
1. 視圖
1.1. 視圖的概念
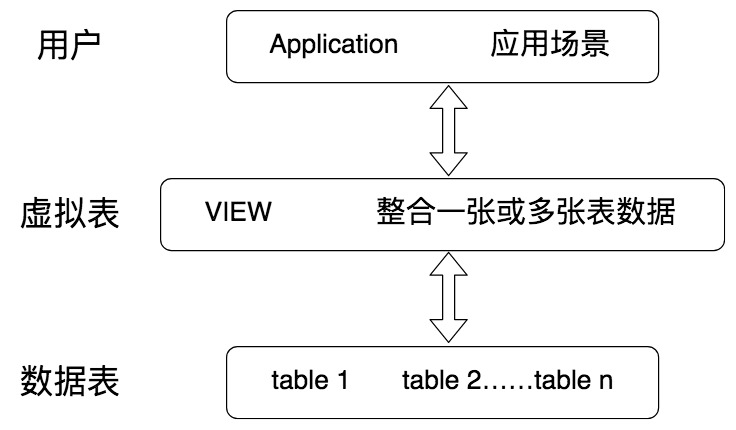
視圖(View):虛擬表,本身不存儲數據,而是封裝了一個 SQL 查詢的結果集。
用途:
- 只顯示部分數據,提高數據訪問的安全性。
- 簡化復雜查詢,提高復用性和可維護性。
- 可為不同用戶提供不同的數據視圖。
虛擬表的創建連接了一個或多個數據表,不同的查詢應用都可以建立在虛擬表之上。
1.2. 創建、更新和刪除視圖
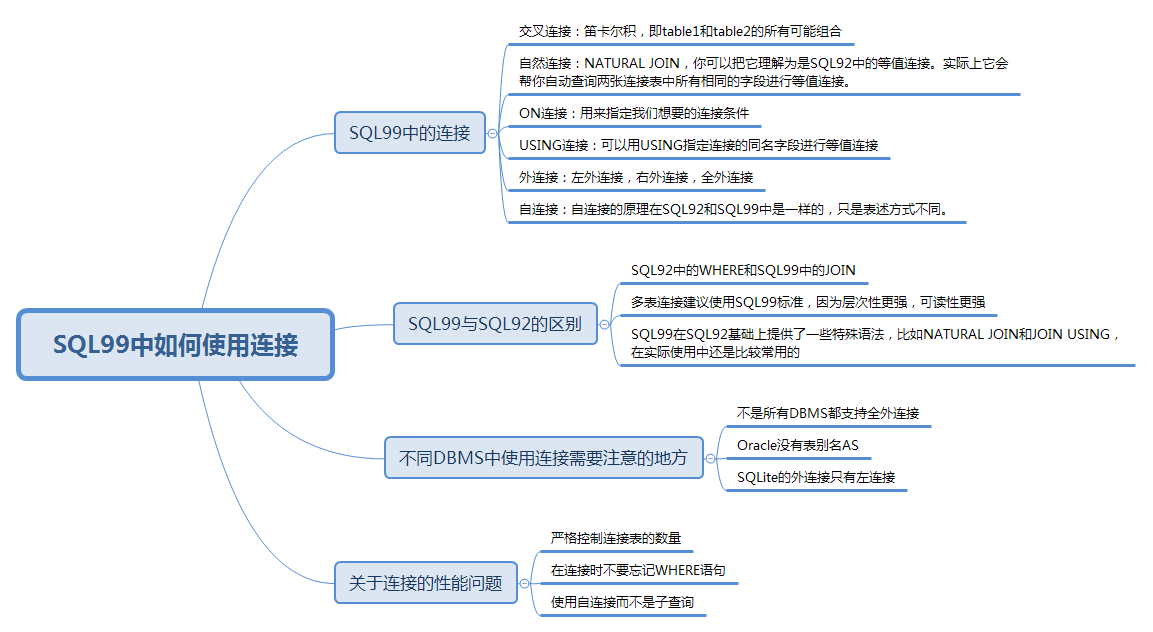
1. 創建視圖:CREATE VIEW
CREATE VIEW view_name AS
SELECT column1, column2
FROM table
WHERE condition;嵌套視圖:
當創建好一張視圖之后,還可以在它的基礎上繼續創建視圖。
2. 修改視圖:ALTER VIEW
ALTER VIEW view_name AS
SELECT column1, column2
FROM table
WHERE condition3. 刪除視圖:DROP VIEW
DROP VIEW view_name1.3. 用視圖簡化SQL操作
1. 復雜連接視圖封裝
? 示例:封裝球員與身高等級的連接
CREATE VIEW player_height_grades AS
SELECT p.player_name, p.height, h.height_level
FROM player AS p
JOIN height_grades AS h
ON p.height BETWEEN h.height_lowest AND h.height_highest;查詢:
SELECT * FROM player_height_grades WHERE height BETWEEN 1.90 AND 2.08;2. 格式化輸出視圖
? 示例:拼接球員姓名和球隊名稱
CREATE VIEW player_team AS
SELECT CONCAT(player_name, '(', team.team_name, ')') AS player_team
FROM player JOIN team
ON player.team_id = team.team_id;3. 計算字段封裝
? 示例:統計球員比賽得分組成
CREATE VIEW game_player_score AS
SELECT game_id, player_id,(shoot_hits - shoot_3_hits)*2 AS shoot_2_points,shoot_3_hits*3 AS shoot_3_points,shoot_p_hits AS shoot_p_points,score
FROM player_score;1.4. 視圖的優點、與臨時表的區別
視圖的優點:
1. 安全性:
- 視圖通常為只讀,避免誤改數據。
- 可基于權限控制字段訪問。
2. 簡潔性與復用性:
- 簡化復雜 SQL。
- 可嵌套定義,便于模塊化管理。
視圖與臨時表的區別:
| 特性 | 視圖(View) | 臨時表(Temporary Table) |
| 是否存儲數據 | 否,虛擬表,實時查詢結果 | 是,存儲在臨時空間 |
| 生命周期 | 持久存在(除非 DROP) | 僅當前會話存在,連接關閉即消失 |
| 用途 | 封裝查詢邏輯,數據隔離 | 存放臨時數據,如中間計算結果 |
| 支持修改數據 | 限制較多(如包含聚合、連接) | 支持普通數據操作(增刪改查) |
| 索引支持 | 大多不支持索引 | 通常支持索引 |
示例應用場景:
視圖:給銷售人員只顯示價格、銷量,不顯示成本。
臨時表:購物車臨時保存每個用戶選購的商品數據。
2. 存儲過程 Stored Procedure
2.1. 存儲過程的定義
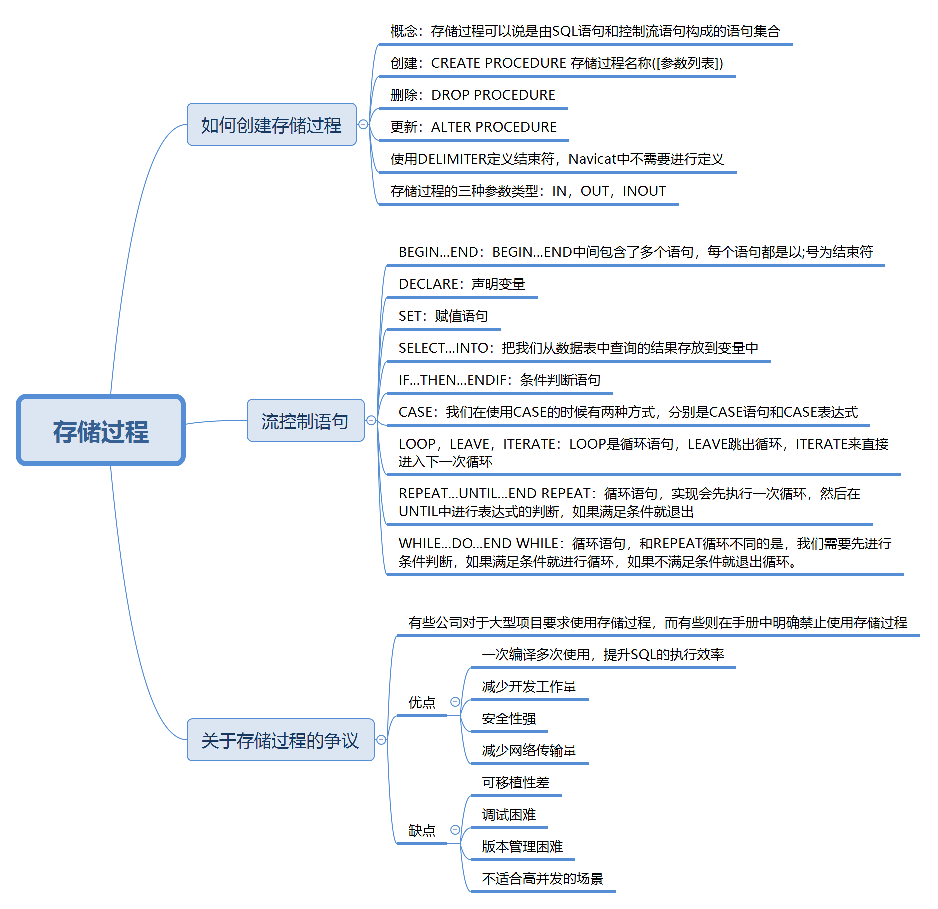
定義:SQL 中對一組語句的封裝,可通過一次定義,多次調用,像函數一樣執行。
結構組成:包含 SQL 語句、流控制語句(如循環、條件判斷等)。
使用方式:
CREATE PROCEDURE proc_name ([參數])
BEGIN-- 語句塊
END2.2. 存儲過程的優缺點
優點:
| ? 1. 一次編譯,多次執行 | 提前編譯后存儲在數據庫中,后續調用無需重新解析,提高執行效率。 |
| ? 2. 封裝邏輯,提升復用性 | 可將復雜邏輯封裝成過程,結構清晰、易于維護與復用,有利于模塊化開發。 |
| ? 3. 減少開發工作量 | 開發者只需調用過程,避免重復寫 SQL,提高開發效率。 |
| ? 4. 增強數據安全性 | 可設置權限控制,用戶只能訪問授權存儲過程,不直接操作底層表。 |
| ? 5. 降低網絡通信成本 | 客戶端只需一次調用,無需多次發送復雜 SQL,節省網絡帶寬與響應時間。 |
| ? 6. 適合執行復雜業務邏輯 | 封裝控制流程(IF、LOOP、CASE)更容易組織復雜業務規則。 |
缺點:
| ?? 1. 可移植性差 | 不同數據庫的語法和支持程度不同(如 MySQL 與 Oracle 存儲過程差異大),跨平臺遷移困難。 |
| ?? 2. 調試不方便 | 多數數據庫缺少完善的調試工具,過程內錯誤排查困難,調試成本高。 |
| ?? 3. 版本管理困難 | 存儲過程通常不受代碼版本控制系統(如 Git)管理,迭代不透明、易錯難追蹤。 |
| ?? 4. 維護成本高 | 對團隊協作和文檔要求高,邏輯變更需謹慎更新過程,否則容易造成邏輯失效。 |
| ?? 5. 不適合高并發環境 | 高并發場景更強調可擴展性與解耦,存儲過程綁定數據庫邏輯,難以靈活應對分庫分表等架構。 |










)








