目錄
1.std::list::splice的使用
2.std::list::remove和std::list::remove_if的使用
2.1remove_if函數的簡單介紹
基本用法
函數原型
使用函數對象作為謂詞
使用普通函數作為謂詞
注意事項
復雜對象示例
2.2remove與remove_if的簡單使用
3.std::list::unique的使用
3.1std::list::unique的第二個函數的簡單介紹
基本語法
基本示例
使用函數對象作為謂詞
處理自定義類型
注意事項
3.2std::list::unique函數的使用
4.std::list::merge的使用
5.std::list::sort函數以及std::swap(list)的使用
6.C++迭代器(非常重要)
1. 輸入迭代器 (input_iterator_tag)
2. 輸出迭代器 (output_iterator_tag)
3. 前向迭代器 (forward_iterator_tag)
4. 雙向迭代器 (bidirectional_iterator_tag)
5. 隨機訪問迭代器 (random_access_iterator_tag)
6.每個容器所對應的迭代器以及注意事項
1. 序列容器 (Sequence Containers)
std::array
std::vector
std::deque?(雙端隊列)
std::list?(雙向鏈表)
std::forward_list?(單向鏈表)
2. 關聯容器 (Associative Containers)
std::set/std::multiset
std::map/std::multimap
3. 無序關聯容器 (Unordered Associative Containers)
std::unordered_set/std::unordered_multiset
std::unordered_map/std::unordered_multimap
4. 容器適配器 (Container Adaptors)
std::stack?和?std::queue
特殊迭代器
std::string
std::string_view
迭代器類別對算法的影響
7.簡單解釋
7.總結

1.std::list::splice的使用
該函數是list新增的一個函數,所以需要進行額外的講解:

splice這個函數翻譯過來是:拼接、粘接的意思,也就是說可以在該list對象的position位置粘接一部分東西,但是它必須是另外一個list對象的一部分或者全部,這里是它的每個函數的用法簡介:

所以說這個函數的功能還是比較多的,但是這個位置position我們需要注意:這個position我們不能直接和vector和string那樣寫的,所以我們如果拼接數據不是在頭部或者尾部的情況下我們不能用l1.begin()+n的方式,因為這種方式是沒定義的。我們可以用之前我們學過的insert的那種方式,這里講解一下如何使用:
第一個函數的使用:
//splice函數的使用
int main()
{list<int> l1({ 4,2,4,2,1,3,5,6,0,9 });list<int> l2({ 6,3,1,8,0 });cout << "l1粘接之前:";for (const auto& e : l1){cout << e << " ";}cout << endl;cout << "l2粘接之前:";for (const auto& e : l2){cout << e << " ";}cout << endl;//(1)//不能這樣寫//l2.splice(l1.begin() + 1, l1);//會在迭代器的分類里面講到//list是雙向迭代器,只支持++、--//只有隨機迭代器支持+、-操作//我們之前學過的那些string和vector都是隨機迭代器,可以使用//要這樣寫auto i1 = std::next(l1.begin(), 1);l1.splice(i1, l2);cout << "l1第一次粘接之后:";for (const auto& e : l1){cout << e << " ";}cout << endl;cout << "l2第一次粘接之后:";for (const auto& e : l2){cout << e << " ";}cout << endl;return 0;
}那么最終運行結果為:
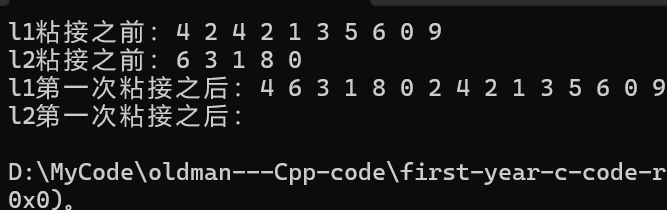
但是如果我們想要插入尾結點那么就不能l1.end()了,因為
l1.end()?是指向?尾后位置(one-past-the-last element)?的迭代器,它并不指向任何實際元素。根據C++標準:
-
splice?函數(第三個重載函數)的第三個參數(要剪切的元素位置)必須指向一個有效的元素 -
end()?迭代器不指向任何實際元素,因此不能用于剪切操作
所以我們如果想插入尾結點不能直接l1.end(),而應該插入它前一個結點才是正確的,比如以splice第三個重載的使用為例。以下是splice第二個函數的使用:
#define _CRT_SECURE_NO_WARNINGS 1
#include<list>
#include<iostream>
using namespace std;
//splice函數的使用2
int main()
{list<int> l1({ 4,2,4,2,1,3,5,6,0,9 });list<int> l2({ 6,3,1,8,0 });cout << "l1粘接之前:";for (const auto& e : l1){cout << e << " ";}cout << endl;cout << "l2粘接之前:";for (const auto& e : l2){cout << e << " ";}cout << endl;//(2)//或者auto i2 = l2.begin();//l2的第四個位置粘接std::advance(i2, 3);//錯誤//l2.splice(i2, l1, l1.end());//正確l2.splice(i2, l1, std::prev(l1.end()));cout << "l1第二次粘接之后:";for (const auto& e : l1){cout << e << " ";}cout << endl;cout << "l2第二次粘接之后:";for (const auto& e : l2){cout << e << " ";}cout << endl;return 0;
}那么最終運行結果為:
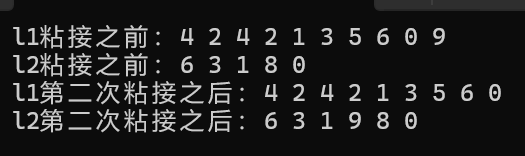
第三個函數的用法如下:
//splice函數的使用3
int main()
{list<int> l1({ 4,2,4,2,1,3,5,6,0,9 });list<int> l2({ 6,3,1,8,0 });cout << "l1粘接之前:";for (const auto& e : l1){cout << e << " ";}cout << endl;cout << "l2粘接之前:";for (const auto& e : l2){cout << e << " ";}cout << endl;//(3)//也可以auto i3 = l2.begin();//在l2的第四個位置開始粘接std::advance(i3, 3);l2.splice(i3, l1, l1.begin(), l1.end());cout << "l1第三次粘接之后:";for (const auto& e : l1){cout << e << " ";}cout << endl;cout << "l2第三次粘接之后:";for (const auto& e : l2){cout << e << " ";}cout << endl;return 0;
}那么最終運行結果如下:
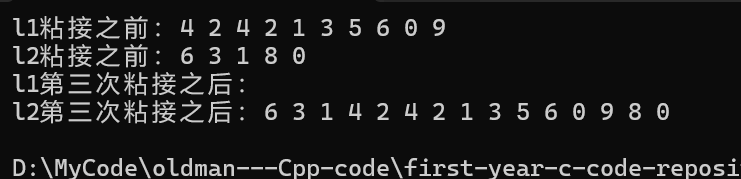
為什么這次沒報錯,因為:
-
splice?的范圍版本接受的是?[first, last)?半開區間 -
標準明確規定?
last?可以是?end()?迭代器 -
這表示"從 first 開始到容器末尾的所有元素"
而且基本上迭代器的last指針通常是不插入這個位置的數據的(可能沒有數據)。
可以看到:splice函數看似簡單,但是我們需要注意的地方還是比較多的,我們還是要注意它的用法,否則很容易報錯,而且我們在寫i1、i2的時候我們要注意如果i1指向l1的結點,那么就是l1.splice(i1,……),不然可能會報錯(自己粘接自己),如果是粘接一段迭代器區間,那么可以自己粘接自己!
2.std::list::remove和std::list::remove_if的使用

這個函數也是在list容器中新增的一個函數,所以需要額外介紹一下它用法,我們來看一下它的用法:

也就是說它可以刪除值為val的所有結點,在該函數的介紹中也能了解它的很多東西,所以這里就不做解釋了。

這個函數我們又有些看不懂了,如果按照正常思維,我們也應該是滿足值為val且滿足pred的條件就可以了,為什么這個是函數模板?我們來看一下它的介紹:

這個函數我們還是沒看懂它如何用的,那我們還是問一下deepseek吧!(以下是deepseek的生成結果,如果不想看的話可以跳到2.2)
2.1remove_if函數的簡單介紹
std::list::remove_if?是 C++ STL 中 list 容器的一個成員函數,用于根據特定條件移除列表中的元素。
基本用法
#include <list>
#include <iostream>int main() {std::list<int> numbers = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};// 移除所有偶數numbers.remove_if([](int n) { return n % 2 == 0; });// 輸出結果: 1 3 5 7 9for (int n : numbers) {std::cout << n << " ";}return 0;
}函數原型
template <class Predicate>
void remove_if(Predicate pred);-
red: 一元謂詞(接受一個元素作為參數并返回 bool 的函數或函數對象) -
返回類型: void(直接修改原列表)
使用函數對象作為謂詞
struct IsGreaterThan {int value;IsGreaterThan(int v) : value(v) {}bool operator()(int n) const { return n > value; }
};int main() {std::list<int> numbers = {5, 12, 3, 8, 15, 7};// 移除所有大于10的元素numbers.remove_if(IsGreaterThan(10));// 輸出結果: 5 3 8 7for (int n : numbers) {std::cout << n << " ";}return 0;
}使用普通函數作為謂詞
bool isNegative(int n) {return n < 0;
}int main() {std::list<int> numbers = {-2, -1, 0, 1, 2, -3};// 移除所有負數numbers.remove_if(isNegative);// 輸出結果: 0 1 2for (int n : numbers) {std::cout << n << " ";}return 0;
}注意事項
-
remove_if?會遍歷整個列表,時間復雜度為 O(n) -
被移除的元素會被銷毀,內存被釋放
-
與?
std::remove_if?算法不同,list 的成員函數?remove_if?會真正刪除元素,而不只是移動元素 -
在遍歷過程中修改列表是安全的,因為這是 list 的特性
復雜對象示例
#include <list>
#include <string>struct Person {std::string name;int age;
};int main() {std::list<Person> people = {{"Alice", 25},{"Bob", 17},{"Charlie", 30},{"David", 16}};// 移除所有未成年人(年齡<18)people.remove_if([](const Person& p) { return p.age < 18; });// 剩下的都是成年人for (const auto& p : people) {std::cout << p.name << " (" << p.age << ")\n";}return 0;
}std::list::remove_if?是一個高效的方式來根據條件刪除 list 中的元素,特別適合與 lambda 表達式結合使用。
2.2remove與remove_if的簡單使用
在剛剛的remove_if的眾多用法中我們只要掌握最基本的用法即可,建議還是傳遞一個返回值為bool的進去。簡單來說就是remove_if能刪除鏈表中若把鏈表所存儲的值代入結果為true的值,所以remove_if函數在之后的用法還是比較多的,至于那個基本用法中的[]……我們暫時用這種方式即可,它是Lambda表達式,這個感興趣的可以去搜索資料。
那么我在這里演示一下兩個函數的用法,兩個函數都是刪除鏈表中的一些元素:
#define _CRT_SECURE_NO_WARNINGS 1
#include<list>
#include<iostream>
using namespace std;
//remove和remove_if的使用
bool isou(int a)
{return a % 2 == 0;
}
int main()
{//removelist<int> l1({ 4,2,4,6,76,3,2,1,9,0,3,5 });cout << "remove之前:";for (const auto& e : l1){cout << e << " ";}cout << endl;l1.remove(3);cout << "remove之后:";for (const auto& e : l1){cout << e << " ";}cout << endl;//remove_iflist<int> l2({ 2,4,6,3,1,7,9,0,8,5,7 });cout << "remove_if之前:";for (const auto& e : l2){cout << e << " ";}cout << endl;l2.remove_if(isou);cout << "remove_if之后:";for (const auto& e : l2){cout << e << " ";}cout << endl;return 0;
}那么最終運行結果為:
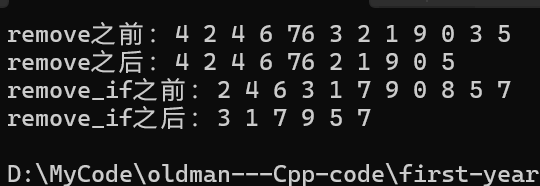
3.std::list::unique的使用

unique也是在string和vector之后新增的一個函數,我們可以通過它函數名的意思知道這個函數大概是什么意思,這個函數名字的中文的意思是單獨的,那么來看一下它的介紹吧:

也就是說它可以刪除連續的重復的元素,然后使每個結點與它的前后結點(除只有一個結點外)所存的值都不相同,這個函數也經常結合sort函數即排序后使用,所以這是第一個函數的用法;第二個函數和remove_if差不多,但是也有些不同,以下是deepseek的搜索結果:
3.1std::list::unique的第二個函數的簡單介紹
std::list::unique?的帶謂詞版本允許你自定義判斷相鄰元素是否"唯一"的標準,而不僅僅是簡單的相等比較。
基本語法
template <class BinaryPredicate>
void unique(BinaryPredicate binary_pred);-
binary_pred:一個二元謂詞(接受兩個元素作為參數并返回 bool 的函數或函數對象) -
功能:移除所有滿足?
binary_pred?的連續重復元素
基本示例
#include <list>
#include <iostream>int main() {std::list<int> numbers = {1, 2, 2, 3, 4, 4, 4, 5, 6, 6, 7};// 使用默認比較(operator==)numbers.unique();// 結果:1, 2, 3, 4, 5, 6, 7// 使用自定義謂詞 - 當兩數差的絕對值小于等于1時視為相同numbers = {1, 2, 4, 5, 7, 8, 10};numbers.unique([](int a, int b) { return std::abs(a - b) <= 1; });// 結果:1, 4, 7, 10return 0;
}使用函數對象作為謂詞
struct AreConsecutive {bool operator()(int a, int b) const {return b == a + 1;}
};int main() {std::list<int> nums = {1, 2, 4, 5, 7, 8, 10};nums.unique(AreConsecutive());// 移除后一個元素是前一個元素+1的相鄰元素// 結果:1, 4, 7, 10return 0;
}處理自定義類型
struct Person {std::string name;int age;bool operator==(const Person& other) const {return name == other.name && age == other.age;}
};int main() {std::list<Person> people = {{"Alice", 25},{"Alice", 25}, // 重復{"Bob", 30},{"Bob", 31}, // 不同{"Charlie", 40},{"Charlie", 40} // 重復};// 移除姓名和年齡完全相同的連續記錄people.unique();// 剩余: Alice(25), Bob(30), Bob(31), Charlie(40)// 自定義謂詞 - 只比較姓名people.unique([](const Person& a, const Person& b) {return a.name == b.name;});// 剩余: Alice(25), Bob(30), Charlie(40)return 0;
}注意事項
-
只移除連續重復項:
unique?只檢查相鄰元素,不相鄰的重復元素不會被移除std::list<int> nums = {1, 2, 1, 2, 1}; nums.unique(); // 不會有任何變化,因為沒有連續重復 -
謂詞要求:謂詞應該是等價關系(自反、對稱、傳遞的)
-
排序后再使用:如果需要移除所有重復項(不僅是連續的),應先排序
std::list<int> nums = {1, 2, 1, 2, 1}; nums.sort(); nums.unique(); // 結果: 1, 2 -
性能:時間復雜度為 O(n),因為 list 的迭代器是雙向的
-
與?
std::unique?的區別:-
std::list::unique?是成員函數,真正刪除元素 -
std::unique?是算法,只移動元素到容器末尾,不改變容器大小
-
這個帶謂詞的?unique?版本提供了極大的靈活性,讓你可以定義什么樣的元素應該被視為"重復"的。
3.2std::list::unique函數的使用
第二個重載的函數的參數與remove_if函數的不同就是:它所需要傳的參數需要兩個,因為這樣才滿足需要刪除的條件是什么,才好進行刪除。至于:

這個需要自己去搜索結果了,這里沒辦法細講!
知道了這么多,我在這里演示一下兩個函數的用法:
#define _CRT_SECURE_NO_WARNINGS 1
#include<list>
#include<iostream>
using namespace std;
//unique的使用
bool panduan(int a, int b)
{//判斷絕對值是否小于2//小于2則認為相同return abs(a - b) < 2;
}
int main()
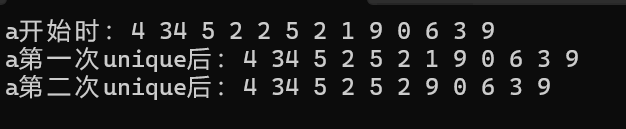
{list<int> a({ 4,34,5,2,2,5,2,1,9,0,6,3,9 });cout << "a開始時:";for (const auto& e : a){cout << e << " ";}cout << endl;a.unique();cout << "a第一次unique后:";for (const auto& e : a){cout << e << " ";}cout << endl;a.unique(panduan);cout << "a第二次unique后:";for (const auto& e : a){cout << e << " ";}cout << endl;return 0;
}那么運行結果為:
4.std::list::merge的使用

該函數還是list新增的一個函數,這里我們先看一下它的介紹:

這個函數用得很少,在這里就只演示用法即可(第一個是默認排成升序的,第二個是可以排成降序的):
#define _CRT_SECURE_NO_WARNINGS 1
#include<list>
#include<iostream>
using namespace std;
//merge的使用
int main()
{list<int> l1({ 3,4,52,5,1,9,90,8,7,3 });list<int> l2({ 4,2,4,6,2,1,8,0,2,6 });//先排序l1.sort();l2.sort();//(1)//再merge//merge后仍然是有序的l1.merge(l2);for (const auto& e : l1){cout << e << " ";}cout << endl;//(2)list<int> l3({ 5,6,3,2,4,9,20,97 });//排成降序不能這樣寫//l3.sort();//我們想要排成降序就這樣寫(了解基本用法,之后會講)greater<int> gt;//sort函數等下講l3.sort(gt);l1.sort(gt);//第二個參數還是要加上的!l1.merge(l3, gt);for (const auto& e : l1){cout << e << " ";}cout << endl;return 0;
}那么運行結果為:

5.std::list::sort函數以及std::swap(list)的使用

這個函數第一個是排成升序,第二個是排成降序,但是我們第二個函數的參數現階段只要知道用這種方式即可:greater<int> gt;l1.sort(gt);但是記得gt的類型也要和l1一樣。

這個函數也是專門針對list設計的swap函數,這個就是為了防止之后我們調用了算法庫里面的函數,這個可以見我的string的模擬實現4的博客!
這個函數就不講解它的用法了,我在這里只講解為什么我們不用算法庫里面的sort函數?
這個其實涉及到迭代器的繼承關系,其中子類時特殊的父類,而在算法庫的sort函數的參數是RandomAccessIterator,是最特殊的子類,只能傳遞隨機迭代器。
6.C++迭代器(非常重要)
我在這里講解的繼承關系現在只是皮毛!!!因為這涉及到子父類的繼承關系,這些將會在C++的繼承博客中進行更詳細講解,這里我們只要在平常別亂用容器本身的迭代器與算法庫里面的迭代器即可:
我們在C++官網中搜索:iterator,則會有:

這5個迭代器是以下迭代器:

我們是看不懂這個箭頭的,也是很難理解的,我們只要知道這些分類即可。
所以以下是deepseek對它們比較簡單的講解:
這五個迭代器類別代表了C++中迭代器的不同能力和層級關系,它們構成了一種繼承層次結構,從功能簡單到功能強大依次是:
1. 輸入迭代器 (input_iterator_tag)
-
能力:只讀、單向
-
支持操作:
-
++?(前綴和后綴) -
*?(解引用,只能讀取) -
==/!=?比較
-
-
典型用途:從數據流中讀取數據(如
istream_iterator) -
限制:只能單次遍歷,不能回退
2. 輸出迭代器 (output_iterator_tag)
-
能力:只寫、單向
-
支持操作:
-
++?(前綴和后綴) -
*?(解引用,只能寫入)
-
-
典型用途:向數據流寫入數據(如
ostream_iterator) -
限制:不能讀取,不能回退,通常只能單次遍歷
3. 前向迭代器 (forward_iterator_tag)
-
能力:可讀可寫、單向
-
支持操作:
-
包含輸入迭代器的所有功能
-
可以多次遍歷同一序列
-
-
典型用途:單向鏈表(如
std::forward_list的迭代器) -
特點:比輸入/輸出迭代器更強,支持多遍遍歷
4. 雙向迭代器 (bidirectional_iterator_tag)
-
能力:可讀可寫、雙向移動
-
支持操作:
-
包含前向迭代器的所有功能
-
--?(前綴和后綴,可以回退)
-
-
典型用途:雙向鏈表(如
std::list的迭代器) -
特點:可以向前和向后移動
5. 隨機訪問迭代器 (random_access_iterator_tag)
-
能力:可讀可寫、隨機訪問
-
支持操作:
-
包含雙向迭代器的所有功能
-
+/-?整數(跳躍式移動) -
[]?下標訪問 -
<,?>,?<=,?>=?比較
-
-
典型用途:數組/向量(如
std::vector、std::array的迭代器) -
特點:功能最強大的迭代器類型
6.每個容器所對應的迭代器以及注意事項
以下是deepseek的搜索結果:
面是C++標準庫中主要容器及其對應的迭代器類別:
1. 序列容器 (Sequence Containers)
std::array
-
迭代器類別:隨機訪問迭代器 (
random_access_iterator_tag) -
說明:支持所有隨機訪問操作,包括
+、-、[]等
std::vector
-
迭代器類別:隨機訪問迭代器 (
random_access_iterator_tag) -
說明:與數組類似,支持高效隨機訪問
std::deque?(雙端隊列)
-
迭代器類別:隨機訪問迭代器 (
random_access_iterator_tag) -
說明:雖然內部結構比vector復雜,但仍提供隨機訪問能力
std::list?(雙向鏈表)
-
迭代器類別:雙向迭代器 (
bidirectional_iterator_tag) -
說明:
-
支持
++和--操作 -
不支持隨機訪問(不能使用
+、-或[])
-
std::forward_list?(單向鏈表)
-
迭代器類別:前向迭代器 (
forward_iterator_tag) -
說明:
-
只支持
++操作 -
不支持
--操作
-
2. 關聯容器 (Associative Containers)
std::set/std::multiset
-
迭代器類別:雙向迭代器 (
bidirectional_iterator_tag) -
說明:
-
元素已排序
-
支持雙向遍歷
-
std::map/std::multimap
-
迭代器類別:雙向迭代器 (
bidirectional_iterator_tag) -
說明:
-
鍵值對已按鍵排序
-
支持雙向遍歷
-
3. 無序關聯容器 (Unordered Associative Containers)
std::unordered_set/std::unordered_multiset
-
迭代器類別:前向迭代器 (
forward_iterator_tag) -
說明:
-
元素無序存儲
-
只支持單向遍歷
-
std::unordered_map/std::unordered_multimap
-
迭代器類別:前向迭代器 (
forward_iterator_tag) -
說明:
-
鍵值對無序存儲
-
只支持單向遍歷
-
4. 容器適配器 (Container Adaptors)
std::stack?和?std::queue
-
迭代器類別:不提供迭代器
-
說明:這些適配器專門設計為限制訪問模式,不支持迭代
特殊迭代器
std::string
-
迭代器類別:隨機訪問迭代器 (
random_access_iterator_tag) -
說明:行為與
std::vector<char>類似
std::string_view
-
迭代器類別:隨機訪問迭代器 (
random_access_iterator_tag) -
說明:提供對字符串的視圖,支持隨機訪問
迭代器類別對算法的影響
不同算法對迭代器有不同要求:
-
需要隨機訪問迭代器的算法:
-
std::sort -
std::binary_search -
std::nth_element
-
-
需要雙向迭代器的算法:
-
std::reverse -
std::unique?(帶謂詞版本) -
std::list::sort?(成員函數)
-
-
只需要前向迭代器的算法:
-
std::search -
std::adjacent_find
-
-
只需要輸入迭代器的算法:
-
std::find -
std::count -
std::accumulate
-
7.簡單解釋
這個迭代器的分類對我們之后是用算法庫里面的函數還是用容器的函數都有很多注意的地方,比如:我們不能用算法庫的sort,因為list是雙向迭代器即:bidirectional_iterator_tag。這個迭代器可以支持++、---的操作,但是不支持+、-的操作,因此若用算法庫里面的可能會導致有些問題。如果我們想用循環++、--的方式來訪問除begin、end位置外的數據也是可以的,我們如果不知道哪種方式遍歷鏈表更好一些,可以見以下圖:
如何選擇:
| 場景 | 推薦方式 | 原因 |
|---|---|---|
順序遍歷(如?for?循環) | ++it | 最高效,直接移動一步。 |
| 跳轉多個位置 | std::advance(it, n) | 需要修改原迭代器時使用(如?it?需要指向新位置)。 |
| 臨時計算新位置 | std::next(it, n) | 不修改原迭代器,適用于范圍操作(如?std::next(begin, 2))。 |
隨機訪問容器(如?vector) | it + n | std::vector?支持?O(1)?隨機訪問,直接?+n?比?advance?更高效。 |
總結:
| 方法 | 是否修改原迭代器 | 時間復雜度(list) | 適用場景 |
|---|---|---|---|
++it | ? 是 | O(1)(單步) | 順序遍歷 |
std::advance | ? 是 | O(n)(多步) | 需要修改迭代器位置時 |
std::next | ? 否 | O(n)(多步) | 臨時計算新位置(更安全) |
功能對比:
| 方法 | 作用 | 是否修改原迭代器 | 適用場景 |
|---|---|---|---|
it++?/?++it | 移動迭代器到下一個位置(單步) | 是 | 簡單遍歷(如?for?循環) |
std::advance(it, n) | 移動迭代器?n?步(可正可負) | 是 | 需要移動多步時(如跳轉訪問) |
std::next(it, n) | 返回移動?n?步后的新迭代器,不修改原迭代器 | 否 | 臨時計算新位置(如獲取下一個元素) |
推薦實踐:
-
默認用?
++?遍歷(最高效)。 -
需要跳轉時用?
std::advance(修改迭代器)。 -
臨時計算用?
std::next(不修改原迭代器,更安全)。
對于如何理解父子類的繼承行為,我們可以認為:子類是特殊的父類,父類有的特征子類都有,我們若把子類認為是正方形,父類是長方形,這個就很容易理解了。
所以在用每個算法庫里面的函數的時候還是要注意它的迭代器的類別:
如果有迭代器類型的參數且類型是Input_Iterator那么我們就只可讀,也就是說只能傳遞Input類別的迭代器;同理對于參數是Output_Iterator類別的,那么就只能傳遞Output類別的迭代器;如果是單向迭代器,那么就能傳遞Input_Iterator、Output_Iterator和單向迭代器;如果是雙向迭代器,那么可以傳遞除隨機迭代器外的所有迭代器;如果參數類型是隨機迭代器,那么就可以傳遞任意類型的迭代器!
我按照常用的容器,給出大概分類:vector、string、deque是隨機迭代器;list、map、set是雙向迭代器、forward_list、unodered_map、unordered_set是單向迭代器。
最后記住:算法庫里面的sort函數是不能用來進行list的排序的!所以我們要注意!
7.總結
list的重要函數的使用已經全部講完了,那些比較運算符的重載、逆置函數、得到一個迭代器這些都不重要,就不講解了,我們主要是要懂得每個函數所對應的用法,已經一些注意事項。這個我用deepseek的也是比較多,因為我自己學的不是很深入,如果照著筆記講還不如不寫博客,所以我覺得還是用deepseek更全面一些,也方便我之后復習用!
好了,C++list的使用就到這里了,下講將講解:list的底層。不過下講內容可能需要下周去了,因為這周四天更新了這是第8篇了,身體有些吃不消了,已經趕得上我的筆記內容了。
喜歡的可以一鍵三連哦,下講再見!

,ADC)

的語音增強)













:最大似然估計的-AI 模型訓練與參數優化)

)
