test?pipeline管道
知識回顧:
1.? 轉化器和估計器的概念
2.? 管道工程
3.? ColumnTransformer和Pipeline類
作業:
整理下全部邏輯的先后順序,看看能不能制作出適合所有機器學習的通用pipeline
偽代碼
# 適合所有機器學習的通用pipeline?#偽代碼
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import time # 導入 time 庫
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False # 防止負號顯示問題# 導入 Pipeline 和相關預處理工具
from sklearn.pipeline import Pipeline # ?用于創建機器學習工作流
from sklearn.compose import ColumnTransformer # 用于將不同的預處理應用于不同的列,之前是對datafame的某一列手動處理,如果在pipeline中直接用standardScaler等函數就會對所有列處理,所以要用到這個工具
from sklearn.preprocessing import OrdinalEncoder, OneHotEncoder, StandardScaler # 用于數據預處理
from sklearn.impute import SimpleImputer # 用于處理缺失值# 機器學習相關庫
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score, precision_score, recall_score, f1_score
from sklearn.model_selection import train_test_split # 只導入 train_test_split
# --- 加載原始數據 ---
data = pd.read_csv('My_data.csv')# --- 分離特征和標簽 (使用原始數據) ---
y = data['My_target']
X = data.drop(['My_target'], axis=1)# --- 劃分訓練集和測試集 (在任何預處理之前劃分) ---
# X_train 和 X_test 現在是原始數據中劃分出來的部分,不包含你之前的任何手動預處理結果
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# --- 定義不同列的類型和它們對應的預處理步驟 (這些將被放入 Pipeline 的 ColumnTransformer 中) ---
# 這些定義是基于原始數據 X 的列類型來確定的# 識別原始的 object 列 (對應你原代碼中的 discrete_features 在預處理前)
object_cols = X.select_dtypes(include=['object']).columns.tolist()# 有序分類特征 (對應你之前的標簽編碼)
# 注意:OrdinalEncoder默認編碼為0, 1, 2... 對應你之前的1, 2, 3...需要在模型解釋時注意
# 這里的類別順序需要和你之前映射的順序一致
ordinal_features = ['xxx', 'xxx', 'xxx']
# 定義每個有序特征的類別順序,這個順序決定了編碼后的數值大小
ordinal_categories = [
? ? ['xxx', 'xxx', 'xxx'],?
? ? ['xxx', 'xxx', 'xxx'],?
? ? [''xxx', 'xxx', 'xxx']?
]
# 先用眾數填充分類特征的缺失值,然后進行有序編碼
ordinal_transformer = Pipeline(steps=[
? ? ('imputer', SimpleImputer(strategy='most_frequent')), # 用眾數填充分類特征的缺失值
? ? ('encoder', OrdinalEncoder(categories=ordinal_categories, handle_unknown='use_encoded_value', unknown_value=-1))
])
# 分類特征?
nominal_features = ['xxx'] # 使用原始列名
# 先用眾數填充分類特征的缺失值,然后進行獨熱編碼
nominal_transformer = Pipeline(steps=[
? ? ('imputer', SimpleImputer(strategy='most_frequent')), # 用眾數填充分類特征的缺失值
? ? ('onehot', OneHotEncoder(handle_unknown='ignore', sparse_output=False)) # sparse_output=False 使輸出為密集數組
])
# 連續特征
# 從X的列中排除掉分類特征,得到連續特征列表
continuous_features = X.columns.difference(object_cols).tolist() # 原始X中非object類型的列# 先用眾數填充缺失值,然后進行標準化
continuous_transformer = Pipeline(steps=[
? ? ('imputer', SimpleImputer(strategy='most_frequent')), # 用眾數填充缺失值 (復現你的原始邏輯)
? ? ('scaler', StandardScaler()) # 標準化,一個好的實踐
])# --- 構建 ColumnTransformer ---
# 將不同的預處理應用于不同的列子集,構造一個完備的轉化器
preprocessor = ColumnTransformer(
? ? transformers=[
? ? ? ? ('ordinal', ordinal_transformer, ordinal_features),
? ? ? ? ('nominal', nominal_transformer, nominal_features),
? ? ? ? ('continuous', continuous_transformer, continuous_features)
? ? ],
? ? remainder='passthrough' # 保留沒有在transformers中指定的列(如果存在的話),或者 'drop' 丟棄
)# --- 構建完整的 Pipeline ---
# 將預處理器和模型串聯起來
# 使用你原代碼中 RandomForestClassifier 的默認參數和 random_state,這里的參數用到了元組這個數據結構
pipeline = Pipeline(steps=[
? ? ('preprocessor', preprocessor), # 第一步:應用所有的預處理 (ColumnTransformer)
? ? ('classifier', RandomForestClassifier(random_state=42)) # 第二步:隨機森林分類器
])# --- 1. 使用 Pipeline 在劃分好的訓練集和測試集上評估 ---
print("--- 1. 默認參數隨機森林 (訓練集 -> 測試集) ---")?
start_time = time.time() # 記錄開始時間# 在原始的 X_train 上擬合整個Pipeline
# Pipeline會自動按順序執行preprocessor的fit_transform(X_train),然后用處理后的數據擬合classifier
pipeline.fit(X_train, y_train)# 在原始的 X_test 上進行預測
# Pipeline會自動按順序執行preprocessor的transform(X_test),然后用處理后的數據進行預測
pipeline_pred = pipeline.predict(X_test)end_time = time.time() # 記錄結束時間
print(f"訓練與預測耗時: {end_time - start_time:.4f} 秒") # 使用你原代碼的輸出格式
print("\n默認隨機森林 在測試集上的分類報告:") # 使用你原代碼的輸出文本
print(classification_report(y_test, pipeline_pred))
print("默認隨機森林 在測試集上的混淆矩陣:") # 使用你原代碼的輸出文本
print(confusion_matrix(y_test, pipeline_pred))
運用heart.csv文件進行一次實戰:
導入庫和數據加載
# 導入基礎庫
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import time # 導入 time 庫
import warnings# 忽略警告
warnings.filterwarnings("ignore")# 設置中文字體和負號正常顯示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 導入 Pipeline 和相關預處理工具
from sklearn.pipeline import Pipeline # 用于創建機器學習工作流
from sklearn.compose import ColumnTransformer # 用于將不同的預處理應用于不同的列
from sklearn.preprocessing import OrdinalEncoder, OneHotEncoder, StandardScaler # 用于數據預處理(有序編碼、獨熱編碼、標準化)
from sklearn.impute import SimpleImputer # 用于處理缺失值# 導入機器學習模型和評估工具
from sklearn.ensemble import RandomForestClassifier # 隨機森林分類器
from sklearn.metrics import classification_report, confusion_matrix # 用于評估分類器性能
from sklearn.model_selection import train_test_split # 用于劃分訓練集和測試集# --- 加載原始數據 ---
# 我們加載原始數據,不對其進行任何手動預處理
data = pd.read_csv('heart.csv')print("原始數據加載完成,形狀為:", data.shape)
# print(data.head()) # 可以打印前幾行看看原始數據
?分離特征和標簽,劃分數據集
# --- 分離特征和標簽 (使用原始數據) ---
y = data['target'] # 標簽
X = data.drop(['target'], axis=1) # 特征 (axis=1 表示按列刪除)print("\n特征和標簽分離完成。")
print("特征 X 的形狀:", X.shape)
print("標簽 y 的形狀:", y.shape)# --- 劃分訓練集和測試集 (在任何預處理之前劃分) ---
# 按照8:2劃分訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 80%訓練集,20%測試集print("\n數據集劃分完成 (預處理之前)。")
print("X_train 形狀:", X_train.shape)
print("X_test 形狀:", X_test.shape)
print("y_train 形狀:", y_train.shape)
print("y_test 形狀:", y_test.shape)
定義預處理步驟
# --- 定義不同列的類型和它們對應的預處理步驟 ---
# 這些定義是基于原始數據 X 的列類型來確定的# 識別原始的 object 列 (對應你原代碼中的 discrete_features 在預處理前)
object_cols = X.select_dtypes(include=['object']).columns.tolist()
# 識別原始的非 object 列 (通常是數值列)
numeric_cols = X.select_dtypes(exclude=['object']).columns.tolist()# 有序分類特征 (對應你之前的標簽編碼)
# 注意:OrdinalEncoder默認編碼為0, 1, 2... 對應你之前的1, 2, 3...需要在模型解釋時注意
# 這里的類別順序需要和你之前映射的順序一致
ordinal_features = ['cp', 'restecg','thal']
# 定義每個有序特征的類別順序,這個順序決定了編碼后的數值大小
ordinal_categories = [['0', '1', '2', '3'], # 'cp' 特征的類別順序['0', '1', '2'], # 'restecg' 特征的類別順序['0', '1', '2', '3'] # 'thal' 特征的類別順序
]# 構建處理有序特征的 Pipeline: 先填充缺失值,再進行有序編碼
ordinal_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='most_frequent')), # 用眾數填充分類特征的缺失值('encoder', OrdinalEncoder(categories=ordinal_categories, handle_unknown='use_encoded_value', unknown_value=-1)) # 進行有序編碼
])
print("有序特征處理 Pipeline 定義完成。")# 標稱分類特征 (對應你之前的獨熱編碼)
nominal_features = ['thal','fbs','exang','slope'] # 使用原始列名
# 構建處理標稱特征的 Pipeline: 先填充缺失值,再進行獨熱編碼
nominal_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='most_frequent')), # 用眾數填充分類特征的缺失值('onehot', OneHotEncoder(handle_unknown='ignore', sparse_output=False)) # 進行獨熱編碼, sparse_output=False 使輸出為密集數組
])
print("標稱特征處理 Pipeline 定義完成。")# 連續特征 (對應你之前的眾數填充 + 添加標準化)
# 從所有列中排除掉分類特征,得到連續特征列表
# continuous_features = X.columns.difference(object_cols).tolist() # 原始X中非object類型的列
# 也可以直接從所有列中排除已知的有序和標稱特征
continuous_features = [f for f in X.columns if f not in ordinal_features + nominal_features]# 構建處理連續特征的 Pipeline: 先填充缺失值,再進行標準化
continuous_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='most_frequent')), # 用眾數填充缺失值 (復現你的原始邏輯)('scaler', StandardScaler()) # 標準化,一個好的實踐 (如果你嚴格復刻原代碼,可以移除這步)
])
print("連續特征處理 Pipeline 定義完成。")

# --- 構建 ColumnTransformer ---
# 將不同的預處理應用于不同的列子集,構造一個完備的轉化器
# ColumnTransformer 接收一個 transformers 列表,每個元素是 (名稱, 轉換器對象, 列名列表)
preprocessor = ColumnTransformer(transformers=[('ordinal', ordinal_transformer, ordinal_features), # 對 ordinal_features 列應用 ordinal_transformer('nominal', nominal_transformer, nominal_features), # 對 nominal_features 列應用 nominal_transformer('continuous', continuous_transformer, continuous_features) # 對 continuous_features 列應用 continuous_transformer],remainder='passthrough' # 如何處理沒有在上面列表中指定的列。# 'passthrough' 表示保留這些列,不做任何處理。# 'drop' 表示丟棄這些列。
)print("\nColumnTransformer (預處理器) 定義完成。")
# print(preprocessor) # 可以打印 preprocessor 對象看看它的結構

構建完整pipeline
# --- 構建完整的 Pipeline ---
# 將預處理器和模型串聯起來
# 使用你原代碼中 RandomForestClassifier 的默認參數和 random_state
pipeline = Pipeline(steps=[('preprocessor', preprocessor), # 第一步:應用所有的預處理 (我們剛剛定義的 ColumnTransformer 對象)('classifier', RandomForestClassifier(random_state=42)) # 第二步:隨機森林分類器 (使用默認參數和指定的 random_state)
])print("\n完整的 Pipeline 定義完成。")
# print(pipeline) # 可以打印 pipeline 對象看看它的結構
使用pipeline完成訓練和評估
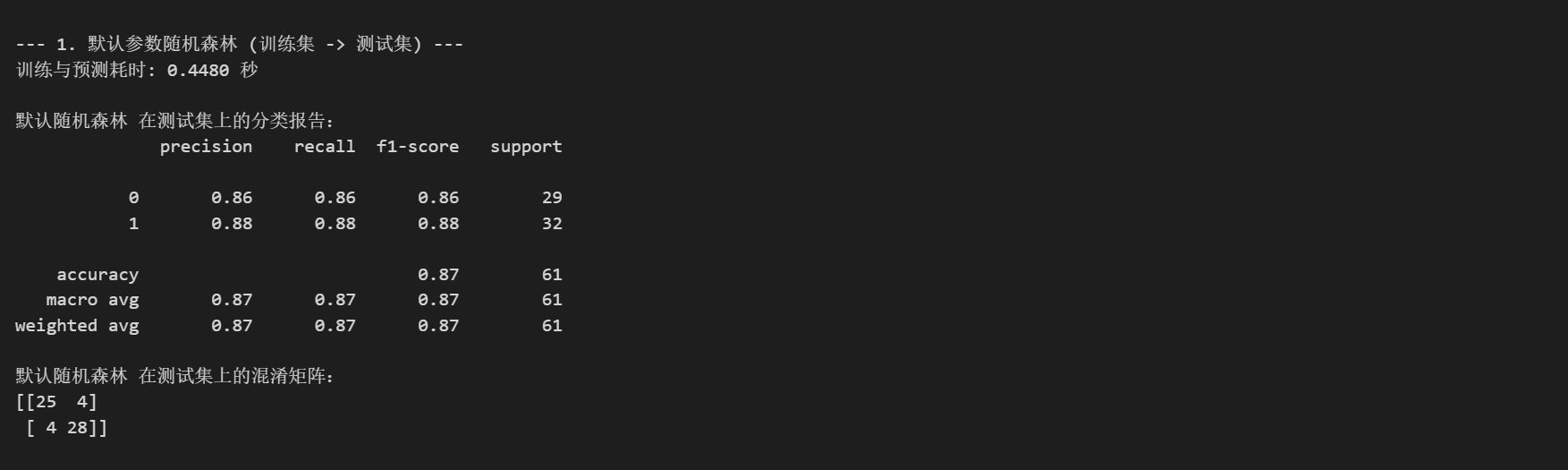
# --- 1. 使用 Pipeline 在劃分好的訓練集和測試集上評估 ---
# 完全模仿你原代碼的第一個評估步驟print("\n--- 1. 默認參數隨機森林 (訓練集 -> 測試集) ---") # 使用你原代碼的輸出文本
# import time # 引入 time 庫 (已在文件頂部引入)start_time = time.time() # 記錄開始時間# 在原始的 X_train, y_train 上擬合整個Pipeline
# Pipeline會自動按順序執行 preprocessor 的 fit_transform(X_train),
# 然后用處理后的數據和 y_train 擬合 classifier
pipeline.fit(X_train, y_train)# 在原始的 X_test 上進行預測
# Pipeline會自動按順序執行 preprocessor 的 transform(X_test),
# 然后用處理后的數據進行 classifier 的 predict
pipeline_pred = pipeline.predict(X_test)end_time = time.time() # 記錄結束時間print(f"訓練與預測耗時: {end_time - start_time:.4f} 秒") # 使用你原代碼的輸出格式print("\n默認隨機森林 在測試集上的分類報告:") # 使用你原代碼的輸出文本
print(classification_report(y_test, pipeline_pred))
print("默認隨機森林 在測試集上的混淆矩陣:") # 使用你原代碼的輸出文本
print(confusion_matrix(y_test, pipeline_pred))
筆記
一、pipeline
????????pipeline在機器學習領域可以翻譯為“管道”,也可以翻譯為“流水線”,是機器學習中一個重要的概念。
????????在機器學習中,通常會按照一定的順序對數據進行預處理、特征提取、模型訓練和模型評估等步驟,以實現機器學習模型的訓練和評估。為了方便管理這些步驟,我們可以使用pipeline來構建一個完整的機器學習流水線。
????????pipeline是一個用于組合多個估計器(estimator)的 estimator,它實現了一個流水線,其中每個估計器都按照一定的順序執行。在pipeline中,每個估計器都實現了fit和transform方法,fit方法用于訓練模型,transform方法用于對數據進行預處理和特征提取。
二、轉換器(transformer)
?????????轉換器(transformer)是一個用于對數據進行預處理和特征提取的 estimator,它實現一個 transform 方法,用于對數據進行預處理和特征提取。轉換器通常用于對數據進行預處理,例如對數據進行歸一化、標準化、缺失值填充等。轉換器也可以用于對數據進行特征提取,例如對數據進行特征選擇、特征組合等。轉換器的特點是無狀態的,即它們不會存儲任何關于數據的狀態信息(指的是不存儲內參)。轉換器僅根據輸入數據學習轉換規則(比如函數規律、外參),并將其應用于新的數據。因此,轉換器可以在訓練集上學習轉換規則,并在訓練集之外的新數據上應用這些規則。
????????常見的轉換器包括數據縮放器(如StandardScaler、MinMaxScaler)、特征選擇器(如SelectKBest、PCA)、特征提取器(如CountVectorizer、TF-IDFVectorizer)等。
之前我們都是說對xxxx類進行實例化,現在可以換一個更加準確的說法,如下:
# 導入StandardScaler轉換器
from sklearn.preprocessing import StandardScaler
# 初始化轉換器
scaler = StandardScaler()
# 1. 學習訓練數據的縮放規則(計算均值和標準差),本身不存儲數據
scaler.fit(X_train)
# 2. 應用規則到訓練數據和測試數據
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 也可以使用fit_transform一步完成
# X_train_scaled = scaler.fit_transform(X_train)
三、估計器(estimator)
????????估計器(Estimator)是實現機器學習算法的對象或類。它用于擬合(fit)數據并進行預測(predict)。估計器是機器學習模型的基本組成部分,用于從數據中學習模式、進行預測和進行模型評估。
????????估計器的主要方法是fit和predict。fit方法用于根據輸入數據學習模型的參數和規律,而predict方法用于對新的未標記樣本進行預測。估計器的特點是有狀態的,即它們在訓練過程中存儲了關于數據的狀態信息,以便在預測階段使用。估計器通過學習訓練數據中的模式和規律來進行預測。因此,估計器需要在訓練集上進行訓練,并使用訓練得到的模型參數對新數據進行預測。
????????常見的估計器包括分類器(classifier)、回歸器(regresser)、聚類器(clusterer)。
from sklearn.linear_model import LinearRegression
# 創建一個回歸器
model = LinearRegression()
# 在訓練集上訓練模型
model.fit(X_train_scaled, y_train)
# 對測試集進行預測
y_pred = model.predict(X_test_scaled)
?四、管道(pipeline)
????????了解了分類器和估計器,所以可以理解為在機器學習是由轉換器(Transformer)和估計器(Estimator)按照一定順序組合在一起的來完成了整個流程。
????????機器學習的管道(Pipeline)機制通過將多個轉換器和估計器按順序連接在一起,可以構建一個完整的數據處理和模型訓練流程。在管道機制中,可以使用Pipeline類來組織和連接不同的轉換器和估計器。Pipeline類提供了一種簡單的方式來定義和管理機器學習任務的流程。
????????管道機制是按照封裝順序依次執行的一種機制,在機器學習算法中得以應用的根源在于,參數集在新數據集(比如測試集)上的重復使用。且代碼看上去更加簡潔明確。這也意味著,很多個不同的數據集,只要處理成管道的輸入形式,后續的代碼就可以復用。(這里為我們未來的python文件拆分做鋪墊),也就是把很多個類和函數操作寫進一個新的pipeline中。
????????這符合編程中的一個非常經典的思想:don't repeat yourself。(dry原則),也叫做封裝思想,我們之前提到過類似的思想的應用: 函數、類,現在我們來說管道。
????????Pipeline最大的價值和核心應用場景之一,就是與交叉驗證和網格搜索等結合使用,來:
????????1. 防止數據泄露: 這是在使用交叉驗證時,Pipeline自動完成預處理并在每個折疊內獨立fit/transform的關鍵優勢。
????????2. 簡化超參數調優: 可以方便地同時調優預處理步驟和模型的參數。
@浙大疏錦行



















