Abstract
Vision Transformer在3D醫學圖像分析的自監督學習(Self-Supervised Learning,SSL)中展現了卓越的性能。掩碼自編碼器(Masked Auto-Encoder,MAE)用于特征預訓練,可以進一步釋放ViT在各種醫學視覺任務中的潛力。然而,由于3D醫學圖像具有更大的空間尺寸和更高的維度,缺乏層次化設計的MAE可能會阻礙下游任務的性能。在本文中,我們提出了一種新穎的3D醫學圖像掩碼內掩碼(Mask in Mask,MiM)預訓練框架,旨在通過從不同尺度的層次化視覺標記中學習區分性表示,來提升MAE的性能。我們引入了多個粒度級別的掩碼輸入,這些輸入來自體數據(volume),并且同時在精細和粗糙級別上進行重建。此外,我們應用了一種跨層次對齊機制,對相鄰層次的體數據進行對齊,以強制執行層次化的解剖學相似性。此外,我們采用了一種混合骨干網絡,以在預訓練期間高效地增強層次化表示學習。MiM在大規模可用的3D體圖像上進行了預訓練,例如包含各種身體部位的計算機斷層掃描(Computed Tomography,CT)圖像。在十二個公共數據集上進行的廣泛實驗表明,MiM在器官/腫瘤分割和疾病分類方面優于其他自監督學習方法。我們進一步將MiM擴展到包含超過1萬個體數據的大規模預訓練數據集上,結果表明大規模預訓練可以進一步提升下游任務的性能。代碼和檢查點將在被接受后提供。
索引詞——CT、自監督學習、分割、分類、3D醫學圖像。
I. INTRODUCTION
深度學習的出現推動了醫學圖像分析領域的前所未有的進步,尤其是在監督學習范式中。然而,這一范式的基本局限性在于其對大量標注訓練數據的依賴,這對于3D醫學圖像來說尤其具有挑戰性,因為標注需要大量的專業知識、時間和資源 [1]–[6]。自監督學習(SSL)作為一種變革性解決方案應運而生,它提供了一種強大的機制,可以從無標注數據中學習到魯棒且可遷移的表示,從而顯著提升下游任務的性能 [7]–[16]。這種范式轉變不僅推動了醫學圖像分析領域的重大進步,還大幅減輕了標注的負擔 [2], [4]。
在自監督學習(SSL)領域中,掩碼自編碼器(Masked Autoencoders,MAE)[17] 通過其創新的通過視覺變換器(Vision Transformer)架構重建失真視圖的方法,在自然圖像分析中取得了顯著的成功 [17], [18]。然而,將這些方法擴展到3D醫學成像領域帶來了獨特的挑戰,因為體積數據具有高維度和跨越多個尺度的復雜解剖結構等固有復雜性。最近的研究進展在解決這些挑戰方面取得了重大突破。MAE3D [19] 通過重建裁剪子體積中的非重疊塊,開創性地適應了3D醫學成像,為理解復雜解剖結構奠定了基礎。GL-MAE [20] 通過引入局部-全局對比學習進一步推動了這一方向,以增強多粒度解剖結構建模,而SwinUNETR [9] 則通過混合變換器 [21] 納入了多尺度特征學習。盡管這些方法展示了有希望的結果,但它們對單尺度裁剪體積的依賴本質上限制了它們捕捉全面解剖關系的能力。最近的努力探索了替代策略來解決這些限制:SwinMM [22] 利用多視圖一致性來增強體積表示,而Alice [7] 則利用預訓練模型 [23] 來捕捉豐富的體積內關系。盡管取得了這些進展,但三個關鍵挑戰仍然存在:①體積裁剪所施加的空間上下文限制阻礙了對完整解剖結構的理解;②缺乏對不同解剖尺度間層次關系的顯式建模;③以及處理全分辨率3D體積的巨大計算需求。這些相互關聯的挑戰突顯了需要一種更復雜的方法,能夠高效地捕捉細粒度解剖細節和全局上下文信息,同時保持實際的計算需求。
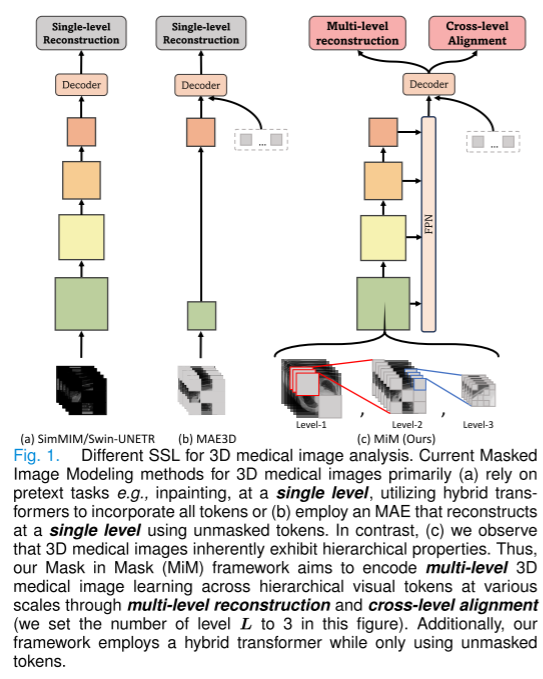
醫學圖像的固有層次性,尤其是那些具有廣闊空間維度的圖像,需要一個復雜的多級分析框架來進行全面的臨床解讀 [9], [24]。如圖1所示,我們引入了MiM,這是一個新穎的層次化框架,從根本上推進了基于MAE的3D醫學圖像表示學習。我們的框架通過三個協同的組件系統地解決了現有方法的關鍵局限性。首先,為了克服裁剪體積的有限上下文,我們提出了一個多級體積生成策略,該策略同時在多個尺度上處理3D體積的較大視圖,使我們的模型能夠捕捉到細粒度的解剖細節及其更廣泛的上下文關系。其次,為了明確地建模層次化表示,我們設計了一個復雜的多級重建機制,該機制在不同的解剖尺度上運行。這種機制在不同的粒度上保留了關鍵的解剖細節,同時通過一種先進的跨層次對齊策略強制執行一致性,確保局部結構及其全局上下文之間的一致性解讀。第三,為了應對處理3D醫學圖像較大視圖的計算挑戰,我們納入了一個高效的混合骨干設計,該設計受到MCMAE [25]的啟發。
這種架構顯著降低了計算開銷,同時保留了基于Transformer模型的優勢,使得分析高分辨率3D醫學圖像變得切實可行。這些創新協同作用,使MiM能夠有效地對完整的解剖層次結構進行建模,同時保持計算效率。
本工作的主要貢獻有三個方面:
1. 我們提出了MiM,這是一個計算效率高的自監督學習(SSL)框架,通過層次化設計推進了掩碼自編碼器(MAE)在3D醫學圖像預訓練中的應用。我們的方法有效地管理了3D醫學數據的復雜性,同時能夠同時捕捉多個尺度上的解剖特征,這對于準確的醫學圖像分析至關重要。
2. 我們引入了一種全面的方法,通過兩個協同的代理任務——多級重建和跨級對齊——來編碼多級視覺信息。這種設計通過我們新穎的跨級對齊機制,在各個尺度上保持解剖學一致性的同時,實現了強大的局部和全局表示學習。
3. 通過在十二個多樣化的數據集上進行廣泛的實驗驗證,使用從1k到10k體積不等的預訓練集,我們展示了最先進的性能,并建立了預訓練數據集規模與模型有效性之間的明確相關性。我們的全面評估表明,在各種醫學成像任務中都有顯著改進,我們的多級方法始終優于單級替代方案。
II. RELATED WORKS
醫學圖像分析領域中自監督學習(SSL)的最新進展經歷了不同的范式演變,其中像分割這樣的密集預測任務對于3D醫學圖像來說至關重要,但同時也極具挑戰性。在本節中,我們首先回顧醫學成像中的SSL方法,重點關注從對比學習方法到生成式方法的演變及其在這些密集預測任務中的有效性。這種演變引導我們討論掩碼圖像建模(Masked Image Modeling),這是一種在3D醫學圖像分析中展現出潛力的強大生成式SSL技術。然而,當前的掩碼圖像建模方法在捕捉3D醫學數據的復雜層次結構方面存在困難,這促使我們審視層次化的SSL設計。通過這一綜述,我們展示了現有方法在有效建模3D醫學圖像的多粒度特征方面存在的不足,從而為我們的層次化掩碼內掩碼(MIM)框架的提出奠定了基礎。
醫學圖像分析中的自監督學習(SSL)醫學成像中的SSL方法主要經歷了兩種范式:基于對比的方法和基于生成的方法 [26]–[28]。基于對比的方法:這些方法專注于在特征空間中對正樣本對進行對齊,同時將負樣本對分開 [29]。像SimCLR [29]、MoCov2 [30]和MoCov3 [31]這樣的開創性工作已經在醫學分類任務中取得了成功 [32], [33],并且通過特定領域的特征金字塔網絡(FPN)創新進一步增強了它們在醫學成像中的有效性。例如,[34]引入了基于子體積的對比學習,而[23], [35]通過在局部和全局尺度上對比特征,推動了對多粒度的理解。然而,這些方法專注于實例級對齊,限制了它們在像分割這樣的密集預測任務中的有效性 [32]。基于生成的方法:這些方法通過明確建模空間結構并保持局部-全局一致性來解決上述限制 [36]。該領域從使用3D U-Net進行基本重建任務 [37], [38]發展到結合現代架構(如帶有修復功能的3D Swin Transformers)的復雜方法 [9], [34]。這一演變最終促成了掩碼圖像建模(Masked Image Modeling)的發展,它在各種3D醫學成像應用中展現出了強大的性能 [17], [19], [20], [39], [40]。
醫學中SSL主要是兩種方法:基于對比和生辰發的方法,對比、生成、掩碼圖像建模,這樣的演變過程
醫學圖像分析中的掩碼圖像建模
掩碼圖像建模(Masked Image Modeling)作為一種強大的醫學圖像分析技術,建立在生成式自監督學習(SSL)的成功基礎之上。最初由[17]提出,這種方法證明了高比例掩碼通過原始像素恢復創建了一個有效的自監督任務。該領域通過掩碼策略[41]和重建目標[18]的創新得到了發展。盡管早期的應用在2D醫學任務中顯示出潛力,包括疾病分類[44]和分割[43],但將其擴展到3D醫學成像帶來了新的挑戰。MAE3D[19]率先將掩碼自編碼技術應用于體積數據,而GL-MAE[20]通過引入全局-局部一致性對比學習,增強了對解剖結構的理解。SwinUNETR[9]通過認識到多尺度表示學習的重要性并納入混合變換器[21],進一步推動了該領域的發展。然而,這些方法[9], [19], [20], [22]盡管有創新,但它們在單一尺度上處理3D醫學圖像,具有有限的感受野,或者僅依賴于骨干級別的多尺度處理。如圖1所示,當處理3D醫學圖像中顯著更大的空間維度和變化的解剖結構時,這種方法變得有問題。
層次化自監督學習(Hierarchical SSL)層次化結構在自監督學習(SSL)中的重要性已經在自然圖像和醫學圖像領域得到了認可。在自然圖像處理中,像[18]和[39]這樣的方法已經將掩碼圖像建模與層次化骨干網絡(如Swin Transformer [45])相結合。[46]探索了多尺度特征重建,而[25]通過利用未掩碼的上下文信息,推進了掩碼塊預測。在醫學成像領域,Adam [47]引入了基于ResNet [48]的多粒度對比學習。然而,這些方法要么受到2D圖像有限維度的限制[25], [47],要么獨立處理層次化級別[47],未能捕捉到對3D醫學圖像至關重要的跨層次語義關系。
與這些方法不同,我們的MiM(掩碼內掩碼)框架通過以下四項關鍵創新推進了3D醫學圖像分析的最新技術:
1. 我們通過設計一種強大的多級體積生成策略,極大地超越了MAE3D [19],該策略能夠同時在細粒度和粗粒度尺度上重建特征,解決了現有單尺度方法感受野有限的局限性 [9], [19], [20], [22]。
2. 受到[20], [49]的啟發,我們為3D醫學體積開發了一種復雜的跨層次對齊機制,該機制在層次化級別之間強制執行解剖學一致性,從而在解剖特征學習方面取得了顯著改進。
3. 我們從2D自然圖像[25]中改編的創新3D混合骨干架構,在預訓練期間以卓越的效率捕捉多尺度特征,同時減少了計算需求。
4. MiM通過成功在超過10,000個體積的超大規模數據集上進行預訓練,展現了卓越的可擴展性,超越了現有3D SSL醫學成像方法的規模 [8], [9], [19], [20], [32], [38]。
這些創新的有效性通過在十二個公共數據集上進行的廣泛實驗得到驗證,涵蓋了器官/腫瘤分割和疾病分類任務,確立了MiM在該領域的一項變革性進步。
III. METHODOLOGY
本節概述了我們提出的MiM方法。 首先,第III-A節介紹了MiM方法的總體框架。 其次,在第III-B節中介紹了多級重建的過程。 然后,在第III-C節中描述了我們提出的MiM方法中通過對比學習進行的跨層次對齊。 最后,在第III-D節中介紹了預訓練階段MiM方法的主干。
A. Overall framework
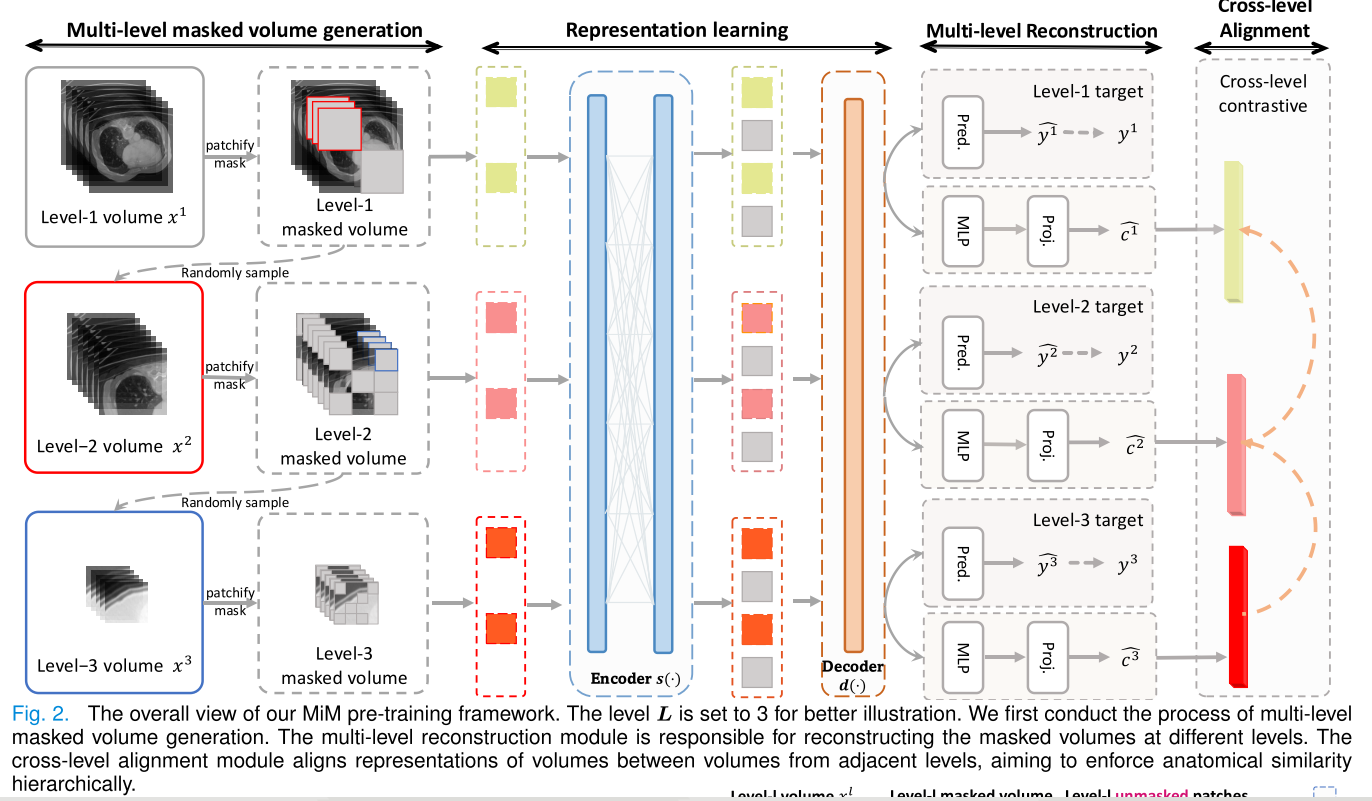
本文提出的MiM方法的整體框架如圖2所示,包括多級重建模塊和跨級對齊模塊。為了使用MiM對模型進行預訓練,我們首先從輸入的3D醫學圖像中生成多級體積。然后,將輸入體積裁剪成不重疊的塊,這些塊分為未掩碼塊和掩碼塊。未掩碼塊通過典型的骨干網絡(CNN [48]和Transformer [50])被轉換到高維特征空間。掩碼塊用于生成下一級的掩碼體積,以進行多級學習。目標是從不同級別的掩碼體積中恢復掩碼塊。在本文中,與單一級別的掩碼體積[41], [46]不同,我們提出通過多級掩碼體積來簡化這一目標。我們開發了一個損失函數來監督最終預測。此外,我們進一步使用一個損失函數
來對齊跨級體積之間的共享語義,旨在學習全局語義內容以及局部細節。更多細節將在第III-B節和第III-C節中介紹。
B. Multi-level reconstruction


因此,來自不同級別的所有未掩碼標記都被輸入到骨干網絡中以提取高維特征z。根據[17], [19]的方法,使用一個輕量級的解碼器將z與可學習的掩碼標記一起投影到潛在特征q。為了重建,解碼器后面跟著一個簡單的預測頭用來重建掩碼標記y。
Single-level reconstruction.我們的重建目標是每個級別體積中掩碼標記的像素值。
利用從骨干網絡提取的特征以及帶有預測頭(即線性層)的解碼器,按照先前的MAE方法[19],我們將預測結果和重建目標重塑為一維向量,即 和
,其中C 是維度的數量。具體來說,我們根據經驗將C設置為768,如在[19],[20]中所做的那樣。

多級重建的損失函數。為了學習多粒度的細節,我們對每個級別的掩碼體積圖像應用單級重建。因此,多級重建損失 LR? 可以如下公式化:
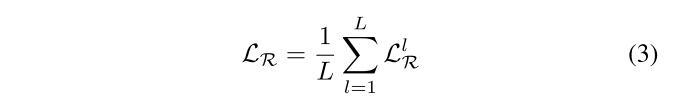
C. Cross-level alignment
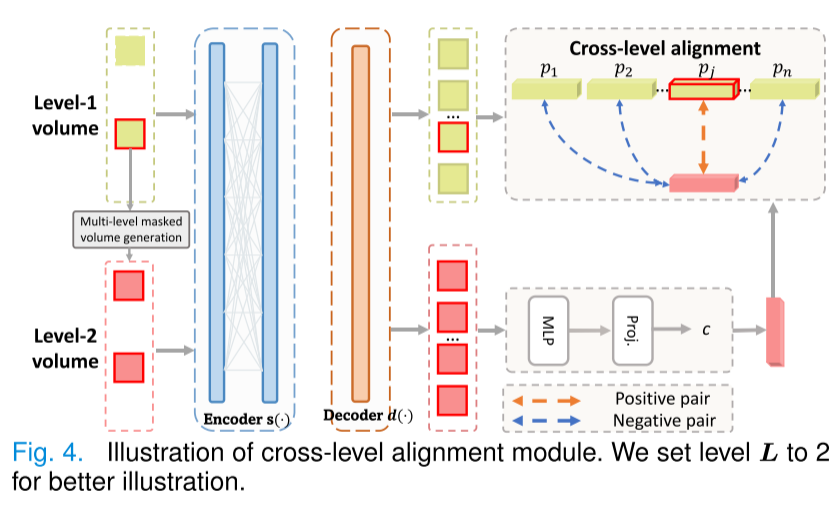
跨層次體積之間共享語義塊的對齊可以從細粒度到粗粒度強制執行解剖學上的相似性。圖4展示了跨層次對齊的過程。由于我們從更粗粒度的體積中生成更細粒度的體積(例如,從第1級體積的掩碼塊生成第2級體積),這些體積必須共享語義上下文,這可以被視為正樣本對。相比之下,粗粒度體積中的非重疊塊(例如,第1級體積中的其余塊)被視為負樣本塊。為了擴大共享解剖結構塊(即正樣本對)的高維特征一致性以及非重疊塊(即負樣本對)之間的差異,我們對上下文向量 x和塊p應用對比學習[29]。特別地,我們將上下文向量和塊重塑為一維向量 和
,其中D 是維度的數量,根據經驗將D 設置為2048,如在[49]中所做的。


D. Backbone
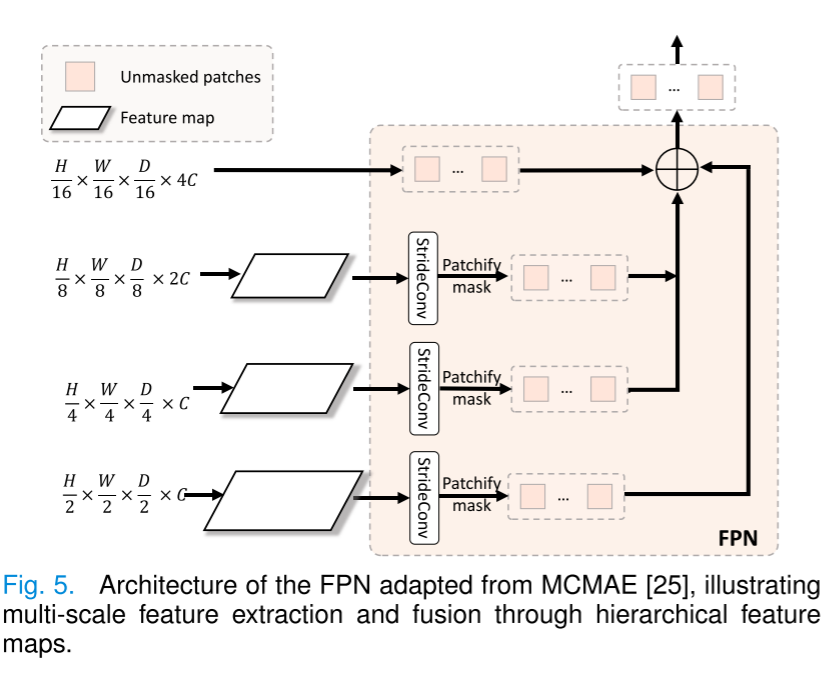
雖然以前的混合變換器(如Swin Transformer [21])能夠生成金字塔形的特征,但在掩碼圖像建模(Masked Image Modeling)預訓練期間,它們會處理所有的標記(解釋一下:在重建的時候會處理掩碼和未掩碼的,但是未掩碼的是不需要重建的),導致計算效率低下[25]。我們通過將MCMAE的骨干網絡[25]擴展到3D醫學圖像,通過增加一個深度維度來解決這個限制,使我們的模型僅在變換器層處理未掩碼的標記。這種優化顯著提高了計算效率和可擴展性,這一點在第四節D.1中得到了驗證。如圖5所示,我們的FPN(特征金字塔網絡)架構采用了MCMAE的[25]層次化設計,在四個尺度(H/2×W/2到H/16×W/16)上處理特征,通道維度為(C到4C)。每個尺度都使用StrideConv[25]進行下采樣,然后被分割成塊,接著進行掩碼操作以生成未掩碼塊。自底向上的路徑通過橫向連接和求和來整合特征,同時保持計算效率,生成全面的多尺度表示。
我們的MiM(Mask in Mask)框架通過多級重建 LR? 和跨級對齊 LC? 引入了一種針對3D醫學圖像表示學習的層次化設計方法。我們根據經驗將掩碼體積的層級數設置為 L=3,因為三級掩碼體積可以在表示學習和計算效率之間提供良好的平衡。關于 L 的消融研究在第四節D.1中進行。具體來說,方程3中的多級重建損失可以進一步展開如下:
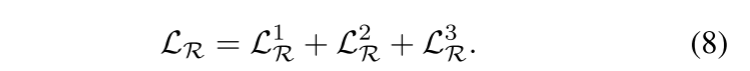
然后,由于相鄰水平體之間施加的跨水平對齊損失,Eq. 6展開為:
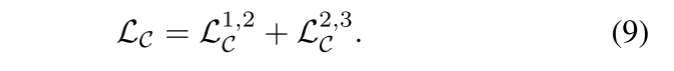
因此,總損失函數L是這兩種損失的組合,如式10所示。
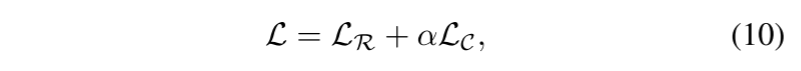
其中超參數α用于平衡這兩種損失的相對貢獻。 根據實驗結果,我們將α設為0.1。 超參數α的消融研究見第IV-D.2節。
IV. EXPERIMENTS
本節將從介紹數據集和評估指標開始。 然后,我們將詳細闡述我們的MiM的實現細節。 最后,我們將展示MiM與現有方法的實驗結果,并對我們提出的方法進行分析。
A. Datasets and Evaluation
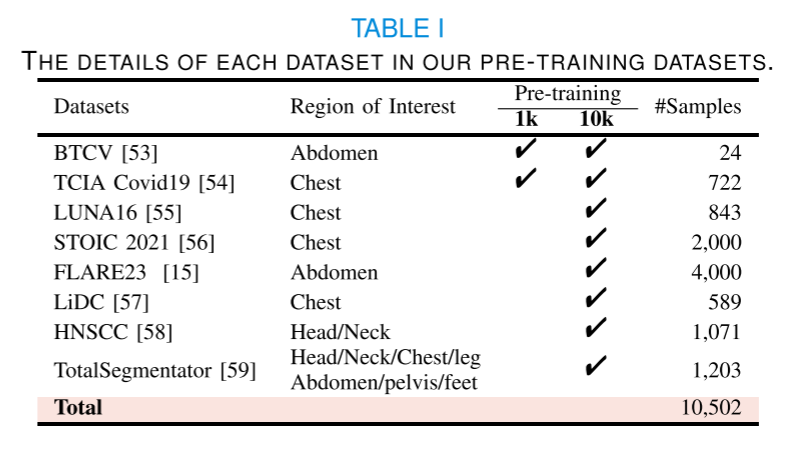
預訓練數據集。為了與之前的研究[8]、[9]、[19]、[20]、[22]、[32]、[38]、[51]、[52]進行公平的比較,我們也在兩個公共數據集上進行了預訓練實驗,即BTCV[53]和TCIA Covid19[54],并將它們合并成一個新的數據集,命名為1k。此外,為了探索我們提出的方法與之前最先進方法[9]、[19]的擴展能力,我們收集了八個公開可訪問的3D醫學圖像數據集,包含10,502次CT掃描,以建立我們的預訓練數據集,我們將其命名為10k。需要注意的是,10k僅用于探索我們提出方法的擴展能力,而我們主要關注1k數據集,以便對我們提出的方法進行公平的比較和分析。表I提供了每個收集的數據集來源的摘要。
下游數據集。我們在十二個公共數據集上進行實驗,即BTCV[53]、MM-WHS[60]、Spleen[61]、Flare22[62]、Amos22[63]、MSD Task03[61]、MSD Task06[61]、MSD Task07[61]、MSD Task08[61]、MSD Task10[61]、BrasTS 21[61]和CC-CCII[64]。這些數據集包括分割和分類任務,前十個數據集用于器官分割,第十一個數據集用于病變分割,第十二個數據集用于腫瘤分割,最后一個數據集用于疾病分類。對于BTCV[53]數據集,我們嚴格遵循先前研究[9]、[11]、[20]中定義的數據分割,僅包括訓練集和驗證集。訓練分割用于預訓練和微調,而驗證分割則從預訓練中排除,僅用于評估。所有其他數據集在預訓練期間都是未見過的。此外,為了評估跨模態泛化能力,我們將在CT掃描上預訓練的模型轉移到MRI數據集BrasTS 21[61]上。我們采用了與之前工作[9]、[19]、[20]一致的設置。
評價指標。 在[9],[20]之后,我們使用骰子相似系數(DSC)和歸一化表面距離(NSD)來評估分割任務。 然后我們利用準確率(ACC)和曲線下面積(AUC)來評估疾病分類任務。
B. Implementation Details
在預訓練過程中,我們遵循了之前研究[9]、[19]的設置,并在表II中提供了我們的MiM(多模態)預訓練設置的詳細信息。具體來說,第一級(level-1)體積是從整個CT體積中隨機裁剪的。我們使用了[25]的backbone作為編碼器,以高效地處理tokens。與之前的自監督學習(SSL)[20]、[49]一樣,預測頭和投影頭都使用MLP層來對齊維度。在微調過程中,我們根據之前的研究[9]、[20],使用Swin-UNETR[21]進行分割任務的微調,使用Swin-ViT進行分類任務的微調。具體來說,對于分割任務,我們丟棄了解碼器,僅在微調期間使用backbone。對于分類任務,我們嚴格遵循了一般計算機視覺[17]、[49]和3D醫學成像[20]中先前使用的方法,僅使用最后一層的特征進行預訓練。雖然結合多尺度特征可以提高分類性能[45]、[67]、[68],但我們選擇不采用這種方法,以確保與其他方法進行公平比較。因此,我們僅使用最后一層的特征,結合全局平均池化(GAP)層和簡單的MLP分類器來預測類別。我們用預訓練過程中學習到的參數初始化網絡的編碼器,并對整個網絡進行微調。對于這些數據集的推理,我們應用了重疊的滑動窗口推理,以便與之前的研究[9]進行公平比較。需要注意的是,為了評估我們提出方法的純粹有效性,我們沒有使用任何基礎模型或后處理技術[7]、[69]。
比較方法。我們將我們的MiM方法與通用自監督學習(SSL)方法和醫學自監督學習方法進行了比較。首先,我們比較了典型的SSL方法MoCov3[66]和MAE[17]、[19],因為它們代表了兩種主流的SSL范式。我們還根據[19]、[20]報告了SimCLR[29]的結果。我們進一步評估了SimMIM[39]、HPM[22]、localMIM[19]和MCMAE[25]的性能,因為它們與我們先進的混合MAE相關。我們還與Adam[47]進行了比較,因為它與我們的多粒度層次設計相關。此外,我們還與大多數現有的最新醫學SSL方法進行了比較。按照自然圖像SSL[17]、[29]、[49]、[66]、[70]和3D醫學圖像[9]、[19]、[20]、[32]、[52]的常見做法,我們對所有方法進行了一輪預訓練和微調,以獲得結果。
C. Experiments on downstream tasks
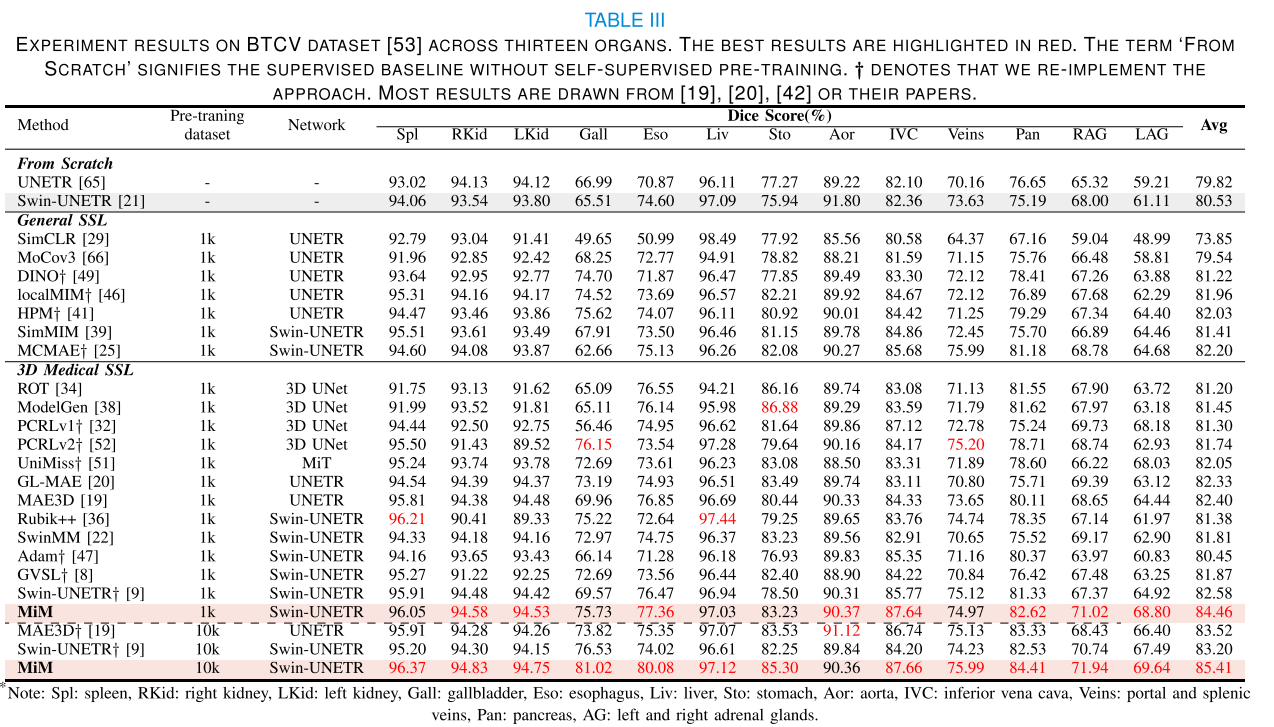
1) Comparison on the BTCV dataset:我們首先在BTCV[53]數據集上進行了實驗,結果展示在表III中。在比較的方法中,SimCLR[29]、MoCov3[66]、DINO[49]、localMIM[46]、HPM[46]、MAE3D[19]、GL-MAE[20]采用了UNETR[65]作為網絡架構。大多數其他方法,包括我們的MiM方法,根據之前的研究[9],使用了Swin-UNETR[21]。表III包括了3D UNet[37]、UNETR[65]和Swin-UNETR[21]的backbone(主干網絡)的詳細信息。UNETR[65]使用了ViT[50],而Swin-UNETR[21]采用了Swin Transformer[45]。對于所有實驗,我們為UNETR[65]使用了ViT-Base[50],為Swin-UNETR[21]使用了Swin-Base[45],以平衡性能和計算效率。這些預訓練的編碼器被用來初始化相應分割網絡的編碼器。
備注:如表III所示,我們觀察到通用自監督學習方法(General SSL methods)的表現不如醫學自監督學習方法(Medical SSL methods)。具體來說,SimCLR[29]和MoCov3[66]分別只達到了73.85%和79.54%。這是因為這些方法依賴于大批量大小和負樣本來避免平凡常數,這對于3D醫學圖像來說是不切實際的。此外,SimCLR[29]和MoCov3[66]中不同圖像之間使用的負關系不適合3D醫學圖像。DINO[49]也只取得了有限的改進。我們提出的MiM方法,以顯著的優勢超越了基于MAE的方法,如MAE3D[19]、GL-MAE[20]、localMIM[46]、HPM[46]和MCMAE[25]。我們得出結論,通用自監督學習方法對3D醫學圖像不太適合,設計自監督學習方法時必須考慮3D醫學圖像的特性。
從頭開始訓練的Swin-UNETR[21]只達到了80.53%的DSC(Dice相似系數)。通過在1k個未標記數據集上預訓練MiM,我們獲得了3.93%的提升,達到了84.46%的DSC,這明顯優于現有的方法。在比較的方法中,Swin-UNETR[9]和MAE3D[19]分別達到了最佳的82.58%和第二好的82.40%的DSC。我們的MiM分別以1.88%和2.06%的DSC超越了這兩種方法,這在這個數據集上是一個明顯的改進。
值得注意的是,擴展定律[71]也適用于3D醫學圖像預訓練。通過在更大規模的未標記10k數據集上進行預訓練,我們觀察到Swin-UNETR[9]和MAE3D[19]分別達到了83.20%和83.52%的DSC分數。我們的MiM在10k數據集上達到了85.41%的DSC分數,這一致顯著地超越了這兩種方法。這些結果表明,擴展在3D醫學圖像預訓練中起著重要作用,我們的MiM方法對于在更大規模的數據集上進行預訓練是有效的。
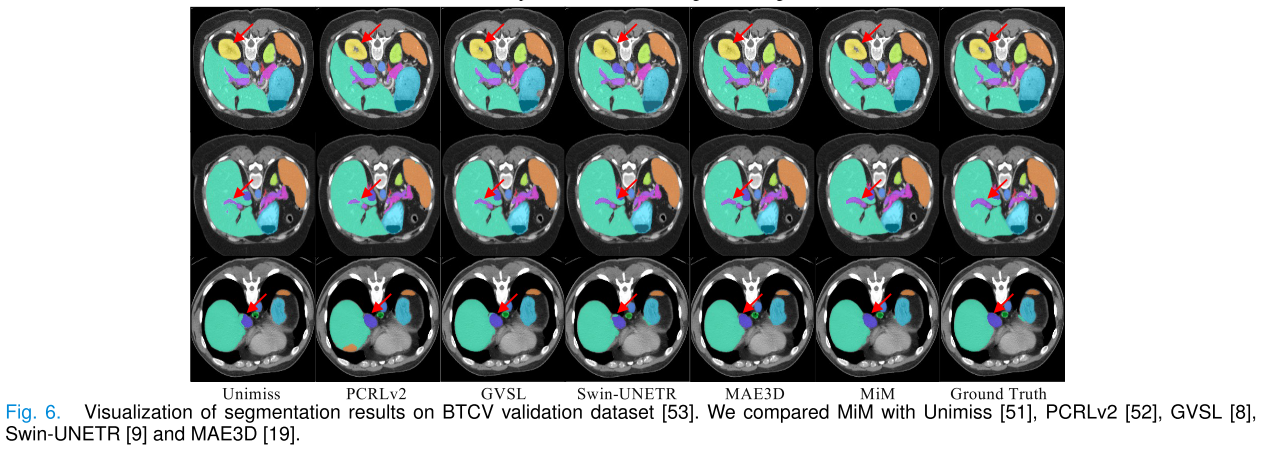
定性結果:MiM被發現可以提高分割結果的完整性,如圖6所示。使用MiM進行分割的結果比現有方法更好。
2) Comparison on the Unseen datasets:
我們進一步在預訓練中未見過的測試集上進行了實驗,即MM-WHS[60]、Spleen[61]、Amos22[63]和Flare22[62]。這四個數據集的結果在表IV中展示。可以觀察到,我們的MiM(可能指某種模型或方法)在所有現有方法中持續表現優異,并且優勢明顯,這證明了其對未見數據集有良好的泛化能力。具體來說,MiM平均比現有方法至少高出1.89%的DSC(可能指某種性能指標,如Dice相似系數)。通過使用更大規模的未標記數據集10k進行預訓練,Swin-UNETR[9]和MAE3D[19]分別提高了0.92%和0.94%的DSC,達到了86.32%和86.64%。我們的MiM也得到了提升,達到了88.34%的DSC,并持續優于這兩種方法。MiM在微調時也顯示出標簽效率[9]。具體來說,使用50%標簽的MiM與從頭開始訓練且使用100%標簽的Swin-UNETR相比,性能相當,并且有明顯的優勢。
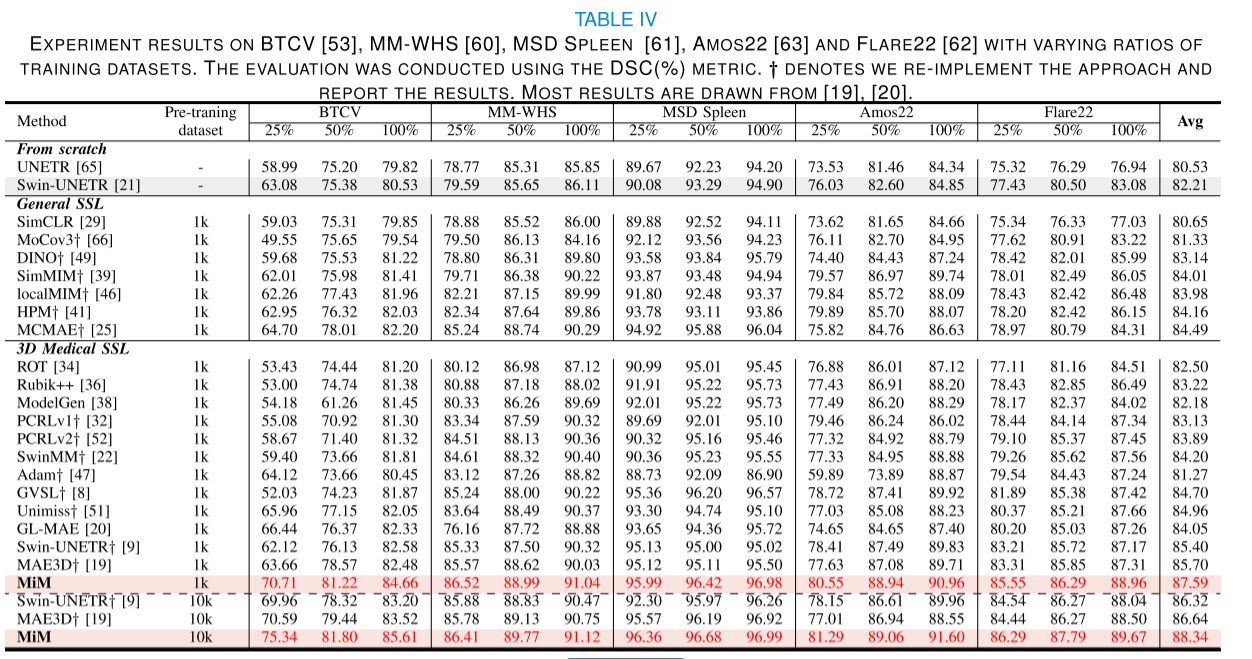
3) Comparison on the MSD datasets:
為了評估在器官分割任務上的泛化能力,我們在MSD數據集[61]上進行了五個基于CT的任務實驗,即任務03肝臟、任務06肺部、任務07胰腺、任務08肝血管和任務10結腸。由于現有的方法沒有使用相同的預訓練數據集進行實驗,我們重新實現了這些方法以便進行公平比較。從表V中可以觀察到,MiM在所有任務中都取得了最好的平均DSC(70.07%)和NSD(78.75%)。由于從頭開始訓練的Swin-UNETR[21]在平均DSC(64.84%對比62.98%)和NSD(73.12%對比69.08%)方面的表現優于UNETR[65],我們進一步基于MiM對UNETR[65]進行了預訓練以進行公平比較。可以觀察到,通過MiM預訓練,Swin-UNETR[21]在DSC和NSD方面分別獲得了平均5.23%和5.63%的提升。使用UNETR[65]作為網絡時,我們在DSC和NSD方面分別觀察到了平均10.09%和9.29%的提升。此外,通過使用更大規模的未標記數據集10k進行預訓練,MiM在DSC和NSD方面分別進一步提高到了70.76%和79.67%。
4) Comparison on CC-CCII dataset:
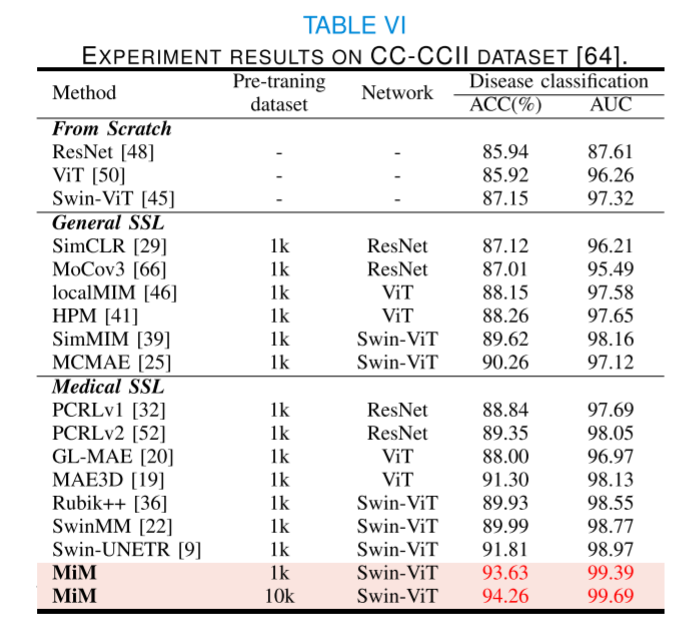
為了評估我們的MiM模型在分類任務上的泛化能力,我們在CC-CCII[64]數據集上對其進行了微調,并將其性能與最先進的通用和醫學領域自監督學習(SSL)方法進行了比較。由于現有的SSL方法沒有在這個數據集上進行實驗,我們復現了相關方法并報告了結果。如表VI所示,可以觀察到MiM在準確率(ACC)和曲線下面積(AUC)方面取得了最佳性能,分別達到了93.63%和99.39%,超越了所有其他方法。這些發現表明,MiM學習到的表征可以很好地轉移到分類問題上,并可有效用于醫學圖像分類任務。通過使用更大規模的預訓練數據集10k,我們的MiM在準確率和AUC方面分別進一步提高到了94.12%和99.52%,這顯示了我們提出的方法在跨任務轉移時的可擴展性。
5) Comparison on the BraTS 21 dataset:
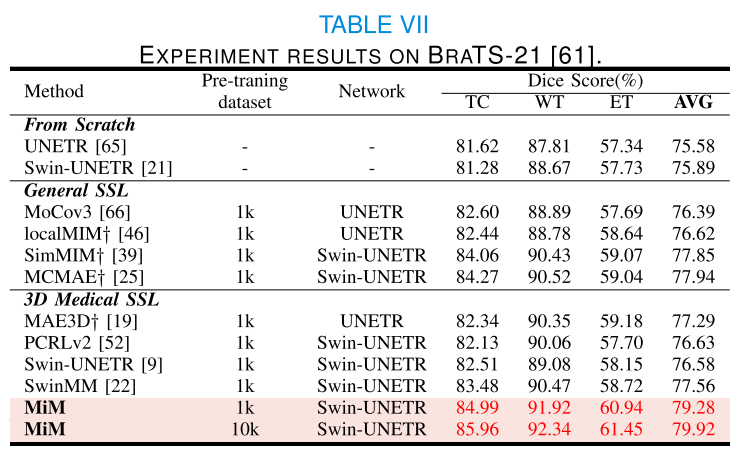
為了評估我們的MiM模型在MRI數據集上的泛化能力,我們在BraTS 21[61] MRI腫瘤分割數據集上對其進行了微調,并將其性能與最先進的通用和醫學自監督學習(SSL)方法進行了比較。WT、TC和ET分別代表整個腫瘤、腫瘤核心和增強腫瘤。從表VII中可以觀察到,SSL方法都能提高模型在BraTS 21[61]數據集上分割腫瘤的性能。這是因為CT和MRI通常用于相同的任務,但目的不同,因此共享相似的解剖結構。因此,從無標簽的CT數據集中學習的SSL方法的知識可以轉移到MRI數據集[9],[72]。我們的MiM模型在所有其他方法中表現最佳,至少提高了1.34%,達到了79.28%的DSC(Dice相似系數)。通過使用更大規模的未標記數據集10k進行預訓練,我們的MiM進一步提高到了79.92%,這顯示了我們提出的方法在跨模態轉移時的可擴展性。
D. Analysis ofour proposed method
所有模型在1k上進行預訓練,然后用BTCV[53]和MM-WHS[60]對模型進行評估。
1) Ablation study:損失函數。 我們對BTCV[53]和MM-WHS[60]驗證數據集進行了全面的消融研究,以評估我們分層設計的有效性,重點是多層次重建和跨水平對準組件。

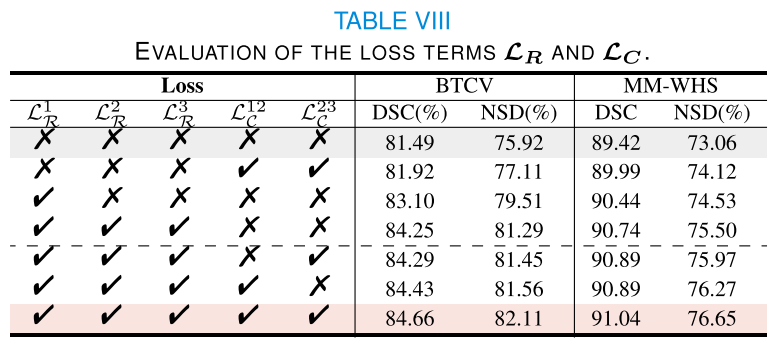
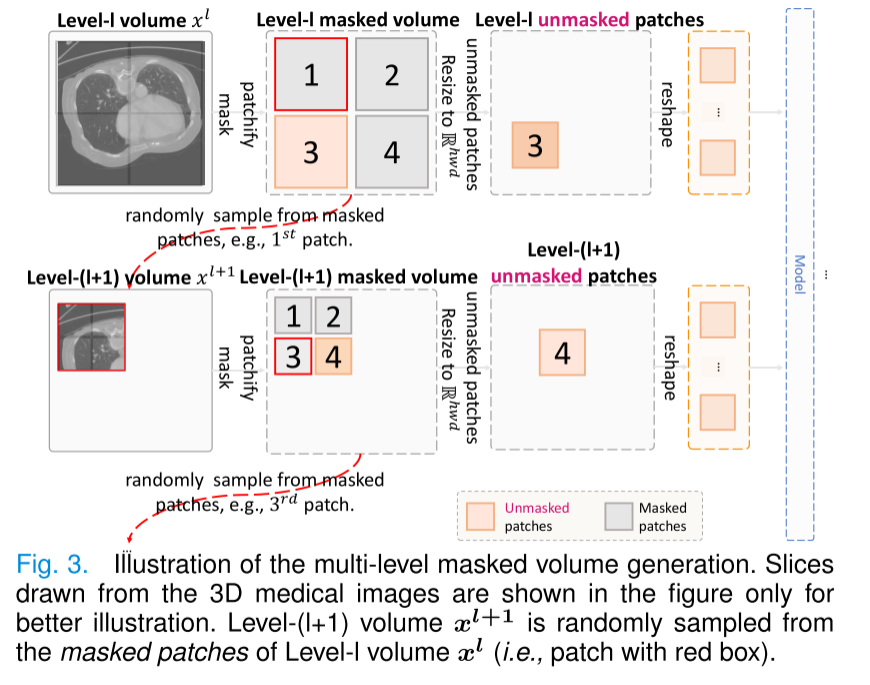
生成后續層級體積的塊類型。 在塊化處理過程中(圖3),每個層級-l體積(xl)被劃分為掩碼和非掩碼塊。 我們在框架中評估了兩種塊類型,用于生成后續層級-l + 1體積(xl+1)。如表IX所示,使用來自xl的掩碼塊來生成xl+1,其性能始終優于使用來自xl的非掩碼塊。這種優越性源于掩碼塊迫使模型恢復缺失信息,從而促進了跨層級重疊區域的有效重建和多尺度語義表示的學習。相比之下,非掩碼塊在同一迭代過程中直接向模型暴露原始體積信息,有效地創建了一個信息捷徑。這個捷徑通過允許模型簡單地復制非掩碼特征,而不是學習推斷和重建它們,減少了學習挑戰,最終限制了模型捕捉豐富語義細節和發展強大泛化能力的能力。
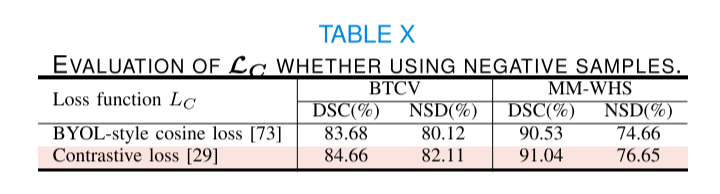
關于LC的負樣本對。在公式6中,我們采用infoNCE損失[29]作為默認選擇。這種損失函數最大化了跨層級圖像之間的相似性,并將負樣本推開。另一種損失函數是BYOL余弦損失[73]。主要區別在于是否使用負樣本。如表X所示,負樣本有助于學習更好的表示[29],因此我們將它們包含在我們的默認選擇中。
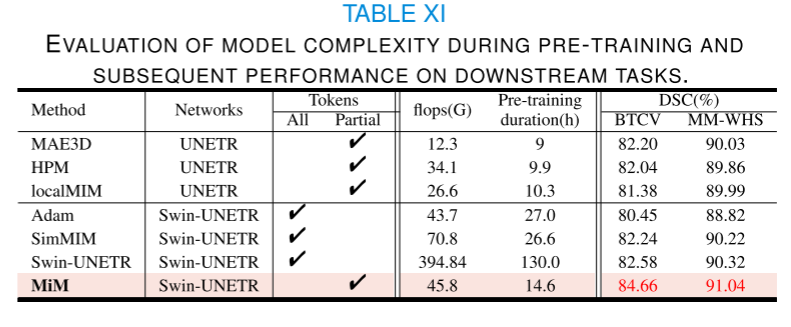
MiM的效率。本研究采用了一種混合卷積-變換器(convolution-transformer)骨干網絡,該網絡將卷積塊與變換器層相結合。通過引入卷積塊,該架構增強了歸納偏置學習,并使得多尺度特征的重用成為可能,有效地支持了混合表示學習[25]。這種設計增強了變換器處理3D醫學圖像的效率和效果。因此,這個骨干網絡是我們所提出框架的基礎組成部分。表XI展示了在預訓練期間不同方法的計算成本(即浮點運算次數flops和時間)的比較分析。我們的評估強調了基于MAE(掩碼自編碼器)的方法與UNETR結合時的計算效率,因為它們僅利用了來自掩碼3D醫學圖像的未掩碼標記。相比之下,其他與混合骨干網絡(如Swin-UNETR)簡單合作的基于MAE的方法則需要處理所有標記。我們提出的方法將混合骨干架構[25]擴展到3D醫學圖像的預訓練階段,在保持計算效率的同時實現了顯著更優的性能。
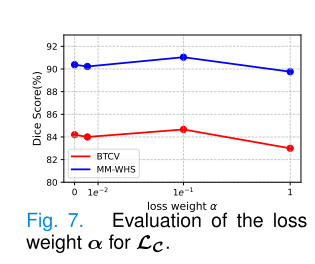
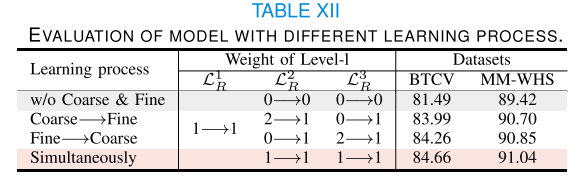
2) Hyper-parameter analysis:LR和LC的權重。在公式10中,MiM的損失函數由兩部分組成。因此,在圖7中,我們增加了α的值。通過觀察,α的最佳值為1e-1。進一步增加跨層對齊的權重并沒有帶來任何額外的好處。這可能是因為跨層對齊函數的幅度遠大于重建損失的幅度,導致忽略了重建過程。不同層級LR的權重。為了確定多級重建的最佳策略,我們通過改變不同層級重建損失的權重,在預訓練期間評估了四種不同的學習過程,如表XII所示。使用BTCV[53]和MM-WHS[60]數據集,我們發現我們的基線模型沒有層次重建(即沒有粗到細和細到粗,所有權重都設置為0)的性能最低,DSC得分為81.4%和89.42%。從粗到細的過程,最初關注較粗的層級,然后再優先考慮較細的層級
,將性能提高到83.99%和90.70%的DSC。值得注意的是,從細到粗的過程,通過從細層級重建開始,顛倒了這個順序,取得了更好的結果,DSC得分為84.26%和90.85%。同時進行的過程,在訓練過程中保持所有層級的權重相等,成為最有效的方法,達到了最高的DSC得分84.66%和91.04%。這些結果表明,層次化學習策略顯著增強了表示學習,同時進行的多級重建證明是最有益的。
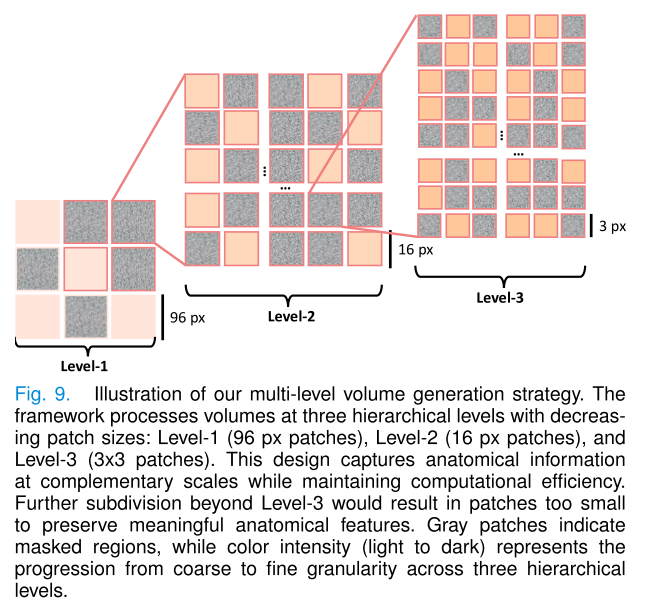
多級數L的設置。我們采用三級架構的做法得到了實證證據和實際考慮的支持。從實證角度來看,如圖9所示,我們的多級策略通過精心選擇的分辨率保留了解剖結構:第一級(384×384×192)捕捉廣泛的上下文信息,第二級(96×96×96)提取中級特征,第三級(16×16×16)保留細節信息。通過在圖8中展示的廣泛實驗,我們研究了改變級數L的數量的影響,并發現L=3產生了最佳性能。增加第四級將導致分辨率極低(1×1×1),雖然可能簡化重建過程,但由于信息損失過大,導致性能次優,這與類似架構中的發現一致[17],[39]。
3) Reconstruction results:我們在圖10中提供了BTCV[53]上的MiM重建結果,其中第一和第二行分別代表體和被遮擋的三維醫學圖像,最后一行的重建結果表現出優異的性能。

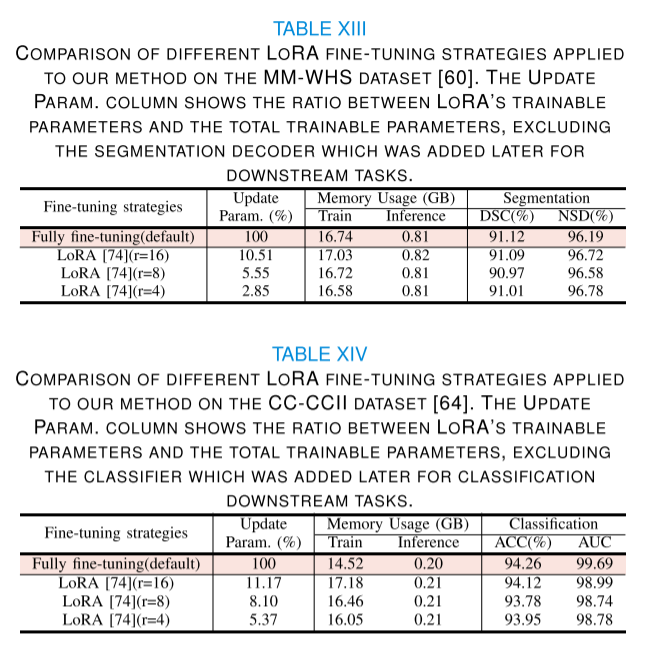
4) Incorporating Parameter-Efficient Fine-Tuning Methods:參數高效的微調方法,如LoRA[74]和Ladder微調[75],在計算資源有限的現實場景中提供了寶貴的洞見[74],[75]。具體來說,我們使用我們提出的方法在3D醫學圖像上評估了LoRA[74]在分類和分割任務上的性能,通過官方代碼庫1實現了它。我們的實現在注意力和卷積層中引入了低秩矩陣來近似權重更新,同時在微調期間凍結原始參數。如表XIII和表XIV所示,LoRA在顯著減少更新參數數量的同時,實現了與全微調相當的性能,這與之前的發現[74]和[75]一致。我們觀察到,增加秩r可以提高性能,接近全微調的性能,盡管這會以增加訓練時間和內存使用為代價。這些結果表明,我們的方法可以在微調期間有效地利用LoRA[74],在計算資源和性能之間實現最佳平衡。
V. CONCLUSION
在本文中,我們介紹了掩碼中的掩碼(Mask in Mask,簡稱MiM)預訓練框架,它顯著推進了3D醫學圖像分析的發展。通過結合層次化設計,即多級重建和跨級對齊,MiM有效地將結構和細節的多粒度視覺線索編碼到表示中。為了促進對現有方法的公平和全面比較,我們收集了十個公共數據集,并策劃了兩個規模的預訓練數據集,即1k和10k。結果表明,MiM框架的層次化設計對于實現3D醫學圖像的優越性能至關重要。我們進一步探索將預訓練數據集擴展到10k。結果表明,通過擴展預訓練數據集,MiM的性能可以進一步提高。這一發現強調了大規模預訓練在構建3D醫學圖像基礎模型中的重要性。
基于這項工作,可以探索幾個有前景的方向。(1) 構建大規模的預訓練數據集,例如,超過10萬個體積。(2) 探索更多的下游任務,例如,3D醫學圖像配準。(4) 探索使用可學習的層級嵌入代替硬編碼層級數量的潛力。(3) 探索與其他模態合作進行多模態預訓練,例如,語言。實際上,(1) 是3D醫學圖像基礎模型的基石,(2) 可以進一步理解評估。(3) 可以通過不同模態的信息來補充3D醫學基礎模型。(4) 可以進一步改進方法的設計。

)
)


?)




)








