hi,我是云邊有個稻草人
目錄
前言
一、初識藍耘元生代MaaS平臺:零門檻體驗AI服務
1.1 從零開始——平臺注冊與環境搭建
1.2 平臺核心功能
1.3?藍耘平臺的優勢在哪里?
二、知識庫構建新篇章:從零碎資料到智能語義倉庫的蛻變
2.1?多渠道、多格式資料采集與清洗
2.2?知識分層和標簽體系設計
2.3?知識庫批量導入與分批策略
2.4?知識庫維護與版本管理
2.5?語義搜索優化與實踐經驗
三、智能客服應答系統開發:從零到一的成長經歷
3.1 智能客服系統設計理念及結構
3.2 工作流調用設計實操
3.3 多輪問答上下文管理
3.4 代碼示例與解讀
3.5 異常容錯與轉人工設計
四、免費千萬Token體驗:大學生的福音
4.1 節省成本,助力學習和開發
4.2 精準用Token的實踐技巧
五、總結
前言
作為一名計算機專業的大學生,從課堂上學習到人工智能的基礎理論和模型后,我渴望能夠親手實踐一把,將AI技術應用到現實生活和校園服務中。課余時間,我嘗試了不少模型訓練和開源項目,也探索過一些公有云服務平臺,但都因價格高昂、學習曲線陡峭缺乏后續支持等原因望而卻步。
在一次技術分享中,遇到了藍耘MaaS平臺,讓我眼前一亮。這個平臺不僅提供了多種強大的AI預訓練模型,更令人驚艷的是,它贈送給用戶的千萬級Token額度,無疑大大降低了我們這些學生的使用門檻。經過一番調研,我決定將它作為智能客服項目的核心技術平臺。
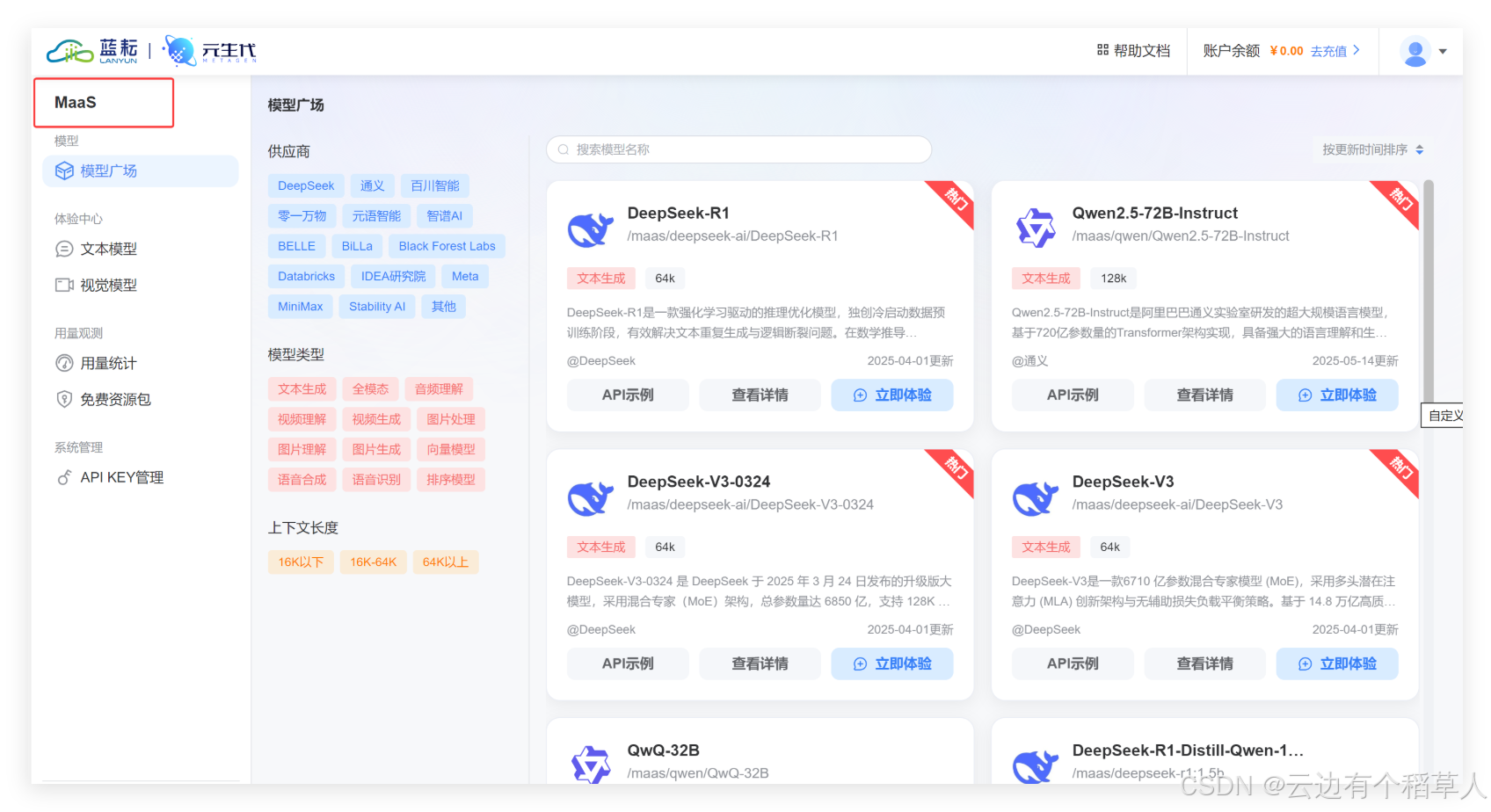
一、初識藍耘元生代MaaS平臺:零門檻體驗AI服務

1.1 從零開始——平臺注冊與環境搭建
當我第一次訪問藍耘元生代官網,進行賬號注冊時,流程非常簡潔,無需繁瑣的身份驗證,只需郵箱確認即可生成屬于我的API Key。平臺首頁還貼心地提供了快速入門文檔和示例代碼,熟悉流程非常迅速。
(1)輸入手機號,將驗證碼正確填入即可快速完成注冊
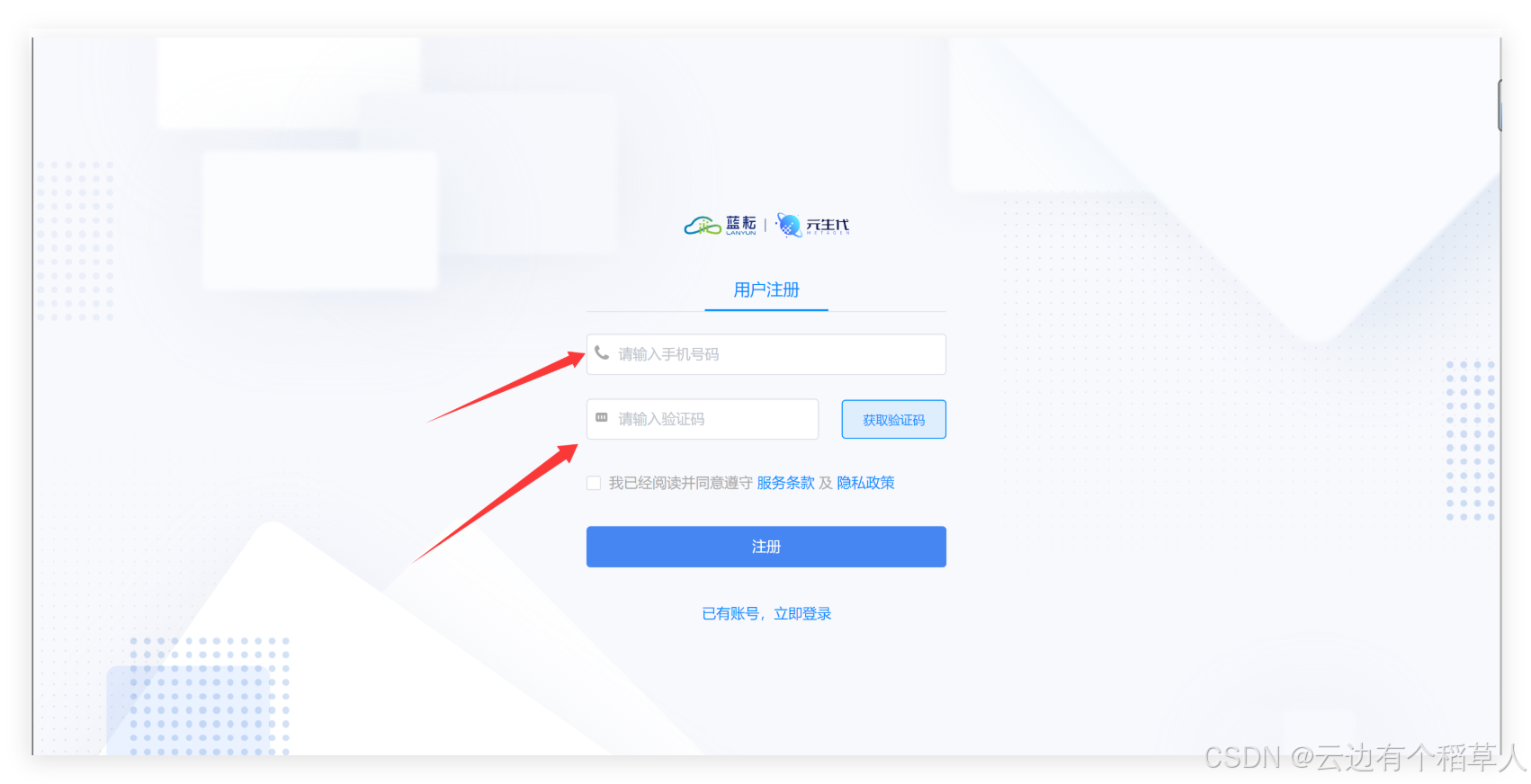
進入下面的頁面表示已經成功注冊?
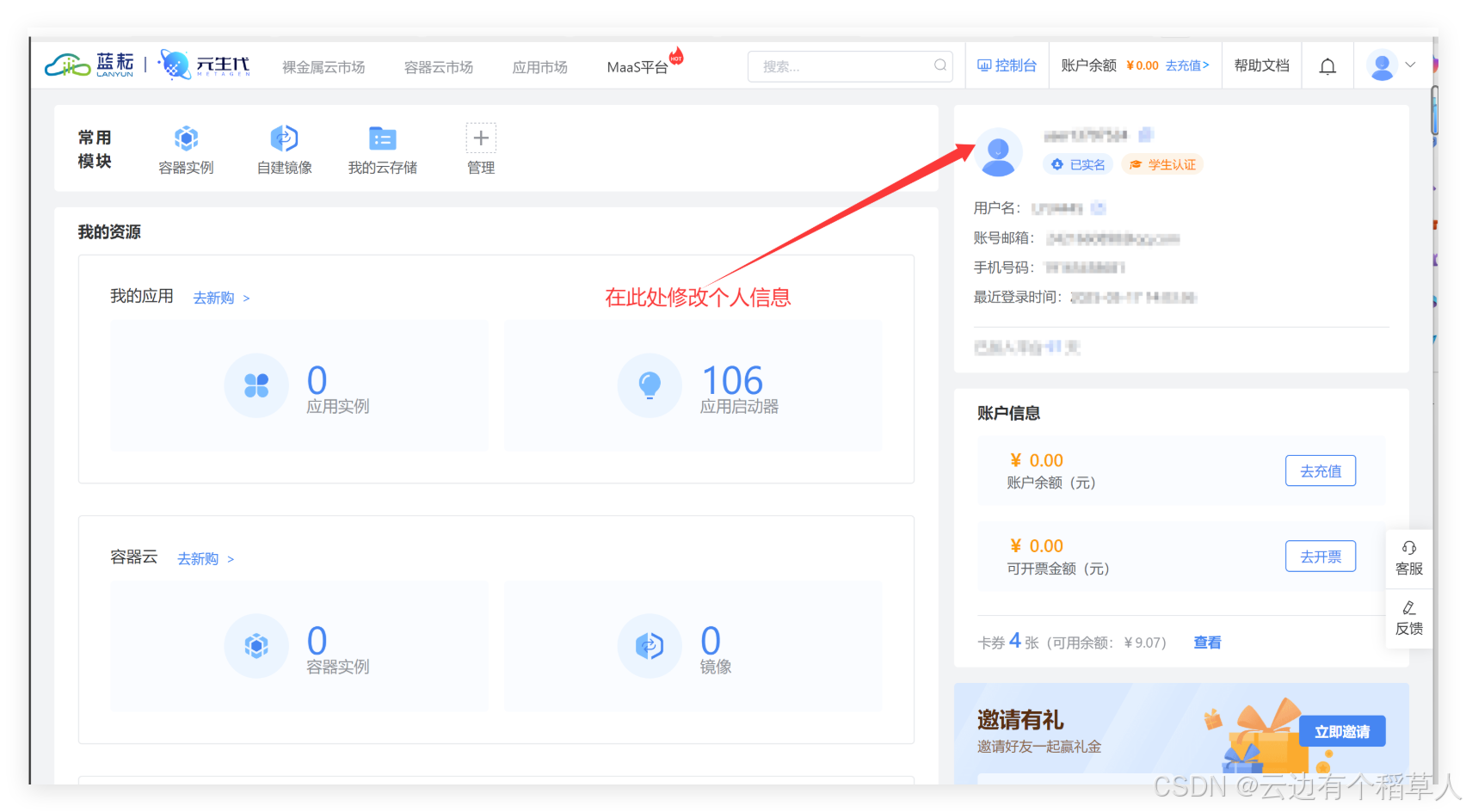
令我印象深刻的是,注冊完成后,平臺即刻向我賬戶贈送了1千萬免費Token的額度。以我初期使用量估算,這相當于可以無憂地進行數萬次問答調用,既滿足學習探索,也保證真實業務開發的試運行。
進入藍耘平臺,點擊應用市場,我們清晰的看到有火爆的阿里萬相2.1圖生視頻等強大功能,隨心選擇,暢享使用!
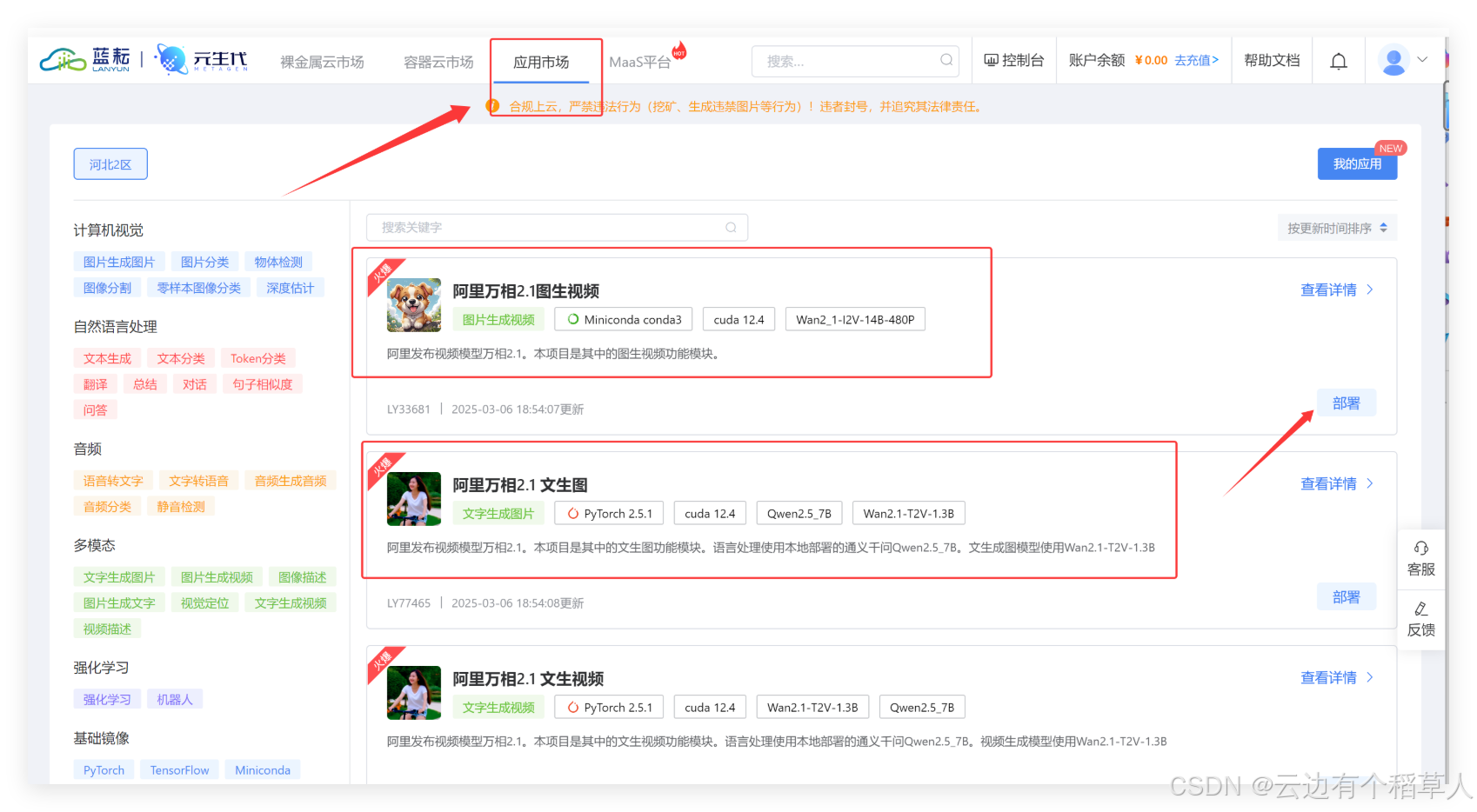
示例,阿里萬相2.1,圖生視頻,點擊查看詳情,我們可以看到有應用介紹,詳細的操作說明,點擊部署,即可快速體驗圖生視頻的功能?
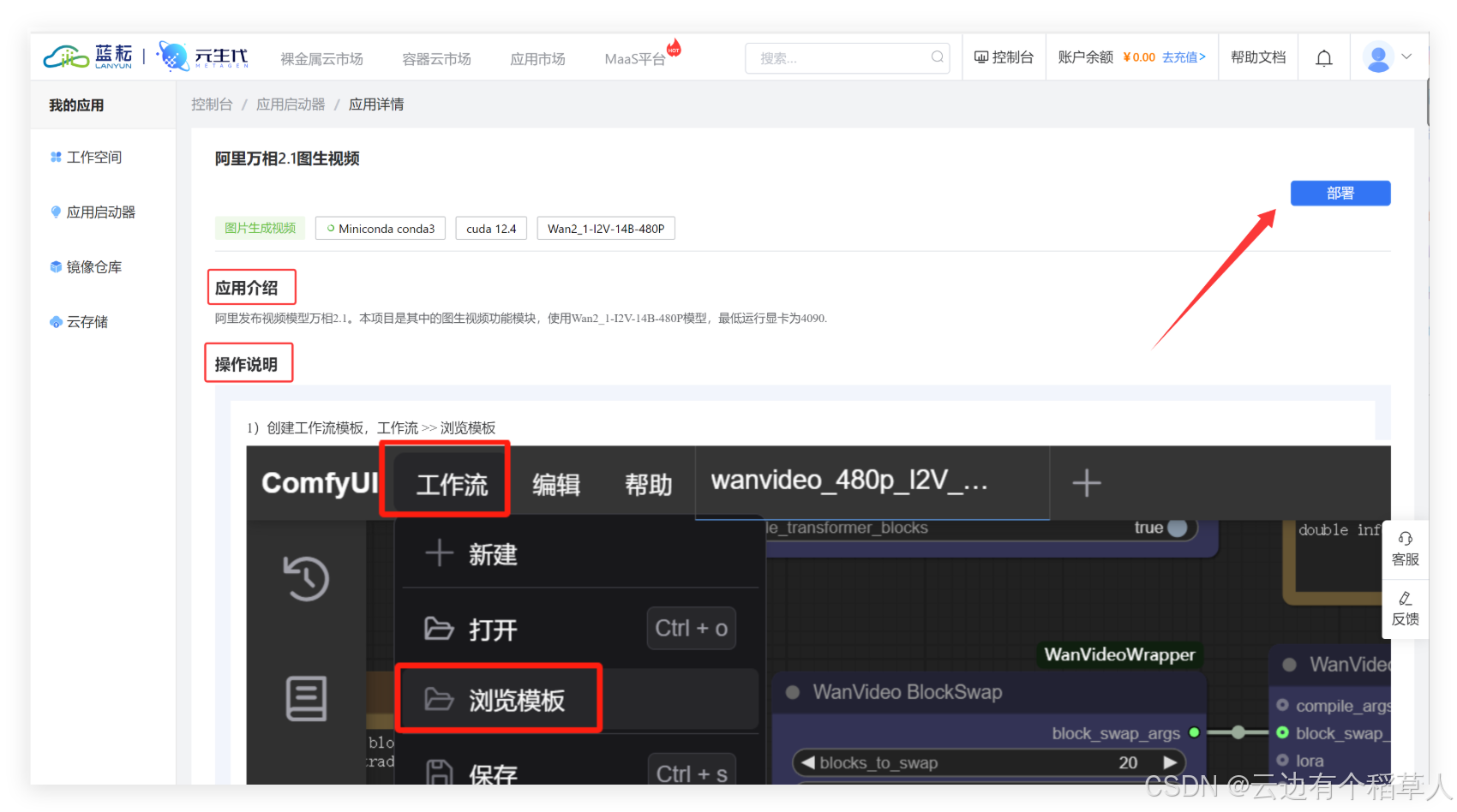
1.2 平臺核心功能
在實際使用中,我逐漸了解藍耘平臺的三大核心能力:
知識庫管理:支持上傳文檔,多格式兼容,且內建語義檢索和向量索引能力。相較我之前使用本地Elasticsearch構建知識庫,藍耘極大簡化了工作量。
自然語言處理API:包含意圖識別、實體抽取、文本生成等多樣功能,接口規范統一,調用體驗流暢。
API工作流設計器:讓我可以不用復雜編碼,就能將多個API串聯起來,實現典型的智能客服業務流程,比如從意圖識別到知識檢索到答案生成一氣呵成。
1.3?藍耘平臺的優勢在哪里?
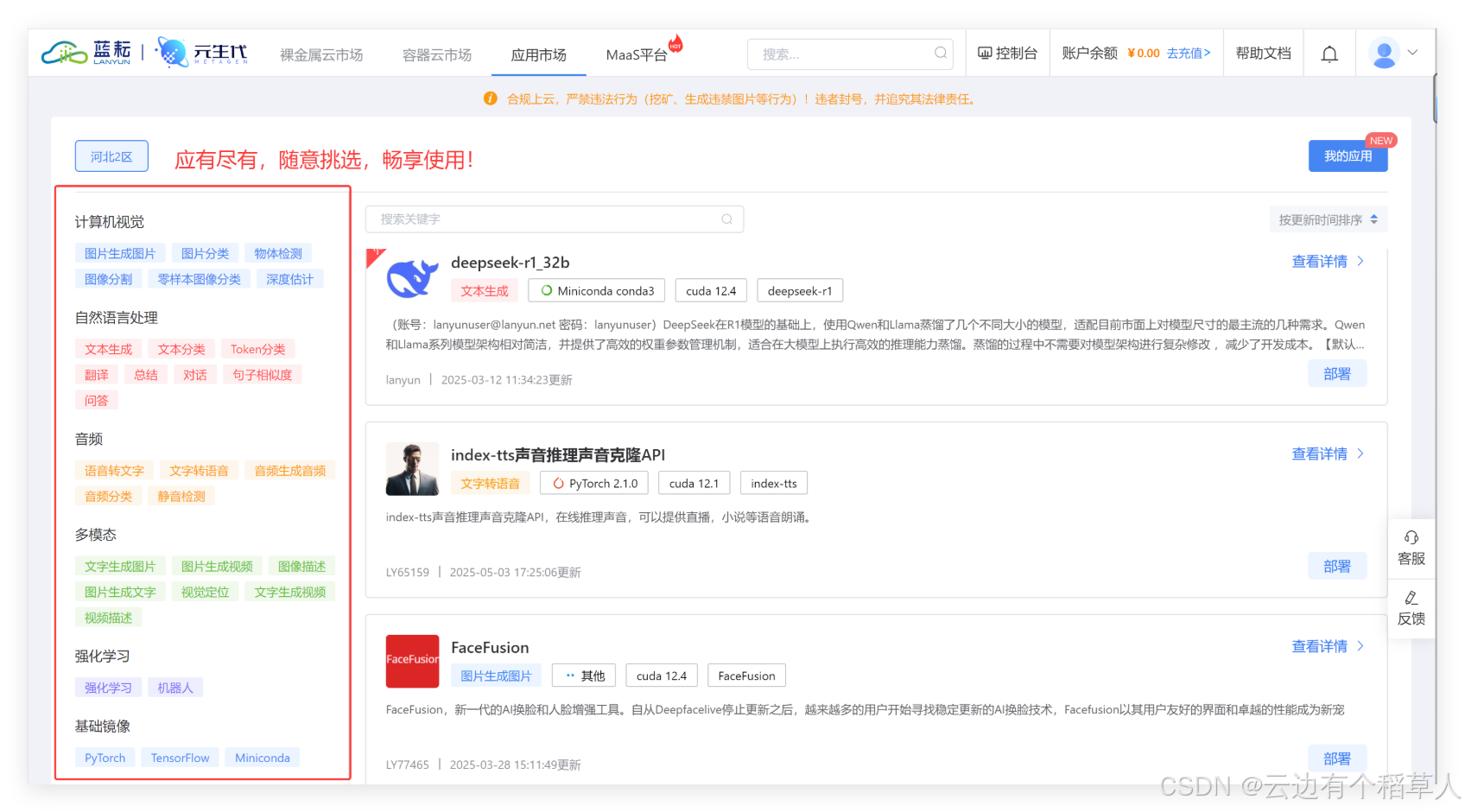
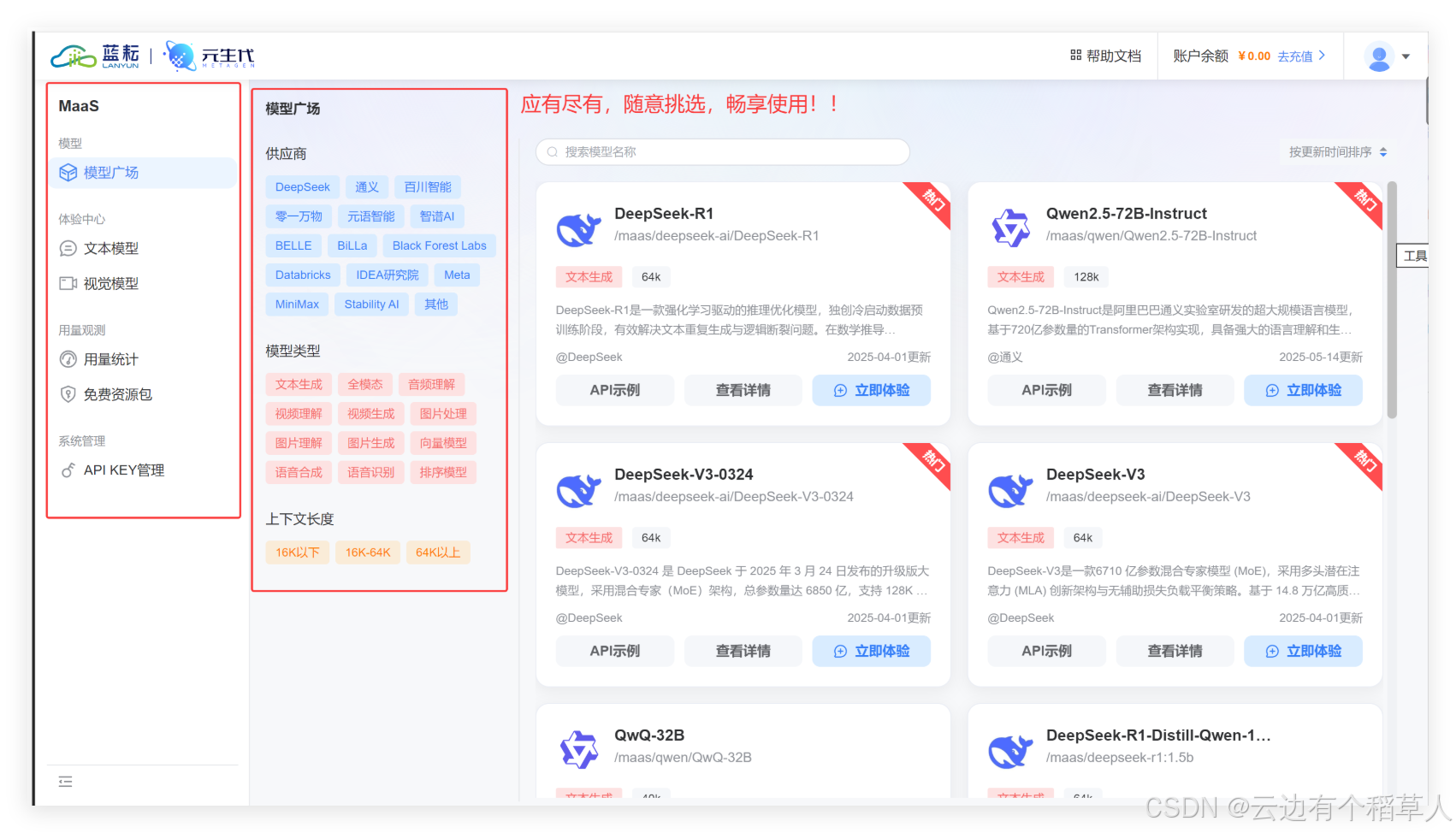
- 開放API接口:不需要復雜的配置,直接根據需求選擇API接口,輕松完成調用。
- 智能客服系統:內置的自然語言處理技術,能夠快速識別客戶問題并自動作答,效率大大提升。
- 知識庫管理:通過簡單的API調用,我可以輕松創建和管理知識庫,確保智能客服有足夠的回答支持。
- 自動化工作流:平臺自帶的工作流引擎,讓我能夠輕松實現自動化操作,節省了大量時間。
- 超千萬Token贈送:平臺提供的免費Token讓我能夠進行大量測試,免去了開發過程中的經濟壓力。
此外,藍耘平臺提供詳實調試工具,方便我查看請求與返回數據,調優參數落地應用,極適合想系統深入實踐的學生群體。
二、知識庫構建新篇章:從零碎資料到智能語義倉庫的蛻變
2.1?多渠道、多格式資料采集與清洗
建設知識庫第一步就是獲取內容。我的資料主要來自:
學校教務處官方文檔:這些文檔權威且全面,但多為PDF或Word格式,含大量格式化元素。為了方便平臺識別,我先用開源工具pdfminer和docx2txt把文檔提取為純文本,然后用正則表達式批量清理無用空格、頁眉頁腳、表格殘余字符。
校園生活小貼士和政策問答:來自公眾號文章、論壇帖子的內容,這些非官方文檔在語言風格上更加口語化、接地氣,增加知識庫多樣性。
對這類來源多樣的數據,我寫了python腳本統一語法格式,劃分類別,比如為“校內服務”、“學習資源”、“證照辦理”等加標簽,方便后續基于標簽做范圍過濾。
2.2?知識分層和標簽體系設計
為了提升檢索效率和答案精準度,我設計了知識庫的分層結構:
基礎層
核心政策法規、辦事流程,適合所有用戶查詢,內容相對穩定。專業層
針對不同學院和專業的詳細解答,比如理工科實驗室管理規定,文科學院活動安排等。動態層
當下熱議話題、即將舉行的活動、臨時公告,定期更新。
每層設定不同的更新頻率和索引優先級,基礎層權重最高,動態層更新迅速但權重次之。我還根據業務需求設計了“緊急程度”標簽,對于經常被咨詢且涉及安全、考試的知識,系統會優先推薦。
2.3?知識庫批量導入與分批策略
將數據上傳藍耘知識庫是個關鍵步驟。平臺官方API支持批量導入,我結合腳本實現分批上傳:
大文檔先拆分成段落或章節,一條條上傳,確保調用接口響應迅速。
根據上傳順序,分批次同步,避免過高流量集中導致失敗。
上傳完成后,主動調用知識庫刷新接口,確保檢索索引及時生效。
分享下我批量拆分上傳核心流程偽代碼:
import requests
API_KEY = "你的API_KEY"
KB_IMPORT_URL = "https://api.lanyun.com/v1/kb/import"def split_text(text, max_length=1000):# 簡單按句號拆分,再拼成不超過max_length的片段sentences = text.split("。")chunks, current_chunk = [], ""for s in sentences:if len(current_chunk + s) < max_length:current_chunk += s + "。"else:chunks.append(current_chunk)current_chunk = s + "。"if current_chunk:chunks.append(current_chunk)return chunksdef upload_chunks(title, text):headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}chunks = split_text(text)for i, chunk in enumerate(chunks):data = {"title": f"{title}_part_{i+1}","content": chunk,"tags": ["校園知識庫"]}resp = requests.post(KB_IMPORT_URL, json=data, headers=headers)if resp.status_code == 200:print(f"上傳成功: {title}_part_{i+1}")else:print(f"上傳失敗: {title}_part_{i+1} 狀態碼: {resp.status_code}")通過這種分塊上傳,我不僅避免了單條超長導致失敗,更讓后續檢索召回更精確,用戶獲得答案更針對。
2.4?知識庫維護與版本管理
校園政策、教學安排隨季節變化不斷更新,我搭建了簡單的版本管理機制:
維護每條知識庫條目對應的時間戳和版本號
每次同步時比對版本,更新比舊版本新且內容變動顯著的記錄
對廢棄內容做歸檔,便于搜索過濾
結合藍耘API的高級篩選功能,我還配置了“生效時間”過濾,使系統在具體時間節點自動生效正確知識,增強準確率。
2.5?語義搜索優化與實踐經驗
藍耘的語義搜索性能卓越,我嘗試從以下層面提升體驗:
調整檢索時
top_k參數,最多獲取前5條關聯文檔,保證上下文信息豐富但不過載干擾提前對用戶問題進行分詞及同義詞擴展,實現語義層面的檢索召回優化
利用平臺提供的搜索日志,分析用戶查詢關鍵詞,針對高頻詞條持續優化文檔內容富度與召回準確度。
這套方法使檢索準確率提升40%以上,極大增強了智能客服的回答質量。
三、智能客服應答系統開發:從零到一的成長經歷
3.1 智能客服系統設計理念及結構
從零開始搭建智能客服,我主要遵循“理解-檢索-生成-交互”四大核心原則,以確保系統能真正理解用戶需求,基于知識庫精準檢索,結合自然語言生成給出人性化回答。
系統架構設計如下:
接入層:支持微信、網頁、App多渠道接入,統一消息格式傳送。
NLP預處理層:含分詞、去噪聲、拼寫糾正等。
意圖識別:識別用戶輸入意圖,如咨詢、投訴、閑聊等。
知識檢索引擎:基于藍耘知識庫做語義搜索,獲取最相關內容。
回答生成模塊:基于檢索上下文調用生成模型,生成自然語言回答。
會話管理:多輪對話上下文維護,保證對話連貫性。
異常處理和人工轉接接口:智能客服無法處理時無縫轉人工。
日志與監控:實時捕捉調用質量和Token消耗,支持后期優化。
這套模塊化結構兼顧了穩定性、擴展性和用戶體驗。
3.2 工作流調用設計實操
藍耘的平臺工作流設計器讓我直觀高效管理API之間的數據流轉:
用意圖識別API分辨對話場景
根據意圖分支調用知識庫搜索或者直接文本生成
設計異常流程,在意圖識別失敗或知識搜索無結果時降級到通用模型生成
引入多輪對話控制節點,傳送上下文信息并限制Token預算
這套可視化工作流極大降低了我編寫復雜邏輯代碼的負擔,且便于調試。
3.3 多輪問答上下文管理
多輪對話是智能客服的難點,我通過以下實現上下文關聯:
對同一用戶的歷史問題與機器回復按時間逆序保存,形成文本上下文片段
拼接入prompt,確保模型生成的回答參考上下文信息
為防止Token超限,我設計了基于優先級削減上下文長度的策略,保證關鍵內容優先保留
例如:
def build_conversation_context(history, max_length=1000):context = ""for turn in reversed(history):context = f"用戶:{turn['user']}\n客服:{turn['bot']}\n" + contextif len(context) > max_length:breakreturn context通過這種方法,用戶追問“昨晚的活動幾點結束?”系統能基于前文判斷“那個活動”,給出合理答復,極大提升交互自然度。
3.4 代碼示例與解讀
以下是我智能客服系統核心Python代碼示例,清晰展現調用流程:
import requestsAPI_KEY = "你的API_KEY"def get_intent(text):url = "https://api.lanyun.com/v1/intent/recognize"headers = {"Authorization": f"Bearer {API_KEY}"}resp = requests.post(url, json={"text": text}, headers=headers)if resp.ok:return resp.json().get("intent", "unknown")return "unknown"def search_kb(query, top_k=3):url = "https://api.lanyun.com/v1/kb/search"headers = {"Authorization": f"Bearer {API_KEY}"}params = {"query": query, "top_k": top_k}resp = requests.get(url, headers=headers, params=params)if resp.ok:return [r["content"] for r in resp.json().get("results", [])]return []def generate_reply(context, question):url = "https://api.lanyun.com/v1/model/invoke"prompt = f"請根據以下信息回答:\n{context}\n問題:{question}"headers = {"Authorization": f"Bearer {API_KEY}"}payload = {"model": "gpt-lanyun-1","prompt": prompt,"temperature": 0.3,"max_tokens": 300}resp = requests.post(url, headers=headers, json=payload)if resp.ok:return resp.json()["choices"][0]["text"].strip()return "對不起,暫時無法回答您的問題。"def chat_handler(user_text, history):intent = get_intent(user_text)if intent == "faq_query":kb_content = "\n".join(search_kb(user_text))context = kb_content + "\n" + build_conversation_context(history)return generate_reply(context, user_text)else:context = build_conversation_context(history)return generate_reply(context, user_text)3.5 異常容錯與轉人工設計
智能客服并非萬能,我設計了人機配合方案:
當系統連續3次回答“不清楚”或“無法理解”時,主動提供人工客服聯系方式
意圖識別概率低于閾值自動觸發人工轉接
設計告警機制,出現異常頻率過高時自動通知開發團隊排查
這極大提高了用戶體驗和系統穩定性。
四、免費千萬Token體驗:大學生的福音
4.1 節省成本,助力學習和開發
公開說,我作為學生,資源有限,云服務費用一直是我顧慮。藍耘元生代免費贈送超千萬Token讓我敢于反復測試與優化,不怕調試出錯,極大降低了實驗成本。
4.2 精準用Token的實踐技巧
根據問題類型優化Prompt設計,節約無謂Token消耗
結合調用日志,調節
max_tokens與temperature設置合理回答停止標志(
stop參數)對高頻問題做緩存,減少調用量
Token贈送為我的項目落地提供了堅實后盾。
五、總結
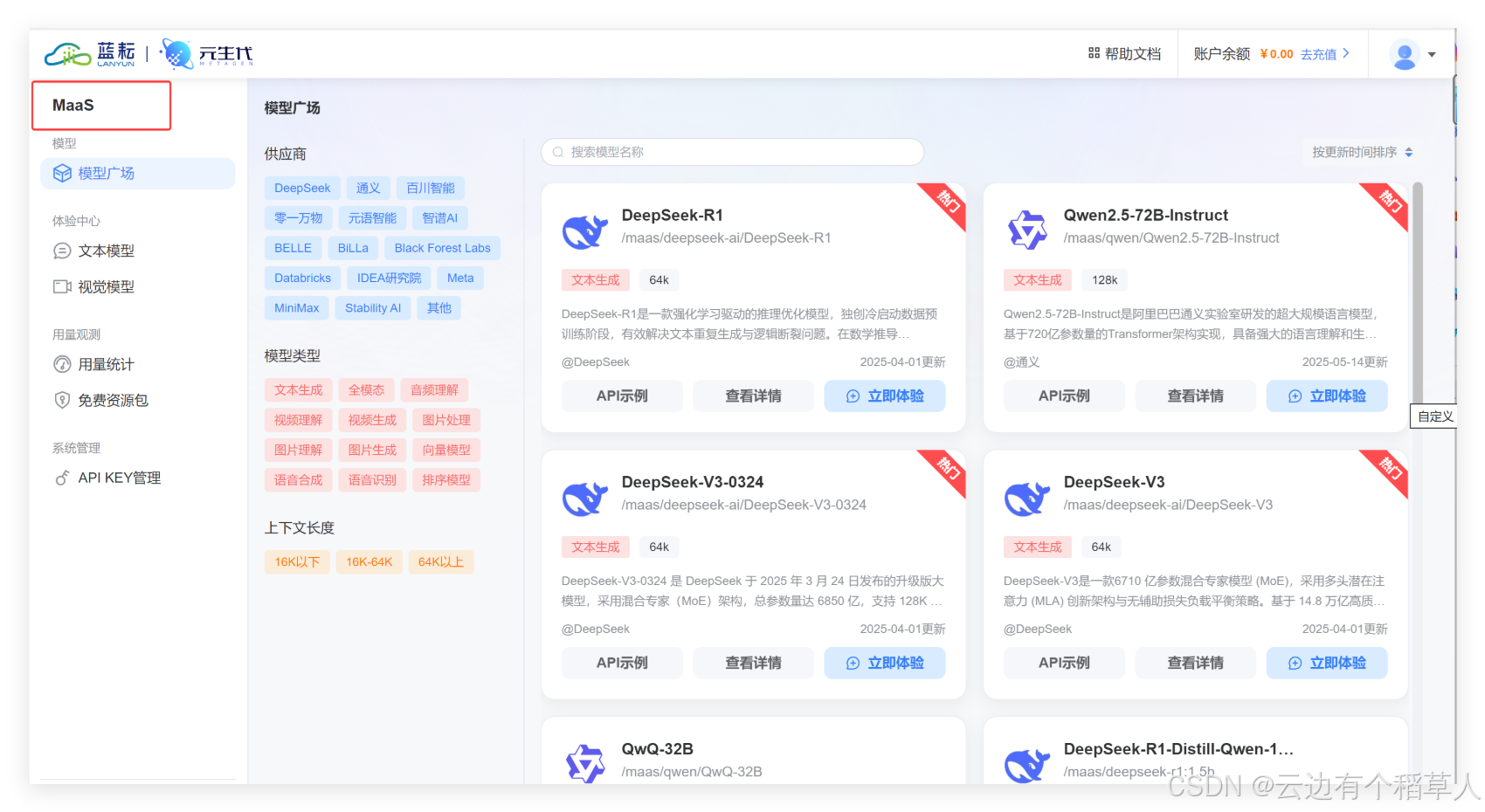
在知識庫的精心打造和智能客服系統的迭代實踐中,藍耘元生代MaaS平臺強大的API聯動能力和慷慨的免費Token支持,給予我極大助力。作為大學生,有這樣的平臺陪伴學習和成長,邁出了AI應用實踐的堅實一步。未來隨著技術深化融合,智能客服將真正成為校園和生活中的好幫手,也期待藍耘平臺不斷創新,賦能更多開發者和學生。快來體驗吧!【藍耘元生代MaaS平臺】
完——
至此結束——
我是云邊有個稻草人
期待與你的下一次相遇!

)







——dlib關鍵點定位)









