡)
1. 核心概念
Host 模式是 Docker 網絡中最特殊的一種:容器直接使用宿主機的網絡棧,不進行任何網絡隔離。容器與宿主機共享 IP 地址、端口空間和網絡設備,相當于容器進程直接運行在宿主機網絡中。
2. 關鍵特性
- 無網絡隔離:容器無獨立 IP,直接使用宿主機 IP,端口映射(
-p)失效(因端口已屬于宿主機)。- 性能優勢:無需 NAT 轉換和 Userland Proxy,網絡延遲最低,適用于對性能敏感的場景(如高并發服務)。
- 平臺限制:僅支持 Linux 主機,Mac/Windows 不支持。
- 集群限制:同一宿主機上,相同端口的容器只能運行一個(端口沖突)。
3. 實戰案例
案例 1:運行 Nginx 容器(Host 模式)
# 無需端口映射,直接使用宿主機 80 端口 docker run -d --rm --name mynginx --network host nginx:latest# 驗證訪問(宿主機 IP:80 直接訪問) curl http://localhost案例 2:Swarm 服務部署(Host 模式)
# 創建 3 個副本的 Nginx 服務(每個節點僅能運行 1 個) docker service create --replicas 3 --name nginx-svc2 --network host nginx:latest# 問題:若節點 1 已運行 80 端口容器,節點 2 部署時會因端口沖突失敗4. 適用場景
- 高性能網絡服務:如 Redis、MySQL 等對網絡延遲敏感的應用。
- 需要直接訪問宿主機網絡設備:如監控工具、網絡測試工具。
- 簡化網絡配置:避免端口映射維護,直接復用宿主機端口。
7. IPvlan網絡驅動
1. 核心概念
IPvlan 是一種高性能網絡驅動,允許容器直接連接到宿主機的物理網絡接口,每個容器分配獨立 IP,共享宿主機 MAC 地址(L2 模式)或獨立 MAC(L3 模式)。其設計目標是實現容器與物理網絡的直接通信,降低網絡開銷。
2. 關鍵配置選項
選項 描述 ipvlan_mode模式選擇:
l2(默認):容器與宿主機共享 MAC,同一子網可直接通信
l3:容器有獨立 MAC,需路由轉發
l3s:L3 模式的擴展,支持多子網ipvlan_flag附加標志: bridge(默認)、private(隔離容器間通信)、vepa(強制流量經父接口轉發)parent指定物理網卡(如? ens33)作為父接口3. 內核要求
- Linux 內核版本需 ≥ 4.2(通過?
uname -r?查看)。4. 實戰案例
案例 1:單機 IPvlan(L2 模式)
# 創建 IPvlan 網絡(L2 模式,共享父接口 MAC) docker network create -d ipvlan \--aux-address vmware=192.168.239.1 \--subnet=192.168.239.0/24 --gateway=192.168.239.2 \-o parent=ens33 -o ipvlan_mode=l2 \pub_ens33# 啟動容器(自動分配子網內 IP) docker run -dit --rm --name alpine8 --network pub_ens33 alpine ash docker run -dit --rm --name alpine9 --network pub_ens33 alpine ash# 查看網絡詳情(容器 IP 與宿主機同子網) docker network inspect pub_ens33案例 2:宿主機與容器通信(L2 模式配置)
# 1. 創建宿主機 IPvlan 子接口 sudo ip link add ipvlan-net link ens33 type ipvlan mode l2 sudo ip addr add 192.168.239.254/24 dev ipvlan-net sudo ip link set ipvlan-net up# 2. 啟用混雜模式(允許接收所有 MAC 幀) sudo ip link set ens33 promisc on sudo ip link set ipvlan-net promisc on# 3. 配置路由表(新建 docker 路由表) sudo vim /etc/iproute2/rt_tables # 添加一行:100 docker sudo ip route flush table docker sudo ip route add default via 192.168.239.254 table docker sudo ip route add 192.168.239.0/24 dev ipvlan-net src 192.168.239.254 metric 10 sudo ip rule add from all to 192.168.239.0/24 table docker# 4. 驗證宿主機訪問容器 ping 192.168.239.3 # 容器 IP# 5. 還原配置(生產環境慎用) sudo ip rule del from all to 192.168.239.0/24 table docker # ...(逐步刪除路由、關閉混雜模式、刪除接口)案例 3:跨主機容器通信(L2 模式)
# 每臺主機創建相同配置的 IPvlan 網絡 docker network create -d ipvlan \--aux-address vmware=192.168.239.1 \--subnet=192.168.239.0/24 --gateway=192.168.239.2 \-o parent=ens33 -o ipvlan_mode=l2 \pub_ens33# 主機1啟動容器 docker run -dit --rm --name alpine10 --ip=192.168.239.10 --network pub_ens33 alpine ash # 主機2啟動容器 docker run -dit --rm --name alpine12 --ip=192.168.239.12 --network pub_ens33 alpine ash# 跨主機通信(需物理網絡支持二層互通) ping 192.168.239.12 # 主機1容器訪問主機2容器案例 4:單機跨網絡通信(L3 模式)
# 創建多子網 IPvlan 網絡(L3 模式,支持跨子網路由) docker network create -d ipvlan \--subnet=192.168.214.0/24 \--subnet=10.1.214.0/24 \-o parent=ens33 -o ipvlan_mode=l3 \pub_ens33-1# 啟動跨子網容器 docker run -dit --rm --name alpine14 --network pub_ens33-1 --ip=192.168.214.10 alpine ash docker run -dit --rm --name alpine15 --network pub_ens33-1 --ip=10.1.214.10 alpine ash# 跨子網通信(需容器內配置路由) # alpine14 中:ip route add 10.1.214.0/24 via 192.168.214.15. 注意事項
- 安全隔離:L2 模式下容器共享 MAC,需通過防火墻限制容器間訪問;L3 模式需配置路由規則。
- 外部訪問:IPvlan 網絡默認不被外部路由知曉,需在物理路由器添加靜態路由。
- 性能優勢:跳過 Docker 網橋轉發,適合高吞吐量場景(如網絡代理、負載均衡器)。
8.?Macvlan 網絡驅動
1. 核心概念
Macvlan 允許為容器的虛擬網卡分配獨立 MAC 地址,使容器看起來像 “物理設備” 直接連接到物理網絡。與 IPvlan 相比,Macvlan 更貼近傳統網絡模型,每個容器有獨立 MAC 和 IP,適用于需要直接接入物理網絡的遺留應用。
2. 關鍵配置選項
選項 描述 macvlan_mode模式選擇:
bridge(默認):容器間直接通信
vepa:流量強制經父接口轉發
passthru:直接使用物理接口(僅一個容器可連接)
private:容器間隔離parent指定物理網卡(如? ens33)作為父接口3. 注意事項
- MAC 地址管理:大量容器可能導致 MAC 地址泛濫,需網絡設備支持(如交換機開啟混雜模式)。
- 性能影響:若網絡設備未優化 MAC 學習,可能導致廣播風暴。
- 替代方案:優先使用 Bridge 或 Overlay 網絡,僅在遺留應用必須直連物理網絡時使用 Macvlan。
4. 實戰案例
# 案例:創建 Macvlan 網絡并啟動容器 docker network create -d macvlan \--subnet=172.16.86.0/24 \--gateway=172.16.86.1 \-o parent=ens33 \pub_mac_ens33# 啟動容器(自動分配獨立 IP 和 MAC) docker run -dit --rm --name alpine16 --network pub_mac_ens33 alpine ash docker run -dit --rm --name alpine17 --network pub_mac_ens33 alpine ash# 查看容器網絡詳情(包含獨立 MAC 地址) docker network inspect pub_mac_ens33
9.?None 網絡模式
1. 核心概念
None 模式是 Docker 中最嚴格的網絡隔離模式:容器創建時僅生成環回接口(
lo),完全沒有網絡連接。適用于不需要網絡的場景(如批處理任務、離線計算)。2. 實戰案例
# 啟動無網絡容器 docker run -dit --rm --name alpine-none --network none alpine ash# 進入容器查看網絡接口(僅有 lo) docker exec alpine-none ip addr # 輸出:1: lo: <LOOPBACK,UP,LOWER_UP> ...3. 適用場景
- 安全敏感場景:禁止容器訪問任何網絡,防止數據泄露。
- 離線任務:如日志處理、文件轉換等無需網絡的批量作業。
五、網絡模式對比與選擇建議
?
網絡模式 隔離性 IP 分配 性能 適用場景 Bridge 中等(同網橋可通信) 容器獨立 IP(NAT) 中等 常規應用、微服務 Host 無 共享宿主機 IP 最高 高性能服務、直接使用宿主機端口 IPvlan/Macvlan 高(可配置隔離) 獨立 IP(直連物理網絡) 高 網絡代理、遺留應用、跨主機二層通信 None 最高 僅有環回接口 N/A 離線任務、安全隔離 選擇原則:優先使用 Bridge 模式;追求性能用 Host;需直連物理網絡用 IPvlan/Macvlan;完全隔離用 None。
?0voice · GitHub?


)



數據-可自定義key和value)

![[藍帽杯 2022 初賽]網站取證_2](http://pic.xiahunao.cn/[藍帽杯 2022 初賽]網站取證_2)
——從數據塵埃到智能生命的煉金秘錄)

)







——dlib關鍵點定位)