一、RKNN部署及工具包安裝
參考1:https://blog.csdn.net/qq_40280673/article/details/136211086#/
參考2:瑞芯微官方教程
RKNN部署針對瑞芯微芯片優化,支持NPU硬件加速,需要安裝rknn-toolkit,用于將pytorch模型轉換為RKNN模型
以下操作均在ubuntu中進行
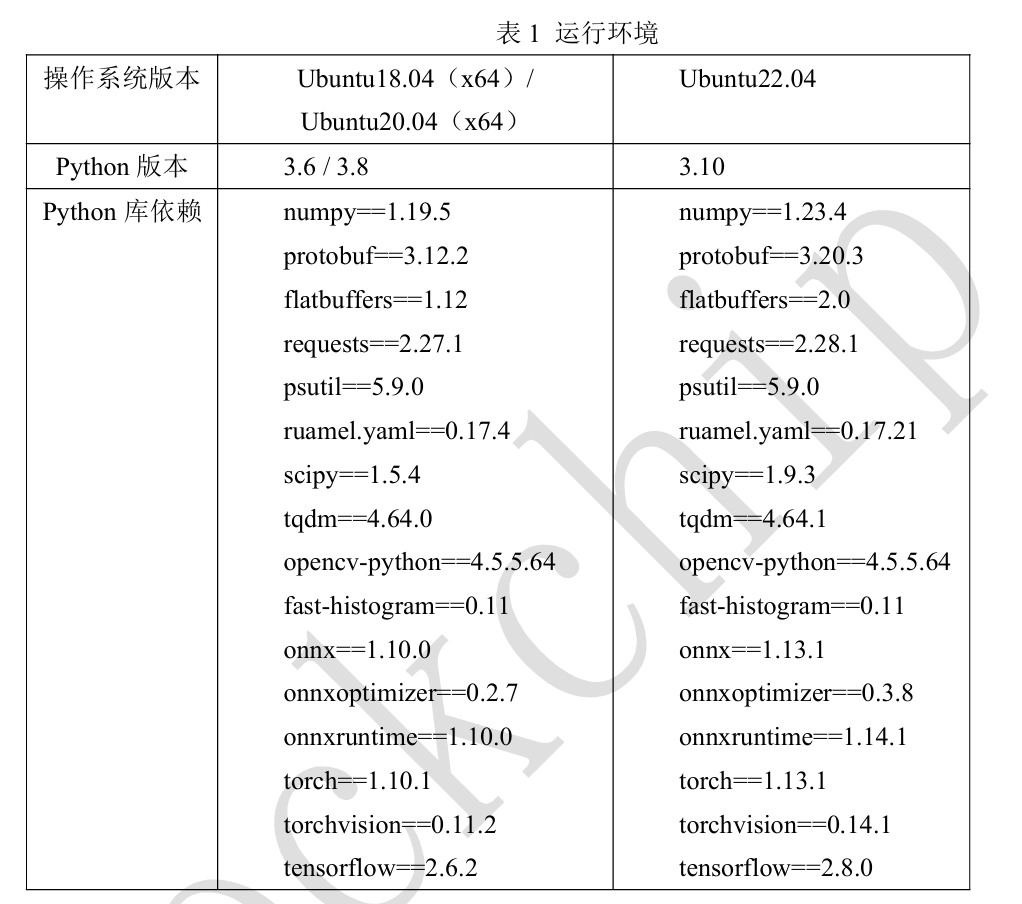
運行環境要求如下:
1、安裝python及相關依賴
sudo apt-get install python3 python3-dev python3-pip
sudo apt-get install libxslt1-dev zlib1g zlib1g-dev libglib2.0-0 libsm6 libgl1-mesa-glx libprotobuf-dev gcc
2、創建虛擬環境
# 創建虛擬環境
conda create -n your_env_name
# 激活虛擬環境
conda activate your_env_name
3、下載系統依賴及rknn-tookit安裝包
系統依賴的庫:requirements_cpxx-1.5.0.txt;
rknn-toolkit2安裝包:rknn_toolkit2-1.5.0+fa95b5c-cpxx-linux_x86_64.whl
上述兩個文件自取:
通過網盤分享的文件:libpackages
鏈接: https://pan.baidu.com/s/10xjTZ2Wr8CgGFV80tfXmZA 提取碼: wwzn
【注】 cpxx取決于安裝的python版本,如我的環境是ubuntu22.04,python版本3.10,因此我需要安裝的是requirements_cp310-1.5.0.txt和rknn_toolkit2-1.5.0+fa95b5c-cp310-linux_x86_64.whl
4、安裝系統依賴及rknn-toolkit2
激活需要安裝的虛擬環境,運行以下指令時,執行目錄須為txt文件和whl文件所在目錄,也可以指定文件所在路徑
pip install -r requirements_cp310-1.5.0.txt -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
pip install rknn_toolkit2-1.5.0+1fa95b5c-cp310-cp310-linux_x86_64.whl -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
【注】 安裝過程中可能有包下載不成功,可以手動pip安裝,多試幾個鏡像源,或者爬梯子安裝,一定要確保所有包安裝成功
二、pytorch模型轉換為rknn模型
我的文件結構如下:
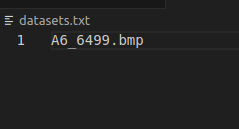
datasets.txt的內容為
1、torch.nn.module——>rknn
參考1:https://blog.csdn.net/qq_40280673/article/details/136229500#/ 大佬的公眾號有源碼包,可以下載后執行
我參考著導出了一下yolov11n-cls模型:
【注】 要使用相同版本的pytorch導出模型并轉為RKNN模型,否則會因為前后版本不一致導致RKNN轉換失敗。
# yolov11n-cls.pt轉rknn模型
'''
1、導入RKNN包
2、實例化RKNN對象
3、定義數據預處理和量化方法
4、加載pytorch模型,即'.pt'文件
5、構建rknn模型
6、導出rknn模型
7、釋放RKNN對象
'''
from rknn.api import RKNNif __name__=="__main__":rknn = RKNN()'''初始化RKNN對象時,可以設置verbose和verbose_file參數:verbose:是否在屏幕上打印詳細的日志信息verbose_file:日志文件示例:將詳細日志信息輸出到屏幕,并寫入到build.log文件中rknn=RKNN(verbose=True,verbose_file='./build.log')'''rknn.config(mean_values=[[0.0, 0.0, 0.0]], std_values=[[1.0, 1.0, 1.0]],target_platform='rk3588')'''def config(mean_values: Any | None = None, 輸入的均值,用于數據預處理中的normalization,如mean_values=[128, 128, 128]]表示輸入的三個通道的值減去128std_values: Any | None = None, 輸入的標準差,用于數據預處理中的normalization,如std_values=[[128, 128, 128]]表示輸入的三個通道減去均值后再除以128quantized_dtype: str = 'asymmetric_quantized-8',量化類型,目前支持asymmetric_quantized-8、asymmetric_quantized-16quantized_algorithm: str = 'normal',計算每一層的量化參數時采用的量化算法,目前支持normal、mmse和kl_divergencenormal:速度快,推薦量化數據量一般為20-100張左右mmse:暴力迭代方式,速度較慢,但精度比normal要高,推薦量化數據量20-50張左右kl_divergence:所有時間比normal多,比mmse少,適用于feature分布不均勻的場景,推薦量化數據量20-100張左右quantized_method: str = 'channel',目前支持layer、channellayer:每層的weight只有一套量化參數channel:每層的weight的每個通道都有一套量化參數,因此channel會比layer精度高target_platform: Any | None = None,指定RKNN模型是基于那個目標芯片平臺生成的,目前支持‘rk3566’、‘rk3588’等quant_img_RGB2BGR: bool = False,表示在加載量化圖像時是否需要先做RGB2BGR的操作(一般用在Caffe模型上)。如果有多個輸入,則用列表包括起來,如[True, True, False]該配置只對jpg/jpeg/png/bmp格式的圖片有效該配置僅用于量化階段(build接口)讀取量化圖像或量化精度分析(accuracy_analysis接口),并不會保存在最終的RKNN模型中,因此如果模型的輸入為bgr,則調用toolkit2的inference或C-API的run函數之前需要保證傳入的圖像數據為BGR格式float_dtype: str = 'float16',用于制定非量化情況下的浮點的數據類型,目前只支持float16optimization_level: int = 3,模型優化等級,通過修改該值可以關掉部分或全部模型轉換過程中使用到的優化規則optimization_level=3:打開所有優化選項optimization_level=1或2:關閉一部分可能會對部分模型精度產生影響的優化選項optimization_level=0:關閉所有優化選項custom_string: Any | None = None,添加自定義字符串信息到RKNN模型,可以在runtime時通過query查詢到該信息,方便部署時根據不同的RKNN模型做特殊處理remove_weight: bool = False,去除conv等權重以生成一個RKNN的從模型,該從模型可以與帶完整權重的RKNN模型共享權重以減少內存消耗compress_weight: bool = False,壓縮模型權重,可以減小RKNN模型的大小inputs_yuv_fmt: Any | None = None,single_core_mode: bool = False,是否僅生成單核模型,可以減小RKNN模型的大小和內存消耗,目前僅對RK3588生效dynamic_input: Any | None = None,用于根據用戶制定的多組輸入shape,來模擬動態輸入的功能,格式為[[input0_shapeA, input1_shapeA, ...], [input0_shapeB, input1_shapeB, ...], ...]假設原始模型只有一個輸入,shape為[1, 3, 224, 224],但需要該模型支持3種不同的輸入shape,如[1, 3, 224, 224], [1, 3, 192, 192]和[1, 3, 160, 160]可以設置dynamic_input=[1, 3, 224, 224], [1, 3, 192, 192]和[1, 3, 160, 160],轉換成RKNN模型后進行推理時,需要傳入對應shape的數據【注】需要原始模型支持動態輸入才可以開啟此功能model_pruning: bool = False,對模型進行無損剪枝,對于權重稀疏的模型,可以減小轉換后RKNN模型的大小和計算量op_target: Any | None = None,用于指定OP的具體執行目標(如NPU/CPU/GPU等)格式為{'op0_output_name':'cpu', 'op1_output_name':'npu',...}'op0_output_name'和'op1_output_name'對應op的輸出tensor名,可以通過精度分析(accuracy_analysis)返回結果中獲取'cpu'和'npu'表示該tensor對應的op的執行目標是CPU或NPU**kwargs: Any)無返回值'''rknn.load_pytorch(model = "yolov11n-cls.pt",input_size_list = [[1, 3, 480, 480]])'''def load_pytorch(model: Any,pytorch模型文件(.pt)路徑,必須是torchscript格式的input_size_list: Any每個輸入節點對應的shape,所有輸入shape存放在一個列表中) 返回值:0:導入成功;-1;導入失敗'''rknn.build(do_quantization=True,dataset='datasets.txt')'''def build(do_quantization: bool = True,是否對模型進行量化dataset: Any | None = None,用于量化校正的數據及,目前僅支持文本文件格式,用戶可以把用于校正的圖片(jpg、bmp或png格式)放到一個.txt文件中,文本文件中每一方存放一條路徑信息,如a.jpg如果有多個輸入,每個輸入對應的文件用空格隔開,如a.jpg b.jpgrknn_batch_size: Any | None = None模型的輸入batch參數調整,如果設置為大于1,則可以在一次推理中同時推理多幀輸入圖像或輸入數據會同時改變輸入和輸出的batch)返回值:0:構建成功;-1:構建失敗'''rknn.export_rknn(export_path="yolov11n-cls.rknn")'''def export_rknn(export_path: Any,導出模型文件的路徑cpp_gen_cfg: Any | None = None,是否生成C++部署示例,生成文件:模型路徑同文件夾下,生成rknn_deploy_demo文件夾、說明文檔;支持驗證模型推理是,各CAPI接口耗時;驗證推理結果的余弦精度;支持常規API接口;支持圖片/NPY輸入**kwargs: Any)返回:0:導出成功;-1:導出失敗'''print("finisned")rknn.release()2、torch.nn.module——>onnx——>rknn
可以通過onnx作為中轉解決pytorch導出和轉換rknn模型的版本不一致問題
參考2:瑞芯微的官方教程
可以看出,onnx轉rknn的程序與torch模型轉rknn唯一的不同就是在加載模型時,使用load_onnx()
【注】 onnx的opset版本需要注意,如果導出失敗可以根據報錯提示,去修改導出onnx文件中的opset的版本號,如報錯信息為ValueError: Unsupport onnx opset 17, need <= 12!,在導出onnx文件中設置model.export(format=“onnx”, opset=11) 即可
from rknn.api import RKNNif __name__=='__main__':rknn = RKNN()rknn.config(mean_values=[[0.0, 0.0, 0.0]],std_values=[[1.0, 1.0, 1.0]],target_platform='rk3588')rknn.load_onnx('yolov11n-cls.onnx')'''def load_onnx(model: Any,onnx模型文件路徑inputs: Any | None = None,模型輸入節點(tensor名),支持多個輸入節點,所有輸入節點名放在一個列表中input_size_list: Any | None = None,每個輸入節點對應的shape,所有輸入shape放在一個列表中。如果inputs有設置,input_size_list也需要設置input_initial_val: Any | None = None,設置模型輸入的初始值,格式為ndarray的列表。主要用于將某些輸入固化為常量,對于不需要固化為常量的輸入可以設置為Noneoutputs: Any | None = None模型的輸出節點(tensor名),支持多個輸出節點,所有輸出節點名放在一個列表中)返回值:0:導入成功;-1:導入失敗'''rknn.build(do_quantization=True,dataset='datasets.txt')rknn.export_rknn('yolov11n-cls.rknn')rknn.release()三、模型推理
模型推理有兩種方式:
1、在PC上運行非RKNN模型
2、在NPU上運行RKNN模型
1、在PC上運行非RKNN模型
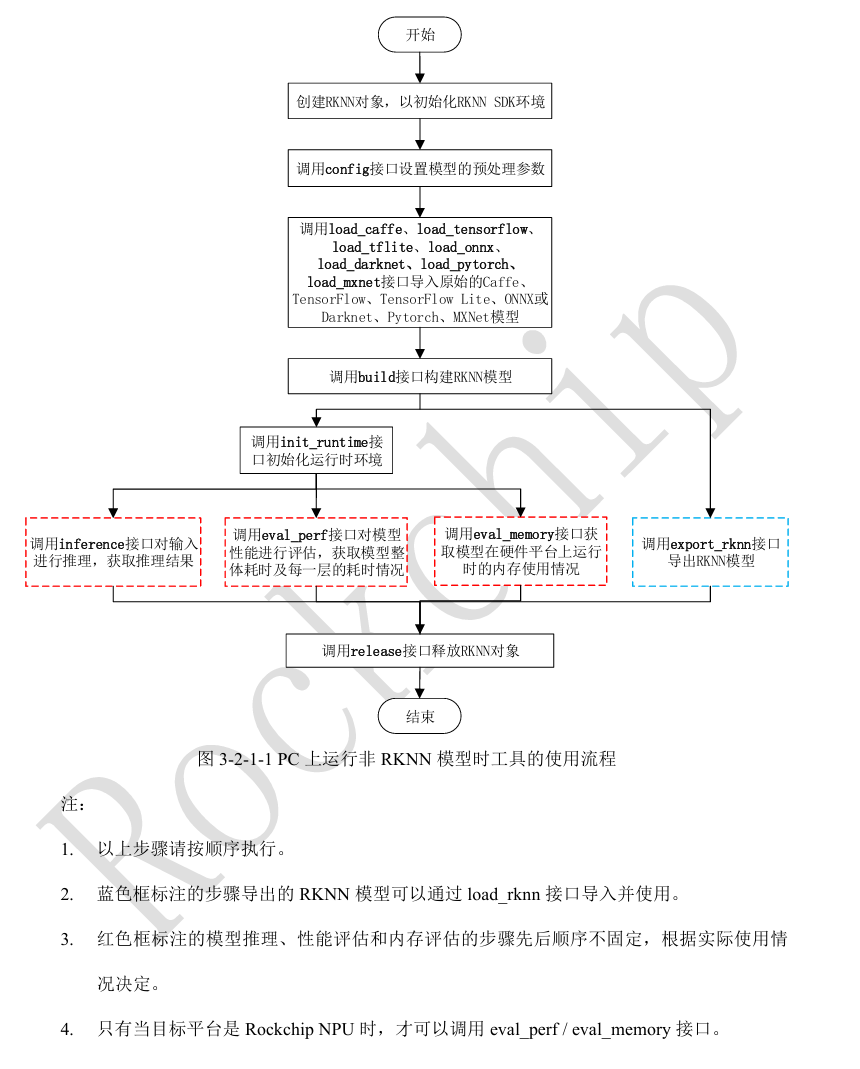
實現步驟為:
'''
1、實例化RKNN對象
2、調用Config接口設置模型的預處理參數
3、調用load_pytorch、load_onnx接口導入pytorch\onnx模型等
4、調用build接口構建RKNN模型
5、調用ini_runtime接口初始化運行環境,注意設置target=None,表示在模擬器上運行
6、導入要推理的數據并預處理數據
7、調用inference接口進行推理,獲取推理結果
8、釋放RKNN對象
'''
實現代碼如下:
from rknn.api import RKNN
import cv2
import numpy as npif __name__=='__main__':rknn = RKNN()rknn.config(mean_values=[[0.0, 0.0, 0.0]], std_values=[[1.0, 1.0, 1.0]],target_platform='rk3588')# rknn.load_pytorch('yolov11n-cls.pt',# input_size_list=[[1, 3, 480, 480]])rknn.load_onnx('yolov11n-cls.onnx',input_size_list=[[1, 3, 480, 480]])rknn.build(do_quantization=True, dataset='datasets.txt', rknn_batch_size=-1)rknn.init_runtime(target=None,# target='rk3588',target_sub_class=None,device_id=None,perf_debug=False,eval_mem=False,async_mode=False,core_mask=RKNN.NPU_CORE_AUTO,)img = cv2.imread(filename='A6_6499.bmp')img = cv2.resize(img, (480, 480))cv2.cvtColor(img, cv2.COLOR_BGR2RGB)outputs = rknn.inference(inputs=[img],data_format="nhwc",'''cv2.imread()讀取的圖像數據的layout為NHWC,data_format的默認值為NHWC,如果模型的輸入不是通過cv2.imread()讀取,需要設置正確的data_format值''')print(np.array(outputs[0][0]))rknn.release()2、在NPU上運行RKNN模型
2.1 推理前的準備工作
1)確保開發板的USB OTG連接到PC,并正確識別到設備。可以通過adb device命令查詢相應設備,也可調用rknn-toolkit2的list_devices接口查詢相應設備。
rknn = RKNN()
rknn.list_devices()
'''
def list_devices():無參數,返回adb_devices列表和ntb_devices列表,如果設備為空,則返回空列表
'''
rknn.release()輸出為:
*************************
all device(s) with adb mode:
VD46C3KM6N
*************************
2)參考https://github.com/rockchip-linux/rknpu2/blob/master/rknn_server_proxy.md說明更新開發板的runtime庫和rknn_server庫,并確保rknn_server服務已經啟動(大部分平臺需要手動通過串口啟動)
3)調用init_runtime接口初始化運行環境時需要指定target參數(開發平臺,如target=‘rk3588’)和device_id參數(由步驟2list_devices中獲取,如本例程中device_id=‘VD46C3KM6N’)。
2.2 模型推理實現步驟
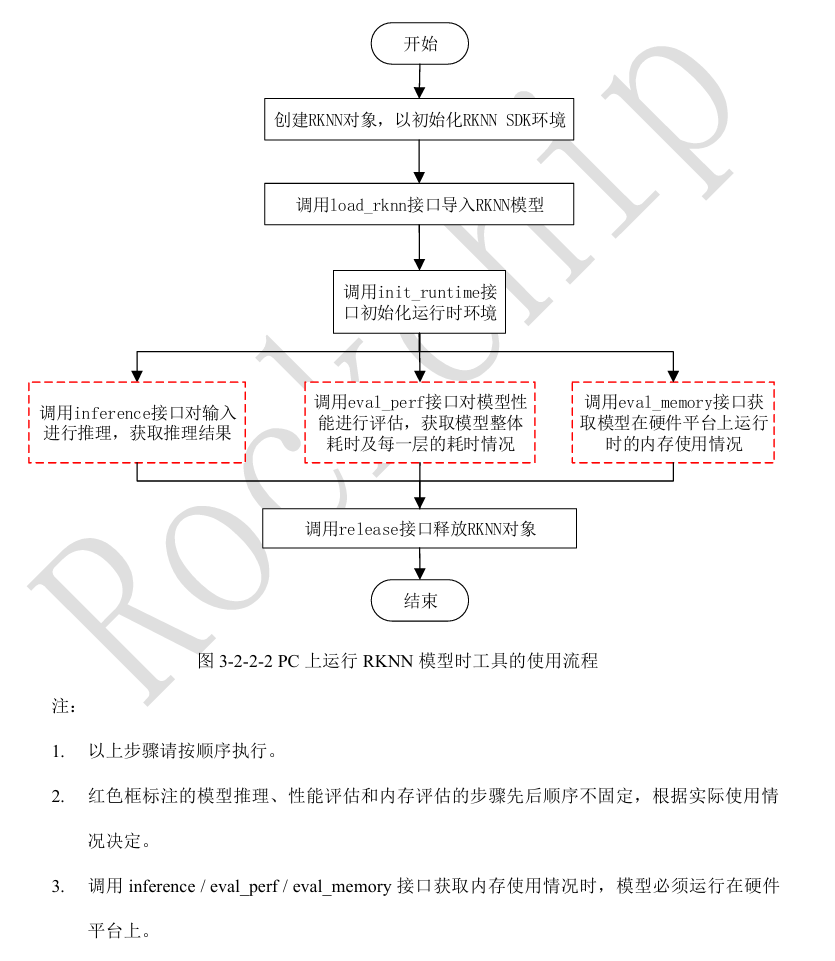
'''
運行RKNN模型,不需要設置模型預處理參數,也不需要構建RKNN模型,推理流程:
1、實例化RKNN對象
2、調用load_rknn導入RKNN模型
3、調用init_runtime初始化,注意設置target='rk3588', device_id的值需要通過rknn.list_devices獲取
4、導入要處理的數據并處理成需要的輸入格式
5、調用inference進行推理并獲取推理結果
6、釋放RKNN對象
'''
實現代碼:
from rknn.api import RKNN
import cv2
import numpy as npif __name__=="__main__":rknn = RKNN()rknn.load_rknn('yolov11n-cls.rknn')rknn.init_runtime(target='rk3588',device_id='VD46C3KM6N')img = cv2.imread(filename='A6_6499.bmp')img = cv2.resize(img, (480, 480))cv2.cvtColor(img, cv2.COLOR_BGR2RGB)outputs = rknn.inference(inputs=[img],data_format="nhwc", '''cv2.imread()讀取的圖像數據的layout為NHWC,data_format的默認值為NHWC,如果模型的輸入不是通過cv2.imread()讀取,需要設置正確的data_format值''')print(np.array(outputs[0][0]))rknn.release()四、模型量化
RKNN模型量化是一種將深度學習模型從浮點精度(如FP32)轉換為低比特整數(如INT8)的技術,旨在減少模型體積、提升推理速度并降低功耗。量化對象:權重量化(模型參數從浮點轉為整數)、激活量化(推理時中間特征圖的數值轉換)
4.1 量化原理:
1)線性量化原理
- 使用比例因子scale和零點zero_point將浮點值映射到整數區間, quantized_value = round(float_value / scale) + zero_point
- 反量化是還原近似原始值,float_value ≈ (quantized_value - zero_point) * scale
2)校準過程(PTQ)
- 通過校準數據集統計各層激活值的動態范圍,確定最優scale和zero_point
- 關鍵作用:減少量化誤差,避免數值溢出或截斷
3)量化類型
- 對稱量化:零點為0,適合權重分布對稱的場景
- 非對稱量化,零點非0,適合偏態分布數據
- 混合精度量化:敏感層保留FP16,其他層用INT8
4.2 量化精度分析
重點函數為accuracy_analysis()
【注】 該接口只能在build和hybrid_quantization_step2之后調用。
【注】 如未制定target,且原始模型應該為已量化的模型,否則會調用失敗
【注】 該接口使用的量化方式與config中制定的一致。
4.2.1 量化精度分析步驟
- 實例化RKNN對象
- 設置模型預處理和量化參數
- 調用load_onnx等接口導入模型
- 調用build構建模型
- 調用accuracy_analysis進行量化精度分析
- 釋放RKNN對象
4.2.2 代碼實現
from rknn.api import RKNNif __name__=="__main__":rknn = RKNN()rknn.config(mean_values=[[0.0, 0.0, 0.0]],std_values=[[1.0, 1.0, 1.0]],target_platform='rk3588')rknn.load_onnx('yolov11n-cls.onnx')rknn.build(do_quantization=True, dataset='datasets.txt')rknn.accuracy_analysis(inputs=['A6_6499.bmp'],output_dir='snapshot',target=None, # 如果連接了開發板,target='rk3588', device_id=設備編號device_id=None)'''推理并產生快照,也就是dump出每一層的tensor數據,會dump出包括fp32和quant兩種數據類型的快照,用于計算量化誤差。def accuracy_analysis(inputs: Any,圖像(jpg/png/bmp/npy等)路徑listoutput_dir: str = './snapshot',輸出目錄,所有快照都保存在該目錄下,默認值為'./snapshot'如果沒有設置target,在output_dir下會輸出:1、simulator目錄:保存整個量化模型在simulator上完整運行時每一層的結果(已經轉成float32)2、golden目錄:保存整個浮點模型在simulator上完整跑下來時每一層的結果3、error_analysis.txt:記錄simulator上量化模型逐層運行時每一層的結果與golden浮點模型逐層運行時每一層的結果的余弦距離(entire_error cosine),以及量化模型取上一層的浮點結果作為輸入時,輸出與浮點模型的余弦距離(single_error cosine)如果有設置target,則在output_dir里還會多輸出:1、runtime目錄:保存整個量化模型在NPU上完整運行時每一層的結果(已轉成float32)2、error_analysis.txt:在上述記錄內容的基礎上,還會記錄量化模型在simulator上逐層運行時每一層的結果的余弦距離target: Any | None = None,目標硬件平臺,如果設置了target,則會獲取NPU運行時每一層的結果,并進行精度分析device_id: Any | None = None設備編號,如果pc連接多臺設備時,需要指定該參數)返回值:0:成功;-1:失敗'''rknn.release()
4.2.3 輸出
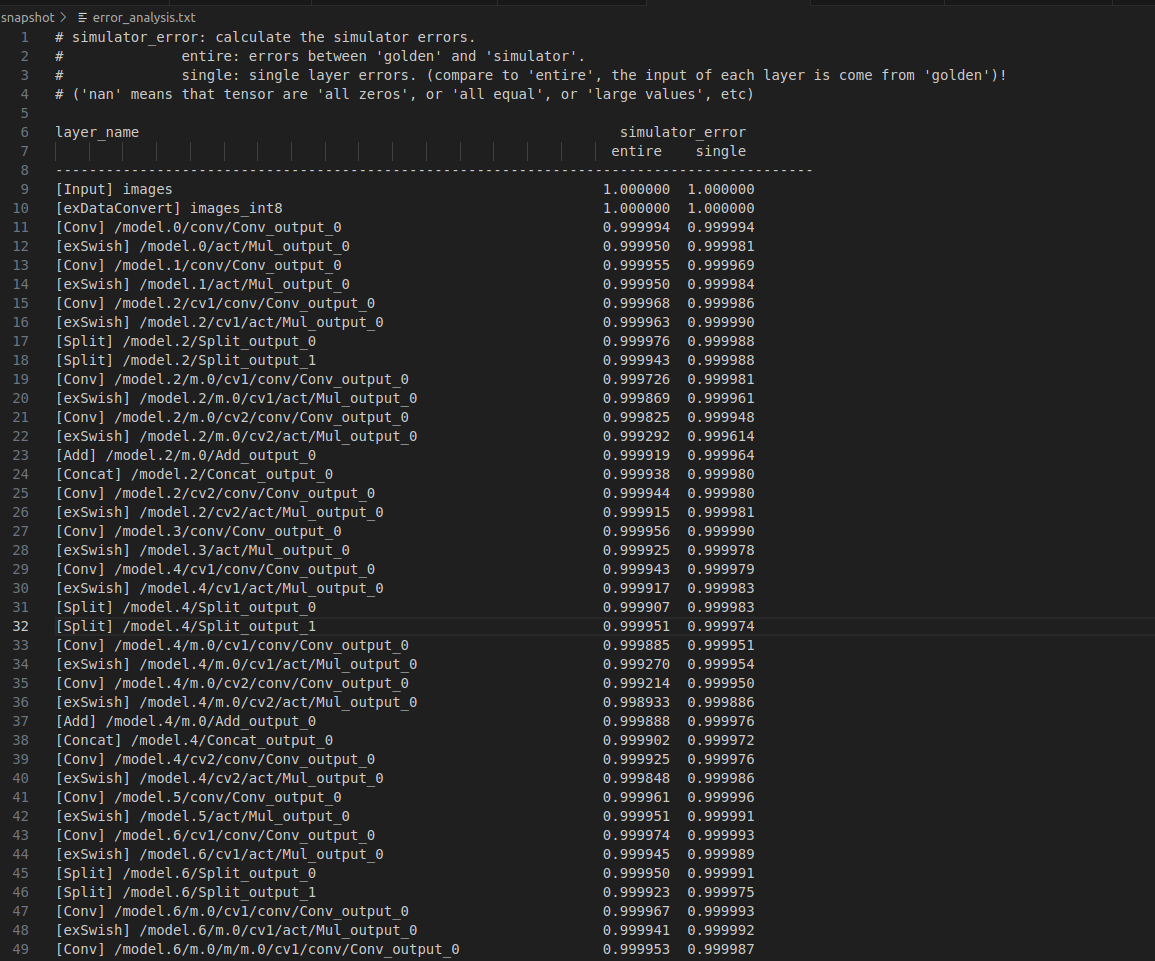
上圖右側有兩列數值輸出,其中entire表示simulator上量化模型逐層運行時每一層的結果與golden浮點模型逐層運行時每一層的結果的余弦距離,即量化模型整體輸出與原始浮點模型(golden)的誤差,反映端到端的累計誤差;sigle表示量化模型取上一層的浮點結果作為輸入時,輸出與浮點模型的余弦距離,反映單層量化精度。值越接近于1表示誤差越小。
【警惕關鍵現象1】 誤差值范圍,越接近1 表示量化誤差越小,若出現顯著下降(如0.99以下)須警惕精度損失
【警惕關鍵現象2】 NaN值,表示張量全零或數值極端,可能由無法激活或量化溢出導致。若存在須檢查校準數據或量化參數。
4.2.4 優化建議
1)敏感層定位:對比entire和single誤差差異較大層,優先采用混合量化
2)校準數據優化:若誤差集中在前幾層,需檢查輸入數據預處理是否與訓練一致
3)量化策略調整:對誤差突增層嘗試非對稱量化或調整量化粒度
4.3 混合量化
量化功能可能會使模型特殊模型的精度下降,為了在性能和精度之間做更好的平衡,混合優化功能,可以根據用用戶的手動指定某些層是否進行量化。
4.3.1 混合量化步驟
- 生成混合量化配置文件,hybrid_quatization_step1()
- 修改第一步生成的量化配置文件(.quantization.cfg)
- 生成新的RKNN模型,hybrid_quantization_step2()
4.3.2 生成混合量化配置文件
重要API為hybrid_quatization_step1(),執行以下代碼會生成臨時模型文件(.model)、數據文件(.data)和量化配置文件(.quantization.cfg)
步驟為:
- 實例化RKNN對象
- 設置模型預處理參數config
- 加載模型文件, onnx等
- 調用hybrid_quantization_step1()
- 釋放RKNN對象
from rknn.api import RKNNif __name__=="__main__":rknn = RKNN()rknn.config(mean_values=[[0.0, 0.0, 0.0]],std_values=[[1.0, 1.0, 1.0]],target_platform='rk3588')rknn.load_onnx('./yolov11n-cls.onnx')rknn.hybrid_quantization_step1(dataset='./datasets.txt',proposal=True,)'''用于生成臨時模型文件(.model)、數據文件(.data)和量化配置文件(.quantization.cfg)def hybrid_quantization_step1(dataset: Any | None = None,量化用的數據集rknn_batch_size: Any | None = None,模型的輸入batch參數的調整proposal: bool = False,產生混合量化的配置建議proposal_dataset_size: int = 1proposal使用的dataset的張數,默認為1.因proposal功能比較耗時,所以默認只是用1張,也就是dataset里的第一張)'''rknn.release()
yolov11n-cls.quatization.cfg文件內容如下
custom_quantize_layers:/model.0/conv/Conv_output_0: float16/model.0/act/Mul_output_0: float16/model.1/conv/Conv_output_0: float16/model.2/m.0/cv1/conv/Conv_output_0: float16/model.2/m.0/cv1/act/Mul_output_0: float16/model.2/m.0/Add_output_0: float16/model.2/Concat_output_0: float16/model.4/m.0/cv2/conv/Conv_output_0: float16/model.4/m.0/cv2/act/Mul_output_0: float16/model.4/m.0/Add_output_0: float16/model.4/Concat_output_0: float16/model.4/cv2/conv/Conv_output_0: float16/model.4/cv2/act/Mul_output_0: float16/model.5/conv/Conv_output_0: float16/model.6/m.0/m/m.0/cv1/act/Mul_output_0: float16/model.6/m.0/m/m.0/cv2/conv/Conv_output_0: float16/model.6/m.0/m/m.0/cv2/act/Mul_output_0: float16/model.6/m.0/m/m.0/Add_output_0: float16/model.6/m.0/cv3/act/Mul_output_0: float16/model.6/Concat_output_0: float16/model.8/m.0/m/m.0/cv1/act/Mul_output_0: float16/model.8/m.0/m/m.0/cv2/conv/Conv_output_0: float16/model.8/m.0/m/m.0/cv2/act/Mul_output_0: float16/model.8/m.0/m/m.0/Add_output_0: float16/model.8/m.0/m/m.1/cv1/conv/Conv_output_0: float16/model.8/m.0/m/m.1/Add_output_0: float16/model.8/m.0/m/m.1/cv1/act/Mul_output_0: float16/model.8/m.0/m/m.1/cv2/conv/Conv_output_0: float16/model.8/m.0/m/m.1/cv2/act/Mul_output_0: float16/model.8/m.0/Concat_output_0: float16/model.8/m.0/cv3/conv/Conv_output_0: float16/model.8/m.0/cv3/act/Mul_output_0: float16/model.8/Concat_output_0: float16/model.8/cv2/conv/Conv_output_0: float16/model.8/cv2/act/Mul_output_0: float16/model.9/cv1/conv/Conv_output_0: float16/model.9/cv1/act/Mul_output_0: float16/model.9/Split_output_0: float16/model.9/Concat_output_0: float16/model.9/Split_output_1: float16/model.9/m/m.0/attn/qkv/conv/Conv_output_0: float16/model.9/m/m.0/Add_output_0: float16/model.9/m/m.0/attn/Reshape_output_0: float16/model.9/m/m.0/attn/Split_output_0: float16/model.9/m/m.0/attn/Softmax_output_0: float16/model.9/m/m.0/attn/Transpose_1_output_0: float16/model.9/m/m.0/attn/MatMul_1_output_0: float16/model.9/m/m.0/attn/Reshape_1_output_0: float16/model.9/m/m.0/attn/Add_output_0: float16/model.9/m/m.0/attn/proj/conv/Conv_output_0: float16/model.9/m/m.0/ffn/ffn.0/act/Mul_output_0: float16/model.9/m/m.0/ffn/ffn.1/conv/Conv_output_0: float16/model.9/cv2/act/Mul_output_0: float16/model.10/conv/conv/Conv_output_0: float16/model.10/conv/act/Mul_output_0: float16/model.10/pool/GlobalAveragePool_2conv_0: float16/model.10/pool/GlobalAveragePool_output_0: float16/model.10/linear/Gemm_output_0_conv: float16
quantize_parameters:images:qtype: asymmetric_quantizedqmethod: layerdtype: float32min:- 0.0max:- 255.0scale: []zero_point: []ori_min:- 0.0ori_max:- 255.0...其中,custom_quatize_layers是一個自定義量化tensor字典,用戶可以將tensor名和相應的量化類型添加到該字典中,即可實現將該tensor作為輸出的層的運算類型改為指定的運算類型。上面的文件是我的rknn導出的cfg文件,可以看出custom_quatize_layers已經列了一些優化層了。
quantize_parameters:是模型中每個tensor的量化參數,每一個tensor都是一個字典,每個字典的key為tensor的名,字典的value為量化參數,如果沒有經過量化,dtype值為float16
4.3.3 修改第一步生成的量化配置文件(.quantization.cfg)
為了測試一下混合量化,我自己修改了一下我的cfg文件,在上一步量化精度分析中,下面兩層的entire和single誤差差值有一點點大
[exSwish] /model.4/cv1/act/Mul_output_0 0.999917 0.999983
[Split] /model.4/Split_output_0 0.999907 0.999983
因此修改yolov11n-cls.quatization.cfg文件如下
【注】 custom_quantize_layers格式問題,官方文檔給的是custom_quantize_layers:{x:float16, x2:float16},但是我這邊會報錯,改成YAML格式的就好了,不曉得為啥。YAML不需要{},也不需要,作為分割,只要縮進做好就可,詳細請參考下述代碼
custom_quantize_layers:/model.4/cv1/act/Mul_output_0:float16/model.4/Split_output_0:float16# 將/model.4/cv1/act/Mul_output_0,/model.4/Split_output_0設置為float16,即不進行量化quantize_parameters:images:qtype: asymmetric_quantizedqmethod: layerdtype: float32min:- 0.0max:- 255.0scale: []zero_point: []ori_min:- 0.0ori_max:- 255.0/model.0/conv/Conv_output_0:qtype: asymmetric_quantizedqmethod: layerdtype: int8min:- -15024.08984375max:- 9862.2978515625scale:- 97.59367723651961zero_point:- 26ori_min:- -15024.08984375ori_max:- 9862.2978515625
4.3.4 生成新的RKNN模型,hybrid_quantization_step2()
步驟為:
- 實例化RKNN對象
- 調用hybrid_quantization_step2()
- 調用accuracy_analysis()再次評估模型,驗證混合量化效果
- 導出RKNN模型
- 釋放RKNN模型
# 混合量化前
[exSwish] /model.4/cv1/act/Mul_output_0 0.999917 0.999983
[Split] /model.4/Split_output_0 0.999907 0.999983# 混合量化后
[exSwish] /model.4/cv1/act/Mul_output_0 0.999791 1.000000
[Split] /model.4/Split_output_0 0.999786 1.000000
五、模型部署
待更新



















