本篇文章依據ElasticSearch權威指南進行實操和記錄
1,空集群
即不包含任何節點的集群
集群大多數分為兩類,主節點和數據節點
主節點
-
職責:主節點負責管理集群的狀態,例如分配分片、添加和刪除節點、監控節點故障等。它們不直接處理搜索或數據存儲任務,但它們對于集群的健康和性能至關重要。
-
選舉過程:在Elasticsearch中,主節點是通過選舉產生的。默認情況下,集群中的任何節點都可以成為主節點候選者。這意味著任何一個節點都可以發起成為主節點的請求,然后與其他節點競爭以決定誰是新的主節點。
-
資源需求:主節點通常不需要太多的資源來處理其任務,因為它不直接處理數據。但是,它需要穩定的網絡連接和足夠的CPU來處理集群狀態管理任務。
數據節點
-
職責:數據節點負責存儲數據、搜索數據和處理與數據相關的操作,如索引和搜索請求。數據節點是執行實際數據存儲和檢索任務的地方。
-
資源需求:數據節點需要大量的資源來存儲和處理數據。這包括大量的內存(用于緩存)、磁盤空間(用于存儲數據)以及CPU資源(用于處理搜索和聚合查詢)。
-
配置:在Elasticsearch中,默認情況下,每個節點都是數據節點。但是,你可以通過配置來指定哪些節點應該僅作為主節點或僅作為數據節點運行
空集群即啟動節點且不包含任何數據和索引,由于集群中必有一個主節點,所以空集群比定為主節點
2,集群健康
集群健康是集群監控系統數據中的其中一項,而且最為重要
輸入如下指令
GET /_cluster/health返回
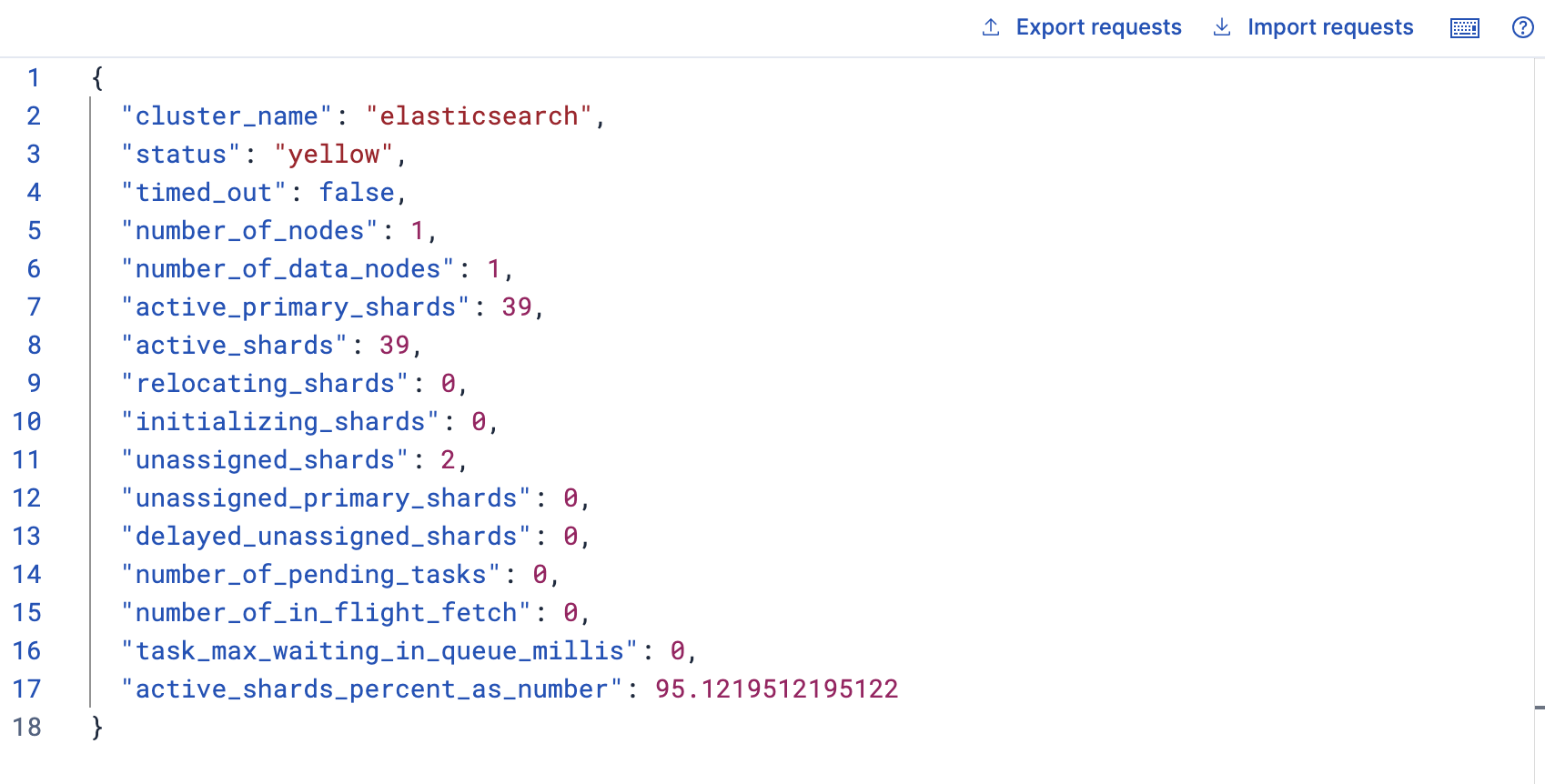
可以看到status返回了yellow
status狀態
status指示著當前集群在總體上是否工作正常。包括三種顏色,green:所有的主分片和副本分片都正常運行,yellow:所有的主分片都正常運行,但不是所有的副本分片都正常運行,red:有主分片沒能正常運行。
全部字段含義
{"cluster_name": "elasticsearch", //集群名稱"status": "green", //集群狀態 "timed_out": false, //檢查是否因超時中斷,false表示檢查完整完成"number_of_nodes": 2, //集群中節點總數(當前為2個)"number_of_data_nodes": 2, //具備數據存儲功能的節點數量(當前為2個)"active_primary_shards": 42, //活躍的主分片數(42個)"active_shards": 84,//總分片數(含副本,84個)"relocating_shards": 0, //正在遷移的分片數(0表示無遷移)"initializing_shards": 0, //初始化中的分片數"unassigned_shards": 0, //未分配的分片數"unassigned_primary_shards": 0,//未分配的主分片數"delayed_unassigned_shards": 0, //延遲未分配的分片數"number_of_pending_tasks": 0, //待處理任務數"number_of_in_flight_fetch": 0, //進行中的分片數據獲取操作數"task_max_waiting_in_queue_millis": 0, //任務隊列中最長等待時間的毫秒數"active_shards_percent_as_number": 100 //活躍分片百分比,100表示全部分片正常
}3,添加索引
索引之前這篇文章簡單介紹過ElasticSeach快速上手筆記-入門篇-CSDN博客??????
es的索引指的是存儲相關數據的數據結構,可以類比成mysql的數據表,es索引會存儲不同的數據結構key和value的關系
分片是一個 Lucene 的實例,以及它本身就是一個完整的搜索引擎。 我們的文檔被存儲和索引到分片內,但是應用程序是直接與索引而不是與分片進行交互
分片可以把數據分散存儲在es的集群中
同樣分片也分為主分片和副分片
主分片:每個索引被劃分成若干個主分片,每個主分片都是一個獨立的索引。主分片負責處理所有的讀和寫操作?,主分片的數量在索引創建時確定,之后不能更改?,主分片是數據存儲的基本單位,每個主分片存儲索引的一部分數據?
副分片:副本分片是主分片的完整復制,位于不同的節點上,副本的數量可以在索引運行時動態調整?,副本分片用于提高系統的可用性和容錯性。如果某個節點故障,系統仍然能夠通過副本分片提供服務?
新建索引
接下來參考權威指南在空集群新建一個索引
PUT /blogs
{"settings" : {"number_of_shards" : 3,"number_of_replicas" : 1}
}返回

可以看到成功新建
再次查看集群健康狀態
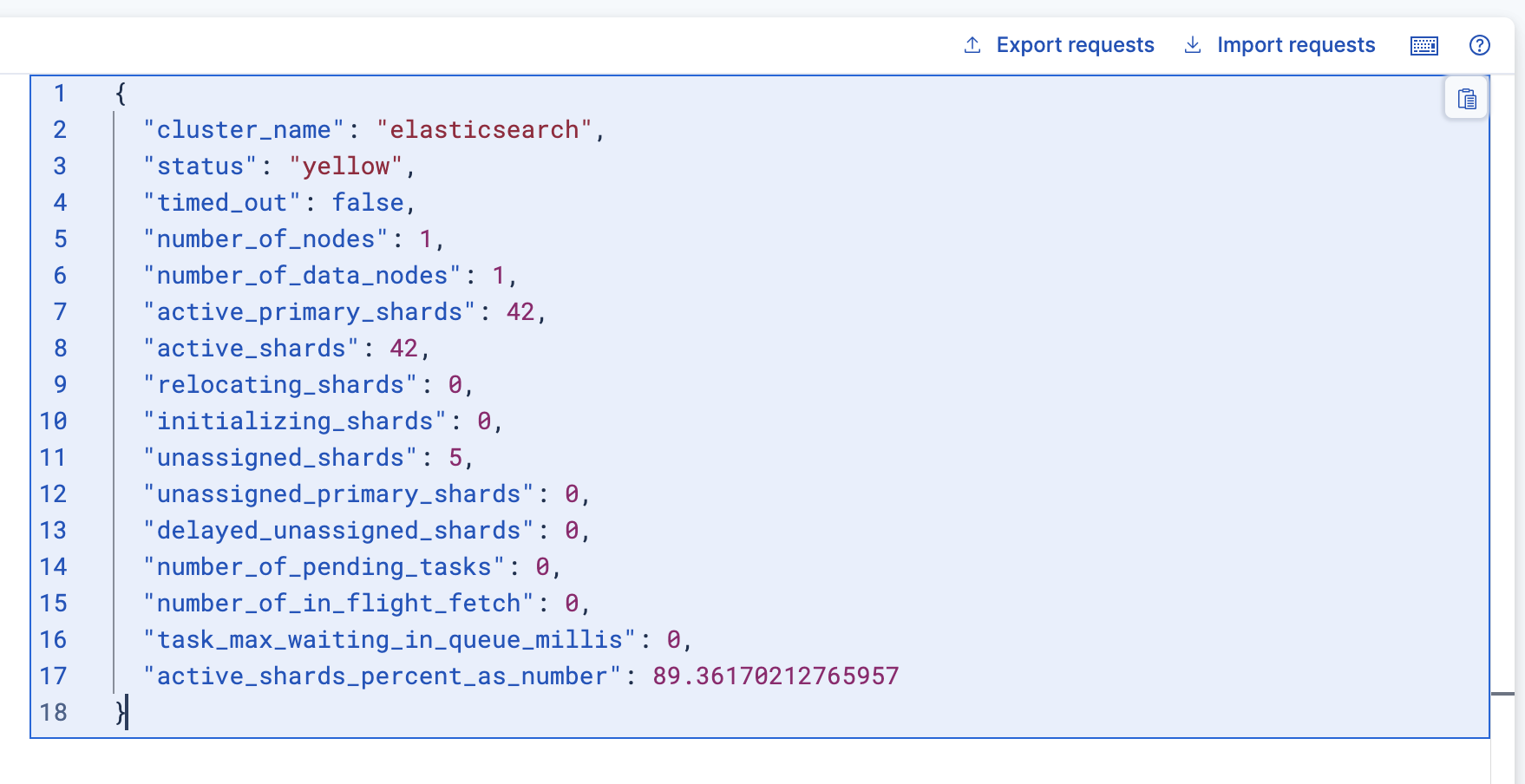
可以看到status=yellow,集群狀態主分片全部正常運行,但是副分片未全部正常,
unassigned_shards=5,這里處于未被分配狀態的分片數量有5個,除了最開始的2個,剛才又新建了2個,所以有5個
注意分片要不只存儲原始數據,要不只存儲副本數量,無需既存儲原始數據又存儲副本數據,這樣會在數據丟失的時候原始數據和副本全部丟失
4,添加故障轉移
當前咱的集群只有一個節點,這樣當前節點宕機等異常的時候會導致數據丟失
所以可以部署新的節點來解決這個問題
準備新節點
首先復制一份es文件

同時把data文件刪除掉

修改elasticsearch.yml文件
cluster.name: elasticsearchnode.name: node-1
http.port: 9303cluster.name:集群名字,確認兩個節點保持相同
node.name:節點名稱,不同的節點名稱唯一
http.port:端口號,各個節點均不同
啟動新節點
./bin/elasticsearch進入es文件下 和之前啟動節點相同執行以上指令
kibana查看節點數量
輸入指令
GET /_cat/nodes?v返回
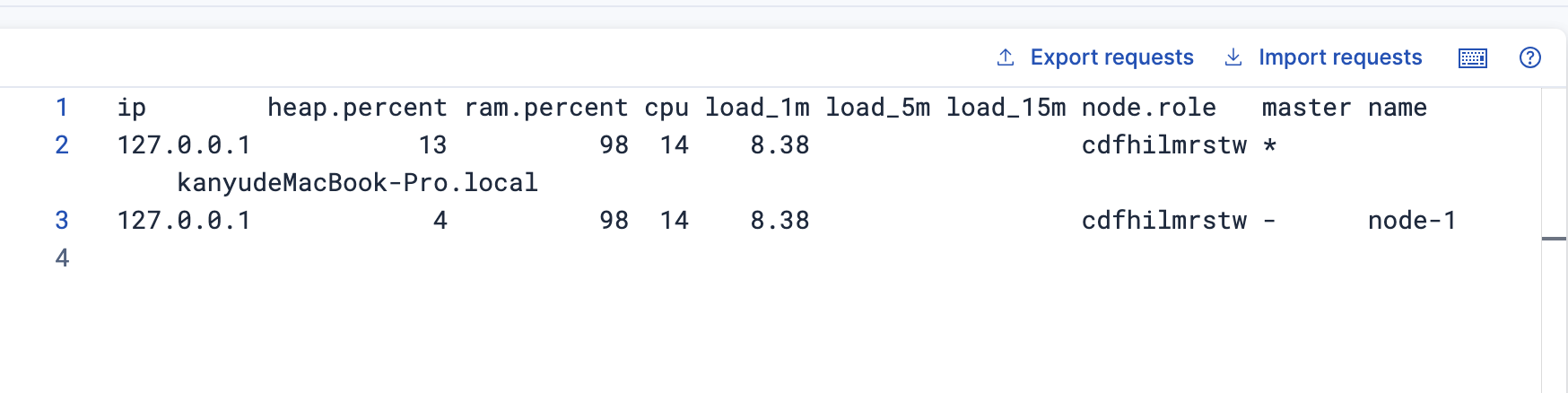
可以看到當前集群下有兩個節點
查看集群健康狀態
GET /_cluster/health
返回
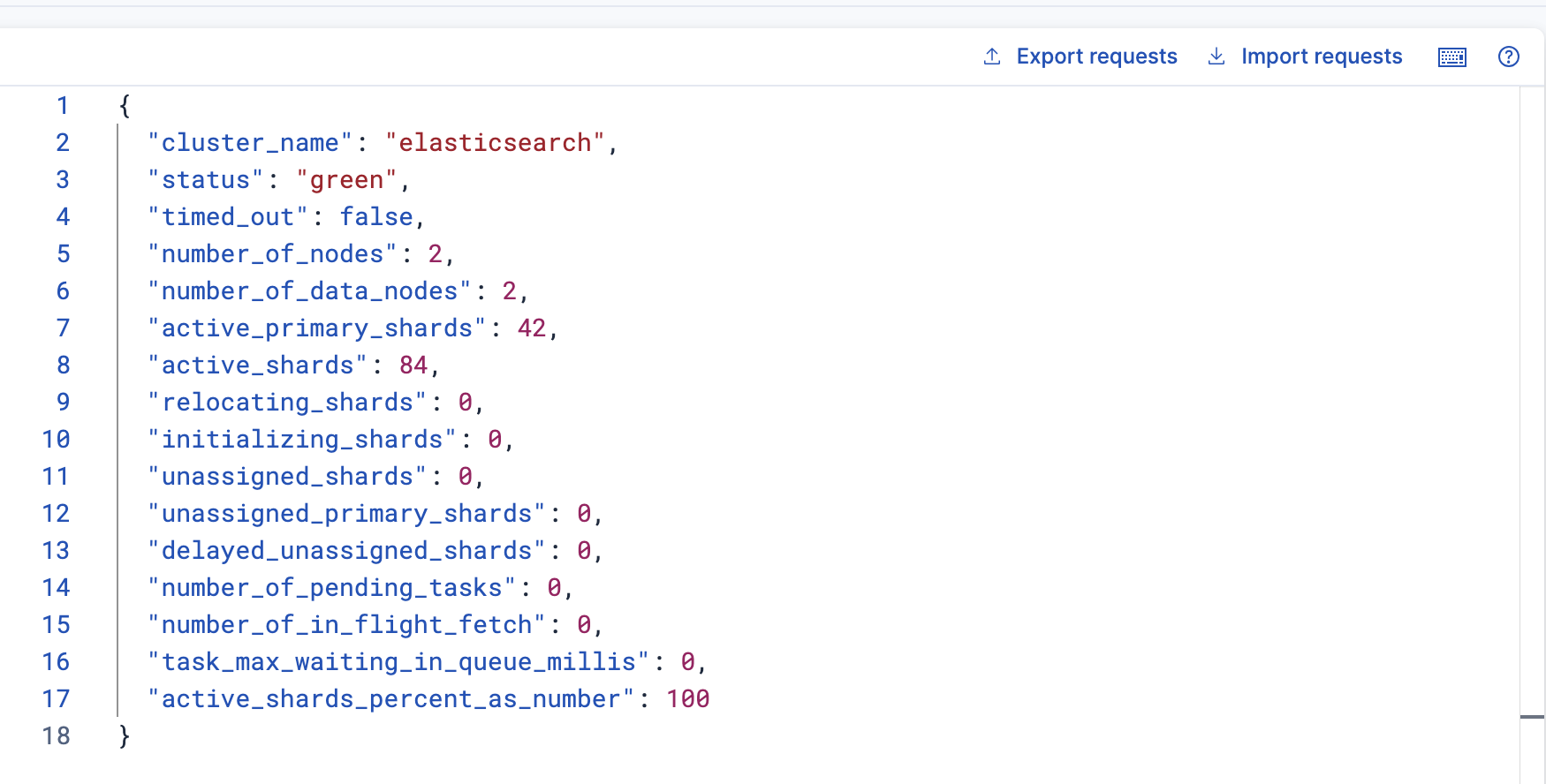
可以看到這個時候的status=green了 表明所有的節點都在正常運行
同時unassigned_shards的數量變成了0
表明所有的分片都分配好了
分片分布情況
節點一分片數量3個,節點二數量3個
可以看到兩個節點的分片是均勻分布的
5,水平擴容
在了解水平擴容之前,先了解下擴容有幾類
水平擴容:水平擴容是指增加更多的節點到集群中,而不是增加單個節點的資源。這種方式可以顯著提高系統的容量和處理能力
垂直擴展:垂直擴展是指增加單個節點的資源,比如增加CPU、內存或者存儲空間。這種方式通常通過升級單個節點的硬件來實現。
當開發的項目量級逐漸增加,需要的存儲的數據越來越多,只有兩個節點是遠遠不夠的,所以需進行水平擴容
增加節點3
參考之前部署節點部署節點3

可以看到節點3成功啟動了
重新查看當前集群的節點情況
GET /_cat/nodes?v
返回

可以看到這個時候多了節點node-3,共有3個節點
分片分布情況
node-1
node-1的分片有2個

node-3

node-3的分片有2個
默認節點

默認節點同樣有2個
作用
之前每個節點擁有3個分片,現在每個節點擁有2個分片
每個節點的硬件資源(CPU, RAM, I/O)將被更少的分片所共享,每個分片的性能將會得到提升
現在擁有6個分片(3個主分片和3個副本分片)的索引可以最大擴容6個節點,每個節點上存在一個分片,并且每個分片擁有所在節點的全部資源
繼續擴容
權威指南里指出當需要的節點數量超過了當前的分片數量的時候,該咋辦
這時候可以通過增加分片的數量進而進行水平擴容
增加分片可以選擇主分片和副本分片,但主分片在索引新建的時候已確定了,但副本分片可以進行讀操作和搜索操作可以動態修改
修改副本分片數量為2個
PUT /blogs/_settings
{"number_of_replicas" : 2
}返回

再次查看分片分布情況
node-1

node-3

默認節點

這個時候分片數量擴容到了9個,因此節點數量可以擴容到9個
注意這個時候咱只是新建了3個節點,沒有提高性能,單分片能夠從節點中獲取的資源更少,所以需拿到更好的水平得把節點數量擴容到分片數量保持相同
當然現在在不增加節點的情況下,可以保證部分節點宕機的情況下,數據不會丟失
6,應對故障
現在來測試下宕機的情況下,節點之間的處理邏輯
查看節點情況
這個時候關閉主節點之后,而集群中必定有個主節點,所以會新選舉出來一個新的主節點
同時主分片會丟失,但不會影響es的正常工作
同時這個主分片對應的副本分片會變成主分片
指令
查看節點的id
GET /_cat/nodes?v&h=id,name,ip,node.role,master
返回
id name ip node.role master
O3QH local 127.0.0.1 cdfhilmrstw *
Y-Pa node-2 127.0.0.1 cdfhilmrstw -
qqxZ node-3 127.0.0.1 cdfhilmrstw -
這個時候主節點為local
其它的兩個節點為從節點
原節點主副分片分配情況
index shard prirep state docs store dataset ip node
blogs 0 r STARTED 0 249b 249b 127.0.0.1 node-2
blogs 0 p STARTED 0 249b 249b 127.0.0.1 node-3
blogs 0 r STARTED 0 249b 249b 127.0.0.1 local
blogs 1 r STARTED 0 249b 249b 127.0.0.1 node-2
blogs 1 r STARTED 0 249b 249b 127.0.0.1 node-3
blogs 1 p STARTED 0 249b 249b 127.0.0.1 local
blogs 2 p STARTED 0 249b 249b 127.0.0.1 node-2
blogs 2 r STARTED 0 249b 249b 127.0.0.1 node-3
blogs 2 r STARTED 0 249b 249b 127.0.0.1 local
主節點擁有 1個主節點p1、2個副分片r0和r2
從節點node-2 擁有r0、r1、p2
從節點node-3擁有 p0、r1、r2
刪除主節點
首先看主節點的PID
GET /_nodes/process
返回
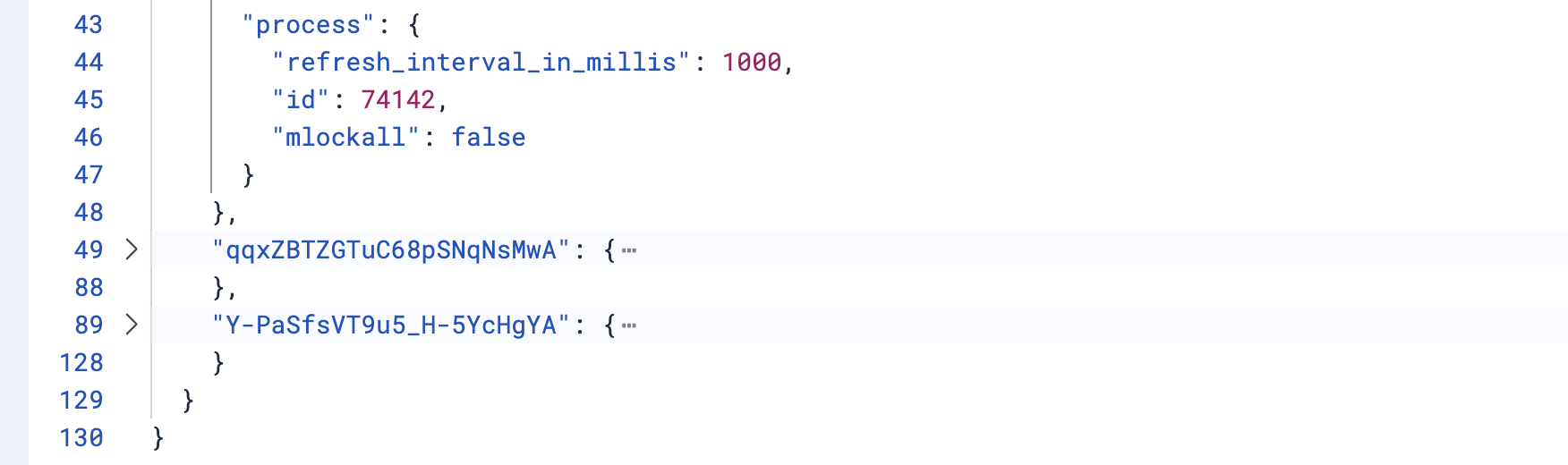
可以看到PID為74142
關閉該節點
kill -9 74142 重新啟動節點1
可以看到主節點變成了節點3
id name ip node.role port master
qqxZ node-3 127.0.0.1 cdfhilmrstw 9302 *
O3QH local 127.0.0.1 cdfhilmrstw 9300 -
Y-Pa node-2 127.0.0.1 cdfhilmrstw 9301 -
再次關閉節點3

可以看到節點2被選舉成為了主節點
當主節點關閉,其余的從節點會選舉成為新的主節點
新分片分布情況
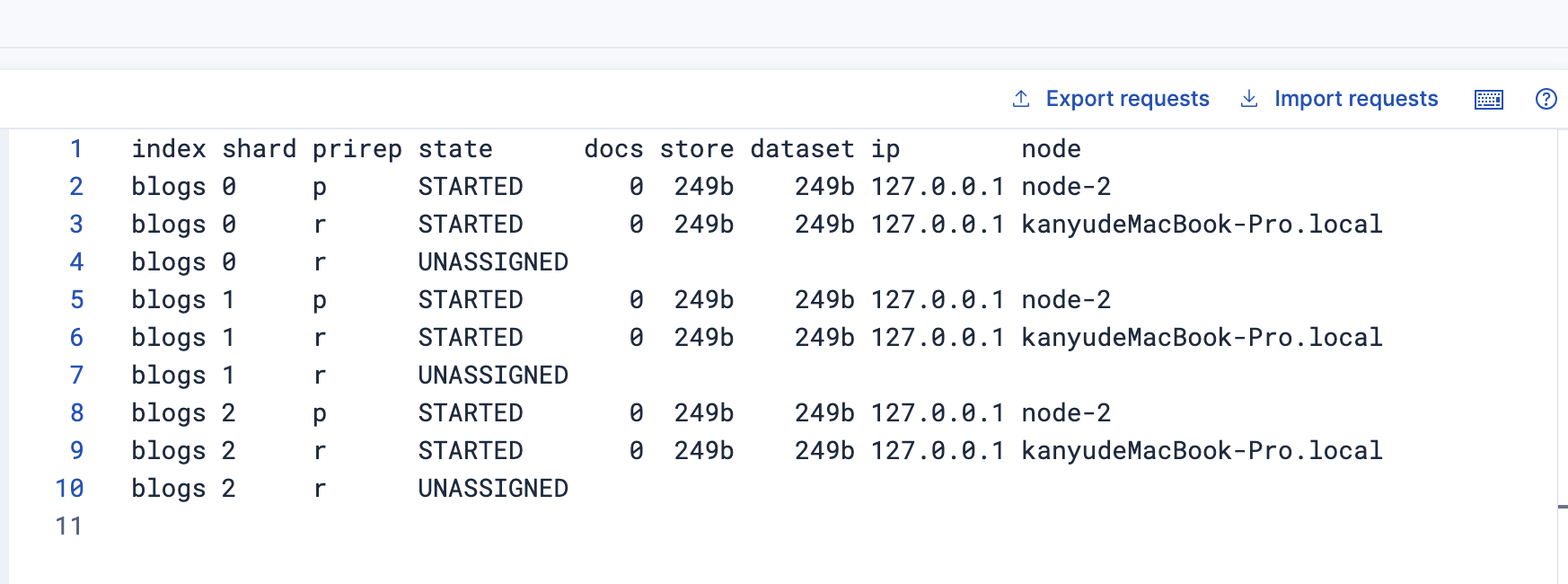
node-2分片:p0、p1、p2
節點1:r0、r1、r2
這個時候查看集群健康狀態
GET /_cluster/health
返回
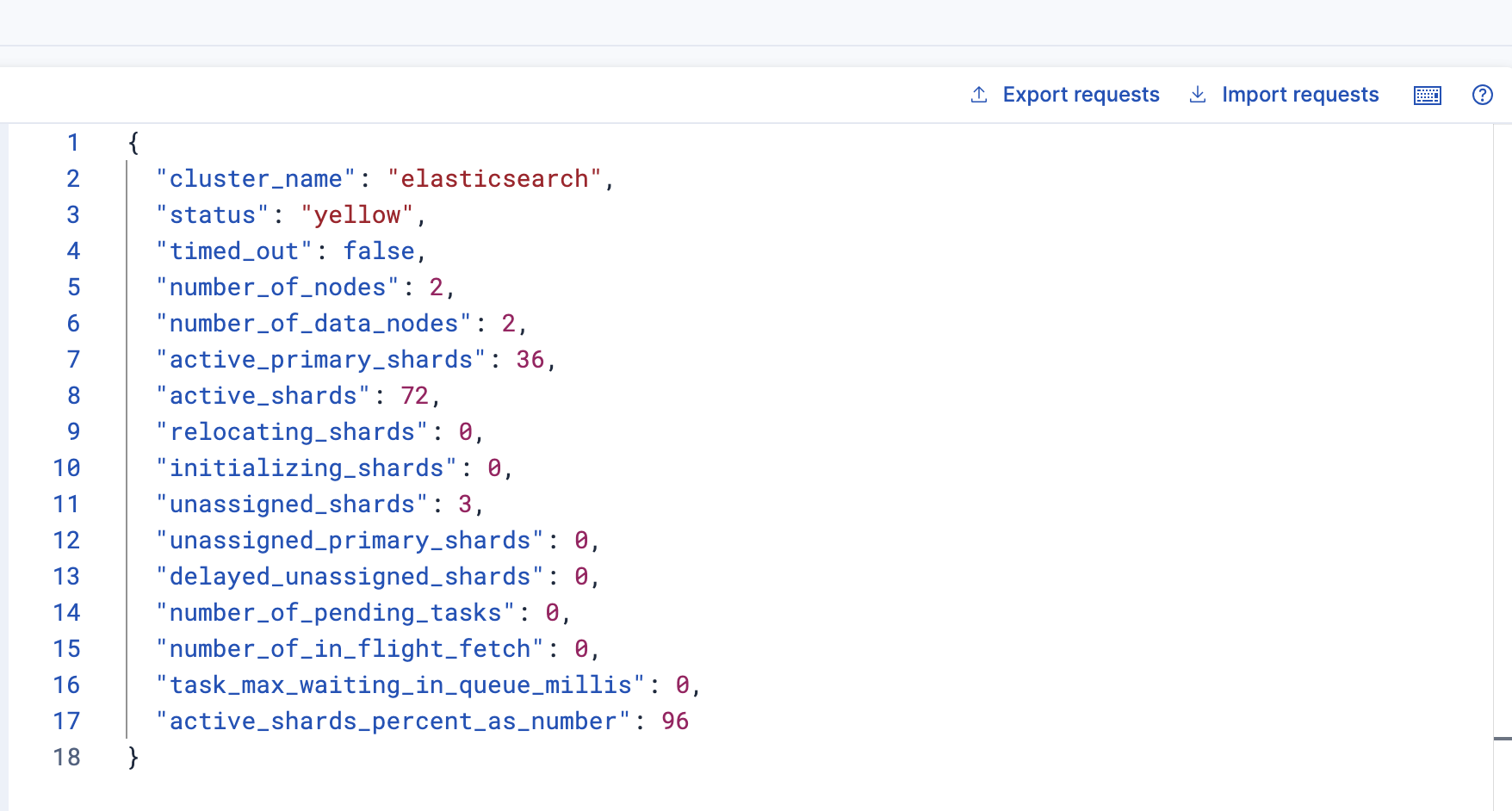
可以看到狀態status=yellow
由于這個時候關閉了節點3,有3個副本分片沒有被分配,但集群仍然會正常運行,由于節點1存儲這個所有主分片的副本分片
重新啟動節點3
看分片情況
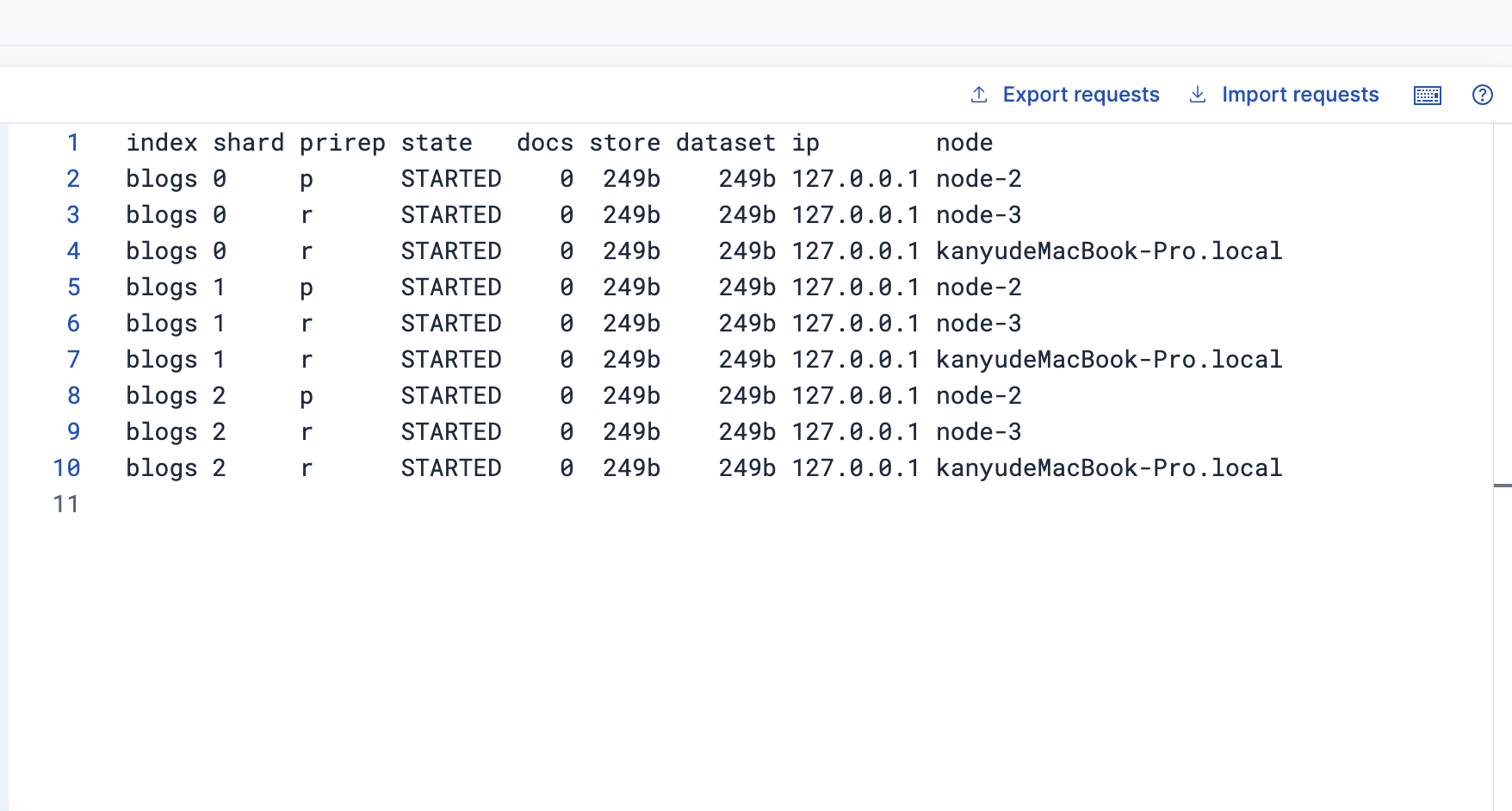
節點1:r0、r1、r2
節點2:p0、p1、p2
節點3:r0、r1、r2
這個時候未分配的副本分片重新分配給了節點3
![LG P9844 [ICPC 2021 Nanjing R] Paimon Segment Tree Solution](http://pic.xiahunao.cn/LG P9844 [ICPC 2021 Nanjing R] Paimon Segment Tree Solution)










)




)


