DeepResearch深度搜索實現方法調研
Deep Research 有三個核心能力
- 能力一:自主規劃解決問題的搜索路徑(生成子問題,queries,檢索)
- 能力二:在探索路徑時動態調整搜索方向(劉亦菲最好的一部電影是什么?如何定義好?已有信息是否足夠?)
- 能力三:對多源的信息進行驗證,整合(一個文檔說 37 歲,另一個文檔說 27 歲,怎么分辨?)
非強化學習方法:
《Search-o1: Agentic Search-Enhanced Large Reasoning Models》(能力二)
作者:人大+清華
https://github.com/sunnynexus/Search-o1 (Star 800)
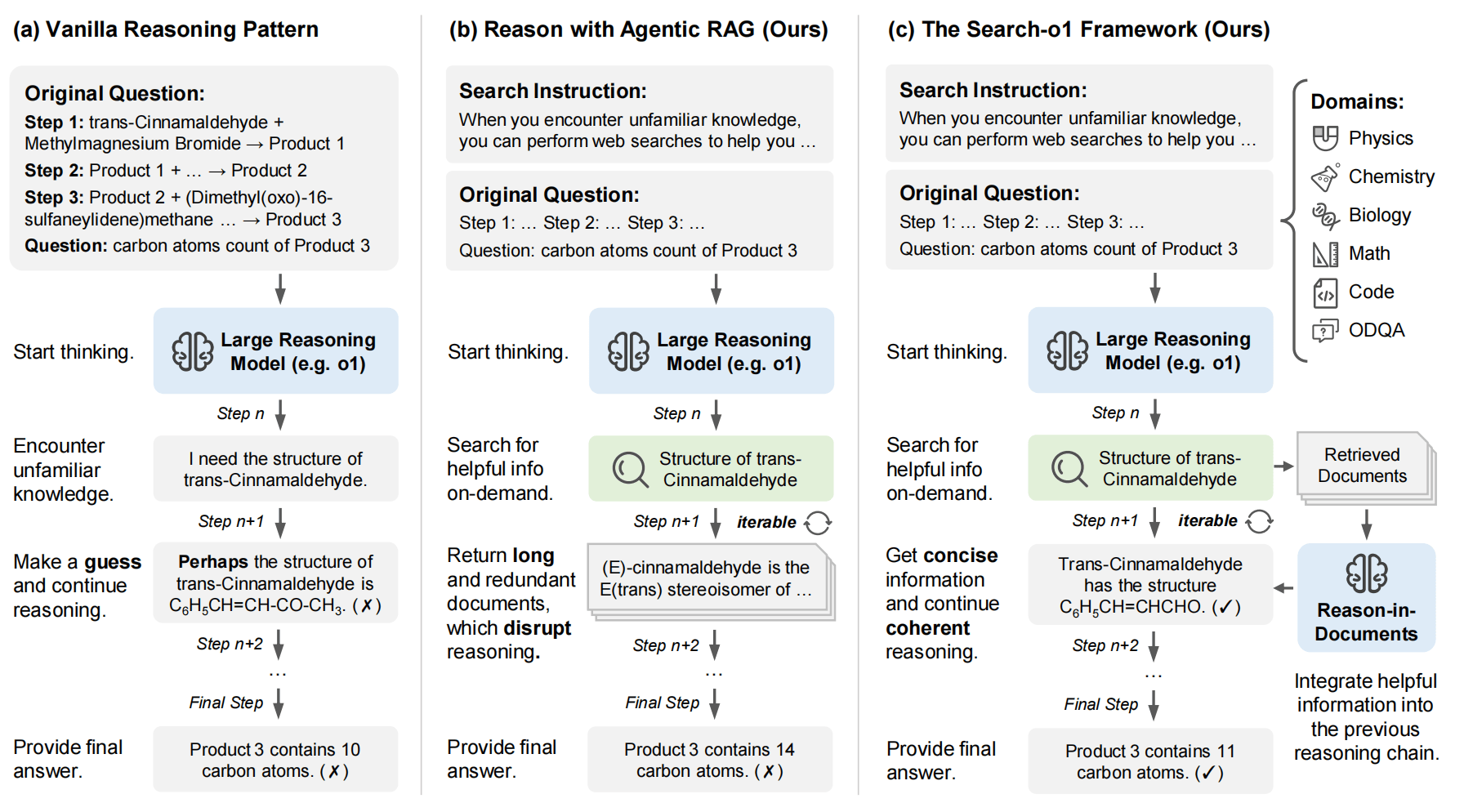
- 當遇到知識不確定的情況時,模型會自動生成搜索查詢,格式為
<|begin_search_query|>搜索詞<|end_search_query|> - 系統檢測到這一標記后,暫停模型推理,執行網絡搜索
- 搜索結果被包裝在
<|begin_search_result|>檢索到的內容<|end_search_result|>標記中返回給模型 - 如果檢索到的結果特別長,就用大語言模型對其進行精煉,再放進推理鏈條中。
優勢:
檢索觸發機制:傳統 RAG 是靜態的、預先定義的;Search-o1 是動態的、由模型主動觸發的,可以在一定程度上實現能力二。
Deep-Searcher
https://github.com/zilliztech/deep-searcher
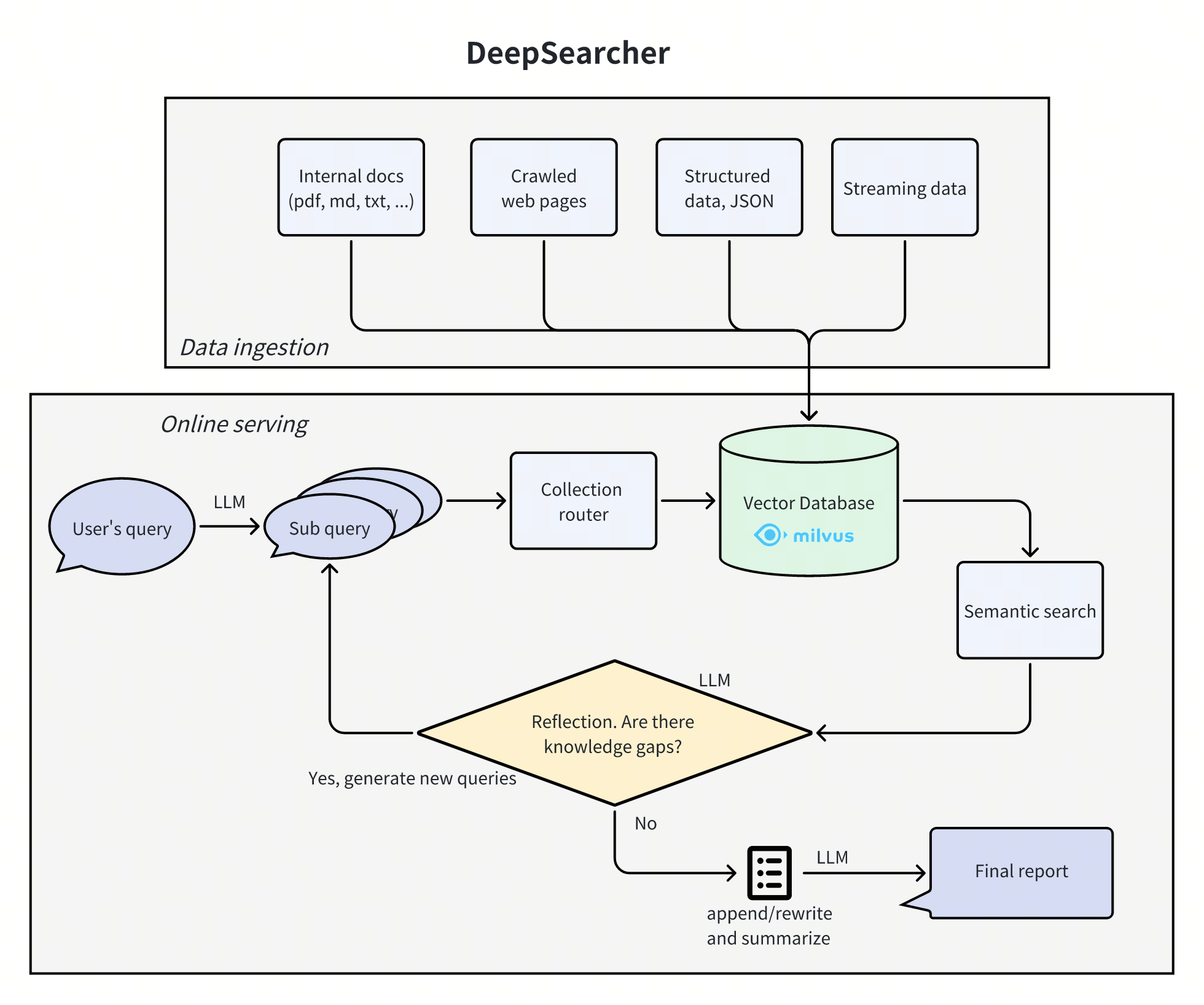
基本流程:
- 將原始問題進行拆解,分成多個子問題。
- 子問題分別進行檢索,得到對應的答案。
- 子問題和答案進行整合,由模型生成下一輪子問題。
- 達到指定檢索輪數后,匯總最終的答案。
OpenDeepResearcher
https://github.com/mshumer/OpenDeepResearcher
- 用戶輸入一個研究主題后,LLM會生成最多四個不同的搜索關鍵詞。
- 每個搜索關鍵詞都通過調用SERPAPI接口進行搜索。
- 將所有獲取到的鏈接進行聚合和去重處理。
- 對每個唯一鏈接調用JINA網頁內容解析接口,利用LLM評估網頁的有用性,如果頁面被判定為有效,則提取相關文本內容。
- 匯總所有信息,判斷是否需要進一步生成新的搜索關鍵詞。如果需要,則生成新的查詢;否則,循環終止。
- 將所有收集到的上下文信息整合后,由LLM生成一份全面、詳盡的報告。
deep-research
https://github.com/dzhng/deep-research
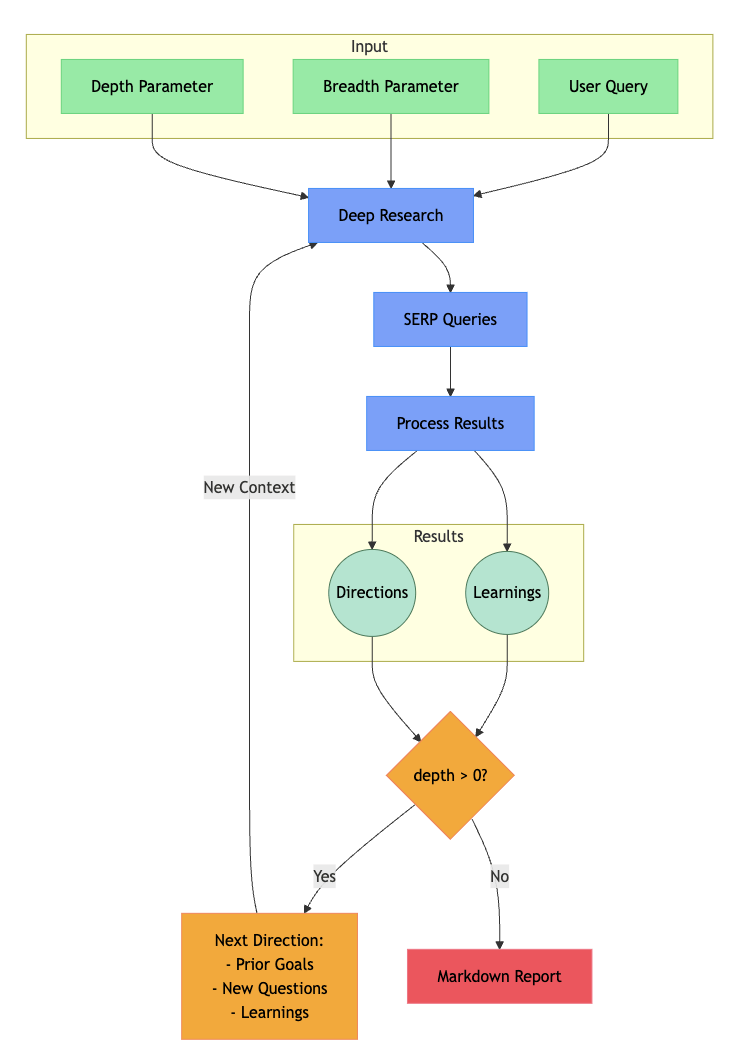
- 獲取用戶的查詢和研究參數(廣度與深度)并生成SERP查詢。
- 處理搜索結果,提取關鍵內容用于生成后續研究方向。
- 如果深度 > 0,則根據新的研究方向繼續探索。
- 將所有上下文匯總成一份全面的Markdown報告。
強化學習方法:
《DeepRetrieval: Hacking Real Search Engines and Retrievers with Large Language Models via Reinforcement Learning》(能力一)
作者:伊利諾伊大學香檳分校+高麗大學
https://github.com/pat-jj/DeepRetrieval (Star 360)
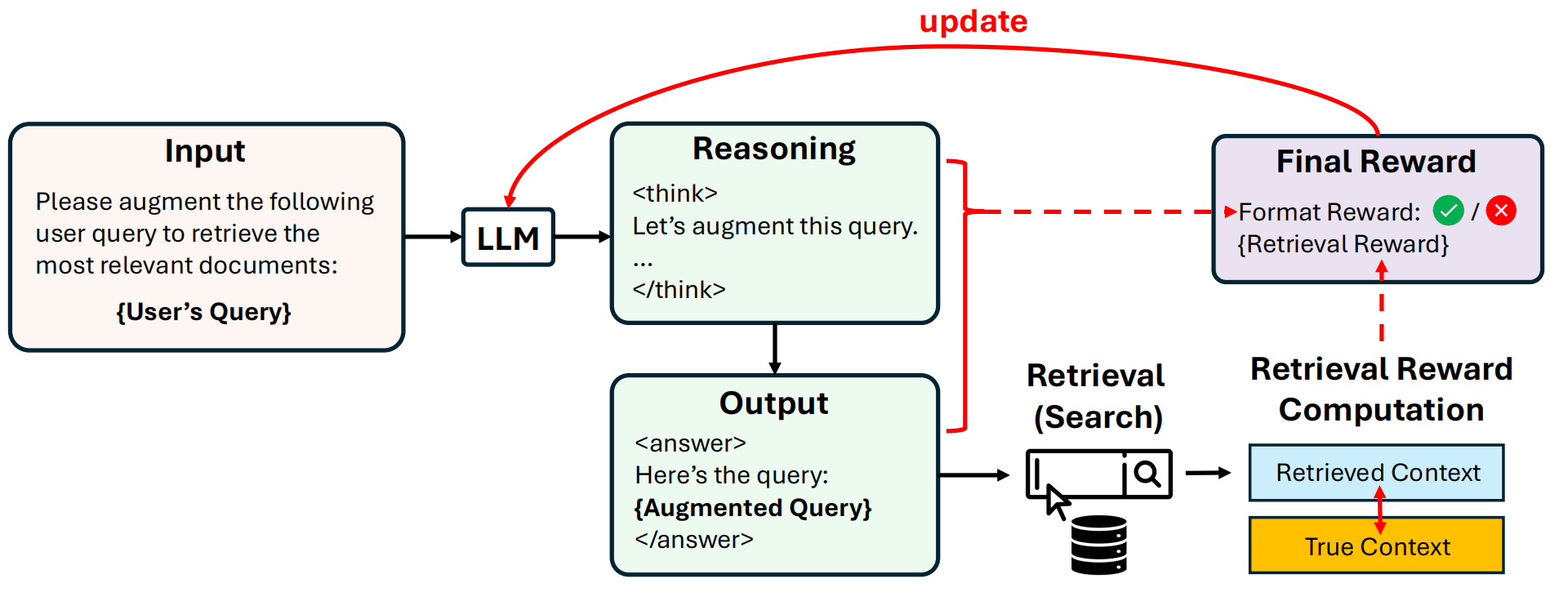
query改寫已被證實是檢索流程中的關鍵步驟。當用戶提交問題時,大型語言模型(LLM)通常會對其進行重新表述(稱為增強查詢),然后再執行檢索。DeepRetrieval采用創新方法,利用強化學習(RL)而非傳統的監督式微調(SFT)來優化這一關鍵步驟。
DeepRetrieval的突出之處在于它能夠通過"試錯"方式直接學習,使用檢索指標作為獎勵,無需昂貴的監督數據。這種方法使模型能夠針對實際性能指標進行優化,而不僅僅是模仿人工編寫的查詢。
訓練策略使用 PPO。


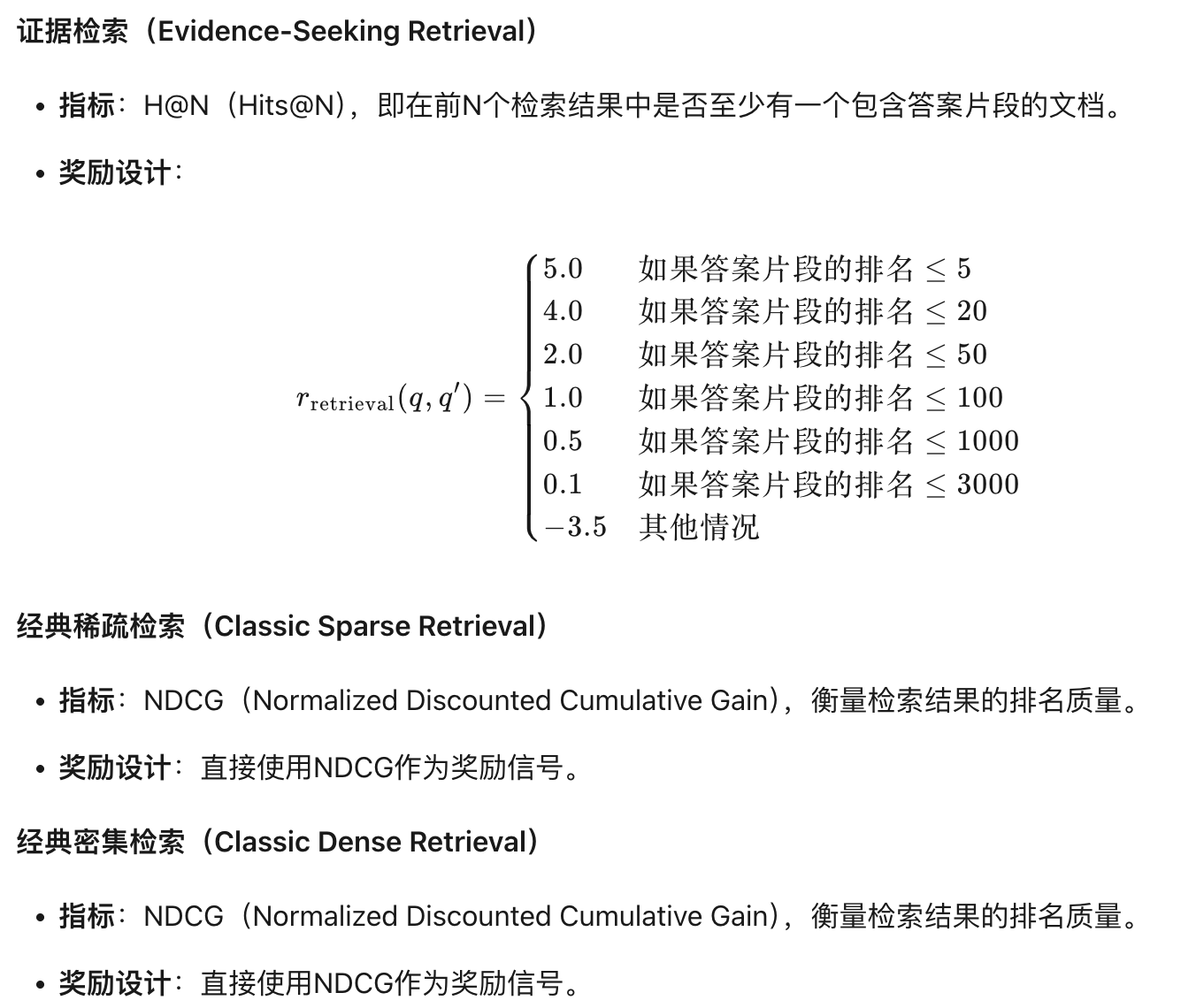

數據集:PubMed、ClinicalTrials.gov…公開數據集
《Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning》(能力一、二、三)
伊利諾伊大學香檳分校
https://github.com/PeterGriffinJin/Search-R1
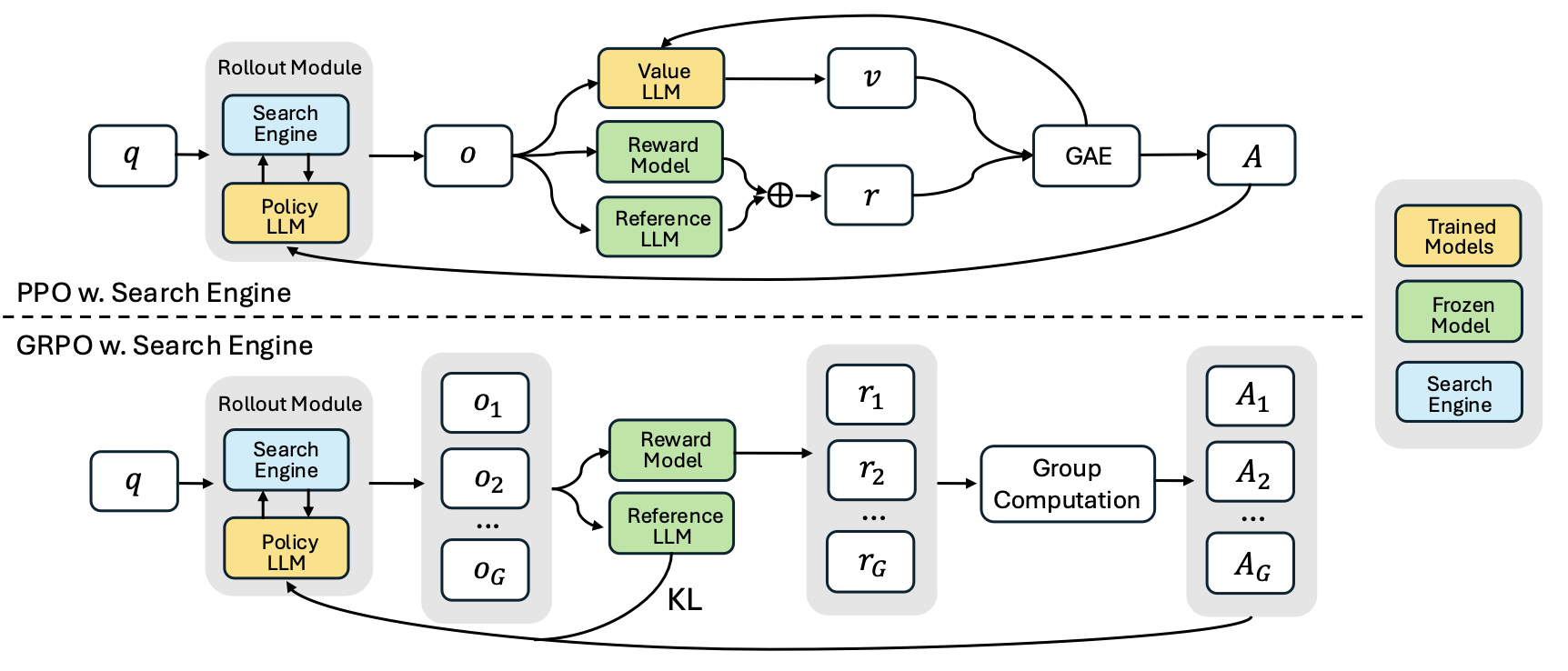
- 將搜索引擎建模為環境的一部分 模型可以在生成中插入
<search>query</search>指令,系統則響應<information>results</information>,最終答案用<answer>標簽輸出,推理過程包裹在<think>中。 - 支持多輪思考-檢索循環 模型可以識別信息缺口并主動發起下一輪搜索,而不是一次性拼接上下文。
- 基于強化學習策略學習 訓練采用 PPO (Proximal Policy Optimization)或 GRPO (Group Relative Policy Optimization)算法,獎勵信號基于最終結果(如 Exact Match)而非過程監督。
- 避免優化干擾的技術細節 引入 Retrieved Token Loss Masking,對搜索返回內容不反向傳播,從而保持訓練穩定。
從下圖來看,它用 7B 模型就能超越 Search-o1 和 680B 參數的 R1?這種“小模型大能力”的背后,正是 RL 訓練出的搜索策略彌補了知識覆蓋和參數規模的不足。
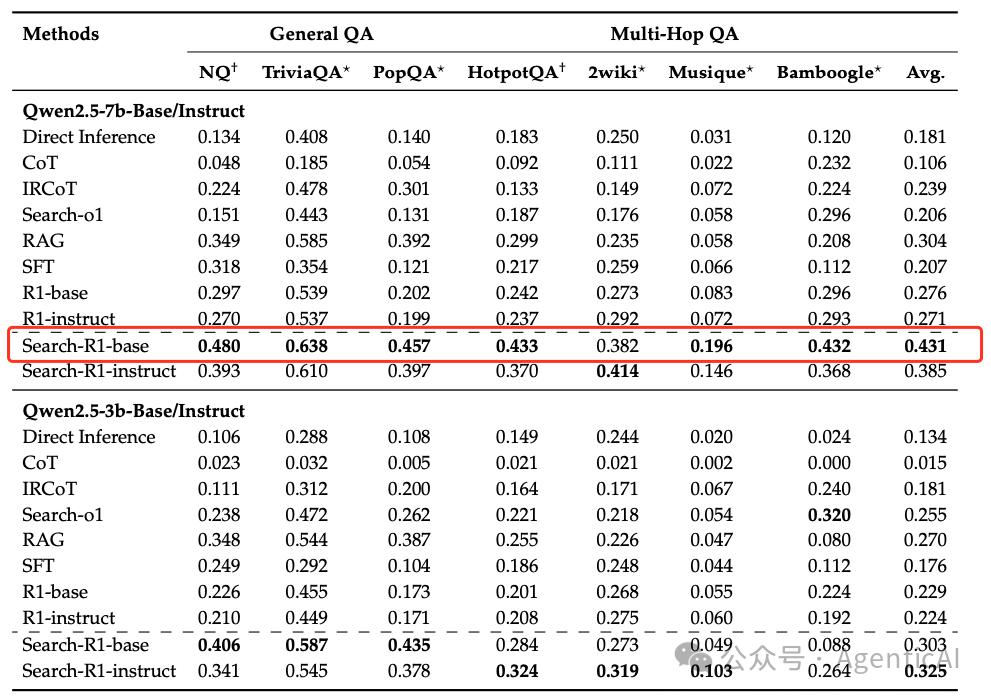
- 數據集:在七個問答數據集上進行評估,包括一般問答(NQ、TriviaQA、PopQA)和多跳問答(HotpotQA、2WikiMultiHopQA、Musique、Bamboogle)。
- 基線比較:與多種方法進行比較,包括無檢索的推理、檢索增強生成(RAG)、工具調用方法(如IRCoT和Search-o1)、監督微調(SFT)和基于RL的微調(R1)。
- 模型和檢索設置:使用Qwen-2.5-3B和Qwen-2.5-7B模型,以2018年維基百科轉儲作為知識源,E5作為檢索器,每次檢索返回3個段落。
獎勵函數:

總結
- 非強化學習方法從技術上來看技術路線都是一樣的,即使用推理模型分析,結合聯網搜索以及ReAct機制,根據用戶輸入擴展問題,再對每個問題進行多次聯網查找,推理、再查找的過程,最終輸出一個綜合性的答案。這套方法也比較容易復現。
- 使用強化學習對整體進行進行端到端訓練固然可以提升效果,用小模型代替大模型。但缺點也很明顯,依賴于高質量的數據,會限制其應用范圍,比如無法支持多種模型。
- 使用強化學習對個別流程進行針對性訓練的是比較有可行性的,比如針對query生成專門訓練。
- 當前的方法主要討論的都是能力一、二,對能力三較少有針對性優化。














后端的逐元素操作(Per-element Operations))
)


的下一代 SQL 注入自動化漏洞獵手)
