文章目錄
- 一、引言
- 二、讀服務的功能性需求
- 三、兩大基本設計原則
- 1. 架構盡量不要分層
- 2. 代碼盡可能簡單
- 四、實戰方案:懶加載架構及其四大挑戰
- 五、改進思路
- 六、總結與思考題

一、引言
在任何后臺系統設計中,「讀多寫少」的業務場景占據主流:瀏覽商品、刷資訊、訪問用戶畫像……相比寫操作,讀操作的并發壓力更大、對性能的要求也更苛刻。為此,我們需要從 讀服務(或稱讀接口/讀業務)的角度,系統地探討如何在高可用、高性能和超高 QPS(上萬~百萬峰值)的場景下構建穩健的架構。
接下來我們將圍繞讀服務的功能特點、兩大基本設計原則,以及行業中常見的懶加載架構及其四大挑戰,快速掌握實戰思路。
二、讀服務的功能性需求
讀服務在執行流程上,基本是 無狀態、無副作用 的:
- 從持久層(數據庫、Redis、Elasticsearch 等)獲取原始數據;
- 簡單加工或直接返回給前端。
因此,讀服務必須滿足三大指標:
- 高可用:任何業務都需保證持續在線;
- 高性能:TP999 必須控制在 100ms 以內;
- 超高 QPS 支撐:滿足上萬至百萬級峰值請求。
只有確保這三點,才能給用戶帶來流暢的體驗,避免卡頓或秒級延遲。
三、兩大基本設計原則
1. 架構盡量不要分層
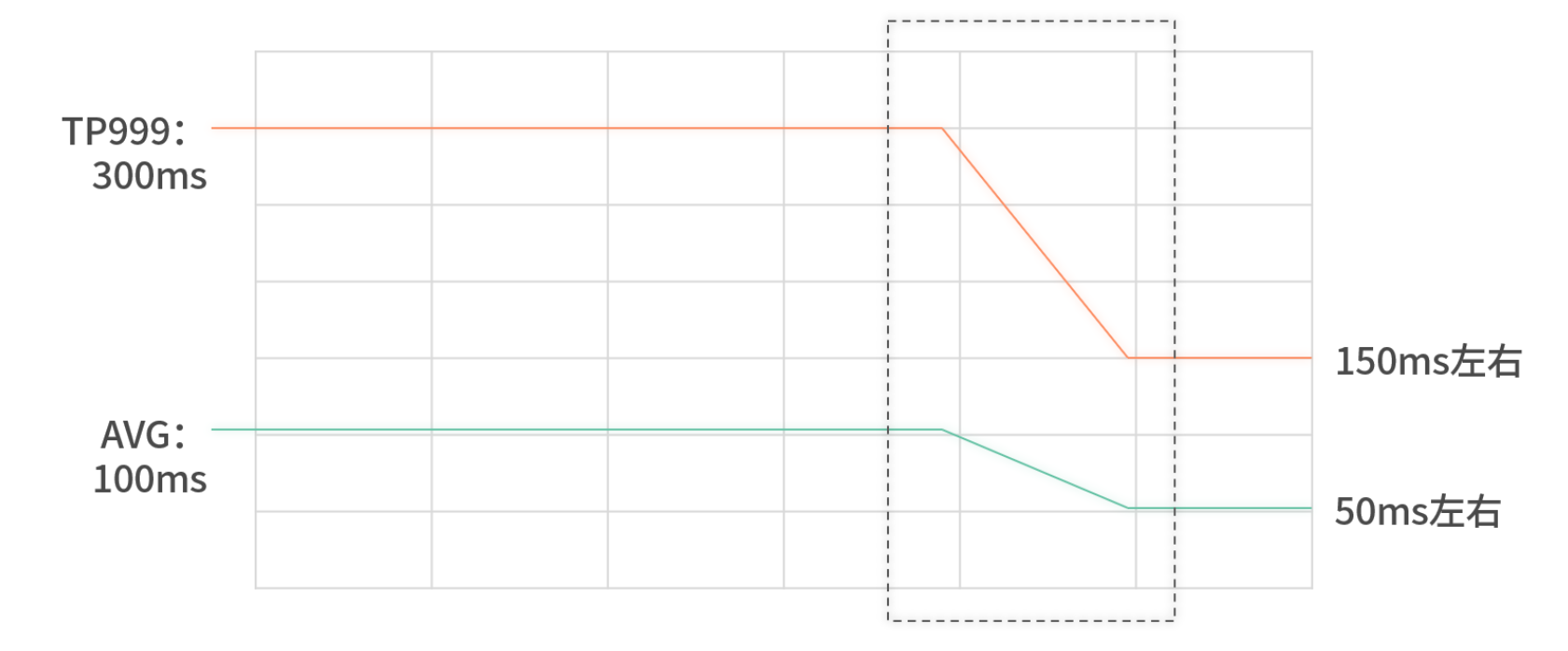
傳統分層(服務層→數據訪問層→存儲)雖然能降低代碼耦合,但網絡調用(RPC/HTTP)往返會成倍消耗延遲。監控數據顯示,分層架構下讀請求的 TP99、TP999 指標往往翻倍,且毛刺明顯增多。
優化思路:將數據訪問層編譯進同一進程,去除網絡傳輸環節。
內嵌后,TP999 可下降近 50%,平均延遲降低 20%~30%,部署成本也大幅下降。
2. 代碼盡可能簡單
讀服務鏈路雖然清晰,但模型層次多、映射開銷大。引入過多框架、全量日志打印、全量字段查詢都會拖慢性能。
- 慎用反射/Codegen 框架:如 Spring Bean.copyProperties,反射性能開銷高。
- 精細化日志:只打印關鍵信息,避免 JSON 序列化全量對象。
- 按需字段查詢:MySQL 避免
SELECT *,Redis 使用 Hash 并定位字段。
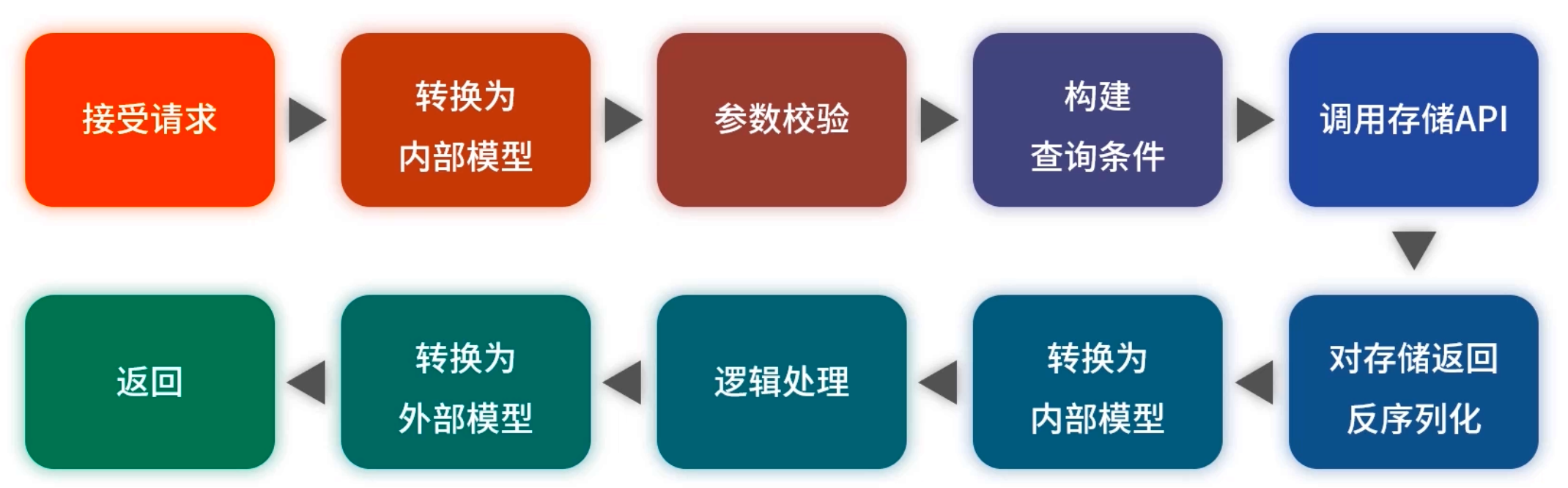
簡化至:參數校驗 → 查詢構建 → 存儲反序列化 → 業務加工 → 返回,把每一步都做到最輕量。
四、實戰方案:懶加載架構及其四大挑戰
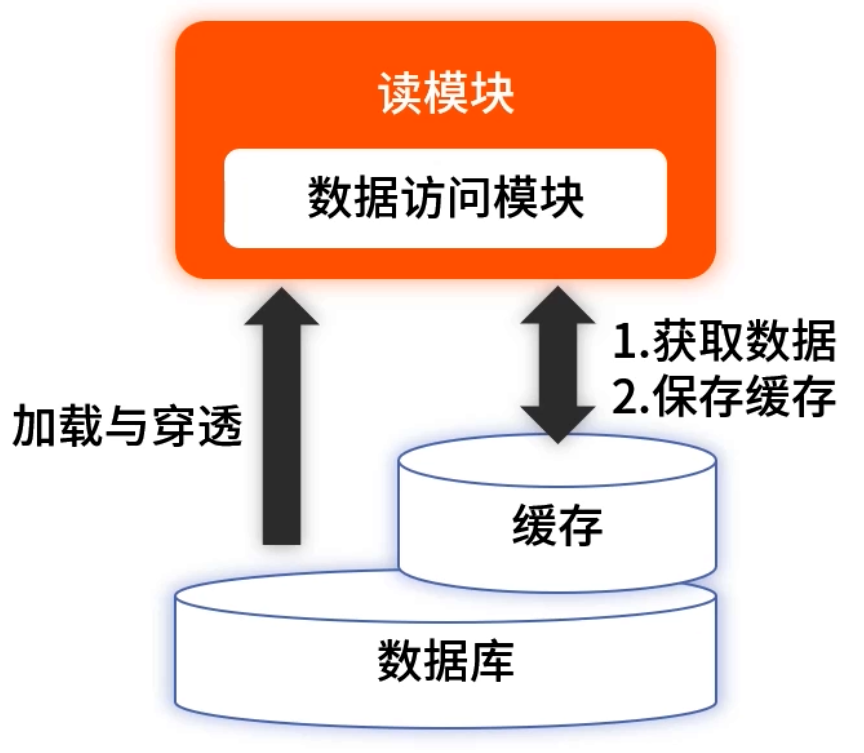
最常見的讀服務方案:緩存(Redis)+ 數據庫(MySQL) 的懶加載模式:
- 服務先查 Redis;
- 未命中則讀數據庫并寫回緩存(帶過期時間);
該方案實現成本低、思路清晰,但在高并發下會暴露以下問題:
-
緩存穿透
- 惡意請求不存在的 key → 每次都落到數據庫,易打掛。 符 + 參數前置校驗(如 IP、MAC、KOAP token),攔截非法請求。
-
緩存雪崩
- 同期過期后大量請求打到數據庫。
- 解決:過期時間加鹽,避免同一時刻熱點 key 大規模失效。
-
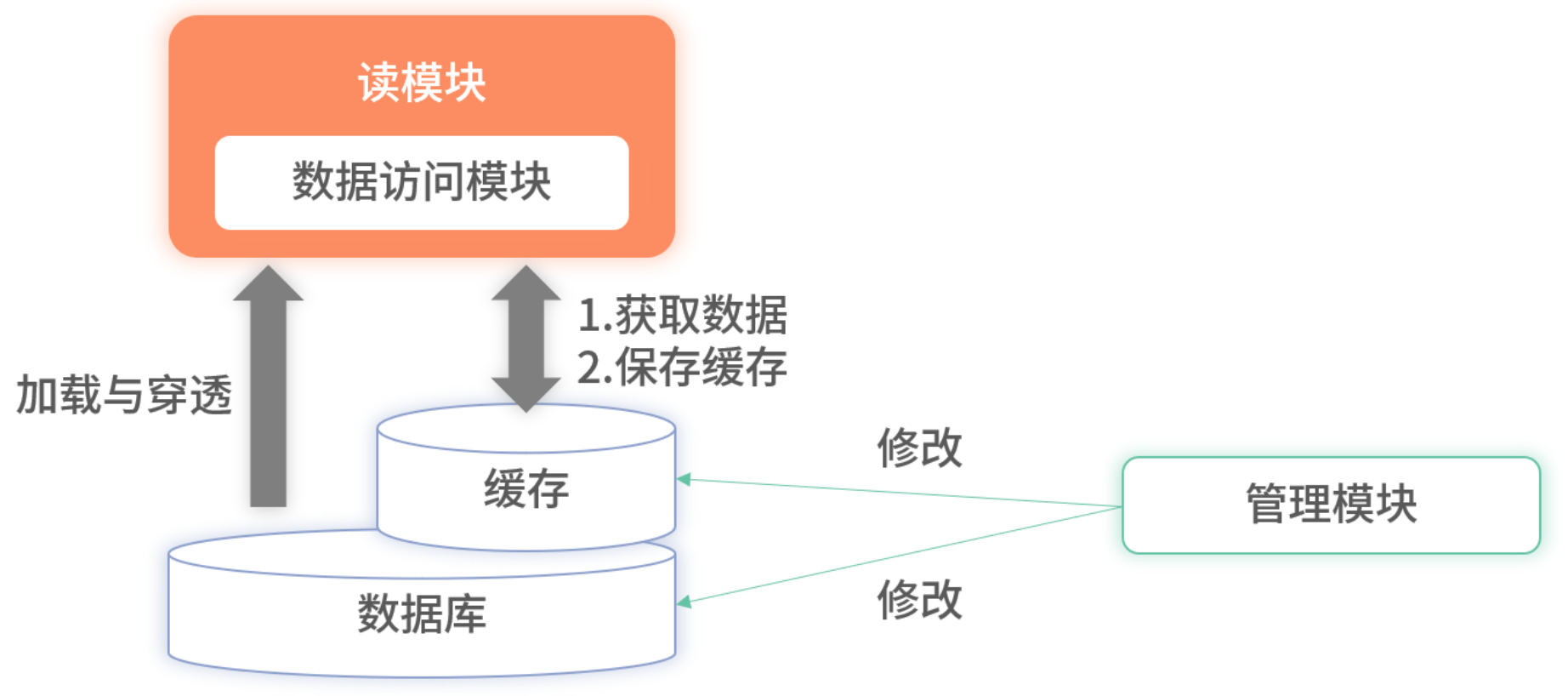
實時性不足
- 依賴過期失效機制,更新延遲。
- 改進可在寫操作后主動推送變更,但需處理數據庫與緩存更新順序及分布式事務漏失。
-
性能毛刺
- 緩存過期瞬間穿透到數據庫,延遲從毫秒級飆升至秒級。
- 可以借助全量緩存和預熱機制以平滑毛刺。
五、改進思路
利用 全量緩存、消息隊列同步、預熱與降級 等技術,打造真正的毫秒級讀服務。請參考下篇博客 。
六、總結與思考題
- 兩大原則:架構不分層、代碼簡單。
- 懶加載四大問題:穿透、雪崩、實時性、毛刺。








)


)



)
實戰指南)



