25年5月來自UC Berkeley 和 TRI 的論文“Real2Render2Real: Scaling Robot Data Without Dynamics Simulation or Robot Hardware”。
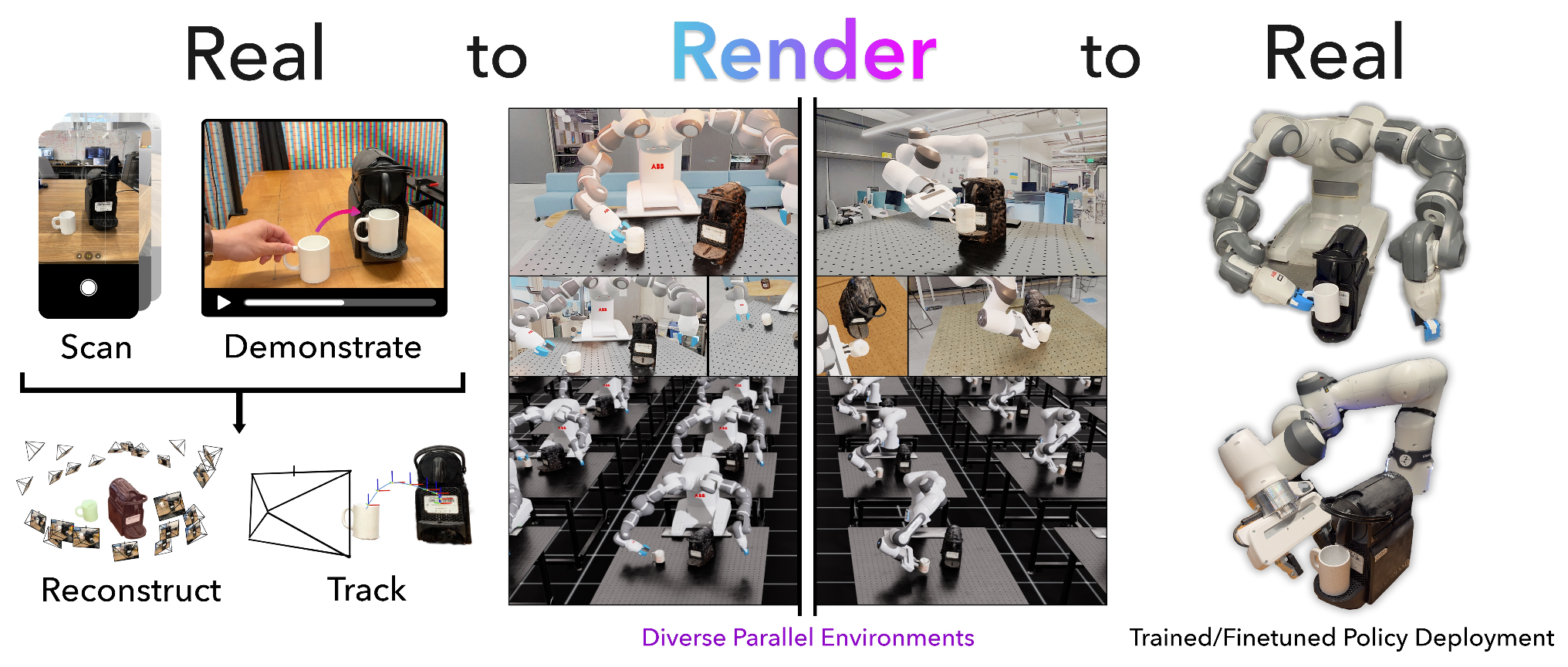
擴展機器人學習需要大量且多樣化的數據集。然而,現行的數據收集范式——人類遙操作——仍然成本高昂,且受到手動操作和機器人物理訪問的限制。Real2Render2Real (R2R2R),這是一種無需依賴目標動力學模擬或機器人硬件遙操作即可生成機器人訓練數據的新方法。輸入是智能手機拍攝的一個或多個目標的掃描圖像以及一段人類演示的視頻。R2R2R 通過重建詳細的 3D 目標幾何形狀和外觀并跟蹤 6-DoF 目標運動,渲染數千個高視覺保真度、與機器人無關的演示。R2R2R 使用 3D 高斯濺射 (3DGS) 為剛性和鉸接式目標實現靈活的資源生成和軌跡合成,將這些表示轉換為網格,以保持與 IsaacLab 等可擴展渲染引擎的兼容性,但需關閉碰撞建模。 R2R2R 生成的機器人演示數據可直接與基于機器人本體感受狀態和圖像觀察的模型集成,例如視覺-語言-動作模型 (VLA) 和模仿學習策略。物理實驗表明,基于單次人類演示的 R2R2R 數據訓練的模型,其性能可媲美基于 150 次人類遙操作演示訓練的模型。
機器人技術長期以來受益于計算可擴展性——概率規劃、軌跡優化和強化學習等方法推動了敏捷運動的重大進步 [1, 2, 3, 4, 5, 6, 7]。然而,靈巧操作面臨著獨特的挑戰:它需要與機器人控制和運動學緊密結合的細粒度視覺感知,以便與目標交互并改變環境。許多系統通過明確地將感知與規劃和控制分離來解決這個問題,并在結構化環境中實現了強大的性能 [8, 9, 10, 11],尤其是在場景幾何、目標位置和感知模態假設成立的情況下。然而,此類流程通常依賴于特定于任務的感知模塊和嚴格控制的環境,從而限制了在非結構化、動態或視覺多樣化環境中的靈活性。
為了解決開放世界操控任務,受大語言模型 (LLM) 和視覺語言模型 (VLM) [12, 13, 14, 15] 的啟發,近期研究者們探索了端到端的通用機器人策略 [16, 17, 18, 19, 20, 21, 22, 23, 24, 25]——這些模型直接從原始感官輸入中學習,并有望實現語言指令遵循、任務遷移和上下文學習等功能。然而,大規模訓練此類模型仍然受到數據的限制:最大的人類遙操作數據集比用于訓練前沿 LLM 和 VLM 的語料庫小 10 萬倍以上 [26, 27],并且受到成本、速度以及人類遙操作數據收集的個體特異性等因素的限制。
其他視覺語言子領域也面臨著類似的數據稀缺問題,并通過計算數據生成來克服這一問題。運動結構恢復、檢測和深度流程如今通常會生成偽標簽來引導大模型;例如,SpatialVLM 合成了 20 億個空間推理問答對 [28],而 RAFT [29]、DUSt3R [30]、MonST3R [31]、Zero-1-to-3 [32] 和 MVGD [33] 均依賴于從多視圖幾何流程(例如 COLMAP [34])獲取的偽真實值來監督密集的 3D 預測任務。這些成功案例為機器人技術提出了一個類似的問題:
能否在不需要動力學模擬或人類遙操作的情況下,以計算方式擴展機器人視覺-動作數據來訓練機器人學習模型?
之前的研究轉向基于物理的模擬,其中軌跡是通過強化學習或在虛擬環境中進行運動規劃來合成的 [35, 36, 37]。雖然現代模擬器提供高吞吐量并支持大規模并行化,但它們面臨著幾個根本性的限制:許多常用的模擬器無法滿足基本的拉格朗日力學,例如能量或動量守恒 [38];準確建模復雜的目標相互作用通常需要大量的參數調整和接觸屬性的手工設置 [39];生成高質量、兼容且無交叉的模擬資產仍然是一項勞動密集型的工作,因為碰撞建模需要仔細處理幾何形狀、摩擦和變形 [40, 41]。
機器人數據收集范式。擴展機器人學習傳統上依賴于兩種范式:來自工業部署的數據和來自人類遙操作的數據。工業機器人日志 [43, 44, 45] 隨著生產吞吐量的增加而擴展,但通常特定于任務和具體實施方式。相比之下,遙操作數據集 [46, 47, 48, 49, 50] 提供了更豐富的視覺和任務多樣性,但仍然受到人力和實時收集的瓶頸制約。與此同時,通用機器人策略 [16, 19, 51, 17, 18, 20, 21, 22, 23, 24, 25] 的興起——能夠根據原始觀察結果執行各種操作任務——放大了對可擴展、多樣化和高質量訓練數據的需求。然而,當前機器人數據集的規模仍然比視覺和語言數據集 [26, 27] 低幾個數量級。
程序化機器人數據生成。為了應對機器人數據擴展的挑戰,許多研究都研究了程序化數據生成,以便自動化機器人數據收集,從而完成預定義任務。許多研究 [52、53、54、55、56、57] 使用預定義的運動原語(可選搭配感知模塊)來實現使用真實機器人的自動化數據收集,并自動重置場景。雖然減少了人為干預,但它們仍然需要機器人硬件進行數據收集,從而限制了可擴展性。最近,模擬數據生成已成為現實世界數據收集的一種可擴展替代方案,它無需物理機器人硬件即可并行生成數據。利用來自模擬器的專有信息,Mahler [10] 為機器人抓取生成了大量且多樣化的數據。Katara [35] 和 Wang [36] 使用強化學習、軌跡優化和運動規劃在模擬中生成大規模機器人數據。MimicGen [58] 結合運動規劃和軌跡重放,從單個人類遙操作序列合成各種模擬。盡管人們努力通過域隨機化 [59]、改進的資源和場景生成 [35, 36] 來彌合模擬與現實之間的差距,但由此產生的模擬數據通常與現實世界的觀察結果存在顯著的視覺差異,需要使用真實數據進行協同訓練才能實現有效的遷移 [60]。
真實-到-合成的數據生成。為了彌合這種視覺領域的差距,一些研究增強并重新利用真實的 RGB 數據,而不是從頭合成。例如,Chen [62] 使用生成模型將機器人的具象特征修復到真實圖像中,從而實現了不同形態機器人的數據合成。然而,此類方法在初始演示中仍然需要人類遙操作。此外,它們缺乏生成除提供的演示之外的其他多樣化軌跡的能力。同樣,Lepert [64] 和 Duan [66] 使用手勢追蹤來引導從人類演示中修復的機器人末端執行器軌跡。雖然這些方法減少了對直接遙操作的需求,但它們通常每個視頻僅生成一條軌跡,并且缺乏對計算規模的軌跡多樣性的支持。相比之下,R2R2R 可以從單個人類演示中生成多個不同的機器人軌跡渲染和動作展示。僅使用 R2R2R 生成的數據訓練的策略,其真實世界性能與使用人類遙操作數據訓練的策略相當。
Real2Sim2Real 數據生成。為了從單個演示生成不同的軌跡,同時彌合模擬與現實之間的差距,許多方法遵循 Real2Sim2Real 范式——使用現實世界的觀察結果來構建用于策略學習的模擬環境。先前的研究 [67] 表明,調整物理參數可以減少動態失配,但較大的視覺域差距仍然需要測試-時感知模塊。近期的方法 [37, 68, 38, 63] 通過從真實掃描中構建數字孿生或“數字表親”[69] 來縮小這種視覺差距。這些方法在對遙操作、模擬和軌跡多樣性的依賴程度上各不相同,但許多方法仍然依賴于遙操作演示、手動設計的獎勵或精確的物理模型,從而限制了可擴展性。例如,DexMimicGen[63] 使用固定的模擬資源;RoboVerse [38] 僅支持剛體;而 RialTo [70] 和 CASHER [39] 則需要手動標注關節和進行獎勵工程。雖然 Video2Policy [37] 避免了通過視覺語言模型進行獎勵調整,但由于視覺不匹配,它仍然需要測試-時目標檢測。這些流程還依賴于物理引擎,這需要高保真網格進行碰撞檢查和廣泛的調整。RoboGSim [61] 避免模擬,但缺乏對單個演示中軌跡多樣性的支持。
相比之下,Real2Render2Real (R2R2R) 通過以下方式解決了這些限制:(1)從人類視頻中提取目標軌跡,(2)自動分割目標部分,(3)渲染逼真的觀察結果以消除對測試-時感知的依賴,(4)消除對碰撞建模和詳細網格的需要,以及(5)從單個演示中生成多樣化的軌跡。
R2R2R 通過舍棄動力學來避免這些挑戰:沒有模擬力或接觸,而是使用 IsaacLab 包 [42] 直接設置每幀的目標和機器人姿態,純粹將其作為一個逼真的并行渲染引擎,將所有目標設置為運動體而非動態體。這種方法尊重機器人運動學,同時避免接觸建模的復雜性,自然地與從 RGB 圖像和本體感受輸入訓練的基于視覺的策略保持一致。
R2R2R 是一種用于從智能手機目標掃描和人類演示視頻生成大規模合成機器人訓練數據的流程。R2R2R 在保持視覺精度的同時擴展軌跡多樣性:它使用目標姿態追蹤從視頻中提取 6 自由度目標部件軌跡,并在隨機目標初始化下通過微分逆運動學(IK)生成相應的機器人執行。從多視角掃描開始,它重建 3D 目標幾何形狀和外觀,通過部件級分解支持剛體和鉸接體,并使用 3D 高斯濺射 (Gaussian Splatting) 生成網格資源。生成的軌跡包括機器人本體感受、末端執行器動作以及在不同光照、相機姿態和目標位置下渲染的成對 RGB 觀測值,使其與現代模仿學習策略(例如視覺-語言-動作模型和擴散模型)直接兼容。
通過消除對動力學模擬或機器人硬件的需求,R2R2R 實現了可訪問且可擴展的機器人數據收集,任何人都可以通過使用智能手機捕捉日常目標交互來做出貢獻。
R2R2R 由三個主要階段組成:(1)真實-到-模擬的資產和軌跡提取,從現實世界的智能手機捕獲中提取剛體或鉸接式體的幾何形狀和部分軌跡;(2)增強,其中目標初始化是隨機的,并且在適當的情況下插入目標運動軌跡;(3)并行渲染,其中使用 IsaacLab [42] 生成各種逼真的機器人執行,并可根據可用的 GPU 內存量和 GPU 數量進行擴展。
如圖所示:Real2Render2Real 為“將杯子放在咖啡機上”的任務生成機器人訓練數據。R2R2R 將多視角目標掃描和單目人體演示視頻作為輸入。然后,R2R2R 通過并行渲染合成多樣化、域隨機化的機器人執行,并輸出配對的圖像動作數據用于策略訓練。該流程無需遙操作或目標動力學模擬,即可實現跨任務和不同場景的可擴展學習。
1. 真實-到-模擬的資產提取
采用受 [71, 72] 啟發的兩階段流程,從智能手機掃描中提取 3D 目標資產。首先,使用 3D 高斯濺射 (3DGS) [73] 重建目標的幾何形狀和外觀,然后應用 GARField [74] 將場景分割成語義上有意義的部分,即通過將二維掩碼提升到三維。這實現了目標級和部件級的分解,包括關節式組件。為了支持基于網格的渲染,生成的高斯組通過 [75] 的擴展版轉換為帶紋理的三角形網格。
如圖所示 3DGS 的目標重建:

2. 真實-到-模擬軌跡提取
給定一段智能手機上人類操作掃描目標的視頻,R2R2R 使用 [71] 中提出的四維可微分部件建模 (4D-DPM) 提取目標及其部件的 6 自由度部件運動。每個 3DGS 目標部件都嵌入預訓練的 DINO 特征,從而能夠通過可微分渲染實現部件姿態優化。本文擴展 [71] 的實現,使其能夠跟蹤演示視頻中的單個或多個剛體以及鉸接體。
雖然有許多替代流程可以將真實圖像轉換為 3D 資源,但本文采用 3DGS -到-網格的轉換,主要有兩個原因:(1) 它能夠通過 3D 分組實現背景-前景分割和部件分解 [74],這對于從單目人體演示中提取特定于目標部件的軌跡至關重要; (2) 它兼容 4D-DPM 軌跡重建和基于網格的渲染引擎,可無縫集成到大規模渲染流程中。此過程無需任何基準點或除智能手機攝像頭之外的硬件,非常適合用于可擴展且易于訪問的真實-到-模擬數據生成。
目標軌跡多樣性的插值方法:Real2Render2Real 的一項關鍵貢獻是能夠從單個人體演示中合成多個有效的 6-DoF 目標軌跡。對于多個相互作用的剛體(例如,將杯子放在咖啡機上),原始演示僅對特定的初始目標配置有效,而簡單地從新的初始姿勢重放該演示將失敗。為了解決這個問題,本文引入一套軌跡插值和重采樣技術,使原始軌跡能夠適應新的起始和結束姿勢,同時保留其語義意圖。
從一條參考軌跡 τ 開始,該軌跡 τ 由演示視頻中部件跟蹤提供的 T 個航點組成,每個航點編碼一個目標方向(四元數)和位置。給定一個新的初始姿態 x_start,以及來自人類演示的期望最終姿態x_end,應用空間歸一化,將原始軌跡變換到正則空間。計算原始和目標端點姿態之間的仿射變換,將其應用于軌跡的平移分量,并使用球面線性插值(Slerp)對關鍵幀方向進行插值。這將生成一條新的軌跡 τ′,其起點和終點均為期望姿態,同時保留原始運動的結構。雖然這些軌跡保留高級語義意圖,但它們的生成沒有明確的避撞機制,并且在遮擋目標后初始化時可能會導致路徑不可行。為了緩解這個問題,應用一種采樣啟發式方法,使初始位置的分布偏離目標姿態(如圖所示)。

抓握姿勢采樣:R2R2R 使用 [76] 從演示視頻中估算手部 3D 關鍵點,然后通過計算關鍵點(食指尖和拇指)與所有分割目標部件質心之間的歐氏距離來確定目標與手的相互作用。這將生成一個隨時間和目標部位索引的距離矩陣。將整個軌跡上總距離最小的部位定義為被抓握的部位,從而有效地在整個演示過程中選擇最接近手部的目標。為了生成物理上合理的抓握,對 3DGS 均值進行采樣以構建更粗的三角形網格(不同于高分辨率渲染網格),應用表面平滑和抽取以獲得一致的法線,并使用遵循 [10] 的解析對映(antipodal)抓握采樣器來確定候選抓握軸。對于雙手任務,每只手獨立應用此過程以推斷單獨的目標關聯和抓握動作,從而支持諸如抬起或穩定等協調動作。
微分逆運動學:對于每個抓取和目標軌跡對,用 PyRoki [77] 求解微分逆運動學問題。求解器計算平滑的關節空間軌跡,這些軌跡會在抓取前、抓取中和抓取后階段誘導出所需的目標運動。至關重要的是,本文方法不需要對目標動力學進行建模或模擬物理相互作用。假設目標在接觸過程中嚴格遵循軌跡運動,而不是像動態模擬那樣求解會物理誘導目標運動的關節扭矩。這種運動學假設避免了接觸建模、柔順性或摩擦力估計等挑戰。求解器只需確保機器人運動學能夠跟蹤受關節位置限制的所需目標運動,并且在抓取前和抓取后階段,額外添加平滑度和速度限制約束,從而生成有效的抓取接近運動。
渲染多樣化環境上下文:為了提高魯棒性,在場景幾何和渲染參數方面應用了廣泛的域隨機化。這包括隨機光照條件(例如強度、色溫)、相機外參(均勻采樣,最多可進行 2 cm 平移和 5° 旋轉)以及目標初始姿態(在工作空間相關范圍內采樣)。通過對以目標為中心的 3D 表示進行建模,可以在渲染過程中直接應用這些增強功能。相機姿態或光照的變化不會影響底層的運動學展開,從而使 R2R2R 能夠從單個演示中生成不同的視覺上下文。這些增強功能通過縮小合成演示與實際部署之間的外觀差距和協變量漂移來擴展數據分布并提高泛化能力。
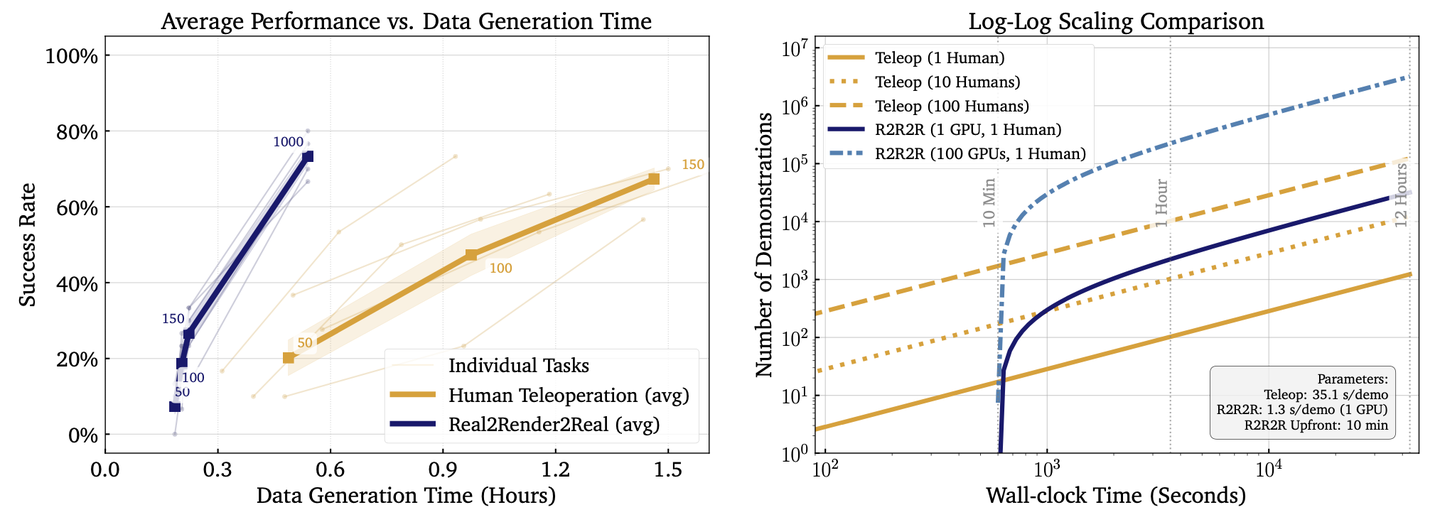
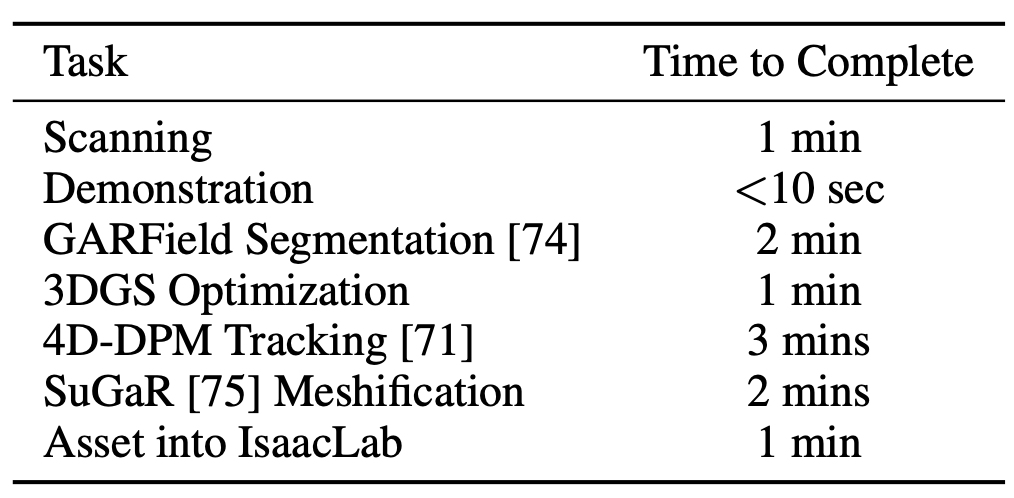
高吞吐量渲染:IsaacLab [42] 使用基于 tile 的渲染、深度學習超級采樣 (DLSS) 和網格資源實例化,支持 GPU 并行執行多個環境上下文。在單塊 NVIDIA RTX 4090 上,R2R2R 使用 IsaacLab 框架以平均每分鐘 51 次演示的速度渲染完整的機器人演示(而人類遙操作每分鐘僅 1.7 次演示),速度提升超過 27 倍。如圖所示,吞吐量與渲染 GPU 的數量呈線性關系。每個任務的數據生成/收集時間見下表。
3. 策略學習
考慮兩種現代模仿學習架構:擴散策略[20]和 π0-FAST [78]。以4個時間步長的本體感覺歷史和448px的RGB觀測數據為條件,從頭開始訓練擴散策略10萬步,以迭代去噪SE(3)中的16個未來絕對末端執行器姿態。用低秩自適應(LoRA)[79](秩 = 16)對 π0-FAST 進行3萬步微調,該方法采用單張224px的方形圖像(以匹配預訓練分辨率)并預測10步相對關節角度動作塊。在單臺NVIDIA GH200上訓練擴散策略大約需要3個小時,而π0-FAST微調則需要11個小時。部署時,兩個模型均接收原始 RGB 圖像和機器人本體感覺——擴散模型中 SE(3) 絕對末端執行器位姿,π0-FAST 模型中為關節位置——并輸出相應的動作目標。為了提高不同時間步預測動作之間的時間一致性,在兩個模型的執行過程中對預測的動作塊應用時間集成 [23]。
擴散策略的超參:
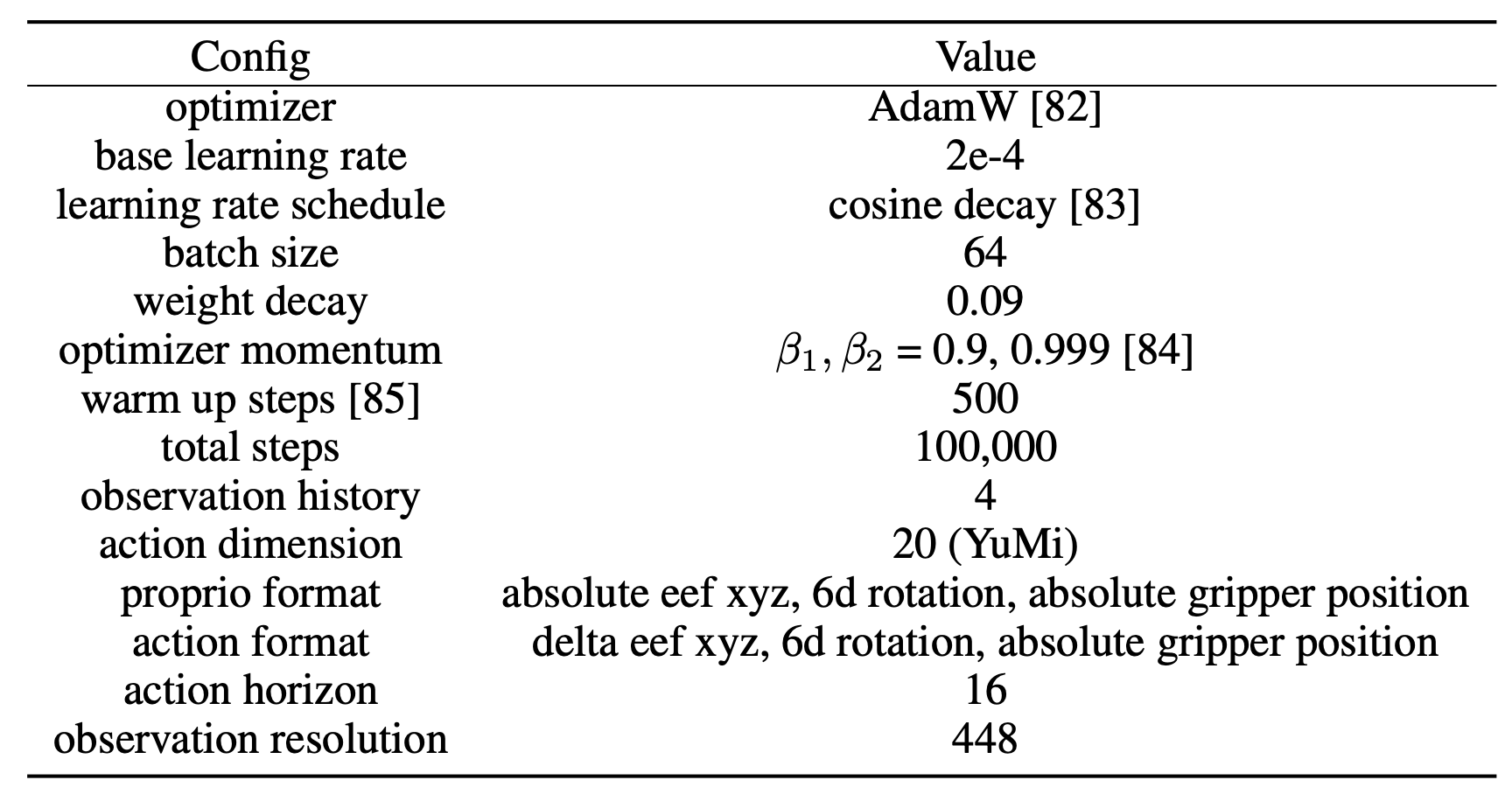
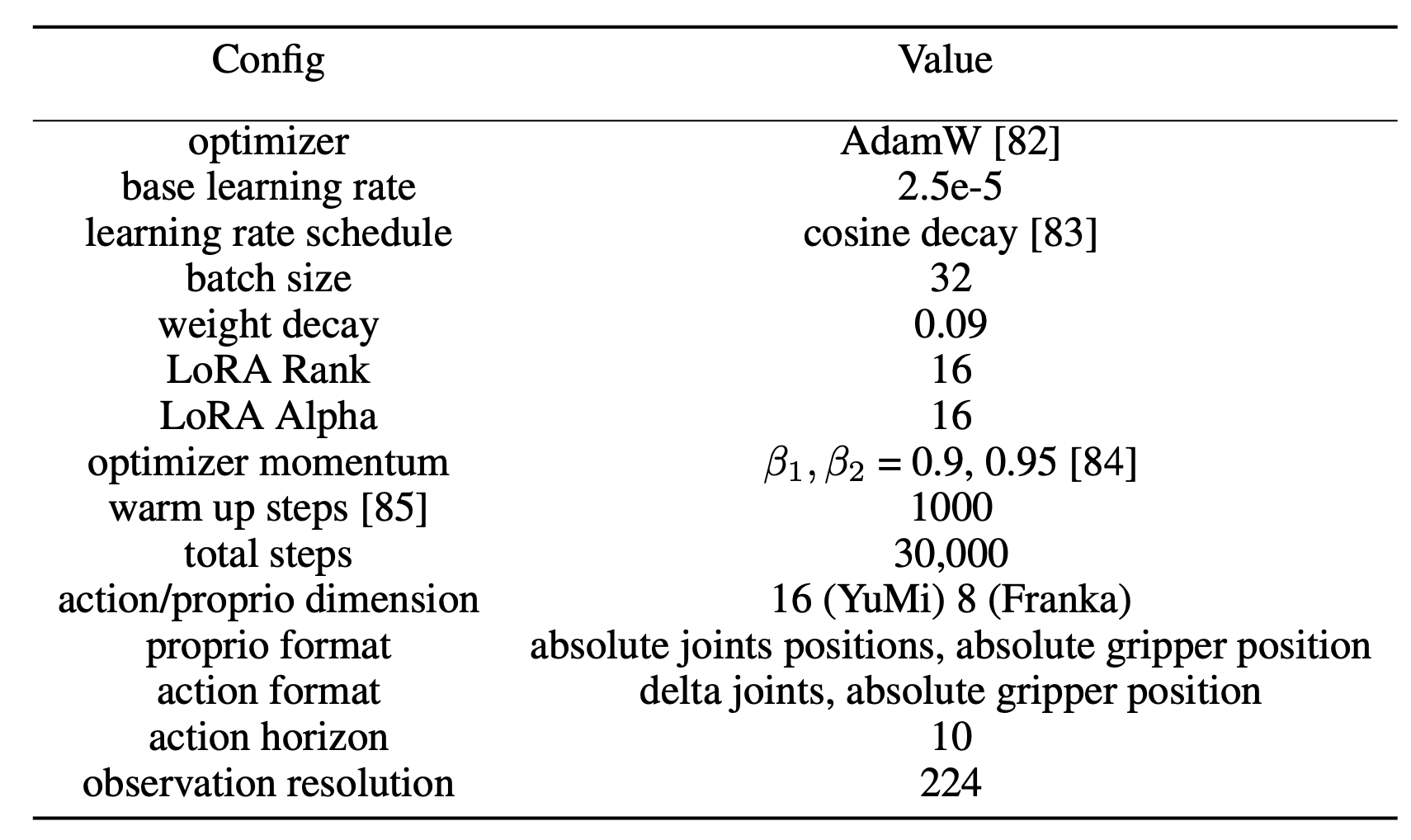
π0-FAST 的超參:










)








