解密企業級大模型智能體Agentic AI 關鍵技術:MCP、A2A、Reasoning LLMs-強化學習算法
現在我們的核心問題是有一些同學會知道要才能強化學習。為什么才能強化學習?是實現AGI。例如從這個其實你從第一階段開始以后,就是chatbot,這個階段開始以后,后續的這每個階段的核心都是強化學習。為什么是這樣?
好,先讓大家看一個視頻。我們我們來播放一個視頻。IT seems to be happening that h IT is uh running a social process in the space, the exchange, trying to the which presses the work Better up with and in the process of creating program, the all is that to know. And so I think in fact one is is Jimmy breath through interest and easy adapt to novelty

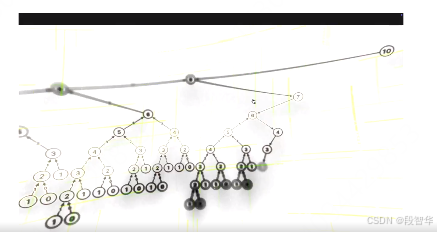
這里面有很重要的,我不知道大家有沒有特別注意到。例如說這個地方有可視化的一個部分,就是他自己在執行或者生成的整個trajectory,或者是這個token sequence的過程中,他會有考慮不同的情況。當然這個情況我們后面再講強化學習的的時候,都會跟大家透徹的去講。例如說你可能采用傳統的蒙特卡羅搜索的方式等等之類。然后你有這些不同的情況,你顯然也會評價他的哪個更好,哪個不是太好。這就會涉及到test time compute。這里面所有的東西其實都是強化學習的內容。
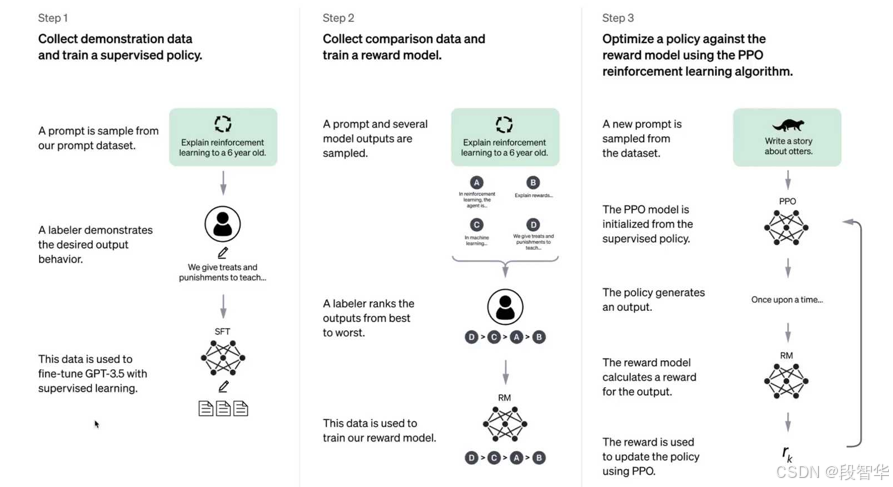
而我們如果要說這個強化學習的內容,我讓大家看這個圖。如果大家關注ChatGPT的話,就是chat ChatGPT發布的時候就給了這樣一幅圖,這幅圖后面的部分主要就是強化學習本身的算法,以PPO為核心的強化學習這個算法。但我們現在知道無論說是OpenAI還是說google還是說llama還是說DeepSeek等等,大家都十分看重強化學習,尤其在我們現在說的這個test time的階段。那為什么強化學習可以做的更好,什么做的更好?就是回到我們前面的問題,做這個AGI的五大階段,為什么?首先這個問題肯定是一個非常關鍵的一個問題。
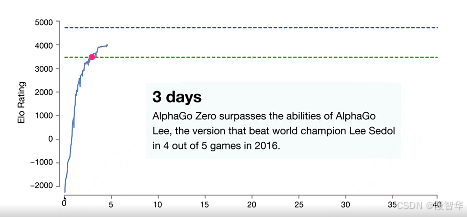
大家看這邊是alphago zero的訓練過程。





)













如何刪除數據庫和表?)

