25年5月來自 CMU 的論文“DexWild: Dexterous Human Interactions for In-the-Wild Robot Policies”。
大規模、多樣化的機器人數據集已成為將靈巧操作策略泛化到新環境的一條有效途徑,但獲取此類數據集面臨諸多挑戰。雖然遙操作可以提供高保真度的數據集,但其高昂的成本限制了其可擴展性。如果人們能夠像在日常生活中一樣用自己的雙手來收集數據,情況會怎樣?在 DexWild 中,一個由多元化數據收集人員組成的團隊用雙手收集了跨越眾多環境和物體的數小時交互數據。為了記錄這些數據,創建 DexWild 系統,這是一款低成本、移動且易于使用的設備。DexWild 學習框架基于人類和機器人的演示進行協同訓練,與單獨訓練每個數據集相比,其性能有所提升。這種組合能夠生成強大的機器人策略,使其能夠以最少的額外機器人特定數據泛化到新的環境、任務和具身中。
模仿學習的泛化
機器人操作的泛化策略學習取得了快速進展,這主要得益于視覺表征學習和大規模數據集模仿學習的進步。在視覺方面,具身表征學習受益于以自我為中心的數據集,例如 Ego4D [15] 和 EPIC-KITCHENS [10],最近的方法 [27, 11, 47, 39] 利用這些數據集來訓練可擴展的視覺編碼器。然而,這些方法仍然需要大量的下游機器人演示來訓練控制策略。
與此同時,僅限機器人的演示數據集在規模和多樣性方面也顯著增長 [21, 8, 54],這推動了行為克隆的研究,并促成了泛化策略架構的構建 [49, 8, 22]。雖然這些策略在許多任務中表現出色,但它們往往難以泛化到未知的目標類別、場景布局或環境條件 [25]。這種魯棒性的缺乏仍然是當前系統的一個關鍵限制。
機器人操作的數據生成
克服機器人數據瓶頸已成為機器人學習的核心挑戰。一種方法是利用互聯網視頻提取動作信息。一些研究,例如 VideoDex [40] 和 HOP [42],利用大規模真人視頻通過重定向學習動作先驗,并以此引導策略訓練。其他研究,例如 LAPA [57],則使用未標記的視頻生成可用于下游任務的潛動作表征。雖然這些基于視頻的方案擁有豐富的視覺多樣性,但它們通常無法捕捉現實世界操作所需的精確、低級運動指令。
模擬能夠快速生成大規模動作數據。然而,為許多任務創建多樣化、逼真的環境并解決模擬與現實之間的差距是一項挑戰。近期在將操作策略從模擬 [43] 遷移方面取得的成功僅限于桌面環境,缺乏在不同環境中部署所需的泛化能力。
在實體機器人上進行直接遙操作可以獲得最高的保真度,但擴展性較差。最近的研究已在固定場景中展現出令人印象深刻的靈活性和高效的學習能力 [59, 56, 41, 19],然而,收集足夠多的演示樣本以推廣到不同場景的成本很快就會變得高昂。
最近,越來越多的研究利用有針對性地收集的高質量人體具身數據,而無需繁瑣的遙操作。
人體動作追蹤系統
為了獲取高質量的人體運動數據,準確的手部和腕部追蹤至關重要。為了規避手勢估計的復雜性,一些研究為用戶配備手持式機器人夾持器 [7, 12, 46]。雖然這種方法簡化重定向操作,但它將用戶限制在機器人夾持器的特定形態上,從而限制捕獲行為的多樣性。此外,許多此類系統依賴于基于 SLAM 的腕部追蹤,這在特征稀疏的環境中或出現遮擋時可能會失效 [7, 23]——例如在打開抽屜或使用工具時。
其他方法旨在直接根據視覺輸入估計手部和腕部姿勢 [29, 35, 5, 45, 28, 20, 32]。這些方法易于部署且無需儀器,但在遮擋(操作過程中不可避免的情況)的情況下,其性能會顯著下降。其他腕部追蹤策略,例如基于 IMU 的 [9, 50] 和由外向內的光學系統 [30],也各有局限性:IMU 輕巧便攜但容易漂移;光學系統精準,但需要繁瑣的標定和受控環境。
DexWild 利用無需標定的 Aruco 追蹤技術,顯著提高了可靠性并最大限度地縮短了設置時間,因為它只需要一個單目攝像頭。
雖然基于視覺的方法通常嘗試同時追蹤腕部和手指,但許多近期系統將兩者分離以提高準確性。運動外骨骼手套可以提供高保真關節測量甚至觸覺反饋 [58],但體積龐大,長期佩戴不舒適。
相反,DexWild 與先前的研究 [41, 55] 一樣,采用了一種基于輕量級手套的解決方案,該方案利用電磁場 (EMF) 感應來估計指尖位置。這可以實現準確、實時的手部追蹤,并且對遮擋具有魯棒性,并且可以輕松地重定位到各種機械手上。
許多人認為,利用海量高質量數據集是創建具有泛化能力的靈巧機器人策略的關鍵 [8, 49, 40, 11]。DexWild 系統是一個用戶友好、高保真度的平臺,用于高效地收集各種真實世界中的自然人手演示。與傳統的基于遙操作方法相比,DexWild 系統的數據采集速度提高了 4.6 倍。
在此系統的基礎上,DexWild,一個模仿學習框架,基于大規模 DexWild 系統的人類演示和少量機器人演示進行協同訓練。這種方法將人類交互的多樣性和豐富性與機器人實例的扎實基礎相結合,使策略能夠穩健地泛化到新目標、環境和實例中。如圖展示DexWild 方法:

數據收集系統
一個可擴展的靈巧機器人學習數據收集系統必須能夠在各種環境中進行自然、高效和高保真度的收集。為此,DexWild-System,作為一款便攜、用戶友好的系統,只需極少的設置和訓練即可捕捉人類的靈巧行為。以往的野外數據收集方法通常依賴于帶傳感器的抓取器,而本文目標是創建一個更直觀的硬件界面,以真實還原人類與世界自然互動的方式。從精細的精細動作到強大的抓握,人類在各種操控任務中都擁有靈巧的操控能力。通過學習這種內在能力,DexWild-System 能夠捕捉豐富多樣的數據,適用于各種機器人應用場景。
DexWild-System 的設計圍繞三個核心目標:
? 便攜性:無需復雜的標定程序,即可在不同環境中快速、大規模地收集數據。
? 高保真度:準確捕捉精細的手部與環境交互,這對于訓練精準的靈巧策略至關重要。
? 不依賴具體形態:能夠從人類演示無縫重定向到各種機器人手。
可移植性:
為了在各種現實環境中收集數據,系統必須便攜、穩定且易于任何人使用。在設計 DexWild 系統時秉持以下目標:它重量輕、易于攜帶,并且只需幾分鐘即可完成設置,從而能夠在多個地點進行可擴展的數據收集。
如圖所示,DexWild 系統僅包含三個組件:用于腕部姿勢估計的單追蹤攝像頭、用于板載數據采集的電池供電微型 PC,以及由動作捕捉手套和同步掌上攝像頭組成的定制傳感器盒。
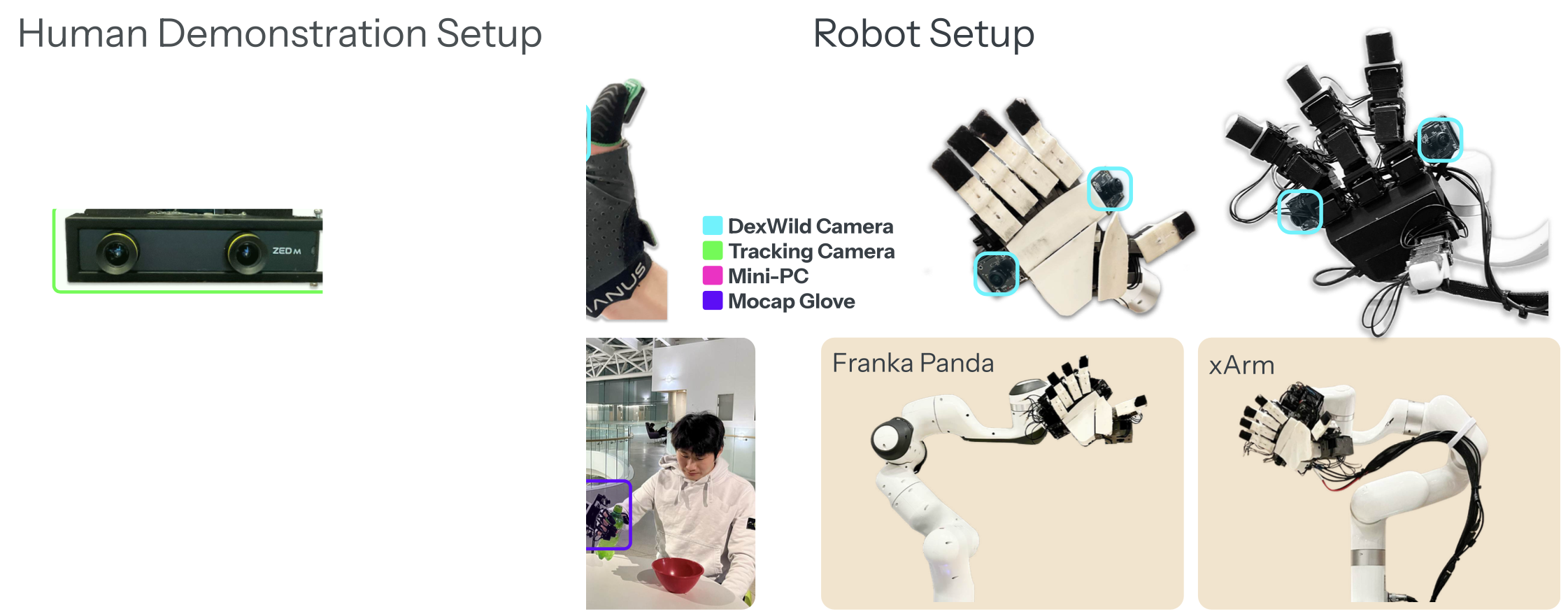
與通常依賴于需要標定、復雜的、由外向內追蹤設置的傳統動作捕捉系統 [60, 13, 4, 52] 不同,DexWild 系統真正實現了無需標定,使其適用于任何場景,即使未經培訓的操作員也能輕松操作。
這是通過采用相對狀態-動作表示來實現的,其中每個狀態和動作都被捕獲為與前一時間步的姿勢的相對差異。這消除了對全局坐標系的任何需求,允許跟蹤攝像頭自由放置——無論是以自我為中心還是以外部為中心。此外,掌上攝像頭在人類和機器人的實體上都牢固地安裝在固定位置。這確保了視覺觀察在不同域中保持一致,無需在部署時進行進一步標定。外部跟蹤攝像頭在精心定位后,還可以捕捉有助于學習穩健策略的補充環境信息。
高保真度:
為了學習靈巧的行為,必須在訓練數據集中捕捉精細、細微的動作。盡管 DexWild 系統僅包含少量便攜式組件,但在數據保真度方面毫不妥協。系統旨在精準捕捉手部和腕部動作,并提供高質量的視覺觀測。
對于腕部和手部追蹤,純視覺方法易于設置。然而,它們在便攜性方面的優勢往往犧牲了準確性和魯棒性——導致姿勢估計噪聲較大,從而降低策略學習的效果 [41, 14, 32, 7]。
對于手部姿勢估計,用動作捕捉手套,它具有高精度、低延遲和抗遮擋魯棒性 [41]。對于腕部追蹤,在手套上安裝 ArUco 標記點,并使用外部攝像頭進行追蹤。這避免了基于 SLAM 腕部追蹤的脆弱性,這種追蹤在特征稀疏的環境中或在遮擋嚴重的任務(例如打開抽屜)中經常失敗。
與許多依賴于以自我為中心或遠距離外部攝像頭的數據集不同,在此將兩個全局快門攝像頭直接放置在手掌上。如上圖所示,這些立體雙目攝像頭能夠捕捉到細致的局部交互視圖,同時最大程度地減少運動模糊并擁有寬廣的視野。這種寬廣的視野使得策略能夠僅使用板載手掌攝像頭進行操作,而無需依賴任何靜態視點。
與具身無關:
為了確保 DexWild 數據的持久性和多功能性,在此目標是使其能夠在不同的機器人具體形態中保持可用性——即使硬件平臺不斷發展。實現這一目標需要仔細協調人機之間的觀察空間和動作空間。
首先要標準化觀察空間。雖然掌上攝像頭擁有廣闊的視野,但特意將它們定位在主要聚焦于環境的位置,從而最大限度地降低手部本身的可見性。重要的是,攝像頭在人手和機器人手上的放置位置是鏡像的。如圖所示,這種設計在不同具身中產生視覺上一致的觀察結果,從而使策略能夠學習到一種可在人類和機器人域泛化的共享視覺表征。

對于動作空間對齊,基于先前研究 [17, 44] 的洞見,優化機器人手的運動學,使其與人類演示中觀察到的指尖位置相匹配。這種方法具有通用性,適用于任何機器人手的具身。它在不同用戶中使用固定的超參數,并且對手部尺寸的變化具有魯棒性,無需針對特定用戶進行調整。
使用自然人手收集數據除了易于使用之外,還具有其他優勢。人類演示者手部形態的多樣性帶來了有用的變異,這有助于策略學習更具泛化的抓取策略——鑒于人類和機器人手部運動學之間固有的不匹配,這一點尤為重要。
總而言之,DexWild 是一款便攜式、高質量、以人為本的系統,任何操作員都可以佩戴,在現實環境中收集人體數據。接下來,將解釋如何利用 DexWild 收集的數據,使靈巧策略能夠泛化到自然場景中。
訓練數據模態與預處理
靈巧操作的泛化需要規模化和具體化基礎。為此,DexWild 收集兩個互補的數據集:一個使用 DexWild 系統的大規模人類演示數據集 D_H,以及一個規模較小的遙控機器人數據集 D_R。
人類數據具有廣泛的任務多樣性,并且在現實環境中易于收集,但缺乏具體化一致性。機器人數據雖然規模有限,但卻為機器人的動作和觀察空間提供了至關重要的基礎。為了充分利用兩者的優勢,用一個批次中固定比例的人類和機器人數據 (w_h, w_r) 共同訓練策略——在多樣性和具身基礎之間取得平衡,從而在部署期間實現穩健的泛化。
在每次訓練迭代中,根據共同訓練權重分別從 D_H 和 D_R 中采樣一個包含轉換 x_h 和 x_r 的批次。時間步 i 的每個轉換 x_i 包含:
? 觀測值 o_i:給定時間步的觀測值包含當前時間步捕獲的兩個同步手掌攝像頭圖像 I_pinky 和 ??I_thumb,以及一系列歷史狀態,這些狀態以給定時間范圍 H 的步長采樣,包含 {?p_i, ?p_i?step, …, ?p_i?H}。每個 ?p 包含相對的歷史末端執行器位置。
? 動作 a_i:i+n?1:大小為 n 的動作塊,包含動作 {a_i, a_i+1, …, a_i+n?1},其中 a_i 是當前時間步的動作。具體而言,a_i 是一個 26 維向量,包含:
– a_arm:一個 9 維向量,描述末端執行器相對位置(3D)和方向(6D)。
– a_hand:一個 17 維向量,描述機器人手的手指關節位置目標。
對于雙手任務,觀察和動作空間會被復制,并將雙手間的姿勢附加到觀察結果中,以促進協調。
雖然重定向程序將人類和機器人的軌跡帶入共享的動作空間,但仍需要一些額外的步驟來使人類和機器人的數據集兼容以進行聯合訓練:
? 動作規范化:對人類和機器人數據的動作分別進行規范化,以解決固有的分布不匹配問題。
? 演示過濾:由于人類演示是由未經訓練的操作員在不受控制的環境中收集的,應用基于啟發式的過濾流程來自動檢測并移除低質量或無效的軌跡。此過濾步驟無需人工標記即可顯著提高數據集質量。
策略訓練
通過精心設計硬件、觀察和動作接口,能夠使用簡單的行為克隆 (BC) 目標 [31, 37, 36] 來訓練靈巧機器人策略。為了有效地從多模態、多樣化的數據中學習,訓練流程利用大規模預訓練的視覺編碼器,并在不同的策略架構中展現出強大的性能。
視覺編碼器:在 DexWild 數據上進行訓練,使策略能夠應對場景、物體和光照等顯著的視覺多樣性,這需要一個能夠良好泛化到這種多樣性的編碼器。為了解決這個問題,采用預訓練的 Vision Transformer (ViT) 主干網絡,該網絡在野外操控任務中表現出優于基于 ResNet 編碼器的性能 [16, 23]。預訓練的 ViT,尤其是在大型互聯網規模數據集上訓練的 ViT,在提取豐富、可遷移的特征方面尤為有效 [27, 33, 47, 11],因此非常適合本文的設置。
策略類別:雖然最近已經提出幾種模仿學習架構 [59, 6],但采用基于擴散的策略。擴散模型特別適合靈巧操作,因為它們比高斯混合模型 (GMM) 或 Transformer 等替代方案更有效地捕捉多模態動作分布。這種能力在 DexWild 中變得越來越重要,因為 DexWild 會從多個使用不同策略的人類身上收集演示,從而產生固有的多模態行為。隨著數據集規模的擴大,對這種可變性進行建模對于穩健的策略學習至關重要。具體而言,DexWild 使用擴散 U-Net 模型 [6] 來生成動作塊。
具體來說,訓練過程概述在算法 1 中。

訓練框架的一個重要發現是,調整人機數據權重會顯著影響現實世界的表現。
實驗的硬件系統部署于 10 位未經訓練的用戶,用于收集各種真實環境中的數據。這些環境包括室內和室外、白天和夜晚、擁擠的自助餐廳和安靜的學習區,其中擺放著各種桌子、物品和燈光設置。收集者本身的手掌大小和演示風格也各不相同,這能夠從各種各樣的環境和互動中學習。
通過收集工作構建兩個數據集:D_H(人工收集數據)和 D_R(機器人收集數據)。人工數據集 D_H 包含五項任務的 9,290 個演示:噴霧瓶任務和玩具清理任務分別包含來自 30 個不同環境的 3,000 個演示;傾倒任務包含來自 6 個環境的 621 條軌跡;花店任務包含來自 15 個環境的 1,545 個演示;折疊衣服任務包含來自 12 個環境的 1,124 個演示。
機器人數據集 D_R 包含 1,395 個演示:388 個噴霧瓶演示、370 個玩具清理演示、111 個傾倒演示、236 個花店演示以及 290 個折疊衣服演示。機器人數據由 xArm 和 LEAP 機械手 V2 Advanced 收集。
訓練和測試目標如圖所示:

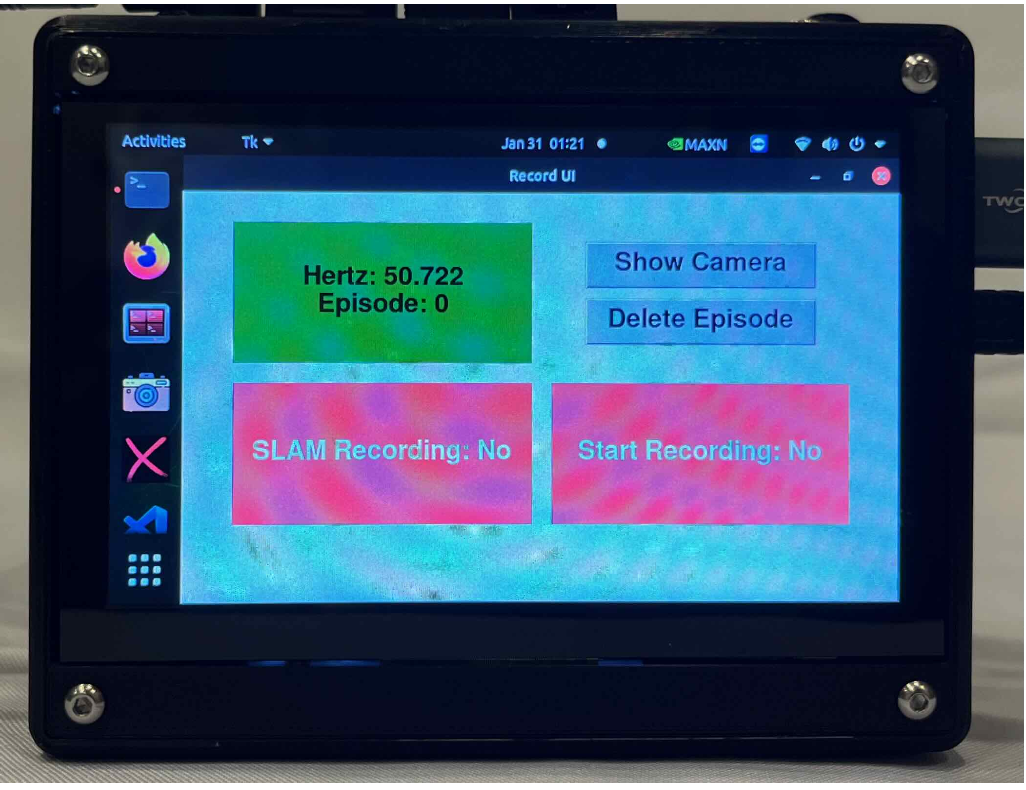
DexWild 系統包含三個核心組件:腕式追蹤攝像頭、用于機載數據采集的電池供電 mini 電腦,以及一個帶有動作捕捉手套和掌上攝像頭的定制傳感器盒。在新地點,用戶只需佩戴動作捕捉手套,并使用提供的移動電源為迷你電腦供電即可。對于以自我為中心的追蹤,頭帶可固定追蹤攝像頭;對于以外部為中心的追蹤,提供可折疊三腳架。啟動后,用戶啟動定制的桌面應用程序,并通過藍牙遙控器或腳踏板控制錄制。用戶界面(如圖所示)顯示傳感器狀態、SLAM 錄制和數據采集指示燈,以及用于查看追蹤攝像頭反饋和刪除最后一集的按鈕。采集人員每個地點收集 100 集數據。一天結束后,會將數據上傳到遠程機器進行處理。
每個 episode 都存儲在其自己的文件夾中,子文件夾用于組織各個動作和觀察結果。來自 Zed Mini 相機的 SVO 記錄(用于 SLAM 和腕部姿勢追蹤)單獨保存,每個文件涵蓋五個episodes。為了開始數據處理,用 Zed SDK 解碼這些 SVO 文件,重建相機的運動,并使用左圖和立體深度數據執行 ArUco 立方體追蹤和腕部姿勢估計。然后,應用過濾流程來評估追蹤質量;如果超過 75% 的持續時間內無法可靠地追蹤腕部姿勢,則丟棄該episode。接下來,計算動作分布,并裁剪第 2 和第 97 個百分位數之外的異常值。用插值和高斯濾波來平滑軌跡,以確保流暢的運動。然后,按照 [41] 中的方法,使用 PyBullet 中的逆運動學重定位手部動作。為了提高效率,整個流程使用 Ray 并行化。
行為克隆策略以 RGB 圖像和相對狀態歷史作為輸入。通過 ViT 獲取圖像觀測的tokens,并通過線性層獲取相對狀態的tokens。ViT 的權重由 [11] 中的 Soup 1M 模型初始化。其包含相對狀態,因為它能顯著提高策略的魯棒性,并使運動更加流暢。特別是對于雙手操作任務,包含雙手間姿勢(左手相對于右手的姿勢)能顯著提高諸如花店之類的任務的成功率。將 Action Chunking Transformer [59] 和 Diffusion U-Net [6] 實現為策略類,它們輸出一系列動作。網絡輸出的動作由相對末端執行器動作和絕對手部關節角度組成。
為了確保策略的平滑度和安全性,采用 Isaac Lab [26] 中實現的黎曼運動策略 (RMP) [34],其中 RMP 根據末端執行器目標動態生成關節空間目標。 RMP 還具有實時防碰撞功能,可防止機械臂與設定的桌面高度發生自碰撞。
![[藍帽杯 2022 初賽]網站取證_2](http://pic.xiahunao.cn/[藍帽杯 2022 初賽]網站取證_2)
——從數據塵埃到智能生命的煉金秘錄)

)







——dlib關鍵點定位)







