引言
三維重建是計算機視覺領域中的一項關鍵技術,它能夠從二維圖像中恢復出三維形狀和結構。隨著深度學習的發展,基于學習的方法已經成為三維重建的主流。NeuralRecon是一種先進的三維重建方法,它能夠從單目視頻中實時生成高質量的三維模型。本文將詳細介紹NeuralRecon的技術原理、步驟以及如何利用TSDF(截斷符號距離函數)進行三維重建。
TSDF(截斷符號距離函數)在三維重建中的作用和原理
什么是TSDF?
TSDF是一種用于三維重建和表面表示的技術。它通過記錄每個體素(voxel)到最近表面的距離來表示三維形狀。這里的“體素”是三維空間中的一個像素,類似于二維圖像中的像素。
TSDF的工作原理
-
體素網格:
- 首先,創建一個三維體素網格,這個網格覆蓋了我們希望重建的三維空間區域。每個體素都有一個位置和大小。
-
距離記錄:
- 每個體素記錄一個距離值,這個值表示該體素到最近表面的距離。這個距離可以是正的、負的或零:
- 正距離:體素在表面外部。
- 負距離:體素在表面內部。
- 零距離:體素正好在表面上。
- 每個體素記錄一個距離值,這個值表示該體素到最近表面的距離。這個距離可以是正的、負的或零:
-
截斷:
- TSDF中的“截斷”意味著距離值被限制在一個特定的范圍內(例如,-1到1)。超出這個范圍的體素將被設置為最大或最小值。這有助于處理噪聲和不準確的測量。
-
表面重建:
- 通過分析體素網格中的TSDF值,可以重建出三維表面。通常,表面被定義為TSDF值從正變負或從負變正的邊界。
- 通過分析體素網格中的TSDF值,可以重建出三維表面。通常,表面被定義為TSDF值從正變負或從負變正的邊界。
示例步驟
假設我們有一個簡單的三維物體,我們希望使用TSDF來重建其表面:
-
初始化體素網格:
- 創建一個覆蓋物體的三維體素網格。
-
獲取深度圖:
- 使用深度相機或激光雷達獲取物體的深度圖。深度圖記錄了每個像素到物體表面的距離。
-
計算體素距離:
- 將深度圖中的距離值轉換為體素網格中的TSDF值。例如,如果一個體素在深度圖中的距離是0.5米,那么它的TSDF值就是0.5。
-
截斷距離值:
- 將所有超出范圍(例如,-1到1)的TSDF值截斷到這個范圍內。
-
重建表面:
- 使用TSDF值重建物體表面。通常,這涉及到找到TSDF值從正變負或從負變正的邊界。
應用
TSDF技術廣泛應用于三維掃描、機器人導航、增強現實等領域。它允許從多個視角捕獲的數據中重建三維模型,是一種強大的工具,用于理解和操作三維空間。
詳細步驟解析

步驟 1: 轉換操作(ds,深度圖中的數值)
在三維重建中,深度圖提供了從相機到物體表面的直接距離信息。每個像素點的深度值 ds 表示從相機到該點的直線距離。這些深度值是重建三維模型的基礎數據,因為它們直接關聯到物體表面的空間位置。
步驟 2: 遍歷每一個體素,計算其在世界坐標系中的位置
體素是三維空間中的像素,是構成三維模型的基本單元。在這一步中,我們需要確定每個體素在世界坐標系中的位置。這通常通過遍歷體素網格并將其索引轉換為世界坐標來實現。世界坐標系是一個全局參考框架,用于描述物體在空間中的位置。
步驟 3: 根據初始化“大塊”時設置的極點位置和體素大小決定
在初始化過程中,我們需要設置體素的大小和它們在世界坐標系中的位置。這涉及到選擇一個起始點(極點)和定義體素的尺寸。這些參數決定了體素網格的分辨率和覆蓋范圍,對重建的精度和細節有重要影響。
步驟 4: 將其在世界坐標中的值轉換成其在相機坐標系中的位置(位姿RT已知)
為了將世界坐標轉換為相機坐標,我們需要使用相機的位姿信息,包括旋轉矩陣 R 和平移向量 T。這些信息描述了相機相對于世界坐標系的位置和方向。通過應用這些變換,我們可以計算出每個體素相對于相機的位置。
步驟 5: 根據相機內參,轉換到像素坐標
最后,我們需要將相機坐標系中的點轉換到像素坐標系中。這需要使用相機的內參,如焦距和主點坐標。這些參數描述了相機的成像特性,將三維空間中的點映射到二維圖像平面上。一旦我們得到像素坐標,就可以從深度圖中獲取對應的深度值,完成從圖像數據到三維空間信息的轉換。
TSDF的計算和應用
TSDF值的計算
TSDF值是通過比較體素到相機的距離 dv(通過相機位姿和內參計算得到)和從深度圖中得到的深度值 ds 來計算的。計算公式為 d(x) = ds - dv。這個差值表示體素相對于最近表面的符號距離。
- 正距離:如果
d(x) > 0,體素位于表面外部。 - 負距離:如果
d(x) < 0,體素位于表面內部。 - 零距離:如果
d(x) = 0,體素正好在表面上。
TSDF的應用
TSDF值的應用包括:
- 表面重建:通過找到TSDF值從正變負或從負變正的邊界,可以重建出物體的表面。
- 噪聲處理:通過截斷TSDF值,可以減少噪聲和不準確測量的影響。
- 多視角融合:TSDF方法可以整合來自多個視角的深度信息,生成一致的三維模型。
示例代碼
以下是一個簡化的示例代碼,展示了如何使用TSDF進行三維重建:
import numpy as npdef compute_tsdf(depth_map, camera_pose, camera_intrinsics, voxel_size):# 假設 depth_map 是深度圖,camera_pose 是相機位姿,camera_intrinsics 是相機內參voxel_grid = np.zeros((100, 100, 100)) # 初始化體素網格for i in range(voxel_grid.shape[0]):for j in range(voxel_grid.shape[1]):for k in range(voxel_grid.shape[2]):world_coords = np.array([i, j, k]) * voxel_sizecamera_coords = np.dot(camera_pose, np.append(world_coords, 1))[:3]pixel_coords = np.dot(camera_intrinsics, camera_coords)pixel_coords = pixel_coords[:2] / pixel_coords[2]ds = depth_map[int(pixel_coords[1]), int(pixel_coords[0])]dv = np.linalg.norm(camera_coords)tsdf = ds - dvvoxel_grid[i, j, k] = tsdfreturn voxel_grid# 示例參數
depth_map = np.random.rand(480, 640) # 隨機生成深度圖
camera_pose = np.eye(4) # 單位矩陣作為相機位姿
camera_intrinsics = np.array([[1000, 0, 320], [0, 1000, 240], [0, 0, 1]]) # 相機內參
voxel_size = 0.05 # 體素大小# 計算TSDF
tsdf_grid = compute_tsdf(depth_map, camera_pose, camera_intrinsics, voxel_size)
結論
TSDF是一種強大的三維重建技術,它通過記錄每個體素到最近表面的距離來表示三維形狀。本文詳細介紹了TSDF的計算過程和在三維重建中的應用,并提供了示例代碼。希望讀者能夠通過本文更好地理解和應用TSDF技術。
NeuralRecon技術詳解
NeuralRecon是一種基于深度學習的三維重建方法,主要用于從單目視頻或多視圖圖像生成高質量的三維場景。本文將詳細介紹NeuralRecon的技術原理、步驟以及如何利用TSDF進行三維重建。
技術原理
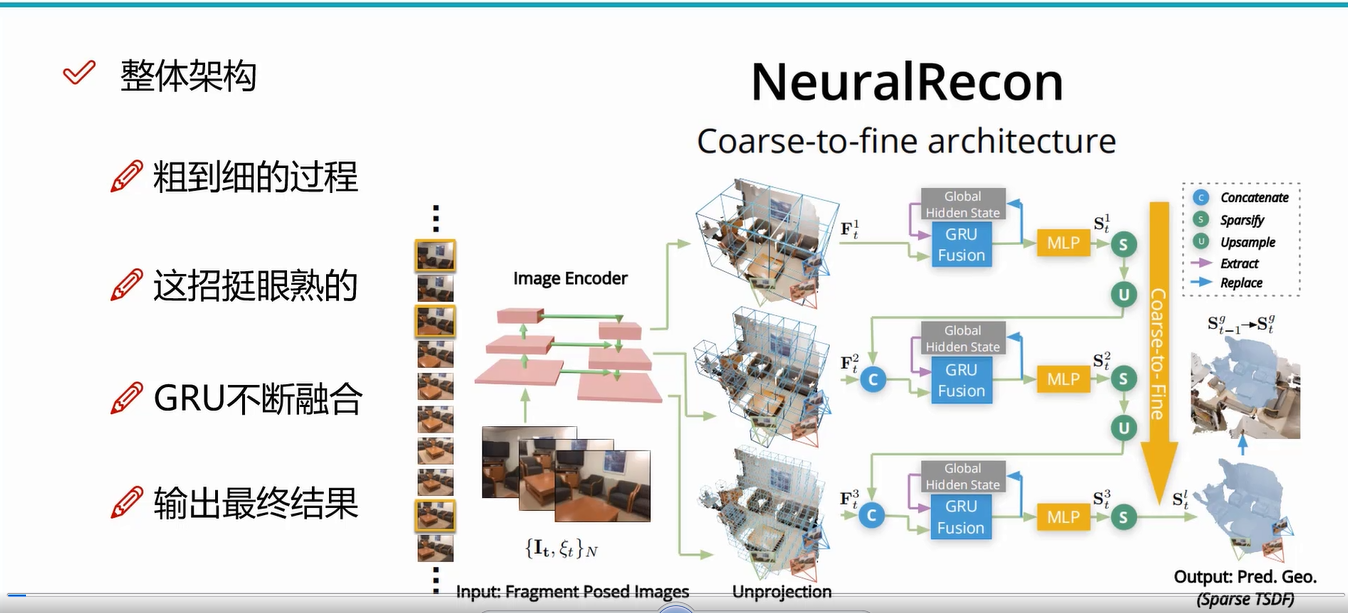
NeuralRecon的核心思想是利用三維稀疏卷積和GRU(門控循環單元)算法,對每個視頻片段的稀疏TSDF體進行增量聯合重構和融合。這種設計使NeuralRecon能夠實時輸出精確的相干重建。實驗表明,NeuralRecon在重建質量和運行速度上都優于現有的方法。
重建步驟
1. 輸入數據
NeuralRecon的輸入包括彩色圖像和相機位姿信息,這些信息提供了三維場景的基本信息。
2. 初始低分辨率重建
從低分辨率的體素網格開始,通過圖像的多視角信息推斷初步體素特征。多張圖像的特征向量會被相加求平均,以此確定該體素的初步特征向量。
3. ConvGRU 更新特征
使用 ConvGRU 遞歸更新每層體素特征,保留前一層的有用信息。ConvGRU 的作用是將前一層的體素特征與當前層的信息進行融合,保留有用的信息,并逐層改進。這一機制確保了不同層次之間的特征一致性和逐步細化的過程。
4. MLP 估計 TSDF
特征通過 3D CNN 處理后,進入多層感知機(MLP)模塊來估計 TSDF 值。在這一步,網絡推斷出每個體素的 TSDF 值,表示體素距離真實表面的距離。
5. 逐層細化
每一層增加體素分辨率,并通過上采樣和特征融合逐層細化體素特征。為了對齊不同分辨率的體素網格,上一層生成的 TSDF 會通過上采樣操作。
6. 輸出最終結果
生成高分辨率的 TSDF,表示最終的 3D 場景結構。
NeuralRecon的重建過程在多個步驟中使用了三維稀疏卷積技術。具體來說:
-
圖像特征提取和投影:首先,視頻片段中的多張圖像通過一個卷積神經網絡(CNN)提取多個分辨率下的圖像深度特征。這些圖像特征隨后被反向投影到三維空間中,形成三維特征體積。
-
從粗到細的三維場景重建:NeuralRecon采用從粗到細的方法,分階段地預測并細化場景的幾何信息。在每個階段中,稀疏三維卷積神經網絡被用來處理三維特征體,最終通過一個多層感知機(MLP)來預測占有分數(Occupancy score)和TSDF值。占有分數表示三維特征體中體素在TSDF截斷距離之內的概率。在每個階段的最后,占有分數小于閾值的體素,都會被定為空,并被除掉。而在稀疏化之后,稀疏三維特征體被上采樣。
-
基于GRU的融合:這一步的目的是讓片段的重建之間保持一致,希望當前片段的重建可以建立在歷史片段重建結果的基礎上。具體來說,該方法提出了一個基于GRU的聯合重建與融合模塊。在每個階段,三維特征體首先通過一個三維稀疏卷積,并進行三維幾何特征提取。然后,三維幾何特征會被輸入進GRU聯合重建與融合模塊。該模塊會將三維幾何特征與在歷史片段重建中獲得的隱變量進行融合,并通過一個全局感知機回歸TSDF和占有分數。
在NeuralRecon中,三維稀疏卷積的使用提高了算子效率,并且與從粗到細的設計相結合,使得預測的TSDF在每個層次上逐漸細化。通過直接重建隱式曲面(TSDF),網絡能夠在自然三維曲面之前學習局部平滑度和全局形狀。這種設計減少了冗余計算,因為在碎片重建過程中,三維表面上的每個區域僅估計一次。
TSDF 計算過程
在計算 TSDF 時,首先通過模型預測獲得圖片中的深度 ds(從圖片中獲取的深度信息),然后根據相機的位姿和內參計算出體素的深度 dv(通過相機拍攝的位姿以及相機的內參計算得來),接著計算體素到真實面的距離 d(x) = ds - dv。若 d(x) > 0,則體素位于真實面前;若 d(x) < 0,則體素位于真實面后。最終,通過進一步處理 d(x) 得到 TSDF 值。
示例代碼
以下是一個簡化的示例代碼,展示了如何使用NeuralRecon進行三維重建:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass NeuralRecon(nn.Module):def __init__(self):super(NeuralRecon, self).__init__()self.image_encoder = self._build_image_encoder()self.gru_fusion = self._build_gru_fusion()self.mlp = self._build_mlp()def _build_image_encoder(self):# 構建圖像編碼器return nn.Sequential(nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2))def _build_gru_fusion(self):# 構建GRU融合模塊return nn.GRU(128, 128, num_layers=1, batch_first=True)def _build_mlp(self):# 構建多層感知機return nn.Sequential(nn.Linear(128, 64),nn.ReLU(inplace=True),nn.Linear(64, 2) # 輸出TSDF值和占用率)def forward(self, x):# 前向傳播x = self.image_encoder(x)x = x.view(x.size(0), -1, x.size(1))h0 = torch.zeros(1, x.size(0), 128).to(x.device)x, _ = self.gru_fusion(x, h0)x = self.mlp(x)return x# 示例輸入
input_tensor = torch.randn(1, 3, 288, 800)
model = NeuralRecon()
output = model(input_tensor)
print(output.shape) # 輸出形狀應為[batch, num_voxels, 2]
GitHub參考
NeuralRecon的代碼可以在GitHub上找到,以下是相關的鏈接:
- NeuralRecon GitHub Repository
通過這些代碼和資源,讀者可以更深入地了解NeuralRecon的實現細節,并嘗試在自己的項目中應用這一技術。
總結
NeuralRecon是一種強大的三維重建技術,它通過結合深度學習和TSDF方法,實現了從單目視頻中實時生成高質量的三維模型。本文詳細介紹了NeuralRecon的技術原理、步驟以及如何利用TSDF進行三維重建,并提供了示例代碼和GitHub參考鏈接。希望讀者能夠通過本文更好地理解和應用NeuralRecon技術。




:最大似然估計的-AI 模型訓練與參數優化)

)









![[Java惡補day6] 15. 三數之和](http://pic.xiahunao.cn/[Java惡補day6] 15. 三數之和)


![[Windows] 游戲常用運行庫- Game Runtime Libraries Package(6.2.25.0409)](http://pic.xiahunao.cn/[Windows] 游戲常用運行庫- Game Runtime Libraries Package(6.2.25.0409))