目錄
一 數據結構,相關概念
1. 數據結構:
2. 數據(Data):
3. 數據元素(Data Element):
4. 數據項:
5. 數據對象(Data Object):
6. 容器(container):
7. 結點(Node):
8. 迭代器(iterator):
9. 前驅 節點:
10. 后繼 節點:
二 數據結構分類
1. 邏輯結構分類
1. 集合結構
2. 線性結構
3. 樹型結構
4. 圖狀結構或網狀結構
2. 物理結構分類?
1. 順序存儲結構
2. 鏈接存儲結構
3. 數據索引存儲結構
4. 數據散列存儲結構 hash
5. 總結?
性能對比與分析
3. 總結
邏輯結構與物理結構的對應關系
一 數據結構,相關概念
1. 數據結構:
是相互之間存在一種或多種特定關系的數據元素的集合。不同的數據元素之間不是獨立的,而是存在特定的關系,我們將這些關系成為結構。
2. 數據(Data):
是對信息的一種符號表示。在計算機科學中是指所有能輸入到計算機中并被計算機程序處理的符號的總稱。描述客觀事物的符號,是計算機中可以操作的對象,是能被計算機識別,并輸入給計算機處理的符號集合。(數據不僅包含整型、實型等數值類型,還包括字符及聲音、圖像、視頻等非數值類型。)
3. 數據元素(Data Element):
是數據的基本單位在計算機程序中通常作為一個整體進行考慮和處理。一個數據元素可由若干個數據項組成。
4. 數據項:
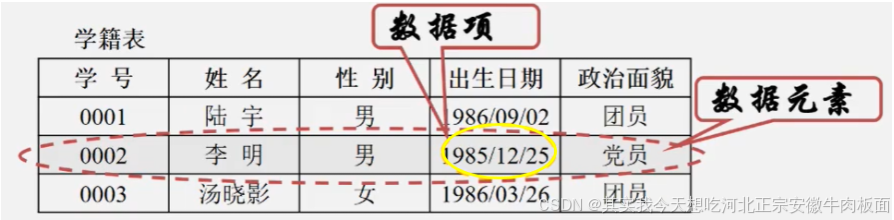
一個數據元素可以由若干個數據項組成。(比如:人可以有眼耳口鼻這些數據項)。數據項是數據不可分割的最小單位。
5. 數據對象(Data Object):
是性質相同的數據元素的集合。是數據的一個子集。
6. 容器(container):
裝入數據元素的外部對象。一般是先有數據關系,再有可以裝入數據元素的容器,一個容器對應一個數據元素,可以把它想象成一個紙箱。
7. 結點(Node):
數據關系中,用于建立關系支撐的連接點,比如路由器網關,樹的分叉;與節點接近但有所區別。
8. 迭代器(iterator):
一個超級接口! 是可以遍歷集合的對象,為各種容器提供了公共的操作接口。
9. 前驅 節點:
數據值小于節點n,且與節點n數值最接近的節點(記為節點m)
10. 后繼 節點:
數據值大于節點n,且數值最接近節點n的第一個節點(記為節點m)
11. 檢索(索引 index):
根據索引快速的找到數據元素;
12. 遍歷:
將數據對象中的所有數據元素全部訪問一遍;
13. 動態擴容:
數據對象中的數據元素數量發生變化。
二 數據結構分類
數據結構是計算機中組織、管理和存儲數據的方式,分為?邏輯結構?和?物理結構(存儲結構)。二者的核心區別在于:
邏輯結構:關注數據元素之間的抽象關系(如順序、層次、連接等),與計算機存儲無關。
物理結構:數據在內存中的實際存儲方式(如連續存儲、分散存儲),直接影響程序性能。
1. 邏輯結構分類
邏輯結構的分類與特點
邏輯結構類型 描述 典型示例 應用場景 線性結構 數據元素間呈一對一關系,形成序列。 數組、鏈表、棧、隊列 順序操作(如遍歷、排序) 樹形結構 數據元素間呈一對多關系,形成層次結構。 二叉樹、B樹、堆、字典樹 文件系統、數據庫索引、決策模型 圖結構 數據元素間呈多對多關系,形成網絡結構。 有向圖、無向圖、鄰接表/矩陣 社交網絡、路徑規劃、依賴分析 集合結構 數據元素間無明確邏輯關系,僅屬于同一集合。 哈希集合、無序列表 去重、成員檢測、數學集合運算 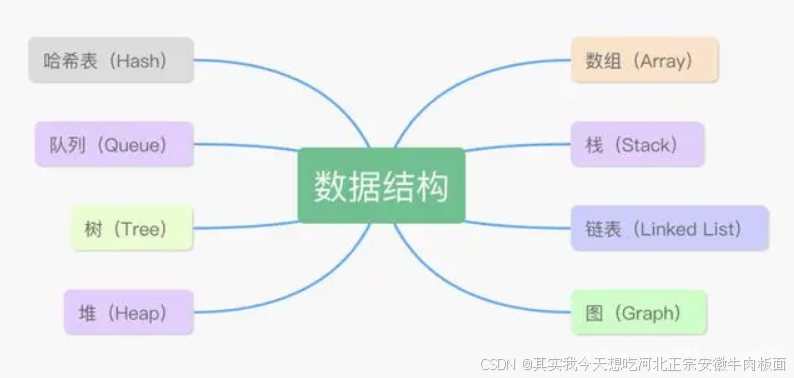
1. 集合結構

定義:數據元素之間無明確邏輯關系,僅屬于同一集合。
特點:
關注元素的唯一性和存在性,而非順序或關聯。
核心操作:插入、刪除、查找。
常見類型:
哈希集合(HashSet):基于哈希表實現,查找時間復雜度O(1)。
示例:Python的
set類型。樹集合(TreeSet):基于平衡二叉搜索樹實現,元素有序。
示例:Java的
TreeSet。應用場景:
數據去重:快速檢測重復元素。
成員檢測:判斷元素是否存在于集合中。
集合運算:并集、交集、差集(如數據庫查詢優化)。
2. 線性結構

定義:數據元素之間存在一對一的順序關系,形成線性序列。每個元素有且僅有一個直接前驅和一個直接后繼。
特點:
元素按順序排列,無分支。
支持遍歷、插入、刪除等操作。
常見類型:
數組:連續內存存儲,支持快速隨機訪問。
示例:
int arr[5] = {1, 2, 3, 4, 5};鏈表:通過指針鏈接非連續內存塊,支持動態擴展。
示例:單鏈表、雙向鏈表。
棧(Stack):后進先出(LIFO),如函數調用棧。
操作:
push(入棧)、pop(出棧)。隊列(Queue):先進先出(FIFO),如任務調度隊列。
操作:
enqueue(入隊)、dequeue(出隊)。應用場景:
數組:需要快速訪問元素的場景(如排序)。
鏈表:頻繁插入/刪除的場景(如實現隊列)。
棧:撤銷操作、表達式求值。
隊列:消息隊列、打印任務管理。
3. 樹型結構
定義:數據元素之間存在一對多的層次關系,形成樹狀層級結構。
特點:
每個節點最多有一個父節點,但可以有多個子節點。
具有唯一的根節點,葉子節點無子節點。
常見類型:
二叉樹:每個節點最多有兩個子節點。
示例:二叉搜索樹(BST)、平衡二叉樹(AVL樹)。
B樹/B+樹:多路平衡查找樹,用于數據庫索引。
堆(Heap):完全二叉樹,支持快速插入和刪除最值。
類型:最大堆、最小堆。
字典樹(Trie):用于字符串前綴匹配,如輸入法提示。
應用場景:
文件系統:目錄與子目錄的層次關系。
數據庫索引:B+樹加速數據查詢。
哈夫曼編碼:壓縮算法中構建最優前綴樹。
4. 圖狀結構或網狀結構
定義:數據元素之間可存在多對多的復雜關系,形成網絡結構。
特點:
頂點(節點)表示實體,邊表示實體間的關系。
邊可帶權重(如距離、成本)或方向(有向圖/無向圖)。
常見類型:
鄰接矩陣:二維數組表示頂點間連接關系。
空間復雜度:O(V2),適合稠密圖。
鄰接表:鏈表數組存儲每個頂點的鄰居。
空間復雜度:O(V + E),適合稀疏圖。
有向圖:邊有方向(如微博關注關系)。
無向圖:邊無方向(如微信好友關系)。
應用場景:
社交網絡:用戶之間的關注/好友關系。
路徑規劃:Dijkstra算法求最短路徑。
推薦系統:基于圖的關系挖掘(如PageRank)。
2. 物理結構分類?
物理結構的分類與特點
物理結構類型 描述 實現方式 優缺點 適用邏輯結構 順序存儲 數據元素在內存中連續存儲。 數組、動態數組 優點:隨機訪問快;
缺點:插入/刪除效率低線性結構(數組、棧、隊列) 鏈式存儲 數據元素通過指針鏈接,存儲位置不連續。 單鏈表、雙向鏈表、樹節點指針 優點:插入/刪除靈活;
缺點:訪問效率低線性結構、樹、圖 索引存儲 通過索引表記錄數據地址,數據本身可分散存儲。 數據庫索引、文件系統 優點:快速定位;
缺點:索引維護開銷集合、線性結構 散列存儲 利用哈希函數計算存儲位置,數據按計算結果存放。 哈希表、布隆過濾器 優點:查找極快;
缺點:哈希沖突處理集合、鍵值對存儲 總結對比
存儲結構 C語言實現 時間復雜度(插入/查找) 適用場景 順序存儲 數組 插入/刪除 O(n),訪問 O(1) 靜態數據、高頻隨機訪問 鏈接存儲 鏈表 插入/刪除 O(1),訪問 O(n) 動態數據、頻繁修改 索引存儲 結構體數組 + 索引表 插入 O(n log n),查找 O(log n) 數據庫、文件系統 散列存儲 哈希表 + 鏈地址法 插入/查找 O(1)(平均) 緩存、字典、去重
1. 順序存儲結構
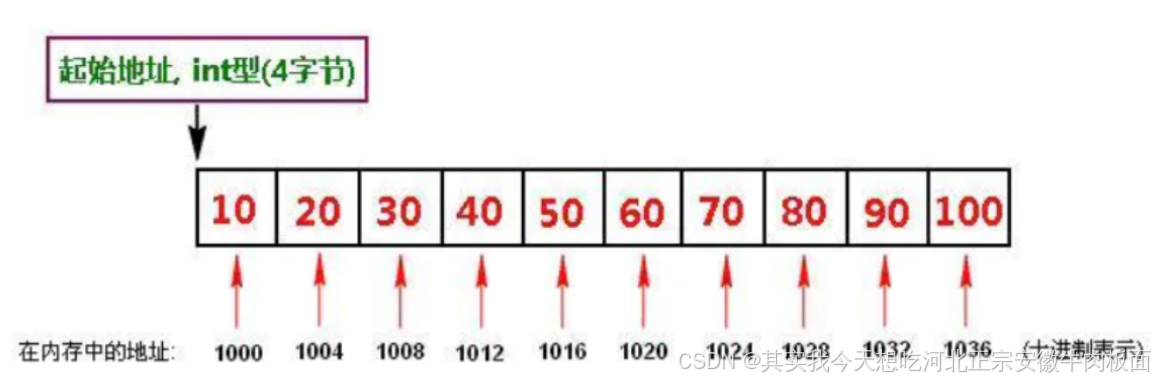
定義:數據元素在內存中按順序連續存放,通過元素下標直接訪問。
特點:
物理連續:元素地址連續,無額外指針開銷。
隨機訪問:通過下標直接定位元素,時間復雜度為 O(1)。
特性 說明 優點 訪問速度快;內存利用率高(無指針開銷)。 缺點 插入/刪除需移動大量元素,效率低;容量固定(動態數組擴容有額外成本)。 實現方式 數組、動態數組(如 C++ 的? vector)。適用場景 數據量固定或變化小,需頻繁隨機訪問的場景(如排序、矩陣運算)。 示例:
int arr[5] = {1, 2, 3, 4, 5}; // 定義數組 printf("%d", arr[2]); // 直接訪問第3個元素(輸出:3)
2. 鏈接存儲結構
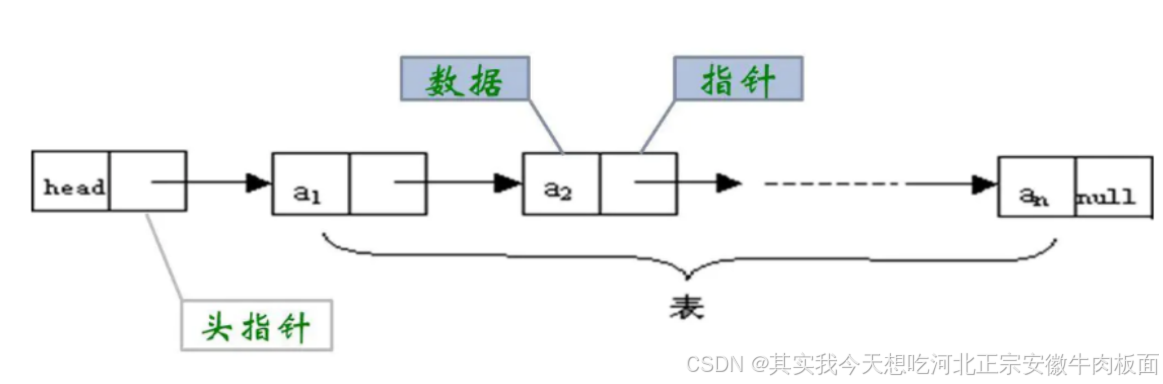
定義:數據元素通過指針鏈接,存儲位置不連續。
特點:
動態分配:內存按需分配,支持靈活擴展。
鏈式訪問:通過指針跳轉訪問元素,時間復雜度為 O(n)。
特性 說明 優點 插入/刪除效率高(僅修改指針);無需預先分配內存。 缺點 訪問效率低(需遍歷);指針占用額外內存。 實現方式 單鏈表、雙向鏈表、樹結構(如二叉樹的指針實現)。 適用場景 頻繁插入/刪除的場景(如隊列、圖結構)。 示例:
struct Node { int data; struct Node *next; }; // 定義節點 struct Node a = {10}, b = {20}; a.next = &b; // 手動鏈接兩個節點 printf("%d", a.next->data); // 輸出:20
3. 數據索引存儲結構
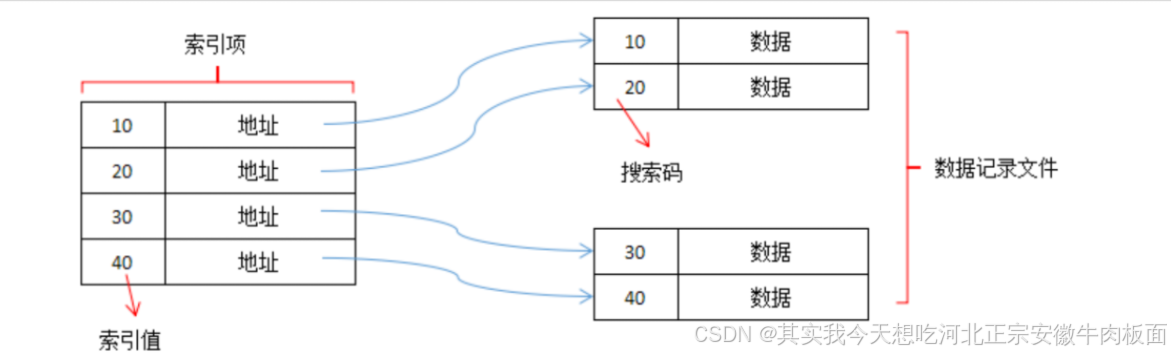
定義:通過索引表記錄數據地址,數據本身可分散存儲。
特點:
快速定位:索引表存儲鍵與物理地址的映射。
分層管理:索引與數據分離,需維護索引一致性。
特性 說明 優點 支持高效范圍查詢;適合大規模數據管理。 缺點 索引維護復雜(增刪需同步更新);存儲開銷大(需額外索引空間)。 實現方式 B樹、B+樹(數據庫索引)、文件分配表(FAT)。 適用場景 數據庫索引、文件系統、有序數據查詢(如按范圍搜索)。 示例:
int data[3] = {100, 200, 300}, index[3] = {0, 1, 2}; // 數據與索引表 printf("%d", data[index[1]]); // 通過索引訪問(輸出:200)
4. 數據散列存儲結構 hash
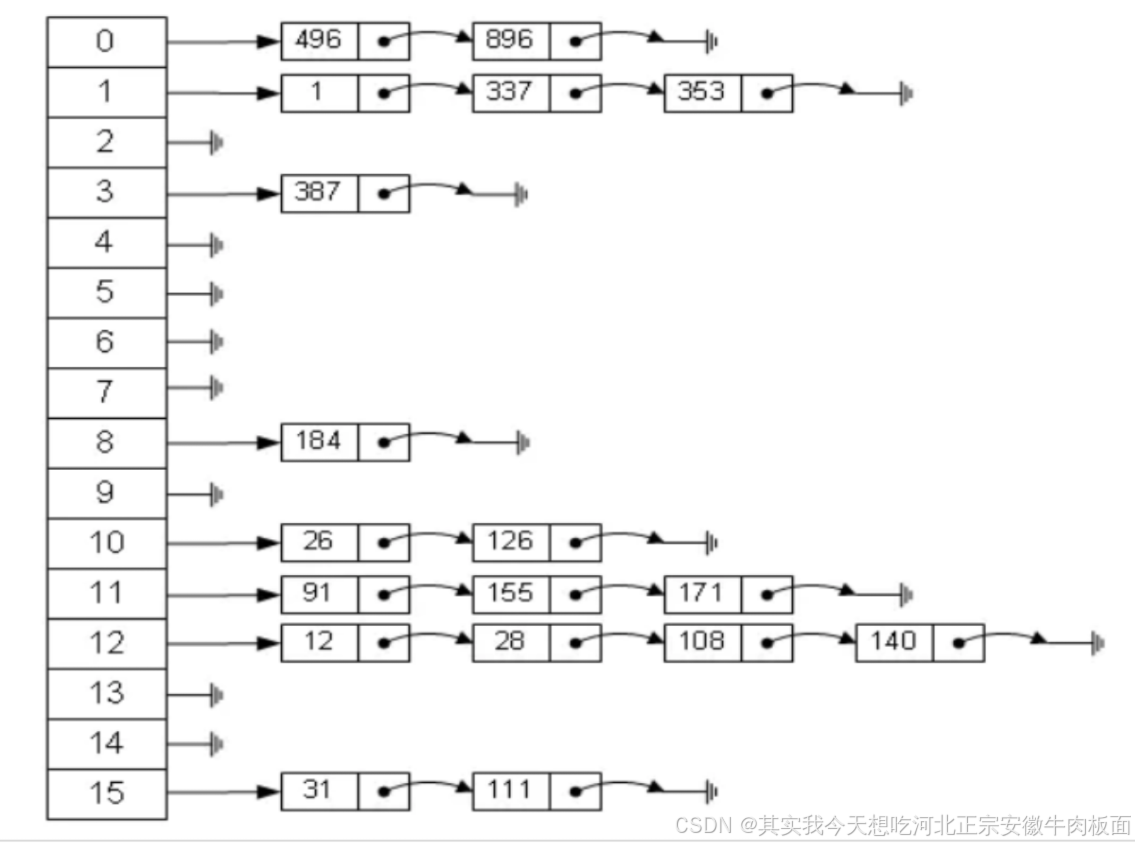
定義:通過哈希函數計算數據存儲位置,直接定位內存地址。
特點:
快速查找:理想情況下時間復雜度為 O(1)。
沖突處理:需解決哈希沖突(如開放尋址法、鏈地址法)。
特性 說明 優點 查找速度極快;適合精確匹配查詢。 缺點 哈希沖突影響性能;不支持范圍查詢。 實現方式 哈希表、布隆過濾器、一致性哈希。 適用場景 緩存系統(如 Redis)、字典、去重(如? HashSet)。示例:
struct HashNode { int key; struct HashNode *next; } *table[10] = {NULL}; // 哈希表 int idx = 5 % 10; table[idx] = &(struct HashNode){5, NULL}; // 插入鍵5 printf("%d", table[idx]->key); // 輸出:5
5. 總結?
性能對比與分析
操作類型 順序存儲(數組) 鏈式存儲(鏈表) 散列存儲(哈希表) 索引存儲(B樹) 隨機訪問 O(1) O(n) O(1)(平均) O(log n) 插入/刪除 O(n) O(1) O(1)(平均) O(log n) 空間利用率 高(連續存儲) 低(指針額外開銷) 中等(哈希表負載因子) 中等(索引結構) 適用場景 靜態數據、頻繁訪問 動態數據、頻繁修改 快速查找、去重 有序數據、范圍查詢
存儲結構 核心代碼 關鍵特點 順序存儲 int arr[5]; arr[2]=3;連續內存,直接訪問 鏈接存儲 struct Node { ... }; a.next = &b;動態指針,靈活增刪 索引存儲 data[index[1]]索引表加速定位 散列存儲 table[hash(key)] = &node;哈希函數映射,沖突處理
3. 總結
邏輯結構與物理結構的對應關系
邏輯結構 支持的物理結構 典型實現示例 線性結構 順序存儲、鏈式存儲 - 數組(順序存儲)
- 鏈表(鏈式存儲)樹形結構 鏈式存儲、順序存儲(完全二叉樹) - 二叉樹(指針鏈式)
- 堆(數組順序存儲)圖結構 鏈式存儲(鄰接表)、順序存儲(鄰接矩陣) - 鄰接表(鏈表實現)
- 鄰接矩陣(二維數組實現)集合結構 散列存儲、索引存儲 - 哈希集合(散列存儲)
- 有序集合(B樹索引存儲)





)
——設計思路、實現步驟、代碼實現)




(已不推薦使用deprecated,建議使用img、video、audio標簽))







