提示詞工程原理
N-gram:通過統計,計算N個詞共同出現的概率,從而預測下一個詞是什么。
深度學習模型:有多層神經網絡組成,可以自動從數據中學習特征,讓模型通過不斷地自我學習不斷成長,直到模型的反饋內容符合我們的預期。
如何編寫提示詞
提示詞(prompt)
是指在使用大模型時,向型提供的一些指令或問題。這些指令作為模型的輸入,引導模型產生所需要的輸出。例如,在生成文本時,Prompt可能是一個問題或者一個句子開始的部分,模型需要根據這個提示來生成接下來的內容。簡單來說,在使用大模型時,我們輸入的內容,不管是問題,還是直接輸入一個文件,都屬于提示詞。
使用提示詞時出現偏差(準確性,相關性,偏見性)的原因
1、模型自身的問題:由于模型是根據訓練數據來學習的,如果訓練數據存在偏見或質量問題,那么模型生成的內容也可能會受到這些問題的影響。此外,模型有時也會產生與提示不相關的內容,或者理解不準確,從而導致輸出結果的質量下降。
2、使用者問題:提問沒有明顯的邏輯結構,缺乏系統性,依賴個人經驗,沒有方法,只有語法;分享給別人時,在沒有溝通過或者一起了解過相關項目內容時無法理解,也無法對其進行有效的修改;沒有學習過如何編寫有效的提示詞。
prompt工程
旨在獲取這些提示并幫助模型在其輸出中實現高準確度和相關性,掌握提示工程相關技能將有助于用戶更好地了解大型語言模型的能力和局限性。特別地,矢量數據庫(以數字的方式將知識存儲起來,比如把“蘋果”變成[0,1,4,5,...],能幫助大模型在搜索知識時可以快速找到類似的內容,因為其保存的數字結構是類似的)、agent和promptpipeline (把簡單提問加工成模型能看懂的“超級提示詞”,類似于在輸出反饋內容之前“打了個小抄”,讓模型能夠更好理解詞語,比如提問“講個笑話”,系統會自動加工為“你是個喜劇大師,用中文講個關于程序員的冷笑話,不超過3句話”)已經被用作在對話中,作為向 LLM 提供相關上下文數據的途徑。
編寫prompt工程的注意點
Prompt格式:確定prompt的結構和格式,例如,問題形式、述形式、關鍵詞形式等。
Prompt內容:選擇合適的詞語、短語或問題,以確保模型理解用戶的意圖。
Prompt上下文:考慮前文或上下文信息,以確保模型的回應與先前的對話或情境相關。
Prompt編寫技巧:使用清晰、簡潔和明了的語言編寫prompt,以準確傳達用戶的需求。
Prompt優化:在嘗試不同prompt后,根據結果對prompt進行調整和優化,以獲得更滿意的回應。
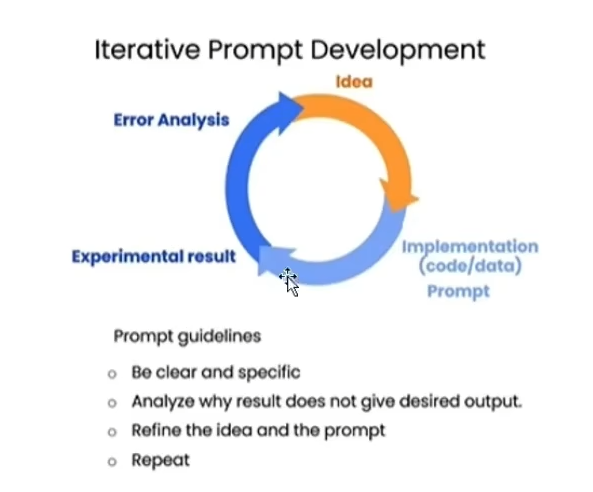
prompt工程的編寫過程
Prompt 工程 的過程和機器學習的過程類似,都需要經過選代的過程。“從一個想法出發,通過一個基礎的實現,在接近真實數據的測試集合上完成驗證,分析失敗的case;不斷重復這個過程,直到100%滿足的你的場景。
構建prompt的原則
1、清晰和明確的指令:模型的提示詞需要清晰明確,避免模糊性和歧義。清晰性意味著提示詞要直接表達出想要模型執行的任務,比如“生成一篇關于氣候變化影響的文章”,而不是僅僅說“寫一篇文章”。明確性則是指要具體說明任務的細節比如文章的風格、長度、包含的關鍵點等。這樣,模型就可以更精確地理解任務要求,并產生與之相匹配的輸出。
2、給模型思考的時間:這里的“時間”是比喻性的,意味著應該給模型足夠的信息,讓它能夠基于充足的上下文來產生回應。這可能涉及到提供額外的描述,或者在復雜任務中分步驟給信息去引導模型。
在實踐中,我們可以通過提供背景信息、上下文環境、以及相關細節來實現。例如,如果我們要模型續寫一篇故事,可以先提供故事的背景信息人物關系和已發生的事件等,讓模型有足夠的“思考時間”,從而能夠在現有信息的基礎上進行合理的創作。而另一類實踐場景,則是我們要充分引導大模型的思考路徑,讓模型沿著正確的道路得出正確的答案,即分步驟引導大模型思考。
prompt結構
一般來說,我們寫的prompt要有背景(比如我的角色或身份是什么,我掌握了什么知識,我要完成什么任務),思考過程(一共要分為哪幾個步驟去做,在這個過程中應該對每個步驟進行評估或者需要往哪個方向思考答案,并給出一個示例)和數據(可以是句子,簡單的提問或者是文件或文章),輸出的方式在沒有硬性要求下一般都是以文本的形式進行輸出,你也可以要求以json的格式(有時候存在輸出的內容是要被拿取給后端使用的,以json的格式可以讓后端接口直接使用)輸出內容。
學習來源于B站教程:【基礎篇】02.提示詞深度講解_嗶哩嗶哩_bilibili

)





)
——設計思路、實現步驟、代碼實現)




(已不推薦使用deprecated,建議使用img、video、audio標簽))





