1. 引言
博主之前做過一個高并發內存池的項目實踐,在實踐中對于內存分配器的內存分配過程理解更加深刻了。在此期間,翻查了不少資料以及博客,發現源碼分享的博客不多,能生動完整的講述ptmalloc2、tcmalloc、jemalloc它們的結構設計以及內存分配過程的博客更是少之又少。那么在這篇文章中博主將總結分享內存分配器ptmalloc2、tcmalloc、jemalloc,歡迎大家留言討論!
2. 現狀
目前大部分服務端程序使用glibc提供的 malloc/free 系列函數,而glibc使用的 ptmalloc2 在性能上遠遠弱后于google的 tcmalloc 和facebook的 jemalloc。 而且后兩者只需要使用LD_PRELOAD環境變量啟動程序即可,甚至并不需要重新編譯。
3. 業務場景
分配內存時進行系統調用的接口,對 heap 的操作, 操作系統提供了 brk() 系統調用,設置了Heap的上邊界; 對 mmap 映射區域的操作,操作系統供了 mmap() 和 munmap() 函數。
因為系統調用的代價很高,不可能每次申請內存都從內核分配空間,尤其是對于小內存分配。 而且因為 mmap 的區域容易被 munmap 釋放,所以一般大內存采用 mmap(),小內存使用 brk()。
4. glibc ptmalloc2
最新版本:作為Glibc的默認內存分配器,ptmalloc2的更新與Glibc(目前更新到2.35+)版本綁定。截至當前,其核心設計仍基于最初的ptmalloc2架構,?glibc 2.26(2017年)開始引入了線程本地緩存(tcache,Thread Local Caching)。
4.1 內存管理結構
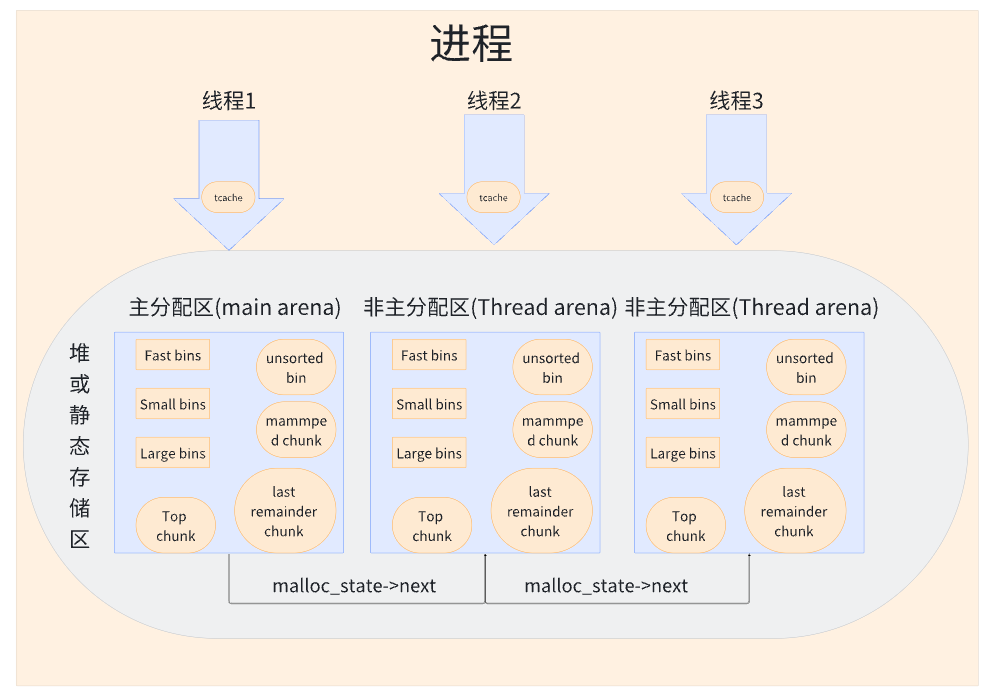
線程本地緩存(tcache)
作用:無鎖快速分配小內存(每個線程獨立)。
管理范圍:默認 ≤ 1032 字節(64 位系統)。
數據結構:
64 個?
tcache_bin(單鏈表,LIFO),每個 bin 對應一種固定大小(8B~1032B)。每個 bin 最多緩存 7 個 chunk(可通過?
GLIBC_TUNABLES?調整)。優化點:
優先從?
tcache?分配/釋放,完全無鎖。若?
tcache?為空,則從?fastbins/smallbins?批量預加載(加鎖)。
Fast Bins(快速通道)
作用:緩存最近釋放的小內存(仍保留 chunk 未合并,加速復用)。
管理范圍:≤ 160 字節(64 位系統)。
數據結構:7 個單鏈表(LIFO),每個鏈表存儲相同大小的 chunk。
與 tcache 的關系:
tcache?不足時從?fastbins?補充。
free()?時,小 chunk 可能先進入?tcache,若?tcache?滿則進入?fastbins。
Small Bins(小內存通道)
作用:管理中等大小的內存(固定大小,合并友好)。
管理范圍:≤ 1008 字節(64 位系統)。
數據結構:62 個雙向鏈表(FIFO),每個 bin 對應一種固定大小(如 16B, 24B, ..., 1008B)。
與 tcache 的關系:
tcache?不足時從?smallbins?分配。
free()?時,若 chunk 大小匹配且?tcache?滿,則進入?smallbins。
Large Bins(大內存通道)
作用:管理大內存塊(范圍區間,按大小排序)。
管理范圍:> 1008 字節。
數據結構:63 個雙向鏈表,每個 bin 管理一個大小范圍(如 1024B~1088B, 1089B~1152B...)。
分配策略:
查找最小滿足大小的 chunk(可能分割)。
若找不到,則進入?
unsorted bin?或?top chunk。
Unsorted Bin(臨時緩沖區)
作用:臨時存放釋放的 chunk,等待重新分類。
數據結構:1 個雙向鏈表(FIFO),存放最近釋放的 chunk(不分大小)。
分配流程:
分配時優先檢查遍歷?
unsorted bin,若找到合適 chunk 直接返回,否則將其轉移到?small/large bins。
Top Chunk(堆頂塊)
作用:當前堆的頂部未分配內存,用于動態擴展。
分配邏輯:
當所有 bins 無法滿足請求時,從 Top Chunk 切割所需內存。
若 Top Chunk 不足,通過?
sbrk(主分配區)或?mmap(非主分配區)擴展堆空間。
mmap 通道(超大內存)
管理大小:默認 ≥ 128KB(可通過?
M_MMAP_THRESHOLD?調整)。特點:
直接通過?
mmap?分配獨立內存段,繞過堆管理。釋放時通過?
munmap?立即歸還系統,避免碎片。
last remainder chunk(最后剩余塊)
優化連續內存分配:當用戶請求的內存略小于某個空閑塊時,分割后剩余的碎片會被標記為?
last remainder,優先用于后續的連續分配請求。減少外部碎片,提升內存利用率。
4.2 內存分配流程
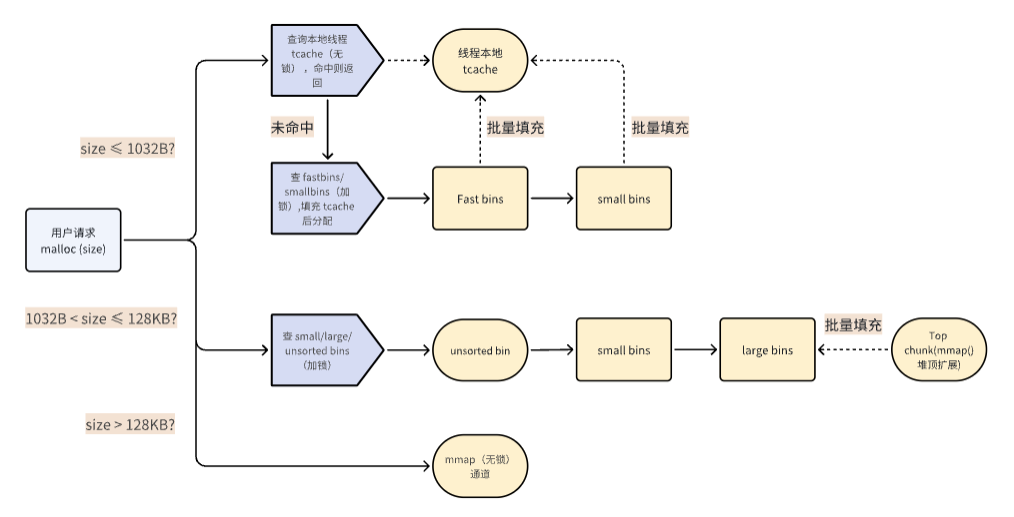
4.3 多線程支持
-
主分配區(Main Arena):主線程默認使用,通過?
brk?擴展堆。 -
非主分配區(Thread Arena):其他線程按需創建(數量受?
MALLOC_ARENA_MAX?限制)。 -
鎖優化:
-
每個分配區有獨立的鎖,線程優先訪問綁定的分配區。
-
若所有分配區被占用,線程會競爭主分配區。
-
4.4 缺點
- 內存碎片:外部和內部碎片問題突出,尤其長期運行后。
- 鎖競爭:盡管有 tcache 和分配區,高并發下仍可能成為瓶頸。
- 釋放延遲:fastbins 延遲合并,
brk?堆收縮不積極。 - 場景局限:不適合高頻小對象分配或實時系統。
5. tcmalloc
最新版本:截至2025年,tcmalloc已迭代至支持per-CPU模式的優化版本(如v2.10+),進一步提升多核性能。場景適用于多核服務器(如 Web 服務、數據庫),高頻小對象分配(如微秒級響應的 RPC 框架)。
5.1 內存管理結構
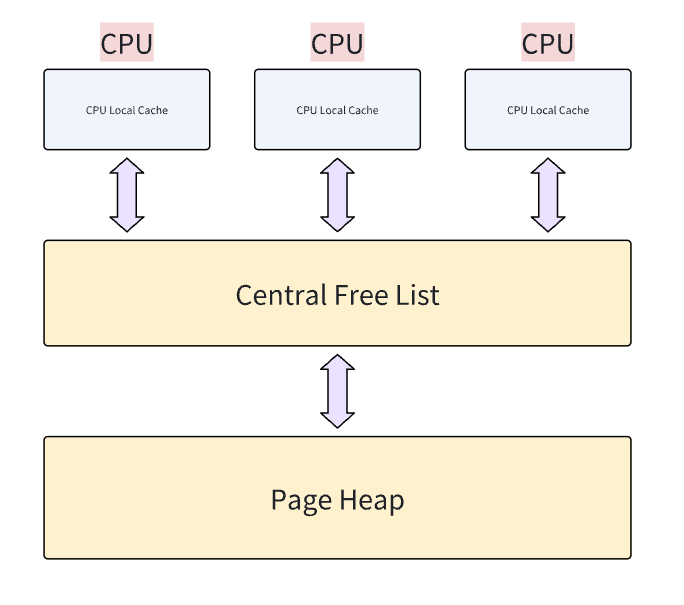
CPU Local Cache(CPU 本地緩存)
申請對象為小內存(通常 ≤256KB)。
使用Size Class 哈希桶,每個 CPU 核心維護一組自由鏈表(FreeList),按大小分類(如 8B、16B、...、256KB)。
動態批量填充,當本地緩存不足時,從下層批量獲取對象(類似慢啟動算法)。
這里無鎖
Central Free List(中心空閑列表)
這一層全局共享,作為 CPU 本地緩存的后備倉庫。
結構為哈希桶Span 鏈表:按大小分類管理內存塊(Span),每個 Span 被切分為多個小對象。
輕量級鎖:僅當 CPU 緩存需要補充時加鎖(鎖粒度細化到 Size Class)。
申請內存,當CPU 緩存耗盡時,從 Central Free List 批量拉取對象(如一次獲取 32 個 16B 的塊)。Central Free List 自身從 PageHeap 申請新的 Span。
PageHeap(頁堆)
以頁(通常 8KB)為粒度的大內存。
合并相鄰空閑頁,減少外碎片。
- 基數樹(Radix Tree)算法,快速映射內存頁到 Span,支持 O(1) 查找。
超過 256KB 的請求直接由 PageHeap 處理(通過?
mmap?或?VirtualAlloc)。
5.2 內存分配流程(Per-CPU 模式)
- 小內存分配(≤256KB)時,線程先獲取當前 CPU 的本地緩存(
GetThisCPUCache()),根據請求大小找到對應的 Size Class 自由鏈表。若鏈表非空,直接彈出對象返回(無鎖),若鏈表為空,從 Central Free List 批量獲取對象(加鎖,但頻率低)。 -
小內存釋放時,將對象放回當前 CPU 的本地緩存自由鏈表(無鎖)。若本地緩存超過閾值(如 1024 個對象),觸發批量歸還到 Central Free List。
- 大內存分配(>256KB)時,直接由 PageHeap 分配,通過?
mmap?或?VirtualAlloc?申請大塊內存。 -
大內存釋放時,通過 PageHeap 的基數樹找到對應 Span,標記為空閑。嘗試合并相鄰空閑 Span,形成更大的連續內存。
5.4 局限性
它是零鎖競爭的,Per-CPU 緩存完全無鎖,適合超高并發場景。本地化操作減少 CPU 緩存行失效(Cache Line Ping-Pong),所以它延遲低。支持彈性擴展,CPU 數量增加時,性能線性提升(無全局瓶頸)。
Per-CPU 緩存可能暫存未使用的對象(可通過調優閾值緩解),造成內存浪費。它對CPU比較依賴,若線程頻繁遷移 CPU,性能會下降(需綁定線程到核心)。
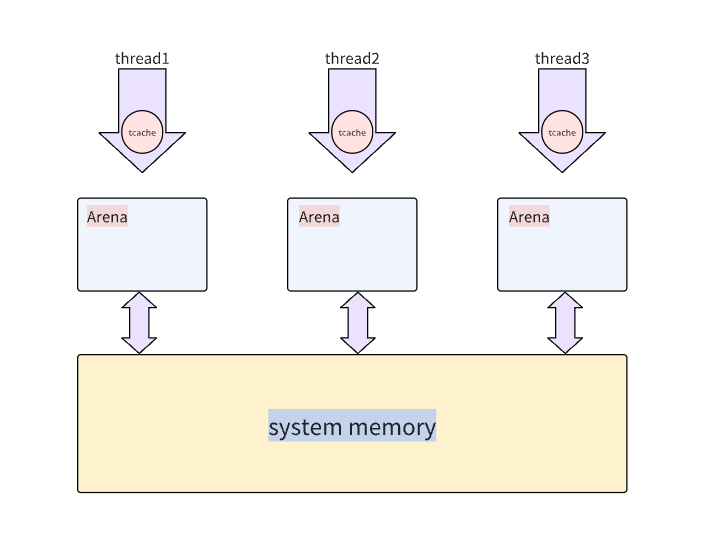
6. jemalloc
最新版本:jemalloc 5.3.0(發布于2025年5月1日),進一步優化內存碎片管理和多線程擴展性。
6.1 內存管理結構
之前的版本
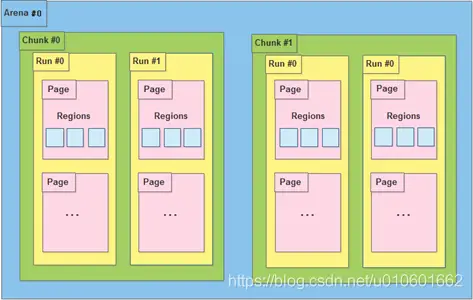
在之前的版本中內存被劃分成若干個arena;每個arena被劃分成若干個chunk(每個默認為4M);每個chunk被劃分成若干個run;每個run由若干個page組成(每個page默認為4K),同一個run中的page又被細分成若干個大小相同的region;
為了減少內存碎片及快速定位到合適大小的內存,jemalloc將run按以下class_size分成44類(同一個run下的region大小相同):
-
small(<4K): [8], [16, 32, 48, …, 128], [192, 256, 320, …, 512], [768, 1024, 1280, …, 3840]
-
large(4K-4M): [4K, 8K, 12K, …, 4072K]
-
huge(>4M): [4M, 8M, 12M, …]
-
對于小于4K內存的申請,jemalloc直接向上取整到最小的class_size,例如申請1-7字節,都會分配一個8字節內存。
新版本
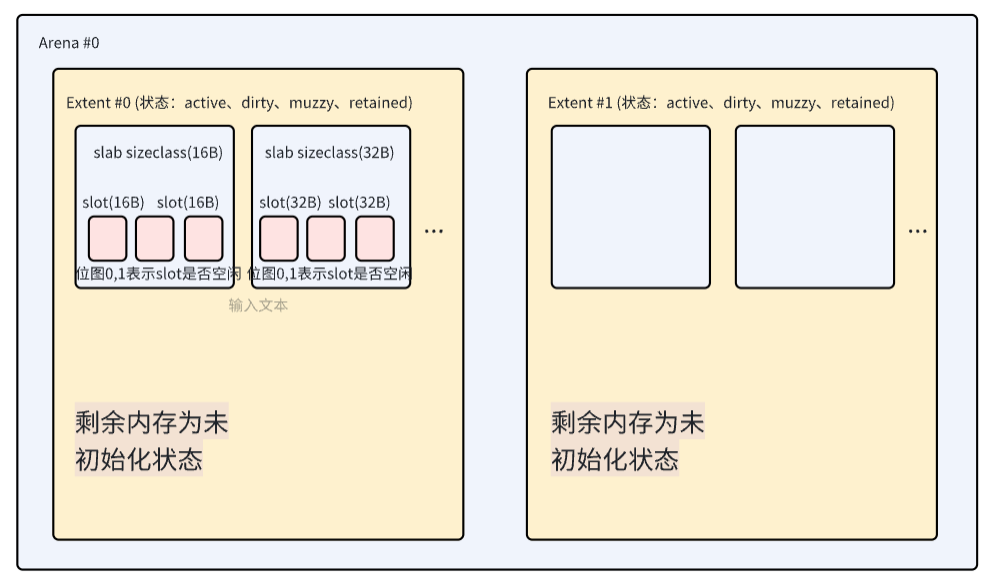
在?jemalloc 5.3.0?中,舊版的?chunk、run?等概念被?Extent?統一取代,其核心設計如下:
1. Extent(擴展塊)
-
表示連續的虛擬內存區域(大小靈活,通常為 2MB 或 4MB,可動態調整)。替代舊版的?
chunk,支持更細粒度的拆分與合并。 -
狀態分級:分為?
Active(在用)、Dirty(已釋放但未擦除)、Muzzy(部分擦除)、Retained(完全擦除保留)。 -
動態管理:支持按需分割為?
Slab?或直接分配。
2. Slab(內存板)
-
將?
Extent?劃分為固定大小的槽位(如 32B、64B),通過位圖管理分配狀態。替代舊版?run?的功能,但更輕量化。 -
按需分配:僅在使用時初始化?
Slab,減少內存占用。 -
延遲釋放:空閑?
Slab?不會立即合并,保留在?Dirty/Muzzy?狀態供快速復用。
3. Page(頁)
-
保留它的意義,仍作為操作系統內存管理的最小單位(如 4KB),但 jemalloc 內部通過?
Extent?聚合多頁。 -
用戶無需關注頁級操作,所有分配均通過?
Extent?和?Slab?抽象。
4. Region(區域)
-
舊版中模糊的?
region?概念被?Extent?和?Slab?明確取代,不再存在于官方文檔。
6.2 內存分配流程
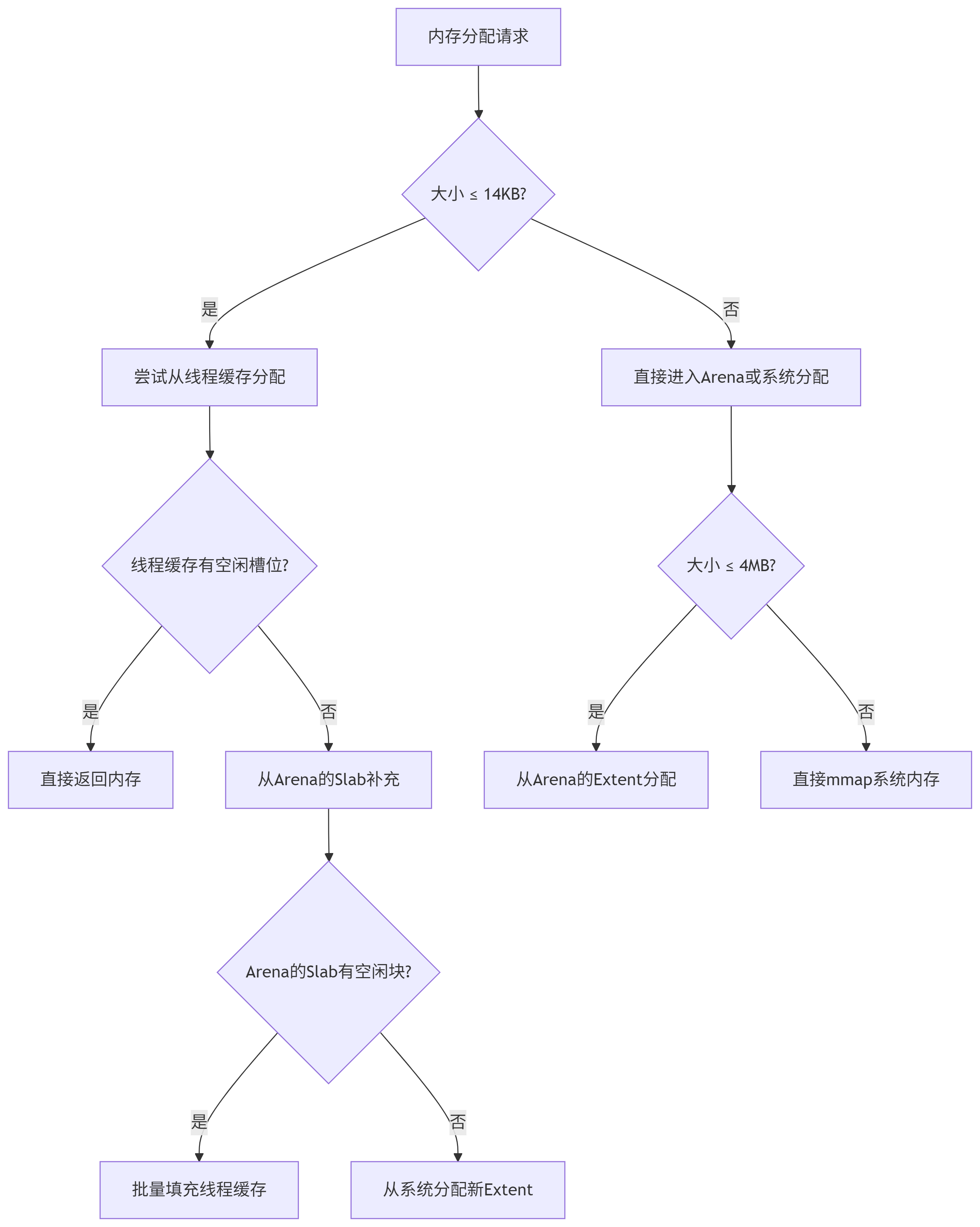
1. 從線程緩存(Thread Cache)分配
-
當請求的內存大小?≤ 14KB(小對象)。線程本地緩存(TLS)中對應的?Size Class 有空閑槽位。根據請求大小匹配對應的?Size Class(如 32B、64B),從線程本地的?Slab 空閑鏈表?中彈出第一個空閑槽位,直接返回槽位內存地址(無鎖操作)。
-
這個過程是零鎖競爭,速度極快(納秒級)。適合高頻小對象分配(如短生命周期對象)。
2. 從 Arena 分配
-
當線程緩存為空,且請求大小?≤ 4MB(中等對象)。或請求大小?>14KB 但 ≤4MB(跳過線程緩存)。
-
線程綁定到特定 Arena(默認輪詢或哈希分配)。若當前 Arena 鎖競爭激烈,可能創建新 Arena。從 Arena 的 Extent/Slab 分配,如果是中等對象(14KB < size ≤4MB),直接分配整個?Extent?或從空閑 Extent 鏈表分割。如果是小對象(≤14KB):從 Arena 的?Slab?中批量獲取多個槽位,填充線程緩存后返回一個。
-
鎖機制:Arena 內部使用細粒度鎖(如每個 Extent 獨立鎖),減少競爭。
3. 從系統內存(mmap/brk)分配
-
當我們請求大小?>4MB(大對象)或 Arena 的 Extent 不足(需擴展堆空間)時。直接調用 mmap,記錄元信息到全局基數樹(Radix Tree)。通過?
mmap?申請獨立內存段(默認 ≥4MB)。這時是大對象,不進入線程緩存或 Arena,直接由全局結構跟蹤。釋放時調用?munmap?立即歸還系統,避免碎片。 -
可以避免污染線程緩存和 Arena。減少大內存的合并開銷。
6.3 內存回收機制
1. 線程本地緩存(Thread Cache)的回收
-
用戶釋放的小對象(≤4KB)首先存入線程本地緩存(Thread Cache)的對應?
size class?槽位。 -
批量回收每個?
size class?的 Thread Cache 槽位有最大保留數量(如默認 200 個)。當超出閾值時,jemalloc 將多余的槽位批量歸還到全局的?Arena。
2. 全局分配區(Arena)的回收
-
每個 Arena 維護一組?
extent(如 4MB 的大塊內存),按?size class?分類。Extent 分割為?slab?后,jemalloc 跟蹤每個 slab 中已分配和空閑的槽位(Slot)。 -
Slab 完全空閑時,即當某個 slab 的所有槽位均被釋放時,其所屬的 Extent 可能被標記為空閑。jemalloc 定期內存壓力檢測或根據系統內存壓力,合并空閑 Extent 并歸還操作系統。
3. Extent 的合并與歸還
-
惰性合并(Lazy Coalescing):jemalloc 不會立即合并相鄰的空閑 Extent,而是保留它們以便快速響應未來可能的相同大小請求。當連續的空閑 Extent 達到一定數量或系統內存不足時,主動合并以減少外部碎片。
-
操作系統歸還:完全空閑的 Extent 可能通過?
munmap?歸還操作系統。jemalloc 默認保留部分空閑 Extent(通過?retain:true?配置),避免頻繁的?mmap/munmap?系統調用開銷。
6.4 局限性
- 內存碎片積累(尤其多 Arena 場景)。
- 線程本地緩存囤積?導致內存利用率下降。
- 超大對象管理開銷?和?配置復雜度高。
- 平臺兼容性差異?和?調試困難。
參考資料:
內存優化總結:ptmalloc、tcmalloc和jemalloc_ptmalloc jemalloc tcmalloc-CSDN博客
ptmalloc VS tcmalloc VS jemalloc 原理及對比測試
ptmalloc代碼淺析2(small bin/large bin結構圖)_largebin-CSDN博客
本篇文章對內存分配器ptmalloc2、tcmalloc、jemalloc,結構設計、內存分配過程做了詳解!歡迎留言討論!






)












