基于LSTM與SHAP可解釋性分析的神經網絡回歸預測模型【MATLAB】
一、引言
在數據驅動的智能時代,時間序列預測已成為許多領域(如金融、氣象、工業監測等)中的關鍵任務。長短期記憶網絡(LSTM)因其在捕捉時間序列長期依賴關系方面的優勢,廣泛應用于復雜時序建模任務中。
與此同時,隨著模型復雜度的提升,其“黑箱”特性也愈發明顯,限制了其在一些對透明性要求較高的場景中的應用。為了解決這一問題,引入**SHAP(SHapley Additive exPlanations)**方法進行可解釋性分析,有助于揭示模型的決策邏輯。
本文將以MATLAB為平臺,圍繞一個基于LSTM與SHAP結合的回歸預測模型,從原理角度出發,介紹其構建思路與解釋方法,避免涉及具體公式與代碼細節。
二、LSTM在回歸預測中的作用
2.1 LSTM的基本結構與思想
LSTM是一種特殊的循環神經網絡(RNN),專門設計用于解決傳統RNN在處理長序列時出現的梯度消失或梯度爆炸問題。它通過引入記憶單元和三個門控機制(輸入門、遺忘門、輸出門),實現了對信息的選擇性保留與更新。
這種結構使得LSTM能夠有效捕捉時間序列中的長期依賴關系,從而更準確地進行趨勢預測。
2.2 LSTM在回歸任務中的角色
在回歸預測任務中,LSTM主要承擔以下功能:
- 自動提取時間序列中的動態模式:無需人工構造滯后特征,模型能自動學習不同時間點之間的依賴關系。
- 處理非線性、非平穩數據:適用于具有復雜波動特性的實際數據,如股價、氣溫變化等。
- 多變量建模能力:支持多維輸入,可以同時考慮多個影響因素(如溫度、濕度、風速等)對目標變量的影響。
因此,LSTM在諸如電力負荷預測、空氣質量預報、設備健康狀態評估等領域表現出色。
三、模型的可解釋性需求與SHAP的作用
盡管LSTM在預測精度上表現優異,但其內部機制較為復雜,導致用戶難以理解其預測依據。這種“黑箱”特性在某些高風險應用場景中會引發信任問題。
3.1 SHAP的核心理念
SHAP是一種基于博弈論的統一解釋框架,其核心思想是:
每個輸入特征對模型輸出的貢獻值等于該特征在所有可能特征組合下的平均邊際貢獻。
SHAP值不僅可以反映各特征的重要性排序,還能指出其對預測結果的具體影響方向(正向或負向),從而提供直觀、一致的解釋。
3.2 SHAP在LSTM模型中的應用
雖然SHAP最初多用于樹模型(如XGBoost、LightGBM),但近年來也被成功應用于神經網絡模型的解釋中。在LSTM模型中使用SHAP,可以實現:
- 對每個時間步的輸入特征進行重要性評分;
- 分析哪些變量在特定時間段內對預測結果影響最大;
- 提供可視化工具幫助用戶理解模型行為,增強模型可信度。
四、LSTM+SHAP聯合建模流程概述
下面是一個典型的基于LSTM與SHAP的回歸預測模型的工作流程:
4.1 數據準備階段
- 收集具有時間依賴性的原始數據(如傳感器采集的時間序列);
- 進行缺失值填充、標準化、歸一化等預處理操作;
- 構造歷史窗口作為輸入樣本,設定目標輸出標簽,劃分訓練集與測試集。
4.2 LSTM建模階段
- 構建包含LSTM層與全連接層的神經網絡結構;
- 使用訓練數據訓練模型,使其學會從歷史序列中提取關鍵信息并輸出預測值;
- 在驗證集上評估模型性能,并根據需要調整網絡結構或訓練參數。
4.3 SHAP解釋階段
- 利用訓練好的LSTM模型生成SHAP值;
- 分析不同時間點、不同輸入變量對預測結果的影響;
- 結合折線圖、熱力圖等形式展示特征重要性及其變化趨勢;
- 根據解釋結果優化模型結構或指導數據采集策略。
五、總結與展望
將LSTM與SHAP相結合,構建具有可解釋性的神經網絡回歸預測模型,是當前人工智能發展的一個重要方向。這種方法既保留了深度學習強大的時序建模能力,又增強了模型的透明度與可信度,有助于推動AI技術在醫療、金融、能源等敏感領域的落地應用。
未來,我們可以進一步探索如何提高SHAP計算效率,或將該框架拓展至其他時序模型(如GRU、Transformer)中,構建更加智能、高效的可解釋系統。
六、部分代碼
%% 清空環境變量
warning off % 關閉報警信息
close all % 關閉開啟的圖窗
clear % 清空變量
clc % 清空命令行
rng('default');
tic
%% 導入數據
res = xlsread('data.xlsx');%% 數據分析
num_size = 0.7; % 訓練集占數據集比例
outdim = 1; % 最后一列為輸出
num_samples = size(res, 1); % 樣本個數
% res = res(randperm(num_samples), :); % 打亂數據集(不希望打亂時,注釋該行)
num_train_s = round(num_size * num_samples); % 訓練集樣本個數
f_ = size(res, 2) - outdim; % 輸入特征維度
lstmnumber = 50;%% 劃分訓練集和測試集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);L = size(P_train, 1);%% 數據歸一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test1 = mapminmax('apply', P_test, ps_input);[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test1 = mapminmax('apply', T_test, ps_output);%% 數據平鋪
% 將數據平鋪成1維數據只是一種處理方式
% 也可以平鋪成2維數據,以及3維數據,需要修改對應模型結構
% 但是應該始終和輸入層數據結構保持一致
p_train = reshape(p_train, L, 1, 1, M);
p_test = reshape(p_test1 , L, 1, 1, N);
t_train = double(t_train)';
t_test = double(t_test1 )';%% 數據格式轉換
for i = 1 : MLp_train{i, 1} = p_train(:, :, 1, i);
end
for i = 1 : NLp_test{i, 1} = p_test( :, :, 1, i);
end
七、運行結果


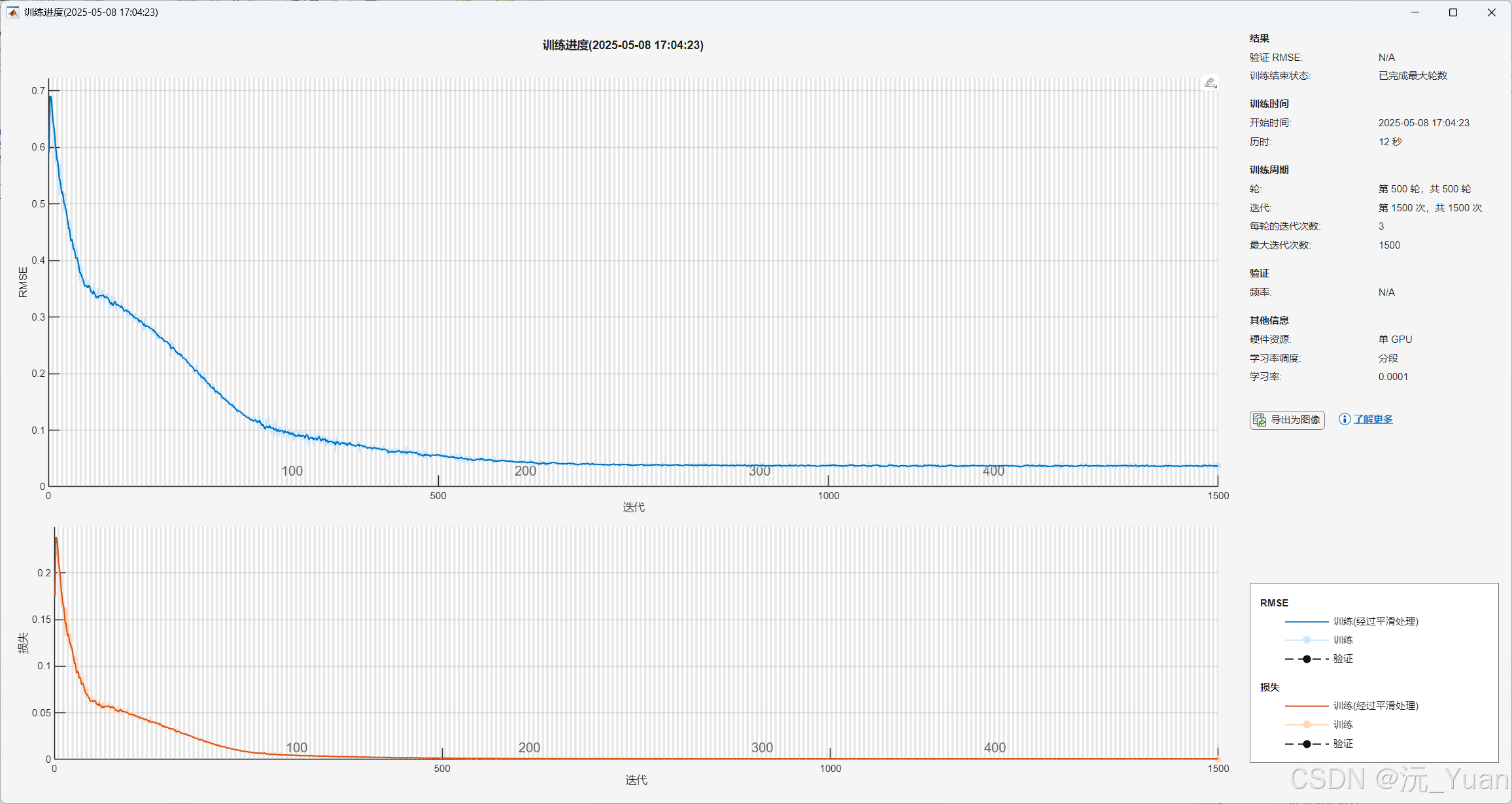
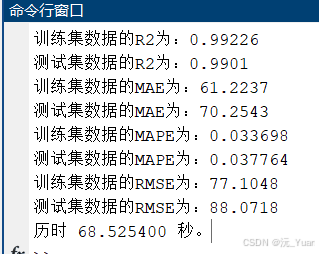
八、代碼下載
完整代碼請私信回復以下關鍵詞:
LSTM-SHAP




之函數)

 使用langchain進行AI開發(2))
)




功能,使用canvas實現功能)



)


