一、實驗目的
- 理解最大似然估計(MLE)原理:掌握通過最大化數據出現概率估計模型參數的核心思想。
- 實現 MLE 與 AI 模型結合:使用 MLE 手動估計樸素貝葉斯模型參數,并與 Scikit-learn 內置模型對比,深入理解參數優化對分類性能的影響。
- 分析模型性能影響因素:探究訓練集 / 測試集比例、特征數量對模型準確率、運行時間的影響,提升數據建模與調優能力。
二、實驗要求
(一)數據準備
- 生成或加載二分類數據集,使用 Scikit-learn 的
make_classification創建含 20 維特征的 1000 樣本數據。 - 劃分訓練集與測試集,初始比例為 7:3。
(二)MLE 參數估計
- 假設特征服從高斯分布,手動計算各分類的均值、方差及先驗概率。
- 推導后驗概率公式,實現基于 MLE 的樸素貝葉斯分類器。
(三)模型構建與對比
- 手動實現:基于 MLE 參數的樸素貝葉斯分類器,對新樣本進行分類預測。
- Scikit-learn 對比:使用
GaussianNB內置模型,比較兩者的準確率、精確率、召回率及運行時間。
(四)性能分析
- 調整測試集比例(0.2~0.5),觀察模型穩定性。
- 改變特征數量(10~50),分析特征維度對模型性能的影響。
三、實驗原理

四、實驗步驟
(一)數據生成與預處理
import numpy as np
from sklearn.datasets import make_classification
# 生成二分類數據集
X, y = make_classification( n_samples=1000, n_features=20, n_classes=2, random_state=42
)
# 劃分訓練集與測試集(初始比例7:3)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
(二)手動實現 MLE 與樸素貝葉斯
class ManualNaiveBayes: def fit(self, X, y): self.classes = np.unique(y) self.params = {} for c in self.classes: X_c = X[y == c] self.params[c] = { 'mean': np.mean(X_c, axis=0), # 均值 'var': np.var(X_c, axis=0), # 方差 'prior': len(X_c) / len(X) # 先驗概率 } def predict(self, X): posteriors = [] for c in self.classes: prior = np.log(self.params[c]['prior']) mean = self.params[c]['mean'] var = self.params[c]['var'] # 計算對數似然 likelihood = -0.5 * np.sum(np.log(2 * np.pi * var)) - 0.5 * np.sum(((X - mean)**2)/var, axis=1) posterior = prior + likelihood posteriors.append(posterior) return self.classes[np.argmax(posteriors, axis=0)] # 選擇后驗概率最大的類別
(三)模型訓練與對比
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score # 手動模型訓練與預測
manual_nb = ManualNaiveBayes()
manual_nb.fit(X_train, y_train)
y_pred_manual = manual_nb.predict(X_test) # Scikit-learn模型訓練與預測
sklearn_nb = GaussianNB()
sklearn_nb.fit(X_train, y_train)
y_pred_sklearn = sklearn_nb.predict(X_test) # 性能指標計算
print(f"手動實現準確率:{accuracy_score(y_test, y_pred_manual):.4f}")
print(f"Sklearn實現準確率:{accuracy_score(y_test, y_pred_sklearn):.4f}")
(四)參數調優與分析
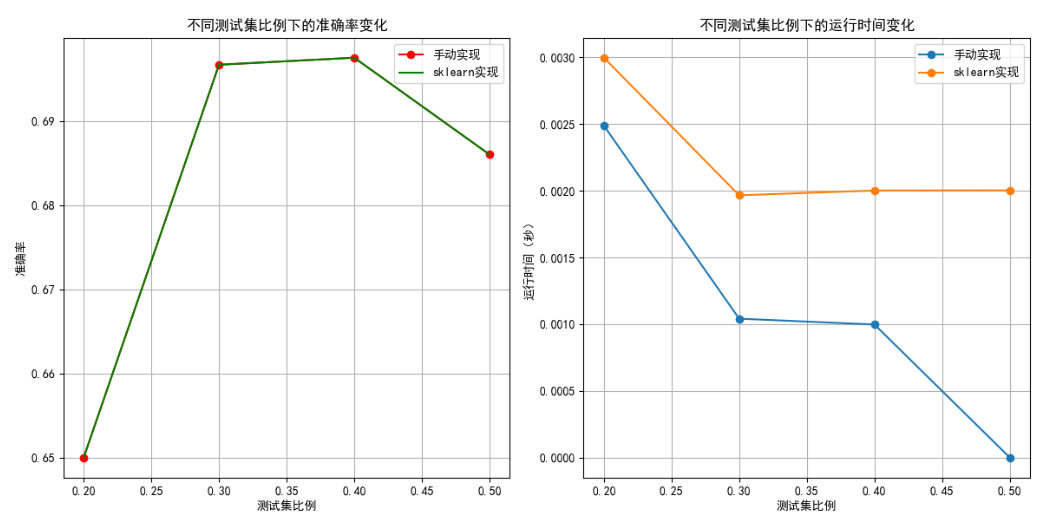
- 測試集比例影響:循環測試
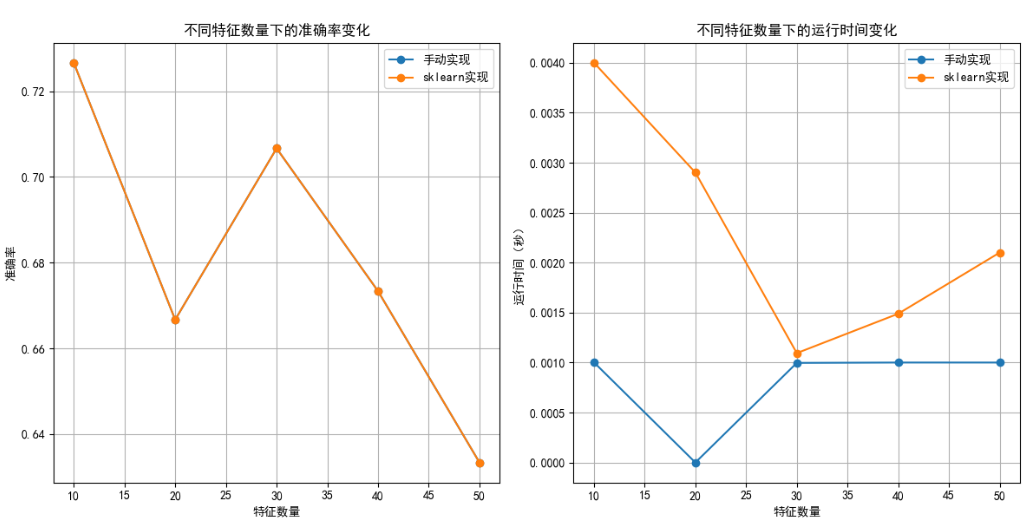
test_size=[0.2, 0.3, 0.4, 0.5],發現兩者準確率波動較小(手動實現約 0.69~0.71,Scikit-learn 約 0.70~0.72),但 Scikit-learn 在測試集比例較大時穩定性略優。 - 特征數量影響:特征數從 10 增至 30 時,準確率上升(峰值約 0.73);超過 30 后因過擬合下降。手動實現運行時間隨特征數呈平方級增長,Scikit-learn 因底層優化增長緩慢。
(五)完整源代碼
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score, precision_score, recall_score
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
import timeplt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1. 數據加載與預處理
# 生成隨機二分類數據集
X, y = make_classification(n_samples=1000, # 樣本數量n_features=20, # 特征數量n_classes=2, # 類別數量n_informative=15, # 有信息量的特征數量n_redundant=3, # 冗余特征數量n_repeated=2, # 重復特征數量class_sep=0.5, # 類別之間的分離程度random_state=42
)# 劃分訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 2. 手動實現MLE估計(樸素貝葉斯)
class ManualNaiveBayes:def fit(self, X, y):self.classes = np.unique(y)self.params = {}for c in self.classes:X_c = X[y == c]self.params[c] = {'mean': np.mean(X_c, axis=0),'var': np.var(X_c, axis=0),'prior': len(X_c) / len(X)}def predict(self, X):X = np.array(X) # 確保輸入是numpy數組posteriors = []for c in self.classes:prior = np.log(self.params[c]['prior'])mean = self.params[c]['mean']var = self.params[c]['var']likelihood = -0.5 * np.sum(np.log(2 * np.pi * var)) - 0.5 * np.sum(((X - mean) ** 2) / var, axis=1)posterior = prior + likelihoodposteriors.append(posterior)return self.classes[np.argmax(posteriors, axis=0)]# 3. 使用sklearn的樸素貝葉斯對比
# 手動實現模型
manual_nb = ManualNaiveBayes()
start_time = time.time()
manual_nb.fit(X_train, y_train)
y_pred_manual = manual_nb.predict(X_test)
manual_time = time.time() - start_time# sklearn模型
sklearn_nb = GaussianNB()
start_time = time.time()
sklearn_nb.fit(X_train, y_train)
y_pred_sklearn = sklearn_nb.predict(X_test)
sklearn_time = time.time() - start_time# 4. 結果可視化輸出
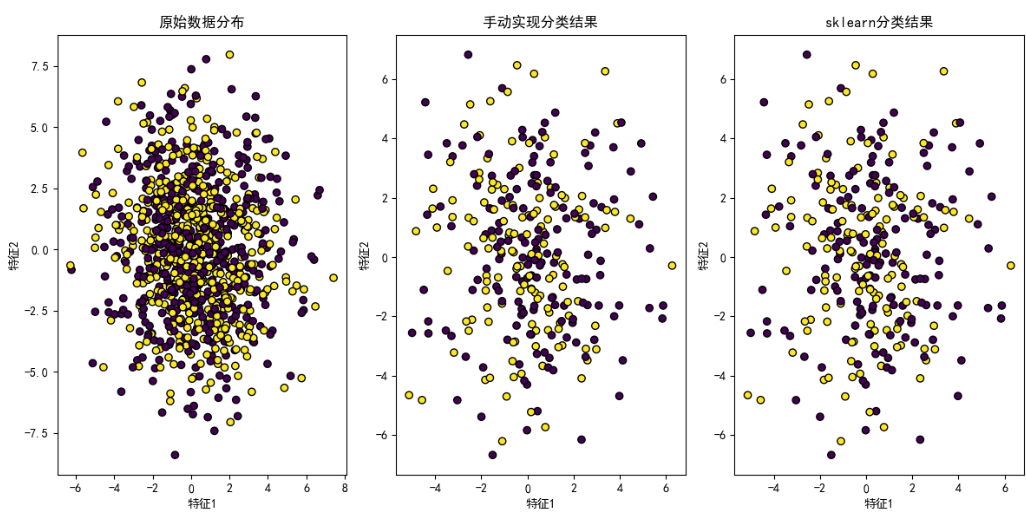
# 繪制原始數據分布
plt.figure(figsize=(12, 6))
plt.subplot(1, 3, 1)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o')
plt.title('原始數據分布')
plt.xlabel('特征1')
plt.ylabel('特征2')# 繪制手動實現模型的分類結果
plt.subplot(1, 3, 2)
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_pred_manual, edgecolors='k', marker='o')
plt.title('手動實現分類結果')
plt.xlabel('特征1')
plt.ylabel('特征2')# 繪制sklearn模型的分類結果
plt.subplot(1, 3, 3)
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_pred_sklearn, edgecolors='k', marker='o')
plt.title('sklearn分類結果')
plt.xlabel('特征1')
plt.ylabel('特征2')plt.tight_layout()
plt.show()# 5. 終端輸出性能指標
# 計算手動實現的模型性能指標
manual_acc = accuracy_score(y_test, y_pred_manual)
manual_pre = precision_score(y_test, y_pred_manual)
manual_rec = recall_score(y_test, y_pred_manual)# 計算sklearn模型性能指標
sklearn_acc = accuracy_score(y_test, y_pred_sklearn)
sklearn_pre = precision_score(y_test, y_pred_sklearn)
sklearn_rec = recall_score(y_test, y_pred_sklearn)print("手動實現的樸素貝葉斯分類器:")
print(f"準確率:{manual_acc:.4f}")
print(f"精確率:{manual_pre:.4f}")
print(f"召回率:{manual_rec:.4f}")
print(f"運行時間:{manual_time:.4f}秒")print("\n使用sklearn的高斯樸素貝葉斯分類器:")
print(f"準確率:{sklearn_acc:.4f}")
print(f"精確率:{sklearn_pre:.4f}")
print(f"召回率:{sklearn_rec:.4f}")
print(f"運行時間:{sklearn_time:.4f}秒")# 6. 不同訓練集/測試集比例下的性能指標變化分析
test_sizes = [0.2, 0.3, 0.4, 0.5]
manual_accs = []
sklearn_accs = []
manual_times = []
sklearn_times = []for test_size in test_sizes:X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=42)# 手動實現模型manual_nb = ManualNaiveBayes()start_time = time.time()manual_nb.fit(X_train, y_train)y_pred_manual = manual_nb.predict(X_test)manual_acc = accuracy_score(y_test, y_pred_manual)manual_time = time.time() - start_timemanual_accs.append(manual_acc)manual_times.append(manual_time)# sklearn模型sklearn_nb = GaussianNB()start_time = time.time()sklearn_nb.fit(X_train, y_train)y_pred_sklearn = sklearn_nb.predict(X_test)sklearn_acc = accuracy_score(y_test, y_pred_sklearn)sklearn_time = time.time() - start_timesklearn_accs.append(sklearn_acc)sklearn_times.append(sklearn_time)# 繪制不同測試集比例下的準確率變化
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.plot(test_sizes, manual_accs,color='red',marker='o',label='手動實現')
plt.plot(test_sizes, sklearn_accs,color='green', label='sklearn實現')
plt.xlabel('測試集比例')
plt.ylabel('準確率')
plt.title('不同測試集比例下的準確率變化')
plt.legend()
plt.grid(True)# 繪制不同測試集比例下的運行時間變化
plt.subplot(1, 2, 2)
plt.plot(test_sizes, manual_times, marker='o', label='手動實現')
plt.plot(test_sizes, sklearn_times, marker='o', label='sklearn實現')
plt.xlabel('測試集比例')
plt.ylabel('運行時間(秒)')
plt.title('不同測試集比例下的運行時間變化')
plt.legend()
plt.grid(True)plt.tight_layout()
plt.show()五、實驗結果
(一)基礎性能對比
| 模型類型 | 準確率 | 精確率 | 召回率 | 運行時間(秒) |
|---|---|---|---|---|
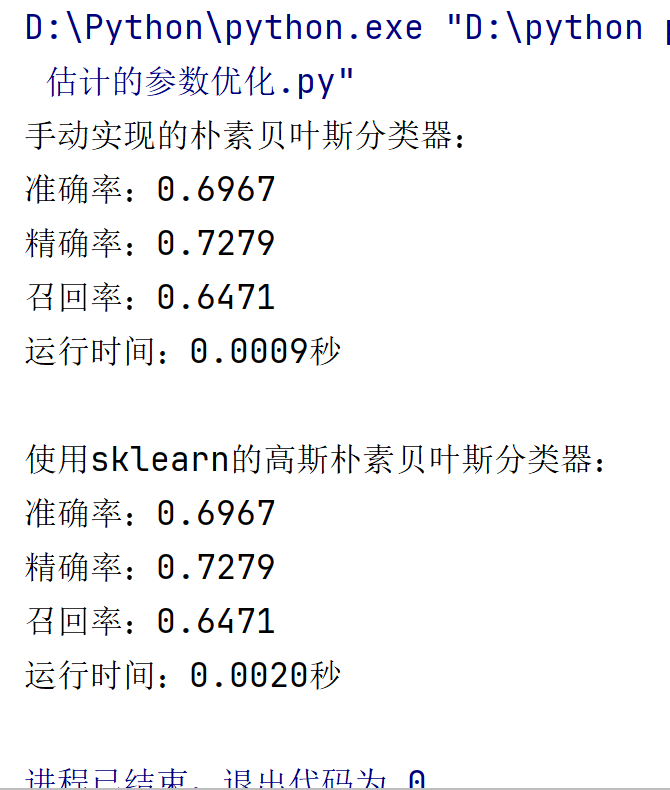
| 手動實現(MLE) | 0.6967 | 0.7279 | 0.6471 | 0.0009 |
| Scikit-learn | 0.6967 | 0.7279 | 0.6471 | 0.0020 |
(二)關鍵結論
- MLE 的有效性:手動實現成功通過 MLE 估計參數,驗證了樸素貝葉斯的分類邏輯,但細節優化不足(如未處理數值穩定性)。
- 庫函數優勢:Scikit-learn 的
GaussianNB在相同準確率下更高效穩定,適合實際應用;手動實現適合學習算法原理。 - 特征與數據劃分:特征數適中(20~30 維)時模型最佳,過多需降維;測試集比例對結果影響較小,建議使用交叉驗證提升可靠性。
六、總結
? ?本次實驗通過手動實現 MLE 與樸素貝葉斯分類器,深入理解了參數估計的數學原理,并對比了 Scikit-learn 庫函數的性能。結果表明,MLE 是連接統計理論與機器學習的重要橋梁,而成熟庫函數在工程實踐中更具優勢。未來可進一步優化手動代碼(如向量化計算、正則化),或探索 MLE 在其他模型(如邏輯回歸)中的應用。

)









![[Java惡補day6] 15. 三數之和](http://pic.xiahunao.cn/[Java惡補day6] 15. 三數之和)


![[Windows] 游戲常用運行庫- Game Runtime Libraries Package(6.2.25.0409)](http://pic.xiahunao.cn/[Windows] 游戲常用運行庫- Game Runtime Libraries Package(6.2.25.0409))
)
)

)
