FreeRTOS 有哪 5 種內存管理方式?
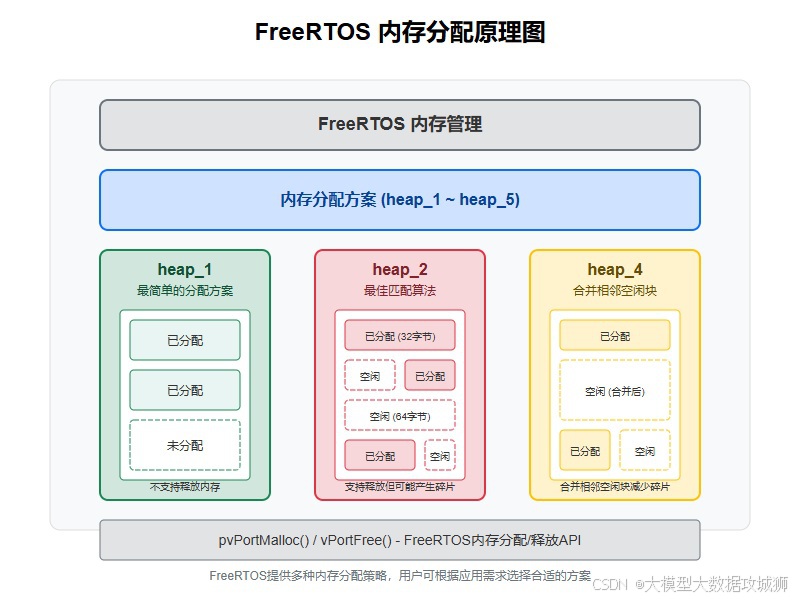
- heap_1.c:這種方式簡單地在編譯時分配一塊固定大小的內存,在整個運行期間不會進行內存的動態分配和釋放。它適用于那些對內存使用需求非常明確且固定,不需要動態分配內存的場景,優點是實現簡單,不會產生內存碎片,但缺乏靈活性,不能滿足運行時動態分配內存的需求。
- heap_2.c:采用首次適配算法來分配內存。當有內存分配請求時,它會從內存塊的起始位置開始查找,找到第一個足夠大的空閑塊來滿足請求。在釋放內存時,不會立即將相鄰的空閑塊合并,可能會導致內存碎片的產生,但相對 heap_1.c 來說,它支持動態內存分配,具有一定的靈活性,適用于那些內存分配和釋放不太頻繁,對內存碎片不太敏感的場景。
- heap_3.c:實際上是對標準 C 庫的內存分配函數 malloc 和 free 的簡單封裝。它借助了標準 C 庫的內存管理機制來實現 FreeRTOS 中的內存管理。這種方式的優點是可以利用標準 C 庫成熟的內存管理算法,具有較好的通用性和兼容性,但可能會帶來較大的內存開銷,并且在一些資源受限的嵌入式系統中可能不太適用,因為標準 C 庫的內存管理函數通常比較復雜,占用較多的代碼空間和運行時資源。
- heap_4.c:使用最佳適配算法來分配內存,它會在所有空閑塊中找到最適合請求大小的空閑塊進行分配,并且在釋放內存時會將相鄰的空閑塊合并,有效地減少了內存碎片的產生。這種方式在動態內存分配的場景下表現較好,能更高效地利用內存空間,但實現相對復雜一些,適用于對內存利用率要求較高,且有頻繁內存分配和釋放操作的應用。
- heap_5.c:允許在多個不連續的內存區域中分配內存。它可以將不同位置、不同大小的內存塊整合起來進行管理,適合于系統中內存分布不連續的情況,例如有多個不同的內存芯片或者內存區域被其他模塊占用一部分的情況。通過合理地配置,它能夠充分利用這些分散的內存資源,但管理起來相對復雜,需要額外的機制來跟蹤和管理這些不連續的內存塊。
FreeRTOS 如何處理中斷?中斷嵌套、中斷搶占和標志位清除的機制是什么?
- 中斷處理流程:當一個中斷發生時,FreeRTOS 首先會保存當前任務的上下文,包括寄存器的值等信息,以便在中斷處理完成后能夠恢復任務的執行。然后,它會根據中斷向量表找到對應的中斷服務函數(ISR)并執行。在 ISR 中,通常會進行一些與中斷相關的操作,如讀取硬件寄存器以獲取中斷原因、處理中斷事件等。
- 中斷嵌套機制:FreeRTOS 支持中斷嵌套,即當一個中斷正在處理時,如果發生了更高優先級的中斷,那么高優先級的中斷可以打斷當前正在處理的中斷,先處理高優先級的中斷。這是通過中斷優先級的設置來實現的,硬件會根據中斷的優先級來決定是否允許嵌套。在 FreeRTOS 中,每個中斷都有一個對應的優先級,數值越低表示優先級越高。當一個中斷進入時,它會檢查當前正在處理的中斷的優先級,如果新的中斷優先級更高,就會暫停當前中斷的處理,保存其上下文,然后去處理更高優先級的中斷。當中斷處理完成后,再按照相反的順序恢復被中斷的中斷的執行。
- 中斷搶占機制:中斷搶占與中斷嵌套類似,但更側重于任務層面。當一個任務正在運行時,如果發生了中斷,且中斷的優先級足夠高,那么中斷會搶占當前任務的執行,保存任務的上下文,然后執行中斷服務函數。在中斷服務函數執行完畢后,根據任務的優先級等情況,決定是恢復被中斷的任務繼續執行,還是切換到其他更高優先級的就緒任務執行。如果在中斷處理過程中,有更高優先級的任務進入了就緒狀態,那么在中斷返回時,FreeRTOS 會進行任務切換,讓更高優先級的任務獲得 CPU 資源。
- 標志位清除機制:在中斷處理中,通常需要清除引發中斷的標志位,以確保中斷不會被重復觸發。這一般是通過向相應的硬件寄存器寫入特定的值來實現的。不同的硬件設備有不同的標志位清除方式,例如,對于一些定時器中斷,可能需要向定時器的控制寄存器寫入特定的命令來清除中斷標志;對于外部中斷,可能需要通過讀取或寫入外部中斷控制器的寄存器來清除標志位。在 FreeRTOS 的中斷服務函數中,會在適當的時候調用與硬件相關的函數來完成標志位的清除操作,以保證系統的正常運行。
RT - Linux 如何實現軟實時性?(如引入搶占性、內核鎖優化、高分辨率計時器、優先級繼承)
- 引入搶占性:RT - Linux 通過改造內核,使其具有搶占性。傳統的 Linux 內核在某些情況下會禁止搶占,以保證內核數據結構的一致性,但這會導致實時任務不能及時得到執行。RT - Linux 在內核中設置了搶占點,在這些點上允許高優先級的實時任務搶占低優先級任務的執行。例如,在系統調用、中斷處理等關鍵位置,會檢查是否有高優先級的實時任務就緒,如果有,則進行任務切換,讓實時任務能夠盡快獲得 CPU 資源,從而提高系統的實時響應能力。
- 內核鎖優化:在傳統 Linux 內核中,對一些共享資源的訪問需要使用鎖來保護,以防止并發訪問導致數據不一致。但傳統的鎖機制可能會導致較長的阻塞時間,影響實時任務的執行。RT - Linux 對內核鎖進行了優化,采用了更高效的鎖實現方式,如自旋鎖等。自旋鎖在等待鎖釋放時不會讓任務進入睡眠狀態,而是通過不斷地循環檢查鎖的狀態,這樣可以減少任務切換的開銷,提高實時任務獲取資源的速度。同時,RT - Linux 還對鎖的使用進行了嚴格的限制和管理,盡量減少鎖的持有時間,避免因長時間持有鎖而阻塞高優先級的實時任務。
- 高分辨率計時器:為了實現精確的時間控制,RT - Linux 采用了高分辨率計時器。傳統的 Linux 計時器分辨率相對較低,無法滿足實時應用對精確時間的要求。RT - Linux 通過硬件支持和軟件算法,實現了納秒級別的高分辨率計時器。這些計時器可以為實時任務提供精確的定時服務,例如,實時任務可以根據高分辨率計時器來精確地控制任務的執行周期、延遲時間等,確保任務按照預期的時間要求執行,提高系統的實時性和確定性。
- 優先級繼承:在多任務系統中,當一個低優先級任務持有資源而高優先級任務需要訪問該資源時,如果不進行特殊處理,可能會導致高優先級任務被阻塞,從而影響實時性。RT - Linux 采用了優先級繼承機制來解決這個問題。當高優先級任務因等待低優先級任務持有的資源而阻塞時,低優先級任務的優先級會暫時提升到與高優先級任務相同的水平,這樣可以讓低優先級任務盡快完成對資源的使用并釋放資源,從而減少高優先級任務的阻塞時間。當低優先級任務釋放資源后,其優先級再恢復到原來的水平。通過優先級繼承機制,可以有效地避免優先級反轉問題,提高系統的實時性能。
Linux 進程有哪些調度方式?請解釋 CFS 調度算法。
- Linux 進程的調度方式主要有以下幾種:
- SCHED_FIFO:這是一種先進先出的實時調度策略。采用這種策略的進程一旦獲得 CPU 資源,就會一直運行直到它主動放棄 CPU 或者被更高優先級的實時進程搶占。它沒有時間片的概念,適合那些對響應時間要求極高,且運行時間較短的實時任務,例如一些關鍵的控制任務,需要在極短的時間內完成處理并返回。
- SCHED_RR:也是一種實時調度策略,與 SCHED_FIFO 類似,但它為每個進程分配了一個時間片。當進程的時間片用完后,即使它還沒有執行完畢,也會被搶占,然后放入就緒隊列的末尾,等待下一次調度。這種方式適用于那些需要公平地共享 CPU 時間,且對響應時間有一定要求的實時任務,例如一些多媒體處理任務,需要在一定的時間內完成數據處理,但又不能長時間獨占 CPU。
- SCHED_OTHER:這是 Linux 中默認的調度策略,用于普通的非實時進程。它采用了完全公平調度算法(CFS),會根據進程的優先級和其他因素來分配 CPU 時間,以實現進程之間的公平調度,盡量保證每個進程都能得到合理的 CPU 資源,滿足大多數用戶的日常使用需求。
- CFS 調度算法:
- 基本原理:CFS 的核心思想是為每個進程維護一個虛擬運行時間(vruntime),并根據 vruntime 來決定哪個進程應該獲得 CPU 資源。虛擬運行時間是一個相對的時間概念,它與進程實際占用的 CPU 時間和進程的權重(優先級)有關。權重越高的進程,其虛擬運行時間增長得越慢,也就越容易獲得 CPU 資源,體現了優先級的差異。CFS 通過不斷地比較各個進程的 vruntime,選擇 vruntime 最小的進程運行,從而實現了公平調度,即每個進程都能根據其優先級獲得相應的 CPU 時間份額。
- 數據結構:CFS 使用紅黑樹來管理就緒進程隊列。紅黑樹是一種自平衡的二叉搜索樹,具有高效的查找、插入和刪除操作性能。在 CFS 中,以進程的 vruntime 作為紅黑樹的鍵值,這樣可以快速地找到 vruntime 最小的進程,也就是下一個應該運行的進程。同時,紅黑樹的結構也便于在進程的狀態發生變化(如睡眠、喚醒)時,快速地更新就緒隊列。
- 調度周期:CFS 將 CPU 的時間劃分為一個個的調度周期。在每個調度周期內,CFS 會根據進程的權重來分配 CPU 時間。例如,在一個調度周期內,總共有 100 個時間單位,有兩個進程 A 和 B,進程 A 的權重是 2,進程 B 的權重是 3,那么按照比例,進程 A 會獲得 40 個時間單位的 CPU 時間,進程 B 會獲得 60 個時間單位的 CPU 時間。通過這種方式,保證了在一個調度周期內,各個進程能夠按照其權重公平地共享 CPU 資源。當一個調度周期結束后,CFS 會重新計算各個進程的 vruntime,并根據新的 vruntime 來進行下一輪的調度。
操作系統如何處理外部中斷?中斷結束后回到任務需要注意什么?
- 操作系統處理外部中斷的過程如下:
- 中斷檢測:硬件設備通過中斷信號線向 CPU 發送中斷請求信號,CPU 在每個指令周期結束時會檢查是否有中斷請求到來。如果檢測到有外部中斷請求,CPU 會暫停當前正在執行的指令,準備進入中斷處理流程。
- 中斷響應:CPU 收到中斷請求后,會根據中斷向量表找到對應的中斷服務程序(ISR)的入口地址。中斷向量表是一個存儲了不同中斷類型對應的 ISR 入口地址的數據結構,它在系統初始化時被設置好。然后,CPU 會保存當前任務的上下文,包括程序計數器(PC)、通用寄存器等的值,以便在中斷處理完成后能夠恢復任務的執行。
- 中斷處理:CPU 跳轉到中斷服務程序的入口地址開始執行 ISR。在 ISR 中,首先會進行一些基本的操作,如禁止其他中斷(可根據需要決定是否禁止),以防止在中斷處理過程中被其他中斷干擾。然后,ISR 會根據中斷的類型和原因進行相應的處理,例如讀取硬件寄存器獲取中斷相關的信息,執行與中斷相關的任務,如數據傳輸、設備控制等。在處理過程中,如果需要訪問共享資源,可能需要使用鎖機制來保證數據的一致性。
- 中斷結束:當中斷服務程序執行完畢后,會進行一些收尾工作,如清除中斷標志位(如果硬件沒有自動清除的話),通知操作系統中斷已經處理完成。然后,恢復之前保存的任務上下文,包括恢復寄存器的值和程序計數器,使 CPU 能夠回到中斷發生前的任務繼續執行。
- 中斷結束后回到任務需要注意以下幾點:
- 上下文恢復的準確性:必須確保在中斷發生時保存的任務上下文被準確無誤地恢復。任何寄存器值或程序計數器的錯誤恢復都可能導致任務執行出現異常,例如程序崩潰或產生錯誤的結果。因此,在保存和恢復上下文時,需要嚴格按照特定的順序和方式進行操作,并且要保證相關的存儲區域沒有被意外修改。
- 中斷狀態的恢復:如果在中斷處理過程中修改了中斷相關的狀態,如中斷屏蔽位等,需要在返回任務前將其恢復到中斷前的狀態。否則,可能會影響后續中斷的正常處理,例如導致某些中斷無法被響應或者中斷嵌套出現問題。
- 任務調度的考慮:在中斷返回時,需要檢查是否有更高優先級的任務已經就緒。如果有,那么操作系統可能會根據調度策略決定是否進行任務切換,讓更高優先級的任務獲得 CPU 資源。即使沒有更高優先級的任務就緒,也需要確保當前任務的狀態是正確的,例如任務是否應該繼續執行、是否需要等待某個事件等。此外,還需要考慮中斷處理過程中是否對其他任務產生了影響,如是否喚醒了其他等待的任務等,以便進行相應的調度決策。
- 數據一致性:如果中斷處理過程中訪問了共享數據結構,那么在返回任務前需要確保這些數據結構處于一致的狀態。可能需要在中斷處理結束時進行一些數據同步操作,或者釋放相關的鎖,以允許其他任務繼續訪問這些共享資源。同時,要考慮中斷處理過程中對全局變量、緩沖區等的修改是否會對任務的后續執行產生影響,必要時進行相應的處理,以保證任務的正確性和穩定性。
用過 MPU(內存保護單元)嗎?簡述其作用。
MPU(Memory Protection Unit)是一種硬件機制,用于實現內存訪問控制和保護。它在嵌入式系統中扮演著至關重要的角色,尤其是在需要確保系統穩定性、安全性和可靠性的場景中。以下從多個方面詳細闡述其作用:
內存訪問控制
MPU 的核心功能是定義和管理內存區域的訪問權限。通過將物理內存劃分為多個可編程的區域(Region),每個區域可獨立配置讀寫權限、執行權限以及訪問特權級別。例如,某些區域可設置為只讀(RO),防止代碼意外修改關鍵數據;某些區域可禁止執行(NX),有效防范緩沖區溢出攻擊。這種精細的訪問控制機制能顯著降低系統因非法內存訪問而崩潰的風險。
任務隔離與安全
在多任務系統中,MPU 可確保各個任務擁有獨立的內存空間,實現任務間的隔離。當一個任務試圖越界訪問其他任務的內存區域時,MPU 會觸發異常(如 HardFault),阻止非法訪問,從而提高系統的安全性。這對于安全關鍵型系統(如醫療設備、航空電子設備)尤為重要,因為一個任務的故障不能影響其他任務的正常運行。
防止棧溢出
棧溢出是嵌入式系統中常見的問題,可能導致程序崩潰或產生不可預測的行為。MPU 可通過為每個任務的棧空間設置邊界,當棧溢出發生時及時檢測并觸發異常,從而保護系統免受棧溢出的影響。例如,在 FreeRTOS 中,結合 MPU 使用可以有效防止任務棧溢出破壞其他任務的內存空間。
內核與用戶空間隔離
在支持特權級別的系統中,MPU 可用于隔離內核空間和用戶空間。內核空間通常擁有更高的特權級別,可訪問所有內存區域;而用戶空間的代碼只能訪問被授權的內存區域。這種隔離機制保護了內核的安全性,防止用戶空間的錯誤代碼破壞內核數據結構,從而提高整個系統的穩定性。
內存保護單元的代碼示例
以下是一個基于 ARM Cortex-M4 的 MPU 配置示例,展示如何使用 MPU 保護關鍵內存區域:
#include "stm32f4xx.h"void MPU_Config(void)
{// 使能MPUSCB->SHCSR |= SCB_SHCSR_MEMFAULTENA_Msk;// 禁用MPU以便配置MPU->CTRL = 0;// 配置Region 0 - 保護代碼段為只讀MPU->RNR = 0; // 選擇Region 0MPU->RBAR = 0x08000000; // 基地址 - Flash起始地址MPU->RASR = (0x03 << 24) | // 大小為512KB(0x01 << 16) | // 執行從不(XN)(0x01 << 8) | // 只讀(0x01 << 2) | // 特權和用戶模式都可訪問(0x01 << 0); // 使能Region 0// 配置Region 1 - 保護棧區域,防止溢出MPU->RNR = 1; // 選擇Region 1MPU->RBAR = 0x20000000; // 基地址 - SRAM起始地址MPU->RASR = (0x05 << 24) | // 大小為16KB(0x00 << 16) | // 允許執行(0x03 << 8) | // 讀寫權限(0x01 << 2) | // 特權和用戶模式都可訪問(0x01 << 0); // 使能Region 1// 使能MPU,采用默認內存映射MPU->CTRL = MPU_CTRL_ENABLE_Msk | MPU_CTRL_PRIVDEFENA_Msk;
}
什么是原子操作?i++ 是否為原子操作?為什么?
原子操作是指在執行過程中不可被中斷的操作,要么完全執行,要么完全不執行,不會出現中間狀態。在多任務或多處理器環境中,原子操作對于保證數據一致性和線程安全至關重要。
i++ 不是原子操作
在大多數編程語言中,包括 C、C++ 等,i++?并非原子操作。它實際上包含三個獨立的步驟:
- 讀取:從內存中讀取變量?
i?的當前值。 - 增加:將讀取的值加 1。
- 寫回:將增加后的值寫回內存。
由于這三個步驟是分開執行的,因此在多線程或中斷環境中,可能會出現競態條件(Race Condition)。例如,當兩個線程同時執行?i++?時,可能會發生以下情況:
- 線程 A 讀取?
i?的值(假設為 10)。 - 線程 B 讀取?
i?的值(此時仍為 10,因為線程 A 尚未寫回)。 - 線程 A 將值加 1(變為 11)并寫回內存。
- 線程 B 將值加 1(同樣變為 11)并寫回內存。
最終,i?的值僅增加了 1 次,而不是預期的 2 次。這種錯誤稱為 “丟失更新”,是競態條件的典型表現。
為什么 i++ 不是原子操作?
i++?不是原子操作的根本原因在于它涉及多個內存訪問和計算步驟,而這些步驟之間可能被其他線程或中斷打斷。現代處理器通常提供專門的原子操作指令,如 ARM Cortex-M 系列的 LDREX/STREX 指令或 x86 的 LOCK 前綴指令,這些指令可以保證單個操作的原子性。但?i++?本身是一個復合操作,需要多條指令才能完成,因此不具備原子性。
如何實現原子操作?
在嵌入式系統中,實現原子操作有以下幾種常見方法:
1. 使用硬件支持的原子指令
許多處理器提供原子操作指令,如 ARM Cortex-M 的 DMB(數據內存屏障)和 LDREX/STREX 指令對。例如,以下代碼使用 GCC 內置函數實現原子遞增:
#include <stdatomic.h>atomic_int i = 0;void increment(void)
{atomic_fetch_add(&i, 1); // 原子遞增操作
}
2. 關中斷
在單處理器系統中,可以通過關閉中斷來保證操作的原子性:
volatile int i = 0;void increment(void)
{uint32_t primask = __get_PRIMASK(); // 保存當前中斷狀態__disable_irq(); // 禁用中斷i++; // 在中斷禁用期間執行,確保原子性__set_PRIMASK(primask); // 恢復中斷狀態
}
3. 使用互斥鎖
在多線程環境中,可以使用互斥鎖(Mutex)來保護共享資源:
#include "FreeRTOS.h"
#include "semphr.h"volatile int i = 0;
SemaphoreHandle_t mutex;void increment(void)
{xSemaphoreTake(mutex, portMAX_DELAY); // 獲取鎖i++;xSemaphoreGive(mutex); // 釋放鎖
}
釋放內存時,系統如何知道要釋放的內存長度?
在使用動態內存分配函數(如?free())釋放內存時,系統必須知道要釋放的內存塊的大小,以便正確回收內存并維護內存管理數據結構。這一信息的存儲和管理方式取決于具體的內存分配器實現,但通常有以下幾種機制:
內存塊頭部信息
大多數內存分配器在分配內存時,會在實際返回的內存地址之前的區域(稱為 “頭部”)存儲有關該內存塊的元數據,包括塊大小、使用狀態(已分配 / 空閑)以及指向前一個或后一個內存塊的指針等。例如:
內存布局示意圖:
+----------------------+----------------------+
| 頭部信息 | 用戶數據 |
| (大小、狀態等元數據) | (malloc返回的地址) |
+----------------------+----------------------+
<-- 頭部大小(通常為16或32字節) -->
當調用?free()?時,系統會通過指針運算計算出頭部的位置,從中讀取塊大小信息,然后釋放整個內存塊(包括頭部和用戶數據區域)。例如:
void free(void *ptr)
{if (ptr == NULL) return;// 通過指針運算找到頭部header_t *header = (header_t*)((char*)ptr - sizeof(header_t));// 從頭部獲取塊大小size_t block_size = header->size;// 標記該塊為空閑header->is_allocated = 0;// 合并相鄰的空閑塊(可選)merge_with_adjacent_free_blocks(header);
}
顯式傳遞大小信息
某些內存分配函數(如 Windows API 中的?HeapFree())允許顯式傳遞內存塊的大小作為參數。這種方式需要程序員在調用釋放函數時提供正確的大小信息,但缺點是增加了使用難度和出錯風險。
分離式內存池
在一些嵌入式系統中,為了簡化內存管理和提高性能,可能會使用分離式內存池(Slab Allocation)。這種方法將內存劃分為固定大小的塊,每個塊的大小在創建內存池時就已確定。當釋放內存時,系統只需知道該內存塊屬于哪個內存池,即可確定其大小。例如:
// 固定大小為128字節的內存池
void *pool = create_memory_pool(128, 100); // 創建100個塊的內存池// 分配和釋放
void *ptr = allocate_from_pool(pool);
free_to_pool(pool, ptr); // 系統知道塊大小為128字節
內存分配器的全局數據結構
一些高級內存分配器(如 glibc 的 ptmalloc)維護全局的內存映射表或紅黑樹等數據結構,記錄每個分配的內存塊的起始地址和大小。當調用?free()?時,系統會在這些數據結構中查找對應的記錄,從而獲取塊大小信息。
示例:簡單內存分配器的頭部結構
以下是一個簡化的內存分配器頭部結構示例:
typedef struct header {size_t size; // 內存塊大小(不包括頭部)unsigned char used; // 使用狀態(1=已分配,0=空閑)struct header *next; // 指向下一個內存塊struct header *prev; // 指向前一個內存塊
} header_t;// 內存分配函數(簡化版)
void *my_malloc(size_t size)
{// 計算實際需要的總大小(包括頭部)size_t total_size = size + sizeof(header_t);// 查找合適的空閑塊header_t *block = find_free_block(total_size);if (block) {// 標記為已使用block->used = 1;// 返回頭部之后的地址(用戶可用空間)return (void*)(block + 1);}// 沒有合適的空閑塊,需要擴展堆block = expand_heap(total_size);if (block) {block->size = size;block->used = 1;return (void*)(block + 1);}return NULL; // 分配失敗
}// 內存釋放函數(簡化版)
void my_free(void *ptr)
{if (ptr == NULL) return;// 獲取頭部指針header_t *block = (header_t*)ptr - 1;// 標記為空閑block->used = 0;// 合并相鄰的空閑塊(優化內存碎片)merge_adjacent_free_blocks(block);
}
簡述 malloc () 的底層實現原理。
malloc()?是 C 標準庫中用于動態內存分配的核心函數,其底層實現原理涉及操作系統、內存管理算法和硬件機制的協同工作。以下從多個層面詳細解析其實現原理:
虛擬內存與物理內存
現代操作系統采用虛擬內存管理機制,將進程的地址空間與物理內存分離。每個進程都有自己獨立的虛擬地址空間,而物理內存則由操作系統統一管理。malloc()?分配的內存實際上是虛擬內存地址,操作系統負責將虛擬地址映射到物理內存頁。
內存分配的層次結構
malloc()?的實現通常分為多個層次:
-
系統調用層:與操作系統內核交互,獲取大塊內存。在 Linux 系統中,這通常通過?
brk()?或?mmap()?系統調用實現。brk():調整進程數據段的結束地址(break),適用于小內存塊的分配。mmap():直接從操作系統映射一塊內存區域,適用于大內存塊(通常大于 128KB)的分配。
-
內存池管理:將從操作系統獲取的大塊內存劃分為多個小內存塊,形成內存池,以便高效分配和回收。
-
分配算法層:實現具體的內存分配策略,如首次適配(First Fit)、最佳適配(Best Fit)或伙伴系統(Buddy System)等。
內存分配算法
常見的內存分配算法包括:
-
首次適配(First Fit):遍歷空閑內存塊列表,找到第一個足夠大的塊分配。優點是分配速度快,缺點是容易產生內存碎片。
-
最佳適配(Best Fit):遍歷所有空閑塊,找到最接近請求大小的塊分配。優點是內存利用率高,缺點是分配速度較慢,且可能產生大量小碎片。
-
伙伴系統(Buddy System):將內存塊按 2 的冪次方大小管理,分配和釋放時通過合并和分裂操作維護內存塊的連續性。優點是分配和釋放速度快,且能有效減少外部碎片,但可能導致內部碎片(分配的塊比實際需要大)。
內存塊管理
malloc()?通過維護內存塊頭部信息來管理分配的內存。頭部通常包含以下信息:
- 內存塊大小
- 使用狀態(已分配 / 空閑)
- 指向前一個和后一個內存塊的指針
- 可選的校驗和或其他元數據
例如,一個簡化的內存塊頭部結構可能如下:
typedef struct mem_block {size_t size; // 內存塊大小(不包括頭部)int is_allocated; // 是否已分配struct mem_block *prev; // 前一個塊struct mem_block *next; // 后一個塊
} mem_block_t;
glibc 的 ptmalloc 實現
GNU C 庫(glibc)的?malloc()?實現(ptmalloc)采用了多種優化策略:
-
線程緩存(Thread Cache):為每個線程分配獨立的緩存,減少線程間的鎖競爭,提高并發性能。
-
分箱管理(Bins):將不同大小的內存塊分類管理,加速查找合適的空閑塊。例如,小內存塊(64 字節以下)使用 fast bins 管理,中等大小的塊使用 small bins,大內存塊使用 large bins。
-
內存池(Arena):多線程環境下,每個線程可以有自己的內存池(arena),減少鎖競爭。
-
內存碎片整理:在釋放內存時,嘗試合并相鄰的空閑塊,減少外部碎片。
簡化的 malloc () 實現示例
以下是一個簡化的?malloc()?實現示例,演示基本原理:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>// 內存塊頭部結構
typedef struct mem_block {size_t size;int is_allocated;struct mem_block *next;
} mem_block_t;// 全局鏈表頭
static mem_block_t *head = NULL;// 查找合適的空閑塊
static mem_block_t* find_free_block(size_t size) {mem_block_t *current = head;while (current) {if (current->is_allocated == 0 && current->size >= size) {return current;}current = current->next;}return NULL;
}// 擴展堆空間
static mem_block_t* expand_heap(size_t size) {mem_block_t *block = sbrk(0); // 獲取當前堆頂void *request = sbrk(size + sizeof(mem_block_t));if (request == (void*)-1) {return NULL; // 內存分配失敗}block->size = size;block->is_allocated = 1;block->next = NULL;return block;
}// 分配內存
void* my_malloc(size_t size) {if (size == 0) return NULL;// 查找空閑塊mem_block_t *block = find_free_block(size);if (block) {block->is_allocated = 1;return (void*)(block + 1); // 返回頭部之后的地址}// 沒有合適的空閑塊,擴展堆block = expand_heap(size);if (!block) {return NULL; // 內存不足}// 如果是第一次分配,設置鏈表頭if (!head) {head = block;}return (void*)(block + 1);
}// 釋放內存
void my_free(void *ptr) {if (!ptr) return;mem_block_t *block = (mem_block_t*)ptr - 1; // 獲取頭部block->is_allocated = 0;// 這里可以添加合并相鄰空閑塊的邏輯
}
內存分配模型(4GB 地址空間,1GB 內核空間,代碼段、數據段、BSS 段、堆棧)中,BSS 段是否占執行文件大小?
在典型的 32 位系統內存分配模型中,進程擁有 4GB 的虛擬地址空間,其中高 1GB 為內核空間,低 3GB 為用戶空間。用戶空間進一步劃分為多個段,包括代碼段(.text)、數據段(.data)、BSS 段(.bss)和堆棧。BSS 段不占用執行文件的大小,以下從多個角度詳細解釋:
BSS 段的定義與作用
BSS(Block Started by Symbol)段用于存儲未初始化或初始化為 0 的全局變量和靜態變量。例如:
int global_var; // 未初始化的全局變量
static int static_var; // 未初始化的靜態變量
int arr[1000] = {0}; // 初始化為0的數組
這些變量在程序運行時需要占用內存空間,但它們的初始值都是 0,因此在執行文件中不需要存儲這些 0 值,只需要記錄變量的類型和大小即可。
執行文件的結構
執行文件(如 ELF 格式)主要包含兩部分:
-
程序頭表(Program Header Table):描述如何將文件映射到內存,包括各段的加載地址、大小等信息。
-
節頭表(Section Header Table):描述文件中各節(Section)的信息,如代碼節、數據節等。
BSS 段在執行文件中僅在程序頭表和節頭表中記錄其大小和加載地址,而不包含實際的數據內容。當程序加載時,操作系統會根據這些信息為 BSS 段分配內存空間,并將其初始化為 0。
為什么 BSS 段不占執行文件大小?
BSS 段不占執行文件大小的主要原因是為了節省磁盤空間和加載時間。如果將所有初始化為 0 的變量都存儲在執行文件中,會導致文件體積龐大,尤其是當存在大量數組或大型數據結構時。通過只記錄 BSS 段的元數據(大小、位置等),而不存儲實際的 0 值,執行文件可以顯著減小。
示例對比
考慮以下兩個全局變量的定義:
// 文件1
int data_var = 42; // 初始化為非零值,存儲在.data段// 文件2
int bss_var = 0; // 初始化為0,存儲在.bss段
在執行文件中:
data_var?需要在數據段(.data)中存儲值 42,因此會占用執行文件的空間。bss_var?只需要在程序頭表中記錄其大小(例如 4 字節),而不需要存儲實際的 0 值,因此不占用執行文件的空間。
BSS 段的內存初始化
當程序加載時,操作系統會為 BSS 段分配內存,并將其初始化為 0。這一過程通常發生在程序啟動階段的初始化代碼中,例如 C 運行時庫的_start 函數會負責完成 BSS 段的清零工作。因此,雖然 BSS 段在執行文件中不占空間,但在程序運行時,它確實占用內存空間。
執行文件大小驗證
可以通過以下步驟驗證 BSS 段不占執行文件大小:
- 編寫一個包含大量未初始化全局變量的程序:
// large_bss.c
#include <stdio.h>int large_array[1000000]; // 未初始化的大數組,存儲在BSS段int main() {printf("Array size: %zu bytes\n", sizeof(large_array));return 0;
}
- 編譯并查看文件大小:
sh
gcc large_bss.c -o large_bss
ls -lh large_bss
盡管large_array占用了 4MB 的內存空間,但執行文件的大小通常只有幾 KB,因為 BSS 段不占文件空間。
- 對比初始化的數組:
// large_data.c
#include <stdio.h>int large_array[1000000] = {1}; // 初始化為非零值,存儲在.data段int main() {printf("Array size: %zu bytes\n", sizeof(large_array));return 0;
}
編譯后,large_data的文件大小會顯著增加,因為.data 段需要存儲數組的實際值。
什么是內存泄漏?如何定位和解決內存泄漏?
內存泄漏(Memory Leak)是指程序在運行過程中動態分配的內存未能被正確釋放,導致這部分內存無法被再次使用,最終造成系統可用內存逐漸減少的現象。在嵌入式系統中,內存泄漏可能導致系統崩潰、性能下降或功能異常,因此需要高度重視。
內存泄漏的原因
內存泄漏通常由以下原因導致:
- 動態內存分配后未釋放:使用 malloc、calloc、realloc 等函數分配內存后,沒有對應的 free 調用。
- 釋放內存的條件未滿足:例如在條件分支中分配了內存,但某些路徑下沒有釋放。
- 指針丟失:在重新賦值前未釋放原指針指向的內存,導致無法訪問該內存塊。
- 對象生命周期管理不當:在面向對象編程中,對象的引用計數未正確維護,導致析構函數未被調用。
- 異常處理不完善:在異常發生時,沒有正確釋放已分配的內存。
內存泄漏的危害
- 系統性能下降:可用內存減少會導致頻繁的內存交換,降低系統運行速度。
- 程序崩潰:當系統內存耗盡時,程序可能無法分配新的內存,導致崩潰。
- 資源耗盡:長期運行的程序(如嵌入式設備的固件)可能因內存泄漏逐漸耗盡所有可用內存。
定位內存泄漏的方法
- 代碼審查:仔細檢查代碼中動態內存分配和釋放的配對情況,確保每個 malloc 都有對應的 free。
- 工具檢測:使用專業工具如 Valgrind(Linux)、BoundsChecker(Windows)等檢測內存泄漏。
- 內存監控:編寫自定義內存分配器,記錄內存分配和釋放的信息,定期檢查未釋放的內存。
- 日志記錄:在關鍵位置添加日志,記錄內存分配和釋放的時間、大小等信息。
- 內存分析工具:如 Linux 下的 pmap、top 命令,Windows 下的任務管理器,查看程序的內存使用情況。
解決內存泄漏的方法
- 嚴格配對:確保每個內存分配函數都有對應的釋放函數,遵循誰分配誰釋放的原則。
- 智能指針:在 C++ 中使用智能指針(如 std::unique_ptr、std::shared_ptr)自動管理內存生命周期。
- RAII 技術:利用 C++ 的構造函數和析構函數,在對象生命周期內管理資源。
- 內存池:使用內存池技術減少動態內存分配和釋放的次數,降低內存泄漏風險。
- 異常安全:在異常處理中確保資源的正確釋放,例如使用 try-finally 塊。
- 定期檢查:在開發和測試階段定期檢查內存使用情況,及時發現和修復泄漏。
內存泄漏檢測示例
以下是一個簡單的內存泄漏檢測工具實現示例:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>// 內存塊信息結構
typedef struct MemoryBlock {void* address;size_t size;const char* file;int line;struct MemoryBlock* next;
} MemoryBlock;// 全局鏈表頭
static MemoryBlock* head = NULL;// 重載malloc函數
void* my_malloc(size_t size, const char* file, int line) {void* ptr = malloc(size);if (ptr) {MemoryBlock* block = (MemoryBlock*)malloc(sizeof(MemoryBlock));if (block) {block->address = ptr;block->size = size;block->file = file;block->line = line;block->next = head;head = block;}}return ptr;
}// 重載free函數
void my_free(void* ptr) {if (ptr) {MemoryBlock* current = head;MemoryBlock* previous = NULL;while (current) {if (current->address == ptr) {if (previous) {previous->next = current->next;} else {head = current->next;}free(current);free(ptr);return;}previous = current;current = current->next;}// 未找到匹配的分配記錄,可能是非法釋放fprintf(stderr, "Error: Attempt to free unallocated memory at %p\n", ptr);}
}// 報告內存泄漏
void report_leaks() {MemoryBlock* current = head;int count = 0;size_t total = 0;printf("Memory leaks detected:\n");while (current) {printf(" Leak at %p: %zu bytes allocated in %s:%d\n",current->address, current->size, current->file, current->line);total += current->size;count++;current = current->next;}if (count == 0) {printf("No memory leaks detected.\n");} else {printf("Total %d leaks, %zu bytes lost.\n", count, total);}
}// 示例使用
#define malloc(size) my_malloc(size, __FILE__, __LINE__)
#define free(ptr) my_free(ptr)int main() {int* ptr = (int*)malloc(sizeof(int) * 10);// 忘記釋放ptrreport_leaks();return 0;
}
如何解決堆內存碎片問題?
堆內存碎片是指堆內存被分割成許多不連續的小塊,導致即使總可用內存足夠,但無法分配大塊連續內存的現象。碎片分為內部碎片和外部碎片,前者是已分配內存塊內部的未使用空間,后者是空閑內存塊之間的間隙。解決堆內存碎片問題需要從內存分配策略、數據結構設計和系統架構等多方面入手。
內存碎片的危害
- 內存利用率降低:可用內存總量充足,但無法分配大塊連續內存。
- 性能下降:碎片增多會導致內存分配和釋放操作變慢,系統需要更多時間尋找合適的內存塊。
- 提前內存耗盡:碎片問題可能導致系統在總內存未被充分使用時就無法分配所需內存。
解決堆內存碎片問題的方法
-
選擇合適的內存分配算法:
- 首次適配(First Fit):找到第一個足夠大的空閑塊分配,速度快但易產生碎片。
- 最佳適配(Best Fit):找到最接近請求大小的空閑塊分配,減少內部碎片。
- 最壞適配(Worst Fit):分配最大的空閑塊,減少外部碎片但可能導致大內存塊不足。
- 伙伴系統(Buddy System):將內存按 2 的冪次方管理,分配和釋放效率高,減少碎片。
-
內存池技術:
- 預先分配大塊內存,劃分為固定大小的小塊,用于特定類型對象的分配。
- 減少動態分配次數,避免碎片產生,適用于頻繁分配相同大小對象的場景。
-
對象生命周期管理:
- 盡量讓相關對象的生命周期一致,避免大對象和小對象交叉分配和釋放。
- 批量分配和釋放內存,減少碎片產生的機會。
-
內存整理(Compaction):
- 移動已分配的內存塊,合并相鄰的空閑塊,形成更大的連續內存空間。
- 需要暫停程序執行,適用于允許暫停的系統,如某些嵌入式實時系統。
-
大內存塊特殊處理:
- 對于大塊內存請求,使用 mmap 直接從操作系統分配,避免影響堆內存的連續性。
- 分配后盡量長時間使用,減少頻繁分配和釋放帶來的碎片。
-
內存對齊優化:
- 合理設計數據結構,減少內存對齊帶來的內部碎片。
- 使用 #pragma pack 等指令控制結構體對齊方式。
-
內存碎片檢測工具:
- 使用 Valgrind、mtrace 等工具檢測和分析內存碎片情況,針對性地優化。
內存池實現示例
以下是一個簡單的固定大小內存池實現示例:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>// 內存池結構
typedef struct MemoryPool {void* memory; // 內存池起始地址size_t block_size; // 每個塊的大小size_t block_count; // 塊的總數size_t free_count; // 空閑塊數量char* free_map; // 空閑塊位圖
} MemoryPool;// 初始化內存池
MemoryPool* init_memory_pool(size_t block_size, size_t block_count) {// 計算所需總內存size_t total_size = block_size * block_count;// 分配內存池結構和內存空間MemoryPool* pool = (MemoryPool*)malloc(sizeof(MemoryPool) + total_size);if (!pool) return NULL;// 初始化內存池結構pool->memory = (char*)pool + sizeof(MemoryPool);pool->block_size = block_size;pool->block_count = block_count;pool->free_count = block_count;// 分配并初始化空閑塊位圖pool->free_map = (char*)malloc((block_count + 7) / 8);if (!pool->free_map) {free(pool);return NULL;}memset(pool->free_map, 0xFF, (block_count + 7) / 8); // 所有塊初始化為空閑return pool;
}// 從內存池分配內存
void* pool_alloc(MemoryPool* pool) {if (!pool || pool->free_count == 0) return NULL;// 查找空閑塊for (size_t i = 0; i < pool->block_count; i++) {size_t byte_idx = i / 8;size_t bit_idx = i % 8;if (pool->free_map[byte_idx] & (1 << bit_idx)) {// 標記為已使用pool->free_map[byte_idx] &= ~(1 << bit_idx);pool->free_count--;// 返回內存塊地址return (char*)pool->memory + i * pool->block_size;}}return NULL; // 不應該到達這里,因為free_count不為0
}// 釋放內存回內存池
void pool_free(MemoryPool* pool, void* ptr) {if (!pool || !ptr) return;// 計算塊索引ptrdiff_t offset = (char*)ptr - (char*)pool->memory;if (offset < 0 || offset >= (ptrdiff_t)(pool->block_size * pool->block_count)) {return; // 無效的指針}size_t block_idx = offset / pool->block_size;// 標記為空閑size_t byte_idx = block_idx / 8;size_t bit_idx = block_idx % 8;if (!(pool->free_map[byte_idx] & (1 << bit_idx))) {pool->free_map[byte_idx] |= (1 << bit_idx);pool->free_count++;}
}// 銷毀內存池
void destroy_memory_pool(MemoryPool* pool) {if (pool) {if (pool->free_map) {free(pool->free_map);}free(pool);}
}// 示例使用
int main() {// 創建一個包含100個塊,每塊128字節的內存池MemoryPool* pool = init_memory_pool(128, 100);if (!pool) {printf("Failed to initialize memory pool.\n");return 1;}// 分配內存void* ptr1 = pool_alloc(pool);void* ptr2 = pool_alloc(pool);// 使用內存...// 釋放內存pool_free(pool, ptr1);pool_free(pool, ptr2);// 銷毀內存池destroy_memory_pool(pool);return 0;
}
智能指針的底層原理是什么?
智能指針是 C++ 中用于自動管理動態內存的工具,它通過 RAII(資源獲取即初始化)技術,在對象生命周期結束時自動釋放所管理的內存,從而避免內存泄漏。智能指針的底層實現基于模板類和引用計數技術,下面詳細介紹其原理。
智能指針的基本原理
智能指針的核心思想是將動態分配的內存交給一個對象管理,當該對象離開作用域時,其析構函數會自動釋放所管理的內存。智能指針通常通過以下方式實現:
- 模板類:智能指針是一個模板類,可以管理任意類型的對象。
- 重載操作符:重載
*和->操作符,使智能指針的使用方式類似于普通指針。 - 引用計數:對于共享所有權的智能指針(如 std::shared_ptr),使用引用計數跟蹤有多少個智能指針共享同一個對象。
- 自定義刪除器:允許用戶指定自定義的刪除器,用于釋放非傳統方式分配的內存或資源。
C++ 標準庫中的智能指針
C++ 標準庫提供了三種主要的智能指針:
- std::unique_ptr:獨占所有權的智能指針,同一時間只能有一個 unique_ptr 指向同一個對象。
- std::shared_ptr:共享所有權的智能指針,使用引用計數管理多個指針共享的對象。
- std::weak_ptr:弱引用智能指針,不控制對象的生命周期,用于解決 std::shared_ptr 的循環引用問題。
std::shared_ptr 的底層實現
std::shared_ptr 的核心是引用計數技術。每個被管理的對象都有一個關聯的控制塊(Control Block),其中包含:
- 引用計數:記錄當前有多少個 shared_ptr 指向該對象。
- 弱引用計數:記錄當前有多少個 weak_ptr 指向該對象。
- 刪除器指針:指向用于釋放對象的刪除器函數。
- 分配器指針:指向用于分配和釋放控制塊的分配器。
當創建一個 shared_ptr 時,引用計數初始化為 1。每當一個 shared_ptr 被復制或賦值時,引用計數加 1;當一個 shared_ptr 被銷毀或重置時,引用計數減 1。當引用計數降為 0 時,對象被刪除。
std::unique_ptr 的底層實現
std::unique_ptr 是一個輕量級的智能指針,它通過禁止拷貝構造和拷貝賦值操作來確保獨占所有權。它的實現主要包括:
- 指向對象的原始指針:存儲被管理對象的地址。
- 刪除器:在析構時調用刪除器釋放對象。
由于 unique_ptr 不允許拷貝,它的性能通常比 shared_ptr 更好,適用于不需要共享所有權的場景。
智能指針的自定義刪除器
智能指針允許用戶指定自定義刪除器,用于釋放非傳統方式分配的內存或資源。例如,對于使用 fopen 打開的文件,可以使用自定義刪除器調用 fclose 關閉文件:
#include <memory>
#include <cstdio>void file_deleter(FILE* file) {if (file) {fclose(file);printf("File closed.\n");}
}int main() {// 使用自定義刪除器創建shared_ptrstd::shared_ptr<FILE> file(fopen("test.txt", "r"), file_deleter);if (file) {// 使用文件...}// 文件會在shared_ptr離開作用域時自動關閉return 0;
}
智能指針的實現示例
以下是一個簡化的 shared_ptr 實現示例,展示其基本原理:
#include <iostream>template <typename T>
class MySharedPtr {
private:T* ptr; // 指向對象的指針int* ref_count; // 引用計數器public:// 默認構造函數MySharedPtr() : ptr(nullptr), ref_count(nullptr) {}// 構造函數explicit MySharedPtr(T* p) : ptr(p) {if (ptr) {ref_count = new int(1);}}// 拷貝構造函數MySharedPtr(const MySharedPtr& other) : ptr(other.ptr), ref_count(other.ref_count) {if (ref_count) {(*ref_count)++;}}// 移動構造函數MySharedPtr(MySharedPtr&& other) noexcept : ptr(other.ptr), ref_count(other.ref_count) {other.ptr = nullptr;other.ref_count = nullptr;}// 析構函數~MySharedPtr() {reset();}// 拷貝賦值運算符MySharedPtr& operator=(const MySharedPtr& other) {if (this != &other) {reset();ptr = other.ptr;ref_count = other.ref_count;if (ref_count) {(*ref_count)++;}}return *this;}// 移動賦值運算符MySharedPtr& operator=(MySharedPtr&& other) noexcept {if (this != &other) {reset();ptr = other.ptr;ref_count = other.ref_count;other.ptr = nullptr;other.ref_count = nullptr;}return *this;}// 解引用運算符T& operator*() const {return *ptr;}// 箭頭運算符T* operator->() const {return ptr;}// 獲取引用計數int use_count() const {return ref_count ? *ref_count : 0;}// 重置智能指針void reset() {if (ref_count) {(*ref_count)--;if (*ref_count == 0) {delete ptr;delete ref_count;}ptr = nullptr;ref_count = nullptr;}}
};// 示例使用
int main() {MySharedPtr<int> ptr1(new int(42));std::cout << "ptr1 use count: " << ptr1.use_count() << std::endl;MySharedPtr<int> ptr2 = ptr1;std::cout << "ptr1 use count: " << ptr1.use_count() << std::endl;std::cout << "ptr2 use count: " << ptr2.use_count() << std::endl;MySharedPtr<int> ptr3;ptr3 = ptr1;std::cout << "ptr1 use count: " << ptr1.use_count() << std::endl;std::cout << "ptr2 use count: " << ptr2.use_count() << std::endl;std::cout << "ptr3 use count: " << ptr3.use_count() << std::endl;return 0;
}
I2C 是一主多從還是多主多從?如何查找從機?
I2C(Inter-Integrated Circuit)總線是一種串行通信協議,支持多主多從的通信模式。在 I2C 總線上,可以有多個主設備和多個從設備,任何一個主設備都可以發起通信。以下詳細介紹其工作原理和從機查找方法。
I2C 的多主多從特性
I2C 總線的基本特點:
- 雙線制:使用兩條線進行通信,SDA(串行數據線)和 SCL(串行時鐘線)。
- 開漏輸出:所有設備的 SDA 和 SCL 引腳都通過上拉電阻連接到電源,支持線與功能。
- 多主多從:總線上可以有多個主設備和多個從設備,每個從設備有唯一的 7 位或 10 位地址。
- 仲裁機制:當多個主設備同時嘗試控制總線時,通過仲裁機制決定哪個主設備獲得總線控制權。
I2C 從機地址
每個 I2C 從設備在總線上有一個唯一的地址,用于主設備識別和選擇從設備。地址分為兩種類型:
- 7 位地址:最常見的地址格式,支持 128 個不同的地址(實際可用 112 個,因為有些地址被保留)。
- 10 位地址:擴展地址格式,支持 1024 個不同的地址,用于需要更多從設備的場景。
查找 I2C 從機的方法
在實際應用中,有時需要確定總線上存在哪些從設備及其地址。以下是幾種常見的查找方法:
1. 手動查閱文檔
每個 I2C 從設備的地址通常在其數據手冊中指定。通過查閱設備文檔,可以直接獲取其地址。例如,常見的 I2C 設備如 EEPROM、溫度傳感器等都有固定的地址或可配置的地址范圍。
2. 使用 I2C 主機發送廣播請求
I2C 主機可以發送一個特殊的廣播地址(0x00),所有從設備都會響應這個地址。但大多數從設備不會對廣播地址做出實質性響應,只有少數支持通用調用的設備會響應。
3. 地址掃描
最常用的方法是通過地址掃描逐個嘗試可能的地址,檢測哪些地址有從設備響應。以下是一個基于 Arduino 的地址掃描示例代碼:
#include <Wire.h>void setup() {Wire.begin();Serial.begin(115200);Serial.println("\nI2C Scanner");Serial.println("Scanning...");byte error, address;int nDevices;nDevices = 0;for(address = 1; address < 127; address++ ) {// 嘗試連接到當前地址Wire.beginTransmission(address);error = Wire.endTransmission();if (error == 0) {Serial.print("I2C device found at address 0x");if (address < 16) {Serial.print("0");}Serial.println(address, HEX);nDevices++;} else if (error == 4) {Serial.print("Unknown error at address 0x");if (address < 16) {Serial.print("0");}Serial.println(address, HEX);}}if (nDevices == 0) {Serial.println("No I2C devices found\n");} else {Serial.println("done\n");}
}void loop() {}
4. 使用專用工具
許多開發板和調試工具提供了 I2C 掃描功能,例如:
- 邏輯分析儀:可以捕獲和分析 I2C 總線上的通信數據,識別從設備地址。
- I2C 總線分析儀:專門用于分析 I2C 總線通信的工具,能直接顯示總線上的從設備地址。
- 開發環境插件:如 STM32CubeMX、Arduino IDE 等提供的 I2C 掃描功能。
5. 從設備地址配置
有些 I2C 從設備允許通過引腳配置或軟件設置其地址。在這種情況下,需要根據設備的配置方式來確定其地址。例如,某些 I2C 設備有地址選擇引腳,通過連接到不同的電平(高或低)來設置地址的一部分。
I2C 仲裁機制
在多主環境中,當多個主設備同時嘗試控制總線時,I2C 通過仲裁機制決定哪個主設備獲得總線控制權。仲裁基于 SDA 線的電平競爭:
- 每個主設備在發送數據時會同時監測 SDA 線的電平。
- 如果某個主設備發送高電平,但檢測到 SDA 線為低電平,則認為自己失去仲裁,停止發送。
- 最終,發送低電平且檢測到低電平的主設備贏得仲裁,繼續控制總線。
DMA 傳輸需要配置哪些參數?如何判斷 DMA 搬運完成?
DMA(Direct Memory Access,直接內存訪問)是一種硬件機制,允許外設與內存之間直接進行數據傳輸,而無需 CPU 的干預。這種方式可以顯著提高數據傳輸效率,減少 CPU 負載。以下詳細介紹 DMA 傳輸的配置參數和完成判斷方法。
DMA 傳輸的基本原理
DMA 控制器負責管理數據傳輸,它可以:
- 直接訪問系統總線,無需 CPU 干預。
- 在內存和外設之間或內存與內存之間傳輸數據。
- 傳輸完成后向 CPU 發送中斷信號。
DMA 傳輸需要配置的參數
配置 DMA 傳輸時,通常需要設置以下參數:
1. 源地址和目標地址
- 源地址:數據的起始位置,可以是內存地址或外設寄存器地址。
- 目標地址:數據的目的地,可以是內存地址或外設寄存器地址。
- 地址增量模式:指定在每次傳輸后源地址和目標地址是否自動遞增。例如,在傳輸數組時通常需要地址遞增。
2. 數據傳輸方向
DMA 傳輸方向通常有三種:
- 外設到內存(如 ADC 數據采集)。
- 內存到外設(如 PWM 波形數據輸出)。
- 內存到內存(如數組復制)。
3. 數據寬度
- 指定每次傳輸的數據大小,常見的有 8 位、16 位或 32 位。
- 數據寬度需要與源和目標的硬件特性匹配。
4. 傳輸數據量
- 指定要傳輸的數據項數量(如字節數、字數等)。
- 有些 DMA 控制器支持塊傳輸和循環傳輸模式,可以設置傳輸塊的大小和循環次數。
5. 傳輸模式
- 單次傳輸:完成指定數量的數據傳輸后停止。
- 循環傳輸:完成一次傳輸后自動重新開始,適用于周期性數據傳輸(如音頻流)。
- 突發傳輸:將多個數據項作為一個塊進行傳輸,提高傳輸效率。
6. 中斷使能
- 配置 DMA 在以下事件發生時產生中斷:
- 傳輸完成(TC,Transfer Complete)。
- 傳輸錯誤(TE,Transfer Error)。
- 半傳輸完成(HT,Half Transfer Complete),適用于雙緩沖區應用。
7. 優先級
- 在多通道 DMA 控制器中,需要配置通道優先級,決定當多個通道同時請求傳輸時的處理順序。
8. 流控制
- 某些 DMA 控制器支持流控制機制,確保數據傳輸速率與外設或內存的訪問速度匹配。
判斷 DMA 搬運完成的方法
判斷 DMA 傳輸是否完成有以下幾種方法:
1. 查詢狀態寄存器
- 大多數 DMA 控制器提供狀態寄存器,包含傳輸完成標志位。
- 通過輪詢該標志位,可以確定傳輸是否完成。例如:
// 假設DMA控制器有一個狀態寄存器DMA_SR,其中位0是傳輸完成標志
while (!(DMA_SR & (1 << 0))); // 等待傳輸完成
// 處理完成后的操作
2. 中斷處理
- 配置 DMA 在傳輸完成時產生中斷,在中斷服務函數中處理完成后的操作。例如:
// DMA傳輸完成中斷服務函數
void DMA_IRQHandler(void) {if (DMA_SR & (1 << 0)) { // 檢查傳輸完成標志// 清除中斷標志DMA_SR &= ~(1 << 0);// 處理完成后的操作process_transfer_complete();}
}
3. 回調函數
- 在高級的驅動庫中,通常提供回調函數機制,允許用戶注冊一個回調函數,在 DMA 傳輸完成時自動調用。例如:
// 注冊DMA傳輸完成回調函數
void setup_dma_transfer(void) {// 配置DMA參數...// 注冊回調函數HAL_DMA_RegisterCallback(&hdma, HAL_DMA_XFER_CPLT_CB_ID, dma_complete_callback);// 啟動DMA傳輸HAL_DMA_Start(&hdma, src_address, dst_address, size);
}// 回調函數實現
void dma_complete_callback(DMA_HandleTypeDef *hdma) {// 處理完成后的操作process_transfer_complete();
}
4. 雙緩沖區機制
- 在需要連續處理數據流的應用中,可以使用雙緩沖區機制。
- 當一個緩沖區傳輸完成時(通過中斷或查詢得知),處理該緩沖區的數據,同時 DMA 開始傳輸另一個緩沖區的數據。例如:
// 雙緩沖區定義
uint8_t buffer1[1024];
uint8_t buffer2[1024];
volatile uint8_t active_buffer = 0;// DMA半傳輸完成中斷服務函數(切換到另一個緩沖區)
void DMA_HT_IRQHandler(void) {// 清除半傳輸完成標志DMA_SR &= ~(1 << 1);active_buffer = 1;process_buffer(buffer1); // 處理緩沖區1的數據
}// DMA傳輸完成中斷服務函數(切換到另一個緩沖區)
void DMA_TC_IRQHandler(void) {// 清除傳輸完成標志DMA_SR &= ~(1 << 0);active_buffer = 0;process_buffer(buffer2); // 處理緩沖區2的數據
}
5. 事件標志
- 在 RTOS 環境中,可以使用事件標志或信號量來同步 DMA 傳輸完成。例如:
// 創建一個二進制信號量
SemaphoreHandle_t dma_complete_semaphore;// 初始化信號量
dma_complete_semaphore = xSemaphoreCreateBinary();// DMA傳輸完成中斷服務函數
void DMA_IRQHandler(void) {BaseType_t xHigherPriorityTaskWoken = pdFALSE;if (DMA_SR & (1 << 0)) { // 檢查傳輸完成標志// 清除中斷標志DMA_SR &= ~(1 << 0);// 釋放信號量xSemaphoreGiveFromISR(dma_complete_semaphore, &xHigherPriorityTaskWoken);// 如果需要喚醒更高優先級的任務,則進行上下文切換portYIELD_FROM_ISR(xHigherPriorityTaskWoken);}
}// 在任務中等待DMA完成
void dma_task(void *pvParameters) {while (1) {// 等待DMA完成信號量if (xSemaphoreTake(dma_complete_semaphore, portMAX_DELAY) == pdTRUE) {// 處理完成后的操作process_transfer_complete();}}
}
DMA 傳輸配置示例
以下是一個基于 STM32 HAL 庫的 DMA 配置示例,展示如何配置和啟動一個內存到外設的 DMA 傳輸:
#include "stm32f4xx_hal.h"// 全局變量
DMA_HandleTypeDef hdma_usart1_tx;
UART_HandleTypeDef huart1;// 發送緩沖區
uint8_t tx_buffer[1024] = "Hello, DMA!";void SystemClock_Config(void);
static void MX_GPIO_Init(void);
static void MX_USART1_UART_Init(void);
static void MX_DMA_Init(void);int main(void) {HAL_Init();SystemClock_Config();MX_GPIO_Init();MX_DMA_Init();MX_USART1_UART_Init();// 啟動DMA傳輸HAL_UART_Transmit_DMA(&huart1, tx_buffer, sizeof(tx_buffer));while (1) {// 主循環可以執行其他任務,無需等待DMA傳輸完成}
}static void MX_USART1_UART_Init(void) {huart1.Instance = USART1;huart1.Init.BaudRate = 115200;huart1.Init.WordLength = UART_WORDLENGTH_8B;huart1.Init.StopBits = UART_STOPBITS_1;huart1.Init.Parity = UART_PARITY_NONE;huart1.Init.Mode = UART_MODE_TX_RX;huart1.Init.HwFlowCtl = UART_HWCONTROL_NONE;huart1.Init.OverSampling = UART_OVERSAMPLING_16;HAL_UART_Init(&huart1);// 關聯DMA句柄__HAL_LINKDMA(&huart1, hdmatx, hdma_usart1_tx);
}static void MX_DMA_Init(void) {__HAL_RCC_DMA2_CLK_ENABLE();// 配置DMA通道hdma_usart1_tx.Instance = DMA2_Stream7;hdma_usart1_tx.Init.Channel = DMA_CHANNEL_4;hdma_usart1_tx.Init.Direction = DMA_MEMORY_TO_PERIPH;hdma_usart1_tx.Init.PeriphInc = DMA_PINC_DISABLE;hdma_usart1_tx.Init.MemInc = DMA_MINC_ENABLE;hdma_usart1_tx.Init.PeriphDataAlignment = DMA_PDATAALIGN_BYTE;hdma_usart1_tx.Init.MemDataAlignment = DMA_MDATAALIGN_BYTE;hdma_usart1_tx.Init.Mode = DMA_NORMAL;hdma_usart1_tx.Init.Priority = DMA_PRIORITY_LOW;hdma_usart1_tx.Init.FIFOMode = DMA_FIFOMODE_DISABLE;HAL_DMA_Init(&hdma_usart1_tx);// 配置DMA中斷HAL_NVIC_SetPriority(DMA2_Stream7_IRQn, 0, 0);HAL_NVIC_EnableIRQ(DMA2_Stream7_IRQn);
}// DMA傳輸完成中斷處理函數
void DMA2_Stream7_IRQHandler(void) {HAL_DMA_IRQHandler(&hdma_usart1_tx);
}// UART DMA傳輸完成回調函數
void HAL_UART_TxCpltCallback(UART_HandleTypeDef *huart) {if (huart->Instance == USART1) {// 處理傳輸完成事件// 例如,可以在這里準備下一次傳輸}
}
ping?www.baidu.com的完整過程是什么?(DNS 解析、ICMP 協議)
當在終端輸入?ping www.baidu.com?時,其完整過程如下:
DNS 解析過程
- 客戶端發送 DNS 查詢:客戶端的操作系統會首先檢查本地的 DNS 緩存,如果緩存中沒有?
www.baidu.com?對應的 IP 地址,它會構造一個 DNS 查詢請求。這個請求會被發送到本地配置的 DNS 服務器(通常是由網絡服務提供商提供的 DNS 服務器)。例如,客戶端會使用 UDP 協議(通常使用 53 端口)發送 DNS 查詢數據包,數據包中包含要查詢的域名?www.baidu.com?。 - DNS 服務器查詢:本地 DNS 服務器接收到查詢請求后,會檢查自己的 DNS 緩存。如果緩存中沒有該域名的記錄,它會向其他 DNS 服務器進行查詢。DNS 服務器之間的查詢通常遵循 DNS 的層次結構,首先查詢根 DNS 服務器,根 DNS 服務器會返回頂級域名服務器(如?
.com?頂級域名服務器)的地址。然后,本地 DNS 服務器會向頂級域名服務器查詢?baidu.com?的地址,頂級域名服務器會返回?baidu.com?的權威 DNS 服務器的地址。最后,本地 DNS 服務器會向?baidu.com?的權威 DNS 服務器查詢?www.baidu.com?的 IP 地址。 - 返回 DNS 查詢結果:權威 DNS 服務器會返回?
www.baidu.com?對應的 IP 地址給本地 DNS 服務器,本地 DNS 服務器會將這個 IP 地址緩存起來,并返回給客戶端。客戶端接收到 IP 地址后,也會將其緩存,以便下次使用。
ICMP 協議過程
- 構造 ICMP 請求:客戶端得到?
www.baidu.com?的 IP 地址后,會構造一個 ICMP 回顯請求數據包。ICMP(Internet Control Message Protocol)是網絡層協議,回顯請求數據包包含一個標識符和一個序列號,用于標識這個請求。例如,標識符通常是由操作系統分配的一個唯一值,序列號從 0 開始遞增。 - 發送 ICMP 請求:客戶端將構造好的 ICMP 回顯請求數據包發送到目標 IP 地址(即?
www.baidu.com?的 IP 地址)。數據包會經過本地的網絡設備(如路由器),路由器會根據路由表將數據包轉發到目標網絡。 - 目標服務器響應:目標服務器(百度的服務器)接收到 ICMP 回顯請求數據包后,會檢查數據包的合法性。如果合法,服務器會構造一個 ICMP 回顯應答數據包,其中包含接收到的標識符和序列號,以及一些其他信息(如時間戳)。
- 返回 ICMP 應答:服務器將 ICMP 回顯應答數據包發送回客戶端。數據包同樣會經過多個網絡設備,最終到達客戶端。
- 客戶端處理應答:客戶端接收到 ICMP 回顯應答數據包后,會檢查數據包的標識符和序列號是否與發送的請求匹配。如果匹配,客戶端會計算往返時間(RTT),并將結果顯示在終端上。例如,顯示每個請求的往返時間,以及統計信息(如發送的請求數、接收的應答數、丟失的數據包數等)。
MAC 幀的目的地址是百度服務器的地址嗎?
MAC(Media Access Control)幀是數據鏈路層的協議數據單元,用于在局域網內進行數據傳輸。在討論 MAC 幀的目的地址是否是百度服務器的地址時,需要考慮網絡的層次結構和數據傳輸的過程。
MAC 幀的基本結構
MAC 幀通常包含以下幾個部分:
- 目的 MAC 地址:標識接收方的 MAC 地址。
- 源 MAC 地址:標識發送方的 MAC 地址。
- 類型 / 長度字段:指示上層協議(如 IP 協議)或幀的長度。
- 數據字段:包含要傳輸的數據,如 IP 數據包。
- 幀校驗序列(FCS):用于檢測幀在傳輸過程中是否發生錯誤。
MAC 幀的目的地址與百度服務器的關系
- 局域網內傳輸:當客戶端發送數據到百度服務器時,首先數據會被封裝成 MAC 幀在局域網內傳輸。在局域網內,MAC 幀的目的地址通常是網關(路由器)的 MAC 地址。這是因為客戶端和百度服務器不在同一個局域網內,數據需要通過網關轉發。例如,在以太網中,客戶端會根據 ARP(Address Resolution Protocol)協議獲取網關的 MAC 地址,并將其設置為 MAC 幀的目的地址。
- 廣域網傳輸:當 MAC 幀到達網關后,網關會解封裝 MAC 幀,提取出 IP 數據包。網關會根據 IP 數據包的目的 IP 地址(百度服務器的 IP 地址)進行路由查找,并將 IP 數據包轉發到下一跳路由器。在廣域網中,數據會經過多個路由器的轉發,每個路由器在轉發數據時都會重新封裝成 MAC 幀。此時,MAC 幀的目的地址是下一跳路由器的 MAC 地址,而不是百度服務器的 MAC 地址。
- 到達目標網絡:當數據到達百度服務器所在的局域網時,最后一跳路由器會將數據封裝成 MAC 幀,此時 MAC 幀的目的地址是百度服務器的 MAC 地址。這是因為在局域網內,數據需要直接發送到目標服務器。
如何檢測網絡設備是否在線?ping 屬于什么協議?
檢測網絡設備是否在線有多種方法,而?ping?是其中一種常用的工具,它基于 ICMP 協議。
檢測網絡設備是否在線的方法
- ping 命令:
ping?命令通過發送 ICMP 回顯請求數據包到目標設備,并等待 ICMP 回顯應答數據包。如果設備在線且網絡連接正常,它會回復 ICMP 回顯應答數據包。ping?命令會顯示往返時間(RTT)和丟包率等信息,從而判斷設備是否在線。例如,在終端輸入?ping 192.168.1.1?來檢測 IP 地址為?192.168.1.1?的設備是否在線。 - ARP 掃描:ARP(Address Resolution Protocol)掃描通過發送 ARP 請求廣播包,請求目標 IP 地址對應的 MAC 地址。如果設備在線,它會回復 ARP 應答包,從而確定設備的 MAC 地址和在線狀態。例如,使用?
arp -a?命令可以查看本地的 ARP 緩存,其中包含已發現的設備的 IP 地址和 MAC 地址信息。 - 端口掃描:端口掃描工具(如 Nmap)通過嘗試連接目標設備的特定端口來檢測設備是否在線。如果端口開放,設備會響應連接請求;如果端口關閉或設備不在線,則不會響應。例如,使用?
nmap -p 80 192.168.1.1?來檢測 IP 地址為?192.168.1.1?的設備的 80 端口是否開放,從而判斷設備是否在線。 - SNMP 查詢:SNMP(Simple Network Management Protocol)是一種用于管理和監控網絡設備的協議。通過發送 SNMP 查詢請求到目標設備,獲取設備的狀態信息(如 CPU 使用率、內存使用率等),從而判斷設備是否在線。例如,使用 SNMP 客戶端工具(如 Net-SNMP)發送查詢請求到設備的 SNMP 代理,根據響應判斷設備的在線狀態。
ping 屬于什么協議
ping?基于 ICMP(Internet Control Message Protocol)協議。ICMP 是網絡層協議,主要用于在 IP 網絡中傳遞控制消息,如網絡可達性、網絡錯誤等。ping?使用 ICMP 的回顯請求和回顯應答消息來檢測目標設備是否在線。具體過程如下:
- 發送回顯請求:客戶端構造一個 ICMP 回顯請求數據包,包含標識符、序列號和一些數據(通常是時間戳)。客戶端將數據包發送到目標設備的 IP 地址。
- 接收回顯應答:如果目標設備在線且網絡連接正常,目標設備會接收到 ICMP 回顯請求數據包,并構造一個 ICMP 回顯應答數據包,包含相同的標識符和序列號,以及一些數據(如接收到的時間戳)。目標設備將回顯應答數據包發送回客戶端。
- 處理應答:客戶端接收到 ICMP 回顯應答數據包后,會檢查標識符和序列號是否與發送的請求匹配。如果匹配,客戶端會計算往返時間(RTT),并將結果顯示在終端上。
TCP 和 UDP 的特點、優劣及適用場景是什么?為什么 TCP 需要三次握手和四次揮手?
TCP(Transmission Control Protocol)和 UDP(User Datagram Protocol)是傳輸層的兩種主要協議,它們具有不同的特點、優劣和適用場景。
TCP 的特點、優劣及適用場景
特點:
- 面向連接:在數據傳輸前需要建立連接,傳輸完成后需要關閉連接。
- 可靠傳輸:通過序列號、確認應答和重傳機制保證數據的可靠傳輸。
- 流量控制:使用滑動窗口機制控制發送方的發送速度,避免接收方緩沖區溢出。
- 擁塞控制:通過慢啟動、擁塞避免等算法動態調整發送方的發送速率,防止網絡擁塞。
- 字節流服務:數據以字節流的形式傳輸,沒有消息邊界。
優點:
- 數據可靠:確保數據按順序到達接收方,丟失的數據會被重傳。
- 流量和擁塞控制:有效防止網絡擁塞和接收方緩沖區溢出。
- 連接管理:通過三次握手和四次揮手管理連接,確保連接的可靠性。
缺點:
- 開銷大:建立和關閉連接需要額外的開銷,傳輸數據時也需要攜帶序列號、確認應答等信息。
- 傳輸速度慢:由于需要等待確認應答,傳輸速度相對較慢。
適用場景:
- 文件傳輸:如 FTP(File Transfer Protocol),確保文件完整、無錯地傳輸。
- 電子郵件:如 SMTP(Simple Mail Transfer Protocol),保證郵件內容的可靠傳輸。
- 網頁瀏覽:如 HTTP(Hypertext Transfer Protocol),確保網頁數據的正確傳輸。
UDP 的特點、優劣及適用場景
特點:
- 無連接:不需要建立和關閉連接,直接發送數據報。
- 不可靠傳輸:不保證數據的可靠傳輸,可能會丟失、重復或亂序。
- 無流量和擁塞控制:發送方不考慮接收方的緩沖區狀態和網絡擁塞情況。
- 數據報服務:數據以數據報的形式傳輸,有消息邊界。
優點:
- 開銷小:不需要建立和關閉連接,數據報頭相對簡單,傳輸效率高。
- 傳輸速度快:無需等待確認應答,適合實時性要求高的應用。
缺點:
- 數據不可靠:可能會導致數據丟失、重復或亂序。
- 無流量和擁塞控制:可能會導致網絡擁塞和接收方緩沖區溢出。
適用場景:
- 實時應用:如 VoIP(Voice over IP)、視頻流,對實時性要求高,允許一定的數據丟失。
- DNS 查詢:如 DNS(Domain Name System)查詢,數據量小,對實時性要求高。
- 簡單請求 - 響應協議:如 SNMP(Simple Network Management Protocol),數據量小,不需要可靠傳輸。
為什么 TCP 需要三次握手和四次揮手?
三次握手:
TCP 三次握手的目的是為了在客戶端和服務器之間建立可靠的連接,確保雙方都具備收發數據的能力,同時避免舊的連接請求干擾新連接的建立。具體過程如下:
- 第一次握手:客戶端向服務器發送一個帶有 SYN(同步序列號)標志的 TCP 報文段,其中包含客戶端的初始序列號(假設為 client_isn)。這表示客戶端想要與服務器建立連接,并告知服務器自己的初始序列號。客戶端進入 SYN_SENT 狀態。
- 第二次握手:服務器接收到客戶端的 SYN 報文段后,向客戶端發送一個帶有 SYN 和 ACK(確認)標志的 TCP 報文段。其中 ACK 用于確認客戶端的 SYN,ACK 字段的值為 client_isn + 1,表示服務器已收到客戶端的連接請求;同時服務器也發送自己的初始序列號(假設為 server_isn)。服務器進入 SYN_RCVD 狀態。
- 第三次握手:客戶端接收到服務器的 SYN + ACK 報文段后,向服務器發送一個帶有 ACK 標志的 TCP 報文段,ACK 字段的值為 server_isn + 1,用于確認服務器的 SYN。客戶端進入 ESTABLISHED 狀態,服務器在收到該 ACK 報文段后也進入 ESTABLISHED 狀態,至此連接建立完成。
如果只有兩次握手,可能會出現以下問題:假設客戶端發送的第一個 SYN 報文段由于網絡延遲等原因在網絡中滯留,客戶端超時后重新發送 SYN 建立連接,完成數據傳輸后關閉連接。此時,滯留的 SYN 報文段到達服務器,服務器誤認為是客戶端的新連接請求,發送 SYN + ACK 進行響應,但客戶端此時已不再等待連接,導致服務器資源浪費。通過三次握手,可以有效避免這種情況。
四次揮手:
TCP 四次揮手用于在數據傳輸結束后關閉連接,確保雙方的數據都已完整傳輸且連接安全關閉。具體過程如下:
- 第一次揮手:客戶端向服務器發送一個帶有 FIN(結束標志)標志的 TCP 報文段,請求關閉連接,客戶端進入 FIN_WAIT_1 狀態。
- 第二次揮手:服務器接收到客戶端的 FIN 報文段后,向客戶端發送一個帶有 ACK 標志的 TCP 報文段,確認客戶端的關閉請求,服務器進入 CLOSE_WAIT 狀態。此時客戶端到服務器的連接關閉,但服務器到客戶端的連接仍然保持,服務器可能還有數據要發送給客戶端。
- 第三次揮手:當服務器數據發送完畢后,服務器向客戶端發送一個帶有 FIN 標志的 TCP 報文段,請求關閉服務器到客戶端的連接,服務器進入 LAST_ACK 狀態。
- 第四次揮手:客戶端接收到服務器的 FIN 報文段后,向服務器發送一個帶有 ACK 標志的 TCP 報文段,確認服務器的關閉請求,客戶端進入 TIME_WAIT 狀態。服務器接收到 ACK 后進入 CLOSED 狀態。客戶端在 TIME_WAIT 狀態等待一段時間(通常為 2 倍的最大段生命周期)后也進入 CLOSED 狀態,連接徹底關閉。
TCP 采用四次揮手是因為連接是全雙工的,數據可以在兩個方向上獨立傳輸。關閉連接時,每個方向都需要單獨關閉,先關閉一個方向的連接(客戶端到服務器),等待服務器數據傳輸完畢后再關閉另一個方向的連接(服務器到客戶端),確保雙方的數據都能完整傳輸,避免數據丟失。
找出子函數中 malloc 相關代碼的錯誤
以下是一些常見的在子函數中使用?malloc?可能出現的錯誤示例及分析:
- 未檢查?
malloc?的返回值:malloc?在內存分配失敗時會返回?NULL,如果不檢查返回值,后續對該指針的操作可能導致程序崩潰。
示例代碼:
void sub_function() {int *ptr = (int *)malloc(sizeof(int));*ptr = 10; // 未檢查malloc返回值,若分配失敗,這里會導致懸空指針引用
}
正確做法是在?malloc?后檢查返回值:
void sub_function() {int *ptr = (int *)malloc(sizeof(int));if (ptr == NULL) {// 處理內存分配失敗的情況,如打印錯誤信息并返回perror("malloc failed");return;}*ptr = 10; free(ptr);
}
- 內存泄漏:在子函數中分配內存后,沒有調用?
free?釋放內存,導致內存泄漏。
示例代碼:
void sub_function() {int *ptr = (int *)malloc(sizeof(int));// 進行一些操作// 未調用free釋放內存,內存泄漏
}
應在不需要該內存時調用?free?釋放:
void sub_function() {int *ptr = (int *)malloc(sizeof(int));// 進行一些操作free(ptr);
}
- 釋放已釋放的內存:多次調用?
free?釋放同一塊內存,這會導致未定義行為。
示例代碼:
void sub_function() {int *ptr = (int *)malloc(sizeof(int));free(ptr);free(ptr); // 第二次釋放已釋放的內存,產生未定義行為
}
確保每個內存塊只釋放一次。
4.?內存越界訪問:在使用?malloc?分配的內存時,訪問超出分配大小的內存,可能導致數據損壞和程序崩潰。
示例代碼:
void sub_function() {int *ptr = (int *)malloc(5 * sizeof(int));for (int i = 0; i < 10; i++) {ptr[i] = i; // 訪問超出分配大小的內存,越界訪問}free(ptr);
}
確保對內存的訪問在分配的范圍內。
5.?類型轉換錯誤:在?malloc?后進行類型轉換時出錯,可能導致錯誤的內存訪問。
示例代碼:
void sub_function() {char *ptr = (char *)malloc(10);int *int_ptr = (int *)ptr; // 錯誤的類型轉換,可能導致錯誤的內存訪問*int_ptr = 10;free(ptr);
}
確保類型轉換正確,符合內存中存儲的數據類型。
通過避免以上錯誤,可以正確使用?malloc?進行內存管理,確保程序的穩定性和可靠性。
C++11 的 STL 容器有哪些?簡述 vector 的底層實現、擴容原理及與 list 的區別。如何實現 vector 不擴容?
C++11 的 STL 容器包括序列容器(如 vector、list、deque)、關聯容器(如 map、set、multimap、multiset)和無序容器(如 unordered_map、unordered_set、unordered_multimap、unordered_multiset)等。
- vector 的底層實現:vector 是基于動態數組實現的,它在內存中分配一塊連續的空間來存儲元素。可以通過下標快速訪問元素,支持隨機訪問。
- vector 的擴容原理:當向 vector 中插入元素時,如果當前容器已滿,vector 會自動分配一塊更大的內存空間,通常是原來空間的兩倍(不同實現可能有所差異),然后將原來的元素復制到新的空間中,再釋放原來的內存空間。這樣可以保證在插入元素時,有足夠的空間來存儲,避免頻繁的內存分配和復制。
- vector 與 list 的區別:
- 內存結構:vector 的元素在內存中是連續存儲的,而 list 的元素是通過指針鏈接起來的,不要求內存連續。
- 隨機訪問:vector 支持快速的隨機訪問,時間復雜度為 O (1),可以直接通過下標訪問元素;list 不支持隨機訪問,訪問元素需要從鏈表頭或尾開始遍歷,時間復雜度為 O (n)。
- 插入和刪除操作:在 vector 中間插入或刪除元素時,需要移動后面的元素,時間復雜度為 O (n);在 list 中插入和刪除元素只需要修改指針,時間復雜度為 O (1),但如果要找到插入或刪除的位置,list 可能需要遍歷鏈表,這在某些情況下可能會比 vector 慢。
- 實現 vector 不擴容:可以在創建 vector 時,使用 reserve 函數預先分配足夠的空間,這樣在后續插入元素時,如果元素數量不超過預分配的空間,就不會發生擴容。例如:
#include <iostream>
#include <vector>int main() {std::vector<int> vec;vec.reserve(100); // 預先分配100個元素的空間// 這里可以插入不超過100個元素,不會觸發擴容for (int i = 0; i < 100; ++i) {vec.push_back(i);}return 0;
}
簡述 C++ 的繼承機制,結構體、類和聯合體的異同。
- C++ 的繼承機制:繼承是面向對象編程中的一種重要機制,它允許一個類(子類或派生類)繼承另一個類(父類或基類)的屬性和行為。子類可以繼承父類的成員變量和成員函數,并且可以在子類中對繼承的成員進行重寫或擴展。通過繼承,可以實現代碼的復用,提高程序的可維護性和可擴展性。在 C++ 中有三種繼承方式:公有繼承(public)、私有繼承(private)和保護繼承(protected)。不同的繼承方式決定了父類成員在子類中的訪問權限。例如,公有繼承時,父類的公有成員和保護成員在子類中仍然保持其原來的訪問屬性,而父類的私有成員在子類中不可直接訪問。
- 結構體、類和聯合體的異同:
- 相同點:結構體、類和聯合體都是 C++ 中用于自定義數據類型的方式,都可以包含成員變量和成員函數(結構體和聯合體中成員函數較少使用),都可以通過定義變量來創建對象。
- 不同點:
- 默認訪問權限:類的默認訪問權限是 private,結構體的默認訪問權限是 public,聯合體的成員默認都是 public。
- 內存布局:類和結構體的成員變量按照聲明的順序在內存中依次排列,每個成員都有自己獨立的內存空間;聯合體的所有成員共享同一塊內存空間,其大小取決于最大成員的大小,同一時刻只能有一個成員有效。
- 用途:類通常用于面向對象編程,封裝數據和行為,實現復雜的邏輯;結構體主要用于組織相關的數據,更側重于數據的存儲和管理;聯合體常用于需要在不同時刻使用不同類型數據,但又不想浪費過多內存空間的場景,例如在某些通信協議中,根據不同的標志位來解析數據,數據可能是不同的類型,但不會同時使用。
vector 是否為線程安全的數據類型?為什么?
vector 不是線程安全的數據類型。原因如下:
- 多個線程同時讀寫操作:當多個線程同時對 vector 進行讀寫操作時,可能會出現數據不一致的情況。例如,一個線程正在向 vector 中插入元素,而另一個線程同時在讀取 vector 中的元素,由于 vector 的插入操作可能會導致內存重新分配和元素移動,那么讀取線程可能會讀到未完全更新的數據,或者在元素移動過程中讀取到錯誤的元素。
- 迭代器失效問題:在多線程環境下,一個線程對 vector 進行插入或刪除操作可能會使其他線程中的迭代器失效。例如,一個線程通過迭代器遍歷 vector,而另一個線程在 vector 中間插入了一個元素,這可能導致迭代器所指向的位置發生變化,從而使迭代器失效,后續使用該迭代器可能會引發未定義行為。
- 沒有內置的同步機制:vector 本身并沒有提供內置的同步機制來保護其內部數據結構的訪問。不像一些專門的線程安全容器,如 std::vectorstd::mutex等,vector 沒有對多線程訪問進行任何的鎖保護或其他同步措施,所以在多線程環境下需要程序員自己通過加鎖等方式來保證對 vector 的訪問是安全的。
gdb 調試的常用方法有哪些?
gdb 是 GNU Debugger 的縮寫,是一款常用的調試工具,以下是一些常用的調試方法:
- 設置斷點:可以使用
break命令(簡寫為b)在程序的特定位置設置斷點。例如,b main會在main函數的入口處設置斷點,b file.c:10會在file.c文件的第 10 行設置斷點。當程序運行到斷點處時,會暫停執行,以便查看程序的狀態。 - 查看變量:使用
print命令(簡寫為p)可以查看變量的值。例如,p variable_name會打印出variable_name的值。還可以使用display命令設置在程序每次暫停時自動顯示某些變量的值,如display variable_name。 - 單步執行:使用
step命令(簡寫為s)可以進入函數內部單步執行,next命令(簡寫為n)則是不進入函數,直接執行下一條語句。這有助于跟蹤程序的執行流程,查看每一步的執行結果。 - 運行程序:使用
run命令(簡寫為r)來啟動程序運行,程序會在遇到斷點或運行結束時停止。可以在run命令后面跟上參數,例如r arg1 arg2,用于向程序傳遞命令行參數。 - 查看調用棧:當程序暫停時,可以使用
backtrace命令(簡寫為bt)查看當前的函數調用棧,了解程序是如何執行到當前位置的,包括調用的函數和函數的參數等信息。 - 修改變量值:可以使用
set variable命令在調試過程中修改變量的值。例如,set variable variable_name = new_value可以將variable_name的值修改為new_value,這對于模擬一些特定的條件或修復程序中的錯誤很有幫助。 - 繼續執行:使用
continue命令(簡寫為c)讓程序從當前斷點處繼續執行,直到遇到下一個斷點或程序結束。
簡述 mmap 原理及 MMU 的地址映射機制。
- mmap 原理:mmap 是一種內存映射技術,它將一個文件或其他對象映射到進程的地址空間中,使得進程可以像訪問內存一樣直接訪問文件內容,而不需要通過傳統的
read和write系統調用。其原理如下:- 系統調用:進程通過調用
mmap函數,告訴操作系統要將某個文件或設備的內存區域映射到自己的地址空間中,并指定映射的屬性,如是否可讀、可寫、可執行等。 - 內核處理:操作系統內核會在進程的虛擬地址空間中分配一段虛擬地址范圍,并建立起該虛擬地址與文件或設備物理內存之間的映射關系。這個映射關系是通過頁表等數據結構來維護的。
- 數據訪問:當進程訪問映射后的虛擬地址時,硬件的內存管理單元(MMU)會根據頁表將虛擬地址轉換為物理地址,從而實現對文件或設備內存的訪問。如果相應的物理頁面不在內存中,會觸發缺頁中斷,操作系統會負責將所需的頁面從磁盤等存儲設備加載到內存中。
- 系統調用:進程通過調用
- MMU 的地址映射機制:MMU 是計算機系統中用于管理內存地址轉換的硬件組件,其地址映射機制如下:
- 虛擬地址空間劃分:每個進程都有自己獨立的虛擬地址空間,虛擬地址空間被劃分為多個頁面,頁面大小通常是固定的,如 4KB 或 8KB 等。
- 頁表:操作系統維護著一個頁表,頁表中記錄了虛擬頁面與物理頁面之間的映射關系。每個頁表項包含了物理頁面的地址、訪問權限、是否在內存中(有效位)等信息。
- 地址轉換:當進程訪問一個虛擬地址時,MMU 會根據虛擬地址的頁號在頁表中查找對應的頁表項。如果頁表項的有效位為 1,表示該頁面在內存中,MMU 會將虛擬地址中的頁內偏移量與頁表項中的物理頁面地址相結合,得到物理地址,從而訪問內存中的數據。如果有效位為 0,表示該頁面不在內存中,會觸發缺頁中斷,由操作系統負責將頁面從磁盤加載到內存中,并更新頁表。
- 地址保護:MMU 還可以通過頁表項中的訪問權限位來實現對內存的訪問控制,例如限制進程對某些內存區域的讀寫權限,防止進程非法訪問其他進程的內存或操作系統的內核空間,從而保證系統的安全性和穩定性。
系統調用的整體流程是什么?
系統調用是用戶程序與操作系統內核之間的接口,其整體流程如下:
- 用戶態準備:用戶程序在用戶態下執行,當需要使用系統資源或執行一些特權操作時,會通過特定的系統調用函數發起請求。例如,在 C 語言中可以使用?
open?函數打開一個文件,此時會將相關參數(如文件名、打開模式等)準備好放在寄存器或棧中。 - 陷入內核態:用戶程序通過執行特定的指令(如在 x86 架構上是?
int 0x80?或?syscall?指令),觸發一個軟中斷,從而從用戶態切換到內核態。這個過程會保存當前用戶程序的上下文,包括程序計數器、寄存器值等,以便后續恢復。 - 內核處理:內核接收到系統調用請求后,根據系統調用號(在中斷向量表或系統調用表中索引)找到對應的內核函數來處理請求。例如對于?
open?系統調用,內核會執行與文件系統相關的代碼,檢查文件權限、查找文件節點等操作。 - 返回用戶態:內核完成系統調用處理后,將結果(如文件描述符、錯誤碼等)通過寄存器或其他約定的方式返回給用戶程序。然后恢復之前保存的用戶程序上下文,將程序計數器設置為系統調用后的下一條指令,從而使程序繼續在用戶態下執行。
了解頁表嗎?簡述其作用。
頁表是一種數據結構,用于實現虛擬地址到物理地址的映射,在現代操作系統的內存管理中起著關鍵作用。
- 地址映射:它將進程的虛擬地址空間劃分為若干個頁,同時將物理內存也劃分為同樣大小的頁框。頁表中記錄了每個虛擬頁對應的物理頁框號,通過查詢頁表,CPU 可以快速將虛擬地址轉換為物理地址,使得進程能夠訪問實際的物理內存。例如,當進程訪問一個虛擬地址時,CPU 會根據頁表中的映射關系找到對應的物理地址,從而讀取或寫入數據。
- 內存保護:頁表還可以用于實現內存保護機制。通過在頁表項中設置一些標志位,如只讀位、可執行位、用戶 / 內核態訪問位等,可以限制進程對內存的訪問權限。例如,將某些頁面設置為只讀,防止進程意外修改重要的數據;設置可執行位來控制哪些頁面可以執行代碼,增強系統的安全性。
- 內存管理輔助:操作系統可以根據頁表來了解內存的使用情況,進行內存的分配和回收。例如,當進程申請內存時,操作系統可以在頁表中查找空閑的頁框,并建立相應的映射;當進程釋放內存時,操作系統則可以更新頁表,將對應的頁框標記為可用。
如何解決程序崩潰問題?core dump 在什么情況下會出現?
解決程序崩潰問題可以采取以下步驟:
- 收集信息:首先要收集盡可能多的關于崩潰的信息,包括崩潰時的錯誤提示、程序的運行日志(如果有)、系統的相關信息(如操作系統版本、硬件信息等)。這些信息有助于定位問題的根源。
- 使用調試工具:利用調試工具如 GDB 來分析程序崩潰時的狀態。可以在程序崩潰后,使用 GDB 加載可執行文件和 core dump 文件(如果生成了),通過查看堆棧信息、變量值等來確定程序崩潰的位置和原因。例如,通過?
backtrace?命令可以查看函數調用棧,找到崩潰發生時正在執行的函數。 - 代碼審查:對可能導致崩潰的代碼區域進行仔細審查,檢查是否存在指針錯誤(如野指針、空指針引用)、數組越界、內存泄漏、邏輯錯誤等。特別要注意一些容易引發問題的操作,如動態內存分配和釋放、文件操作、多線程訪問等。
- 測試和重現:嘗試在不同的環境下重現崩潰問題,以確定是否是特定環境因素導致的。可以通過編寫單元測試或使用自動化測試工具來模擬各種情況,觀察程序是否會再次崩潰。如果能夠重現問題,就可以更方便地進行調試和驗證解決方案。
core dump 是當程序發生異常(如段錯誤、非法訪問內存等)導致崩潰時,操作系統將程序當時的內存映像、寄存器值等信息轉儲到一個文件中的過程。以下情況可能會出現 core dump:
- 內存訪問錯誤:當程序試圖訪問不存在的內存地址(如野指針訪問)、訪問沒有權限的內存區域(如對只讀內存進行寫操作)或者數組越界訪問時,可能會觸發 core dump。
- 程序運行錯誤:例如除零錯誤、無效的系統調用、使用未初始化的指針等,這些錯誤會導致程序處于異常狀態,從而引發 core dump。
- 系統資源耗盡:當程序耗盡系統資源,如內存不足、文件描述符用完等,也可能導致系統終止程序并生成 core dump。
什么是 PendSV?哪些情況會觸發 PendSV?
PendSV(可掛起的系統服務調用)是一種由 Cortex - M 系列處理器提供的中斷機制,用于實現上下文切換等操作。
- 低優先級中斷:PendSV 是一種低優先級的中斷,它會在其他高優先級中斷處理完成后才被執行。這使得它適合用于一些不緊急但又需要在合適時機執行的任務,比如任務切換。
- 上下文切換:當操作系統需要進行任務切換時,會觸發 PendSV。例如,當一個任務的時間片用完,或者有更高優先級的任務就緒時,操作系統會設置 PendSV 中斷請求,然后在合適的時機(通常是當前正在執行的任務進入空閑狀態或者完成了關鍵操作),PendSV 中斷會被響應,從而執行任務切換的代碼,保存當前任務的上下文,并恢復下一個要執行任務的上下文。
- 異常返回時觸發:在一些情況下,當異常處理完成并返回時,如果發現有 PendSV 中斷等待處理,那么在返回后會立即執行 PendSV。這確保了上下文切換能夠及時進行,不會因為其他中斷的干擾而延遲太久。
為什么任務切換選用 PendSV 而非定時器中斷?
選用 PendSV 而非定時器中斷進行任務切換主要有以下原因:
- 優先級和時機控制:PendSV 是低優先級中斷,可以在其他高優先級中斷處理完之后再執行,這樣能夠保證任務切換不會打斷關鍵的中斷處理過程,確保系統的實時性和穩定性。而定時器中斷的優先級相對較高,如果直接用定時器中斷來進行任務切換,可能會在一些重要的中斷處理過程中被頻繁打斷,導致關鍵任務不能及時完成。
- 精確的切換時機:任務切換需要在一個任務執行完關鍵操作或者進入空閑狀態時進行,以保證系統的一致性和數據的完整性。PendSV 可以由操作系統根據任務的狀態來主動觸發,能夠精確地控制任務切換的時機。相比之下,定時器中斷是按照固定的時間間隔觸發,可能在任務執行到一半時就觸發切換,這可能會導致數據不一致等問題。
- 減少中斷開銷:定時器中斷會周期性地觸發,無論系統是否需要進行任務切換。而 PendSV 只有在需要進行任務切換時才會被觸發,這樣可以減少不必要的中斷開銷,提高系統的效率。特別是在一些對實時性要求較高的系統中,過多的定時器中斷可能會占用大量的 CPU 時間,影響系統的整體性能。
- 與硬件的協同性:PendSV 與 Cortex - M 系列處理器的架構緊密結合,能夠更好地利用硬件特性來實現高效的任務切換。例如,它可以利用處理器的寄存器保存和恢復機制,快速地完成上下文切換操作,而不需要額外的復雜處理。
如何使用定時器中斷?
使用定時器中斷一般需要以下步驟:
- 初始化定時器:首先要對定時器進行配置,包括設置定時器的時鐘源、預分頻系數、計數模式(向上計數、向下計數或中心對齊計數)等參數。例如,在 STM32 微控制器中,可以通過寄存器配置定時器的 PSC(預分頻器)和 ARR(自動重裝載值)來設置定時器的溢出時間。
- 設置中斷參數:配置定時器的中斷觸發條件,如定時器溢出時觸發中斷。同時,要設置中斷優先級,確保定時器中斷在系統中的優先級符合設計要求。在一些處理器中,還需要使能定時器的中斷輸出。
- 編寫中斷服務函數:編寫定時器中斷服務函數,當定時器中斷觸發時,系統會自動跳轉到該函數執行。在中斷服務函數中,需要清除中斷標志位,以防止重復觸發中斷。同時,可以在中斷服務函數中實現需要定時執行的任務,如更新計數器、采集傳感器數據等。
- 使能定時器和中斷:完成上述配置后,使能定時器開始計數,并使能相應的中斷。這樣,當定時器滿足中斷觸發條件時,就會執行中斷服務函數。
以下是一個簡單的示例代碼,展示了如何在 STM32 上使用定時器中斷:
#include "stm32f10x.h"void TIM3_Configuration(void) {TIM_TimeBaseInitTypeDef TIM_TimeBaseStructure;NVIC_InitTypeDef NVIC_InitStructure;// 使能定時器3的時鐘RCC_APB1PeriphClockCmd(RCC_APB1Periph_TIM3, ENABLE);// 配置定時器3TIM_TimeBaseStructure.TIM_Period = 999; // 自動重裝載值TIM_TimeBaseStructure.TIM_Prescaler = 7199; // 預分頻系數TIM_TimeBaseStructure.TIM_ClockDivision = 0;TIM_TimeBaseStructure.TIM_CounterMode = TIM_CounterMode_Up;TIM_TimeBaseInit(TIM3, &TIM_TimeBaseStructure);// 使能定時器3的更新中斷TIM_ITConfig(TIM3, TIM_IT_Update, ENABLE);// 配置中斷優先級NVIC_InitStructure.NVIC_IRQChannel = TIM3_IRQn;NVIC_InitStructure.NVIC_IRQChannelPreemptionPriority = 0;NVIC_InitStructure.NVIC_IRQChannelSubPriority = 0;NVIC_InitStructure.NVIC_IRQChannelCmd = ENABLE;NVIC_Init(&NVIC_InitStructure);// 使能定時器3TIM_Cmd(TIM3, ENABLE);
}// 定時器3中斷服務函數
void TIM3_IRQHandler(void) {if (TIM_GetITStatus(TIM3, TIM_IT_Update) != RESET) {// 清除中斷標志位TIM_ClearITPendingBit(TIM3, TIM_IT_Update);// 在這里執行定時任務,例如更新LED狀態GPIO_WriteBit(GPIOC, GPIO_Pin_13, (BitAction)(1 - GPIO_ReadOutputDataBit(GPIOC, GPIO_Pin_13)));}
}int main(void) {// 初始化GPIO,用于控制LEDGPIO_InitTypeDef GPIO_InitStructure;RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOC, ENABLE);GPIO_InitStructure.GPIO_Pin = GPIO_Pin_13;GPIO_InitStructure.GPIO_Mode = GPIO_Mode_Out_PP;GPIO_InitStructure.GPIO_Speed = GPIO_Speed_50MHz;GPIO_Init(GPIOC, &GPIO_InitStructure);// 初始化定時器3TIM3_Configuration();while (1) {// 主循環可以執行其他任務}
}
任務切換時,中斷處理函數需要完成哪些操作?
任務切換時,中斷處理函數需要完成以下操作:
- 保存當前任務上下文:將當前正在執行任務的寄存器狀態(如通用寄存器、程序計數器、狀態寄存器等)保存到該任務的堆棧中。這樣,當該任務下次被調度執行時,能夠恢復到之前的執行狀態。保存上下文的操作需要按照處理器的架構和寄存器約定進行,確保所有重要的寄存器值都被正確保存。
- 選擇下一個要執行的任務:根據任務調度算法,從中斷處理函數內部或者通過調用調度器函數來選擇下一個要執行的任務。任務調度算法可以基于優先級、時間片輪轉等策略,確保系統資源合理分配。
- 恢復下一個任務的上下文:從下一個要執行任務的堆棧中恢復之前保存的寄存器狀態,包括程序計數器、通用寄存器等。這樣,當從中斷返回時,處理器將從恢復的程序計數器地址開始執行下一個任務的代碼。
- 更新任務控制塊信息:更新任務的狀態信息,如將當前任務的狀態標記為就緒或阻塞,將下一個要執行任務的狀態標記為運行。同時,記錄任務的執行時間、優先級等信息,以便后續調度決策。
- 觸發上下文切換:通過特定的指令或操作,觸發處理器從當前任務切換到下一個任務。在一些處理器架構中,可能需要設置特定的寄存器或標志位來指示上下文切換的發生。
什么是設計模式?你用過哪些設計模式?
設計模式是指在軟件開發過程中,針對反復出現的問題所總結歸納出的通用解決方案。它是一種經過驗證的、可復用的設計理念,可以幫助開發者更高效地構建軟件系統,提高代碼的可維護性、可擴展性和可復用性。
常見的設計模式包括:
- 單例模式:確保一個類只有一個實例,并提供一個全局訪問點。例如,在嵌入式系統中,可能需要一個全局的配置管理器,使用單例模式可以確保整個系統中只有一個配置管理器實例,避免資源沖突和數據不一致。
- 工廠模式:定義一個創建對象的接口,讓子類決定實例化哪個類。工廠模式可以將對象的創建和使用分離,提高代碼的靈活性。例如,在一個圖形繪制系統中,可以使用工廠模式根據不同的參數創建不同類型的圖形對象。
- 觀察者模式:定義對象間的一種一對多的依賴關系,當一個對象的狀態發生改變時,所有依賴它的對象都會得到通知并自動更新。這種模式常用于事件處理系統,如 GUI 框架中的事件監聽機制。
- 狀態模式:允許一個對象在其內部狀態改變時改變它的行為,對象看起來似乎修改了它的類。狀態模式可以將復雜的狀態邏輯封裝在不同的狀態類中,使代碼更加清晰和易于維護。例如,在一個電梯控制系統中,可以使用狀態模式來表示電梯的不同狀態(如上升、下降、停止等),并根據當前狀態執行相應的操作。
Linux 環境下搭建 Server/Client 需要哪些步驟?涉及哪些系統調用?
在 Linux 環境下搭建 Server/Client 需要以下步驟:
- 服務器端步驟:
- 創建套接字:使用
?socket系統調用創建一個套接字,指定協議族(如 AF_INET 表示 IPv4)、套接字類型(如 SOCK_STREAM 表示 TCP)和協議(通常為 0,表示默認協議)。 - 綁定地址:使用
?bind系統調用將套接字與一個特定的 IP 地址和端口號綁定,以便客戶端能夠連接到該地址和端口。 - 監聽連接:使用
?listen系統調用將套接字設置為監聽狀態,準備接受客戶端的連接請求。可以指定一個隊列長度,表示最多可以同時等待處理的連接請求數量。 - 接受連接:使用
?accept系統調用接受客戶端的連接請求,并返回一個新的套接字,用于與該客戶端進行通信。 - 數據傳輸:使用
?read和?write系統調用在新的套接字上進行數據的讀取和寫入,與客戶端進行通信。 - 關閉套接字:通信結束后,使用
?close系統調用關閉套接字,釋放系統資源。
- 創建套接字:使用
- 客戶端步驟:
- 創建套接字:同樣使用
?socket系統調用創建一個套接字。 - 連接服務器:使用
?connect系統調用將套接字連接到服務器的 IP 地址和端口號。 - 數據傳輸:使用
?write和?read系統調用在套接字上進行數據的寫入和讀取,與服務器進行通信。 - 關閉套接字:通信結束后,使用
?close系統調用關閉套接字。
- 創建套接字:同樣使用
HTTP 和 HTTPS 的端口號分別是什么?
HTTP 的默認端口號是 80,而 HTTPS 的默認端口號是 443。這兩個端口號是互聯網上廣泛使用的標準端口號,用于標識不同的服務。當客戶端訪問一個網站時,如果使用的是 HTTP 協議,通常會默認連接到服務器的 80 端口;如果使用的是 HTTPS 協議,則會默認連接到服務器的 443 端口。服務器需要在相應的端口上監聽客戶端的連接請求,以便提供對應的服務。例如,Web 服務器(如 Apache、Nginx 等)通常會配置為在 80 端口提供 HTTP 服務,在 443 端口提供 HTTPS 服務。
HTTPS 如何保證安全性?它基于 TCP 協議嗎?
HTTPS 通過以下方式保證安全性:
- 加密傳輸:采用 SSL/TLS 協議對數據進行加密。在連接建立時,客戶端和服務器會協商加密算法和密鑰,之后數據在傳輸過程中被加密,即使被截取也難以破解內容。例如,瀏覽器與服務器之間傳輸的用戶登錄信息、信用卡號等敏感數據,經過加密后,第三方無法獲取其真實內容。
- 身份驗證:服務器向客戶端提供數字證書,客戶端可以驗證服務器的身份是否合法,確保連接到的是真實的服務器,防止中間人攻擊。比如,用戶訪問銀行網站時,瀏覽器會驗證銀行服務器的證書,確認其為合法的銀行網站,而非假冒站點。
- 數據完整性保護:使用消息認證碼(MAC)等技術,對傳輸的數據進行完整性校驗,確保數據在傳輸過程中沒有被篡改。一旦數據被篡改,接收方能夠檢測到并拒絕接受。
HTTPS 是基于 TCP 協議的。HTTPS 在 TCP 之上建立連接,先通過 TCP 的三次握手建立連接,確保網絡連接的可靠性。然后在這個連接之上,利用 SSL/TLS 協議進行加密和身份驗證等操作,再進行數據傳輸。這樣既利用了 TCP 的可靠傳輸特性,又通過 SSL/TLS 實現了安全傳輸。
TCP 的流量控制和擁塞控制機制有哪些?
- 流量控制機制:
- 滑動窗口協議:發送方和接收方都有一個緩存窗口,接收方通過向發送方通告自己的接收窗口大小,來控制發送方的發送速率。發送方根據接收方通告的窗口大小,在不超過該窗口的范圍內發送數據。例如,接收方的接收窗口為 1000 字節,發送方就會在未收到新的窗口通告前,最多發送 1000 字節的數據。當接收方處理數據的速度變慢時,會減小通告窗口,發送方隨之降低發送速率,避免數據丟失。
- 糊涂窗口綜合征預防:接收方在緩存有足夠空間或能一次性處理較大數據塊之前,不會通告小的窗口;發送方在收到較大的窗口通告或數據量達到一定程度之前,不會發送小的數據段,以此提高傳輸效率。
- 擁塞控制機制:
- 慢啟動:在連接建立初期或出現擁塞后恢復時,發送方先以較小的速率發送數據,然后逐漸增加發送速率,呈指數增長。比如,初始時發送一個數據段,收到確認后發送兩個數據段,再收到確認后發送四個數據段,以此類推,快速探測網絡的承載能力。
- 擁塞避免:當慢啟動達到一定閾值后,進入擁塞避免階段,發送方的發送速率不再呈指數增長,而是線性增長,每次收到確認后只增加一個數據段的發送量,以避免網絡擁塞。
- 快重傳:當接收方發現有數據丟失時,會立即向發送方發送重復的確認報文,發送方只要收到三個相同的確認報文,就會認為該數據段丟失,不等超時就重新發送該數據段,加快數據的重傳,提高傳輸效率。
- 快恢復:在快重傳之后,發送方不進行慢啟動,而是將擁塞窗口大小減半,然后進入擁塞避免階段,繼續線性增加發送速率,以更快地恢復數據傳輸,減少因擁塞導致的傳輸延遲。










:Pod間偶發超時問題排查)

)






