XPath 簡介
XPath (XML Path Language) 最初是為了在 XML 文檔中進行導航而設計的語言,后來被廣泛應用于 HTML 文檔的解析。與 BeautifulSoup 相比,XPath 有以下特點:
- 語法強大:可以通過簡潔的表達式精確定位元素
- 跨平臺性:幾乎所有編程語言都有 XPath 的實現
- 靈活性高:可以通過各種軸、謂詞和函數構建復雜的選擇條件
在 Python 中,我們主要通過 lxml 或者 selenium 庫來使用 XPath 功能。可以通過 pip 安裝下面的依賴包。
pip install lxml
pip install seleniumXPath 測試工具
瀏覽器
用瀏覽器測試驗證 XPath 最直觀,最方便,優先推薦這種方式。比如在百度熱搜?百度熱搜 測試?XPath。
在瀏覽器開發者工具的 Elements 中按?Ctrl + F,在搜索框中輸入 XPath 。比如查找百度熱搜標題,XPath 正確的話,會在頁面高亮顯示對應的元素。
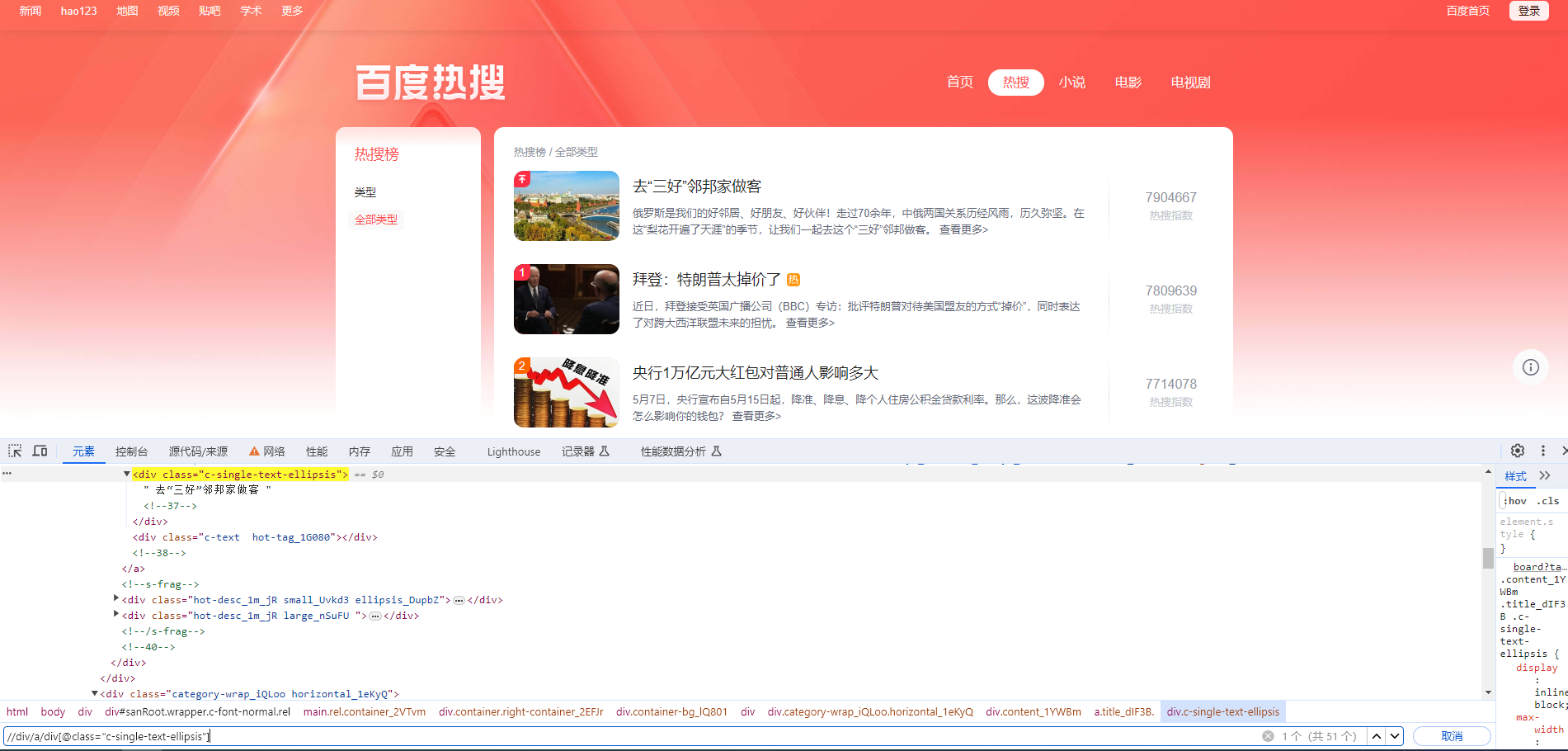
lxml?
Python 的 lxml 庫提供了強大的 XPath 支持。比如以下用來解析提取熱搜新聞標題。
from lxml import etree
import requests# 獲取HTML內容
url = "https://top.baidu.com/board?tab=realtime"
response = requests.get(url)
html_text = response.text# 解析HTML
# html = etree.HTML(html_text)
# 或者從文件加載HTML
html = etree.parse('百度熱搜.html', etree.HTMLParser())# 使用XPath提取數據
titles = html.xpath('//div/a/div[@class="c-single-text-ellipsis"]/text()') # 獲取標題文本
for index, title in enumerate(titles):print(f"第 {index + 1} 條新聞;新聞標題:{title}")
print("===熱搜標題提取正常===")
第 1 條新聞;新聞標題:去“三好”鄰邦家做客
第 2 條新聞;新聞標題:拜登:特朗普太掉價了
第 3 條新聞;新聞標題:央行1萬億元大紅包對普通人影響多大
...
第 48 條新聞;新聞標題:世界人形機器人運動會將在北京舉辦
第 49 條新聞;新聞標題:蘋果探索在瀏覽器中加入AI搜索功能
第 50 條新聞;新聞標題:專家解讀:為何央行此時宣布降準降息
第 51 條新聞;新聞標題:騎士G2冤死 裁判報告公布三次漏判
===熱搜標題提取正常===selenium
Python 的 selenium 庫提也供了強大的 XPath 支持。比如使用 RPA 流程自動化爬取數據的時候,總避免不了通過 XPath 去定位和查詢元素。以下用來解析提取熱搜新聞標題。
from selenium import webdriver
from selenium.webdriver.common.by import Bydef init_driver():option = webdriver.ChromeOptions()driver = webdriver.Chrome(r'./driver/chromedriver.exe', options=option)driver.maximize_window()return driverdef main():driver = init_driver()url = r'file:///E:\lky_project\tmp_project\百度熱搜.html'driver.get(url)try:xpath_titles = '//div/a/div[@class="c-single-text-ellipsis"]'titles = driver.find_elements(By.XPATH, xpath_titles)for index, title in enumerate(titles):print(f"第 {index + 1} 條新聞;新聞標題:{title.text}")print("===熱搜標題提取正常===")except Exception as e:print("===熱搜標題提取報錯===", e)returnif __name__ == '__main__':main()
第 1 條新聞;新聞標題:去“三好”鄰邦家做客
第 2 條新聞;新聞標題:拜登:特朗普太掉價了
第 3 條新聞;新聞標題:央行1萬億元大紅包對普通人影響多大
...
第 48 條新聞;新聞標題:世界人形機器人運動會將在北京舉辦
第 49 條新聞;新聞標題:蘋果探索在瀏覽器中加入AI搜索功能
第 50 條新聞;新聞標題:專家解讀:為何央行此時宣布降準降息
第 51 條新聞;新聞標題:騎士G2冤死 裁判報告公布三次漏判
===熱搜標題提取正常===XPath 常用函數?
contains()
contains()?函數用于判斷某個屬性的取值中是否包含指定的字符串。其語法格式如下:
contains(@attribute, "substring")
@attribute:表示要過濾的屬性名稱,屬性名稱前需加上@符號。substring:表示要判斷是否包含的字符串。
在自動化測試中,contains?函數特別適用于定位那些屬性值不固定的元素。例如,某個元素的id?屬性值在每次頁面刷新時都會發生變化,但其中某些字符是固定的。通過?contains?函數,可以基于這些固定的字符進行定位。
比如頁面中查找?name?屬性中包含?username?的?input?元素:
//input[contains(@name, 'username')]starts-with()
與 contains() 類似,只不過是限定指定開頭的屬性或者文本。
//div/a/div[starts-with(text(), " 國防部")]ends-with()
限定指定結尾的屬性或者文本(部分瀏覽器不一定支持,要想兼容性更強的話建議最好少用)。
//div/a/div[ends-with(text(), "熱烈歡迎 ")]position()
position()?函數用于選取指定位置的元素。其語法格式如下。
//element[position() < number]
//element[position() <= number]
//element[position() = number]
//element[position() > number]
//element[position() >= number]position():表示元素的序號,從1開始計數。number:表示設定的閾值。
比如:
//element[1]等價于:
//element[position() = 1]?比如頁面中有多個?input?元素,我們希望選取前兩個?input?元素。
//input[position()<3]last()
last()?函數用于選取從后往前數的元素。其語法格式如下:
//element[last() - number]
last():表示匹配元素的總數。number:表示從后往前數的元素位置。
假設頁面中有多個?input?元素,我們希望選取最后一個?input?元素:
//input[last()]
如果希望選取倒數第二個?input?元素:
//input[last() - 1]count()?
count() 函數通過對子元素指定類型節點進行統計來限定父元素的選取。語法格式如下:
//element[count(sub_element) < number]
//element[count(sub_element) <= number]
//element[count(sub_element) = number]
//element[count(sub_element) > number]
//element[count(sub_element) >= number]count(sub_element):表示 element 元素 下 sub_element 的數目。number:表示設定的閾值。
?比如我們選取子元素中 div 的個數為 2 的 a 元素:
//a[count(div)=2] text()
text() 函數用于獲取元素的直接文本內容。一般與 contains() 結合使用,來選取文本內容包含指定字符串的元素。
比如查找文本中包含 "熱烈歡迎" 的 div 元素。
//div[contains(text(), "熱烈歡迎")]也可以用文本的精確匹配。
//div[text()="熱烈歡迎"]node()
node()?函數用于選取所有節點。其語法格式如下:
//node()
node()函數的功能與?* 通配符號類似,用于選取所有節點。例如:
//*
或
//node()
上述兩種表達式的效果相同,均用于選取頁面中的所有節點(但通配符 * 不包括文本,注釋,指令等節點,如果也要包含這些節點請用 node() 函數)。
XPath 基礎語法
路徑操作符
| 操作符 | 描述 | 示例 |
|---|---|---|
/ | 從根節點選取元素 | /html/body |
// | 遞歸步進下降選擇文檔中符合條件的所有元素 | //a |
. | 選取當前節點 | ./div |
.. | 選取當前節點的父節點 | ../ |
@ | 選取屬性 | //div[@id] |
* | 通配符,選擇任意元素 | //* |
條件謂詞
XPath 允許我們使用方括號?[]?來添加條件謂詞進行篩選限定 。
//div[1] # 第一個div元素
//div[last()] # 最后一個div元素
//div[position()<3] # 前兩個div元素
//div[@class] # 所有有class屬性的div元素
//div[@class='main'] # class屬性值為'main'的div元素
//div[contains(@class, 'content')] # class屬性包含'content'的div元素
//a[text()='click'] # 文本內容為'click'的a元素
//a[count(div)=2] # 包含2個div元素的a元素軸操作
以?百度熱搜?首頁為例。
ancestor
ancestor 用以獲取元素的祖先節點。比如 熱搜 對應? xpath 為:
//div[2]/a/span[text()="熱搜"]則下面的 xpath 用以獲取 熱搜 元素對應的所有祖先節點:
//div[2]/a/span[text()="熱搜"]/ancestor::*包含當前節點自身則需要用?ancestor-or-self:?
//div[2]/a/span[text()="熱搜"]/ancestor-or-self::*則下面的 xpath 用以獲取 熱搜 元素對應的所有 div 祖先節點:
//div[2]/a/span[text()="熱搜"]/ancestor::divdescendant
descendant 用以獲取元素的后代節點。
比如獲取?//div[@id="sanRoot"] 的所有后代 div 節點(不限定節點類型則使用 *)
//div[@id="sanRoot"]/descendant::div包含當前節點自身則需要用?decendant-or-self:?
//div[@id="sanRoot"]/descendant-or-self::divfollowing
following 用以選取文檔中當前節點結束標簽之后的所有節點。
//div/div[@class="bg-wrapper"]/following::*如果只選取當前節點之后的所有兄弟節點,則使用?following-sibling。
//div/div[@class="bg-wrapper"]/following-sibling::*preceding
preceding?用于選取文檔中當前節點開始標簽之前的所有節點(不包含當前節點的父輩節點)。
//div[last()]/div[@class="content_1YWBm"]/preceding::*如果選取當前節點之前的所有同級節點,則使用?preceding-sibling。
//div[last()]/div[@class="content_1YWBm"]/preceding-sibling::*parent
parent 用以獲取元素的父節點。
//div/div[@class="bg-wrapper"]/parent::*child
child 用以獲取元素的子節點。
//div/div[@id="sanRoot"]/child::*self?
self 用以獲取當前元素節點自己本身。
//div/div[@id="sanRoot"]/self::*attribute?
通過屬性來獲取元素。
比如獲取所有包含 class 屬性的節點。
//attribute::class
或
//@class獲取所有包含 class 屬性的 div 節點。
//div[@class]邏輯運算符
and
邏輯與,比如查詢熱搜的前三個熱搜。
//div/div[@class="category-wrap_iQLoo horizontal_1eKyQ" and position()<4]or
邏輯或
//div/div[@class="category-wrap_iQLoo horizontal_1eKyQ" or position()=last()]not
非
//div/a/div[not(@class="c-single-text-ellipsis")]XPath 優化

一般可以在瀏覽器中直接復制?XPath,但是瀏覽器復制的 XPath 一般是用絕對路徑寫的能唯一定位這個元素的 XPath。 如果頁面結構稍微發生變動,可能導致 XPath 不可用。
比如復制的 XPath 如下:
//*[@id="sanRoot"]/main/div[2]/div/div[2]/div[1]/div[2]/a/div[1]優化后可以為:?
//div[1]/div/a/div[@class="c-single-text-ellipsis"]?XPath 常用的優化思路包括:
- 找到元素附近的獨特標識(如 id、特定的 class 等)
- 盡量使用相對路徑而非絕對路徑
- 使用?
contains()?等函數處理動態變化的屬性值

)













)



已過)